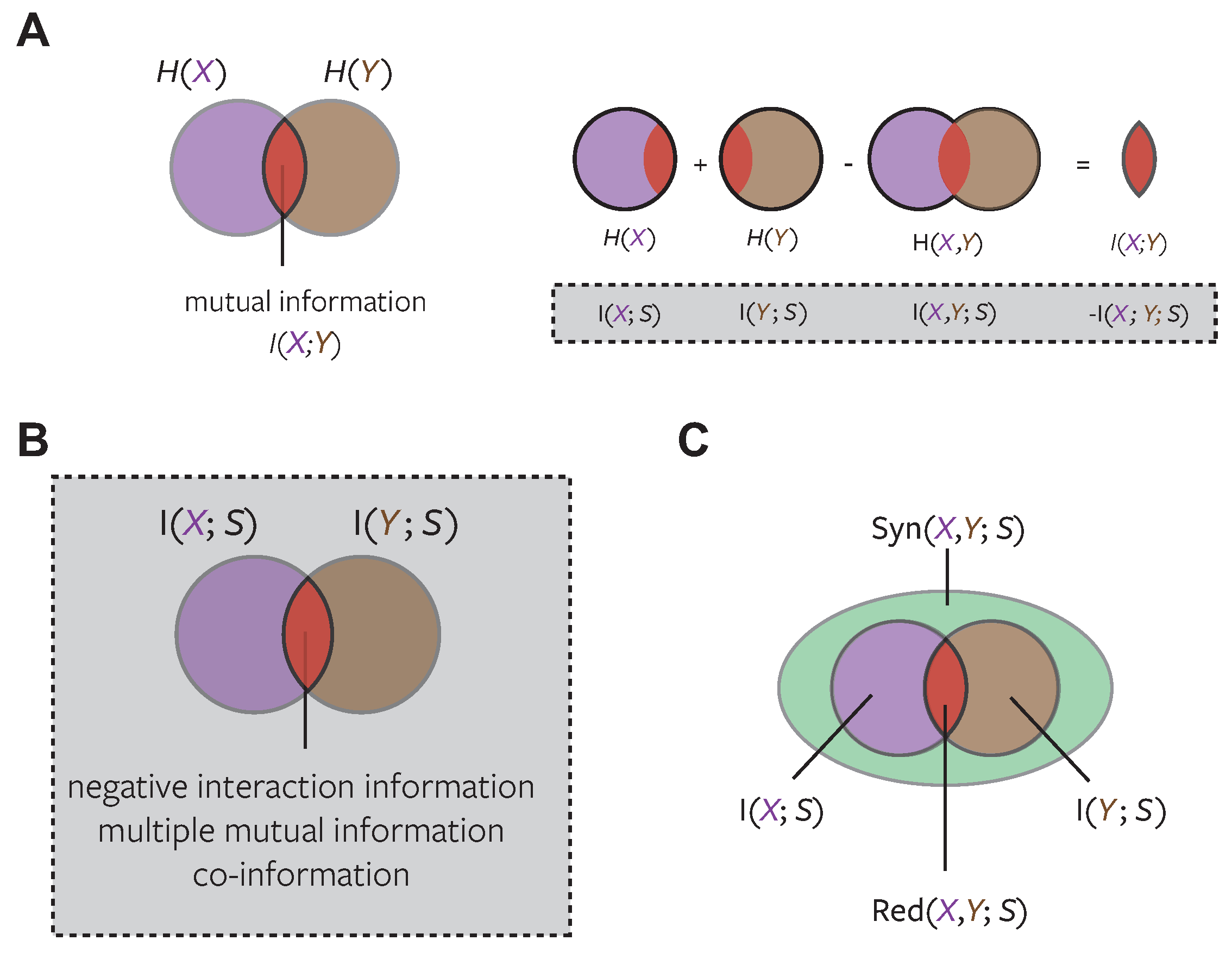
4.3.1. A Game-Theoretic Operational Definition of Unique Information
Bertschinger et al. [
12] introduce an operational interpretation of unique information based on decision theory, and use that to argue the “unique and shared information should only depend on the marginal [source-target] distributions”
(their Assumption (*) and Lemma 2). Under the assumption that those marginals alone should specify redundancy they find
via maximisation of co-information. Here we review and extend their operational argument and arrive at a different conclusion.
Bertschinger et al. [
12] operationalise unique information based on the idea that if an agent, Alice, has access to unique information that is not available to a second agent, Bob, there should be some situations in which Alice can exploit this information to gain a systematic advantage over Bob ([
7], Appendix B therein). They formalise this as a decision problem, with the systematic advantage corresponding to a higher expected reward for Alice than Bob. They define a decision problem as a tuple
where
is the marginal distribution of the target,
S,
is a set of possible actions the agent can take, and
is the reward function specifying the reward for each
. They assert that unique information exists if and only if there exists a decision problem in which there is higher expected reward for an agent making optimal decisions based on observation of
, versus an agent making optimal decisions on observations of
. This motivates their fundamental assumption that unique information depends only on the pairwise target-predictor marginals
,
([
12] Assumption *), and their assertion that
implies no unique information in either predictor.
We argue that the decision problem they consider is too restrictive, and therefore the conclusions they draw about the properties of unique and redundant information are incorrect. Those properties come directly from the structure of the decision problem; the reward function u is the same for both agents, and the agents play independently from one other. The expected reward is calculated separately for each agent, ignoring by design any trial by trial covariation in their observed evidence , and resulting actions.
While it is certainly true that if their decision problem criterion is met, then there is unique information, we argue that the decision problem advantage is not a necessary condition for the existence of unique information. We prove this by presenting below a counter-example, in which we demonstrate unique information without a decision theoretic advantage. To construct this example, we extend their argument to a game-theoretic setting, where we explicitly consider two agents playing against each other. Decision theory is usually defined as the study of individual agents, while situations with multiple interacting agents are the purview of game theory. Since the unique information setup includes two agents, it seems more natural to use a game theoretic approach. Apart from switching from a decision theoretic to a game theoretic perspective, we make exactly the same argument. It is possible to operationalise unique information so that unique information exists if and only if there exists a game (with certain properties described below) where one agent obtains a higher expected reward when both agents are playing optimally under the same utility function.
We consider two agents interacting in a game, specifically a non-cooperative, simultaneous, one-shot game [
40] where both agents have the same utility function. Non-cooperative means the players cannot form alliances or agreements. Simultaneous (as opposed to sequential) means the players move simultaneously; if not actually simultaneous in implementation such games can be effectively simultaneous as long as each player is not aware of the other players actions. This is a crucial requirement for a setup to operationalise unique information because if the game was sequential, it would be possible for information to “leak” from the first players evidence, via the first players action, to the second. Restricting to simultaneous games prevents this, and ensures each game provides a fair test for unique information in each players individual predictor evidence. One-shot (as opposed to repeated) means the game is played only once as a one off, or at least each play is completely independent of any other. Players have no knowledge of previous iterations, or opportunity to learn from or adapt to the actions of the other player. The fact that the utility function is the same for the actions of each player makes it a fair test for any advantage given by unique information—both players are playing by the same rules. These requirements ensure that, as for the decision theoretic argument of [
12], each player must chose an action to maximise their reward based only the evidence they observe from the predictor variable. If a player is able to obtain a systematic advantage, in the form of a higher expected reward for some specific game, given the game is fair and they are acting only on the information in the predictor they observe, then this must correspond to unique information in that predictor. This is the same as the claim made in [
12] that higher expected reward in a specific decision problem implies unique information in the predictor.
In fact, if in addition to the above properties the considered game is also symmetric and non-zero-sum then this is exactly equivalent to the decision theoretic formulation. Symmetric means the utility function is invariant to changes of player identity (i.e., it is the same if the players swap places). Alternatively, an asymmetric game is one in which the reward is not necessarily unchanged if the identity of the players is switched. A zero-sum game is one in which there is a fixed reward that is distributed between the players while in a non-zero-sum game the reward is not fixed. The decision problem setup is non-zero-sum, since the action of one agent does not affect the reward obtained by the other agent. Both players consider the game as a decision problem and so play as they would in the decision theoretic framework (i.e., to choose an action based only on their observed evidence in such a way as to maximise their expected reward). This is because since the game is non-cooperative, simultaneous and one-shot they have no knowledge of or exposure to the other players actions.
We argue unique information should also be operationalised in asymmetric and zero-sum games, since these also satisfy the core requirements outlined above for a fair test of unique information. In a zero-sum game, the reward of each agent now also depends on the action of the other agent, therefore unique information is not invariant to changes in
, because this can change the balance of rewards on individual realisations. Note that this does not require either player is aware of the others actions (because the game is simultaneous), they still chose an action based only on their own predictor evidence, but their reward depends also on the action of the other agent (although those actions themselves are invisible). The stochastic nature of the reward from the perspective of each individual agent is not an issue since, as for the decision theoretic approach, we consider only one-shot games. Alternatively, if an asymmetry is introduced to the game, for example by allowing one agent to set the stake in a gambling task, then again
affects the unique information. We provide a specific example for this second case, and specify an actual game which meets the above requirements and provides a systematic advantage to one player, demonstrating the presence of unique information. However, this system does not admit a decision problem which provides an advantage. This counter-example therefore proves that the decision theoretic operationalisation of [
12] is not a necessary condition for the existence of unique information.
Borrowing notation from [
12] we consider two agents, which each observe values from
and
respectively, and take actions
. Both are subject the same core utility function
, but we break the symmetry in the game by allowing one agent to perform a second action—setting the stake on each hand (realisation). This results in utility functions
, where
c is a stake weighting chosen by agent 1 on the basis of their evidence. This stake weighting is not related to their guess on the value
s (their action
), but serves here as a way to break the symmetry of the game while maintaining equal utility functions for each player. That is, although the reward here is a function also of
, it is the same function for both players, so
. In general, in the game theoretic setting the utility function can depend on the entire state of the world,
, but here we introduce only an asymmetric dependence on
. Both agents have the same utility function as required for a fair test of unique information, but that utility function is asymmetric—it is not invariant to switching the players. The second agent is not aware of the stake weighting applied to the game when they choose their action. The tuple
defines the game with
. In this case the reward of agent 2 depends on
, introducing again a dependence on
. However, because both agents have the same asymmetric utility function, this game meets the intuitive requirements for an operational test of unique information. If there is no unique information, agent 1 should not be able to profit simply by changing the stakes on different trials. If they can profit systematically by changing the stakes on trials that are favourable to them based on the evidence they observe, that is surely an operationalisation of unique information. We emphasise again that we are considering here a non-cooperative, simultaneous, one-shot, non-zero-sum, asymmetric game. So agent 2 does not have any information about the stake weight on individual games, and cannot learn anything about the stake weight from repeated plays. Therefore, there is no way for unique information in
to affect the action of agent 2 via the stake weight setting. The only difference from the decision theoretic framework is that here we consider an asymmetric utility function.
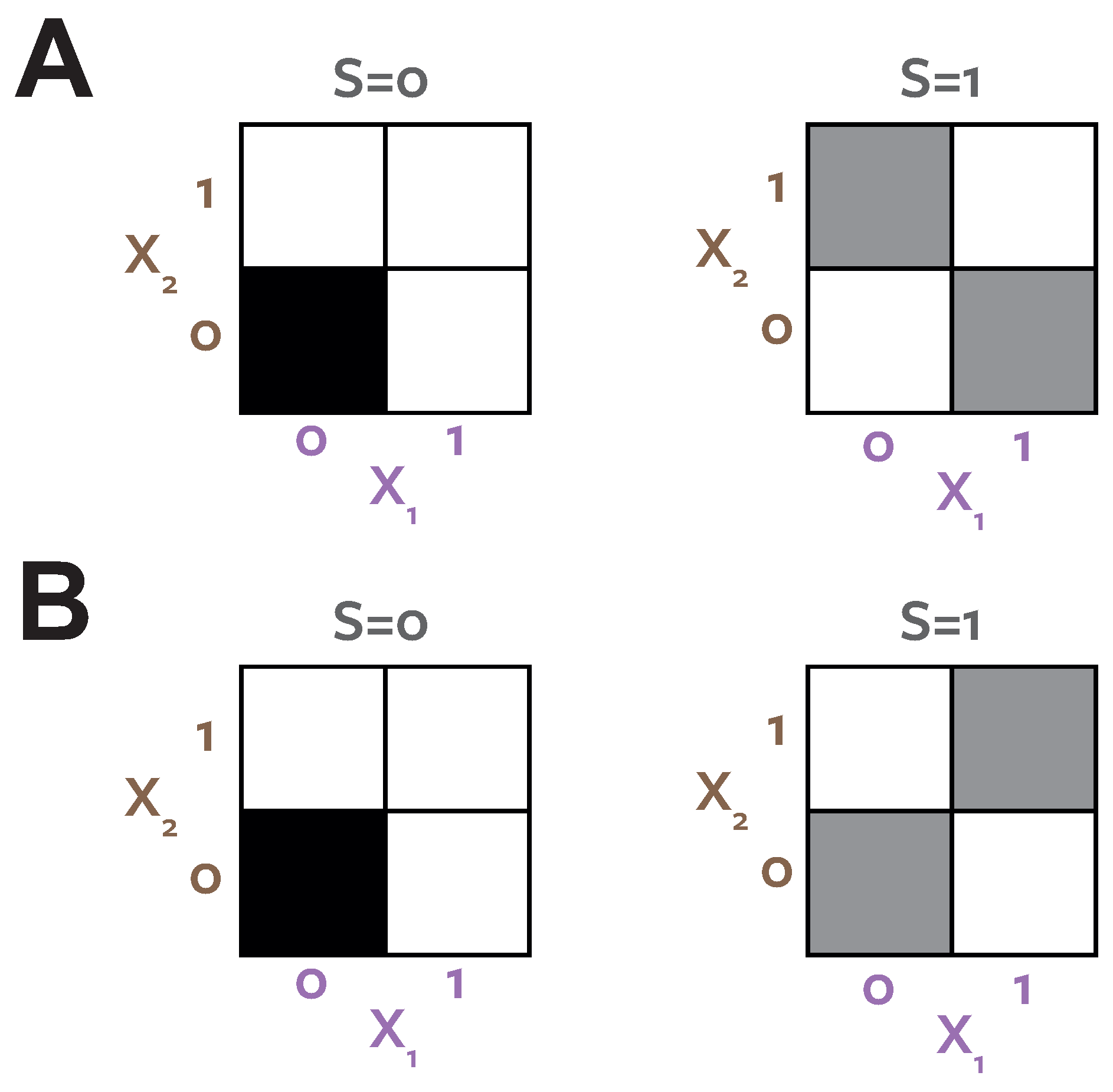
To demonstrate this, and provide a concrete counter-example to the decision theoretic argument [
12] we consider a system termed
ReducedOr (Joseph Lizier,
personal communication).
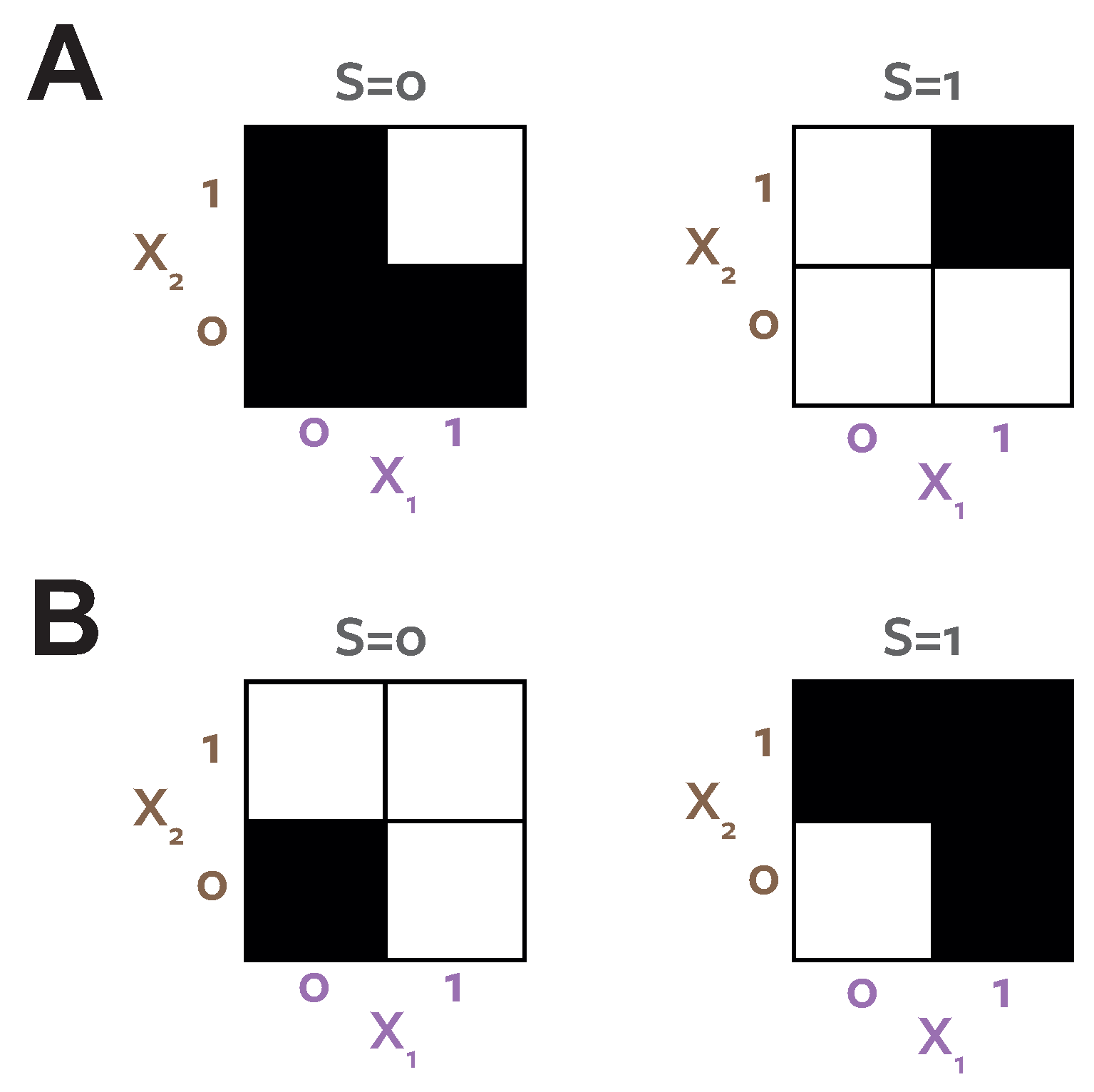
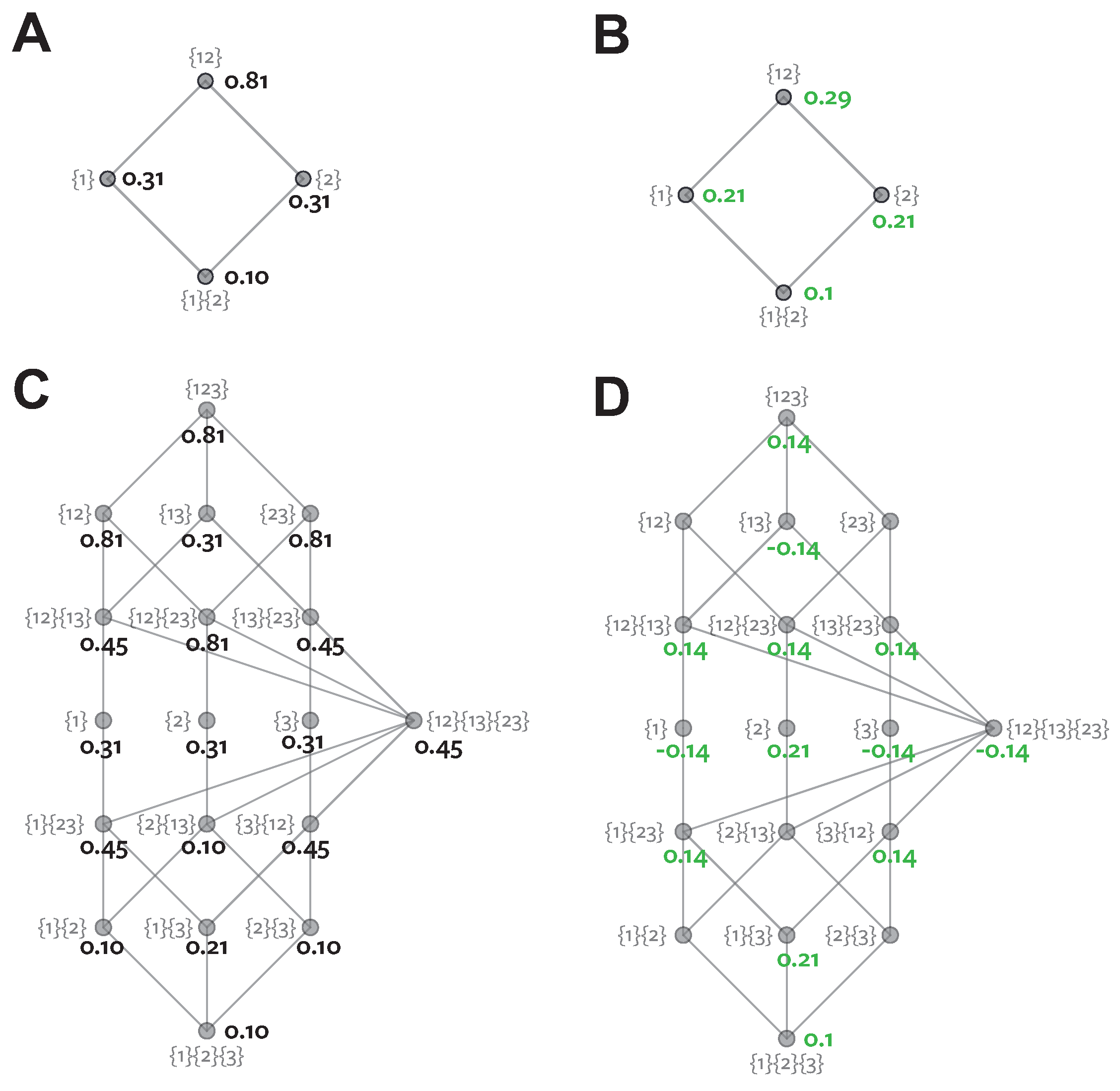
Figure 4A shows the probability distribution which defines this binary system.
Table 6 shows the PIDs for this system.
Figure 4B shows the distribution resulting from the
optimisation procedure. Both systems have the same target-predictor marginals
, but have different predictor-predictor marginals
.
reports zero unique information.
reports zero redundancy, but unique information present in both predictors.
In the
optimised distribution (
Figure 4B) the two predictors are directly coupled,
. In this case there is clearly no unique information. The coupled marginals mean both agents see the same evidence on each realisation, make the same choice and therefore obtain the same reward, regardless of the stake weighting chosen by agent 1. However, in the actual system, the situation is different. Now the evidence is de-coupled, the agents never both see the evidence
on any particular realisation
. Assuming a utility function
reflecting a guessing game task, the optimal strategy for both agents is to make a guess
when they observe
, and guess
when they observe
. If Alice (
) controls the stake weight she can choose
which results in a doubling of the reward when she observes
versus when she observes
. Under the true distribution of the system for realisations where
, we know that
and
, so Bob will guess
and be wrong (have zero reward). On an equal number of trials Bob will see
, guess correctly and Alice will win nothing, but those trials have half the utility of the trials that Alice wins due to the asymmetry resulting from her specifying the gambling stake. Therefore, on average, Alice will have a systematically higher reward as a result of exploiting her unique information, which is unique because on specific realisations it is available only to her. Similarly, the argument can be reversed, and if Bob gets to choose the stakes, corresponding to a utility weighting
, he can exploit unique information available to him on a separate set of realisations.
Both games considered above would provide no advantage when applied to the
distribution (
Figure 4B). The information available to each agent when they observe
is not unique, because it always occurs together on the same realisations. There is no way to gain an advantage in any game since it will always be available simultaneously to the other agent. In both decompositions the information corresponding to prediction of the stimulus when
is quantified as
bits.
quantifies this as redundancy because it ignores the structure of
and so does not consider the within trial relationships between the agents evidence.
cannot distinguish between the two distributions illustrated in
Figure 4.
quantifies the
bits as unique information in both predictors, because in the true system each agent sees the informative evidence on different trials, and so can exploit it to gain a higher reward in a certain game.
agrees with
in the system in
Figure 4B, because here the same evidence is always available to both agents, so is not unique.
We argue that this example directly illustrates the fact that unique information is not invariant to
, and that the decision theoretic operational definition of [
12] is too restrictive. The decision theory view says that unique information corresponds to an advantage which can be obtained only when two players go to different private rooms in a casino, play independently and then compare their winnings at the end of the session. The game theoretic view says that unique information corresponds to any obtainable advantage in a fair game (simultaneous and with equal utility functions), even when the players play each other directly, betting with a fixed pot, on the same hands at the same table. We have shown a specific example where there is an advantage in the second case, but not the first case. We suggest such an advantage cannot arise without unique information in the predictor and therefore claim this counter-example proves that the decision theoretic operationalisation is not a necessary condition for the existence of unique information. While this is a single specific system, we will see in the examples (
Section 5) that the phenomenon of
over-stating redundancy by neglecting unique information which is masked when the inputs are coupled occurs frequently. We argue this occurs because the
optimisation maximises co-information. It therefore couples the predictors to maximise the contribution of source redundancy to the co-information, since the game theoretic operationalisation shows that redundancy is not invariant to the predictor-predictor marginal distribution.
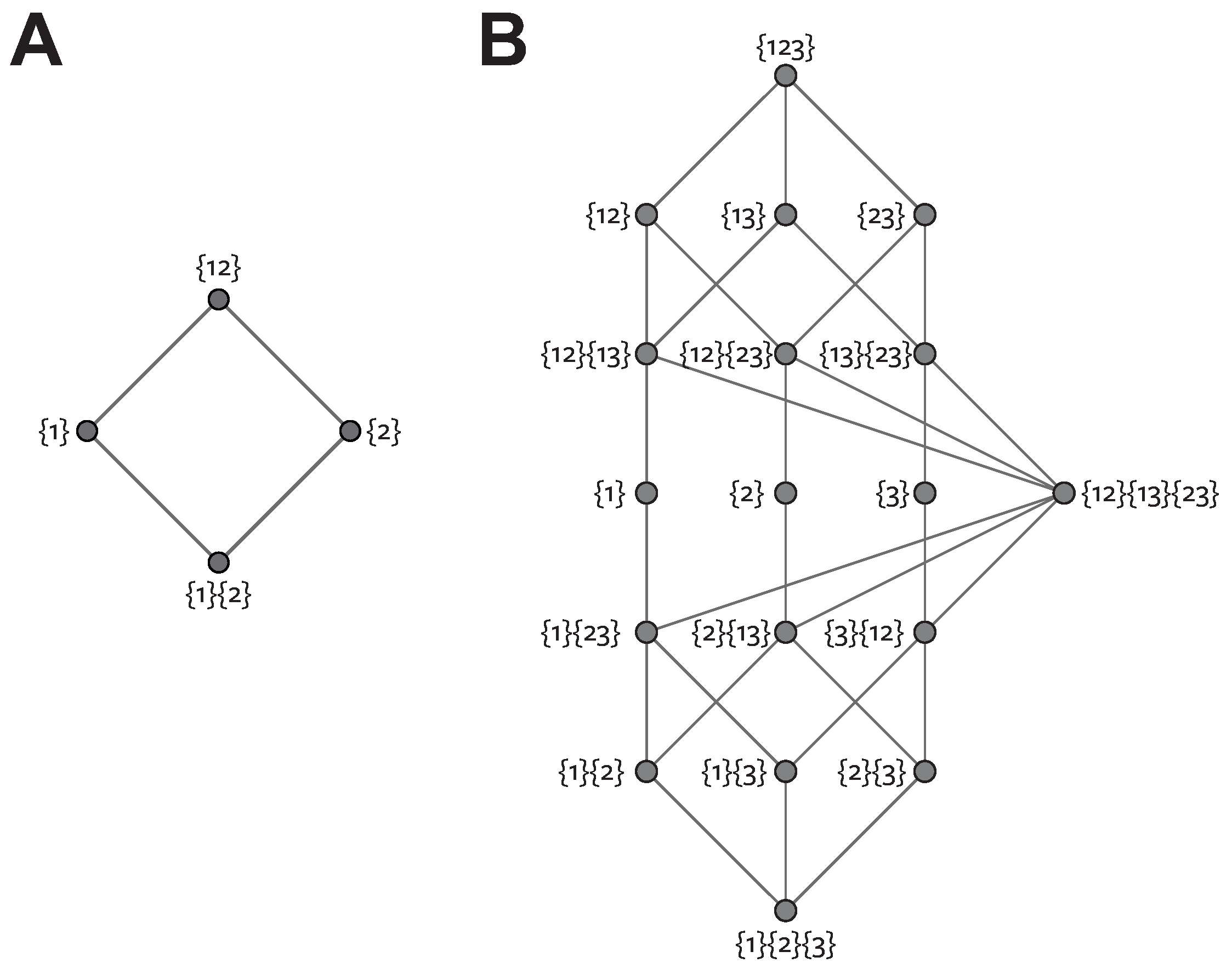
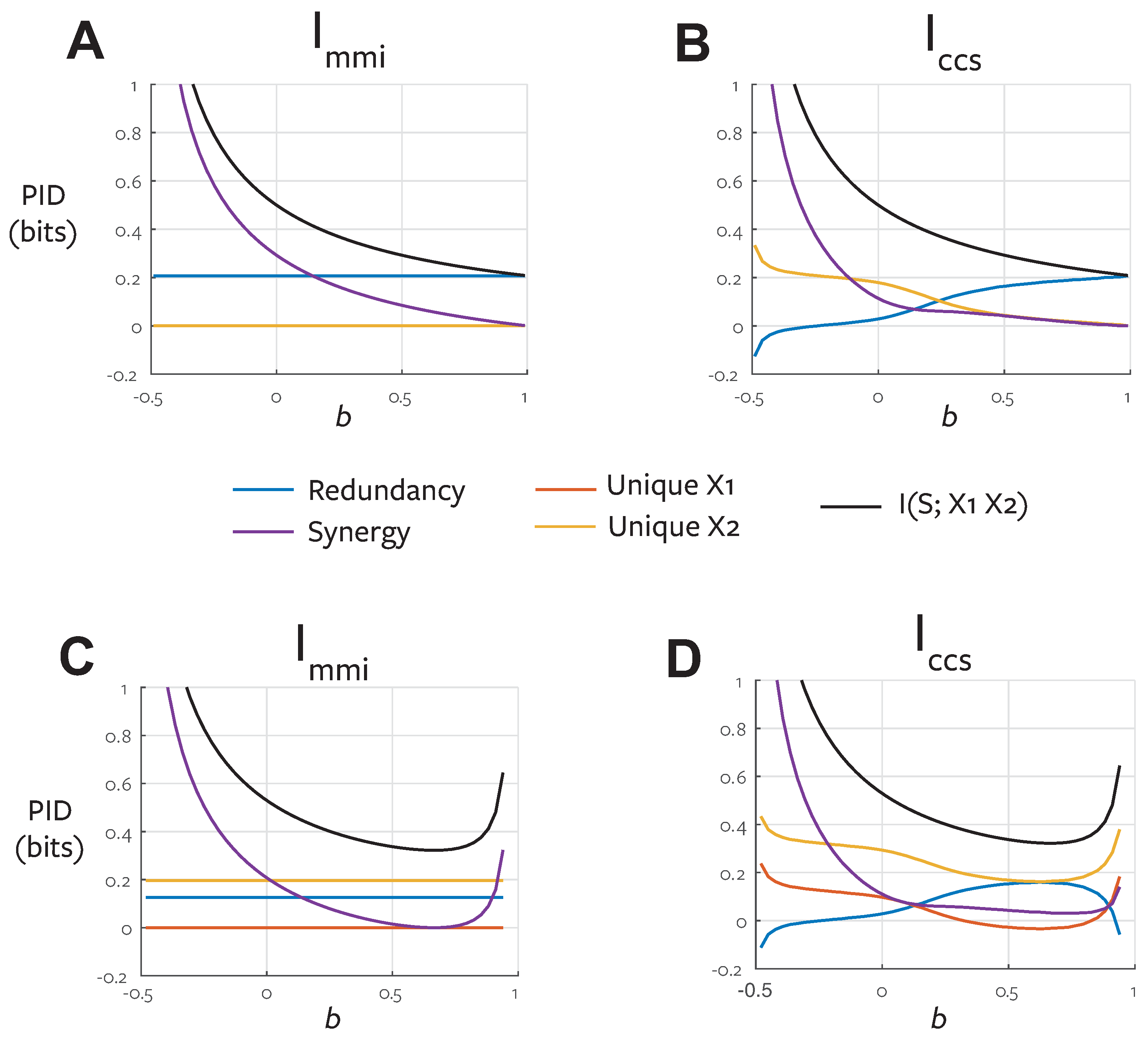
4.3.2. Maximum Entropy Optimisation
For simplicity we consider first a two-predictor system. The game-theoretic operational definition of unique information provided in the previous section requires that the unique information (and hence redundancy) should depend only on the pairwise marginals
,
and
. Therefore, any measure of redundancy which is consistent with this operational definition should take a constant value over the family of distributions which satisfy those marginal constraints. This is the same argument applied in [
12] but we consider here the game-theoretic extension to their decision theoretic operationalisation. Co-information itself is not constant over this family of distributions, because its value can be altered by third order interactions (i.e., those not specified by the pairwise marginals). Consider for example
Xor. The co-information of this distribution is
bits, but the maximum entropy distribution preserving pairwise marginal constraints is the uniform distribution with a co-information of 0 bits. Therefore, if
were calculated using the full joint distribution it would not be consistent with the game-theoretic operational definition of unique information.
Since redundancy should be invariant given the specified marginals, our definition of
must be a function only of those marginals. However, we need a full joint distribution over the trivariate joint space to calculate the pointwise co-information terms. We use the maximum entropy distribution subject to the constraints specified by the game-theoretic operational definition (Equation (
31)). The maximum entropy distribution is by definition the most parsimonious way to fill out a full trivariate distribution given only a set of bi-variate marginals [
41]. It introduces no additional structure to the 3-way distribution over that which is specified by the constraints. Pairwise marginal constrained maximum entropy distributions have been widely used to study the effect of third and higher order interactions, because they provide a surrogate model which removes these effects [
42,
43,
44,
45]. Any distribution with lower entropy would by definition have some additional structure over that which is required to specify the unique and redundant information following the game-theoretic operationalisation.
Note that the definition of
follows a similar argument. If redundancy was measured with co-information directly, it would not be consistent with the decision theoretic operationalisation [
12]. Bertschinger et al. [
12] address this by choosing the distribution which maximises co-information subject to the decision theoretic constraints. While we argue that maximizing entropy is in general a more principled approach than maximizing co-information, note that with the additional predictor marginal constraint introduced by the game-theoretic operational definition, both approaches are equivalent for two predictors (since maximizing co-information is equal to maximizing entropy given the constraints). However, once the distribution is obtained the other crucial difference is that
separates genuine redundant contributions at the local level, while
computes the full co-information, which conflates redundant and synergistic effects (
Table 3) [
6].
We apply our game-theoretic operational definition in the same way to provide the constraints in Equation (
31) for an arbitrary number of inputs. The action of each agent is determined by
(or equivalently
) and the agent interaction effects (from zero-sum or asymmetric utility functions) are determined by
.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}