Extracting Knowledge from the Geometric Shape of Social Network Data Using Topological Data Analysis


Abstract
:1. Introduction
- We investigated the feasibility of topological data analysis for social network analysis and mining since topological data analysis has not been previously investigated for social network analysis and mining to address the issues arising from the nature of social network data, and
- in order to employ topological data analysis to social network data, the problem of image popularity on social network is addressed. Our results show that topological data analysis outperforms traditional data mining techniques in terms of accuracy.
2. Theory
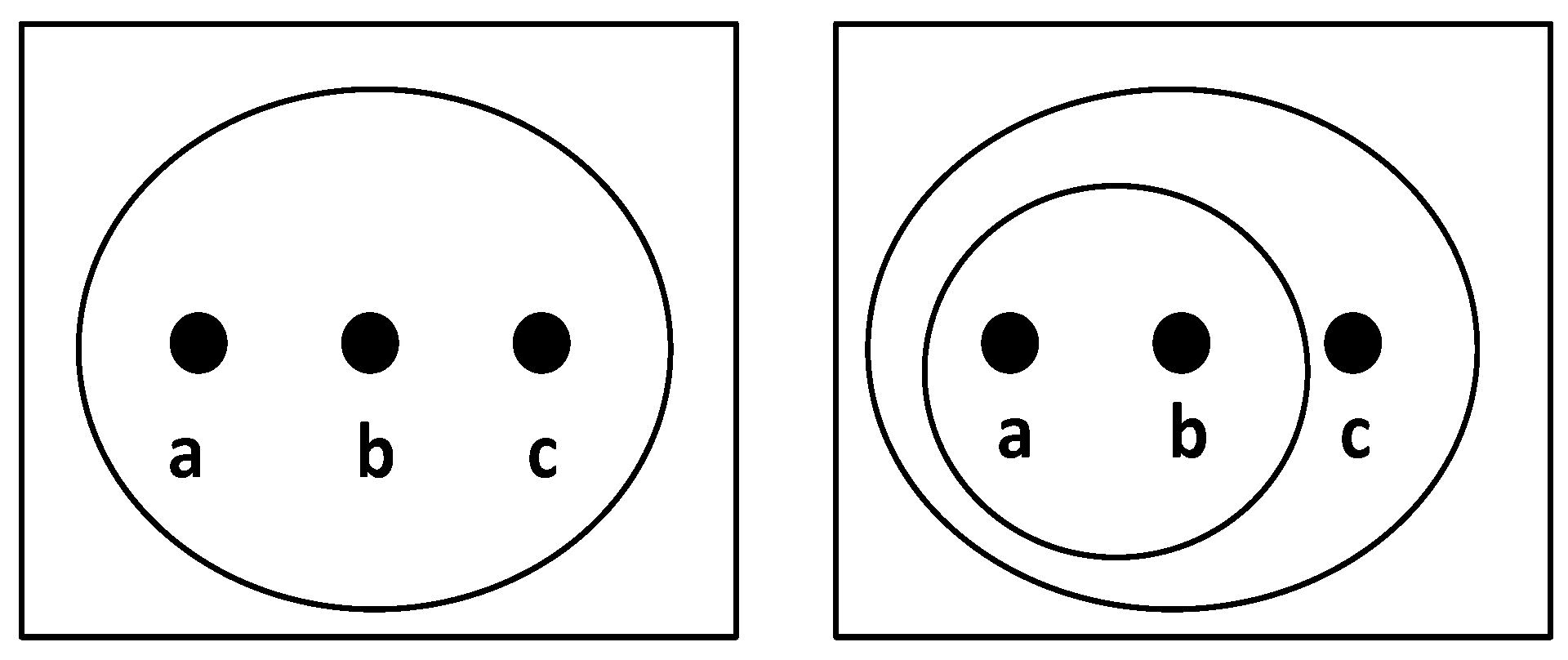
2.1. Topology
- Both ∅ and X are in ,
- the union of the elements of any subcollection of is in , and
- the intersection of the elements of any finite subcollection of is in .
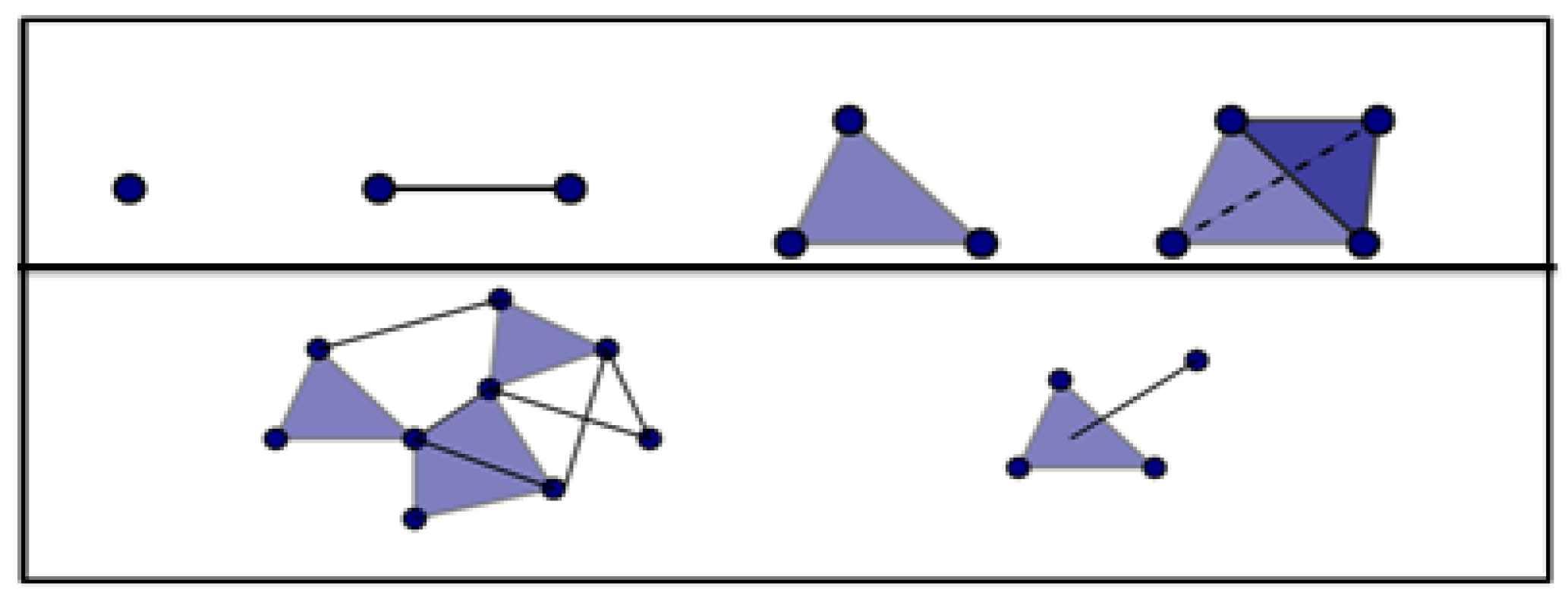
2.2. Topological Data Analysis
- The shapes are not dependent on specific coordinates,
- the shapes are not changed under any transformation without tearing the shape apart, and
- the shapes are produced in a compressed representation that contains infinite distances.
3. Social Network Analysis
3.1. Related Work for Image Popularity Prediction
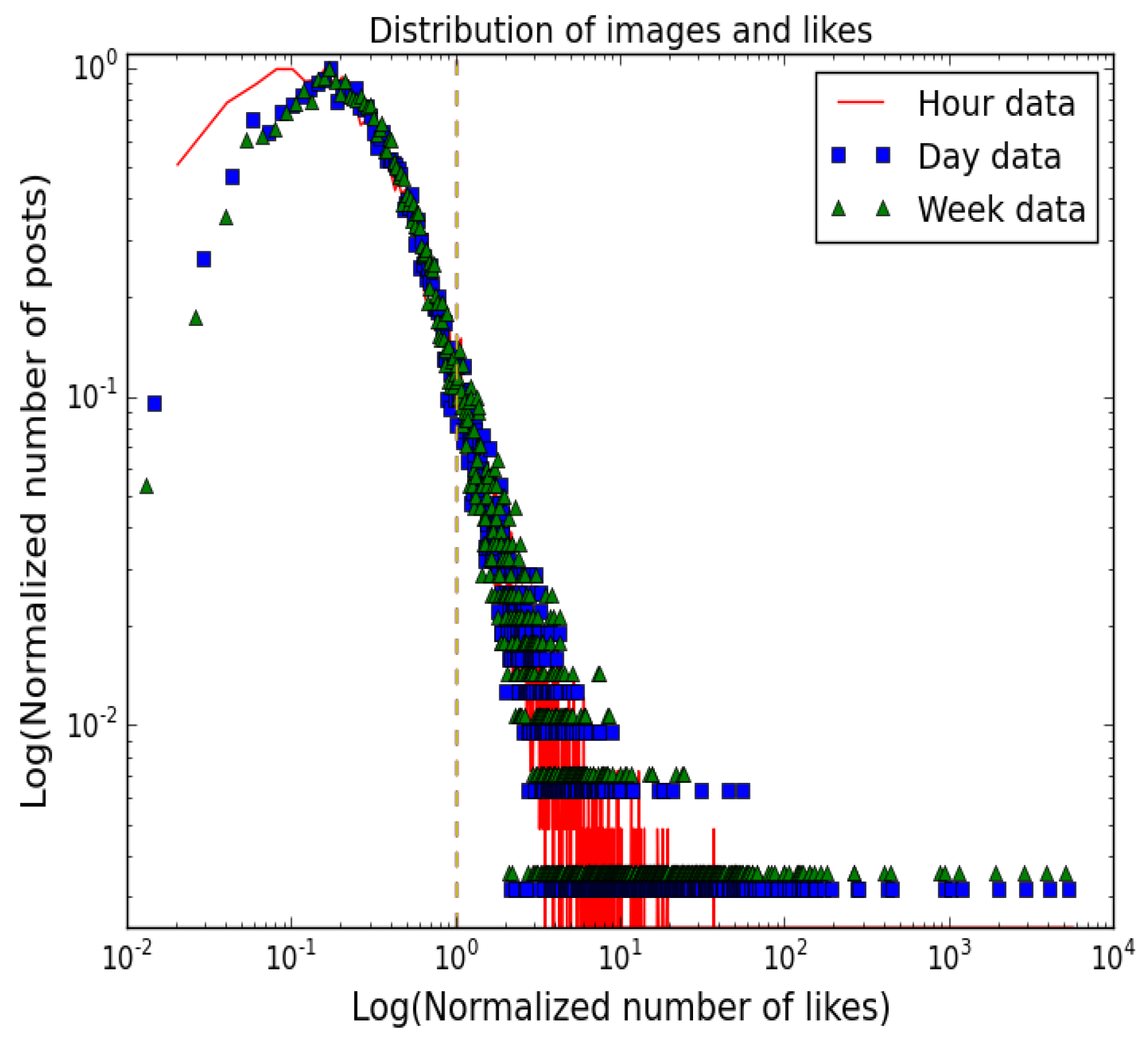
3.2. Popularity Threshold
3.3. Problems Statement
3.4. Features
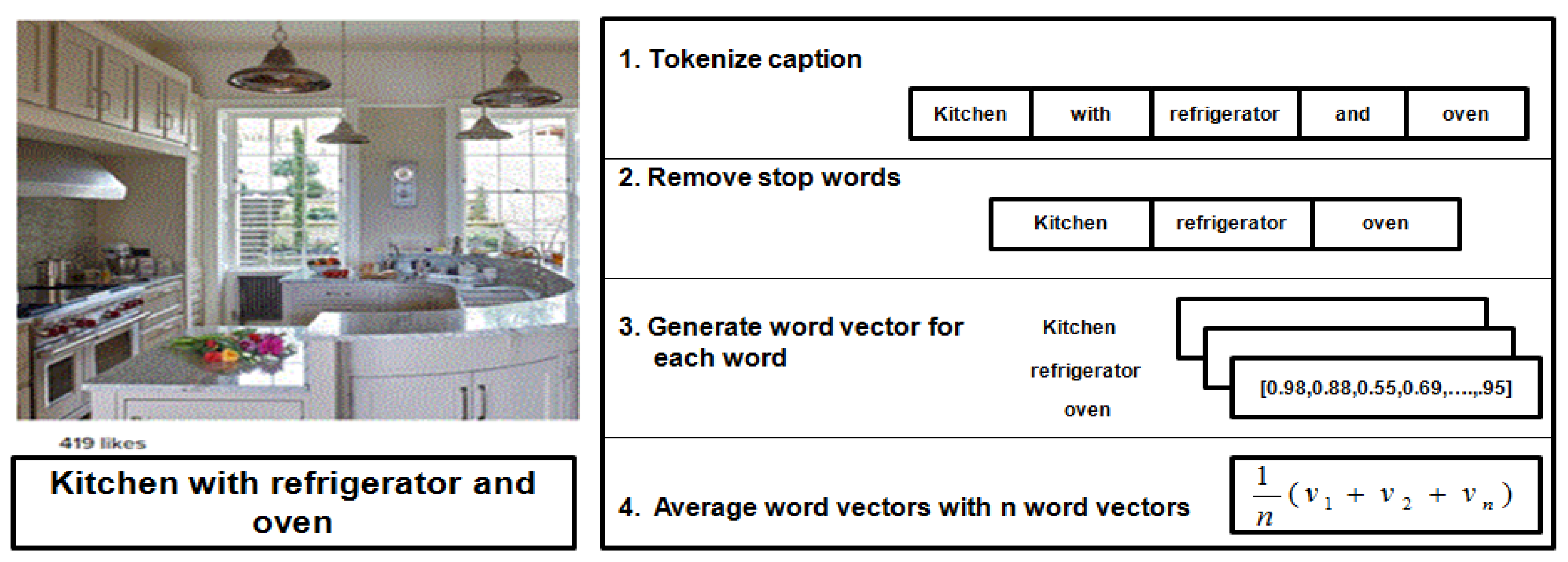
3.4.1. Image Content
3.4.2. Social Context
4. Approach
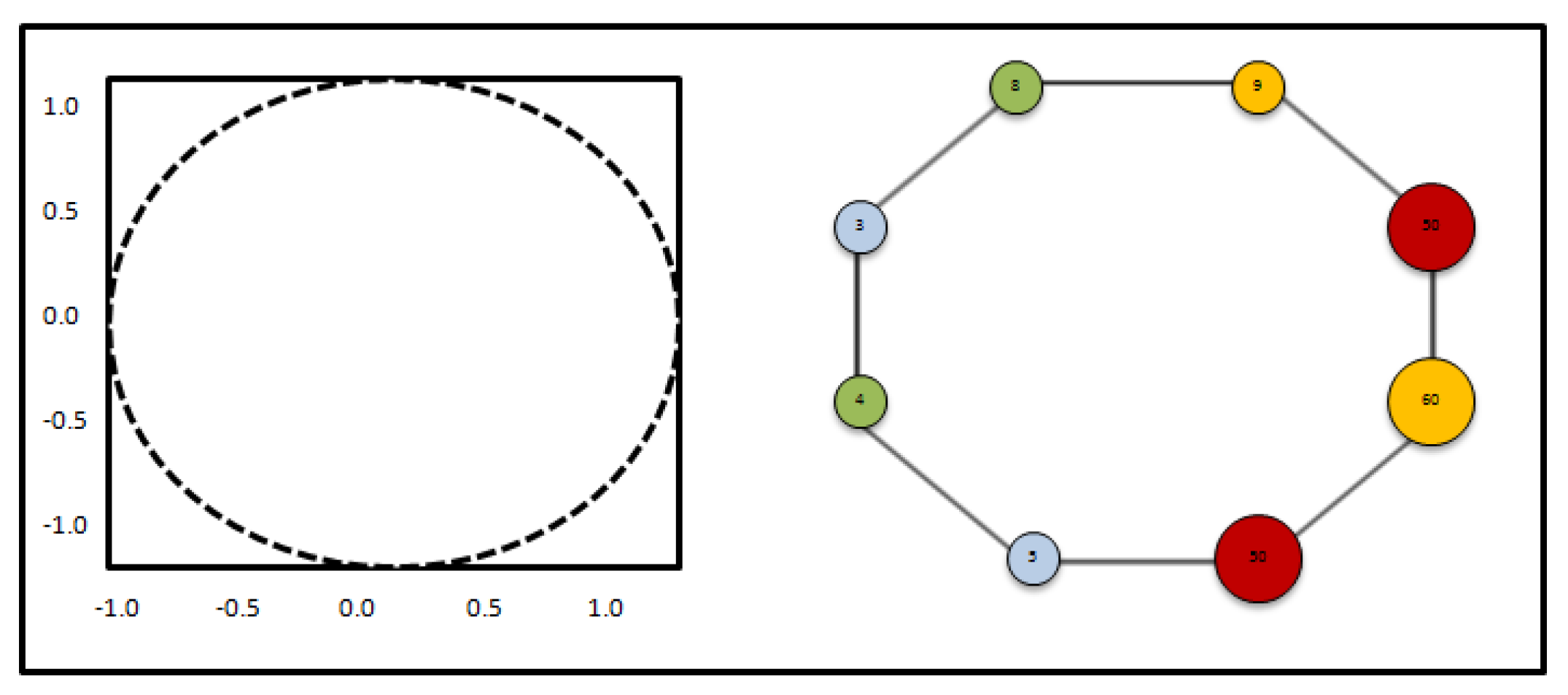
4.1. Clustering
4.2. Prediction
5. Experimental Setup
5.1. Instagram Dataset
5.2. Implementation
5.3. Evaluation
6. Empirical Results Using Topological Data Analysis
6.1. Clustering
6.2. Prediction
7. Empirical Results Using Clustering Algorithms
7.1. k-Means
7.1.1. Clustering
7.1.2. Prediction
7.2. Hierarchical Clustering
7.2.1. Clustering
7.2.2. Prediction
8. Comparison
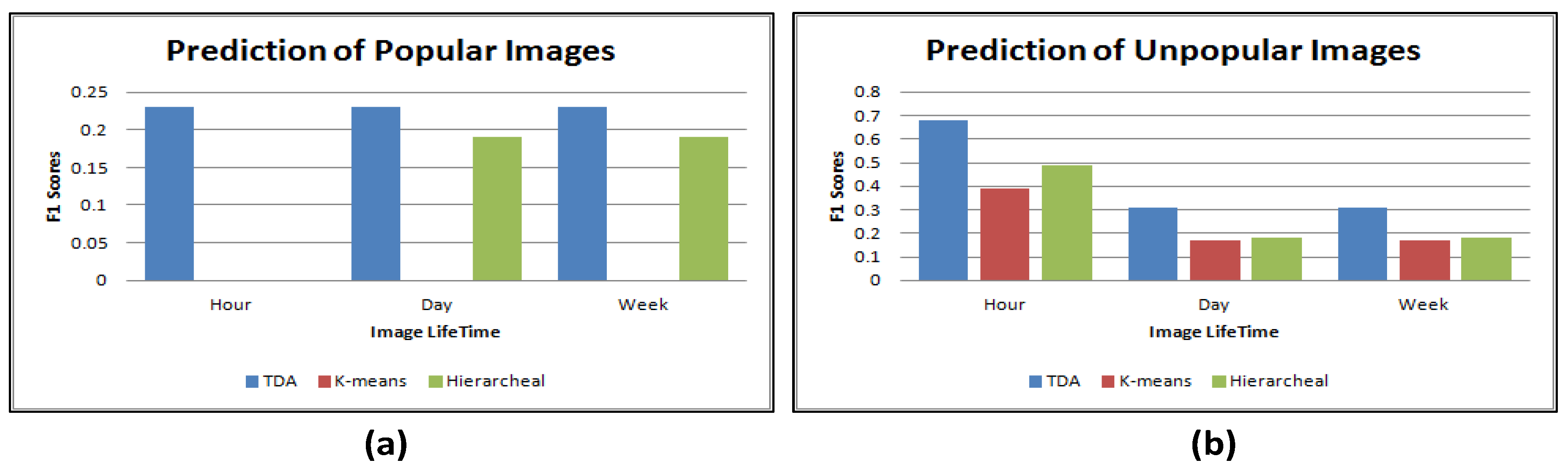
8.1. Image Content
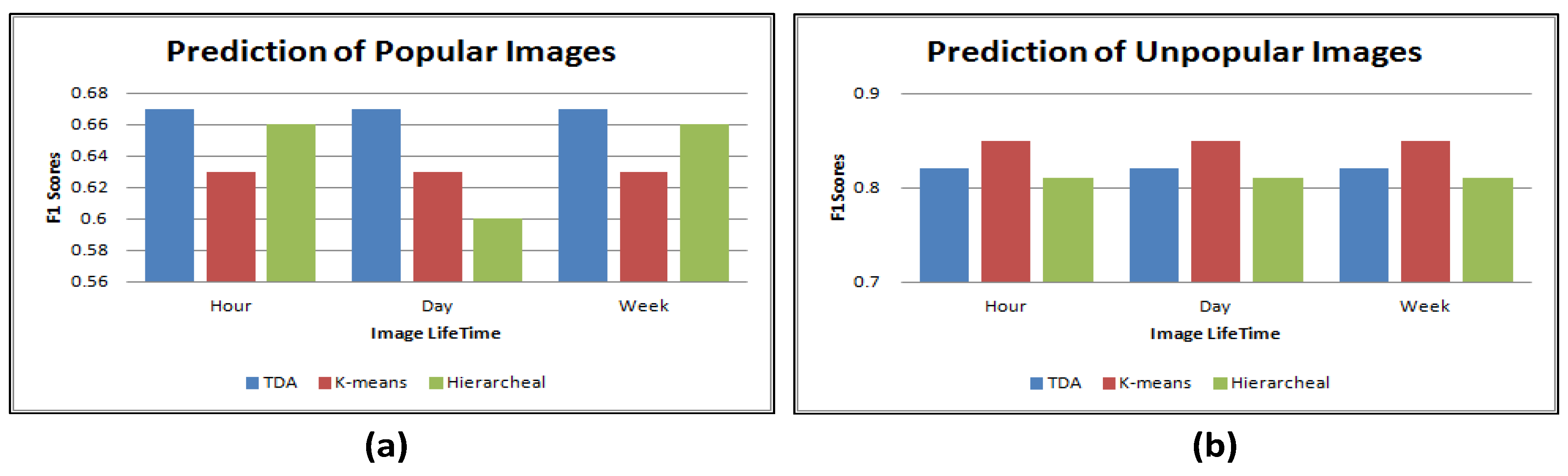
8.2. Social Context
9. Discussion
- Topological data analysis is feasible for social network analysis and mining;
- Image content and social context have correlations to image popularity;
- Topological data analysis significantly outperformed traditional clustering algorithms using the high dimensional feature, i.e., image content. It achieved higher accuracy rates than k-means and hierarchical clustering algorithms. It also generated a meaningful connectivity between the clusters, i.e., a monotonic increase in the popularity ratio along the connected clusters;
- For predicting the popularity of images using the low dimensional feature, i.e., social context, traditional data mining techniques perform as well as topological data analysis;
- The results show that using the context feature improves the accuracy rates significantly, which confirms that the popularity of images is highly related to users’ popularity;
- For the changes of popularity over time, a trend is only observed for the prediction of popular images using the image content;
- Lastly, the results show that popularity of images is saturated in a short period of time.
10. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Twitter. Twitter Usage. 2016. Available online: https://about.twitter.com/company (accessed on 13 April 2017).
- Facebook. Facebook Stats. 2016. Available online: https://newsroom.fb.com/company-info/ (accessed on 13 April 2017).
- Instagram. Instagram Stats. 2016. Available online: https://business.instagram.com (accessed on 13 April 2017).
- Wu, X.; Zhu, X.; Wu, G.Q.; Ding, W. Data mining with big data. IEEE Trans. Knowl. Data Eng. 2014, 26, 97–107. [Google Scholar]
- Fan, J.; Han, F.; Liu, H. Challenges of big data analysis. Natl. Sci. Rev. 2014, 1, 293–314. [Google Scholar] [CrossRef] [PubMed]
- Becker, H.; Naaman, M.; Gravano, L. Event Identification in Social Media. In Proceedings of the International Workshop on the Web and Databases, Snowbird, UT, USA, 22 June 2014. [Google Scholar]
- Edelsbrunner, H.; Letscher, D.; Zomorodian, A. Topological persistence and simplification. In Proceedings of the 41st Annual Symposium on Foundations of Computer Science, Washington, DC, USA, 12–14 November 2000; pp. 454–463. [Google Scholar]
- Carlsson, G. Topology and data. Bull. Am. Math. Soc. 2009, 46, 255–308. [Google Scholar] [CrossRef]
- Nicolau, M.; Tibshirani, R.; Børresen-Dale, A.L.; Jeffrey, S.S. Disease-specific genomic analysis: Identifying the signature of pathologic biology. Bioinformatics 2007, 23, 957–965. [Google Scholar] [CrossRef] [PubMed]
- Nicolau, M.; Levine, A.J.; Carlsson, G. Topology based data analysis identifies a subgroup of breast cancers with a unique mutational profile and excellent survival. Proc. Natl. Acad. Sci. USA 2011, 108, 7265–7270. [Google Scholar] [CrossRef] [PubMed]
- Choudhary, D.; Bansal, S. Topological Data Analysis. 2014. Available online: https://cse.iitk.ac.in/users/cs365/2014/submissions/deepakc/project/report.pdf (accessed on 14 July 2017).
- Singh, G.; Mémoli, F.; Carlsson, G.E. Topological methods for the analysis of high dimensional data sets and 3D object recognition. In Proceedings of the 2007 Symposium on Point-Based Graphics, Prague, Czech Republic, 2–3 September 2007; pp. 91–100. [Google Scholar]
- Gidea, M.; Katz, Y.A. Topological Data Analysis of Financial Time Series: Landscapes of Crashes. arXiv, 2017; arXiv:1703.04385. [Google Scholar] [CrossRef]
- Schebesch, K.B.; Stecking, R.W. Topological Data. In Operations Research Proceedings 2015; Springer: Cham, Switzerland, 2017; pp. 483–489. [Google Scholar]
- Webster, M. The Merriam-Webster Dictionary; Merriam-Webster: Springfield, MA, USA, 2005. [Google Scholar]
- Almgren, K.; Lee, J.; Kim, M. Predicting the Future Popularity of Images on Social Networks. In Proceedings of the 3rd Multidisciplinary International Social Networks Conference on SocialInformatics, Union, NJ, USA, 15–17 August 2016; p. 15. [Google Scholar]
- Almgren, K.; Lee, J.; Kim, M. Prediction of image popularity over time on social media networks. In Proceedings of the IEEE Annual Connecticut Conference on Industrial Electronics, Technology & Automation (CT-IETA), Bridgeport, CT, USA, 14–15 October 2016; pp. 1–6. [Google Scholar]
- McParlane, P.J.; Moshfeghi, Y.; Jose, J.M. Nobody comes here anymore, it’s too crowded; predicting image popularity on flickr. In Proceedings of the International Conference on Multimedia Retrieval, Glasgow, UK, 1–4 April 2014; p. 385. [Google Scholar]
- Can, E.F.; Oktay, H.; Manmatha, R. Predicting retweet count using visual cues. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 1481–1484. [Google Scholar]
- Guille, A.; Hacid, H.; Favre, C.; Zighed, D.A. Information diffusion in online social networks: A survey. ACM SIGMOD Rec. 2013, 42, 17–28. [Google Scholar] [CrossRef]
- Bakshy, E.; Rosenn, I.; Marlow, C.; Adamic, L. The role of social networks in information diffusion. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 519–528. [Google Scholar]
- Cappallo, S.; Mensink, T.; Snoek, C.G. Latent factors of visual popularity prediction. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 195–202. [Google Scholar]
- Khosla, A.; Das Sarma, A.; Hamid, R. What makes an image popular? In Proceedings of the 23rd International Conference on World Wide Web; pp. 867–876.
- Munkres, J.R. Topology; Prentice Hall: Upper Saddle River, NJ, USA, 2000. [Google Scholar]
- Cartan, H.; Eilenberg, S. Homological Algebra (PMS-19); Princeton University Press: Princeton, NJ, USA, 2016; Volume 19. [Google Scholar]
- Murphy, N. Topological Data Analysis. 2016. Available online: https://www.colby.edu/math/program/honorsprojects/2016-Murphy-HonorsThesis.pdf (accessed on 14 July 2017).
- Zomorodian, A.; Carlsson, G. Computing persistent homology. Discret. Comput. Geom. 2005, 33, 249–274. [Google Scholar] [CrossRef]
- Cohen-Steiner, D.; Edelsbrunner, H.; Harer, J. Stability of persistence diagrams. Discret. Comput. Geom. 2007, 37, 103–120. [Google Scholar] [CrossRef]
- Michel, B. Statistics and Topological Data Analysis. Available online: https://www.turing-gateway.cam.ac.uk/sites/default/files/asset/doc/1606/BertrandMichel.pdf (accessed on 14 July 2017).
- Müllner, D.; Babu, A. Python Mapper: An Open-Source Toolchain for Data Exploration, Analysis and Visualization. 2013. Available online: http://danifold.net/mapper (accessed on 14 July 2017).
- Erlandsson, F.; Bródka, P.; Borg, A.; Johnson, H. Finding influential users in social media using association rule learning. Entropy 2016, 18, 164. [Google Scholar] [CrossRef]
- Almgren, K.; Lee, J. An empirical comparison of influence measurements for social network analysis. Soc. Netw. Anal. Min. 2016, 6, 52. [Google Scholar] [CrossRef]
- Chen, W.; Gao, Q.; Xiong, H. Temporal Predictability of Online Behavior in Foursquare. Entropy 2016, 18, 296. [Google Scholar] [CrossRef]
- Li, Y.; Wu, C.; Luo, P.; Zhang, W. Exploring the characteristics of innovation adoption in social networks: Structure, homophily, and strategy. Entropy 2013, 15, 2662–2678. [Google Scholar] [CrossRef]
- Rodríguez Barraquer, T. From Observable Behaviors to Structures of Interaction in Binary Games of Strategic Complements. Entropy 2013, 15, 4648–4667. [Google Scholar] [CrossRef]
- Silva, T.H.; de Melo, P.O.V.; Almeida, J.M.; Salles, J.; Loureiro, A.A. A picture of Instagram is worth more than a thousand words: Workload characterization and application. In Proceedings of the 2013 IEEE International Conference on Distributed Computing in Sensor Systems (DCOSS), Cambridge, MA, USA, 20–23 May 2013; pp. 123–132. [Google Scholar]
- Mejova, Y.; Haddadi, H.; Noulas, A.; Weber, I. #Foodporn: Obesity patterns in culinary interactions. In Proceedings of the 5th International Conference on Digital Health, Florence, Italy, 18–20 May 2015; pp. 51–58. [Google Scholar]
- Saganowski, S.; Gliwa, B.; Bródka, P.; Zygmunt, A.; Kazienko, P.; Koźlak, J. Predicting community evolution in social networks. Entropy 2015, 17, 3053–3096. [Google Scholar] [CrossRef]
- Xu, H.; Hu, Y.; Wang, Z.; Ma, J.; Xiao, W. Core-based dynamic community detection in mobile social networks. Entropy 2013, 15, 5419–5438. [Google Scholar] [CrossRef]
- Aloufi, S.; Zhu, S.; El Saddik, A. On the Prediction of Flickr Image Popularity by Analyzing Heterogeneous Social Sensory Data. Sensors 2017, 17, 631. [Google Scholar] [CrossRef] [PubMed]
- Yamaguchi, K.; Berg, T.L.; Ortiz, L.E. Chic or social: Visual popularity analysis in online fashion networks. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 773–776. [Google Scholar]
- Totti, L.C.; Costa, F.A.; Avila, S.; Valle, E.; Meira, W., Jr.; Almeida, V. The impact of visual attributes on online image diffusion. In Proceedings of the 2014 ACM Conference on Web Science, Bloomington, IN, USA, 23–26 June 2014; pp. 42–51. [Google Scholar]
- Niu, X.; Li, L.; Mei, T.; Shen, J.; Xu, K. Predicting image popularity in an incomplete social media community by a weighted bi-partite graph. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo (ICME), Melbourne, VIC, Australia, 9–13 July 2012; pp. 735–740. [Google Scholar]
- Gelli, F.; Uricchio, T.; Bertini, M.; Del Bimbo, A.; Chang, S.F. Image popularity prediction in social media using sentiment and context features. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, QLD, Australia, 26–30 October 2015; pp. 907–910. [Google Scholar]
- Oglesbee, L. Writing Captions. Commun. J. Educ. Today 1998, 32, 2–6. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Bonchev, D.; Trinajstić, N. Information theory, distance matrix, and molecular branching. J. Chem. Phys. 1977, 67, 4517–4533. [Google Scholar] [CrossRef]
- Larsen, B.; Aone, C. Fast and effective text mining using linear-time document clustering. In Proceedings of the Fifth ACM SIGKDD International Conference On Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 16–22. [Google Scholar]
- Deza, M.M.; Deza, E. Encyclopedia of distances. In Encyclopedia of Distances; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–583. [Google Scholar]
- Rehurek, R.; Sojka, P. Gensim–Python Framework for Vector Space Modelling; Masaryk University: Brno, Czech Republic, 2011. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL on Interactive Presentation Sessions, Sydney, NSW, Australia, 17–18 July 2006; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006; pp. 69–72. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, Louisiana, 7–9 January 2007; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007; pp. 1027–1035. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Johnson, S.C. Hierarchical clustering schemes. Psychometrika 1967, 32, 241–254. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Popularity Thresholds | 1 Hour | 1 Day | 1 Week |
|---|---|---|---|
| Number of Likes | 45 | 69 | 75 |
| Periods | Accuracy Rates | |||
|---|---|---|---|---|
| Image Content | Social Context | |||
| Popular Images | Unpopular Images | Popular Images | Unpopular Images | |
| Hour | 0.23 | 0.68 | 0.67 | 0.82 |
| Day | 0.23 | 0.31 | 0.67 | 0.82 |
| Week | 0.23 | 0.23 | 0.67 | 0.82 |
| Periods | Accuracy Rates | |||
|---|---|---|---|---|
| Image Content | Social Context | |||
| Popular Images | Unpopular Images | Popular Images | Unpopular Images | |
| Hour | 0 | 0.39 | 0.85 | 0.63 |
| Day | 0 | 0.17 | 0.85 | 0.63 |
| Week | 0 | 0.17 | 0.85 | 0.63 |
| Periods | Accuracy Rates | |||
|---|---|---|---|---|
| Image Content | Social Context | |||
| Popular Images | Unpopular Images | Popular Images | Unpopular Images | |
| Hour | 0 | 0.49 | 0.66 | 0.81 |
| Day | 0.19 | 0.18 | 0.66 | 0.81 |
| Week | 0.19 | 0.18 | 0.66 | 0.81 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almgren, K.; Kim, M.; Lee, J. Extracting Knowledge from the Geometric Shape of Social Network Data Using Topological Data Analysis. Entropy 2017, 19, 360. https://doi.org/10.3390/e19070360
Almgren K, Kim M, Lee J. Extracting Knowledge from the Geometric Shape of Social Network Data Using Topological Data Analysis. Entropy. 2017; 19(7):360. https://doi.org/10.3390/e19070360
Chicago/Turabian StyleAlmgren, Khaled, Minkyu Kim, and Jeongkyu Lee. 2017. "Extracting Knowledge from the Geometric Shape of Social Network Data Using Topological Data Analysis" Entropy 19, no. 7: 360. https://doi.org/10.3390/e19070360
APA StyleAlmgren, K., Kim, M., & Lee, J. (2017). Extracting Knowledge from the Geometric Shape of Social Network Data Using Topological Data Analysis. Entropy, 19(7), 360. https://doi.org/10.3390/e19070360