A View of Information-Estimation Relations in Gaussian Networks



.png)
Abstract
:1. Introduction
- Capacity questions, including both converse proofs and bounds given additional constraints such as discrete inputs;
- The MMSE SNR-evolution, meaning the behavior of the MMSE as a function of SNR for asymptotically optimal code sequences (code sequences that approach capacity as ); and
- Finite blocklength effects on the SNR-evolution of the MMSE and hence effects on the rate as well.
- In Section 2 we review information and estimation theoretic tools that are necessary for the presentation of the main results.
- In Section 3 we go over point-to-point information theory and give the following results:
- In Section 3.1, using the I-MMSE and a basic MMSE bound, a simple converse is shown for the Gaussian point-to-point channel;
- In Section 3.2, a lower bound, termed the Ozarow-Wyner bound, on the mutual information achieved by a discrete input on an AWGN channel, is presented. The bound holds for vector discrete inputs and yields the sharpest known version of this bound; and
- In Section 3.3, it is shown that the MMSE can be used to identify optimal point-to-point codes. In particular, it is shown that an optimal point-to-point code has a unique SNR-evolution of the MMSE.
- In Section 4 we focus on the wiretap channel and give the following results:
- In Section 4.1, using estimation theoretic properties a simple converse is shown for the Gaussian wiretap channel that avoids the use of the entropy power inequality (EPI); and
- In Section 4.2, some results on the SNR-evolution of the code sequences for the Gaussian wiretap channel are provided, showing that for the secrecy capacity achieving sequences of codes the SNR-evolution is unique.
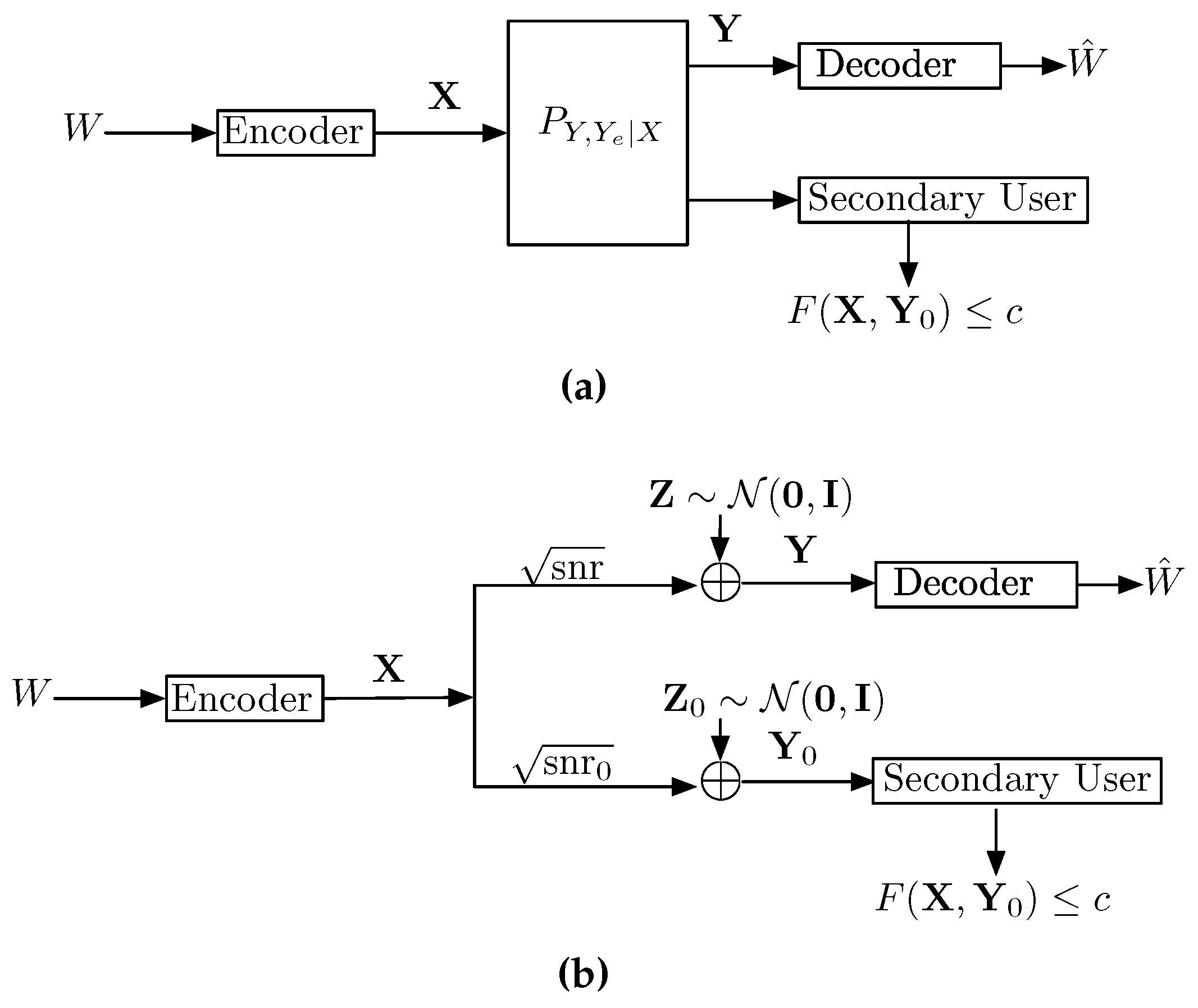
- In Section 5 we study a communication problem in which the transmitter wishes to maximize its communication rate, while subjected to a constraint on the disturbance it inflicts on the secondary receiver. We refer to such scenarios as communication with a disturbance constraint and give the following results:
- In Section 5.1 it is argued that an instance of a disturbance constraint problem, when the disturbance is measured by the MMSE, has an important connection to the capacity of a two-user Gaussian interference channel;
- In Section 5.2 the capacity is characterized for the disturbance problem when the disturbance is measured by the MMSE;
- In Section 5.3 the capacity is characterized for the disturbance problem when the disturbance is measured by the mutual information. The MMSE and the mutual information disturbance results are compared. It is argued that the MMSE disturbance constraint is a more natural measure in the case when the disturbance measure is chosen to model the unintended interference;
- In Section 5.4 new bounds on the MMSE are derived and are used to show upper bounds on the disturbance constraint problem with the MMSE constraint when the block length is finite; and
- In Section 5.5 a notion of mixed inputs is defined and is used to show lower bounds on the rates of the disturbance constraint problem when the block length is finite.
- In Section 6 we focus on the broadcast channel and give the following results:
- In Section 6.1, the converse for a scalar Gaussian broadcast channel, which is based only on the estimation theoretic bounds and avoids the use of the EPI, is derived; and
- In Section 6.2, similarly to the Gaussian wiretap channel, we examine the SNR-evolution of asymptotically optimal code sequences for the Gaussian broadcast channel, and show that any such sequence has a unique SNR-evolution of the MMSE.
- In Section 7 the SNR-evolution of the MMSE is derived for the K-user broadcast channel.
- In Section 8, building on the MMSE disturbance problem in Section 5.1, it is shown that for the two-user Gaussian interference channel a simple transmission strategy of treating interference as noise is approximately optimal.
1.1. Notation
- Random variables and vectors are denoted by upper case and bold upper case letters, respectively, where r.v. is short for either random variable or random vector, which should be clear from the context. The dimension of these random vectors is n throughout the survey. Matrices are denoted by bold upper case letters;
- If A is an r.v. we denote the support of its distribution by ;
- The symbol may denote different things: is the determinant of the matrix , is the cardinality of the set , is the cardinality of , or is the absolute value of the real-valued x;
- The symbol denotes the Euclidian norm;
- denotes the expectation;
- denotes the density of a real-valued Gaussian r.v. with mean vector and covariance matrix ;
- denotes the uniform probability mass function over a zero-mean pulse amplitude modulation (PAM) constellation with points, minimum distance , and therefore average energy ;
- The identity matrix is denoted by ;
- The reflection of the matrix along its main diagonal, or the transpose operation, is denoted by ;
- The trace operation on the matrix is denoted by ;
- The order notation implies that is a positive semidefinite matrix;
- denotes the logarithm to the base ;
- is the set of integers from to ;
- For we let denote the largest integer not greater than x;
- For we let and ;
- Let be two real-valued functions. We use the Landau notation to mean that for some there exists an such that for all , and to mean that for every there exists an such that for all ; and
- We denote the upper incomplete gamma function and the gamma function by
2. Estimation and Information Theoretic Tools
2.1. Estimation Theoretic Measures
2.2. Mutual Information and the I-MMSE
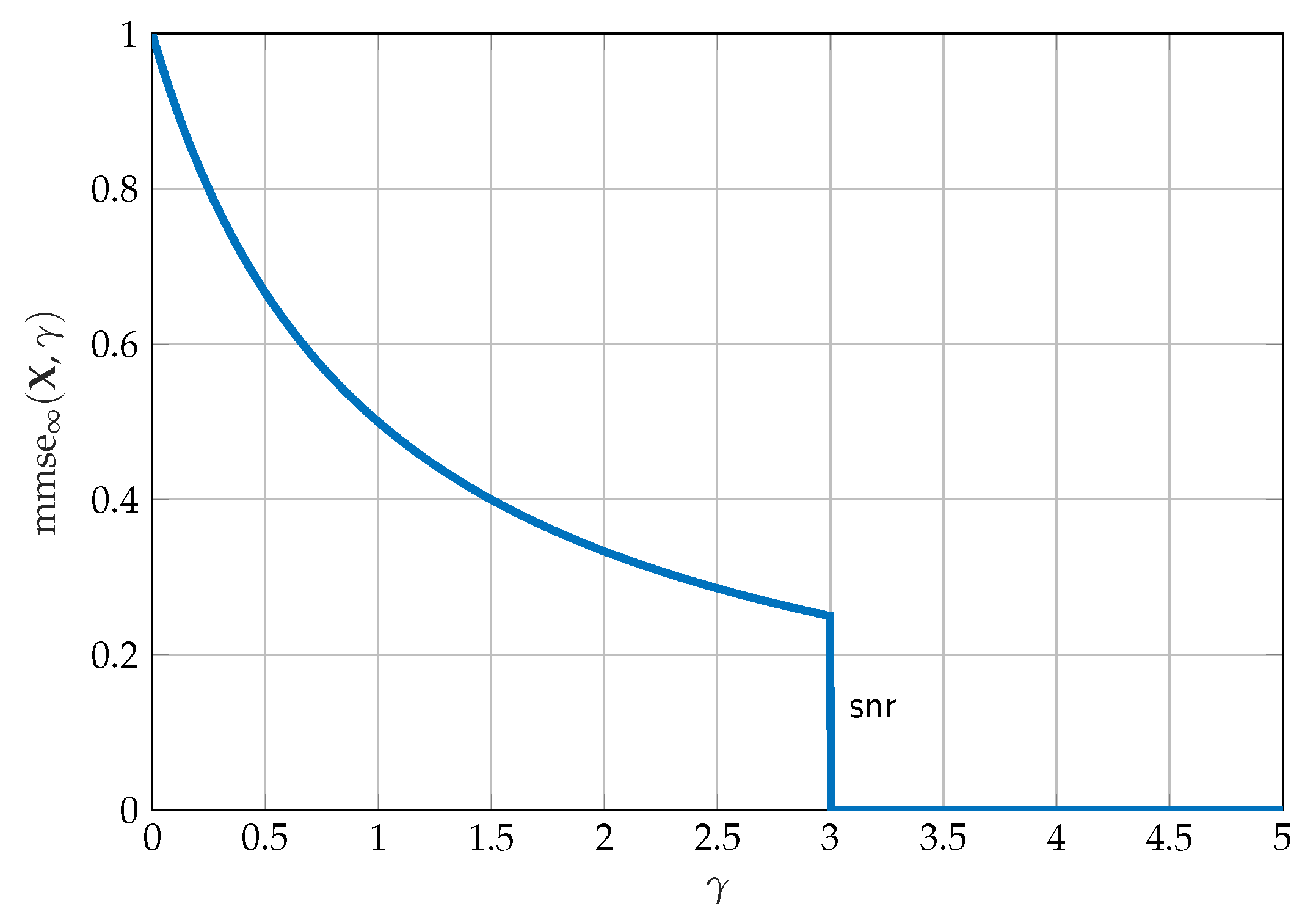
2.3. Single Crossing Point Property
2.4. Complementary SCPP Bounds
2.5. Bounds on Differential Entropy
- The MMPE can be used to bound the conditional entropy (see Theorem 2 in Section 2.5). These bounds are generally tighter than the MMSE based bound especially for highly non-Gaussian statistics;
- The MMPE can be used to develop bounds on the mutual information of discrete inputs via the generalized Ozarow-Wyner bound (see Theorem 4 in Section 3.2); The MMPE and the Ozarow-Wyner bound can be used to give tighter bounds on the gap to capacity achieved by PAM input constellations (see Figure 2);
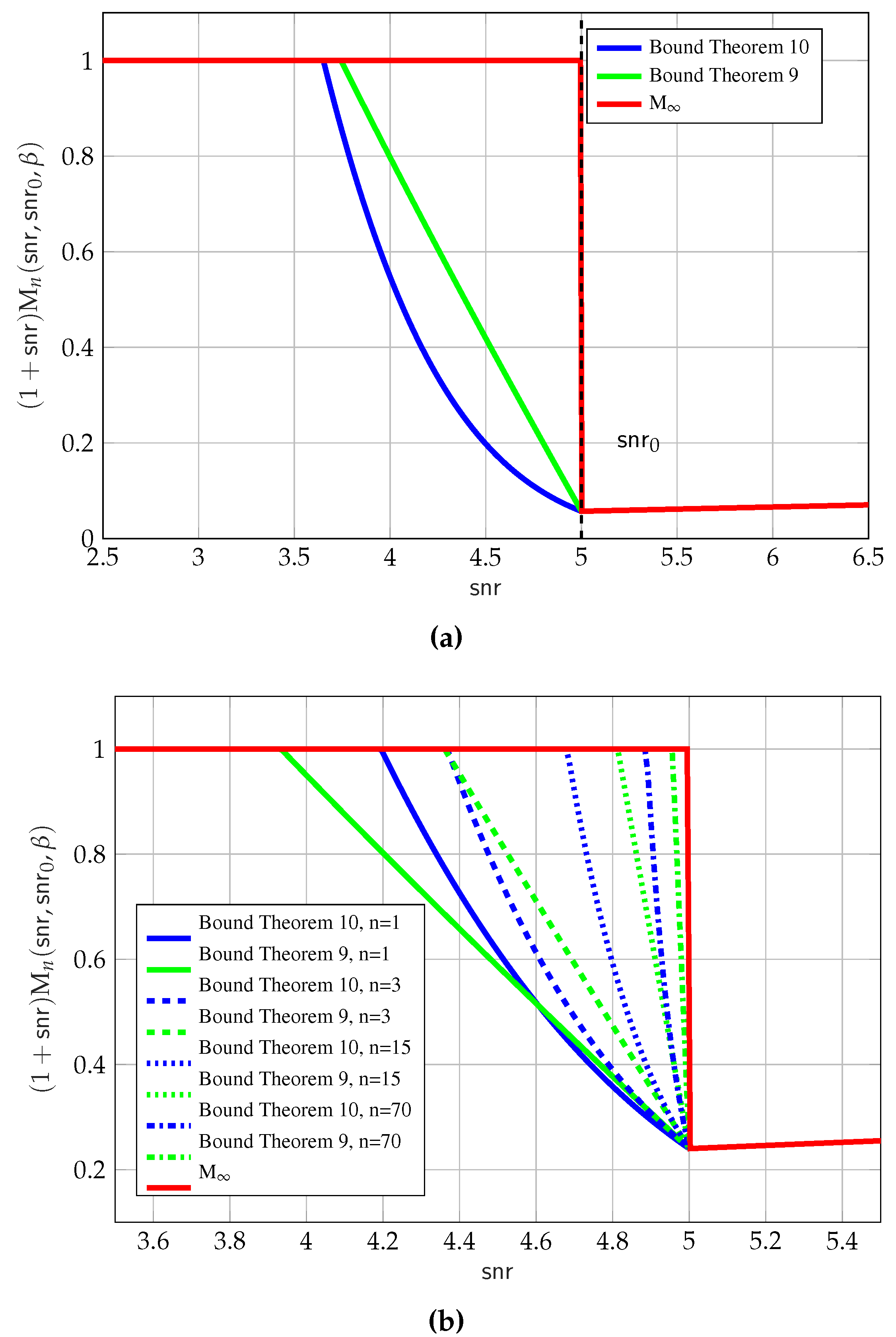
- The MMPE can be used as a key tool in finding complementary bounds on the SCPP (see Theorem 10 in Section 5.4). Note that using the MMPE as a tool produces the correct phase transition behavior; and
- While not mentioned, another application is to use the MMPE to bound the derivatives of the MMSE; see [25] for further details.
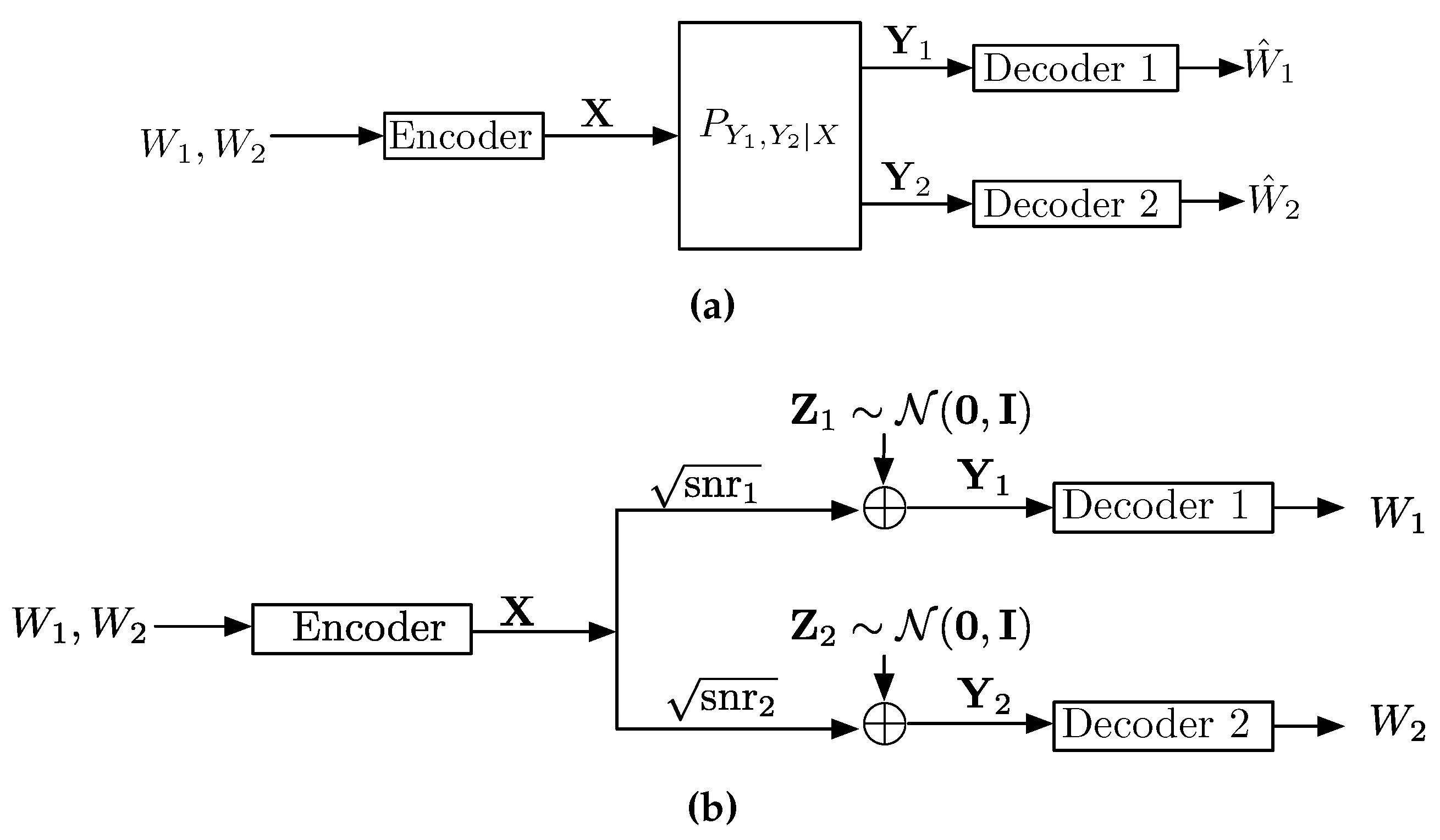
3. Point-to-Point Channels
- A message set. We assume that the message W is chosen uniformly over the message set.
- An encoding function that maps messages W to codewords . The set of all codewords is called the codebook and is denoted by ; and
- A decoding function that assigns an estimate to each received sequence.
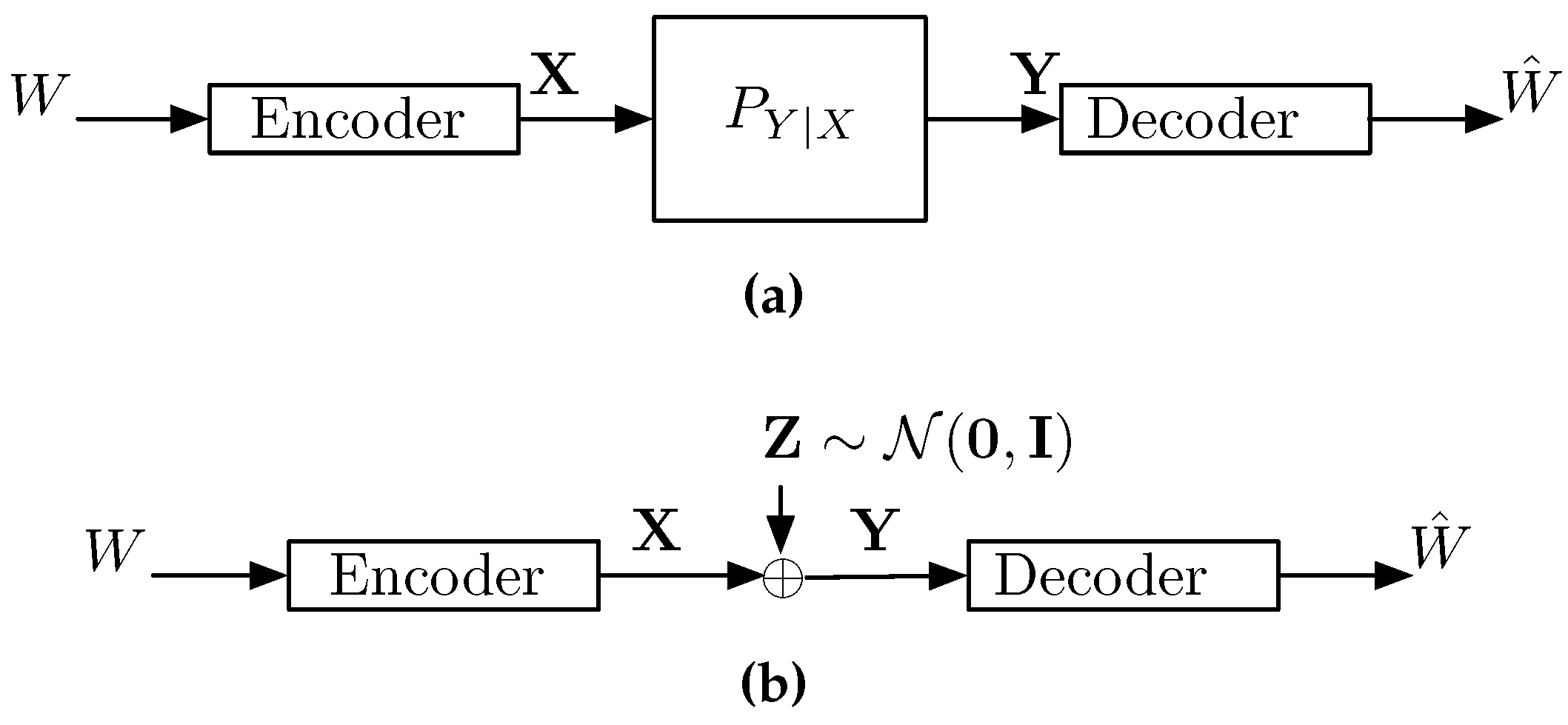
3.1. A Gaussian Point-to-Point Channel
3.2. Generalized Ozarow-Wyner Bound
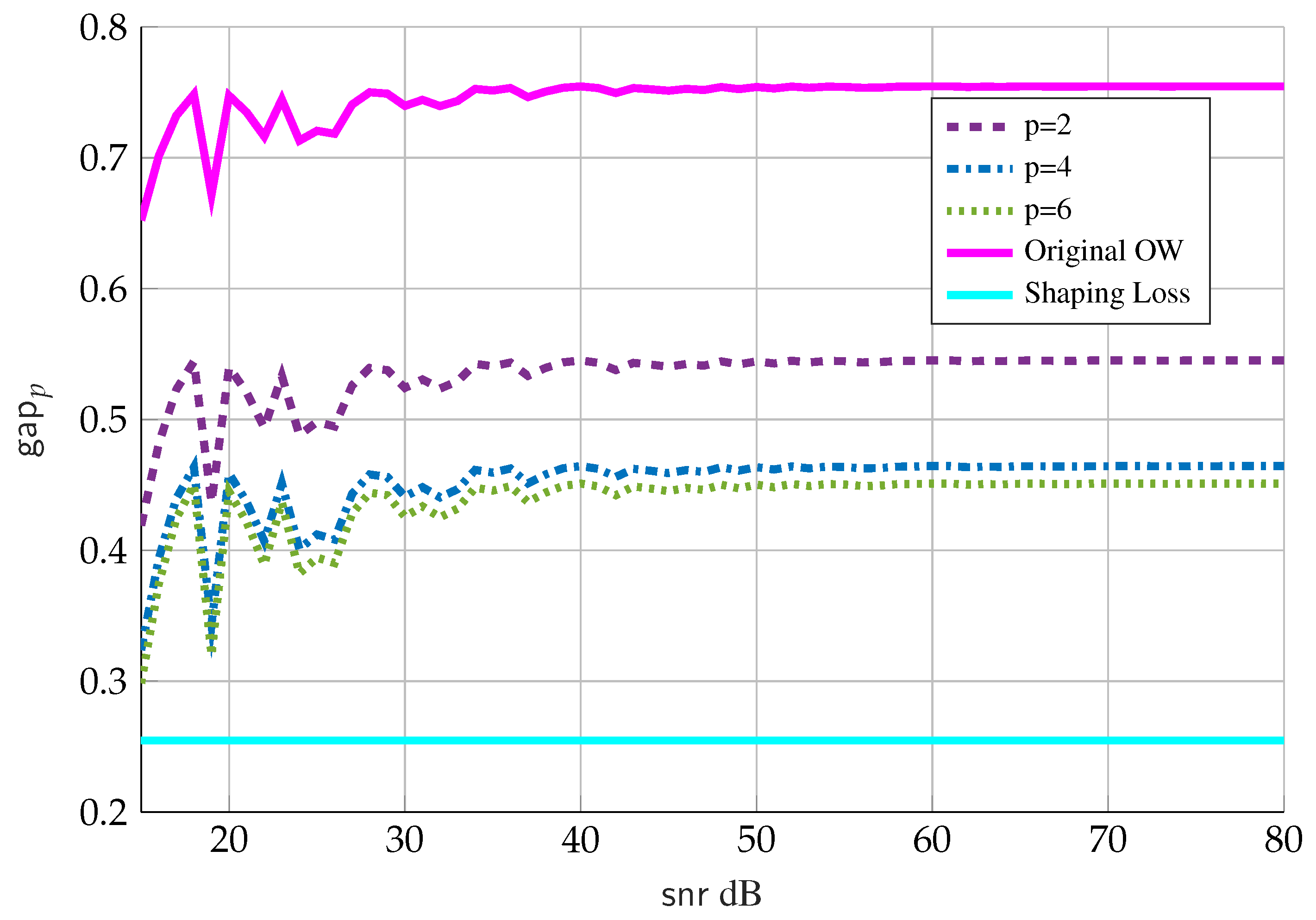
- The solid cyan line is the “shaping loss” for a one-dimensional infinite lattice and is the limiting gap if the number of points N grows faster than ;
- The solid magenta line is the gap in the original Ozarow-Wyner bound in (33); and
- The dashed purple, dashed-dotted blue and dotted green lines are the new gap given by Theorem 4 for values of , respectively, and where we choose .
3.3. SNR Evolution of Optimal Codes
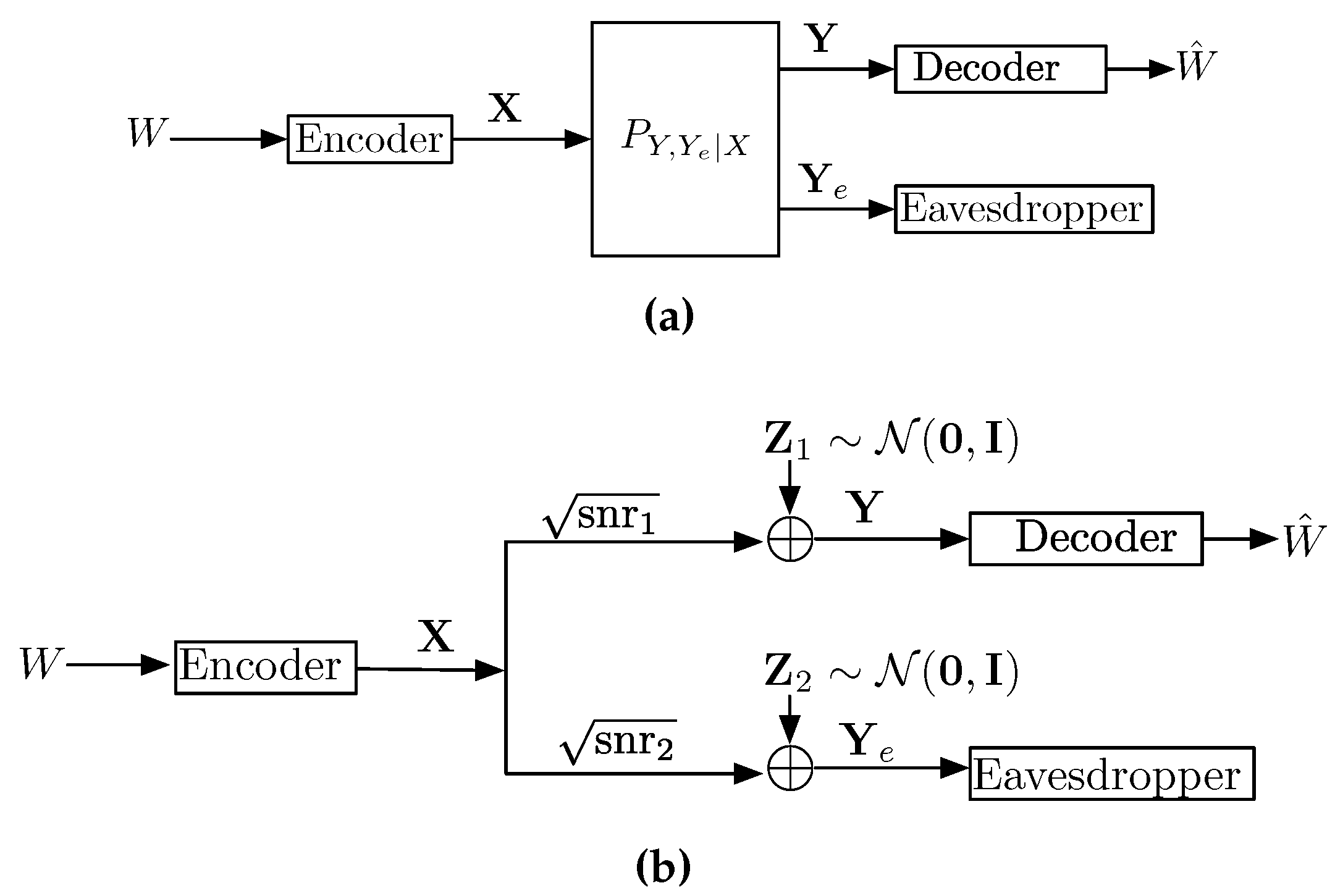
4. Applications to the Wiretap Channel
4.1. Converse of the Gaussian Wiretap Channel
4.2. SNR Evolution of Optimal Wiretap Codes
5. Communication with a Disturbance Constraint
5.1. Max-I Problem
- Partial interference cancellation: by using the Han-Kobayashi (HK) achievable scheme [74], part of the interfering message is jointly decoded with part of the desired signal. Then the decoded part of the interference is subtracted from the received signal, and the remaining part of the desired signal is decoded while the remaining part of the interference is treated as Gaussian noise. With Gaussian codebooks, this approach has been shown to be capacity achieving in the strong interference regime [75] and optimal within 1/2 bit per channel per user otherwise [76].
- Soft-decoding/estimation: the unintended receiver employs soft-decoding of part of the interference. This is enabled by using non-Gaussian inputs and designing the decoders that treat interference as noise by taking into account the correct (non-Gaussian) distribution of the interference. Such scenarios were considered in [44,46,49], and shown to be optimal to within either a constant or a gap for all regimes in [45].
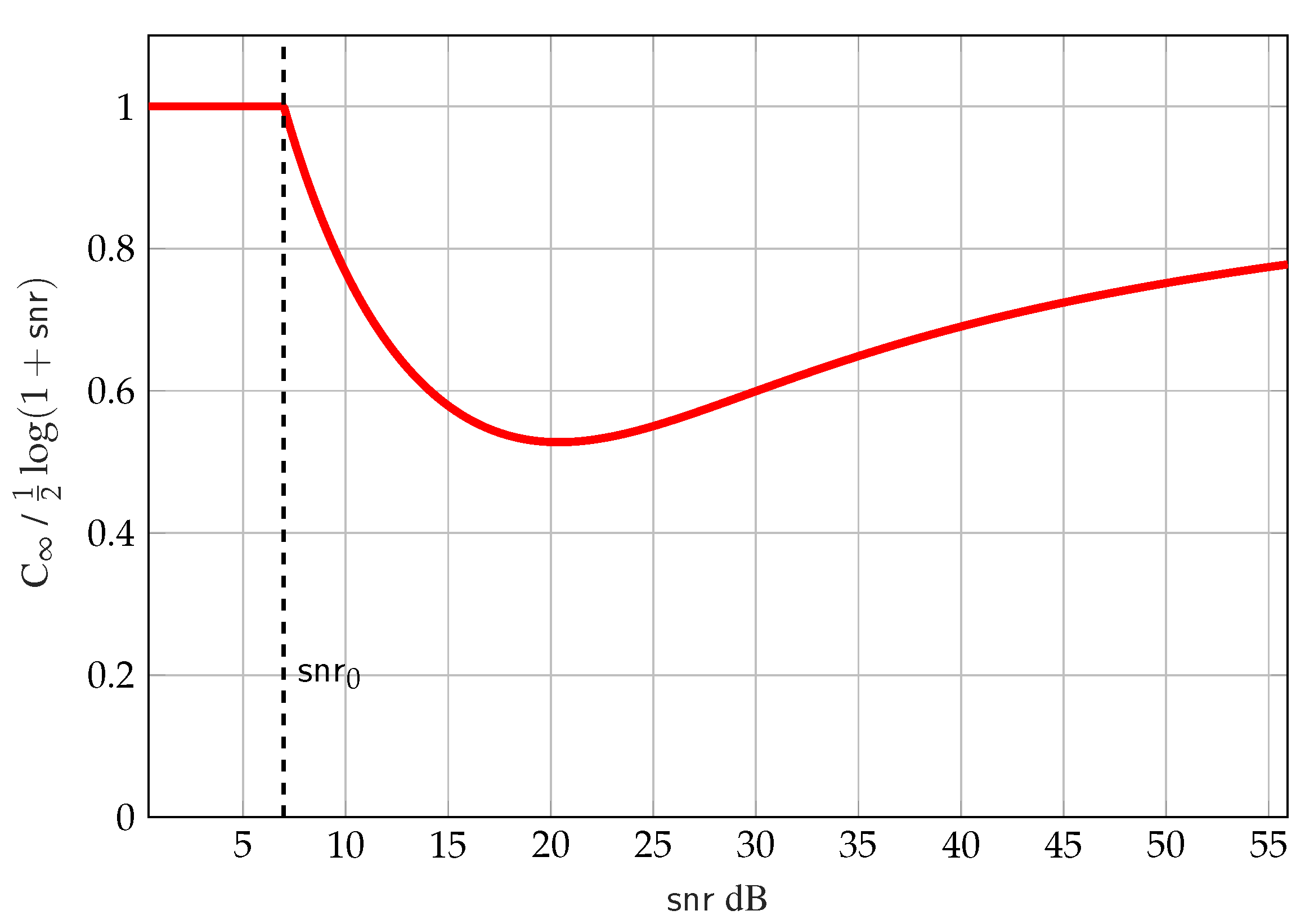
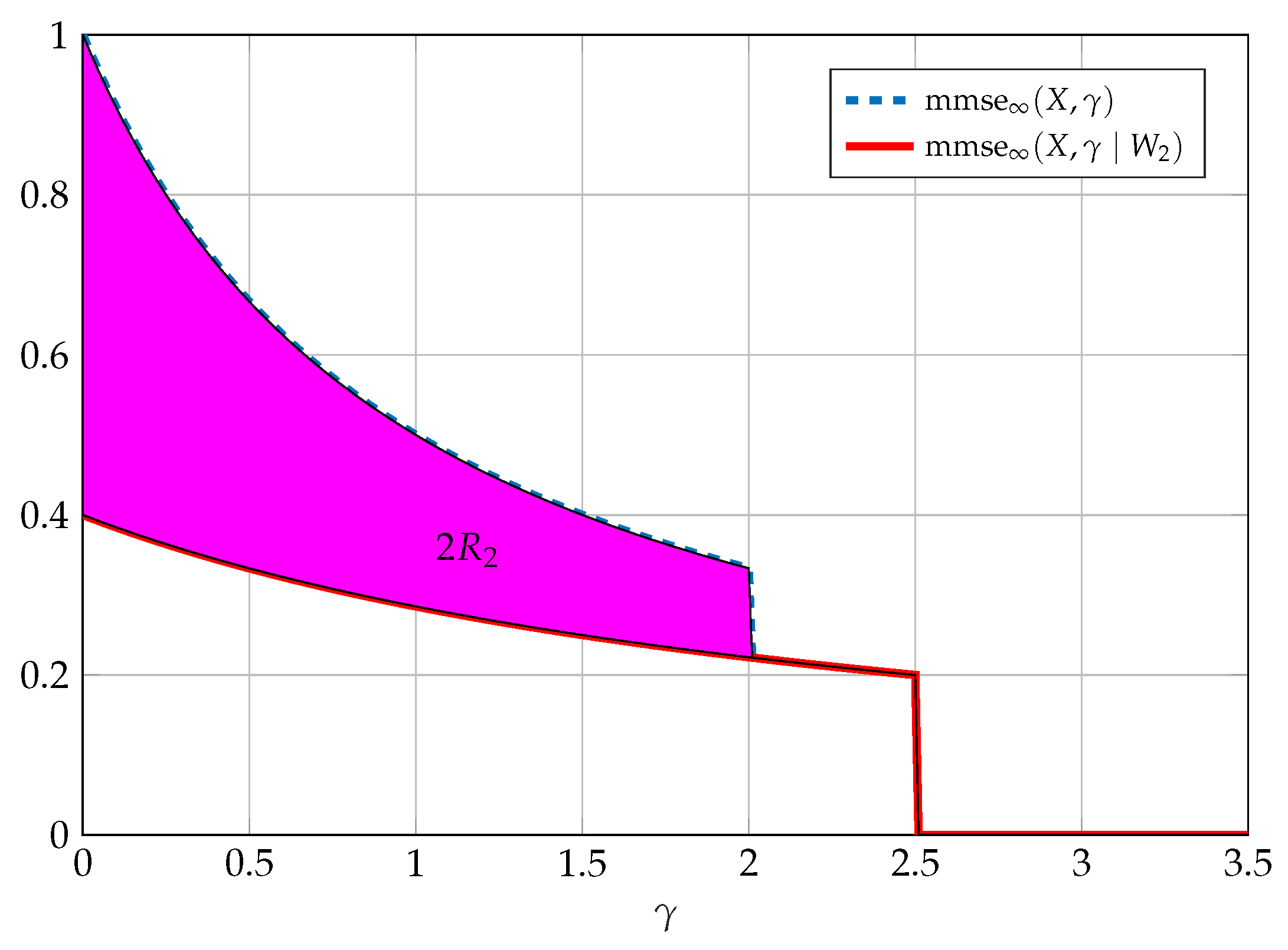
5.2. Characterization of as
5.3. Proof of the Disturbance Constraint Problem with a Mutual Information Constraint
5.4. Max-MMSE Problem
5.5. Mixed Inputs
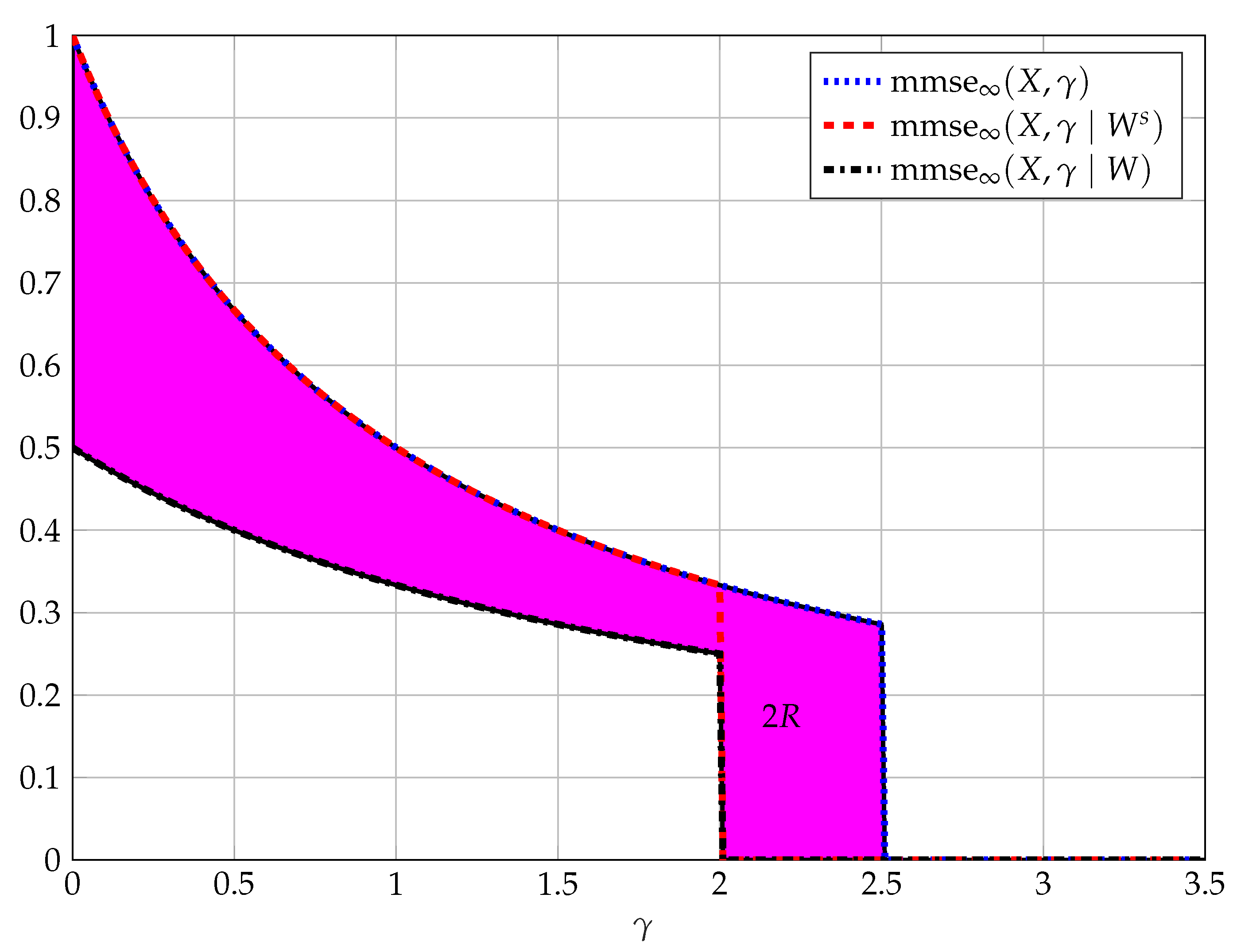
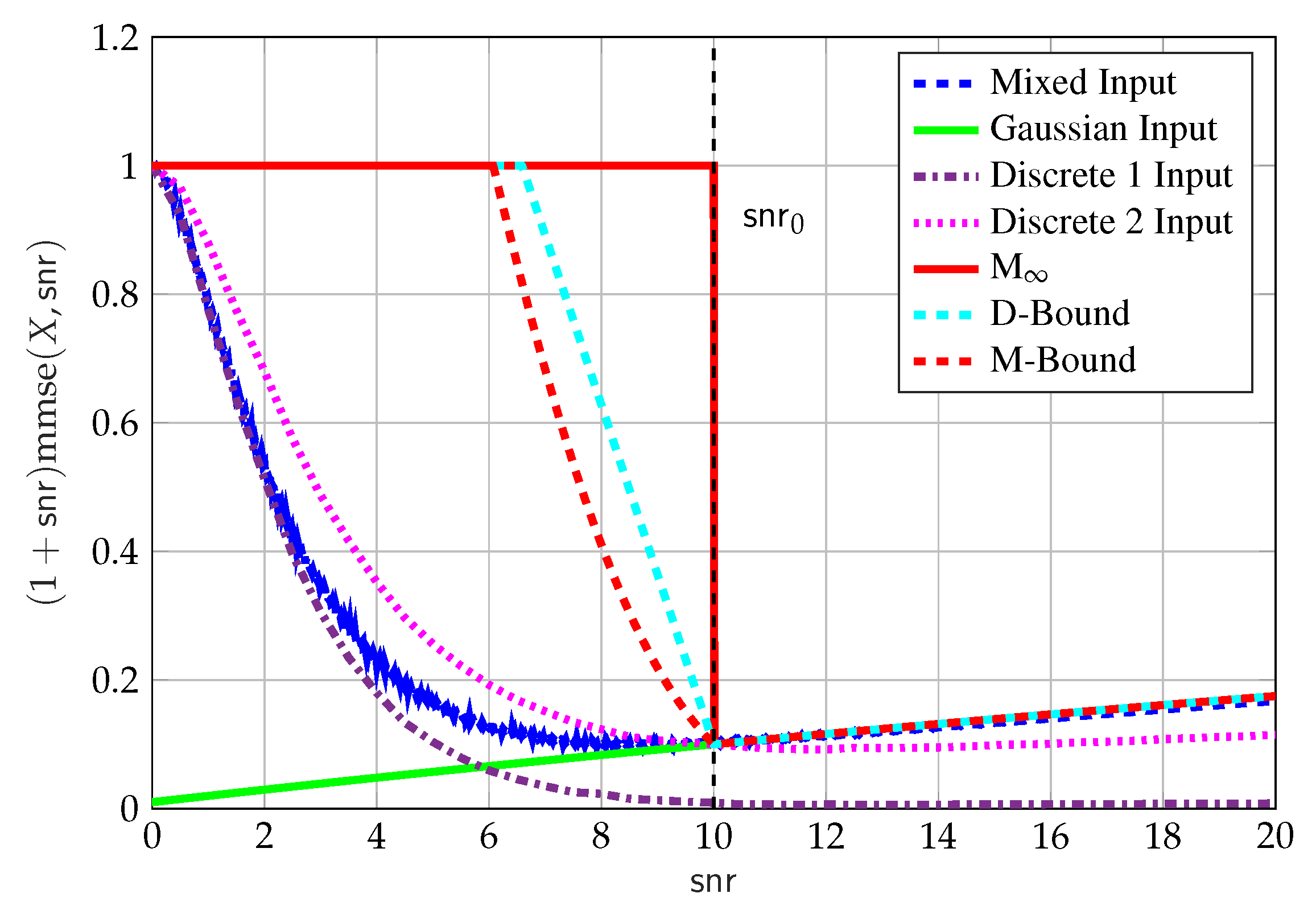
- The upper bound in (63) (solid red line);
- The upper D-bound (69a) (dashed cyan line) and upper M-bound (dashed red line) (70a);
- The Gaussian-only input (solid green line), with , where the power has been reduced to meet the MMSE constraint;
- The mixed input (blue dashed line), with the input in (71). We used Proposition 7 where we optimized over for . The choice of is motivated by the scaling property of the MMSE, that is, , and the constraint on the discrete component in (74). That is, we chose such that the power of is approximately while the MMSE constraint on in (74) is not equal to zero. The input used in Figure 9 was found by a local search algorithm on the space of distributions with , and resulted in with , which we do not claim to be optimal;
- The discrete-only input (Discrete 1 brown dashed-dotted line), withwith , that is, the same discrete part of the above mentioned mixed input. This is done for completeness, and to compare the performance of the MMSE of the discrete component of the mixed input with and without the Gaussian component; and
- The discrete-only input (Discrete 2 dotted magenta line), withwith , which was found by using a local search algorithm on the space of discrete-only distributions with points.
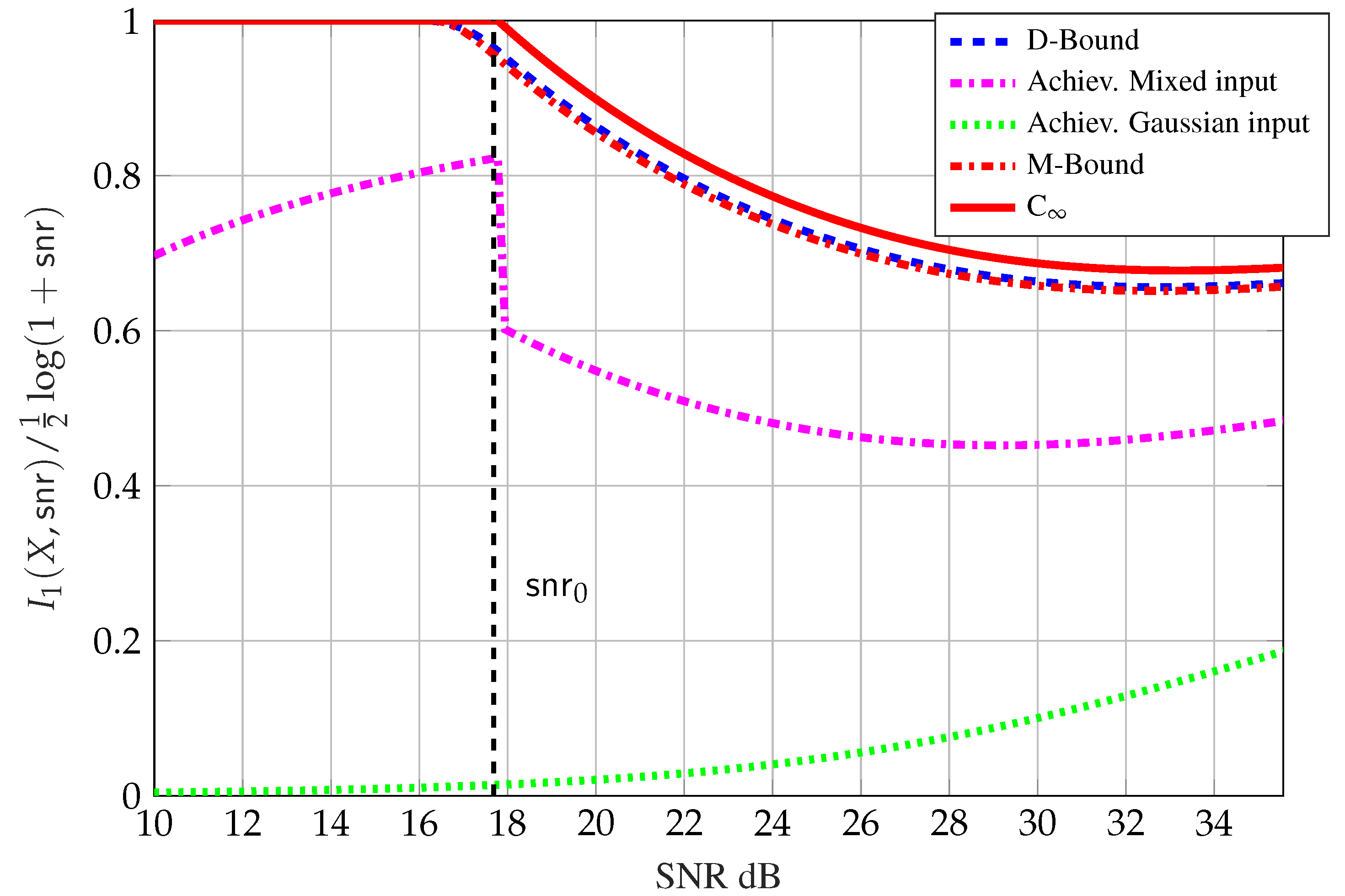
- The upper bound in (54) (solid red line);
- The upper bound from integration of the bound in (69a) (dashed blue line);
- The upper bound from integration of the bound in (70a) (dashed red line); and
- The inner bound with , where the reduction in power is necessary to satisfy the MMSE constraint (dotted green line).
6. Applications to the Broadcast Channel
6.1. Converse for the Gaussian Broadcast Channel
6.2. SNR Evolution of Optimal BC Codes
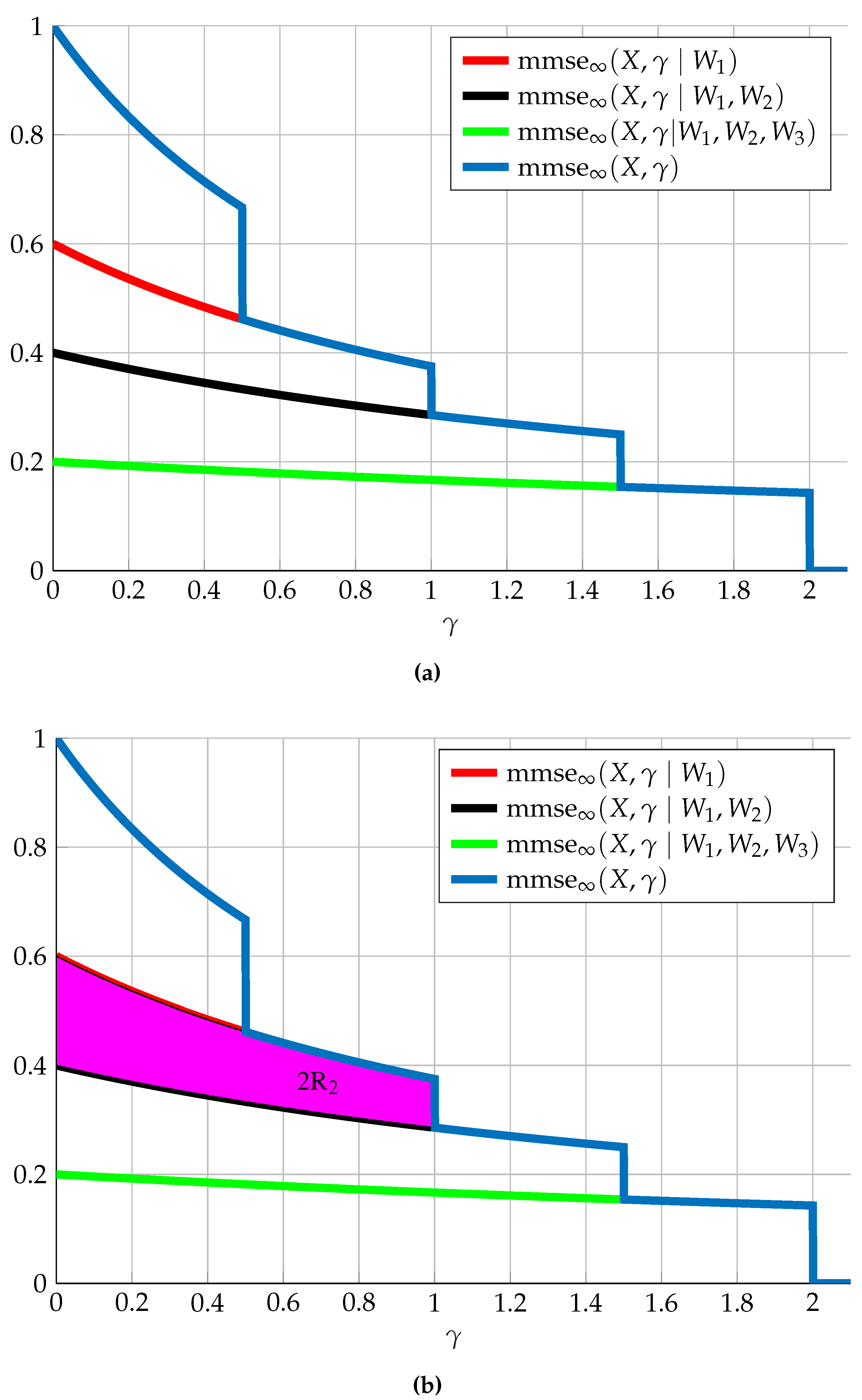
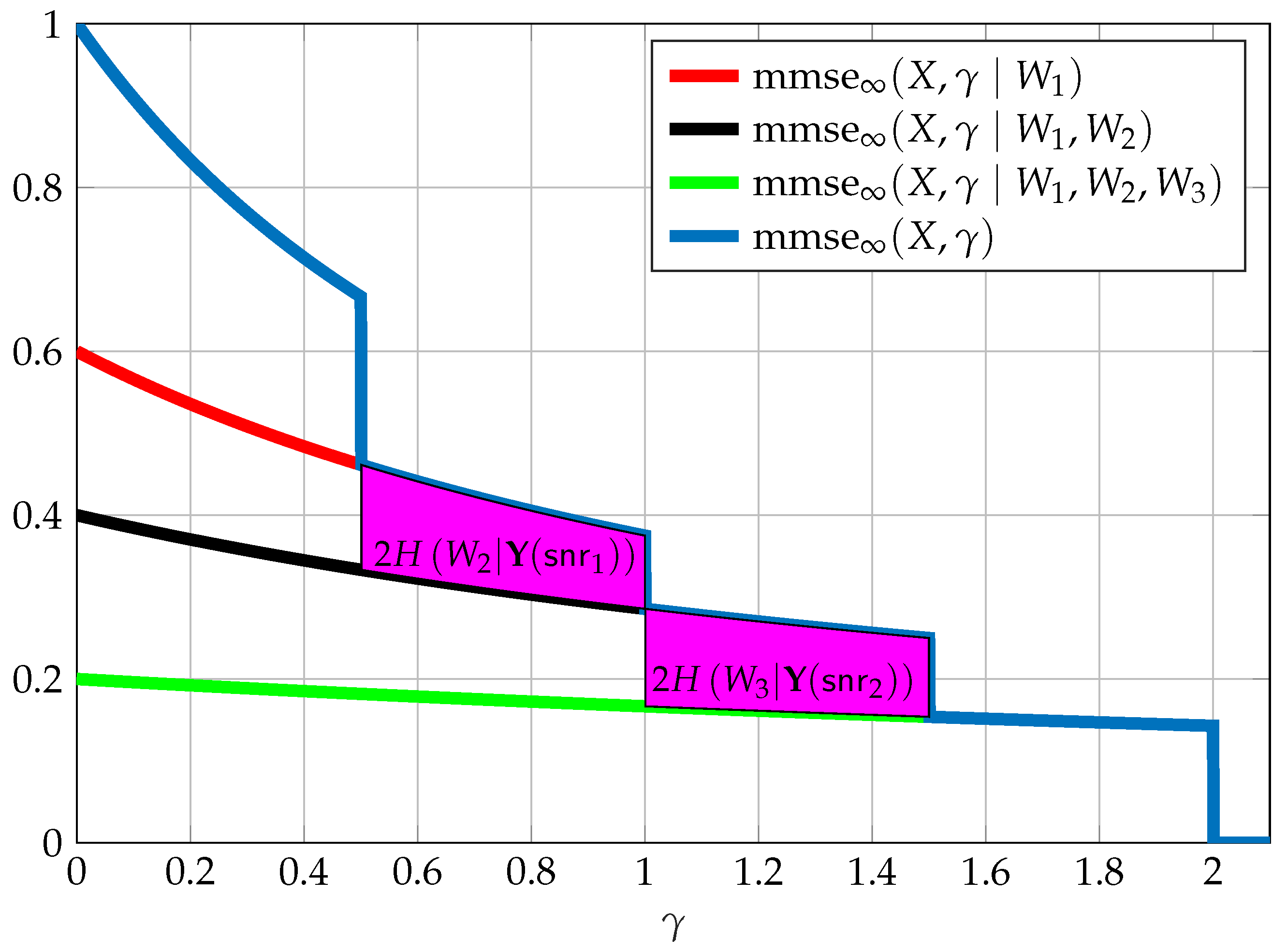
7. Multi-Receiver SNR-Evolution
- Reliably decoding some subset of these messages;
- Begin ignorant to some extent regarding some subset of these messages, meaning having at least some level of equivocation regarding the messages within this subset;
- A receiver may be an “unintended” receiver with respect to some subset of messages, in which case we might wish also to limit the “disturbance” these message have at this specific receiver. We may do so by limiting the MMSE of these messages; and
- Some combination of the above requirements.
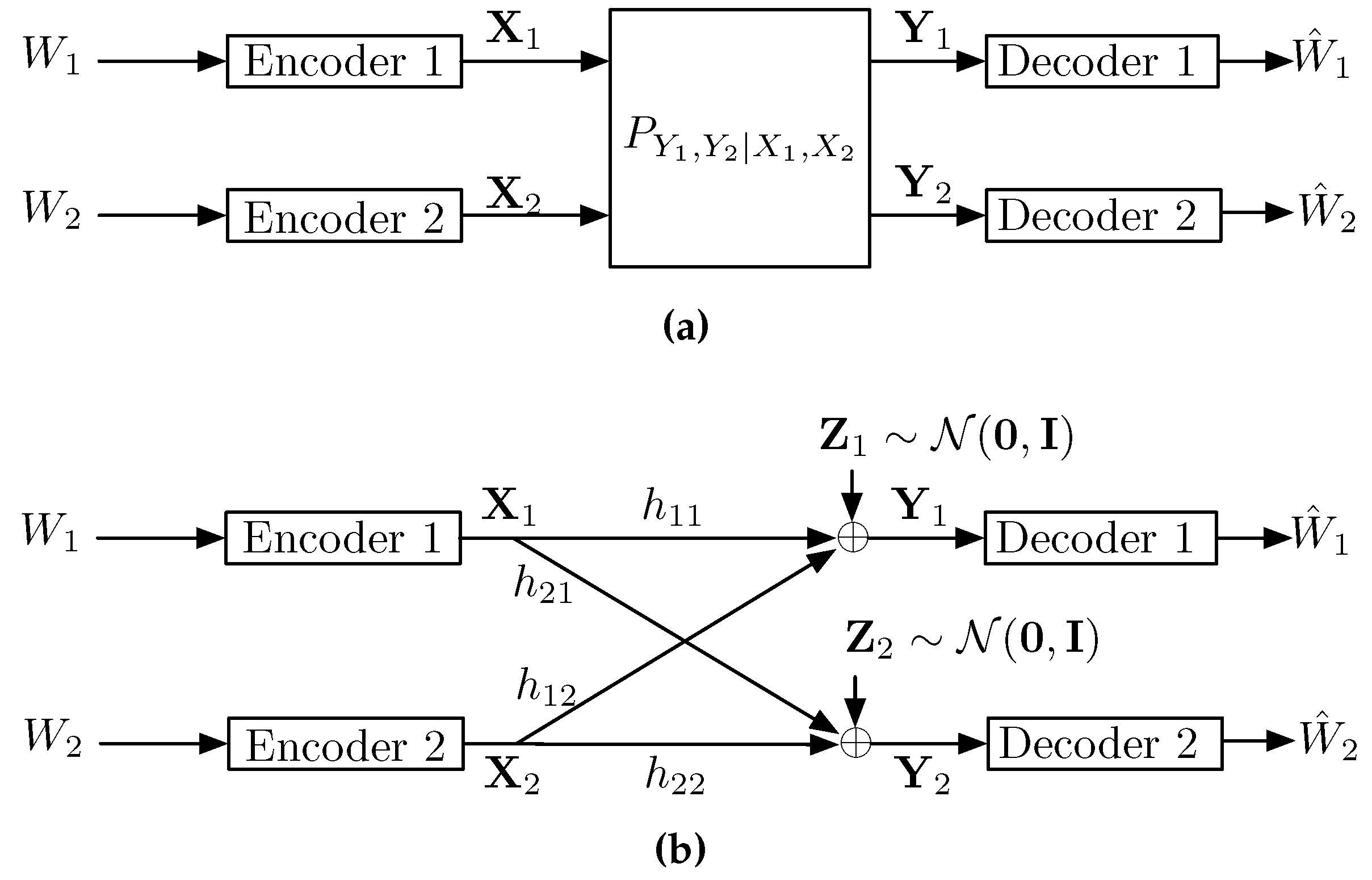
8. Interference Channels
8.1. Gaussian Interference Channel
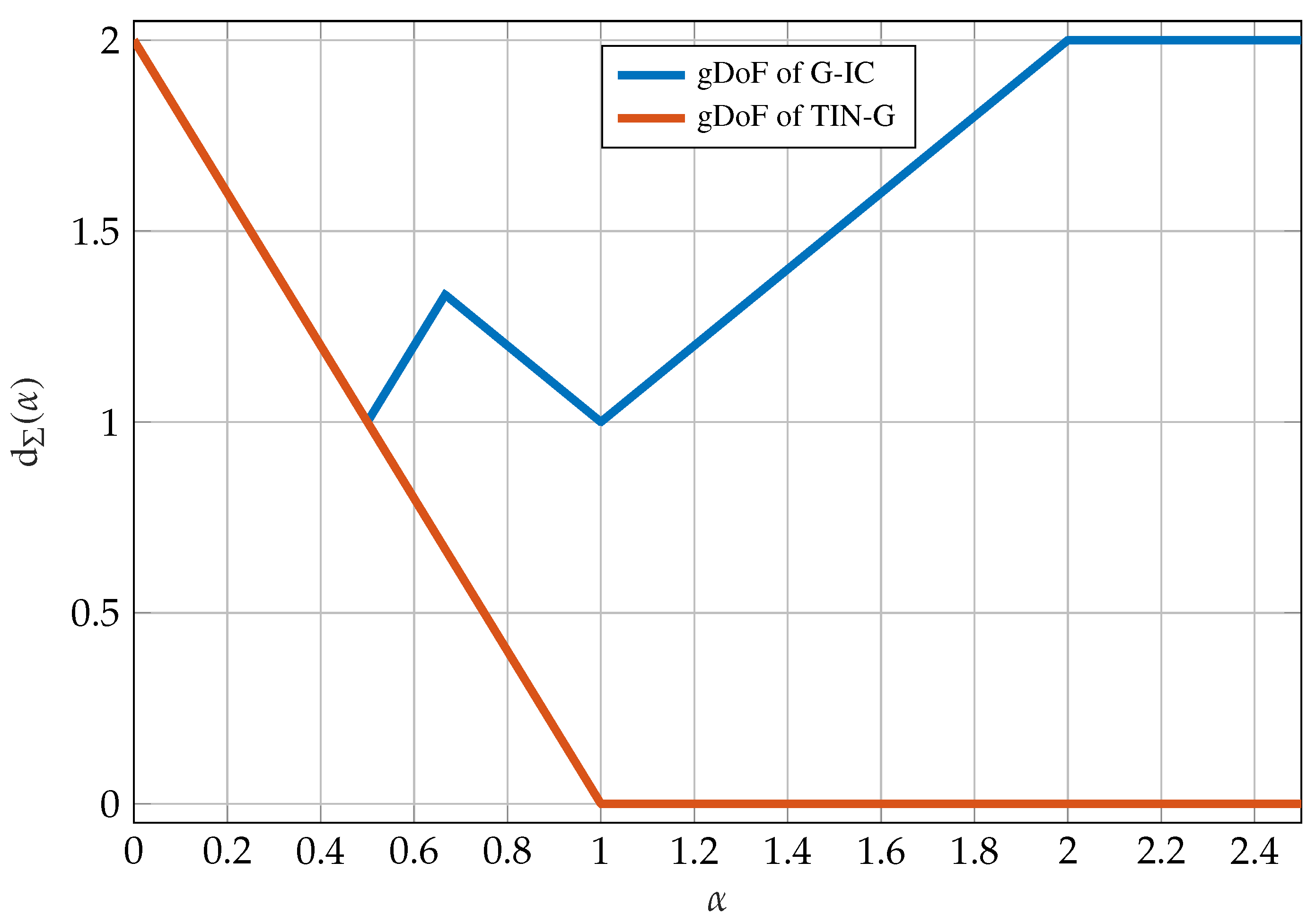
8.2. Generalized Degrees of Freedom
8.3. Treating Interference as Noise
9. Concluding Remarks and Future Directions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Proof of Proposition 3
Appendix B. Proof of Proposition 5
References
- Stam, A.J. Some inequalities satisfied by the quantities of information of Fisher and Shannon. Inf. Control 1959, 2, 101–112. [Google Scholar] [CrossRef]
- Esposito, R. On a relation between detection and estimation in decision theory. Inf. Control 1968, 12, 116–120. [Google Scholar] [CrossRef]
- Hatsell, C.; Nolte, L. Some geometric properties of the likelihood ratio. IEEE Trans. Inf. Theor. 1971, 17, 616–618. [Google Scholar] [CrossRef]
- Duncan, T.E. Evaluation of likelihood functions. Inf. Control 1968, 13, 62–74. [Google Scholar] [CrossRef]
- Kadota, T.; Zakai, M.; Ziv, J. Mutual information of the white Gaussian channel with and without feedback. IEEE Trans. Inf. Theor. 1971, 17, 368–371. [Google Scholar] [CrossRef]
- Kailath, T. The innovations approach to detection and estimation theory. Proc. IEEE 1970, 58, 680–695. [Google Scholar] [CrossRef]
- Duncan, T.E. On the calculation of mutual information. SIAM J. Appl. Math. 1970, 19, 215–220. [Google Scholar] [CrossRef]
- Guo, D.; Shamai (Shitz), S.; Verdú, S. Mutual information and minimum mean-square error in Gaussian channels. IEEE Trans. Inf. Theor. 2005, 51, 1261–1282. [Google Scholar] [CrossRef]
- Palomar, D.P.; Verdú, S. Gradient of mutual information in linear vector Gaussian channels. IEEE Trans. Inf. Theor. 2006, 52, 141–154. [Google Scholar] [CrossRef]
- Han, G.; Song, J. Extensions of the I-MMSE Relationship to Gaussian Channels With Feedback and Memory. IEEE Trans. Inf. Theor. 2016, 62, 5422–5445. [Google Scholar] [CrossRef]
- Guo, D.; Shamai (Shitz), S.; Verdú, S. Additive non-Gaussian noise channels: Mutual information and conditional mean estimation. In Proceedings of the IEEE International Symposium on Information Theory, Adelaide, Australia, 4–9 September 2005; pp. 719–723. [Google Scholar]
- Guo, D.; Shamai (Shitz), S.; Verdú, S. Mutual information and conditional mean estimation in Poisson channels. IEEE Trans. Inf. Theor. 2008, 54, 1837–1849. [Google Scholar] [CrossRef]
- Atar, R.; Weissman, T. Mutual information, relative entropy, and estimation in the Poisson channel. IEEE Trans. Inf. Theor. 2012, 58, 1302–1318. [Google Scholar] [CrossRef]
- Jiao, J.; Venkat, K.; Weissman, T. Relation between Information and Estimation in Discrete-Time Lévy Channels. IEEE Trans. Inf. Theor. 2017, 63, 3579–3594. [Google Scholar] [CrossRef]
- Taborda, C.G.; Guo, D.; Perez-Cruz, F. Information-estimation relationships over binomial and negative binomial models. IEEE Trans. Inf. Theor. 2014, 60, 2630–2646. [Google Scholar] [CrossRef]
- Verdú, S. Mismatched estimation and relative entropy. IEEE Trans. Inf. Theor. 2010, 56, 3712–3720. [Google Scholar] [CrossRef]
- Guo, D. Relative entropy and score function: New information-estimation relationships through arbitrary additive perturbation. In Proceedings of the IEEE International Symposium on Information Theory, Seoul, Korea, 28 June–3 July 2009; pp. 814–818. [Google Scholar]
- Zakai, M. On mutual information, likelihood ratios, and estimation error for the additive Gaussian channel. IEEE Trans. Inf. Theor. 2005, 51, 3017–3024. [Google Scholar] [CrossRef]
- Duncan, T.E. Mutual information for stochastic signals and fractional Brownian motion. IEEE Trans. Inf. Theor. 2008, 54, 4432–4438. [Google Scholar] [CrossRef]
- Duncan, T.E. Mutual information for stochastic signals and Lévy processes. IEEE Trans. Inf. Theor. 2010, 56, 18–24. [Google Scholar] [CrossRef]
- Weissman, T.; Kim, Y.H.; Permuter, H.H. Directed information, causal estimation, and communication in continuous time. IEEE Trans. Inf. Theor. 2013, 59, 1271–1287. [Google Scholar] [CrossRef]
- Venkat, K.; Weissman, T. Pointwise relations between information and estimation in Gaussian noise. IEEE Trans. Inf. Theor. 2012, 58, 6264–6281. [Google Scholar] [CrossRef]
- Guo, D.; Shamai (Shitz), S.; Verdú, S. The Interplay Between Information and Estimation Measures; Now Publishers: Boston, MA, USA, 2013. [Google Scholar]
- Ozarow, L.; Wyner, A. On the capacity of the Gaussian channel with a finite number of input levels. IEEE Trans. Inf. Theor. 1990, 36, 1426–1428. [Google Scholar] [CrossRef]
- Dytso, A.; Bustin, R.; Tuninetti, D.; Devroye, N.; Poor, H.V.; Shamai (Shitz), S. On the minimum mean p-th error in Gaussian noise channels and its applications. arXiv 2016, arXiv:1607.01461. [Google Scholar]
- Sherman, S. Non-mean-square error criteria. IRE Trans. Inf. Theor. 1958, 4, 125–126. [Google Scholar] [CrossRef]
- Akyol, E.; Viswanatha, K.B.; Rose, K. On conditions for linearity of optimal estimation. IEEE Trans. Inf. Theor. 2012, 58, 3497–3508. [Google Scholar] [CrossRef]
- Bustin, R.; Schaefer, R.F.; Poor, H.V.; Shamai (Shitz), S. On the SNR-evolution of the MMSE function of codes for the Gaussian broadcast and wiretap channels. IEEE Trans. Inf. Theor. 2016, 62, 2070–2091. [Google Scholar] [CrossRef]
- Bustin, R.; Poor, H.V.; Shamai (Shitz), S. The effect of maximal rate codes on the interfering message rate. In Proceedings of the IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 91–95. [Google Scholar]
- Guo, D.; Wu, Y.; Shamai (Shitz), S.; Verdú, S. Estimation in Gaussian noise: Properties of the minimum mean-square error. IEEE Trans. Inf. Theor. 2011, 57, 2371–2385. [Google Scholar]
- Wu, Y.; Verdú, S. Functional properties of minimum mean-square error and mutual information. IEEE Trans. Inf. Theor. 2012, 58, 1289–1301. [Google Scholar] [CrossRef]
- Wu, Y.; Verdú, S. MMSE dimension. IEEE Trans. Inf. Theor. 2011, 57, 4857–4879. [Google Scholar] [CrossRef]
- Bustin, R.; Payaró, M.; Palomar, D.P.; Shamai (Shitz), S. On MMSE crossing properties and implications in parallel vector Gaussian channels. IEEE Trans. Inf. Theor. 2013, 59, 818–844. [Google Scholar] [CrossRef]
- Bustin, R.; Schaefer, R.F.; Poor, H.V.; Shamai (Shitz), S. On MMSE properties of optimal codes for the Gaussian wiretap channel. In Proceedings of the IEEE Information Theory Workshop, Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Verdú, S.; Guo, D. A simple proof of the entropy-power inequality. IEEE Trans. Inf. Theor. 2006, 52, 2165–2166. [Google Scholar] [CrossRef]
- Guo, D.; Shamai (Shitz), S.; Verdú, S. Proof of entropy power inequalities via MMSE. In Proceedings of the IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 1011–1015. [Google Scholar]
- Tulino, A.M.; Verdú, S. Monotonic decrease of the non-Gaussianness of the sum of independent random variables: A simple proof. IEEE Trans. Inf. Theor. 2006, 52, 4295–4297. [Google Scholar] [CrossRef]
- Dytso, A.; Bustin, R.; Poor, H.V.; Shamai (Shitz), S. Comment on the equality condition for the I-MMSE proof of the entropy power inequality. arXiv 2017, arXiv:1703.07442. [Google Scholar]
- Cover, T.; Thomas, J. Elements of Information Theory; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Shannon, C. A mathematical theory of communication. Available online: http://math.harvard.edu/~ctm/home/text/others/shannon/entropy/entropy.pdf (accessed on 3 August 2017).
- Csiszar, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Gamal, A.E.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Abbe, E.; Zheng, L. A coordinate system for Gaussian networks. IEEE Trans. Inf. Theor. 2012, 58, 721–733. [Google Scholar] [CrossRef] [Green Version]
- Bennatan, A.; Shamai (Shitz), S.; Calderbank, A. Soft-decoding-based strategies for relay and interference channels: analysis and achievable rates using LDPC codes. IEEE Trans. Inf. Theor. 2014, 60, 1977–2009. [Google Scholar] [CrossRef]
- Dytso, A.; Tuninetti, D.; Devroye, N. Interference as noise: Friend or foe? IEEE Trans. Inf. Theor. 2016, 62, 3561–3596. [Google Scholar] [CrossRef]
- Moshksar, K.; Ghasemi, A.; Khandani, A. An alternative to decoding interference or treating interference as Gaussian noise. IEEE Trans. Inf. Theor. 2015, 61, 305–322. [Google Scholar] [CrossRef]
- Shamai (Shitz), S. From constrained signaling to network interference alignment via an information-estimation perspective. IEEE Inf. Theor. Soc. Newslett. 2012, 62, 6–24. [Google Scholar]
- Ungerboeck, G. Channel coding with multilevel/phase signals. IEEE Trans. Inf. Theor. 1982, 28, 55–67. [Google Scholar] [CrossRef]
- Dytso, A.; Tuninetti, D.; Devroye, N. On the two-user interference channel with lack of knowledge of the interference codebook at one receiver. IEEE Trans. Inf. Theor. 2015, 61, 1257–1276. [Google Scholar] [CrossRef]
- Dytso, A.; Bustin, R.; Tuninetti, D.; Devroye, N.; Poor, H.V.; Shamai (Shitz), S. New bounds on MMSE and applications to communication with the disturbance constraint. Available online: https://arxiv.org/pdf/1603.07628.pdf (accessed on 3 August 2017).
- Dong, Y.; Farnia, F.; Özgür, A. Near optimal energy control and approximate capacity of energy harvesting communication. IEEE J. Selected Areas Commun. 2015, 33, 540–557. [Google Scholar] [CrossRef]
- Shaviv, D.; Nguyen, P.M.; Özgür, A. Capacity of the energy-harvesting channel with a finite battery. IEEE Trans. Inf. Theor. 2016, 62, 6436–6458. [Google Scholar] [CrossRef]
- Bloch, M.; Barros, J.; Rodrigues, M.R.; McLaughlin, S.W. Wireless information-theoretic security. IEEE Trans. Inf. Theor. 2008, 54, 2515–2534. [Google Scholar] [CrossRef]
- Dytso, A.; Bustin, R.; Tuninetti, D.; Devroye, N.; Poor, H.V.; Shamai, S. On the applications of the minimum mean p-th error (MMPE) to information theoretic quantities. In Proceedings of the IEEE Information Theory Workshop, Cambridge, UK, 11–14 September 2016; pp. 66–70. [Google Scholar]
- Forney, G.D., Jr. On the role of MMSE estimation in approaching the information theoretic limits of linear Gaussian channels: Shannon meets Wiener. In Proceedings of the 41st Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 1–3 October 2003. [Google Scholar]
- Alvarado, A.; Brannstrom, F.; Agrell, E.; Koch, T. High-SNR asymptotics of mutual information for discrete constellations with applications to BICM. IEEE Trans. Inf. Theor. 2014, 60, 1061–1076. [Google Scholar] [CrossRef]
- Wu, Y.; Verdú, S. The impact of constellation cardinality on Gaussian channel capacity. In Proceedings of the 48th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 29 September–11 October 2010; pp. 620–628. [Google Scholar]
- Dytso, A.; Tuninetti, D.; Devroye, N. On discrete alphabets for the two-user Gaussian interference channel with one receiver lacking knowledge of the interfering codebook. In Proceedings of the Information Theory and Applications Workshop, San Diego, CA, USA, 9–14 February 2014; pp. 1–8. [Google Scholar]
- Dytso, A.; Goldenbaum, M.; Poor, H.V.; Shamai (Shitz), S. A generalized Ozarow-Wyner capacity bound with applications. In Proceedings of the IEEE International Symposium on Information Theory, Aachen, Germany, 25–30 June 2017; pp. 1058–1062. [Google Scholar]
- Dytso, A.; Bustin, R.; Poor, H.V.; Shamai (Shitz), S. On additive channels with generalized Gaussian noise. In Proceedings of the IEEE International Symposium on Information Theory, Aachen, Germany, 25–30 June 2017. [Google Scholar]
- Dytso, A.; Goldenbaum, M.; Shamai (Shitz), S.; Poor, H.V. Upper and lower bounds on the capacity of amplitude-constrained MIMO channels. In Proceedings of the IEEE Global Communications Conference, Singapore, 4–8 December 2017. [Google Scholar]
- Peleg, M.; Sanderovich, A.; Shamai (Shitz), S. On extrinsic information of good codes operating over memoryless channels with incremental noisiness. In Proceedings of the IEEE 24th Convention of Electrical and Electronics Engineers in Israel, Eilat, Israel, 15–17 November 2006; pp. 290–294. [Google Scholar]
- Merhav, N.; Guo, D.; Shamai (Shitz), S. Statistical physics of signal estimation in Gaussian noise: Theory and examples of phase transitions. IEEE Trans. Inf. Theor. 2010, 56, 1400–1416. [Google Scholar] [CrossRef]
- Wyner, A.D. The wire-tap channel. Bell Lab. Tech. J. 1975, 54, 1355–1387. [Google Scholar] [CrossRef]
- Csiszár, I.; Korner, J. Broadcast channels with confidential messages. IEEE Trans. Inf. Theor. 1978, 24, 339–348. [Google Scholar] [CrossRef]
- Leung-Yan-Cheong, S.; Hellman, M. The Gaussian wire-tap channel. IEEE Trans. Inf. Theor. 1978, 24, 451–456. [Google Scholar] [CrossRef]
- Massey, J.L. A simplified treatment of Wyner’s wire-tap channel. In Proceedings of the 21st Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 3–4 October 1983; pp. 268–276. [Google Scholar]
- Bloch, M.; Barros, J. Physical-Layer Security: From Information Theory to Security Engineering; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Bandemer, B.; El Gamal, A. Communication with disturbance constraints. IEEE Trans. Inf. Theor. 2014, 60, 4488–4502. [Google Scholar] [CrossRef]
- Bustin, R.; Shamai (Shitz), S. MMSE of ‘bad’ codes. IEEE Trans. Inf. Theor. 2013, 59, 733–743. [Google Scholar] [CrossRef]
- Shang, X.; Kramer, G.; Chen, B. A new outer bound and the noisy-interference sum-rate capacity for Gaussian interference channels. IEEE Trans. Inf. Theor. 2009, 55, 689–699. [Google Scholar] [CrossRef]
- Motahari, A.S.; Khandani, A.K. Capacity bounds for the Gaussian interference channel. IEEE Trans. Inf. Theor. 2009, 55, 620–643. [Google Scholar] [CrossRef]
- Annapureddy, V.S.; Veeravalli, V.V. Gaussian interference networks: Sum capacity in the low-interference regime and new outer bounds on the capacity region. IEEE Trans. Inf. Theor. 2009, 55, 3032–3050. [Google Scholar] [CrossRef]
- Han, T.; Kobayashi, K. A new achievable rate region for the interference channel. IEEE Trans. Inf. Theor. 1981, 27, 49–60. [Google Scholar] [CrossRef]
- Sato, H. The capacity of Gaussian interference channel under strong interference. IEEE Trans. Inf. Theor. 1981, 27, 786–788. [Google Scholar] [CrossRef]
- Etkin, R.; Tse, D.; Wang, H. Gaussian interference channel capacity to within one bit. IEEE Trans. Inf. Theor. 2008, 54, 5534–5562. [Google Scholar] [CrossRef]
- Ahlswede, R. Multi-way communication channels. In Proceedings of the IEEE International Symposium on Information Theory, Ashkelon, Israel, 25–29 June 1973; pp. 23–52. [Google Scholar]
- Gherekhloo, S.; Chaaban, A.; Sezgin, A. Expanded GDoF-optimality regime of treating interference as noise in the M×2 X-channel. IEEE Trans. Inf. Theor. 2016, 63, 355–376. [Google Scholar] [CrossRef]
- Cheng, R.; Verdú, S. On limiting characterizations of memoryless multiuser capacity regions. IEEE Trans. Inf. Theor. 1993, 39, 609–612. [Google Scholar] [CrossRef]
- Blasco-Serrano, R.; Thobaben, R.; Skoglund, M. Communication and interference coordination. In Proceedings of the Information Theory and Applications Workshop, San Diego, CA, USA, 9–14 February 2014; pp. 1–8. [Google Scholar]
- Huleihel, W.; Merhav, N. Analysis of mismatched estimation errors using gradients of partition functions. IEEE Trans. Inf. Theor. 2014, 60, 2190–2216. [Google Scholar] [CrossRef]
- Dytso, A.; Bustin, R.; Tuninetti, D.; Devroye, N.; Poor, H.V.; Shamai (Shitz), S. On communications through a Gaussian noise channel with an MMSE disturbance constraint. In Proceedings of the Information Theory and Applications Workshop, San Diego, CA, USA, 1–5 February 2016; pp. 1–8. [Google Scholar]
- Cover, T. Broadcast channels. IEEE Trans. Inf. Theor. 1972, 18, 2–14. [Google Scholar] [CrossRef]
- Cover, T. Comments on broadcast channels. IEEE Trans. Inf. Theor. 1998, 44, 2524–2530. [Google Scholar] [CrossRef]
- Gallager, R.G. Capacity and coding for degraded broadcast channels. Problemy Peredachi Informatsii 1974, 10, 3–14. [Google Scholar]
- Bergmans, P. A simple converse for broadcast channels with additive white Gaussian noise. IEEE Trans. Inf. Theor. 1974, 20, 279–280. [Google Scholar] [CrossRef]
- Bustin, R.; Schaefer, R.F.; Poor, H.V.; Shamai (Shitz), S. On MMSE properties of “good” and “bad” codes for the Gaussian broadcast channel. In Proceedings of the IEEE International Symposium on Information Theory, Hong Kong, China, 14–19 June 2015; pp. 14–19. [Google Scholar]
- Bustin, R.; Schaefer, R.F.; Poor, H.V.; Shamai (Shitz), S. An I-MMSE based graphical representation of rate and equivocation for the Gaussian broadcast channel. In Proceedings of the IEEE Conference on Communications and Network Security, Florence, Italy, 28–30 September 2015; pp. 53–58. [Google Scholar]
- Zou, S.; Liang, Y.; Lai, L.; Shamai (Shitz), S. Degraded broadcast channel: Secrecy outside of a bounded range. In Proceedings of the IEEE Information Theory Workshop, Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Wu, Y.; Shamai (Shitz), S.; Verdú, S. Information dimension and the degrees of freedom of the interference channel. IEEE Trans. Inf. Theor. 2015, 61, 256–279. [Google Scholar] [CrossRef]
- Carleial, A. A case where interference does not reduce capacity. IEEE Trans. Inf. Theor. 1975, 21, 569–570. [Google Scholar] [CrossRef]
- Costa, M.H.; El Gamal, A. The capacity region of the discrete memoryless interference channel with strong interference. IEEE Trans. Inf. Theor. 1987, 33, 710–711. [Google Scholar] [CrossRef]
- El Gamal, A.; Costa, M. The capacity region of a class of deterministic interference channels. IEEE Trans. Inf. Theor. 1982, 28, 343–346. [Google Scholar] [CrossRef]
- Bresler, G.; Tse, D. The two-user Gaussian interference channel: a deterministic view. Trans. Emerg. Telecommun. Technol. 2008, 19, 333–354. [Google Scholar] [CrossRef]
- Telatar, E.; Tse, D. Bounds on the capacity region of a class of interference channels. In Proceedings of the IEEE International Symposium on Information Theory, Toronto, ON, Canada, 6–11 July 2008; pp. 2871–2874. [Google Scholar]
- Nair, C.; Xia, L.; Yazdanpanah, M. Sub-optimality of Han-Kobayashi achievable region for interference channels. In Proceedings of the IEEE International Symposium on Information Theory, Hong Kong, China, 14–19 June 2015; pp. 2416–2420. [Google Scholar]
- Tse, D. It’s easier to approximate. IEEE Infor. Theor. Soc. Newslett. 2010, 60, 6–11. [Google Scholar]
- Cadambe, V.R.; Jafar, S.A. Interference alignment and degrees of freedom of the K-user interference channel. IEEE Trans. Inf. Theor. 2008, 54, 3425–3441. [Google Scholar] [CrossRef]
- Huang, C.; Cadambe, V.; Jafar, S. On the capacity and generalized degrees of freedom of the X channel. arXiv 2008, arXiv:0810.4741. [Google Scholar]
- Jafar, S.A. Interference alignment—A new look at signal dimensions in a communication network. Found. Trend. Commun. Inf. Theor. 2011, 7, 1–134. [Google Scholar] [CrossRef]
- Bustin, R.; Liu, R.; Poor, H.V.; Shamai (Shitz), S. An MMSE approach to the secrecy capacity of the MIMO Gaussian wiretap channel. EURASIP J. Wirel. Commun. Netw. 2009, 1, 370970. [Google Scholar] [CrossRef]
- Liu, R.; Liu, T.; Poor, H.V.; Shamai (Shitz), S. A vector generalization of Costa’s entropy-power inequality with applications. IEEE Trans. Inf. Theor. 2010, 56, 1865–1879. [Google Scholar]
- Pérez-Cruz, F.; Rodrigues, M.R.; Verdú, S. MIMO Gaussian channels with arbitrary inputs: Optimal precoding and power allocation. IEEE Trans. Inf. Theor. 2010, 56, 1070–1084. [Google Scholar] [CrossRef]
- Wu, Y.; Verdú, S. Optimal phase transitions in compressed sensing. IEEE Trans. Inf. Theor. 2012, 58, 6241–6263. [Google Scholar] [CrossRef]
- Chechik, G.; Globerson, A.; Tishby, N.; Weiss, Y. Information bottleneck for Gaussian variables. J. Mach. Learn. Res. 2005, 6, 165–188. [Google Scholar]
- Liu, T.; Viswanath, P. An extremal inequality motivated by multiterminal information-theoretic problems. IEEE Trans. Inf. Theor. 2007, 53, 1839–1851. [Google Scholar] [CrossRef]
- Weingarten, H.; Steinberg, Y.; Shamai (Shitz), S. The capacity region of the Gaussian multiple-input multiple-output broadcast channel. IEEE Trans. Inf. Theor. 2006, 52, 3936–3964. [Google Scholar] [CrossRef]
- Liu, T.; Shamai (Shitz), S. A note on the secrecy capacity of the multiple-antenna wiretap channel. IEEE Trans. Inf. Theor. 2009, 55, 2547–2553. [Google Scholar] [CrossRef]
- Rini, S.; Tuninetti, D.; Devroye, N. On the capacity of the Gaussian cognitive interference channel: New inner and outer bounds and capacity to within 1 bit. IEEE Trans. Inf. Theor. 2012, 58, 820–848. [Google Scholar] [CrossRef]
- Wu, Y.; Guo, D.; Verdú, S. Derivative of mutual information at zero SNR: The Gaussian-noise case. IEEE Trans. Inf. Theor. 2011, 57, 7307–7312. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Regime | Input Parameters |
|---|---|
| Weak Interference () | , |
| Strong Interference () | , , |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dytso, A.; Bustin, R.; Poor, H.V.; Shamai, S. A View of Information-Estimation Relations in Gaussian Networks. Entropy 2017, 19, 409. https://doi.org/10.3390/e19080409
Dytso A, Bustin R, Poor HV, Shamai S. A View of Information-Estimation Relations in Gaussian Networks. Entropy. 2017; 19(8):409. https://doi.org/10.3390/e19080409
Chicago/Turabian StyleDytso, Alex, Ronit Bustin, H. Vincent Poor, and Shlomo Shamai (Shitz). 2017. "A View of Information-Estimation Relations in Gaussian Networks" Entropy 19, no. 8: 409. https://doi.org/10.3390/e19080409
APA StyleDytso, A., Bustin, R., Poor, H. V., & Shamai, S. (2017). A View of Information-Estimation Relations in Gaussian Networks. Entropy, 19(8), 409. https://doi.org/10.3390/e19080409