Invariant Components of Synergy, Redundancy, and Unique Information among Three Variables





{kind=link}
{kind=link}
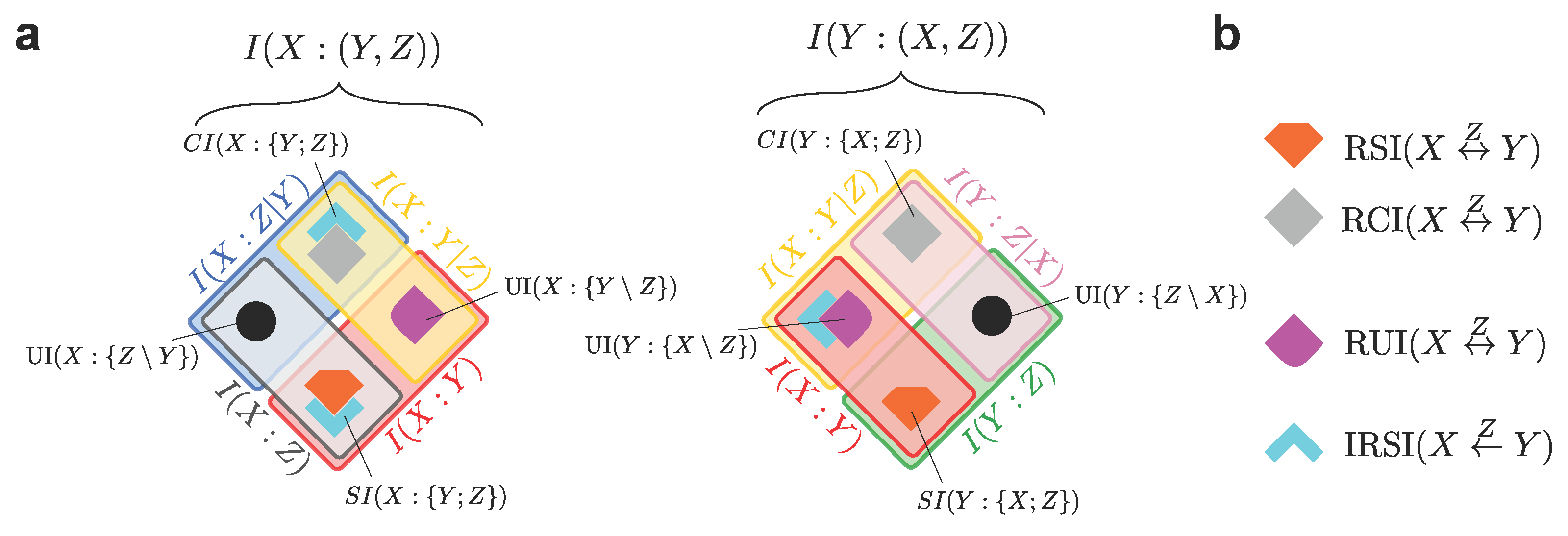{kind=link}
{kind=link}
{kind=link}
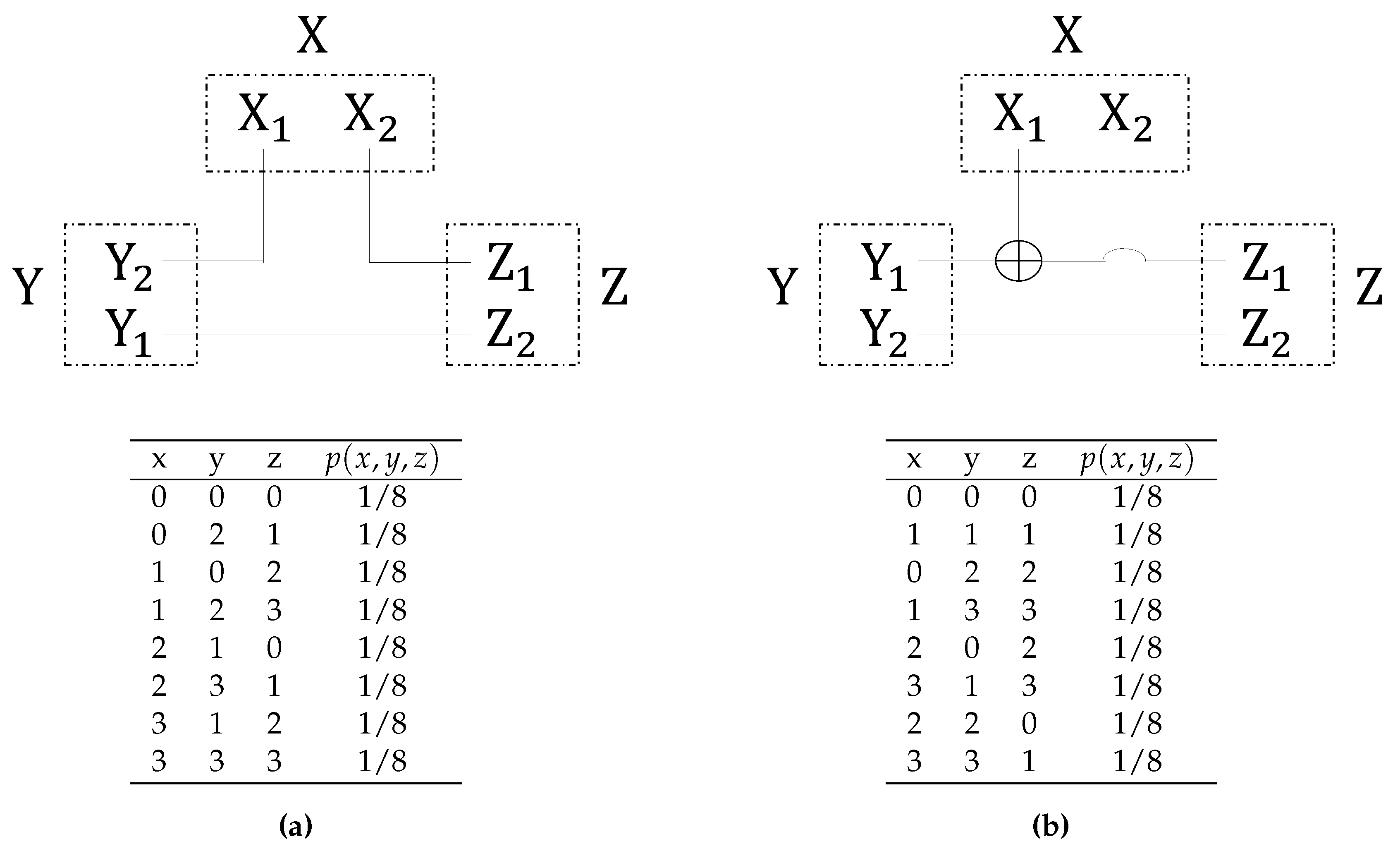{kind=link}
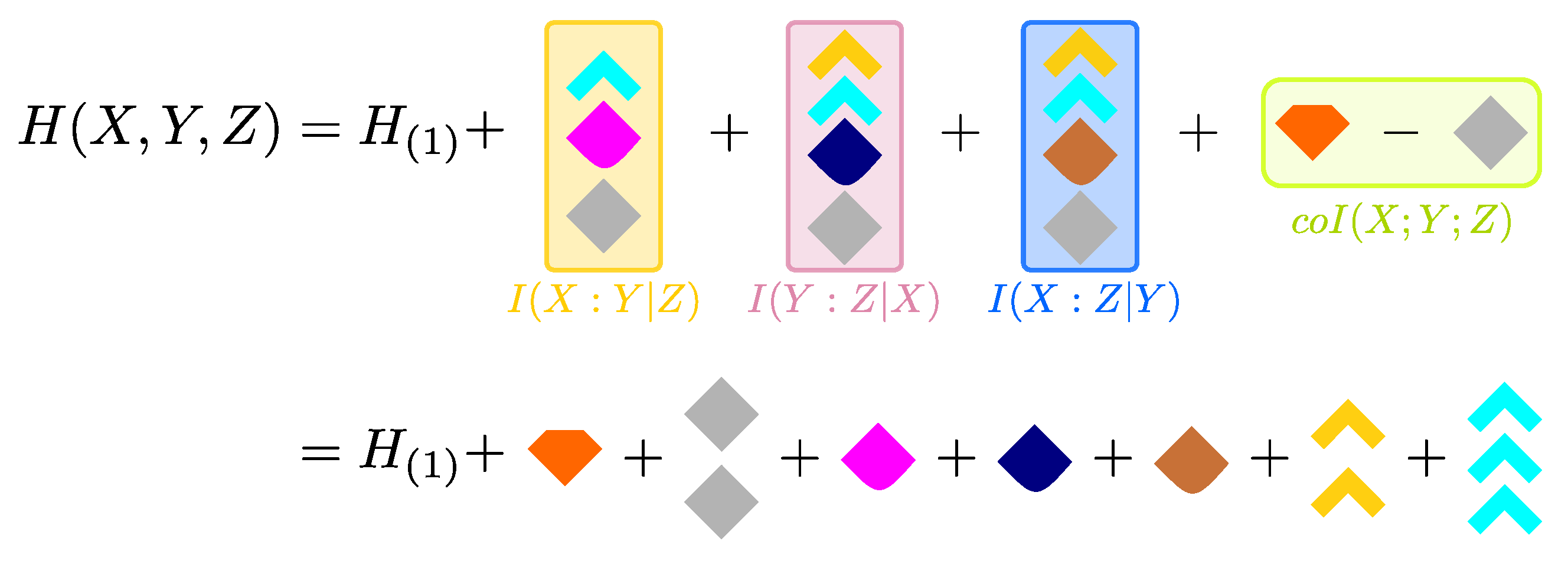{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
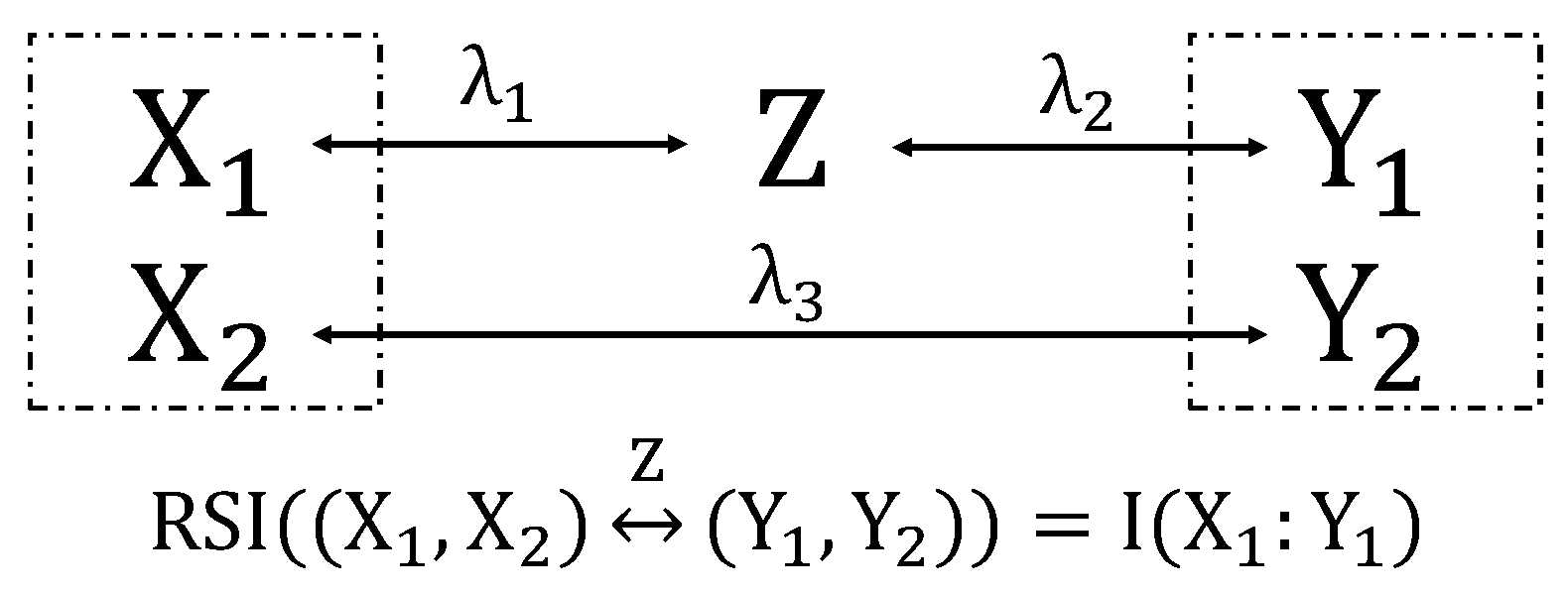{kind=link}
Abstract
:1. Introduction
2. Preliminaries and State of the Art
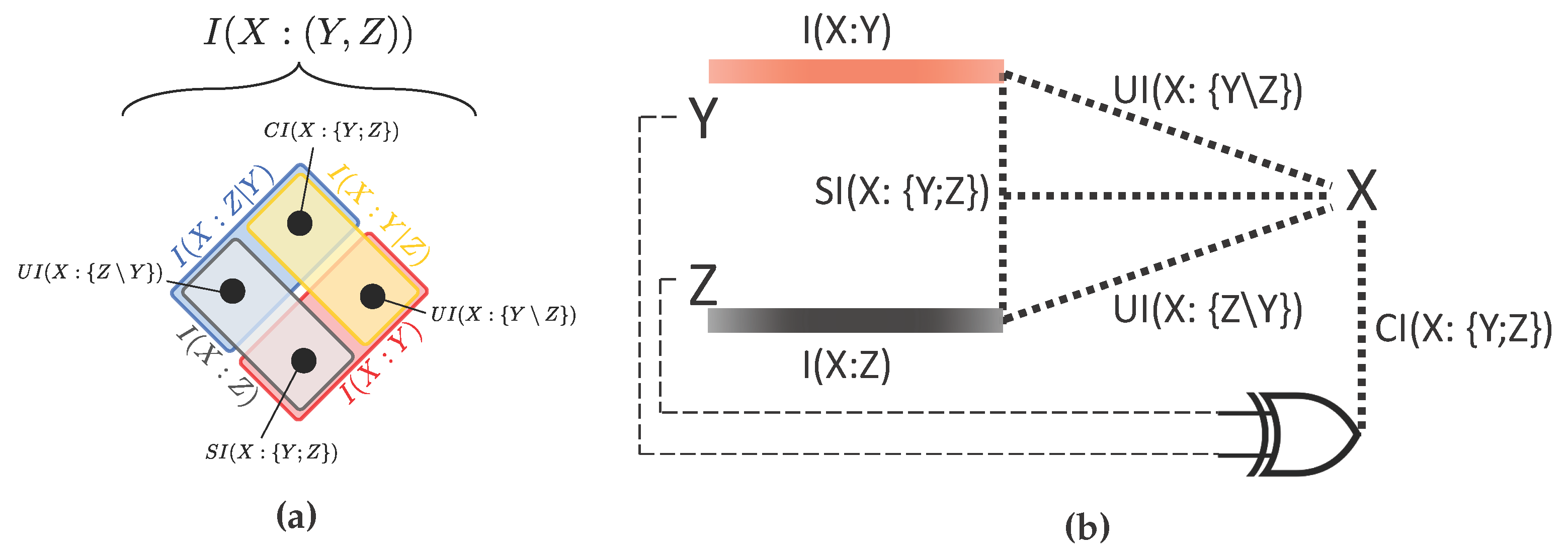
- the Shared Information , which is the information about the target that is shared between the two sources (the redundancy);
- the Unique Informations and , which are the separate pieces of information about the target that can be extracted from one of the sources, but not from the other;
- the Complementary Information , which is the information about the target that is only available when both of the sources are jointly observed (the synergy).
- the mechanistic redundancy, which can be larger than zero even if there is no mutual information between the sources.
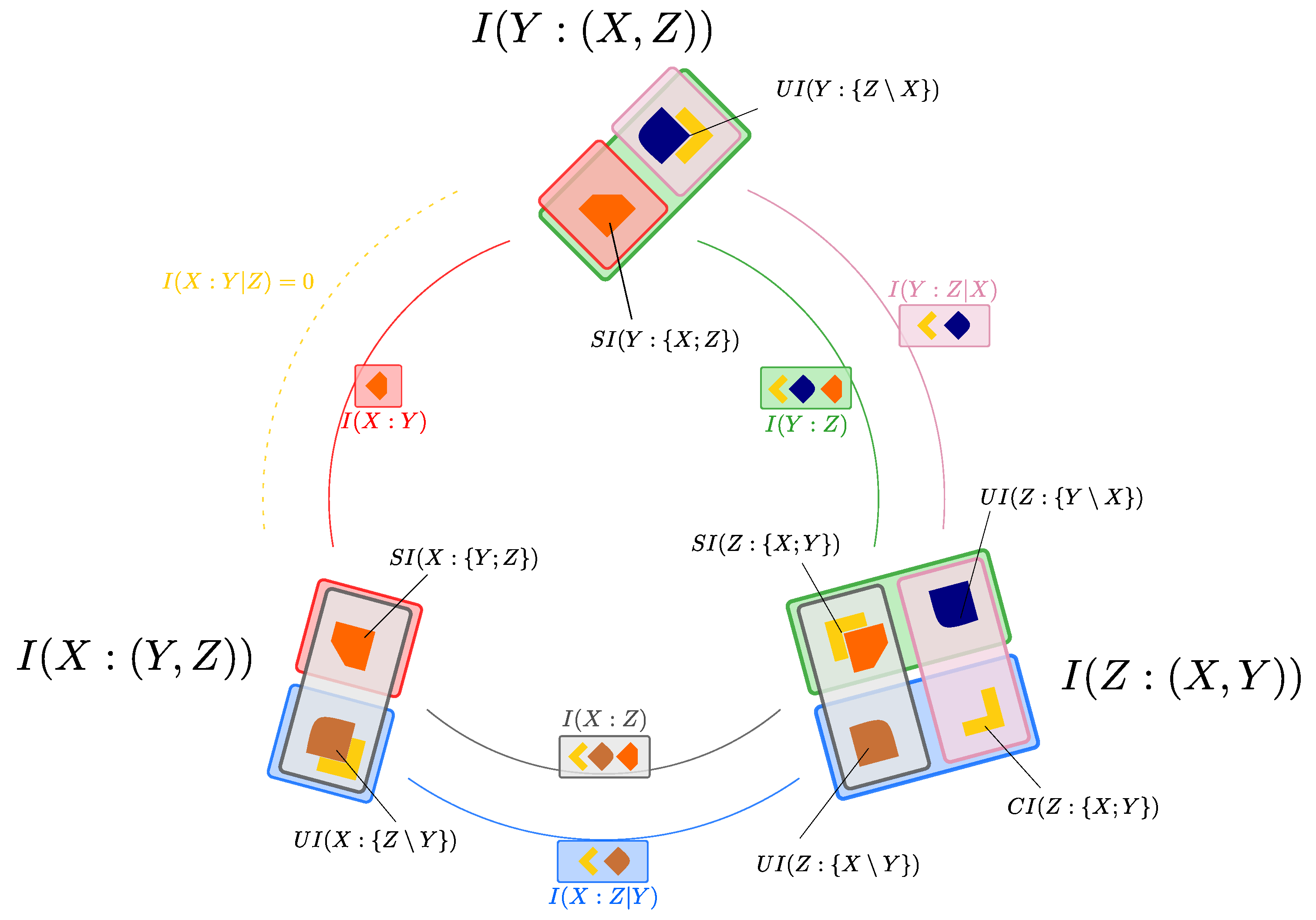
3. More PID Diagrams Unveil Finer Structure in the PID Framework
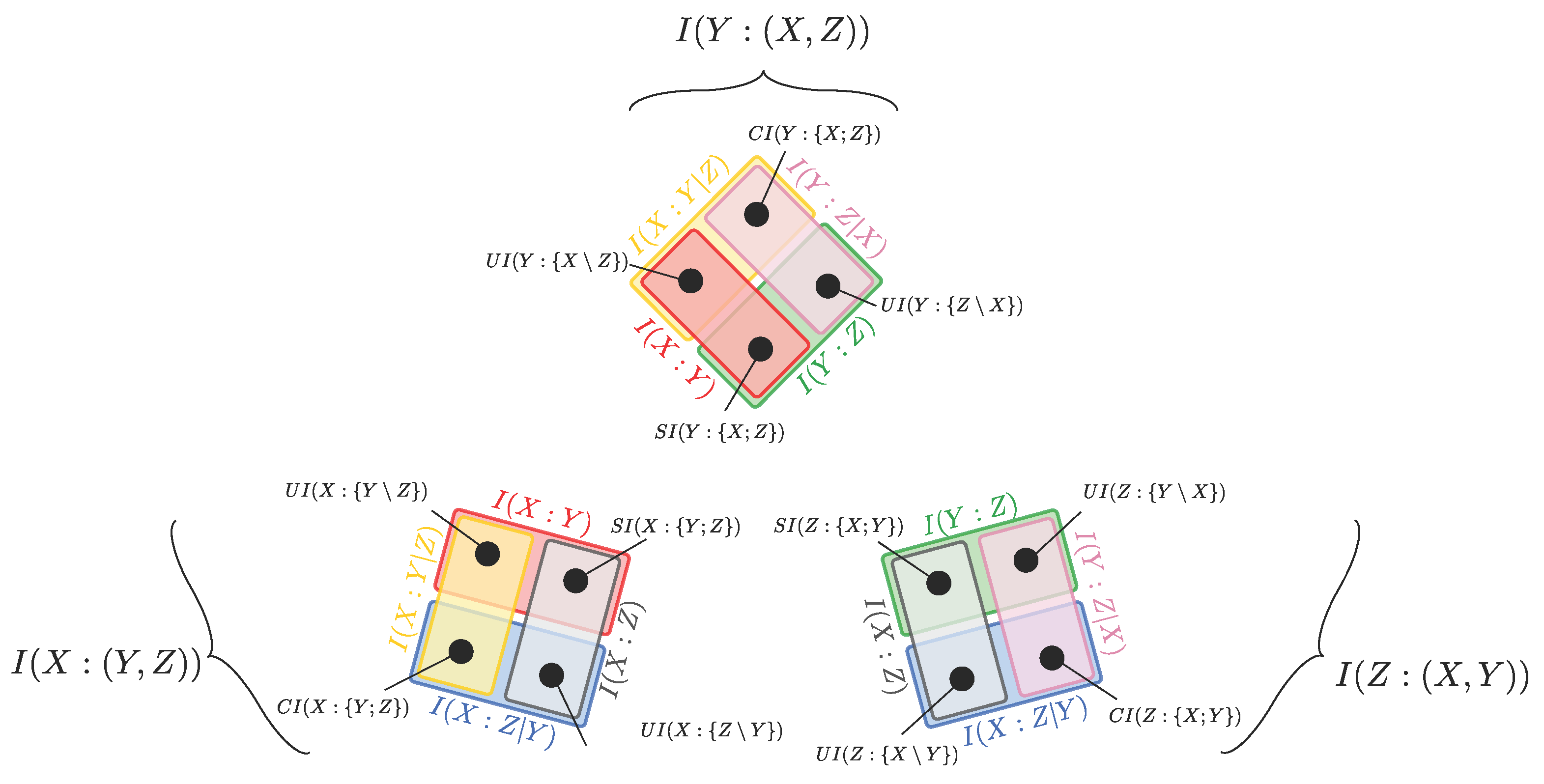
3.1. The Relationship between PID Diagrams with Different Target Selections
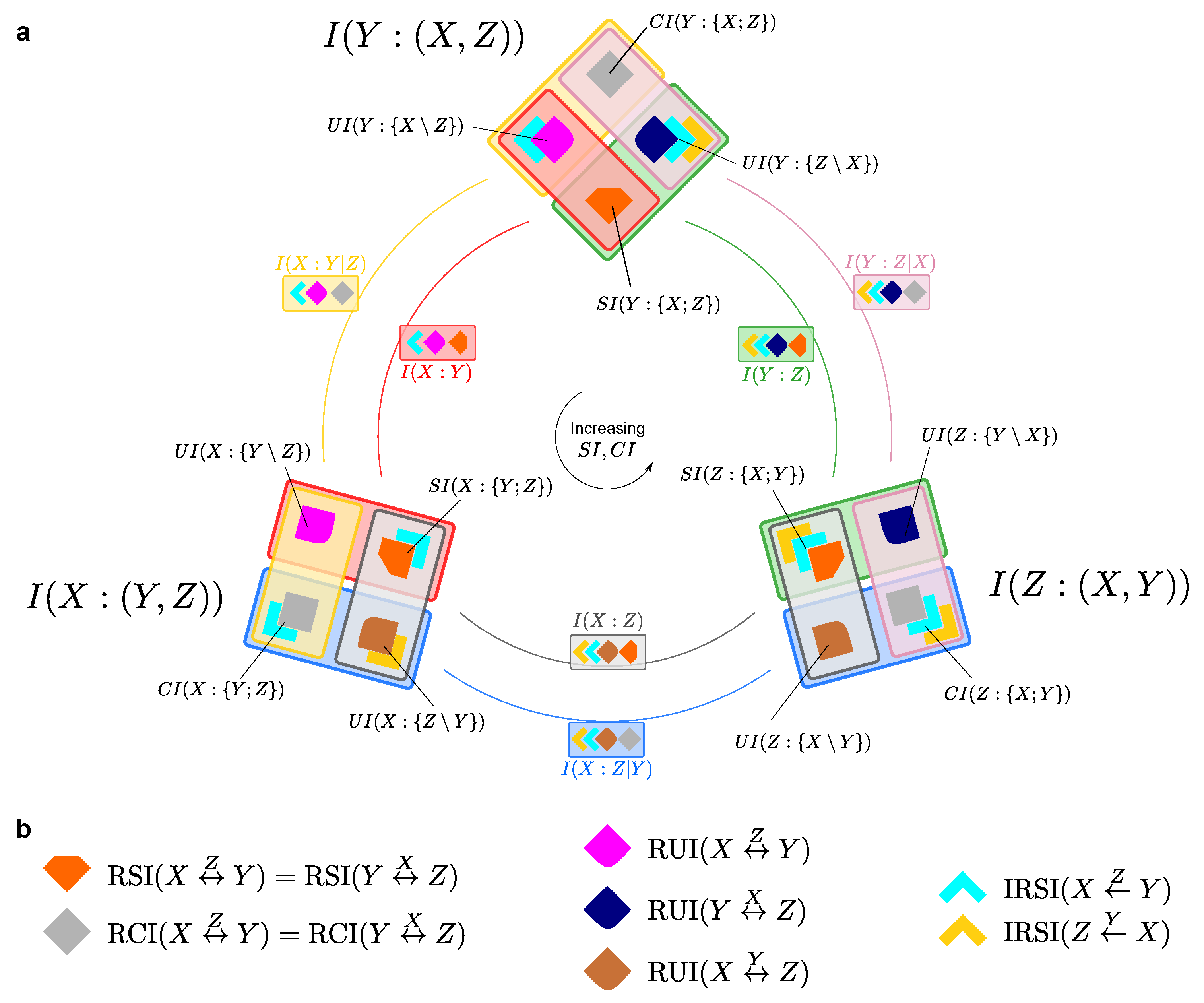
3.2. Unveiling the Finer Structure of the PID Framework
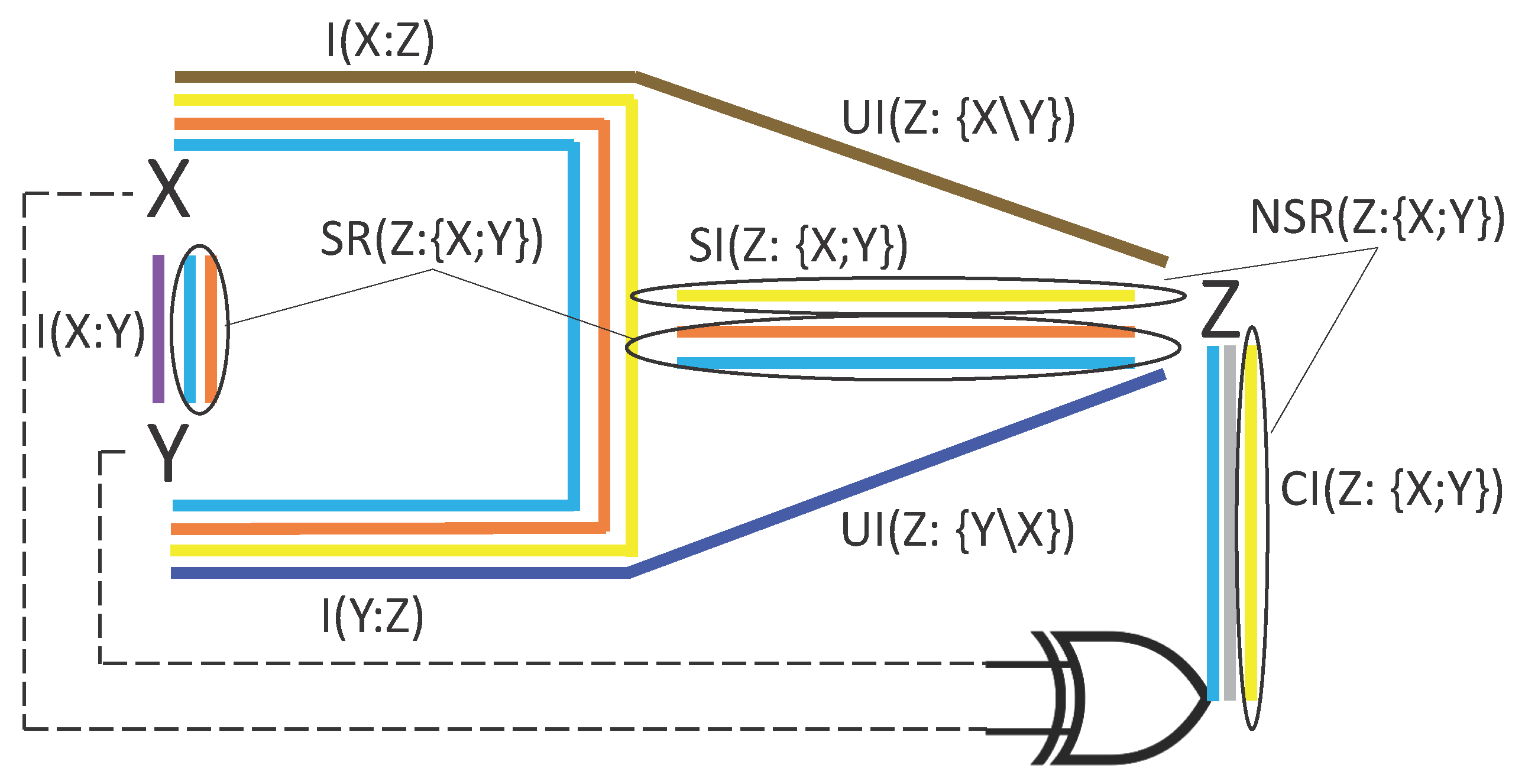
4. Quantifying Source Redundancy
4.1. The Difference between Source and Non-Source Redundancy
5. Decomposing the Joint Entropy of a Trivariate System
5.1. The Finer Structure of the Entropy
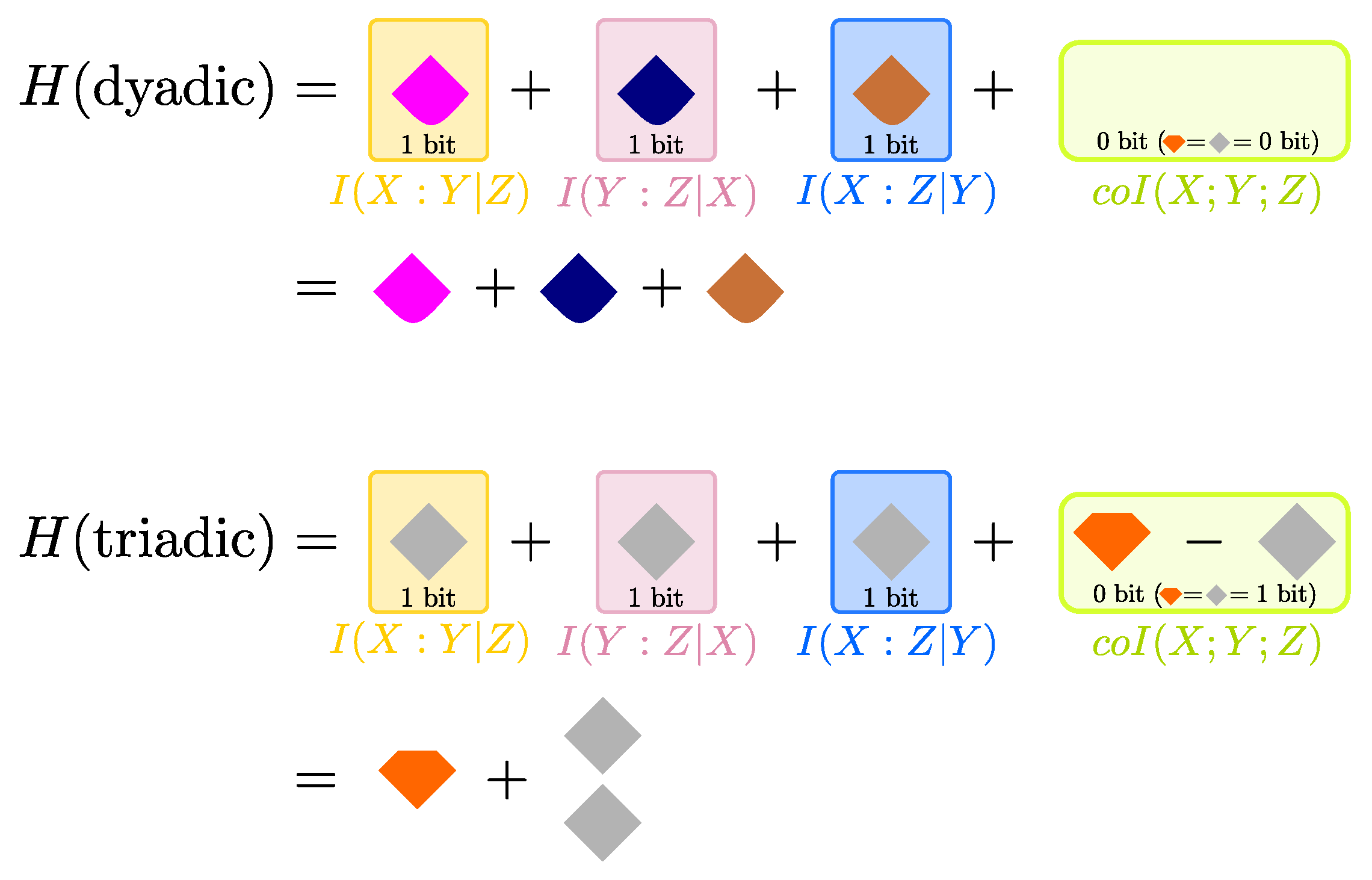
5.2. Describing for Dyadic and Triadic Systems
6. Applications of the Finer Structure of the PID Framework
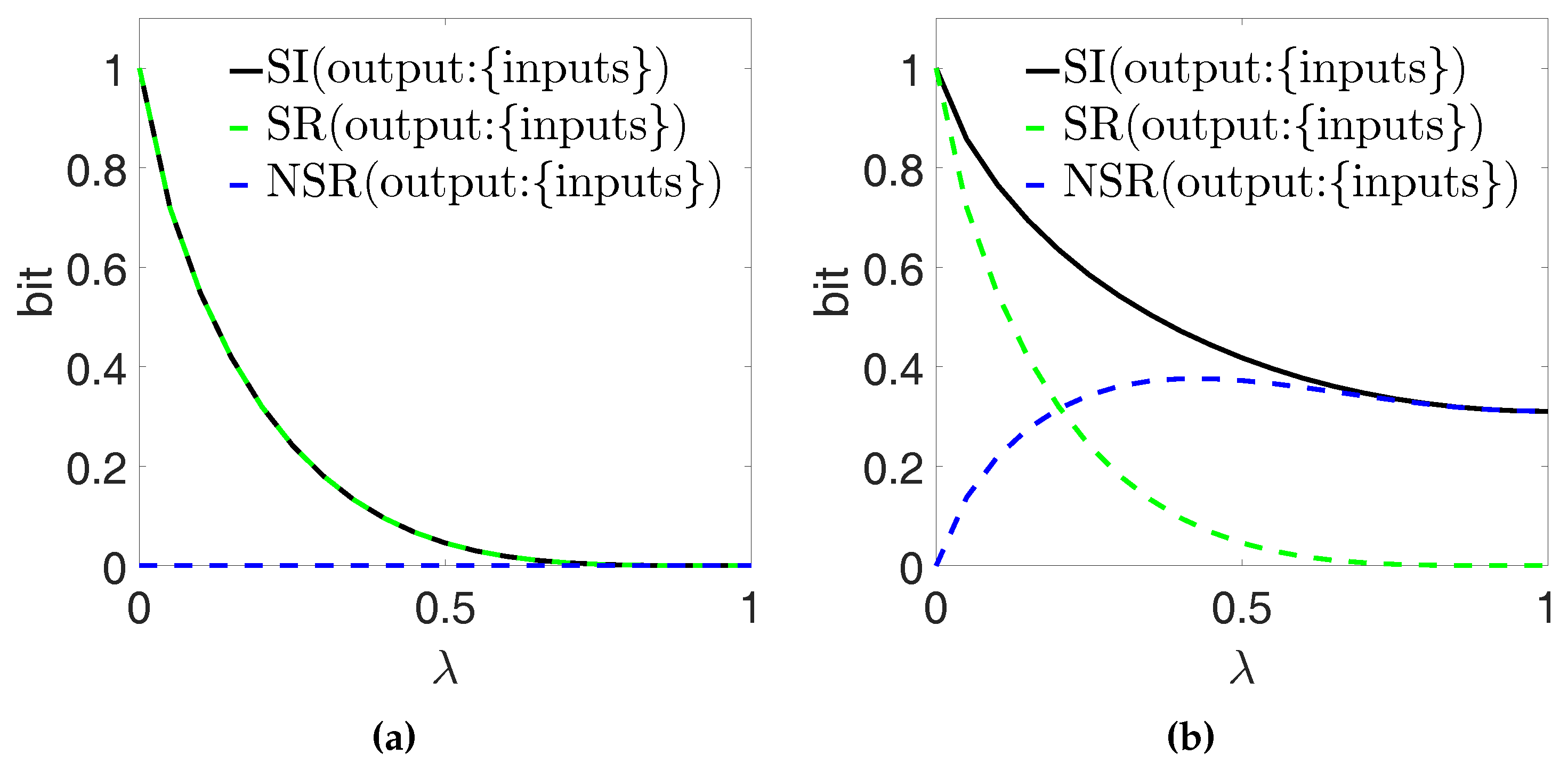
6.1. Computing Source and Non-Source Redundancy
6.1.1. Copying—The Redundancy Arises Entirely from Source Correlations
6.1.2. AND Gate: The Redundancy is not Entirely Related to Source Correlations
6.1.3. Dice Sum: Tuning Irreversible Redundancy
6.1.4. Trivariate Jointly Gaussian Systems
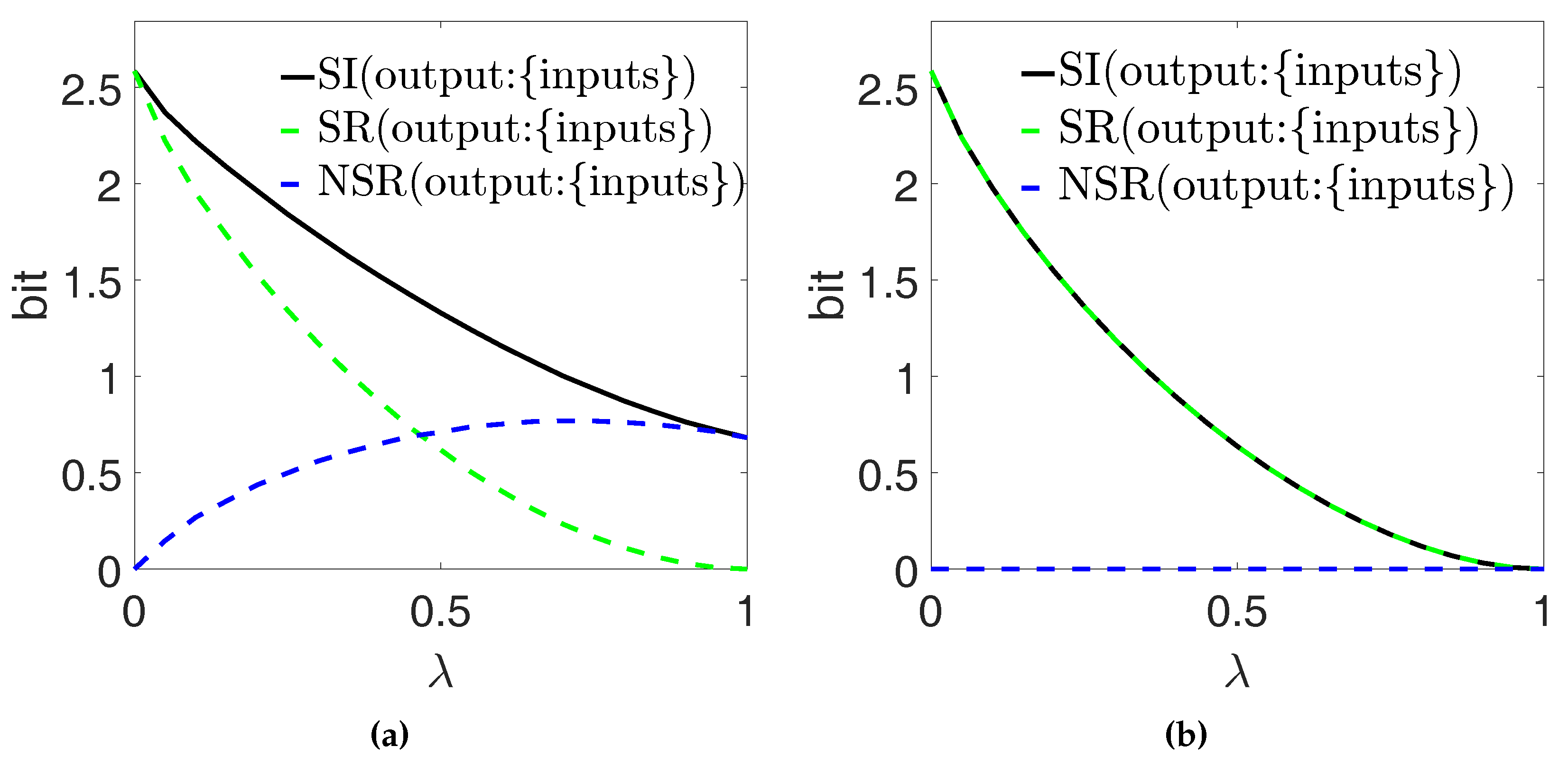
6.2. Quantifies Information between two Variables That also Passes Monotonically Through the Third
6.2.1. Markov Chains
6.2.2. Two Parallel Communication Channels
6.2.3. Other Examples
7. Discussion
7.1. Use of the Subatoms to Map the Distribution of Information in Trivariate Systems
7.2. Possible Extensions of the Formalism to Multivariate Systems with Many Sources
7.3. Potential Implications for Systems Biology and Systems Neuroscience
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Summary of the Relationships Among Distinct PID Lattices
References
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Ay, N.; Olbrich, E.; Bertschinger, N.; Jost, J. A unifying framework for complexity measures of finite systems. In Proceedings of the European Conference Complex Systems, Oxford, UK, 25–29 September 2006; Volume 6. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J. Shared Information—New Insights and Problems in Decomposing Information in Complex Systems. In Proceedings of the Proceedings of the ECCS 2012, Brussels, Belguim, 3–7 September 2012. [Google Scholar]
- Tononi, G.; Sporns, O.; Edelman, G.M. Measures of degeneracy and redundancy in biological networks. Proc. Natl. Acad. Sci. USA 1999, 96, 3257–3262. [Google Scholar] [CrossRef] [PubMed]
- Tikhonov, M.; Little, S.C.; Gregor, T. Only accessible information is useful: Insights from gradient-mediated patterning. R. Soc. Open Sci. 2015, 2, 150486. [Google Scholar] [CrossRef] [PubMed]
- Timme, N.; Alford, W.; Flecker, B.; Beggs, J.M. Synergy, redundancy, and multivariate information measures: An experimentalist’s perspective. J. Comput. Neurosci. 2014, 36, 119–140. [Google Scholar] [CrossRef] [PubMed]
- Pola, G.; Thiele, A.; Hoffmann, K.P.; Panzeri, S. An exact method to quantify the information transmitted by different mechanisms of correlational coding. Network 2003, 14, 35–60. [Google Scholar] [CrossRef] [PubMed]
- Schneidman, E.; Bialek, W.; Berry, M.J. Synergy, redundancy, and independence in population codes. J. Neurosci. 2003, 23, 11539–11553. [Google Scholar] [PubMed]
- Latham, P.E.; Nirenberg, S. Synergy, redundancy, and independence in population codes, revisited. J. Neurosci. 2005, 25, 5195–5206. [Google Scholar] [CrossRef] [PubMed]
- Williams, P.L.; Beer, R.D. Nonnegative Decomposition of Multivariate Information. arXiv, 2010; arXiv:1004.2515. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying Unique Information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Chicharro, D.; Panzeri, S. Synergy and Redundancy in Dual Decompositions of Mutual Information Gain and Information Loss. Entropy 2017, 19, 71. [Google Scholar] [CrossRef]
- Anastassiou, D. Computational analysis of the synergy among multiple interacting genes. Mol. Syst. Biol. 2007, 3, 83. [Google Scholar] [CrossRef] [PubMed]
- Lüdtke, N.; Panzeri, S.; Brown, M.; Broomhead, D.S.; Knowles, J.; Montemurro, M.A.; Kell, D.B. Information-theoretic sensitivity analysis: A general method for credit assignment in complex networks. J. R. Soc. Interface 2008, 5, 223–235. [Google Scholar] [CrossRef] [PubMed]
- Watkinson, J.; Liang, K.C.; Wang, X.; Zheng, T.; Anastassiou, D. Inference of Regulatory Gene Interactions from Expression Data Using Three-Way Mutual Information. Ann. N. Y. Acad. Sci. 2009, 1158, 302–313. [Google Scholar] [CrossRef] [PubMed]
- Faes, L.; Marinazzo, D.; Nollo, G.; Porta, A. An Information-Theoretic Framework to Map the Spatiotemporal Dynamics of the Scalp Electroencephalogram. IEEE Trans. Biomed. Eng. 2016, 63, 2488–2496. [Google Scholar] [CrossRef] [PubMed]
- Pitkow, X.; Liu, S.; Angelaki, D.E.; DeAngelis, G.C.; Pouget, A. How Can Single Sensory Neurons Predict Behavior? Neuron 2015, 87, 411–423. [Google Scholar] [CrossRef] [PubMed]
- Haefner, R.M.; Gerwinn, S.; Macke, J.H.; Bethge, M. Inferring decoding strategies from choice probabilities in the presence of correlated variability. Nat. Neurosci. 2013, 16, 235–242. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Harvey, C.D.; Piasini, E.; Latham, P.E.; Fellin, T. Cracking the Neural Code for Sensory Perception by Combining Statistics, Intervention, and Behavior. Neuron 2017, 93, 491–507. [Google Scholar] [CrossRef] [PubMed]
- Wibral, M.; Priesemann, V.; Kay, J.W.; Lizier, J.T.; Phillips, W.A. Partial information decomposition as a unified approach to the specification of neural goal functions. Brain Cogn. 2017, 112, 25–38. [Google Scholar] [CrossRef] [PubMed]
- James, R.G.; Crutchfield, J.P. Multivariate Dependence Beyond Shannon Information. arXiv, 2016; arXiv:1609.01233v2. [Google Scholar]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E 2013, 87, 012130. [Google Scholar] [CrossRef] [PubMed]
- Barrett, A.B. Exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems. Phys. Rev. E 2015, 91, 052802. [Google Scholar] [CrossRef] [PubMed]
- Williams, P.L. Information Dynamics: Its Theory and Application to Embodied Cognitive Systems. Ph.D. Thesis, Indiana University, Bloomington, IN, USA, 2011. [Google Scholar]
- Ince, R.A.A. Measuring Multivariate Redundant Information with Pointwise Common Change in Surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef]
- Griffith, V.; Koch, C. Quantifying Synergistic Mutual Information. In Guided Self-Organization: Inception; Springer: Berlin/Heidelberg, Germany, 2014; pp. 159–190. [Google Scholar]
- Griffith, V.; Chong, E.K.P.; James, R.G.; Ellison, C.J.; Crutchfield, J.P. Intersection Information Based on Common Randomness. Entropy 2014, 16, 1985–2000. [Google Scholar] [CrossRef]
- Banerjee, P.K.; Griffith, V. Synergy, Redundancy and Common Information. arXiv, 2015; arXiv:1509.03706. [Google Scholar]
- Ince, R.A.A. The Partial Entropy Decomposition: Decomposing multivariate entropy and mutual information via pointwise common surprisal. arXiv, 2017; arXiv:1702.01591v2. [Google Scholar]
- Rauh, J.; Banerjee, P.K.; Olbrich, E.; Jost, J.; Bertschinger, N. On extractable shared information. arXiv, 2017; arXiv:1701.07805. [Google Scholar]
- Griffith, V.; Koch, C. Quantifying synergistic mutual information. arXiv, 2013; arXiv:1205.4265v3. [Google Scholar]
- Stramaglia, S.; Angelini, L.; Wu, G.; Cortes, J.M.; Faes, L.; Marinazzo, D. Synergetic and Redundant Information Flow Detected by Unnormalized Granger Causality: Application to Resting State fMRI. IEEE Trans. Biomed. Eng. 2016, 63, 2518–2524. [Google Scholar] [CrossRef] [PubMed]
- Rosas, F.; Ntranos, V.; Ellison, C.J.; Pollin, S.; Verhelst, M. Understanding Interdependency Through Complex Information Sharing. Entropy 2016, 18, 38. [Google Scholar] [CrossRef]
- McGill, W.J. Multivariate information transmission. Psychometrika 1954, 19, 97–116. [Google Scholar] [CrossRef]
- Han, T.S. Nonnegative entropy measures of multivariate symmetric correlations. Inf. Control 1978, 36, 133–156. [Google Scholar] [CrossRef]
- Watanabe, S. Information Theoretical Analysis of Multivariate Correlation. IBM J. Res. Dev. 1960, 4, 66–82. [Google Scholar] [CrossRef]
- Margolin, A.A.; Nemenman, I.; Basso, K.; Wiggins, C.; Stolovitzky, G.; Favera, R.D.; Califano, A. ARACNE: An Algorithm for the Reconstruction of Gene Regulatory Networks in a Mammalian Cellular Context. BMC Bioinform. 2006, 7. [Google Scholar] [CrossRef] [PubMed]
- Averbeck, B.B.; Latham, P.E.; Pouget, A. Neural correlations, population coding and computation. Nat. Rev. Neurosci. 2006, 7, 358–366. [Google Scholar] [CrossRef] [PubMed]
- Quian, R.Q.; Panzeri, S. Extracting information from neuronal populations: information theory and decoding approaches. Nat. Rev. Neurosci. 2009, 10, 173–185. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Macke, J.H.; Gross, J.; Kayser, C. Neural population coding: combining insights from microscopic and mass signals. Trends Cogn. Sci. 2015, 19, 162–172. [Google Scholar] [CrossRef] [PubMed]
- Pearl, J. Causality: Models, Reasoning and Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Shamir, M. Emerging principles of population coding: In search for the neural code. Curr. Opin. Neurobiol. 2014, 25, 140–148. [Google Scholar] [CrossRef] [PubMed]
- Runyan, C.A.; Piasini, E.; Panzeri, S.; Harvey, C.D. Distinct timescales of population coding across cortex. Nature 2017, 548, 92–96. [Google Scholar] [CrossRef] [PubMed]
- Timme, N.M.; Ito, S.; Myroshnychenko, M.; Nigam, S.; Shimono, M.; Yeh, F.C.; Hottowy, P.; Litke, A.M.; Beggs, J.M. High-Degree Neurons Feed Cortical Computations. PLoS Comput. Biol. 2016, 12, e1004858. [Google Scholar] [CrossRef] [PubMed]
- Jazayeri, M.; Afraz, A. Navigating the Neural Space in Search of the Neural Code. Neuron 2017, 93, 1003–1014. [Google Scholar] [CrossRef] [PubMed]
- Gallego, J.A.; Perich, M.G.; Miller, L.E.; Solla, S.A. Neural Manifolds for the Control of Movement. Neuron 2017, 94, 978–984. [Google Scholar] [CrossRef] [PubMed]
- Sharpee, T.O. Optimizing Neural Information Capacity through Discretization. Neuron 2017, 94, 954–960. [Google Scholar] [CrossRef] [PubMed]
- Pitkow, X.; Angelaki, D.E. Inference in the Brain: Statistics Flowing in Redundant Population Codes. Neuron 2017, 94, 943–953. [Google Scholar] [CrossRef] [PubMed]












© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pica, G.; Piasini, E.; Chicharro, D.; Panzeri, S. Invariant Components of Synergy, Redundancy, and Unique Information among Three Variables. Entropy 2017, 19, 451. https://doi.org/10.3390/e19090451
Pica G, Piasini E, Chicharro D, Panzeri S. Invariant Components of Synergy, Redundancy, and Unique Information among Three Variables. Entropy. 2017; 19(9):451. https://doi.org/10.3390/e19090451
Chicago/Turabian StylePica, Giuseppe, Eugenio Piasini, Daniel Chicharro, and Stefano Panzeri. 2017. "Invariant Components of Synergy, Redundancy, and Unique Information among Three Variables" Entropy 19, no. 9: 451. https://doi.org/10.3390/e19090451
APA StylePica, G., Piasini, E., Chicharro, D., & Panzeri, S. (2017). Invariant Components of Synergy, Redundancy, and Unique Information among Three Variables. Entropy, 19(9), 451. https://doi.org/10.3390/e19090451