1. Introduction
Rate-distortion theory, a branch of information theory that studies models for lossy data compression, was introduced by Claude Shannon in [
1]. The approach of [
1] is to model the information source with distribution
on
, a reconstruction alphabet
, and a distortion measure
. When the information source produces a sequence of
n realizations, the source
is defined on
with reconstruction alphabet
, where
and
are
n-fold Cartesian products of
and
. In that case, [
1] extended the notion of a single-letter distortion measure to the
n-letter distortion measure,
, by taking an arithmetic average of single-letter distortions,
Distortion measures that satisfy (
1) are referred to as
separable (also additive, per-letter, averaging); the separability assumption has been ubiquitous throughout rate-distortion literature ever since its inception in [
1].
On the one hand, the separability assumption is quite natural and allows for a tractable characterization of the fundamental trade-off between the rate of compression and the average distortion. For example, in the case when
is a stationary and memoryless source the rate-distortion function, which captures this trade-off, admits a simple characterization:
On the other hand, the separability assumption is very restrictive as it only models distortion penalties that are
linear functions of the per-letter distortions in the source reproduction. Real-world distortion measures, however, may be highly
non-linear; it is desirable to have a theory that also accommodates non-linear distortion measures. To this end, we propose the following definition:
Definition 1 (f-separable distortion measure).
Let be a continuous, increasing function on . An n-letter distortion measure is -separable with respect to a single-letter distortion if it can be written as
For
this is the classical separable distortion set up. By selecting
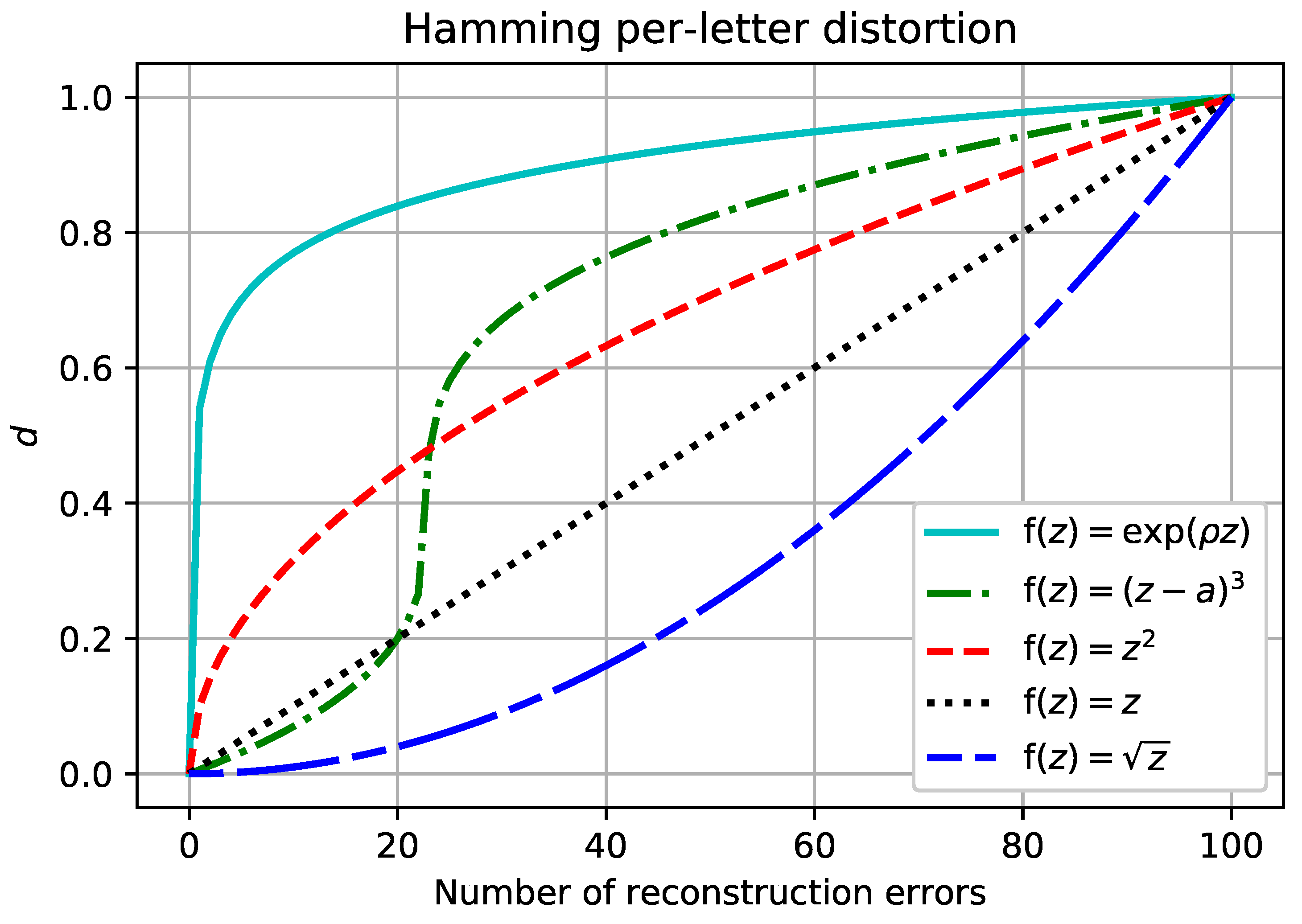
appropriately, it is possible to model a large class of non-linear distortion measures, see
Figure 1 for illustrative examples.
In this work, we characterize the rate-distortion function for stationary and ergodic information sources with
-separable distortion measures. In the special case of memoryless and stationary sources we obtain the following intuitive result:
A pleasing implication of this result is that much of rate-distortion theory (e.g., the Blahut-Arimoto algorithm) developed since [
1] can be leveraged to work under the far more general
-separable assumption.
The rest of this paper is structured as follows. The remainder of
Section 1 overviews related work:
Section 1.1 provides the intuition behind Definition 1,
Section 1.2 reviews related work in other compression problems, and
Section 1.3 connects
-separable distortion measures with sub-additive distortion measures.
Section 2 formally sets up the problem and demonstrates why convexity of the rate-distortion function does not always hold under the
-separable assumption.
Section 3 presents our main result, Theorem 1, as well as some illustrative examples. Additional discussion about problem formulation and sub-additive distortion measures is given in
Section 4. We conclude the paper in
Section 5.
1.1. Generalized -Mean and Rényi Entropy
To understand the intuition behind Definition 1, consider aggregating
n numbers
by defining a sequence of functions (indexed by
n)
where
is a continuous, increasing function on
,
, and
. It is easy to see that (
5) satisfies the following properties:
is continuous and monotonically increasing in each ,
is a symmetric function of each ,
If for all i, then ,
Moreover, it is shown in [
2] that any sequence of functions
that satisfies these properties must have the form of Equation (
5) for some continuous, increasing
. The function
is referred to as “Kolmogorov mean”, “quasi-arithmetic mean”, or “generalized
-mean”. The most prominent examples are the geometric mean,
, and the root-mean-square,
.
The main insight behind Definition 1 is to define an
n-letter distortion measure to be an
-mean of single-letter distortions. The
-separable distortion measures include all
n-letter distortion measures that satisfy the above properties, with the last property saying that the non-linear “shape” of distortion measure (cf.
Figure 1) is independent of
n.
Finally, we note that Rényi also arrived at his well-known family of entropies [
3] by taking an
-mean of the information random variable:
where the information at
x is
Rényi [
3] limited his consideration to functions of the form
in order to ensure that entropy is additive for independent random variables.
1.2. Compression with Non-Linear Cost
Source coding with non-linear cost has already been explored in the variable-length lossless compression setting. Let
denote the length of the encoding of
x by a given variable length code. Campbell [
4,
5] proposed minimizing a cost function of the form
instead of the usual expected length. The main result of [
4,
5] is that for
the fundamental limit of such setup is Rényi entropy of order
. For more general
, this problem was handled by Kieffer [
6], who showed that (
9) has a fundamental limit for a large class of functions
. That limit is Rényi entropy of order
with
More recently, a number of works [
7,
8,
9] studied related source coding paradigms, such as guessing and task encoding. These works also focused on the exponential functions given in (
10); in [
7,
8] Rényi entropy is shown to be a fundamental limit yet again.
1.3. Sub-Additive Distortion Measures
A notable departure from the separability assumption in rate-distortion theory is sub-additive distortion measures discussed in [
10]. Namely, a distortion measure is sub-additive if
In the present setting, an
-separable distortion measure is sub-additive if
is concave:
Thus, the results for sub-additive distortion measures, such as the convexity of the rate-distortion function, are applicable to
-separable distortion measures when
is concave.
2. Preliminaries
Let X be a random variable defined on with distribution , with reconstruction alphabet , and a distortion measure . Let be the message set.
Definition 2 (Lossy source code).
A lossy source code is a pair of mappings, A lossy source-code
is an
-lossy source code on
if
A lossy source code
is an
-lossy source code on
if
Definition 3. An information source is a stochastic process If is an -lossy source code for on , we say is an -lossy source code. Likewise, an -lossy source code for on is an -lossy source code.
2.1. Rate-Distortion Function (Average Distortion)
Definition 4. Let a sequence of distortion measures be given. The rate-distortion pair is achievable if there exists a sequence of -lossy source codes such that Our main object of study is the following rate-distortion function with respect to -separable distortion measures.
Definition 5. Let be a sequence of -separable distortion measures. Then, If is the identity, then we omit the subscript and simply write .
2.2. Rate-Distortion Function (Excess Distortion)
It is useful to consider the rate-distortion function for -separable distortion measures under the excess distortion paradigm.
Definition 6. Let a sequence of distortion measures be given. The rate-distortion pair is (excess distortion) achievable if for any there exists a sequence of -lossy source codes such that Definition 7. Let be a sequence of -separable distortion measures. Then, Characterizing the -separable rate-distortion function is particularly simple under the excess distortion paradigm, as shown in the following lemma.
Lemma 1. Let the single-letter distortion and an increasing, continuous function be given. Then,where is computed with respect to . Proof. Let be a sequence of -separable distortions based on and let be a sequence of separable distortion measures based on .
Since
is increasing and continuous at
d, then for any
there exists
such that
The reverse is also true by continuity of
: for any
there exists
such that (
22) is satisfied.
Any source code
is an
-lossless code under
-separable distortion
if and only if
is also an
-lossless code under separable distortion
. Indeed,
where
. It follows that
is (excess distortion) achievable with respect to
if and only if
is (excess distortion) achievable with respect to
. The lemma statement follows from this observation and Definition 6. ☐
2.3. -Separable Rate-Distortion Functions and Convexity
While it is a well-established result in rate-distortion theory that all separable rate-distortion functions are convex ([
11], Lemma 10.4.1), this need not hold for
-separable rate-distortion functions.
The convexity argument for separable distortion measures is based on the idea of time sharing; that is, suppose there exists an
-lossy source code of blocklength
and an
-lossy source code of blocklength
. Then, there exists an
-lossy source code of blocklength
n with
and
: such a code is just a concatenation of codes over blocklengths
and
. The distortion
d is achievable since
and letting
,
Time sharing between the two schemes gives
However, this bound on the distortion need not hold for
-separable distortions. Consider
which is strictly convex and suppose
We can write
Thus, concatinating the two schemes together does not guarantee that the distortion assigned by the
-separable distortion measure is bounded by
d.
3. Main Result
In this section we make the following standard assumptions, see [
12].
Theorem 1. Under the stated assumptions, the rate-distortion function is given bywhereis the rate-distortion function computed with respect to the separable distortion measure given by . For stationary memoryless sources (34) particularizes to Proof. Equations (
35) and (
36) are widely known in literature (see, for example, [
10,
11,
13]); it remains to show (
34). Under the stated assumptions,
where (a) follows from assumption (2) and Theorem A1 in the
Appendix A, (b) is shown in Lemma 1, and (c) is due to [
14] (see also ([
13], Theorem 5.9.1)). The other direction,
is a consequence of the strong converse by Kieffer [
12], see Lemma A1 in the
Appendix A. ☐
An immediate application of Theorem 1 gives the -separable rate-distortion function for several well-known binary memoryless sources (BMS).
Example 1 (BMS, Hamming distortion).
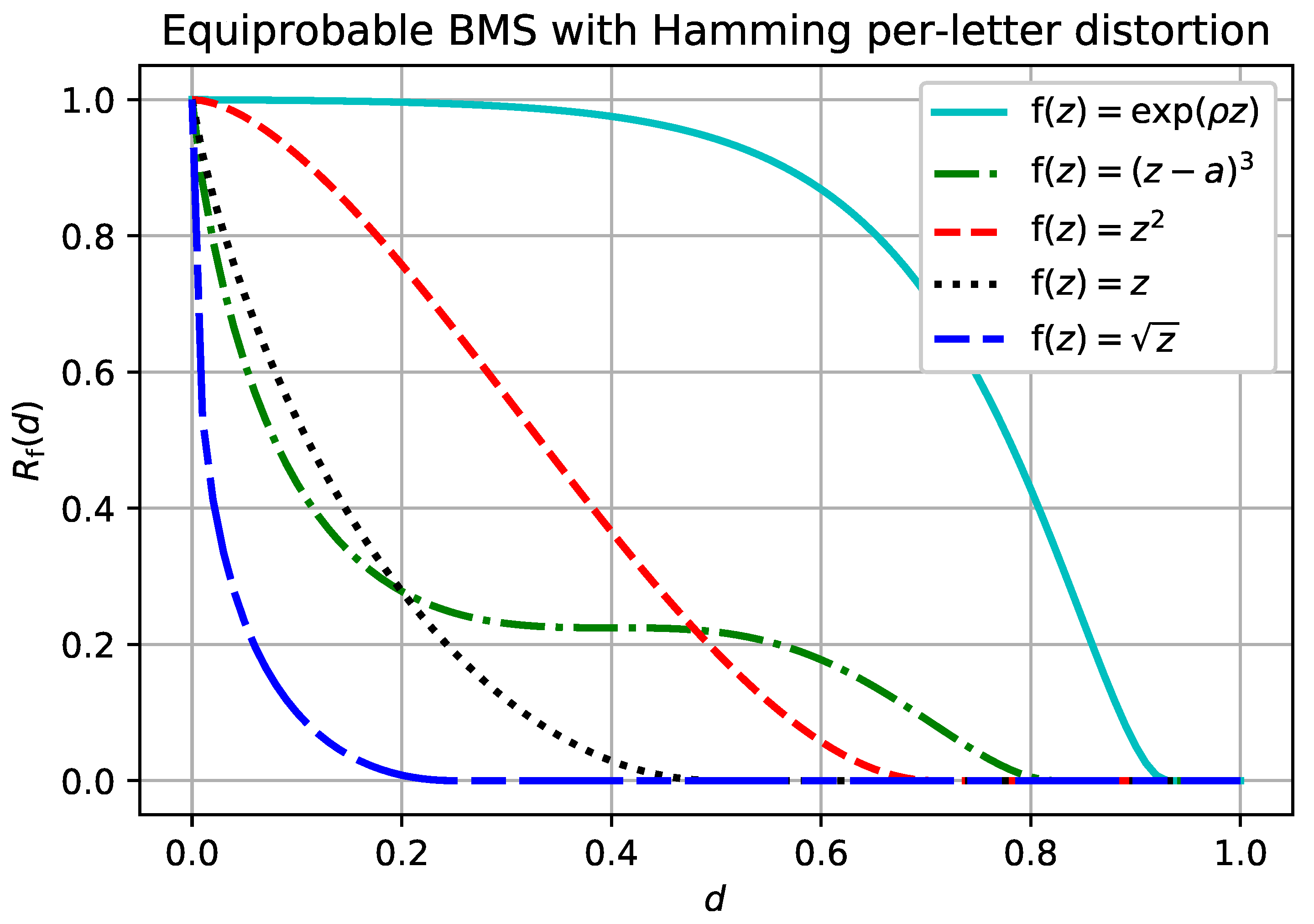
Let be the binary memoryless source. That is, , is a Bernoulli random variable, and is the usual Hamming distortion measure. Then, for any continuous increasing and ,whereis the binary entropy function. The result follows from a series of obvious equalities, The rate-distortion function given in Example 1 is plotted in
Figure 2 for different functions
. The simple derivation in Example 1 could be applied to any source for which the single-letter distortion measure can take on only two values, as is shown in the next example.
Example 2 (BMS, Erasure distortion).
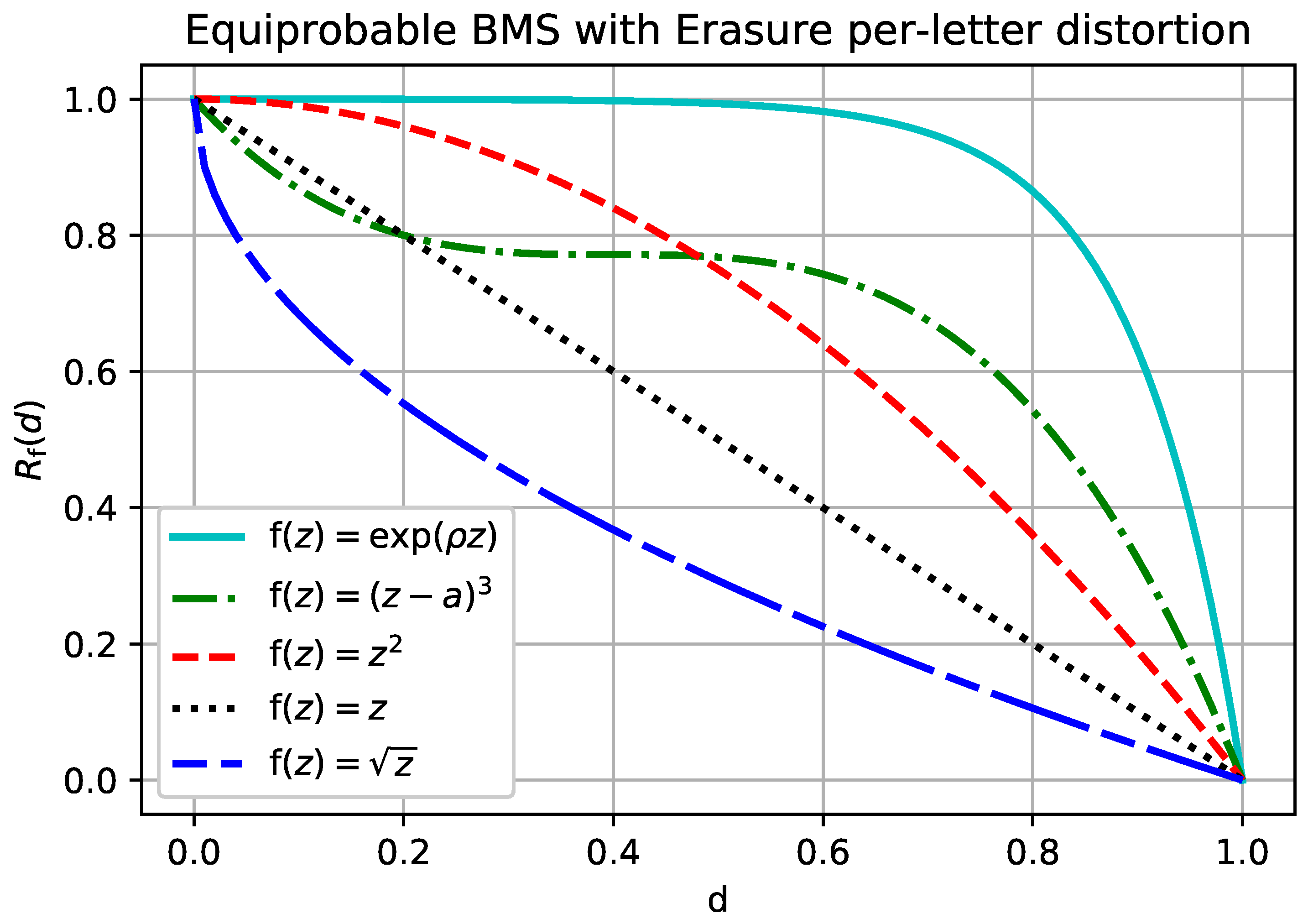
Let be the binary memoryless source and let the reconstruction alphabet have the erasure option. That is, , , and is a Bernoulli random variable. Let be the usual erasure distortion measure: The separable rate-distortion function for the erasure distortion is given bysee ([11], Problem 10.7). Then, for any continuous increasing , The rate-distortion function given in Example 2 is plotted in
Figure 3 for different functions
. Observe that for concave
(i.e., subadditive distortion) the resulting rate-distortion function is convex, which is consistent with [
10]. However, for
that are not concave, the rate-distortion function is not always convex. Unlike in the conventional separable distortion measure, an
-separable distortion measure is not convex in general.
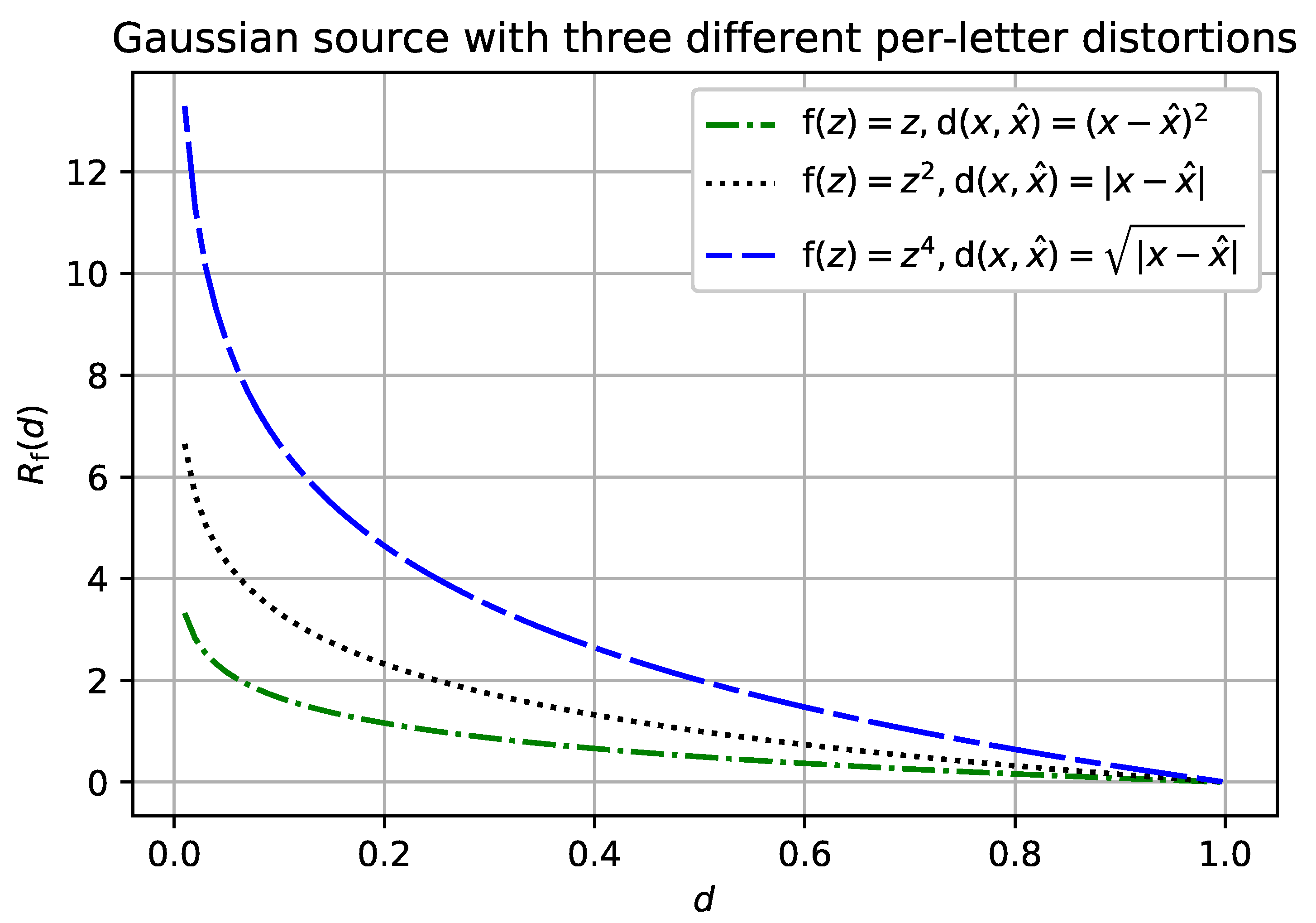
Having a closed-form analytic expression for a separable distortion measure does not always mean that we could easily derive such an expression for an
-separable distortion measure with the same per-letter distortion. For example, consider the Gaussian source with the mean-square-error (MSE) per-letter distortion. According to Theorem 1, letting
recovers the Gaussian source with the absolute value per-letter distortion. This setting, and variations on it, is a difficult problem in general [
15]. However, we can recover the
-separable rate-distortion function whenever the per-letter distortion
composed with
reconstructs the MSE distortion, see
Figure 4.
Theorem 1 shows that for well-behaved stationary ergodic sources, admits a simple characterization. According to Lemma 1, the same characterization holds for the excess distortion paradigm without stationary and ergodic assumptions. The next example shows that, in general, within the average distortion paradigm. Thus, assumption (1) is necessary for Theorem 1 to hold.
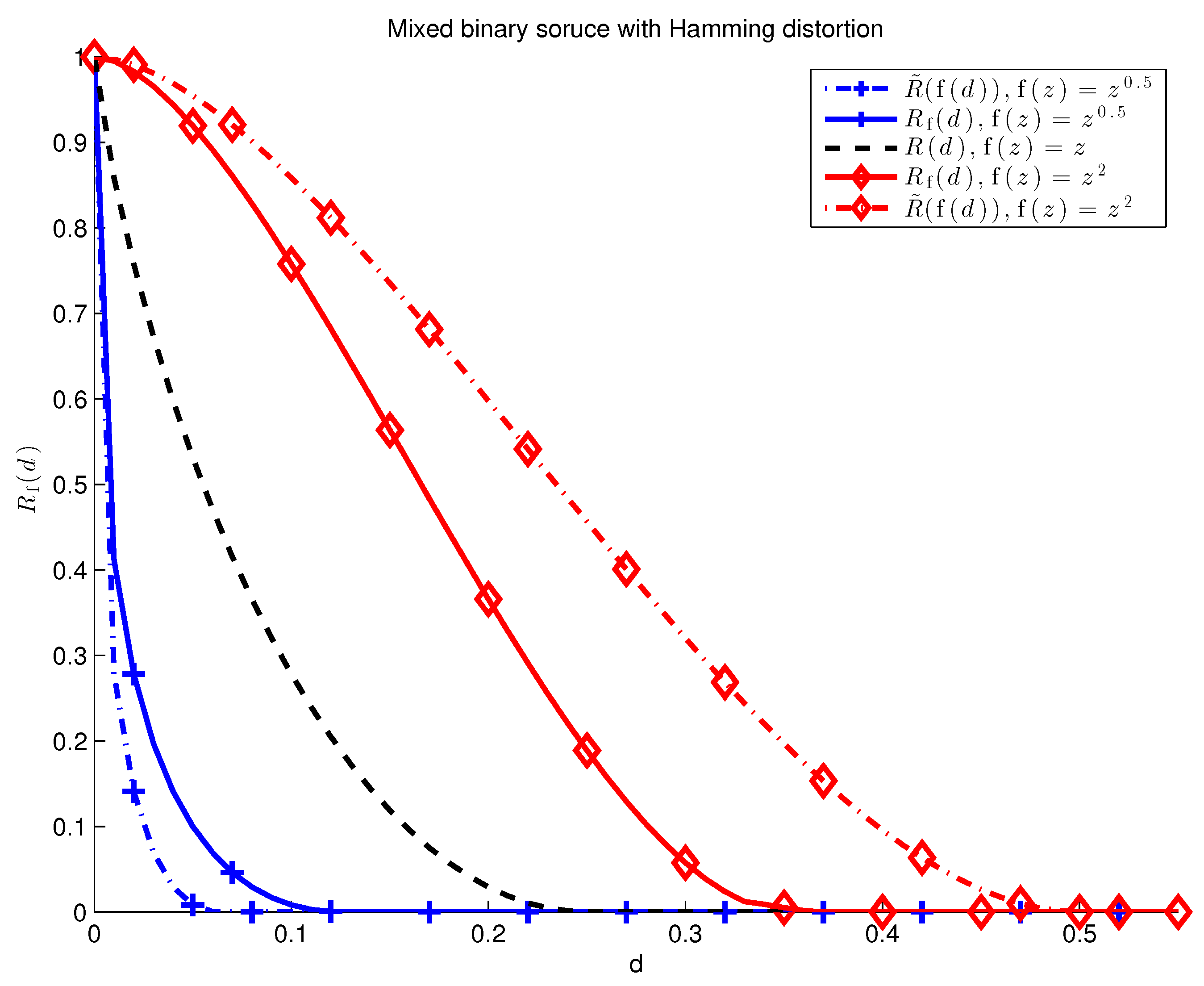
Example 3 (Mixed Source).
Fix and let the source be a mixture of two i.i.d. sources, We can alternatively express aswhere Z is a Bernoulli(λ) random variable. Then, the rate-distortion function for the mixture source (45) and continuous increasing is given in Lemma A2 in the Appendix B. Namely,where and are the rate-distortion functions for discrete memoryless soruces given by and , respectively. Likewise, As shown in Figure 5, Equations (47) and (48) are not equal in general. 4. Discussion
4.1. Sub-Additive Distortion Measures
Recall that an
-separable distortion measure is sub-additive if
is concave (cf.
Section 1.3). Clearly, not all
-separable distortion measures are sub-additive, and not all sub-additive distortion measures are
-separable. An examplar of a sub-additive distortion measure (which is not
-separable) given in ([
10], Chapter 5.2) is
The sub-additivity of (
49) follows from the Minkowski inequality. Comparing (
49) to a sub-additive,
-separable distortion measure given by
we see that the discrepancy between (
49) and (
50) has to do not only with the different ranges of
q but with the scaling factor as a function of
n.
Consider a binary source with Hamming distortion and let
. Rewriting (
49) we obtain
and
In the binary example, the limiting distortion of (
49) is zero even when the reconstruction of
gets every single symbol wrong. It is easy to observe that example (
49) is similarly degenerate in many cases of interest. The distortion measure given by (
50), on the other hand, is an example of a non-trivial sub-additive distortion measure, as can be seen in
Figure 2 and
Figure 3 for
.
4.2. A Consequence of Theorem 1
In light of the discussion in
Section 1.1, an alert reader may consider modifying (
16) to
and studying the
-lossy source codes under this new paradigm. Call the corresponding rate-distortion function
and assume that
n-letter distortion measures are separable. Thus, at block length
n the constraint (
55) is
where
. This is equivalent to the following constraints:
where
is an
-separable distortion measure. Putting these observations together with Theorem 1 yields
A consequence of Theorem 1 is that the rate distortion function remains unchanged under this new paradigm.
5. Conclusions
This paper proposes -separable distortion measures as a good model for non-linear distortion penalties. The rate-distortion function for -separable distortion measures is characterized in terms of separable rate-distortion function with respect to a new single-letter distortion measure, . This characterization is straightforward for the excess distortion paradigm, as seen in Lemma 1. The proof is more involved for the average distortion paradigm, as seen in Theorem 1. An important implication of Theorem 1 is that many prominant results in rate-distortion literature (e.g., Blahut-Arimoto algorithm) can be leveraged to work for -separable distortion measures.
Finally, we mention that a similar generalization is well-suited for channels with non-linear costs. That is, we say that
is an
-separable cost function if it can be written as
With this generalization we can state the following result which is out of the scope of this special issue.
Theorem 2 (Channels with cost).
The capacity of a stationary memoryless channel given by and -separable cost function based on single-letter function is

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




