Modulation Signal Recognition Based on Information Entropy and Ensemble Learning

Abstract
:1. Introduction
2. Theories and Methods
2.1. Entropy Feature Extraction Algorithm
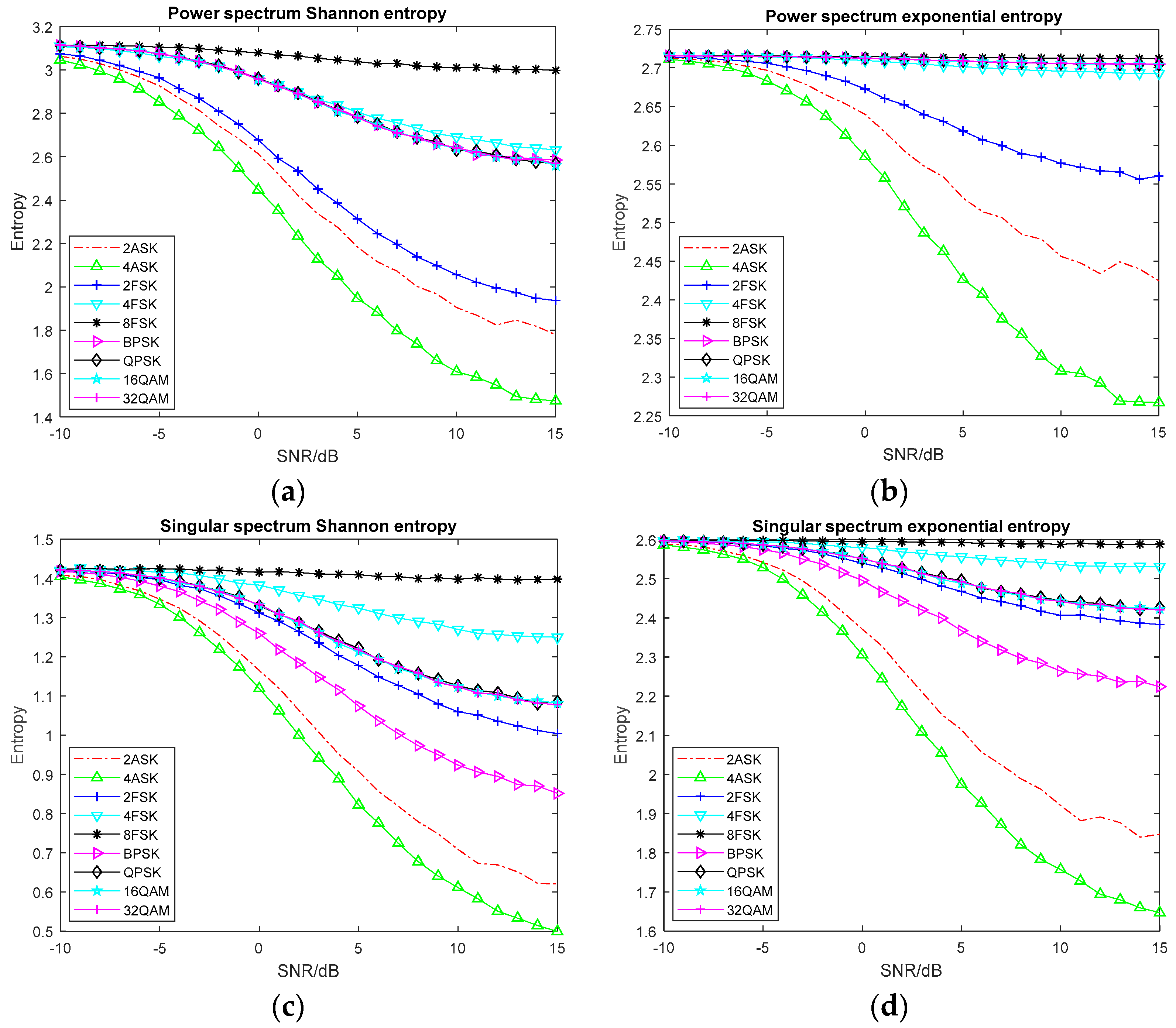
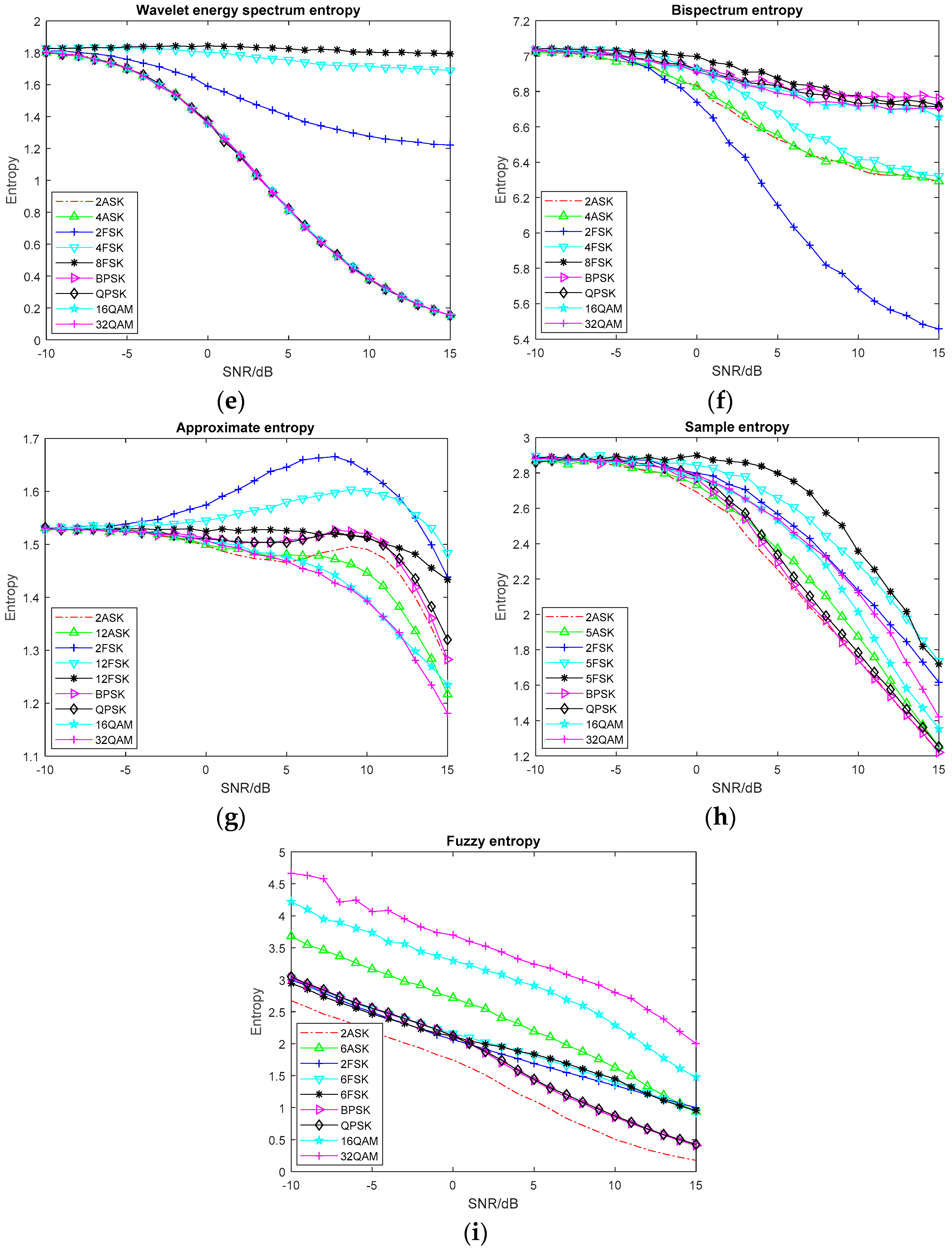
2.1.1. Common Entropy
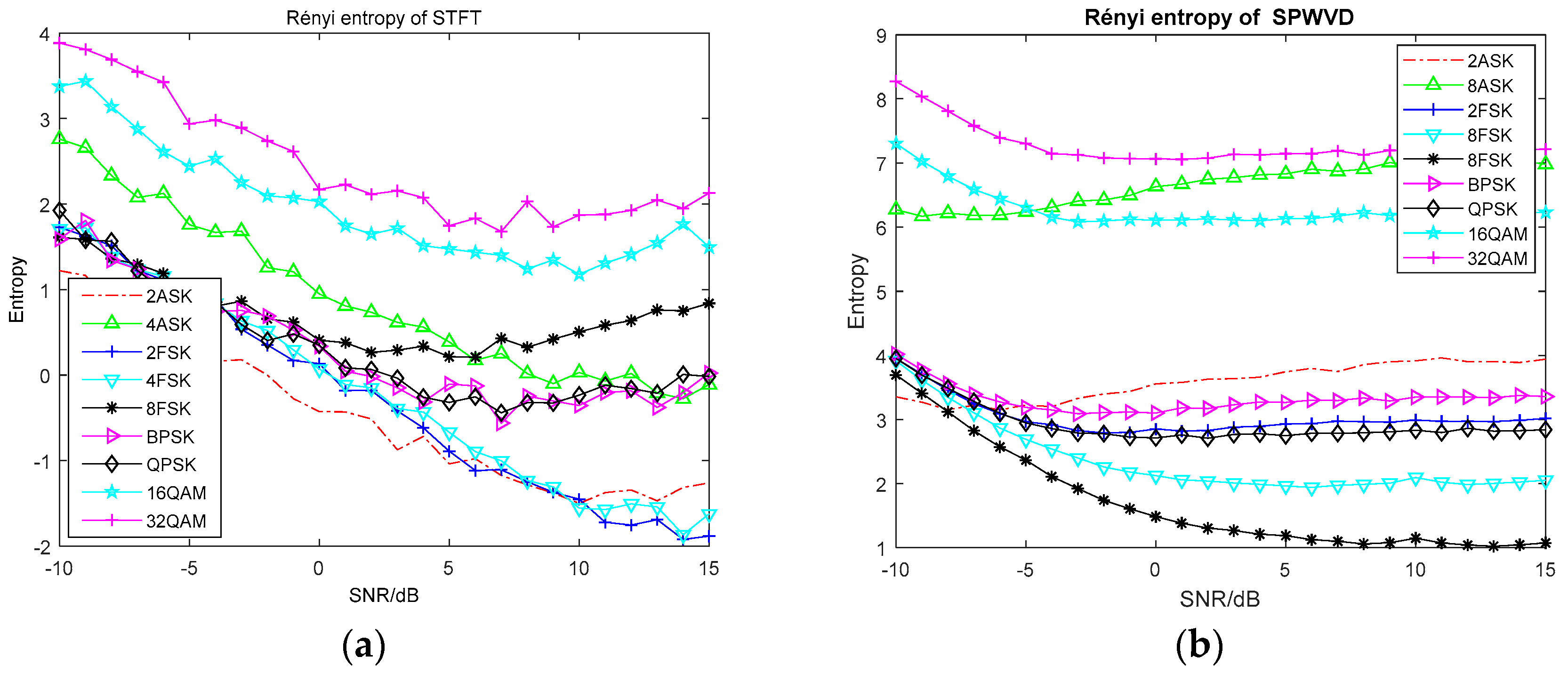
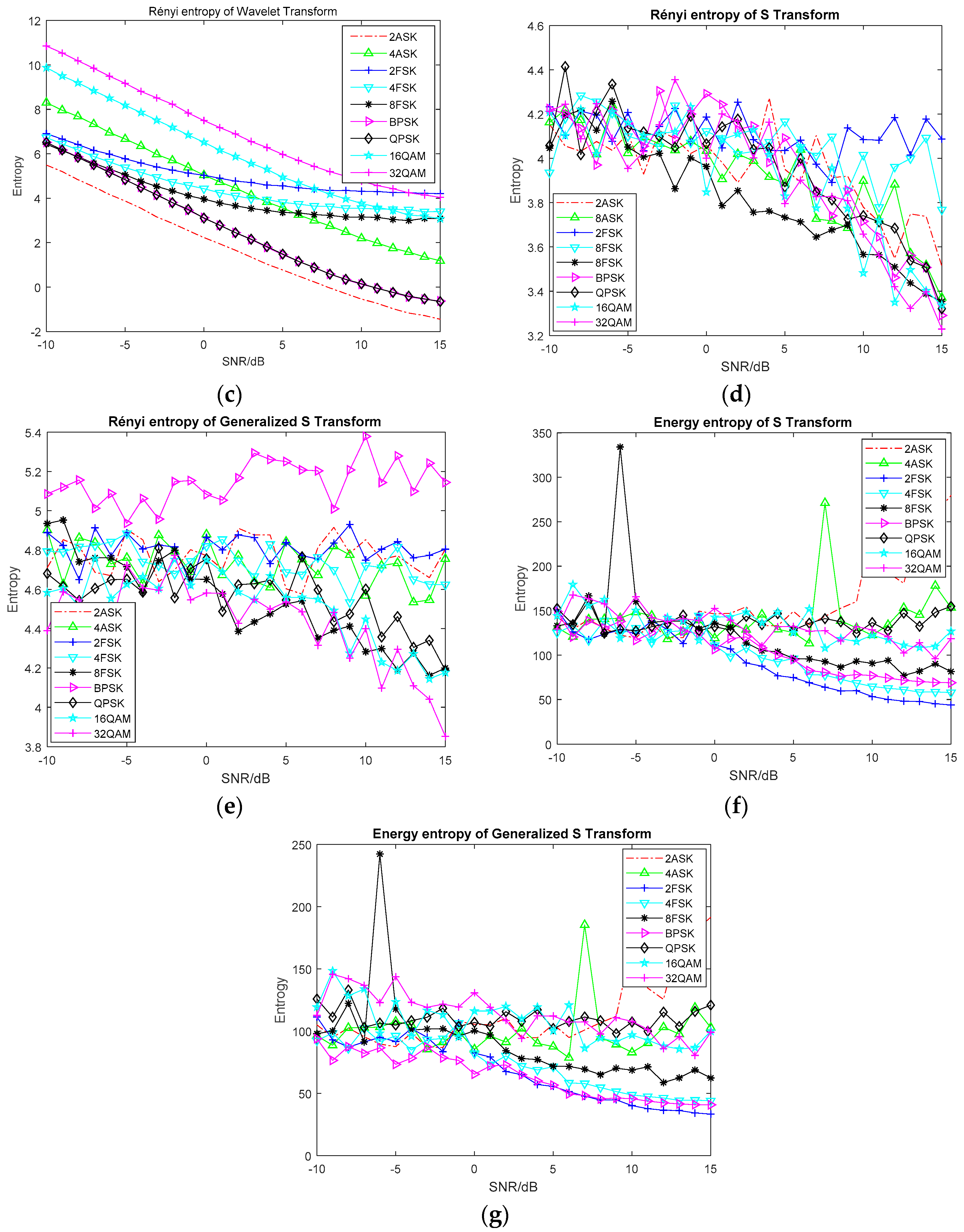
2.1.2. Entropy Based on Time-Frequency Analysis
2.2. Feature Selection Algorithms
2.2.1. Sequence Forward Selection Algorithm
2.2.2. Sequence Forward Floating Selection Algorithm
2.2.3. RELIEF-F Algorithm
2.3. Classifiers
2.3.1. K-Nearest Neighbor Classifier
2.3.2. Support Vector Machine
2.3.3. Adaboost
2.3.4. Gradient Boosting Decision Tree
2.3.5. XGBoost
3. Results and Discussion
3.1. Experimental Data
3.2. Experimental Methodology
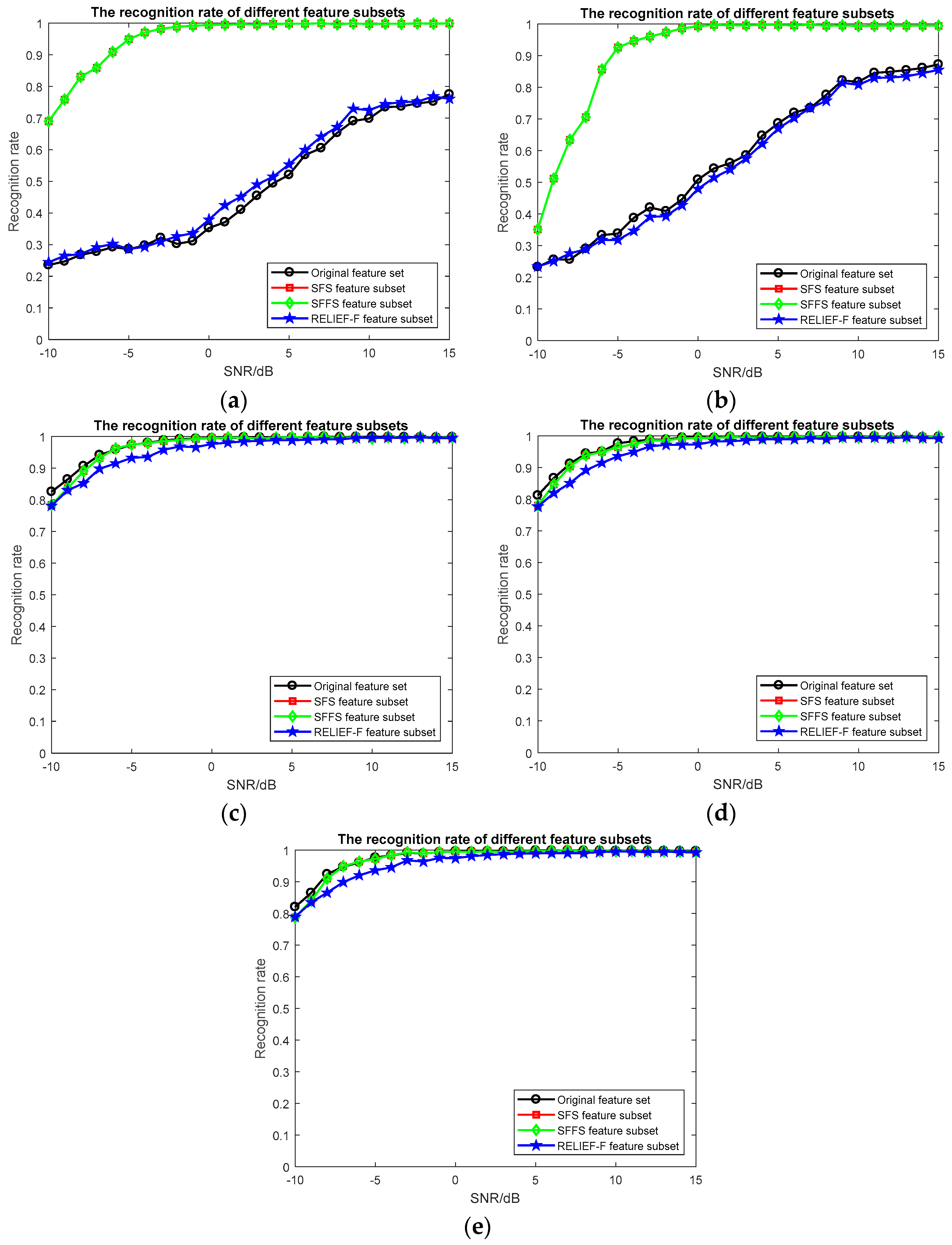
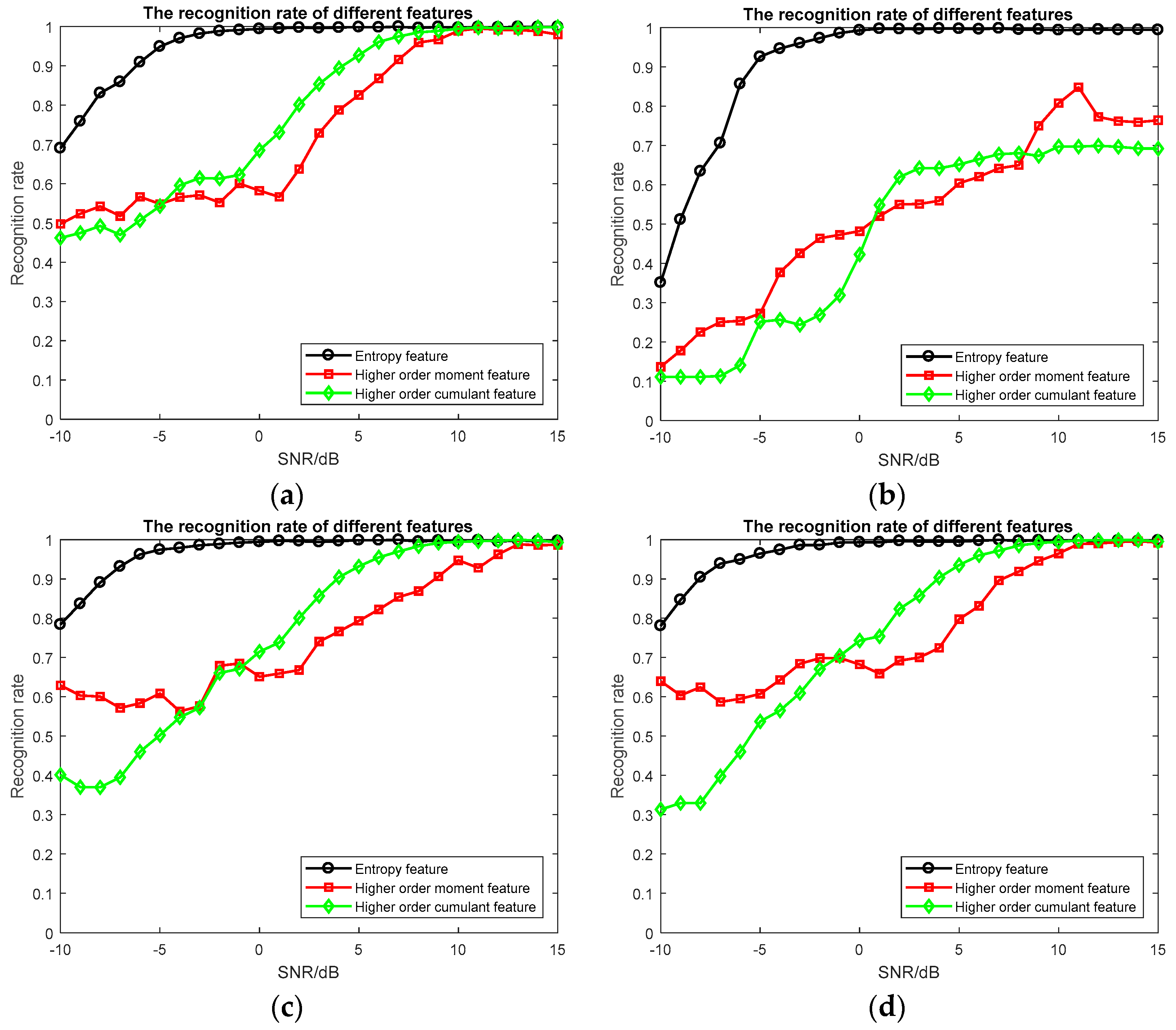
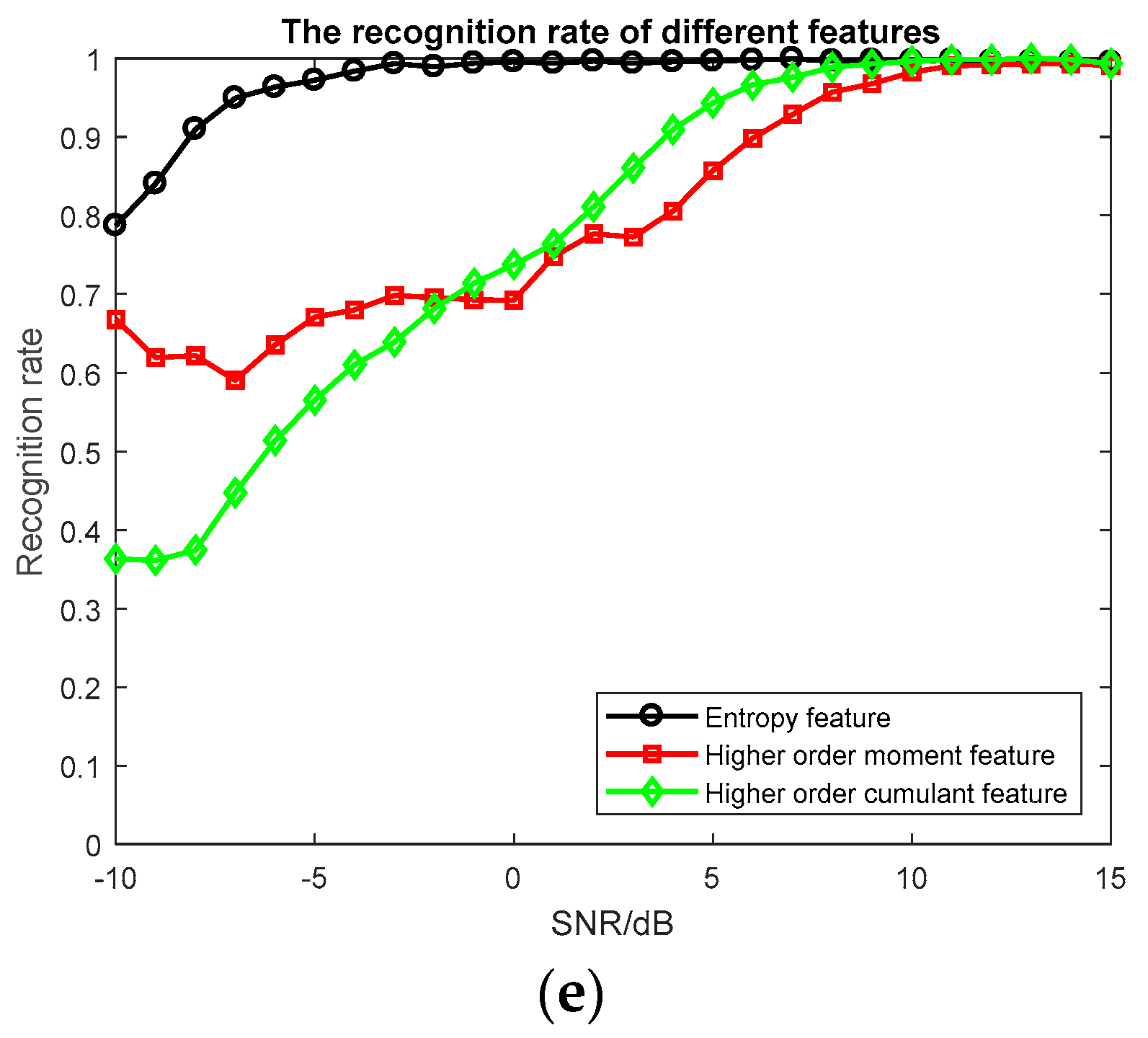
3.3. Experimental Results and Discussion
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yang, Z.; Ping, S.; Sun, H.; Aghvami, A.H. CRB-RPL: A Receiver-based Routing Protocol for Communications in Cognitive Radio Enabled Smart Grid. IEEE Trans. Veh. Technol. 2017, 66, 5985–5994. [Google Scholar] [CrossRef]
- Liu, L.; Cheng, C.; Han, Z. Realization of Radar Warning Receiver Simulation System. Int. J. Control Autom. 2015, 8, 450–463. [Google Scholar]
- Petrov, N.; Jordanov, I.; Roe, J. Identification of radar signals using neural network classifier with low-discrepancy optimization. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation (CEC), Cancun, Mexico, 20–23 June 2013; pp. 2658–2664. [Google Scholar]
- Gulum, T.O.; Pace, P.E.; Cristi, R. Extraction of polyphase radar modulation parameters using a wigner-ville distribution—Radon transform. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 1505–1508. [Google Scholar]
- Thayaparan, T.; Stankovic, L.; Amin, M.; Chen, V.; Cohen, L.; Boashash, B. Editorial Time-frequency approach to radar detection, imaging, and classification. IET Signal Process. 2010, 4, 197–200. [Google Scholar] [CrossRef]
- Zhu, J.; Zhao, Y.; Tang, J. Automatic recognition of radar signals based on time-frequency image character. In Proceedings of the IET International Radar Conference 2013, Xi’an, China, 14–16 April 2013; pp. 1–6. [Google Scholar]
- Wang, S.; Zhang, D.; Bi, D.; Yong, X.; Li, C. Radar emitter signal recognition based on sample entropy and fuzzy entropy. In Sino-Foreign-Interchange Conference on Intelligent Science and Intelligent Data Engineering; Springer: Berlin, Germany, 2011; pp. 637–643. [Google Scholar]
- Sun, J.; Wang, W.; Kou, L.; Lin, Y.; Zhang, L.; Da, Q.; Chen, L. A data authentication scheme for UAV ad hoc network communication. J. Supercomput. 2017. [Google Scholar] [CrossRef]
- Wang, H.; Jingchao, L.I.; Guo, L.; Dou, Z.; Lin, Y.; Zhou, R. Fractal Complexity-Based Feature Extraction Algorithm of Communication Signals. Fractals 2017, 25, 1740008. [Google Scholar] [CrossRef]
- Shi, X.; Zheng, Z.; Zhou, Y.; Jin, H.; He, L.; Liu, B.; Hua, Q.S. Graph Processing on GPUs: A Survey. ACM Comput. Surv. 2017, 50, 1–35. [Google Scholar] [CrossRef]
- Guo, J.; Zhao, N.; Yu, R.; Liu, X.; Leung, V.C. Exploiting Adversarial Jamming Signals for Energy Harvesting in Interference Networks. IEEE Trans. Wirel. Commun. 2017, 16, 1267–1280. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, C.; Wang, J.; Dou, Z. A Novel Dynamic Spectrum Access Framework Based on Reinforcement Learning for Cognitive Radio Sensor Networks. Sensors 2016, 16, 1675. [Google Scholar] [CrossRef] [PubMed]
- Lunden, J.; Terho, L.; Koivunen, V. Waveform Recognition in Pulse Compression Radar Systems. In Proceedings of the IEEE Workshop on Machine Learning for Signal Processing, Mystic, CT, USA, 28 September 2005; pp. 271–276. [Google Scholar]
- Guo, Q.; Nan, P.; Zhang, X.; Zhao, Y.; Wan, J. Recognition of radar emitter signals based on SVD and AF main ridge slice. J. Commun. Netw. 2015, 17, 491–498. [Google Scholar]
- Ma, J.; Huang, G.; Zuo, W.; Wu, X.; Gao, J. Robust radar waveform recognition algorithm based on random projections and sparse classification. IET Radar Sonar Navig. 2014, 8, 290–296. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Chikha, W.B.; Chaoui, S.; Attia, R. Performance of AdaBoost classifier in recognition of superposed modulations for MIMO TWRC with physical-layer network coding. In Proceedings of the 2017 25th International Conference on Software, Telecommunications and Computer Networks, Split, Croatia, 21–23 September 2017; pp. 1–5. [Google Scholar]
- Wang, S.; Li, J.; Wang, Y.; Li, Y. Radar HRRP target recognition based on Gradient Boosting Decision Tree. In Proceedings of the International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Datong, China, 15–17 October 2016; pp. 1013–1017. [Google Scholar]
- Chen, W.; Fu, K.; Zuo, J.; Zheng, X.; Huang, T.; Ren, W. Radar emitter classification for large data set based on weighted-xgboost. IET Radar Sonar Navig. 2017, 11, 1203–1207. [Google Scholar] [CrossRef]
- Liu, T.; Guan, Y.; Lin, Y. Research on modulation recognition with ensemble learning. EURASIP J. Wirel. Commun. Netw. 2017, 2017, 179. [Google Scholar] [CrossRef]
- Yi-Bing, L.I.; Ge, J.; Yun, L. Modulation recognition using entropy features and SVM. Syst. Eng. Electron. 2012, 34, 1691–1695. [Google Scholar]
- Liu, S.; Lu, M.; Liu, G.; Pan, Z. A Novel Distance Matric: Generalized Relative Entropy. Entropy 2017, 19, 269. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, Y.; Li, H.; Teng, W.; Li, Z. Fault feature extraction for gear crack based on bispectral entropy. China Mech. Eng. 2013, 24, 190–194. [Google Scholar]
- Yang, X.; Wang, S.; Zhang, E.; Zhao, Z. Special emitter identification based on difference approximate entropy and EMD. In Proceedings of the 10th National Conference on Signal and Intelligent Information Processing and Applications, Xiangyang, China, 21 Octorber 2016; pp. 541–547. [Google Scholar]
- Richman, J.S.; Lake, D.E.; Moorman, J.R. Sample entropy. Methods Enzymol. 2004, 384, 172–184. [Google Scholar] [PubMed]
- Manis, G.; Aktaruzzaman, M.; Sassi, R. Low Computational Cost for Sample Entropy. Entropy 2018, 20, 61. [Google Scholar] [CrossRef]
- Zhang, X.; Jin, L. Improving of fuzzy entropy based on string variable. J. Jiangsu Univ. 2015, 36, 70–73. [Google Scholar]
- Szmajda, M.; Górecki, K.; Mroczka, J. Gabor Transform, SPWVD, Gabor-Wigner Transform and Wavelet Transform—Tools for Power Quality Monitoring. Metrol. Meas. Syst. 2010, 17, 383–396. [Google Scholar] [CrossRef]
- Stockwell, R.G.; Mansinha, L.; Lowe, R.P. Localization of the complex spectrum: The S transform. IEEE Trans. Signal Process. 1996, 44, 998–1001. [Google Scholar] [CrossRef]
- Adams, M.D.; Kossentini, F.; Ward, R.K. Generalized S transform. IEEE Trans. Signal Process. 2002, 50, 2831–2842. [Google Scholar] [CrossRef]
- Baraniuk, R.G.; Flandrin, P.; Janssen, A.J.E.M.; Michel, O.J. Measuring time-frequency information content using the Renyi entropies. IEEE Trans. Inf. Theory 2001, 47, 1391–1409. [Google Scholar] [CrossRef]
- Zhao, Z.; Wang, S.; Zhang, W.; Xie, Y. Classification of Signal Modulation Types Based on Multi-features Fusion in Impulse Noise Underwater. J. Xiamen Univ. 2017, 56, 416–422. [Google Scholar]
- Whitney, A.W. A Direct Method of Nonparametric Measurement Selection. IEEE Trans. Comput. 1971, 100, 1100–1103. [Google Scholar] [CrossRef]
- Pudil, P.; Kittler, J. Floating search methods in feature selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Liu, Y.; Zheng, Y.F. FS_SFS: A novel feature selection method for support vector machines. Pattern Recognit. 2006, 39, 1333–1345. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhou, Y.; Zhou, T.; Ren, H.; Shi, L. Research on Improved Algorithm Based on the Sequential Floating Forward Selection. Comput. Meas. Control 2017. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Proceedings of the International Workshop on Machine Learning, Aberdeen, Scotland, 1–3 July 1992; Morgan Kaufmann Publishers Inc.: San Mateo, CA, USA, 1992; pp. 249–256. [Google Scholar]
- Kononenko, I. Estimating attributes: Analysis and extensions of RELIEF. In Proceedings of the European Conference on Machine Learning on Machine Learning, Catania, Italy, 6–8 April 1994; Springer: New York, NY, USA, 1994; pp. 171–182. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Athitsos, V.; Alon, J.; Sclaroff, S. Efficient Nearest Neighbor Classification Using a Cascade of Approximate Similarity Measures. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 486–493. [Google Scholar]
- Song, Y.; Huang, J.; Zhou, D.; Zha, H.; Giles, C.L. IKNN: Informative K-Nearest Neighbor Pattern Classification. In Proceedings of the Knowledge Discovery in Databases: Pkdd 2007, European Conference on Principles and Practice of Knowledge Discovery in Databases, Warsaw, Poland, 17–21 September 2007; pp. 248–264. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ding, G.; Wang, J.; Wu, Q.; Yao, Y.D.; Song, F.; Tsiftsis, T.A. Cellular-Base-Station-Assisted Device-to-Device Communications in TV White Space. IEEE J. Sel. Areas Commun. 2015, 34, 107–121. [Google Scholar] [CrossRef]
- Lin, Y.; Zhu, X.; Zheng, Z.; Dou, Z.; Zhou, R. The individual identification method of wireless device based on dimensionality reduction and machine learning. J. Supercomput. 2017. [Google Scholar] [CrossRef]
- Liu, L.; Shen, B.; Wang, X. Research on Kernel Function of Support Vector Machine. In Advanced Technologies, Embedded and Multimedia for Human-Centric Computing; Springer: Dordrecht, The Netherlands, 2014; pp. 827–834. [Google Scholar]
- Freund, Y.; Schapire, R.E. A desicion-theoretic generalization of on-line learning and an application to boosting. In Computational Learning Theory; Springer: Berlin/Heidelberg, Germany, 1995; pp. 119–139. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference on International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; Morgan Kaufmann Publishers Inc.: San Mateo, CA, USA, 1996; pp. 148–156. [Google Scholar]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entropy | Time |
|---|---|
| Power spectrum Shannon entropy | 0.199 |
| Power spectrum exponential entropy | 0.210 |
| Singular spectrum Shannon entropy | 0.205 |
| Singular spectrum exponential entropy | 0.204 |
| Wavelet energy spectrum entropy | 0.558 |
| Bispectrum entropy | 2.414 |
| Approximate entropy | 683.003 |
| Sample entropy | 396.102 |
| Fuzzy entropy | 428.461 |
| Rényi entropy of STFT | 162.988 |
| Rényi entropy of SPWVD | 156.508 |
| Rényi entropy of Wavelet Transform | 166.227 |
| Rényi entropy of S Transform | 10.224 |
| Rényi entropy of Generalized S Transform | 9.986 |
| Energy entropy of S Transform | 7.043 |
| Energy entropy of Generalized S Transform | 6.974 |
| Algorithm | No | SFS | SFFS | RELIEF-F |
|---|---|---|---|---|
| Features | 16 | 7 | 7 | 6 |
| Algorithm | NO | SFS/SFFS | RELIEF-F |
|---|---|---|---|
| KNN | 47.76% | 95.71% | 49.53% |
| SVM | 57.93% | 91.48% | 56.39% |
| Adaboost | 97.63% | 97.19% | 95.70% |
| GBDT | 97.59% | 97.16% | 95.70% |
| XGBoost | 97.74% | 97.40% | 95.91% |
| Algorithm | Time |
|---|---|
| SFS | 465.909 |
| SFFS | 735.793 |
| RELIEF-F | 3.467 |
| Algorithm | NO | SFS/SFFS | RELIEF-F |
|---|---|---|---|
| KNN | 5.179 | 2.075 | 1.856 |
| SVM | 2352.019 | 124.972 | 2495.665 |
| Adaboost | 11.544 | 5.507 | 4.914 |
| GBDT | 36.644 | 18.049 | 17.659 |
| XGBoost | 13.276 | 7.784 | 6.973 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Li, Y.; Jin, S.; Zhang, Z.; Wang, H.; Qi, L.; Zhou, R. Modulation Signal Recognition Based on Information Entropy and Ensemble Learning. Entropy 2018, 20, 198. https://doi.org/10.3390/e20030198
Zhang Z, Li Y, Jin S, Zhang Z, Wang H, Qi L, Zhou R. Modulation Signal Recognition Based on Information Entropy and Ensemble Learning. Entropy. 2018; 20(3):198. https://doi.org/10.3390/e20030198
Chicago/Turabian StyleZhang, Zhen, Yibing Li, Shanshan Jin, Zhaoyue Zhang, Hui Wang, Lin Qi, and Ruolin Zhou. 2018. "Modulation Signal Recognition Based on Information Entropy and Ensemble Learning" Entropy 20, no. 3: 198. https://doi.org/10.3390/e20030198
APA StyleZhang, Z., Li, Y., Jin, S., Zhang, Z., Wang, H., Qi, L., & Zhou, R. (2018). Modulation Signal Recognition Based on Information Entropy and Ensemble Learning. Entropy, 20(3), 198. https://doi.org/10.3390/e20030198