1. Introduction and Overview
Whatever else it may be, Quantum mechanics (QM) is a machine for making probabilistic predictions about the results of measurements. To this extent, QM is, at least in part, about information. Over the last decade or so, it has become clear that the formal apparatus of quantum theory, at least in finite dimensions, can be recovered from constraints on how physical systems store and process information. To this extent, finite-dimensional QM is just about information.
The broad idea of regarding QM in this way, and of attempting to derive its mathematical structure from simple operational or probabilistic axioms, is not new. Efforts in this direction go back at least to the work of von Neumann [
1], and include also attempts by Schwinger [
2], Mackey [
3], Ludwig [
4], Piron [
5], and many others. However, the consensus is that these were not entirely successful: partly because the results they achieved (e.g., Piron’s well-known representation theorem) did not rule out certain rather exotic alternatives to QM, but mostly because the axioms deployed seem, in retrospect, to lack sufficient physical or operational motivation.
More recently, with inspiration from quantum information theory, attention has focused on finite-dimensional systems, where the going is a bit easier. Just as importantly, quantum information theory prompts us to treat properties of composite systems as fundamental, where earlier work focused largely on systems in isolation (a recent exception to this trend is the paper [
6] of Barnum, Müller and Ududec). These shifts of emphasis are illustrated by the work of Hardy [
7], who presented five simple, broadly information-theoretic postulates governing the states and measurements associated with a physical system, determining a very restricted set of possible theories, parametrized by a positive integer
r, with finite-dimensional quantum and classical probability theory corresponding to
and
. Following this lead, several papers, notably [
8,
9,
10], have derived finite-dimensional QM from various packages of axioms governing the information-carrying and information-processing capacity of finite-dimensional systems.
Problems with existing approaches. These recent reconstructive efforts suffer from two related problems. First, they make use of assumptions that seem too strong. Secondly, in trying to derive exactly complex, finite-dimensional quantum theory, they derive too much.
All of the cited papers assume local tomography. This is the doctrine that the state of a bipartite composite system is entirely determined by the joint probabilities it assigns to outcomes of measurements on the two subsystems. This rules out both real and quaternionic QM, both of which are legitimate quantum theories [
11].
These papers also all make some version of a uniformity assumption: that all systems having the same information-carrying capacity are isomorphic, or that all systems are composed, in a uniform way, from “bits” of a uniform type. Here, “information carrying capacity” means essentially the maximum number of states that can be distinguished from one another with probability one by a single measurement. A bit is a system for which this number is two. This rules out systems involving superselection rules, i.e., those that admit both real and classical degrees of freedom (for example, the quantum system corresponding to , corresponding to a classical choice between one of two qubits, has the same information-carrying capacity as a single, four-level quantum system). More seriously, it rules out any theory that includes, e.g., real and complex, or real and quaternionic systems, as the state spaces of the bits of these theories have different dimensions. As I will discuss below, one can indeed construct mathematically-reasonable theories that embrace finite-dimensional quantum systems of all three types.
Another shortcoming, not related to the exclusion of real and quaternionic QM, is the technical assumption (explicit in [
10] for bits) that all positive affine functionals on the state space taking values between zero and one correspond to physically-accessible “effects”, i.e., possible measurement results. From an operational point of view, this principle (called the “no-restriction hypothesis” in [
12]) seems to call for further motivation.
Another approach. In these notes, I am going to describe an alternative approach that avoids these difficulties. This begins by associating with every physical system a convex set of states and a distinguished set of basic measurements (or experiments) that can be made on the system. We then isolate two striking features shared by classical and quantum probabilistic systems. The first is the possibility of finding a joint state that perfectly correlates a system A with an isomorphic system (call it a conjugate system) in the sense that every basic measurement on A is perfectly correlated with the corresponding measurement on . In finite-dimensional QM, where A is represented by a finite-dimensional Hilbert space , , corresponds to the conjugate Hilbert space , and the perfectly-correlating state is the maximally-entangled “EPR” state on .
The second feature is the existence of what I call filters associated with each basic measurement. These are processes that independently attenuate the “response” of each outcome of the measurement by some specified factor. Such a process will generally not preserve the normalization of states, but up to a constant factor, in both classical and quantum theory, one can prepare any desired state by applying a suitable filter to the maximally-mixed state. Moreover, when the target state is not singular (that is, when it does not assign probability zero to any nonzero measurement outcome), one can reverse the filtering process, in the sense that it can be undone by another process with positive probability.
The upshot is that all probabilistic systems having conjugates and a sufficiently lavish supply of (probabilistically) reversible filters can be represented by formally real Jordan algebras, a class of structures that includes real, complex and quaternionic quantum systems, and just two further well-studied additional possibilities, which I will review below.
In addition to leaving room for real and quaternionic quantum mechanics (which I take to be a virtue), this approach has another advantage: it is much easier! The assumptions involved are few and easily stated, and the proof of the main technical result (Lemma 1 in
Section 4) is short and straightforward. By contrast, the mathematical developments in the papers listed above are significantly more difficult and ultimately lean on the (even more difficult) classification of compact groups acting on spheres. My approach, too, leans on a received result, but one that is relatively accessible. This is the Koecher–Vinberg theorem, which characterizes formally real, or Euclidean, Jordan algebras in terms of ordered real vector spaces with homogeneous, self-dual cones. A short and non-taxing proof of this classical result can be found in [
13].
These ideas were developed in [
14,
15,
16] and especially [
17], of which this paper is, to an extent, a summary. However, the presentation here is slightly different, and some additional ideas are also explored. In particular, I have spelled out in more detail the connection between conjugate systems and measurement records, only alluded to in the earlier paper. I also link this approach to the categorical approach to quantum theory due to Abramsky, Coecke and others [
18], along the way briefly discussing recent work with Howard Barnum and Matthew Graydon [
19] on the construction of probabilistic theories in which real, complex and quaternionic quantum systems coexist. Finally,
Appendix B presents a uniqueness result for spectral decompositions of states, which may find further application.
A bit of background. At this point, I had better pause to explain some terms. A Jordan algebra is a real commutative algebra (a real vector space with a commutative bilinear multiplication ) having a multiplicative unit u and satisfying the Jordan identity: , for all , where . A Jordan algebra is formally real if sums of squares of nonzero elements are always nonzero. The basic, and motivating, example is the space of self-adjoint operators on a complex Hilbert space, with the Jordan product given by . Note that here, , so the notation is unambiguous. To see that is formally real, just note that is always a positive operator.
If
is finite dimensional,
carries a natural inner product, namely
. This plays well with the Jordan product:
for all
. More generally, a finite-dimensional Jordan algebra equipped with an inner product having this property is said to be
Euclidean. For finite-dimensional Jordan algebras, being formally real and being Euclidean are equivalent [
13]. In what follows, I will abbreviate “Euclidean Jordan algebra” to EJA.
Jordan algebras were originally proposed, with what now looks like slightly thin motivation, by P. Jordan [
20]: if
a and
b are quantum-mechanical observables, represented by
, then while
is again self-adjoint,
and
are not, unless
a and
b commute; however, their average,
, is self-adjoint and, thus, represents another observable. Almost immediately, Jordan, von Neumann and Wigner showed [
21] that all formally real Jordan algebras are direct sums of simple such algebras, with the latter falling into just five classes, parametrized by positive integers
n: the self-adjoint parts,
, of matrix algebras
, where
or
(the quaternions) or, for
, over
(the octonions); and also what are called spin factors
(closely related to Clifford algebras). There is some overlap:
and
. In all but one case, one can show that a simple Jordan algebra is a Jordan subalgebra of
for suitable
n. The exceptional Jordan algebra,
, admits no such representation.
Besides this classification theorem, there is only one other important fact about Euclidean Jordan algebras that is needed for what follows. This is the Koecher–Vinberg (KV) theorem alluded to above. Recall that an ordered vector space is a real vector space, call it , spanned by a distinguished convex cone having its vertex at the origin. Such a cone induces a translation-invariant partial order on , namely iff . As an example, the space is ordered by the cone of positive operators. More generally, any EJA is an ordered vector space, with positive cone . This cone has two special features: first, it is homogeneous, i.e., for any points in the interior of , there exists an automorphism of the cone (a linear isomorphism , taking onto itself) that maps a to b. In other words, the group of automorphisms of the cone acts transitively on the cone’s interior. The other special property is that is self-dual. This means that carries an inner product (in fact, the given one making Euclidean) such that iff for all .
An
order unit in an ordered vector space
is an element
such that, for all
, there exists some
with
. In finite dimensions, this is equivalent to
u’s belonging to the interior of the cone
[
22]. In the following, by a Euclidean order unit space, I mean an ordered vector space
equipped with an inner product
with
for all
, and a distinguished order-unit
u. I will say that such a space
is HSD iff
is homogeneous, and also self-dual with respect to the given inner product.
Theorem 1 (Koecher 1958; Vinberg 1961).
Let be a finite-dimensional euclidean order-unit space. If is HSD, then there exists a unique product with respect to which (with its given inner product) is a euclidean Jordan algebra, u is the Jordan unit, and is the cone of squares.
It seems, then, that if we can motivate a representation of physical systems in terms of HSD order-unit spaces, we will have “reconstructed” what with a little license we might call finite-dimensional Jordan-quantum mechanics. In view of the classification theorem glossed above, this gets us into the neighborhood of orthodox QM, but still leaves open the possibility of taking real and quaternionic quantum systems seriously. (It also leaves the door open to two possibly unwanted guests, namely spin factors and the exceptional Jordan algebra. I will discuss below some constraints that at least bar the latter.)
Some notational conventions. My notation is mostly consistent with the following conventions (more standard in the mathematics than the physics literature, but in places slightly excentric relative to either). Capital Roman letters serve as labels for systems. stands for the set of matrices over or ; is the set of self-adjoint such matrices. Vectors in a Hilbert space are denoted by little Roman letters from the end of the alphabet. Operators on will usually be denoted by little Roman letters from the beginning of the alphabet. Roman letters typically stand for real numbers. The space of all linear operators on is denoted ; as already indicated above, is the (real) vector space of self-adjoint operators on .
As above, the conjugate Hilbert space is denoted . I will write for the vectors in corresponding to . From a certain point of view, this is the same vector; the bar serves to remind us that for scalars . Alternatively, one can regard as the space of “bra” vectors corresponding to the “kets” in , i.e., as the dual space of .
The inner product of is written as and is linear in the first argument (if you like: in Dirac notation). The inner product on is then . The rank-one projection operator associated with a unit vector is . Thus, . I denote functionals on by little Greek letters, e.g., , and operators on by capital Greek letters, e.g., . Two exceptions to this scheme: a generic density operator on is denoted by the capital Roman letter W, and a certain special unit vector in is denoted by the capital Greek letter . With luck, context will help keep things straight.
2. Homogeneity and Self-Duality in Quantum Theory
Why should a probabilistic physical system be represented by a Euclidean order-unit space that is either homogeneous or self-dual? One place to start hunting for an answer might be to look at standard quantum probability theory, to see if we can isolate, in operational or probabilistic terms, what makes this self-dual and homogeneous.
Correlation and self-duality. Let be a finite-dimensional complex Hilbert space, representing some finite-dimensional quantum system. The system’s states are represented by density operators, i.e., positive trace-one operators ; possible measurement-outcomes are represented by effects, i.e., positive operators with . The Born rule specifies the probability of observing effect a in state W as . If W is a pure state, i.e., where v is a unit vector in , then ; by the same token, if , then .
For , let . This is an inner product. By the spectral theorem, for all iff for all unit vectors x. However, . So for all iff , i.e., the trace inner product is self-dualizing. However, this now leaves us with the following:
Question: What does the trace inner product represent, oprationally or probabilistically?
Let
be the conjugate Hilbert space to
. Suppose
has dimension
n. Any unit vector
in
gives rise to a joint probability assignment to effects
a on
and
on
, namely
. Consider the EPR state for
defined by the unit vector:
where
E is any orthonormal basis for
. A straightforward computation shows that the joint probability of observing
a and
b in the state
is:
In other words, the normalized trace inner product just is the joint probability function determined by the pure state vector !
As a consequence, the state represented by has a very strong correlational property: if are two orthogonal unit vectors with corresponding rank-one projections and , we have , so . On the other hand, . Hence, perfectly, and uniformly, correlates every basic measurement (orthonormal basis) of with its counterpart in .
Filters and homogeneity. Next, let us see why the cone is homogeneous. Recall that this means that any state in the interior of the cone (here, any non-singular density operator) can be obtained from any other by an automorphism of the cone. However, in fact, something better is true: this order-automorphism can be chosen to represent a probabilistically-reversible physical process, i.e., an invertible CP mapping with a CP inverse.
To see how this works, suppose
W is a positive operator on
. Consider the pure CP mapping
given by:
Then, . If W is nonsingular, so is , so is invertible, with inverse , again a pure CP mapping. Now, given another nonsingular density operator M, we can get from W to M by applying .
All well and good, but we are still left with the following:
Question: What does the mapping represent, physically?
To answer this, suppose
W is a density operator, with spectral expansion
. Here,
E is an orthonormal basis for
diagonalizing
W, and
is the eigenvalue of
W corresponding to
. Then, for each vector
,
where
is the projection operator associated with
x. We can understand this to mean that
acts as a filter on the test
E: the response of each outcome
is attenuated by a factor
(my usage here is slightly non-standard, in that I allow filters that “pass” the system with a probability strictly between zero and one). Thus, if
M is another density operator on
, representing some state of the corresponding system, then the probability of obtaining outcome
x after preparing the system in state
M and applying the process
is
times the probability of
x in state
M. In detail: suppose
is the rank-one projection operator associated with
x, and note that
. Thus,
If we think of the basis
E as representing a set of alternative channels plus detectors, as in the figure below, we can add a classical filter attenuating the response of one of the detectors (say,
x) by a fraction
. What the computation above tells us is that we can achieve the same result by applying a suitable CP map to the system’s state. Moreover, this can be done independently for each outcome of
E. In
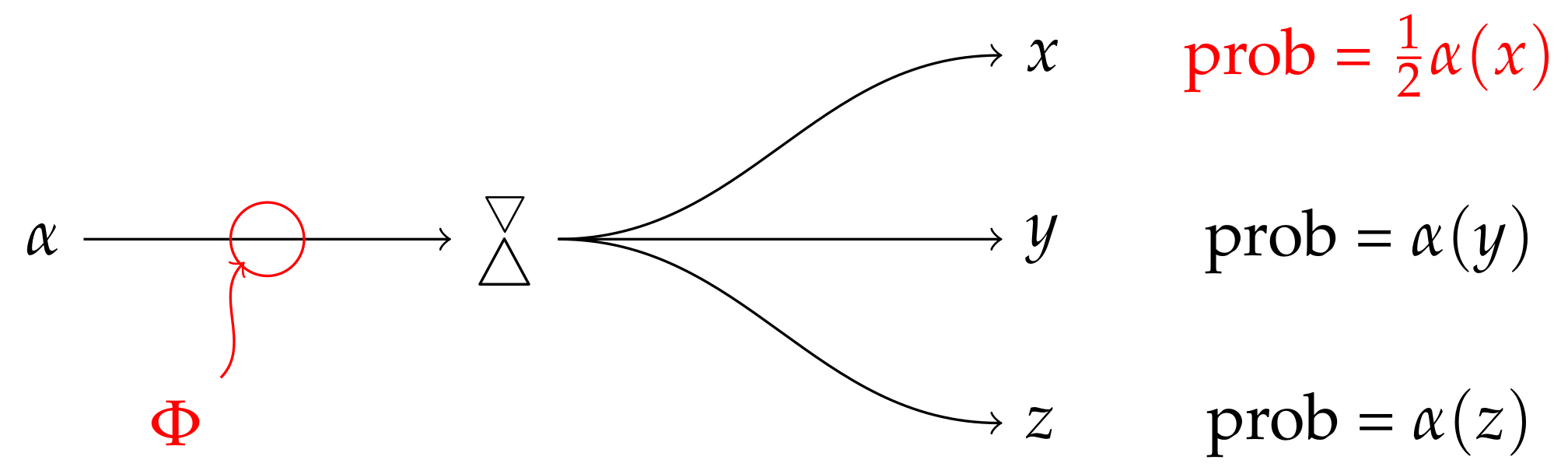
Figure 1, this is illustrated for a three-level quantum system:
is an orthonormal basis, representing three possible outcomes of a Stern–Gerlach-like experiment; the filter
acts on the system’s state in such a way that the probability of outcome
x is attenuated by a factor of
, while outcomes
y and
z are unaffected. Returning to the general situation, if we apply a filter
to the maximally-mixed state
, we obtain
. Thus, we can prepare
W, up to normalization, by applying the filter
to the maximally mixed state.
Filters are symmetric. Here is a final observation, linking these last two: the filter
is symmetric with respect to the uniformly-correlating “EPR” state
, in the sense that:
for all effects
. Remarkably, this is all that is needed to recover the Jordan structure of finite-dimensional quantum theory: the existence of a conjugate system, with a uniformly-correlating joint state, plus the possibility of preparing non-singular states by means of filters that are symmetric with respect to this state, and doing so reversibly when the state is nonsingular.
In a very rough outline, the argument is that states preparable (up to normalization) by symmetric filters have spectral decompositions, and the existence of spectral decompositions makes the uniformly-correlating joint state a self-dualizing inner product. However, to spell this out in a precise way, I need a general mathematical framework for discussing states, effects and processes in abstraction from quantum theory. The next section reviews the necessary apparatus.
3. General Probabilistic Theories
A characteristic feature of quantum mechanics is the existence of incompatible, or non-comeasurable, observables. This suggests the following simple, but very fruitful, notion:
Definition 1. A test space is a collection of non-empty sets , each representing the outcome-set of some measurement, experiment, or test. At the outset, one makes no special assumptions about the combinatorial structure of . In particular, distinct tests are permitted to overlap. Let denote the set of all outcomes of all tests in : a probability weight on is a function such that for every .
Test spaces were introduced and studied by D. J. Foulis and C. H. Randall in a long series of papers beginning around 1970. The original term for a test was an operation, which has the advantage of signaling that the concept has wider applicability than simply reading a number off a meter: anything an agent can do that leads to a well-defined, exhaustive set of mutually-exclusive outcomes defines an operation. Accordingly, test spaces were originally called “manuals of operations”.
It can happen that a test space admits no probability weights at all. However, to serve as a model of a real family of experiments associated with an actual physical system, a test space should obviously carry a lavish supply of such weights. One might want to single out some of these as describing physically (or otherwise) possible states of the system. This suggests the following:
Definition 2. A probabilistic model is a pair , where is a test space and Ω is some designated convex set of probability weights, called the states of the model.
The definition is deliberately spare. Nothing prohibits us from adding further structure (a group of symmetries, say, or a topology on the space of outcomes). However, no such additional structure is needed for the results I will discuss below. I will write and for the test space, associated outcome space and state space of a model A. The convexity assumption on is intended to capture the possibility of forming mixtures of states. To allow the modest idealization of taking outcome-wise limits of states to be states, I will also assume that is closed as a subset of (in its product topology). This makes compact and, so, guarantees the existence of pure states, that is, extreme points of . If is the set of all probability weights on , I will say that A has a full state space.
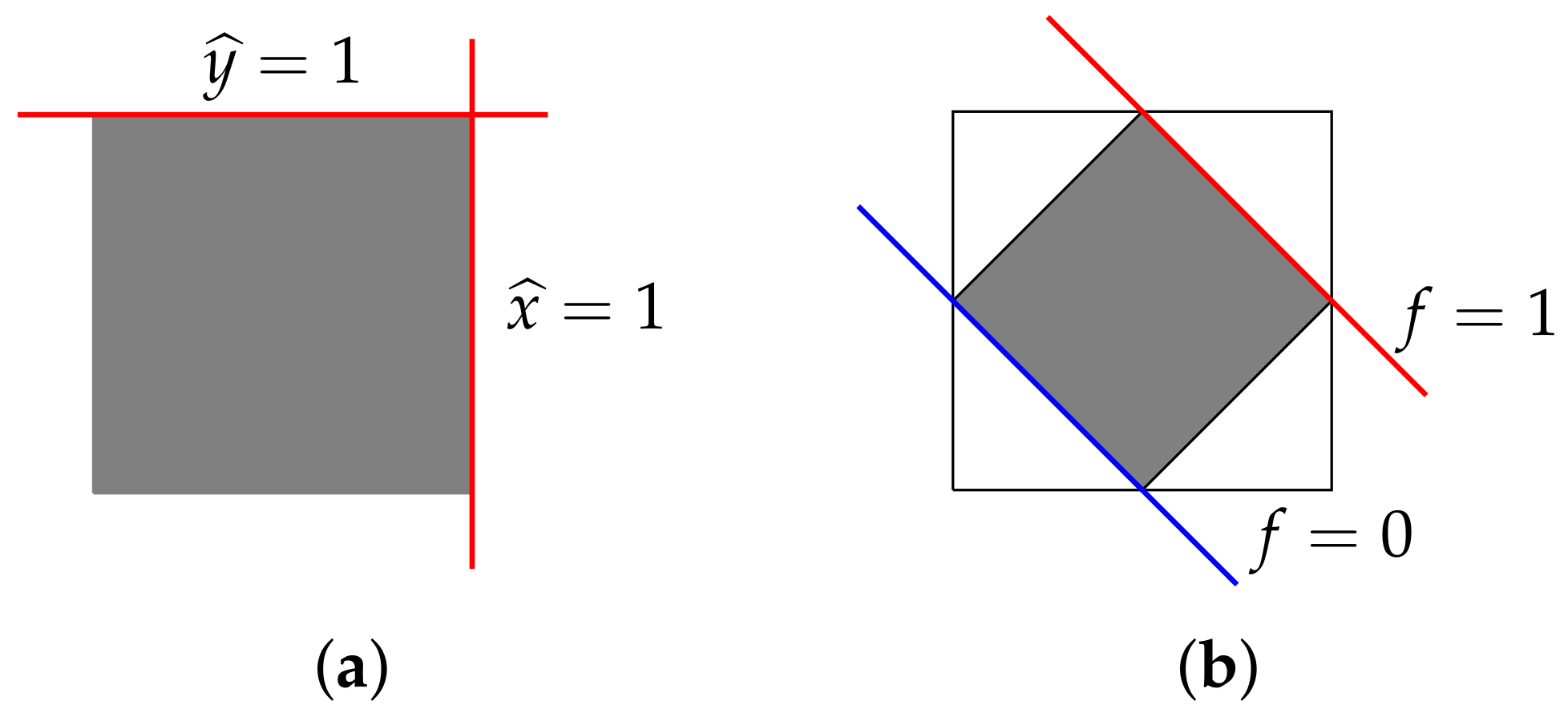
Two bits. Here is a simple, but instructive illustration of these notions. Consider a test space
. Here, we have two tests, each with two outcomes. We are permitted to perform either test, but not both at once. A probability weight is determined by the values it assigns to
x and to
y, and since the sets
and
are disjoint, these values are independent. Thus, geometrically, the space of all probability weights is the unit square in
(
Figure 2a, below). To construct a probabilistic model, we can choose any closed, convex subset of the square for
. For instance, we might let
be the convex hull of the four probability weights
,
and
corresponding to the midpoints of the four sides of the square, as in
Figure 2b, that is,
and similarly for
and
.
The model of
Figure 2a, in which we take
to be the entire set of probability weights on
, is sometimes called the
square bit. I will call the model of
Figure 2b the
diamond bit.
Classical, quantum and Jordan models. If E is a finite set, the corresponding classical model is where is the simplex of probability weights on E. If is a finite-dimensional complex Hilbert space, let denote the set of orthonormal bases of : then is the unit sphere of , and any density operator W on defines a probability weight , given by for all . Letting denote the set of states of this form, we obtain the quantum model, , associated with (Gleason’s theorem tells us that has a full state space for , but we will not need this fact).
More generally, every Euclidean Jordan algebra gives rise to a probabilistic model as follows. A minimal or primitive idempotent of is an element with and, for , . A Jordan frame is a maximal pairwise orthogonal set of primitive idempotents. Let be the set of primitive idempotents; let be the set of Jordan frames; and let be the set of probability weights of the form where with . These data define the Jordan model associated with . In the case where for a finite-dimensional Hilbert space , this almost gives us back the quantum model : the difference is that we replace unit vectors by their associated projection operators, thus conflating outcomes that differ only by a phase.
Sharp models. Jordan models enjoy many special features that the generic probabilistic model lacks. I want to take a moment to discuss one such feature, which will be important below.
Definition 3. A model A is unital iff, for every outcome , there exists a state with , and sharp if this state is unique (from which it follows easily that it must be pure). If A is sharp, I will write for the unique state making certain.
If A is sharp, then there is a sense in which each test is maximally informative: if we are certain which outcome will occur, then we know the system’s state exactly, as there is only one state in which x has probability 1.
Classical and quantum models are obviously sharp. More generally, every Jordan model is sharp. To see this, note first that every state
on a Euclidean Jordan algebra
has the form
where
with
and where
is the given inner product on
, normalized so that
for all primitive idempotents (equivalently, so that
, the rank of
). The spectral theorem for EJAs [
13] shows that
where
E is a Jordan frame and the coefficients
are non-negative and sum to one (since
). If
, then
implies that, for every
with
,
. However,
, so this implies that
, which in turn implies that
.
In general, a probabilistic model need not even be unital, much less sharp. On the other hand, given a unital model
A, it is often possible to construct a sharp model by suitably restricting the state space. This is illustrated in
Figure 2b above: the full state space of the square bit is unital, but far from sharp; however, by restricting the state space to the convex hull of the barycenters of the faces, we obtain a sharp model. This is possible whenever
A is unital and carries a group of symmetries acting transitively on the outcome-set
. For details, see
Appendix A. The point here is that sharpness is not, by itself, a very stringent condition: since we should expect to find highly symmetric, unital models represented abundantly “in nature”, we can also expect to encounter an abundance of systems represented by sharp models.
The spaces , . Any probabilistic model gives rise to a pair of ordered vector spaces in a canonical way. These will be essential in the development below, so I am going to go into a bit of detail here.
Definition 4. Let A be any probabilistic model. Let be the span of the state space in , ordered by the cone consisting of non-negative multiples of states, i.e., Call the model A finite-dimensional iff is finite-dimensional. From now on, I assume that all models are finite-dimensional.
Let denote the dual space of , ordered by the dual cone of positive linear functionals, i.e., functionals f with for all . Any measurement-outcome yields an evaluation functional , given by for all . More generally, an effect is a positive linear functional with for every state . The functionals are effects. One can understand an arbitrary effect a to represent a mathematically possible measurement outcome, having probability in state . I stress the adjective mathematically because, a priori, there is no guarantee that every effect will correspond to a physically-realizable measurement outcome. In fact, at this stage, I make no assumption at all about what, apart from the tests , is or is not physically realizable. (Later, it will follow from further assumptions that every element of represents a random variable associated with some and is, therefore, operationally meaningful. However, this will be a theorem, not an assumption.)
The unit effect is the functional , where E is any element of . This takes the constant value of one on , and, thus, represents a trivial measurement outcome that occurs with probability one in every state. This is an order unit for (to see this, let , and let N be the maximum value of for , remembering that the latter is compact: then ).
For both classical and quantum models, the ordered vector spaces and are naturally isomorphic. If is the classical model associated with a finite set E, both are isomorphic to the space of all real-valued functions on E, ordered pointwise. If is the quantum model associated with a finite-dimensional Hilbert space , and are both naturally isomorphic to the space of Hermitian operators on , ordered by its usual cone of positive semi-definite operators. More generally, if is a Euclidean Jordan algebra and is the corresponding Jordan model, then , with ordered as usual, i.e., by its cone of squares. The first of these isomorphisms is due to the definition of the model and the second to ’s self-duality.
The space . It is going to be technically useful to introduce a third ordered vector space, which I will denote by
. This is the span of the evaluation-effects
, associated with measurement outcomes
, in
, ordered by the cone:
That is,
is the set of linear combinations of effects
having non-negative coefficients. It is important to note that this is, in general, a proper sub-cone of
. To see this, we can revisit the example of the “diamond bit” of
Figure 2b. Letting
x and
y be the outcomes corresponding to the right face and the top face of the larger (full) state space pictured below in
Figure 3a, consider the functional
. This takes positive values on the smaller state space of the diamond bit, but is negative on, for example, the state
corresponding to the lower-left corner of the full state space (see
Figure 3b). Thus,
, but
.
Since we are working in finite dimensions, the outcome-effects span . Thus, as vector spaces, and are the same. However, as the diamond bit illustrates, they can have quite different positive cones and, thus, need not be isomorphic as ordered vector spaces.
Processes and subnormalized states. A subnormalized state of a model A is an element of with . These can be understood as states that allow a nonzero probability of some generic “failure” event, (e.g., the destruction of the system), represented by the zero functional in .
More generally, we may wish to regard two systems, represented by models
A and
B, as the input to and output from some process, whether dynamical or purely information-theoretic, that has some probability to destroy the system or otherwise “fail”. Since such a process should preserve probabilistic mixtures, it should be represented mathematically by an affine mapping
, taking each normalized state
of
A to a possibly sub-normalized state
of
B. One can show that such a mapping extends uniquely to a positive linear mapping:
so from now on, this is how I represent processes.
Even if a process T has a nonzero probability of failure, it may be possible to reverse its effect with nonzero probability.
Definition 5. A process is probabilistically reversible iff there exists a process S such that, for all , , where .
This means that there is a probability of the composite process failing, but a probability p that it will leave the system in its initial state (note that, since is linear, p must be constant); where T preserves normalization, so that , S can also be taken to be normalization-preserving and will undo the result of T with probability one. This is the more usual meaning of “reversible” in the literature.
Given a process , there is a dual mapping , also positive, given by for all and . The assumption that T takes normalized states to subnormalized states is equivalent to the requirement that , that is that maps effects to effects.
Remark 1. Since we are attaching no special physical interpretation to the cone , we do not require a physical process to have a dual process that maps to . That is, we do not require to be positive as a mapping .
Joint probabilities and joint states. If
and
are two test spaces, with outcome-spaces
and
, we can construct a space of product tests (note here the savage abuse of notation:
is not the Cartesian product of
and
):
This models a situation in which tests from
and from
can be performed separately, and the results collated. Note that the outcome-space for
is
. A joint probability weight on
and
is just a probability weight on
, that is a function
such that
for all tests
and
. One says that
is non-signaling iff the marginal (or reduced) probability weights
and
, given by:
are well-defined, i.e., independent of the choice of the tests
E and
F, respectively. One can understand this to mean that the choice of which test to measure on
has no observable, i.e., no statistical, influence on the outcome of tests made of
, and vice versa. In this case, one also has well-defined conditional probability weights:
(with, say,
if
, and similarly for
). This gives us the following bipartite version of the law of total probability [
23]: for any choice: of
or
,
Definition 6. A joint state on a pair of probabilistic models A and B is a non-signaling joint probability weight ω on such that, for every and every , the conditional probability weights and belong to and , respectively. It follows from (1) that the marginal weights and are also states of A and B, respectively.
This naturally suggests that one should define, for models
A and
B, a composite model
, the states of which would be precisely the joint states on
A and
B. If one takes
, this is essentially the “maximal tensor product” of
A and
B [
24]. However, this does not coincide with the usual composite of quantum-mechanical systems. In
Section 6, I will discuss composite systems in more detail. Meanwhile, for the main results of this paper, the idea of a joint state is sufficient.
For a simple example of a joint state that is neither classical, nor quantum, let
B denote the “square bit” model discussed above. That is,
where e
is a test space with two non-overlapping, two-outcome tests, and
is the set of all probability weights thereon, amounting to the unit square in
. The joint state on
given by
Table 1 (a variant of the “non-signaling box” of Popescu and Rohrlich [
25]) is clearly non-signaling. Notice that it also establishes a perfect, uniform correlation between the outcomes of any test on the first system and its counterpart on the second.
Conditioning maps. If
is a joint state on
A and
B, define the associated
conditioning maps by:
for all
and
. Note that
for every
, i.e.,
can be understood as the un-normalized conditional state of
B given the outcome
x on
A. Similarly,
is the unnormalized conditional state of
A given outcome
y on
B.
The conditioning map extends uniquely to a positive linear mapping , which I also denote by , such that for all outcomes . To see this, consider the linear mapping defined, for , by for all . If , we have , whence, for all , . Since the evaluation functionals span , the range of T lies in , and moreover, T is positive on the cone . Hence, as advertised, T defines a positive linear mapping , extending . In the same way, defines a positive linear mapping .
An immediate and important corollary is that any joint state on A and B defines a bilinear form, which by abuse of notation I also call , on , given by for all . Note that for all and also that the bilinear form is positive, in the sense that for all and all .
4. Conjugates and Filters
We are now in a position to abstract the two features of QM discussed earlier. Call a test space
uniform iff all tests
have the same size, which we then call the
rank of the test space. The test spaces associated with quantum models are uniform, and it is quite easy to generate many other examples (see
Appendix A).
A uniform test space of rank n always admits at least one probability weight, namely the maximally-mixed probability weight for all . I will say that a probabilistic model A is uniform if the test space is uniform and the maximally-mixed state belongs to .
By an isomorphism from a probabilistic model A to a probabilistic model B, I mean the obvious thing: a bijection taking onto , and such that maps onto .
Definition 7. Let A be uniform probabilistic model with tests of size n. A conjugate for A is a model , plus a chosen isomorphism and a joint state on A and such that for all ,
- (a)
- (b)
where .
This corresponds to what is called a “weak conjugate” in [
17]. Note that if
, we have
and
. Hence,
for
with
. Thus,
establishes a perfect, uniform correlation between any test
and its counterpart,
, in
.
The symmetry condition (b) is pretty harmless. If is a joint state on A and satisfying (a), then so is ; thus, satisfies both (a) and (b). In fact, if A is sharp, (b) is automatic: if satisfies (a), then the conditional state assigns probability one to the outcome x. If A is sharp, this implies that is uniquely defined, whence is also uniquely defined. In other words, for a sharp model A and a given isomorphism , there exists at most one joint state satisfying (a); whence, in particular, .
If
is the quantum-mechanical model associated with an
n-dimensional Hilbert space
, then we can take
and define
, where
is the EPR state on
, as discussed in
Section 3.
So much for conjugates. We generalize the filters associated with pure CP mappings as follows:
Definition 8. A filter associated with a test is a positive linear mapping such that for every outcome , there is some coefficient with for every state .
Equivalently, is a filter iff the dual process satisfies for each . Just as in the quantum-mechanical case, a filter independently attenuates the “sensitivity” of the outcomes . (The extreme case is one in which the coefficient corresponding to a particular outcome is one, and the other coefficients are all zero. In that case, all outcomes other than x are, so to say, blocked by the filter. Conversely, given such an “all or nothing” filter for each , we can construct an arbitrary filter with coefficients by setting .)
Call a filter reversible iff is an order-automorphism of ; that is, iff it is probabilistically reversible as a process. Evidently, this requires that all the coefficients be nonzero. We will eventually see that the existence of a conjugate, plus the preparability of arbitrary nonsingular states by symmetric reversible filters, will be enough to force A to be a Jordan model. Most of the work is done by the easy Lemma 1, below. First, some terminology.
Definition 9. Suppose is a family of states indexed by outcomes and such that . Say that a state α is spectral with respect to Δ iff there exists a test such that . Say that the model A itself is spectral with respect to Δ if every state of A is spectral with respect to Δ.
If A has a conjugate , then the bijection extends to an order-isomorphism . It follows that every non-signaling joint probability weight on A and defines a bilinear form on .
The following is essentially proven in [
17], but the presentation here is somewhat different.
Lemma 1. Let A have a conjugate . Suppose A is spectral with respect to the states , . Then: where n is the rank of A, defines a self-dualizing inner product on , with respect to which . Moreover, A is sharp, and . Proof. That is symmetric and bilinear follows from ’s being symmetric and non-signaling. Note that for every and for any distinct lying in a common test. We need to show that is positive-definite. Since and the latter is spectral, so is the former. It follows that takes onto and, hence, is an order-isomorphism. From this, it follows that every has a “spectral” decomposition of the form for some coefficients and some test . In fact, any , positive or otherwise, has such a decomposition (albeit with possibly negative coefficients). If is arbitrary, with for some , we can find with . Thus, , and so, for some , and hence, .
Now, let
. Decomposing
for some test
E and some coefficients
, we have:
This is zero only where all coefficients are zero, i.e., only for . Therefore, is an inner product, as claimed.
We need to show that is self-dualizing. Clearly for all . Suppose is such that for all . Then, for all . Now, for some test E; thus, for all , we have , whence, .
Next, we want to show that
. Since
is an order-isomorphism, for every
, there exists a unique
with
. In particular,
It follows that if
,
Since every has the form for some , if , we have for all , whence, by the self-duality of the latter cone, . Thus, .
Finally, let us see that A is sharp. If , let a be the unique element of with . In particular, . If a has spectral decomposition , where , then for all , ; hence, . Thus, , whence, . Now, suppose for some : then, ; as , we have . However, now , whence, . Hence, there is only one weight with , namely, , so A is sharp. ☐
If A is sharp, then we say that A is spectral iff it is spectral with respect to the pure states defined by . If A is sharp and has a conjugate , then, as noted earlier, the state is exactly , so the spectrality assumption in Lemma 1 is fulfilled if we simply say that A is spectral. Hence, a sharp, spectral model with a conjugate is self-dual.
For the simplest systems, this is already enough to secure the desired representation in terms of a Euclidean Jordan algebra.
Definition 10. Call A a bit iff it has rank two (that is, all tests have two outcomes) and if every state can be expressed as a mixture of two sharply distinguishable states; that is, for some and states and with and for some test .
Corollary 1. If A is a sharp bit, then is a ball of some finite dimension d.
The proof is given in
Appendix C. If
d is 2, 3 or 5, we have a real, complex or quaternionic bit. For
or
, we have a non-quantum spin factor.
For systems of higher rank (higher “information capacity”), we need to assume a bit more. Suppose A satisfies the hypotheses of Lemma 1. Appealing to the Koecher–Vinberg theorem, we see that if and, hence, are also homogeneous, then carries a canonical Jordan structure. In fact, we can say something a little stronger.
Theorem 2. Let A be spectral with respect to a conjugate system . If is homogeneous, then there exists a canonical Jordan product on with respect to which is the Jordan unit. Moreover, with respect to this product, is exactly the set of primitive idempotents, and is exactly the set of Jordan frames.
The first part is almost immediate from the Koecher–Vinberg theorem, together with Lemma 1. The KV theorem gives us an isomorphism between the ordered vector spaces
and
, so if one is homogeneous, so is the other. Since
is also self-dual by Lemma 1, the KV theorem yields the requisite unique Euclidean Jordan structure having
u as the Jordan unit. One can then show without much trouble that every outcome
is a primitive idempotent of
with respect to this Jordan structure and that every test is a Jordan frame. The remaining claims (that every minimal idempotent belongs to
and every Jordan frame, to
) take a little bit more work. I will not reproduce the proof here; the details (which are not especially difficult, but depend on some facts concerning Euclidean Jordan algebras) can be found in [
17].
The homogeneity of can be understood as a preparability assumption: it is equivalent to saying that every state in the interior of can be obtained, up to normalization, from the maximally-mixed state by a reversible process. That is, if , there is some such process such that where . One can think of the coefficient p as the probability that the process will yield a nonzero result (more dramatically: will not destroy the system). Thus, if we prepare an ensemble of identical copies of the system in the maximally-mixed state and subject them all to the process , the fraction that survives will be about p, and these will all be in state .
In fact, if the hypotheses of Lemma 1 hold, the homogeneity of follows directly from the mere existence of reversible filters with arbitrary non-zero coefficients. To see this, suppose has a spectral decomposition for some , with for all x when a belongs to the interior of . Now, if we can find a reversible filter for E with for all , then applying this to the order-unit yields a. Thus, is homogeneous.
Two paths to spectrality. Some axiomatic treatments of quantum theory have taken one or another form of spectrality as an axiom [
6,
26]. If one is content to do this, then Lemma 1 above provides a very direct route to the Jordan structure of quantum theory. However, spectrality can actually be derived from assumptions that, on their face, seem a good deal weaker, or anyway more transparent (a different path to spectrality is charted in a recent paper [
27] by G. Chiribella and C. M. Scandolo).
I will call a joint state on models A and B correlating iff it sets up a perfect correlation between some pair of tests and . More exactly:
Definition 11. A joint state ω on probabilistic models A and B correlates a test with a test iff there exist subsets and , and a bijection such that for unless . In this case, say that ω correlates E with F along f. A joint state on A and B is correlating iff it correlates some pair of tests .
Note that correlates E with F along f iff , which, in turn, is equivalent to saying that for .
Lemma 2. Suppose A is sharp and that every state α of A arises as the marginal of a correlating joint state between A and some model B. Then, A is spectral.
Proof. Suppose , where is a joint state correlating a test with a test , say along a bijection , where and . Then, for any with , , whence, as A is sharp, , the unique state making x certain. It follows from the law of total probability that . ☐
In principle, the model B can vary with the state . Lemma 2 suggests the following language:
Definition 12. A model A satisfies the correlation condition iff every state is the marginal of some correlating joint state of A and some model B.
This has something of the same flavor as the
purification postulate of [
8], which requires that all states of a given system arise as marginals of a pure state on a larger, composite system, unique up to symmetries on the purifying system. However, note that we do not require the correlating joint state to be either pure (which, in classical probability theory, it will not be) or unique.
If A is sharp and satisfies the correlation condition, then every state of A is spectral. If, in addition, A has a conjugate, then for every , we have . In this case, A is spectral with respect to the family of states , and the hypotheses of Lemma 1 are satisfied.
Here is another, superficially quite different, way of arriving at spectrality. Suppose
A has a conjugate,
. Call a transformation
symmetric with respect to
iff, for all
,
Say that a state is preparable by a filter iff , where is the maximally-mixed state.
Lemma 3. Let A have a conjugate, , and suppose every state of A is preparable by a symmetric filter. Then, A is spectral.
Proof. Let
where
is a filter on a test
, say
for all
. Then:
☐
Thus, the hypotheses of either Corollary 2 or Lemma 3 will supply the needed spectral assumption that makes Lemma 1 work (in fact, it is not hard to see that these hypotheses are actually equivalent, an exercise I leave for the reader).
To obtain a Jordan model, we still need homogeneity. This is obviously implied by the preparability condition in Lemma 3, provided the preparing filters
can be taken to be reversible whenever the state to be prepared is non-singular. On the other hand, as noted above, in the presence of spectrality, it is enough to have arbitrary reversible filters, as these allow one to prepare the spectral decompositions of arbitrary non-singular states. Thus, conditions (a) and (b) below both imply that
A is a Jordan model. Conversely, one can show that any Jordan model satisfies both (a) and (b), closing the loop [
17]:
Theorem 3. The following are equivalent:
- (a)
A has a conjugate, and every non-singular state can be prepared by a reversible symmetric filter;
- (b)
A is sharp, has a conjugate, satisfies the correlation condition and has arbitrary reversible filters;
- (c)
A is a Jordan model.
5. Measurement, Memory and Correlation
Of the spectrality-underwriting conditions given in Lemmas 2 and 3, the one that seems less transparent (to me, anyway) is the correlation condition, i.e., that every state arises as the marginal of a correlating bipartite state. While surely less ad hoc than spectrality, this still calls for further explanation. Suppose we hope to implement a measurement of a test dynamically. This would involve bringing up an ancilla system B (also uniform, suppose; and which we can suppose, by suitable coarse-graining, if necessary, to have tests of the same cardinality as A’s) in some “ready” state . We would then subject the combined system to some physical process, at the end of which, is in some final joint state , and B is (somehow!) in one of a set of record states, , each corresponding to an outcome . (This way of putting things takes us close to the usual formulation of the quantum-mechanical “measurement problem”, which I certainly do not propose to discuss here. The point is only that, if any dynamical process, describable within the theory, can account for measurement results, it should be consistent with this description.)
We would like to insist that:
- (a)
The states are distinguishable, or readable, by some test . This means that for each , there is a unique such that . Note that this sets up an injection .
- (b)
The record states must be accurate, in the sense that if we were to measure E on A, and secure , the record state should coincide with the conditional state (if this is not the case, then a measurement of A cannot correctly calibrate the system B as a measuring device for E).
It follows from (a) and (b) that, for
and
,
In other words, must correlate E with F, along the bijection . If the measurement process leaves undisturbed, in the sense that , then dilates to a correlating state. This suggests the following non-disturbance principle: every state can be measured, by some test , without disturbance. Lemma 2 then tells us that if A is sharp and satisfies the non-disturbance principle, every state of A is spectral.
Here is a slightly different, but possibly more compelling, version of this story. Suppose we can perform a test E on A directly (setting aside, that is, any issue of whether or not this can be achieved through some dynamical process): this will result in an outcome x occurring. To do anything with this, we need to record its having occurred. This means we need a storage medium, B and a family of states , one for each , such that if, on performing the test E, we obtain x, then B will be in state . Moreover, these record states need to be readable at a later time, i.e., distinguishable by a later measurement on B. To arrange this, we need A and B to be in a joint state, associated with a joint probability weight , such that (because we want to have prepared A in the state ) and for every . We then measure E on A; upon our obtaining outcome , B is in the state . Since the ensemble of states is readable by some with , we have correlation, and must also be spectral.
Of course, these desiderata cannot always be satisfied. What is true, in QM, is that for every choice of state , there will exist some test that is recordable in that state, in the foregoing sense. If we promote this to the general principle, we again see that every state is the marginal of a correlating state, and hence spectral, if A is sharp.
6. Composites and Categories
Thus far, we have been referring to the correlator
as a joint state, but dodging the question:
state of what? Mathematically, nothing much hangs on this question: it is sufficient to regard
as a bipartite probability assignment on
A and
. However, it would surely be more satisfactory to be able to treat it as an actual physical state of some composite system
. How should this be chosen? As mentioned above, one possibility is to take
to be the maximal tensor product of the models
A and
[
24]. By definition, this has for its states all non-signaling probability assignments with conditional states belonging to
A and
. However, we might want composite systems, in particular
, to satisfy the same conditions we are imposing on
A and
, i.e., to be a Jordan model. If so, we need to work somewhat harder: the maximal tensor product will be self-dual only if
A is classical.
In order to be more precise about all this, the first step is to decide what ought to count as a composite of two probabilistic models. If we mean to capture the idea of two physical systems that can be acted upon separately, but which cannot influence one another in any observable way (e.g., two spacelike-separated systems), the following seems to capture the minimal requirements:
Definition 13. A non-signaling composite of models A and B is a model , together with a mapping such that: and, for , is a joint state on A and B, as defined in Section 2. The idea here, expressed in Alice-and-Bob language (Alice controlling system
A, Bob controlling system
B), is that
is an effect of the composite system
, corresponding to
x being observed by Alice and
y, by Bob. In many cases,
will actually be an outcome in
. Indeed, we usually have
injective, and for
,
a test in
. The rank of
will then be the product of the ranks of
A and
B. Accordingly, let us call a non-signaling composite with these these properties
multiplicative. Composites in real and complex quantum mechanics are multiplicative; in quaternionic quantum mechanics, with the most plausible definition of tensor product, they are not [
28].
Therefore, the question becomes: can one construct, for Jordan models
A and
B, a non-signaling composite
that is also a Jordan model? At present, and in this generality, this question seems to be open, but some progress is made in [
28]: if neither
A, nor
B contain the exceptional Jordan algebra as a summand, such a composite can indeed be constructed, and in multiple ways. Moreover, under a considerably more restrictive definition of “Jordan composite”, no Jordan composite
can exist if either factor has an exceptional summand.
Categories of Self-Dual Probabilistic Models. It is natural to interpret a physical theory as a category, in which objects represent physical systems and morphisms represent physical processes having these systems (or their states) as inputs and outputs. In order to discuss composite systems, this should be a symmetric monoidal category. That is, for every pair of objects
, there should be an object
, and for every pair of morphisms
and
, there should be a morphism
, representing the two processes
f and
g occurring “in parallel”. One requires that ⊗ be associative and commutative, and have a unit object
I, in the sense that there exist canonical isomorphisms
,
,
and
/ These must satisfy various “naturality conditions”, guaranteeing that they interact correctly; see [
29] for details. One also requires that ⊗ be bifunctorial, meaning that
, and if
,
,
and
, then:
By a probabilistic theory, I mean a category of probabilistic models and processes; that is, objects of are models, and a morphism , where , is a process . A monoidal probabilistic theory is such a category, , carrying a symmetric monoidal structure , where is a non-signaling composite in the sense of the definition above. I also assume that the monoidal unit, I, is the trivial Model 1 with , and that, for all ,
- (a)
iff the mapping given by belongs to ;
- (b)
The evaluation functional belongs to for all outcomes .
Call
locally tomographic iff
is a locally tomographic composite for all
. Much of the qualitative content of (finite-dimensional) quantum information theory can be formulated in purely categorical terms [
11,
18,
30]. In particular, in the work of Abramsky and Coecke [
18], it is shown that a range of quantum phenomena, notably gate teleportation, is available in any
dagger-compact category. For a review of this notion, as well as a proof of the following result, see
Appendix D:
Theorem 4. Let be a locally-tomographic monoidal probabilistic theory, in which every object is sharp, spectral and has a conjugate , with . Assume also that, for all ,
- (i)
, with ;
- (ii)
If , then .
Then, has a canonical dagger-compact structure, in which is the dual of A with as the co-unit.
Jordan composites. The local tomography assumption in Theorem 4 is a strong constraint. As is well known, the standard composite of two real quantum systems is not locally tomographic, yet the category of finite-dimensional real mixed-state quantum systems is certainly dagger-compact and satisfies the other assumptions of Theorem 4, so local tomography is definitely not a necessary condition for dagger-compactness.
This raises some questions. One is whether local tomography can simply be dropped in the statement of Theorem 4. At any rate, at present, I do not know of any non-dagger-compact monoidal probabilistic theory satisfying the other assumptions.
Another question is whether there exist examples other than real QM of non-locally-tomographic, but still dagger-compact, monoidal probabilistic theories satisfying the assumptions of Theorem 2. The answer to this is yes. Without going into detail, the main result of [
28] is that one can construct a dagger-compact category in which the objects are Hermitian parts of finite-dimensional real, complex and quaternionic matrix algebras, that is the Euclidean Jordan algebras corresponding to finite-dimensional real, complex or quaternionic quantum-mechanical systems, and morphisms are certain completely positive mappings between enveloping complex *-algebras for these Jordan algebras. The monoidal structure gives
almost the expected results: the composite of two real quantum systems is the real system corresponding to the usual (real) quantum-mechanical composite of the two components (and, in particular, is not locally tomographic). The composite of two quaternionic systems is a real system (see [
11] for an account of why this is just what one wants). The composite of a real and a complex, or a quaternionic and a complex, system is again complex. The one surprise is that the composite of two standard complex quantum systems, in this category, is not the usual thing, but rather, comes with an extra superselection rule. This functions to make time-reversal a legitimate physical operation on complex systems, as it is for real and quaternionic systems. This is part of the price one pays for the dagger-compactness of this category.
7. Conclusions
As promised, we have here an easy derivation of something close to orthodox, finite-dimensional QM, from operationally or probabilistically transparent assumptions. As discussed earlier, this approach offers, in addition to its relative simplicity, greater latitude than the locally-tomographic axiomatic reconstructions of [
7,
8,
9,
10], putting us in the slightly less constrained realm of formally real Jordan algebras. This allows for real and quaternionic quantum systems, superselection rules and even theories, such as the ones discussed in
Section 6, in which real, complex and quaternionic quantum systems coexist and interact.
There remains some mystery as to the proper interpretation of the conjugate system . Operationally, the situation is clear enough: if we understand A as controlled by Alice and , by Bob, then if Alice and Bob share the state , then they will always obtain the same result, as long as they perform the same test. However, what does it mean physically that this should be possible (in a situation in which Alice and Bob are still able to choose their tests independently)? In fact, there is little consensus (that I can find, anyway) among physicists as to the proper interpretation of the conjugate of the Hilbert space representing a given quantum-mechanical system. One popular idea is that the conjugate is a time-reversed version of the given system; but why, then, should we expect to find a state that perfectly correlates the two? At any rate, finding a clear physical interpretation of conjugate systems, even (or especially!) in orthodox quantum mechanics, seems to me an urgently important problem.
I would like to close with another problem, this one of mainly mathematical interest. The hypotheses of Theorem 2 yield a good deal more structure than just a homogeneous, self-dual cone. In particular, we have a distinguished set
of orthonormal observables in
, with respect to which every effect has a spectral decomposition. Moreover, with a bit of work, one can show that this decomposition is essentially unique. More exactly, if
where the coefficients
are all distinct and the effects
are associated with a coarse-graining of a test
, then both the coefficients and the effects are uniquely determined. The details are in
Appendix B. Using this, we have a functional calculus on
, i.e., for any real-valued function
f of a real variable and any effect
a with spectral decomposition
as above, we can define
. This gives us a unique candidate for the Jordan product of effects
a and
b, namely,
We know from Theorem 2 (and thus, ultimately, from the KV theorem) that this is bilinear. The challenge is to show this without appealing to the KV theorem (the fact that the state spaces of “bits” are always balls, as shown in
Appendix C, is perhaps relevant here).





{kind=link}
{kind=link}
{kind=link}