An Adaptive Learning Based Network Selection Approach for 5G Dynamic Environments †

Abstract
:1. Introduction
- The heterogeneous network selection scenario is abstracted as a multiagent coordination problem, and a corresponding mathematical model is established. We analyzed the theoretical results of the model, i.e., the system guarantees convergence towards Nash equilibrium, which is proved to be Pareto optimal and socially optimal.
- The multiagent network selection strategy is proposed and appropriate algorithms are designed that enable users to adaptively adjust their selections in response to the gradually or abruptly changing environment.
- The performances of the approach are investigated under various conditions and parameters. Moreover, we compare our results with two existing approaches and get significantly better performances. Finally, the robustness of our proposed approach is examined, for which the system keeps desirable performances with non-compliant terminal users.
2. Background
2.1. Game Theory
- The most commonly adopted solution concept in game theory is Nash equilibrium (NE). Under an NE, no player can benefit by unilaterally deviating from its current strategy.
- An outcome is Pareto optimal if there does not exist any other outcome under which no player’s payoff is decreased while at least one player’s payoff is strictly increased.
- Socially optimal outcomes refer to those outcomes under which the sum of all players’ payoffs are maximized [14].
2.2. Q-Learning
2.3. Dynamic HetNet Environments
3. Methods
3.1. Network Selection Problem Definition
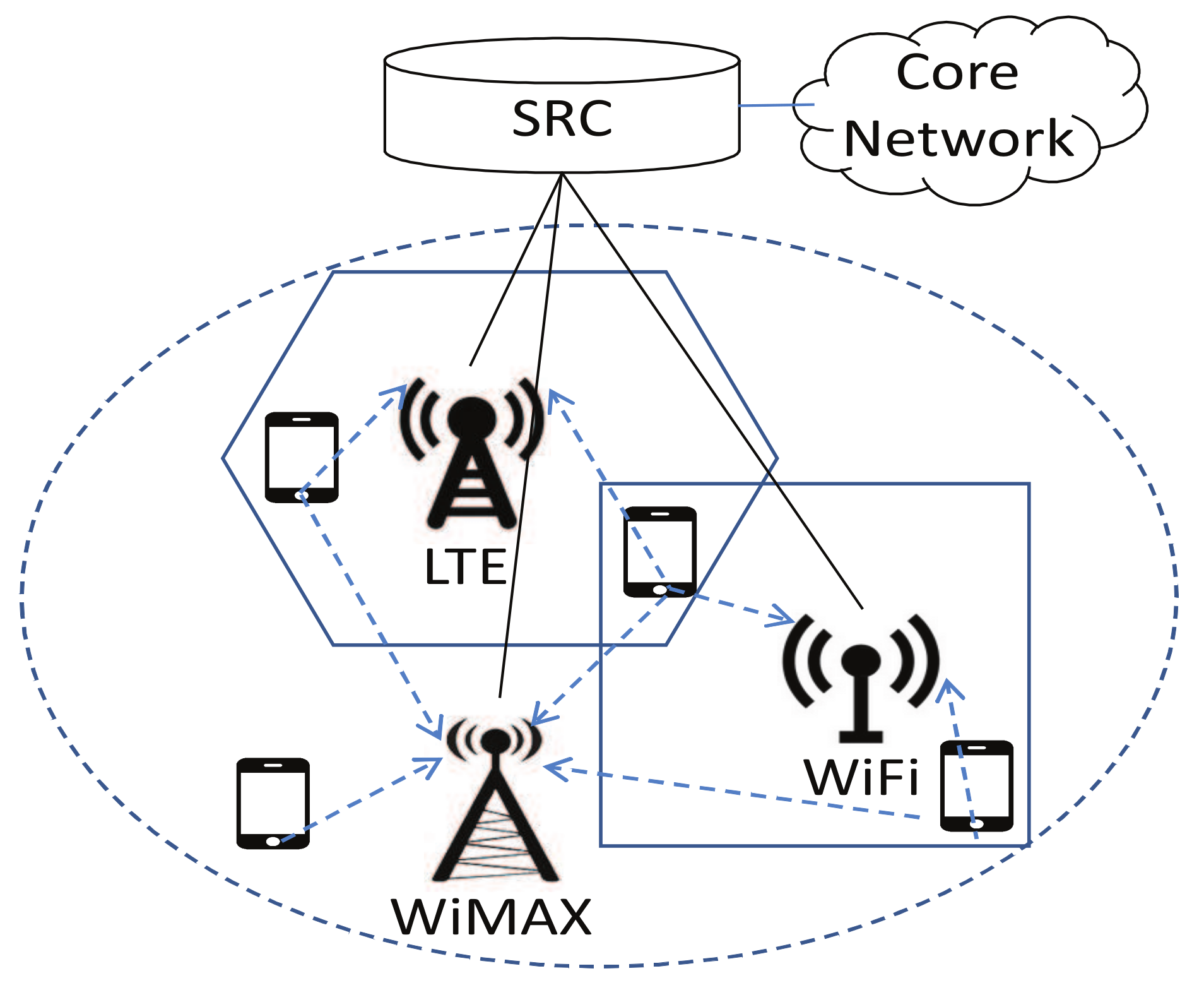
3.1.1. Multiagent Network Selection Model
- is the set of available base stations (BSs) in the HetNet environment.
- denotes the provided bandwidth of base station at time t, which varies over time.
- is the set of terminal users involved.
- denotes the bandwidth demand of user at time t, which also changes over time.
- is the finite set of actions available to user , and denotes the action (i.e., selected base station) taken by user i.
- denotes the expected payoff of user by performing the strategy profile at time t.
3.1.2. Theoretical Analysis
3.2. Multiagent Network Selection Strategy
| Algorithm 1 Network selection algorithm for each user |
| Input: available base station set |
| bandwidth demand |
| Output: selected base station |
| 1: loop |
| 2: Selection() |
| 3: receive the feedback of state information in the last compelted interaction |
| 4: Evaluation() |
| 5: end loop |
3.2.1. Selection
| Algorithm 2 Selection | |
| 1: | for all do |
| 2: | if then |
| 3: | push k in |
| 4: | else |
| 5: | LoadPredict() active predictor |
| 6: | BWPredict() |
| 7: | if then |
| 8: | push k in |
| 9: | end if |
| 10: | end if |
| 11: | end for |
| 12: | if then |
| 13: | for all do |
| 14: | |
| 15: | end for |
| 16: | |
| 17: | else if then |
| 18: | random() |
| 19: | else |
| 20: | stay at last BS |
| 21: | |
| 22: | end if |
- 1
- Create predictor set. Each user keeps a set of r predictors , which is created from some predefined set in evaluation procedure (Section 3.2.2, case 1), for each available base station k. Each predictor is a function from a time series of historic loads to a predictive load value, i.e., .
- 2
- Select active predictor. One predictor is called active predictor, which is chosen in the evaluation procedure (Section 3.2.2, case 2,3), used in real load prediction.
- 3
- Make forecast. Predict the base station’s possible load via its historic load records and the active predictor.
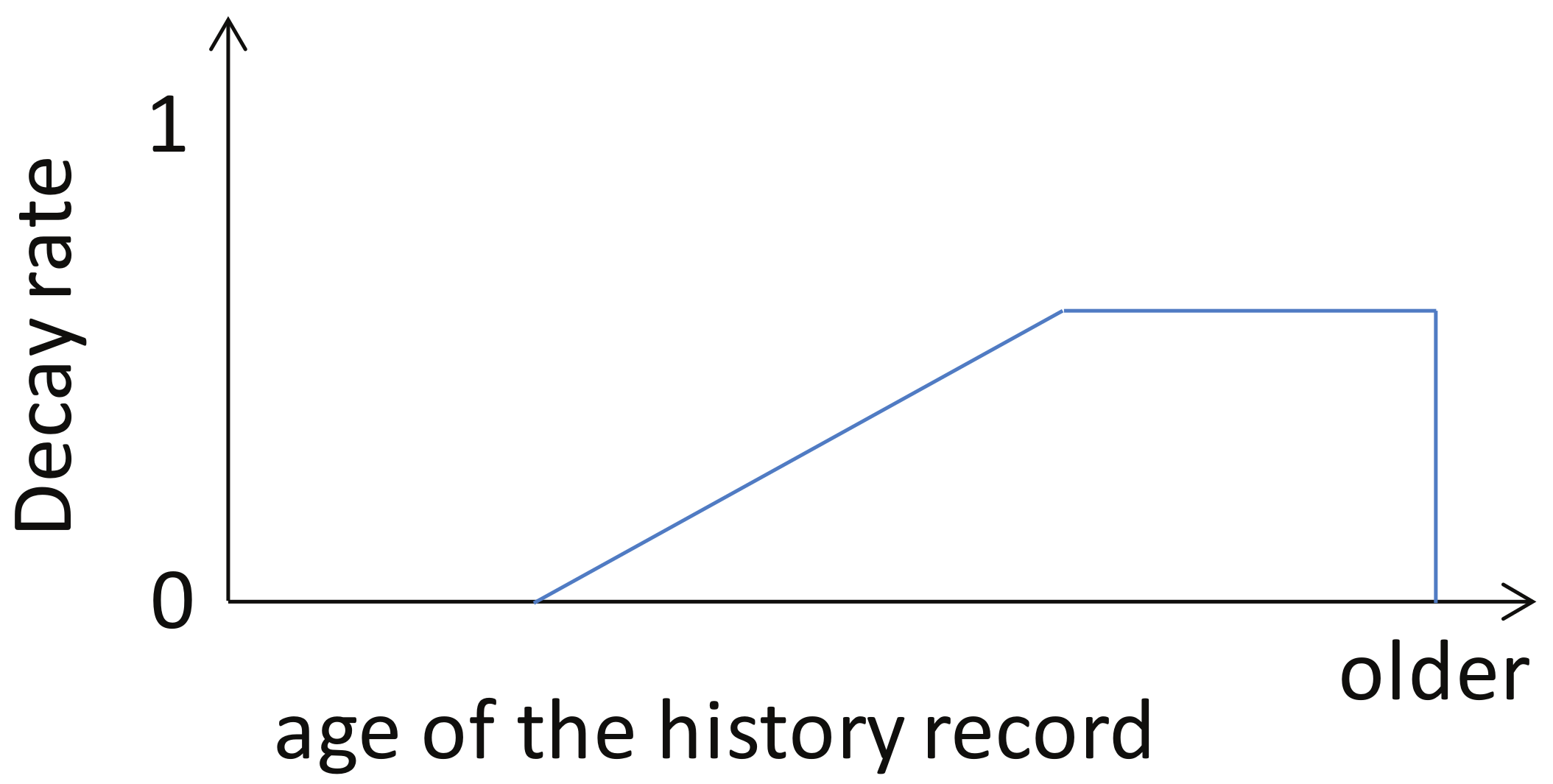
3.2.2. Evaluation
| Algorithm 3 Evaluation | |
| 1: | if then |
| 2: | create for |
| 3: | random |
| 4: | update |
| 5: | else if then |
| 6: | for all do |
| 7: | delete with a probability |
| 8: | end for |
| 9: | else |
| 10: | for all do |
| 11: | LoadPredict |
| 12: | |
| 13: | |
| 14: | end for |
| 15: | BoltzmanExploration |
| 16: | abruptly changing environment |
| 17: | if then |
| 18: | |
| 19: | for all do |
| 20: | |
| 21: | end for |
| 22: | end if |
| 23: | update |
| 24: | end if |
4. Results
- RAT type: we consider three typical networks with various radio access technologies (RATs), namely IEEE 802.11 Wireless Local Area Networks (WLAN), IEEE 802.16 Wireless Metropolitan Area Networks (WMAN) and OFDMA Cellular Network, which are represented by . Multi-mode user equipment in the heterogeneous wireless network can access any of the three networks.
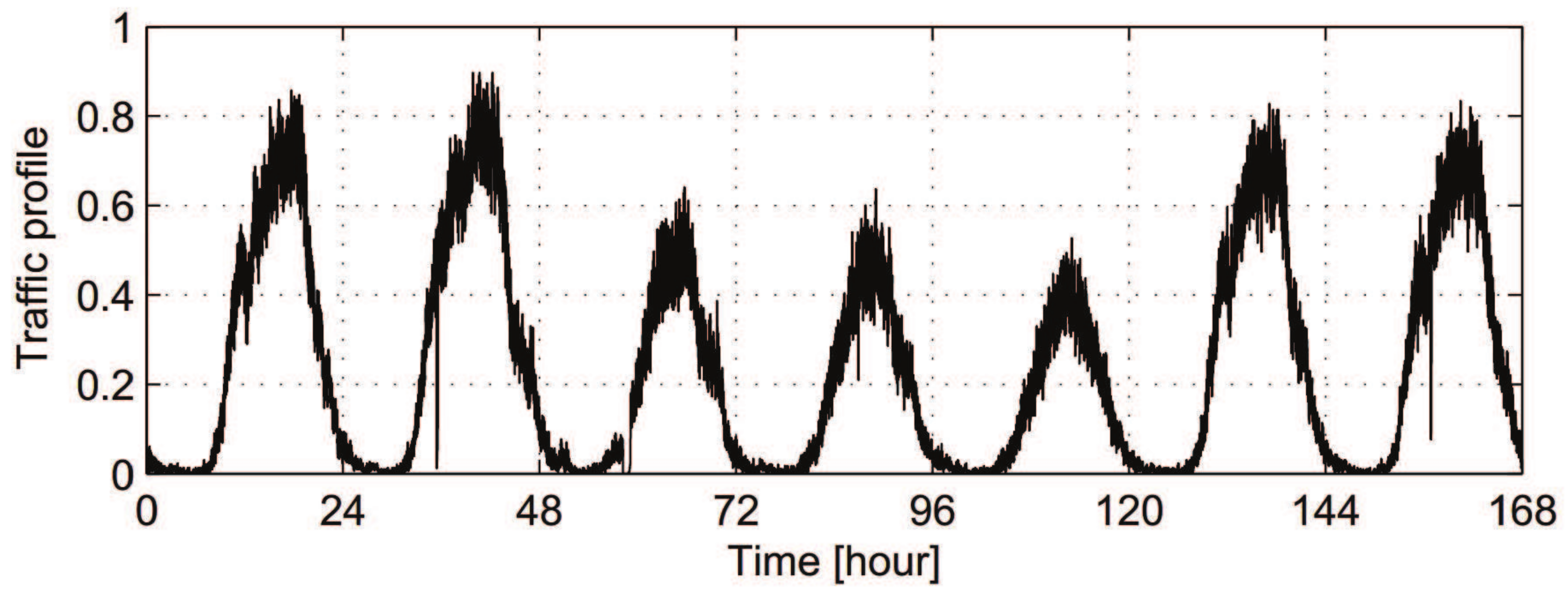
- provided bandwidth: the maximum provided bandwidth of the three networks are 25 Mbps, 50 Mbps, and 5 Mbps, respectively [30]. Without loss of generality, two types of changing environments based on historical statistic traffic are considered. One of them is simulated as sinusoidal profiles, which change gradually. The provided bandwidth may also change abruptly according to time division, such as dawn, daytime and evening.
- bandwidth demand: users’ bandwidth demands also vary in a reasonable range. There are two types of traffic demand in the area: real-time voice traffic and non-real-time data traffic, which are randomly distributed.
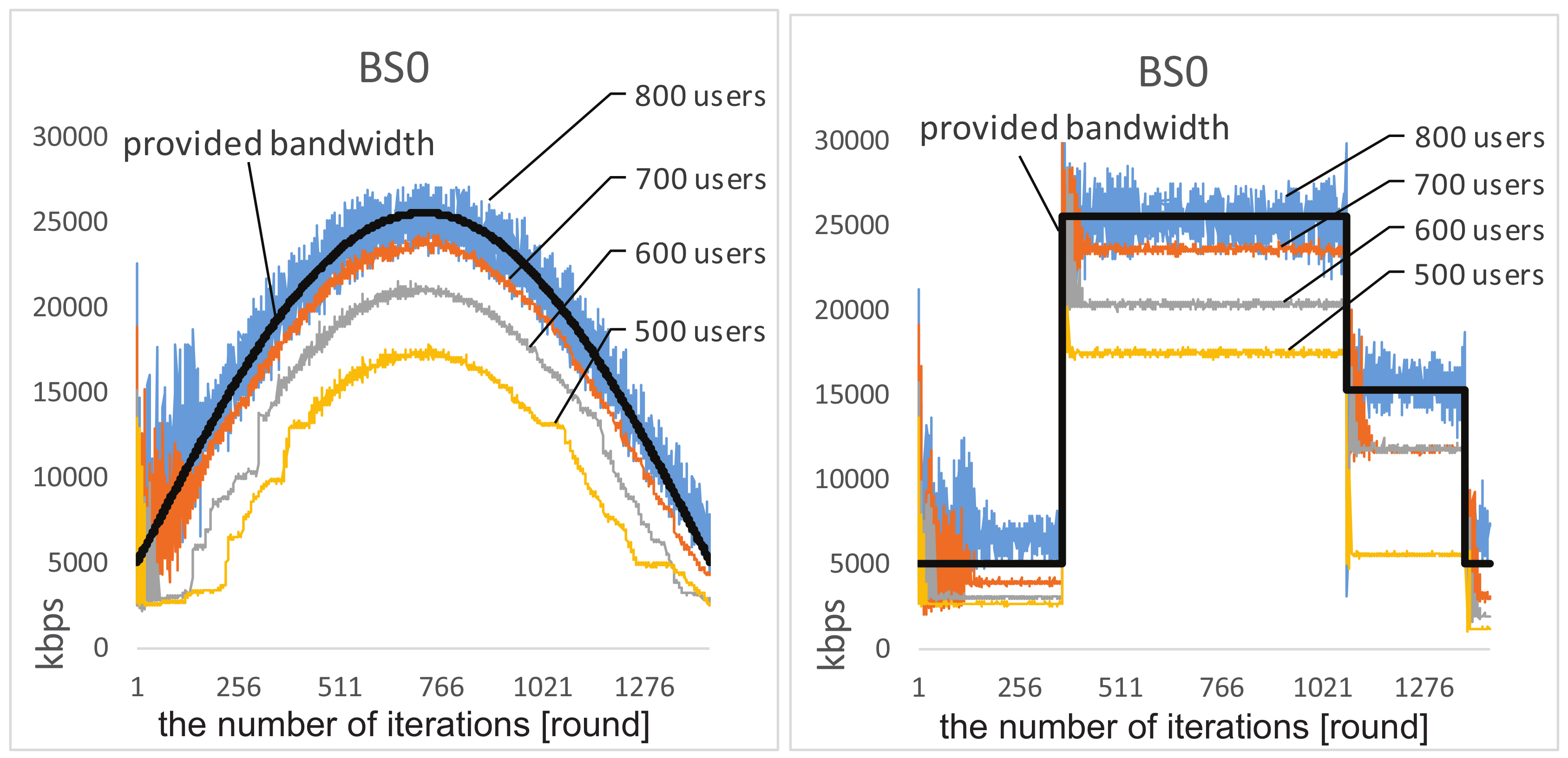
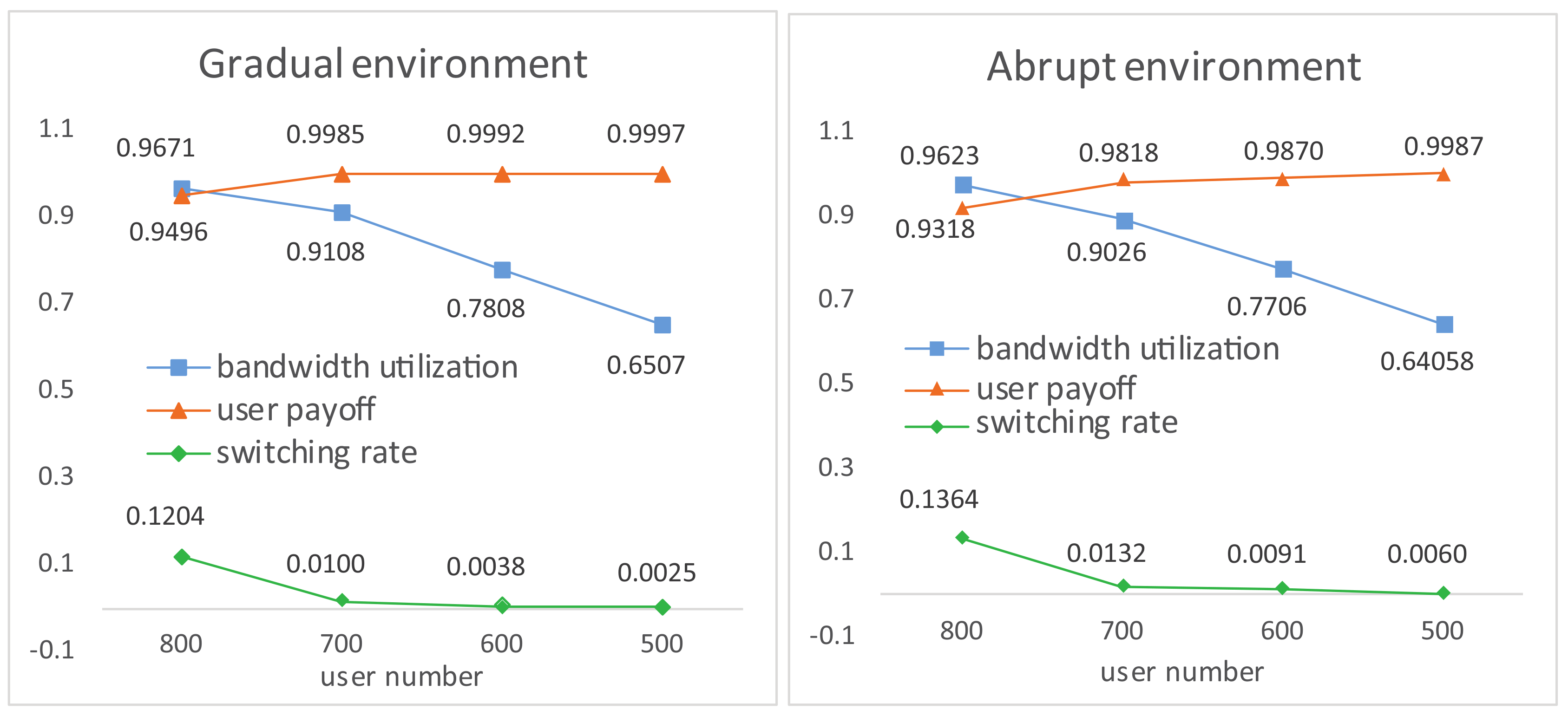
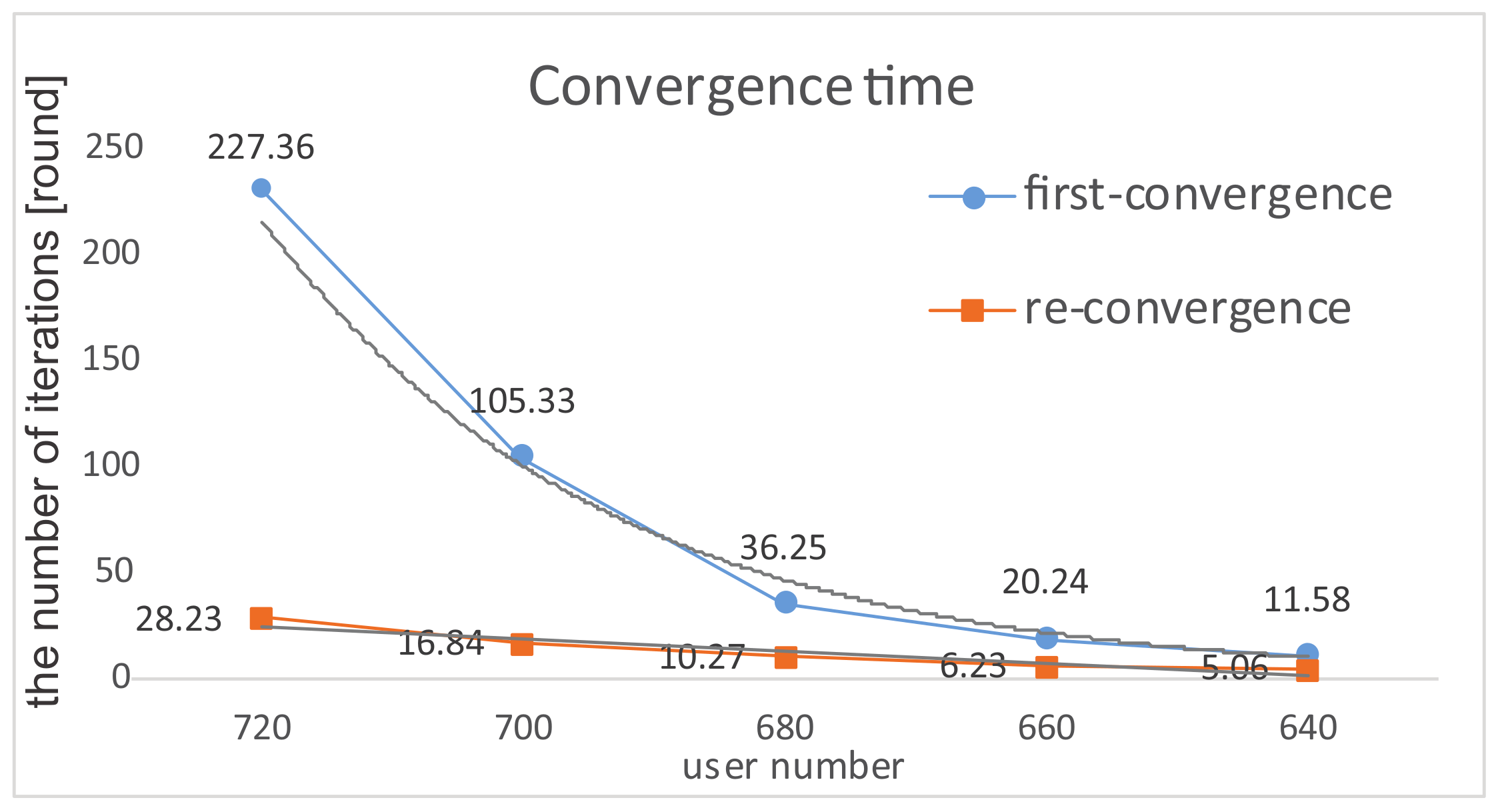
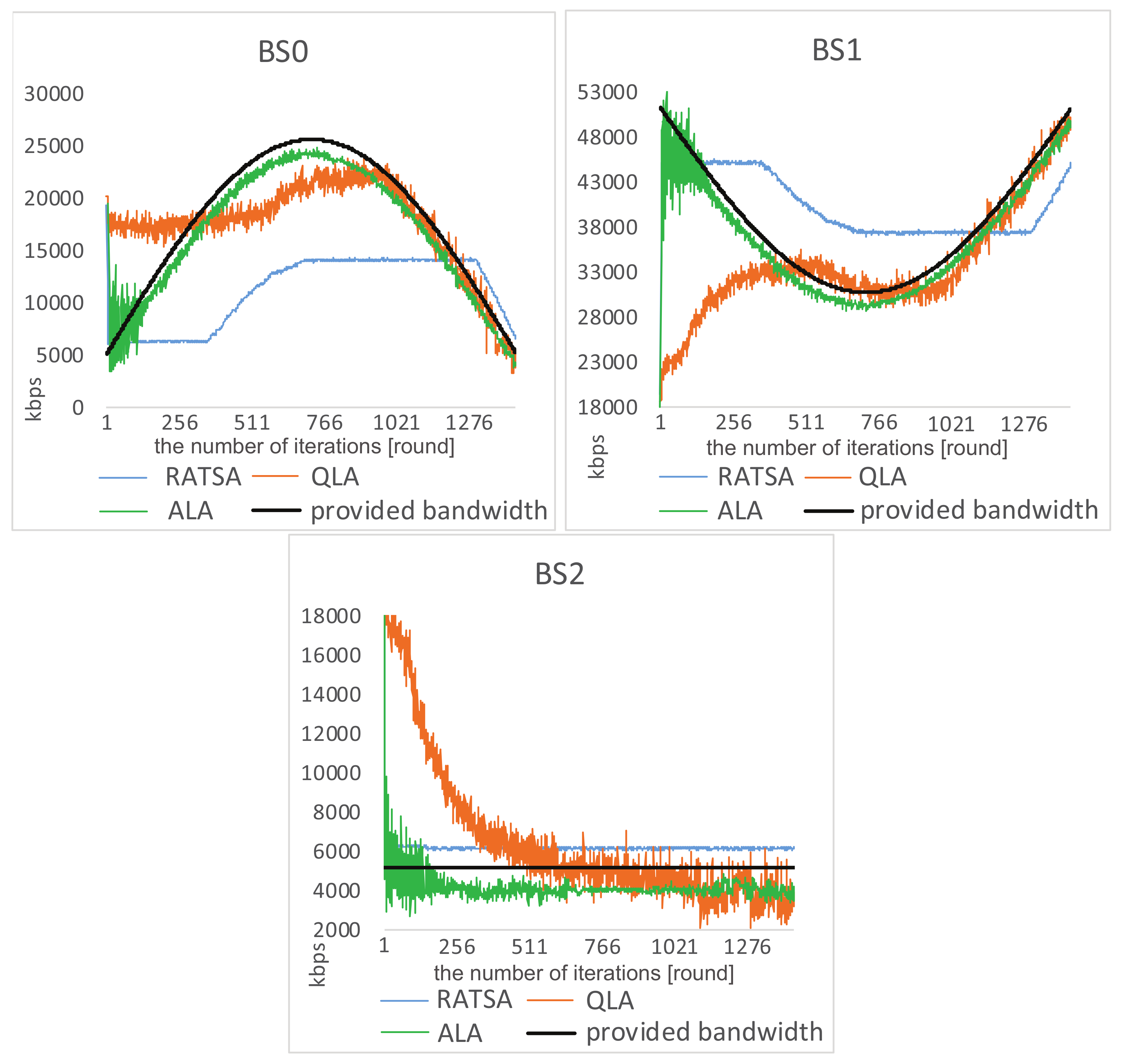
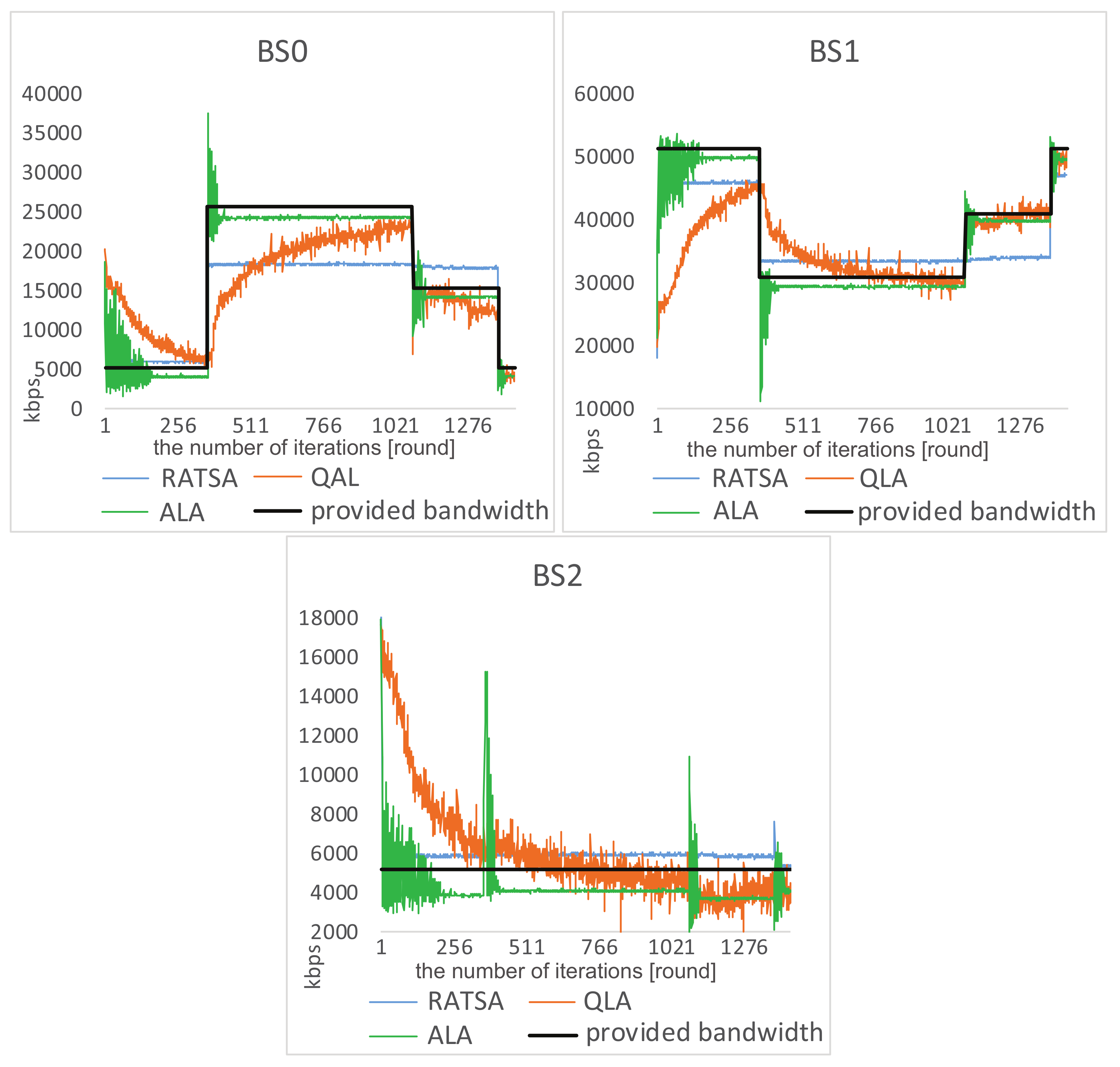
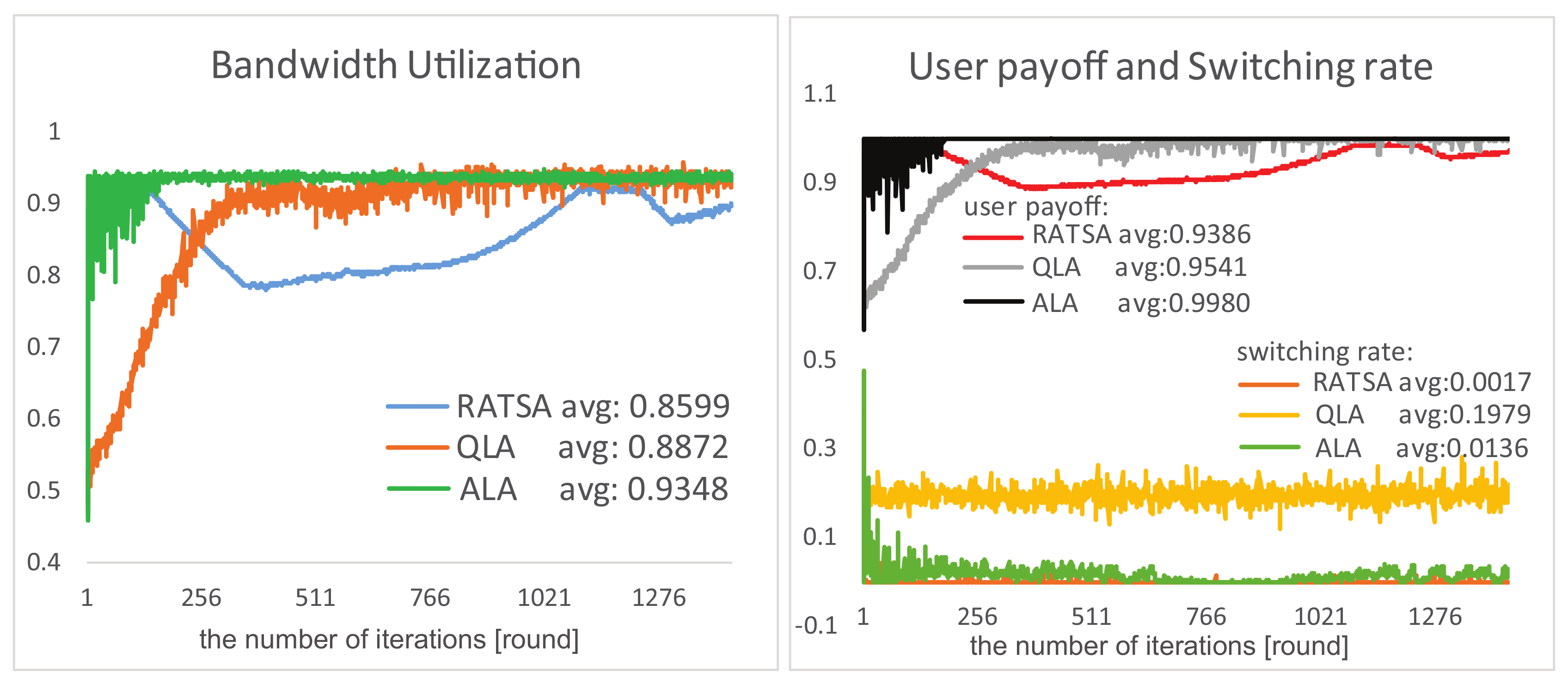
4.1. Experiment Results
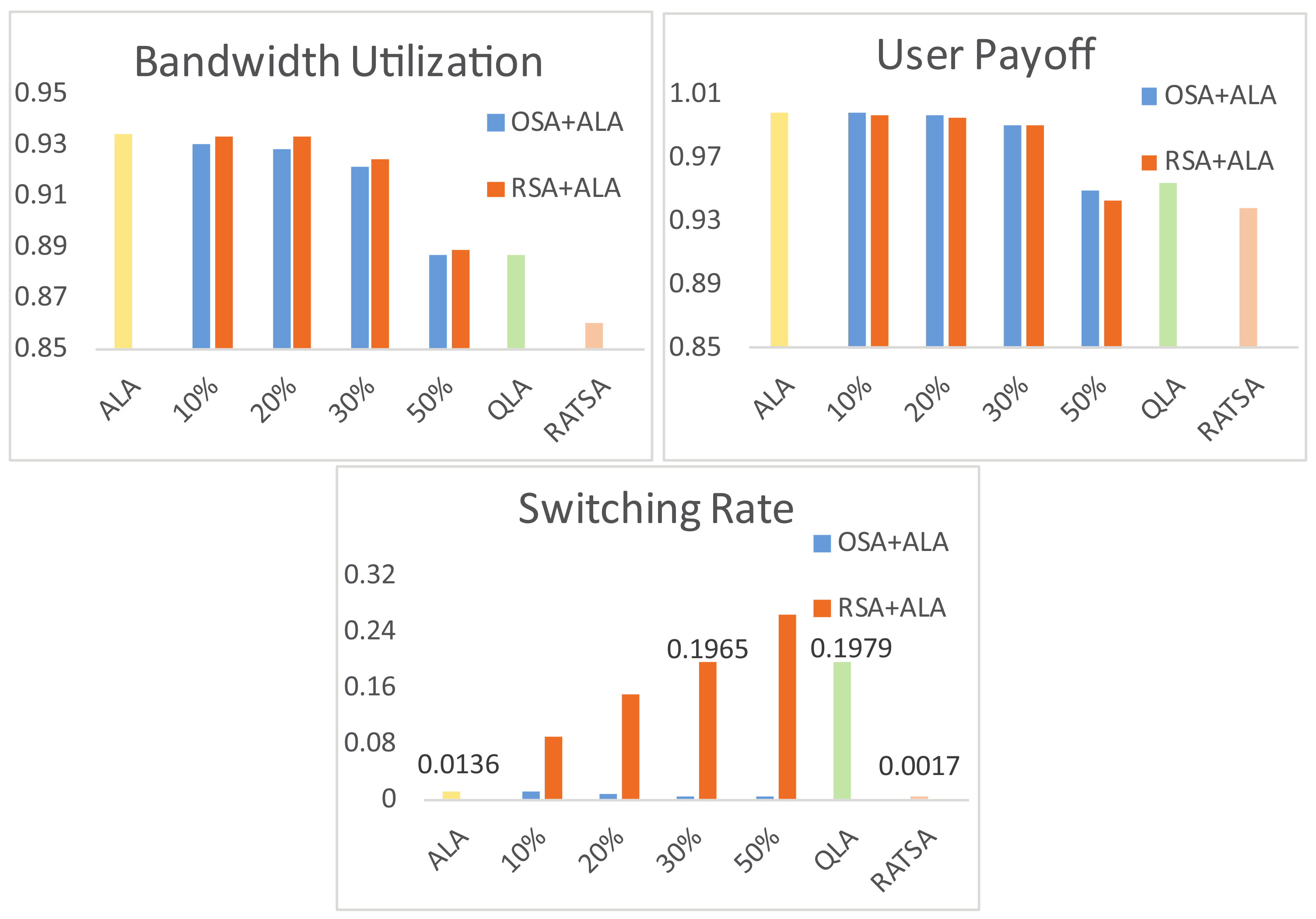
4.2. Experiment Comparisons
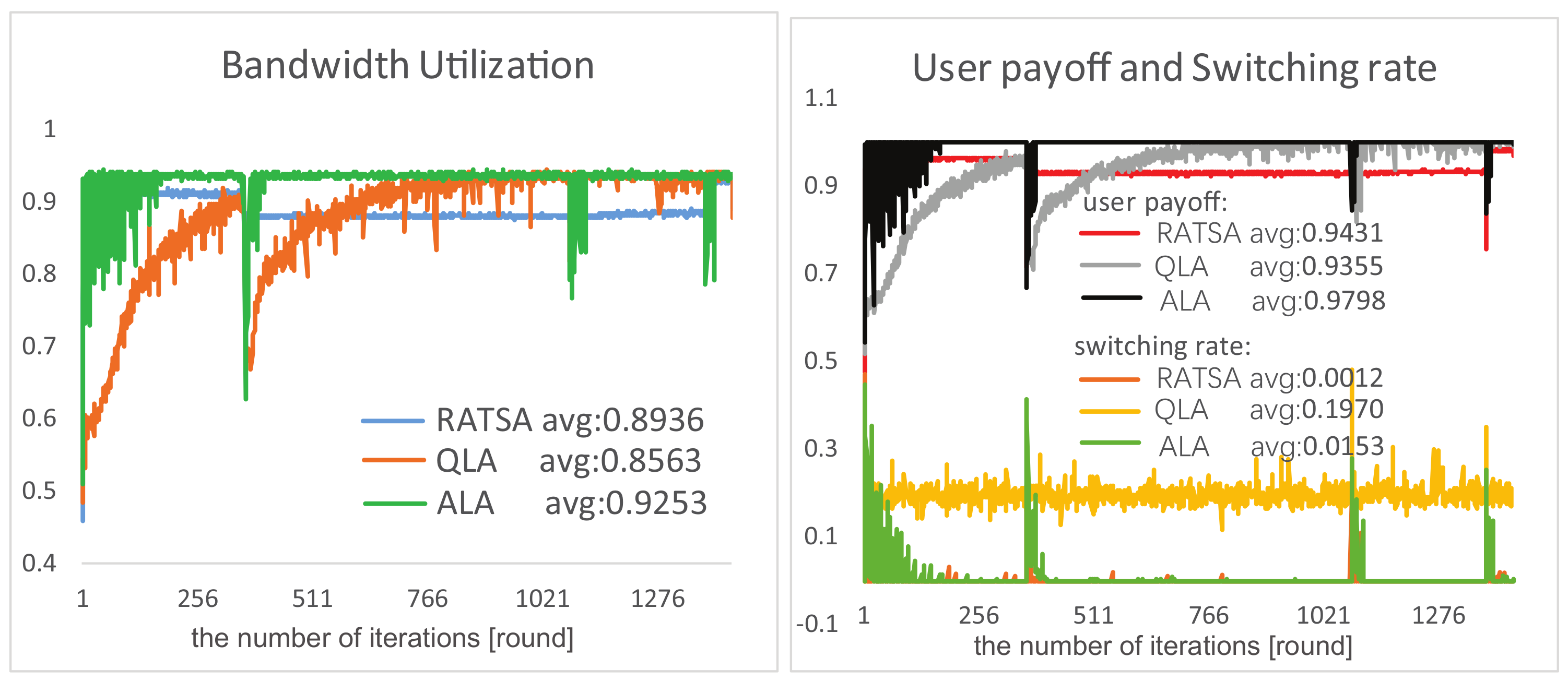
4.3. Robustness Testing
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wang, C.X.; Haider, F.; Gao, X.; You, X.H. Cellular architecture and key technologies for 5G wireless communication networks. Commun. Mag. IEEE 2014, 52, 122–130. [Google Scholar] [CrossRef]
- Andrews, J.G.; Buzzi, S.; Choi, W.; Hanly, S.V.; Lozano, A.; Soong, A.C.; Zhang, J.C. What will 5G be? IEEE J. Sel. Areas Commun. 2014, 32, 1065–1082. [Google Scholar] [CrossRef]
- Chin, W.H.; Fan, Z.; Haines, R. Emerging technologies and research challenges for 5G wireless networks. IEEE Wirel. Commun. 2014, 21, 106–112. [Google Scholar] [CrossRef]
- Trestian, R.; Ormond, O.; Muntean, G.M. Game theory-based network selection: Solutions and challenges. IEEE Commun. Surv. Tutor. 2012, 14, 1212–1231. [Google Scholar] [CrossRef]
- Martinez-Morales, J.D.; Pineda-Rico, U.; Stevens-Navarro, E. Performance comparison between MADM algorithms for vertical handoff in 4G networks. In Proceedings of the 2010 7th International Conference on Electrical Engineering Computing Science and Automatic Control (CCE), Tuxtla Gutierrez, Mexico, 8–10 September 2010; pp. 309–314. [Google Scholar]
- Lahby, M.; Cherkaoui, L.; Adib, A. An enhanced-TOPSIS based network selection technique for next generation wireless networks. In Proceedings of the 2013 20th International Conference on Telecommunications (ICT), Casablanca, Morocco, 6–8 May 2013; pp. 1–5. [Google Scholar]
- Lahby, M.; Adib, A. Network selection mechanism by using M-AHP/GRA for heterogeneous networks. In Proceedings of the 2013 6th Joint IFIP Wireless and Mobile Networking Conference (WMNC), Dubai, UAE, 23–25 April 2013; pp. 1–6. [Google Scholar]
- Wang, L.; Kuo, G.S.G. Mathematical modeling for network selection in heterogeneous wireless networks—A tutorial. IEEE Commun. Surv. Tutor. 2013, 15, 271–292. [Google Scholar] [CrossRef]
- Niyato, D.; Hossain, E. Dynamics of network selection in heterogeneous wireless networks: An evolutionary game approach. IEEE Trans. Veh. Technol. 2009, 58, 2008–2017. [Google Scholar] [CrossRef]
- Wu, Q.; Du, Z.; Yang, P.; Yao, Y.D.; Wang, J. Traffic-aware online network selection in heterogeneous wireless networks. IEEE Trans. Veh. Technol. 2016, 65, 381–397. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, J.; Wu, Q. Distributed learning of equilibria with incomplete, dynamic, and uncertain information in wireless communication networks. Prov. Med. J. Retrosp. Med. Sci. 2016, 4, 306. [Google Scholar]
- Vamvakas, P.; Tsiropoulou, E.E.; Papavassiliou, S. Dynamic Provider Selection & Power Resource Management in Competitive Wireless Communication Markets. Mob. Netw. Appl. 2018, 23, 86–99. [Google Scholar]
- Tsiropoulou, E.E.; Katsinis, G.K.; Filios, A.; Papavassiliou, S. On the Problem of Optimal Cell Selection and Uplink Power Control in Open Access Multi-service Two-Tier Femtocell Networks. In Lecture Notes in Computer Science Description; Springer: Berlin, Germany, 2014; pp. 114–127. [Google Scholar]
- Hao, J.; Leung, H.F. Achieving socially optimal outcomes in multiagent systems with reinforcement social learning. ACM Trans. Auton. Adapt. Syst. 2013, 8, 15. [Google Scholar] [CrossRef]
- Malanchini, I.; Cesana, M.; Gatti, N. Network selection and resource allocation games for wireless access networks. IEEE Trans. Mob. Comput. 2013, 12, 2427–2440. [Google Scholar] [CrossRef] [Green Version]
- Aryafar, E.; Keshavarz-Haddad, A.; Wang, M.; Chiang, M. RAT selection games in HetNets. In Proceedings of the 2013 IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 998–1006. [Google Scholar]
- Monsef, E.; Keshavarz-Haddad, A.; Aryafar, E.; Saniie, J.; Chiang, M. Convergence properties of general network selection games. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; pp. 1445–1453. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar]
- Busoniu, L.; Babuska, R.; De Schutter, B. A comprehensive survey of multiagent reinforcement learning. IEEE Trans. Syst. Man Cybern. C 2008, 38, 156–172. [Google Scholar] [CrossRef]
- Barve, S.S.; Kulkarni, P. Dynamic channel selection and routing through reinforcement learning in cognitive radio networks. In Proceedings of the 2012 IEEE International Conference on Computational Intelligence Computing Research, Coimbatore, India, 18–20 December 2012; pp. 1–7. [Google Scholar]
- Xu, Y.; Chen, J.; Ma, L.; Lang, G. Q-Learning Based Network Selection for WCDMA/WLAN Heterogeneous Wireless Networks. In Proceedings of the 2014 IEEE 79th Vehicular Technology Conference (VTC Spring), Seoul, Korea, 18–21 May 2014; pp. 1–5. [Google Scholar]
- Kittiwaytang, K.; Chanloha, P.; Aswakul, C. CTM-Based Reinforcement Learning Strategy for Optimal Heterogeneous Wireless Network Selection. In Proceedings of the 2010 Second International Conference on Computational Intelligence, Modelling and Simulation (CIMSiM), Tuban, Indonesia, 28–30 September 2010; pp. 73–78. [Google Scholar]
- Demestichas, P.; Georgakopoulos, A.; Karvounas, D.; Tsagkaris, K.; Stavroulaki, V.; Lu, J.; Xiong, C.; Yao, J. 5G on the horizon: Key challenges for the radio-access network. IEEE Veh. Technol. Mag. 2013, 8, 47–53. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, L. Green Base Station Solutions and Technology. Zte Commun. 2011, 9, 58–61. [Google Scholar]
- Oh, E.; Krishnamachari, B. Energy savings through dynamic base station switching in cellular wireless access networks. In Proceedings of the 2010 IEEE Global Telecommunications Conference (GLOBECOM 2010), Miami, FL, USA, 6–10 December 2010; pp. 1–5. [Google Scholar]
- Hao, J.Y.; Huang, D.P.; Cai, Y.; Leung, H.F. The dynamics of reinforcement social learning in networked cooperative multiagent systems. Eng. Appl. Artif. Intell. 2017, 58, 111–122. [Google Scholar] [CrossRef]
- Sachs, J.; Prytz, M.; Gebert, J. Multi-access management in heterogeneous networks. Wirel. Pers. Commun. 2009, 48, 7–32. [Google Scholar] [CrossRef]
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting; Springer: Berlin, Germany, 2016. [Google Scholar]
- Kianercy, A.; Galstyan, A. Dynamics of Boltzmann q learning in two-player two-action games. Phys. Rev. E 2012, 85, 041145. [Google Scholar] [CrossRef] [PubMed]
- Zhu, K.; Niyato, D.; Wang, P. Network Selection in Heterogeneous Wireless Networks: Evolution with Incomplete Information. In Proceedings of the 2010 IEEE Wireless Communications and NETWORKING Conference (WCNC), Sydney, Australia, 18–21 April 2010; pp. 1–6. [Google Scholar]
- Mcgarry, M.P.; Maier, M.; Reisslein, M. Ethernet pons: A survey of dynamic bandwidth allocation (dba) algorithms. IEEE Commun. Mag. 2004, 42, 8–15. [Google Scholar] [CrossRef]
- Malialis, K.; Devlin, S.; Kudenko, D. Resource abstraction for reinforcement learning in multiagent congestion problems. In Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems, Singapore, 9–13 May 2016; pp. 503–511. [Google Scholar]
- Li, J.Y.; Qiu, M.K.; Ming, Z.; Quan, G.; Qin, X.; Gu, Z.H. Online optimization for scheduling preemptable tasks on IaaS cloud systems. Int. J. Comput. Sci. Mob. Comput. 2013, 2, 666–677. [Google Scholar] [CrossRef]
- Hao, J.Y.; Sun, J.; Chen, G.Y.; Wang, Z.; Yu, C.; Ming, Z. Efficient and Robust Emergence of Norms through Heuristic Collective Learning. ACM Trans. Auton. Adapt. Syst. 2017, 12, 1–20. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Description (Window Size ) |
|---|---|
| Weighted Average | |
| Geometric Average | |
| Linear Regression | ( can be obtained by using least square method) |
| Exponential Smoothing | |
| Access Tech | Network Rep | Base Station | Maximum Bandwidth | User Demand |
|---|---|---|---|---|
| WLAN | Wi-Fi | 25 Mbps | voice traffic: 32 kbps | |
| WMAN | WiMAX | 50 Mbps | data traffic: 64 | |
| OFDMA Cellular Network | 4G | 5 Mbps | kbps ∼ 128 kbps |
| Algorithm | ALA | RATSA | QLA |
|---|---|---|---|
| common information required | before selection: BS candidates; bandwidth demand. after selection: perceived bandwidth w from selected BS. | ||
| different information required | 1. previous provided bandw-idth of selected BS. 2. histroical load on selected BS. | 1. future provided bandwidth of each BS. 2. number of users on each BS. 3. number of past consecutive migrations on selected BS. | – |
| base stations to be communicated | selected BS | all BS candidates | selected BS |
| influencing parameter | – | switching threshold | – |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Cao, R.; Hao, J. An Adaptive Learning Based Network Selection Approach for 5G Dynamic Environments. Entropy 2018, 20, 236. https://doi.org/10.3390/e20040236
Li X, Cao R, Hao J. An Adaptive Learning Based Network Selection Approach for 5G Dynamic Environments. Entropy. 2018; 20(4):236. https://doi.org/10.3390/e20040236
Chicago/Turabian StyleLi, Xiaohong, Ru Cao, and Jianye Hao. 2018. "An Adaptive Learning Based Network Selection Approach for 5G Dynamic Environments" Entropy 20, no. 4: 236. https://doi.org/10.3390/e20040236
APA StyleLi, X., Cao, R., & Hao, J. (2018). An Adaptive Learning Based Network Selection Approach for 5G Dynamic Environments. Entropy, 20(4), 236. https://doi.org/10.3390/e20040236