1. Introduction
Network science provides a powerful framework for modelling and understanding how individual entities give rise to complex—and often unexpected—phenomena by interacting with each other [
1,
2,
3,
4,
5,
6]. Network models encapsulate the topology of interactions among entities by means of links distributed among nodes. Defining the centrality of nodes in complex networks is an important question for determining the role of individual agents in a variety of dynamical processes such as information flow and influence maximisation [
7,
8,
9], network growth [
1], and resilience to cascade failures [
10,
11].
In many of these processes, centrality can be defined by means of network distance—that is, the minimum number of links separating any two nodes. Overwhelming evidence from real-world network analysis has shown how distance among nodes is an important indicator of the evolution of a given process: in general, information flows at slower rates between nodes at greater distance in social networks [
7]; the recollection of words at greater distance in semantic networks in memory tasks is slower [
12]; smaller network distance between oscillators facilitates synchronization [
9] and consensus [
13]; and there is a higher turnover rate of animal and plant species among closer sites in river networks [
14].
Network distance can be used to quantify a node’s centrality in spreading processes where the flow follows shortest paths and such centrality is called closeness [
7,
15]. Closeness centrality quantifies the average distance of all the network paths leading to a given node. In undirected, unweighted networks, closeness centrality
of node
i (
) is defined as [
15]:
where
is the number of nodes in the same connected component of
i and
is the network distance between nodes
i and
j. It is worth noting that
for networks with a single connected component. It has been shown that this estimator is ill-defined in the case of disconnected networks [
16]; however, in the following we will deal only with connected networks and we can safely use the above definition of closeness centrality.
Closeness centrality has proved to be powerful in many real-world applications [
7,
11,
17,
18,
19]. Recently, the closeness centrality of words in multiplex lexical networks of word–word similarities resulted as an optimal predictor of word learning [
18], outperforming other single- and multi-layer network measures such as degree, betweenness, local clustering, PageRank, eigenvector centralities, and even word statistical features such as frequency and word length. In this work, we enrich closeness centrality with a new measure of
distance entropy, quantifying node centrality through the distribution of path lengths. We develop our analysis within the established framework of graph distance-based entropies [
20,
21,
22,
23], which represent information-theoretic measures for characterising structural patterns in graphs. We test the combination of distance entropy and closeness centrality—a composition we call
distance entropy cartography—in artificial network models and then apply it to improving word prediction based on closeness only. Distance entropy significantly improves the already optimal results of closeness for the prediction of word learning. These improvements are not observed when closeness is coupled with other centrality measures such as degree. Our results provide compelling evidence for the importance of considering information measures relative to shortest paths for gaining insights into real-world complex systems.
2. Introducing a New Distance Entropy
The definition of a graph entropy for a network
G with
N nodes relies on the choice for an information functional
to attribute to each node (e.g., degree centrality). The information functional determines a node probability
for each node
i, and the relative graph entropy is defined as the Shannon entropy of the probabilities
(
) [
20].
Closeness centrality represents the inverse of the mean value of the distribution of path lengths from a given node to the rest of the system. Hence, closeness alone offers no information about the spread of the distribution of network distances. To account for this spread, we introduce the
distance entropy , defined as the information entropy of the set
of distances between node
i and any other node
j in the system, here assumed to be of size
N (
). Let us denote with
the maximum distance
and with
the minimum distance
. Let us denote by
with
, the probability that the generic entry
is equal to
k. If node
i is at distance
k from
other nodes, then
. In the graph entropy literature,
represents our chosen information functional. Chen et al. [
21] considered the same information functional, but they limited themselves to considering only nodes of a given specific distance
k from node
i, at variance with our approach considering all possible distances (
). Other approaches used distances as information functionals, but did not consider counting paths of a given length (for a review, we refer the interested reader to [
20,
23]). We exclude the distance of a node from itself. In this analysis, we introduce the following definition of distance entropy as:
With this definition,
ranges between 0 and 1. Note that our definition can also be generalised to strongly connected components [
2] of directed networks by counting lengths in directed paths. The extension to weighted networks is not trivial, as the definition of shortest paths in this case is not unique [
24,
25,
26]. Here we explore the case of undirected, unweighted graph models and real-world networks.
It is worth remarking that we can interpret the meaning of the extremal values of our distance entropy in terms of network centrality by considering specific classes of regular graphs, as in the following.
Distance Entropy in Regular Graphs
Let us consider a complete graph of N nodes, . In this graph, node i is at distance 1 from all the other nodes, so then is a set of entries, all equal to 1. It is straightforward to verify that, in this case, the information entropy for node i is . The same analysis holds for all the other nodes in the complete graph. Hence, all the nodes in a complete graph have distance entropy . More generally, distance entropy is 0 for all nodes adjacent to all other nodes in any given network.
In star graphs, there is a central node connected to all other peripheral nodes and no other links are present. The result for nodes in complete graphs also holds for the star centre. Consequently, the centres of star graphs have distance entropy . Hence, we can interpret distance entropy as a measure of the regularity of the distribution of path lengths between a given node and its neighbours, with representing the case of maximum homogeneity in the path length distribution. Since it is not possible for a node to be at distance from all other nodes simultaneously in a connected network, then identifies nodes adjacent to all other nodes.
In a ring graph where
nodes have only two neighbours, then every node has the same set of distances to the other
nodes and the possible distances are
, where
is the floor function. If
N is odd, then it is easy to check that
. Consequently, the entropy of any node
i in a ring graph with an odd number of nodes is:
Hence, when N is odd, then all nodes in a ring graph have maximum distance entropy , which corresponds to the case of minimum homogeneity of path lengths; that is, paths between connected nodes have lengths that are distributed uniformly across all possible distances.
When
N is even, then
except for
, for which
. Then the formula for the distance entropy of a node becomes:
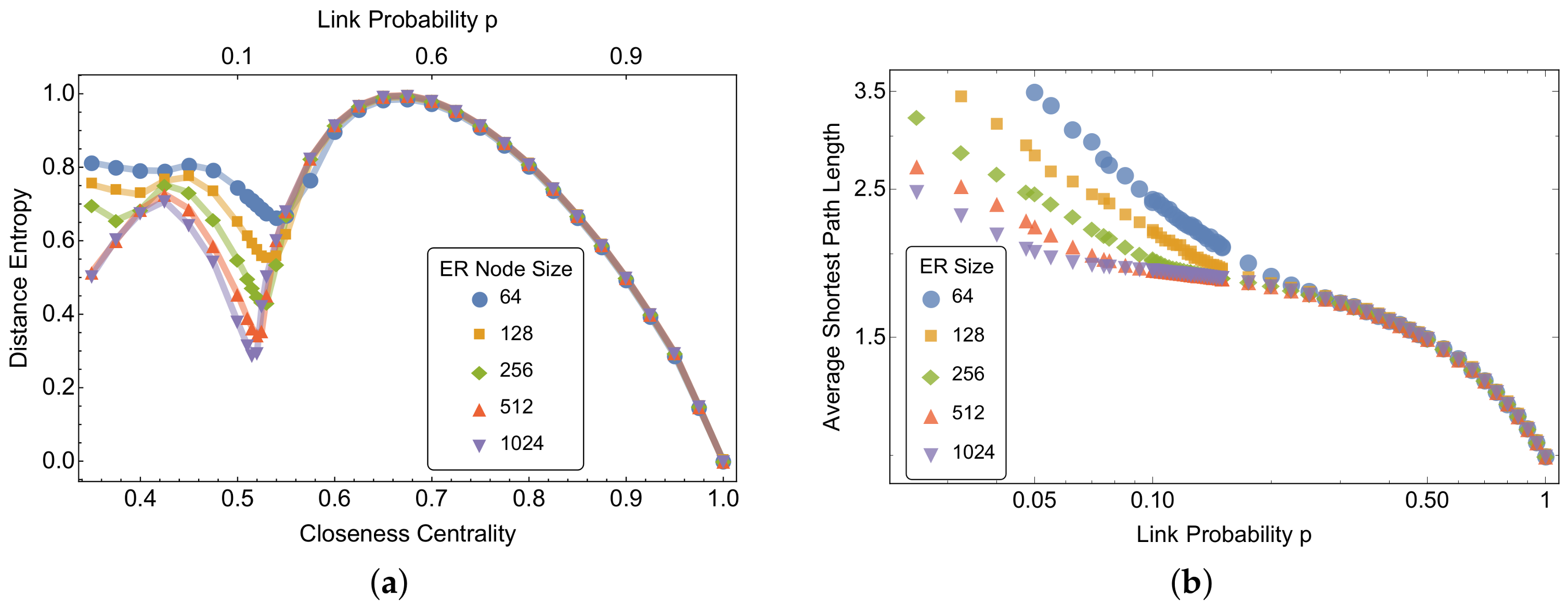
Note that ring graphs are lattice graphs for which the coordination number (i.e., every node is connected only to two other nodes). While the analytical results for ring graphs can also be extended to cases for , when z approaches the lattice becomes a complete graph and hence for every node. When , instead, results similar to the ring lattices hold and the lattice nodes are expected to have values of distance entropy close to 1. Rather than considering other regular structures, we now focus on characterising patterns of distance entropy in network models frequently used in the relevant literature.
4. Cartography Based on Distance Entropy and Closeness Centrality
In the previous sections, we focused on characterising the mean distance entropy of networks by considering different models. We now focus on the structural patterns of individual nodes that emerge by considering closeness centrality and distance entropy together in one given network. We consider distance entropy as an estimator of the variation of distances of a given node from all its neighbours, thus providing additional information compared to considering closeness centrality only (which reports only on the mean distance of a node from the other nodes).
We combine information from both the closeness and distance entropy of a node by introducing the concept of
distance entropy cartography. We draw inspiration from the concept of cartography introduced by Guimerá and Amaral for characterising the role played by individual nodes in community structure [
29], a concept later generalised to the participation of nodes on multiplex structures [
30]. Network cartographies are useful for visualising the map of topological patterns that nodes have in a given network structure.
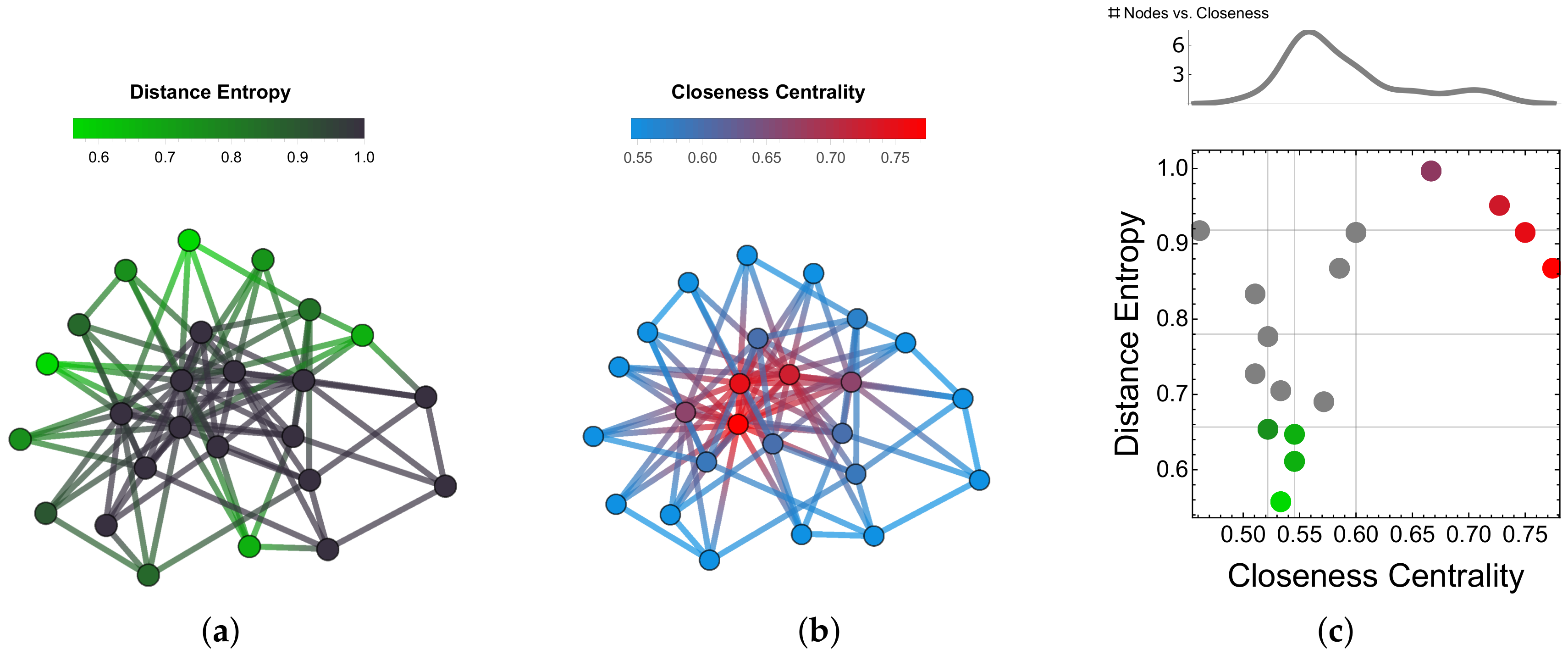
In
Figure 4 we show an example of distance entropy cartography for a toy model (BA network with
and
nodes). Sub-panel (a) highlights nodes with the lowest distance entropy (i.e., a more homogeneous distribution of network distances) while (b) highlights nodes with the highest closeness centrality (i.e., at shortest average distance in the network). Note that nodes with higher closeness centrality also tend to have higher distance entropy, as they are closer to each other but further apart from peripheral nodes. Consequently, the set of nodes with high closeness does not overlap with the set of nodes with low distance entropy—the two metrics provide complementary information. We define a cartography by a 2D space where each node has its distance entropy and its closeness as coordinates (sub-panel (c)). Representing nodes in this 2D space is informative; in fact, most of the nodes in the network have similar closeness centrality around
(see also sub-panel (c), top plot) but display evidently different values of distance entropy, ranging from
up to
. Hence, considering distance entropy can help to reduce the degeneracy observed when considering closeness only: nodes having similar closeness centrality are found—by means of the distance entropy—to be differently connected to the rest of the network.
5. Applying Distance Entropy Cartography to Multiplex Lexical Networks
We apply the cartographic analysis previously introduced to multiplex lexical networks [
6,
31], successfully applied for modelling trends of progressive language impairments such as aphasia [
19], but also patterns of language development such as modelling and predicting strategies of word learning in toddlers [
18]. When considering multiplex lexical networks and learning, we wonder if distance entropy can provide any improvement for detecting word learning strategies in toddlers.
Here, we use the same empirical networks used in [
18] (i.e., multi-layer edge-coloured networks where nodes represent words). There are no explicit inter-layer links, and layers represent semantic relationships (e.g., “dog” and “cat” share the feature of being an animal) and phonological similarities (e.g., “bad” and “bed” differ by one phoneme only) among words. For ranking words in the order they are learned by most English toddlers between 18 and 30 months of age, we use longitudinal data from the CHILDES dataset accessed through TalkBank [
32]. The longitudinal data allows the reconstruction of the fraction of children producing a certain word in a given month (i.e., production probability). Within each month, words are ranked in descending order of production probability. This ranking represents a proxy for the normative learning of most toddlers [
18,
33,
34].
Recently, different network approaches have been successfully used for predicting the acquisition of words based on their network features (e.g., word degree, closeness centrality, network gaps) [
18,
33,
35,
36]. Here, we rank words according to the introduced cartography and then compare against the ranking of the estimated age of acquisition, in which words acquired earlier (e.g., “mommy”) are ranked higher than words learned later (e.g., “picture”). The extent to which an artificial ranking
predicts the words learned according to the normative learning ranking
is measured through the word gain:
representing at position
t the fraction of words predicted as
correctly learned in
by the network ranking
(
), with respect to random guessing (
). A word gain of
when
words have been learned means that
predicts as correctly learned 40 words more than random ranking.
Multiplex closeness centrality provides a word gain higher than other measures (e.g., betweenness, degree, and local clustering coefficient) on both single and multiplex network topologies [
18]. Hence, here we focus on the ranking
of descending closeness centrality and use it as a reference level to test whether enriching it with information from distance entropy can achieve higher word gains. Distance entropy is computed on the multiplex shortest paths, namely the shortest paths where links from different layers can be combined together [
3]. The resulting cartography is shown in
Figure 5.
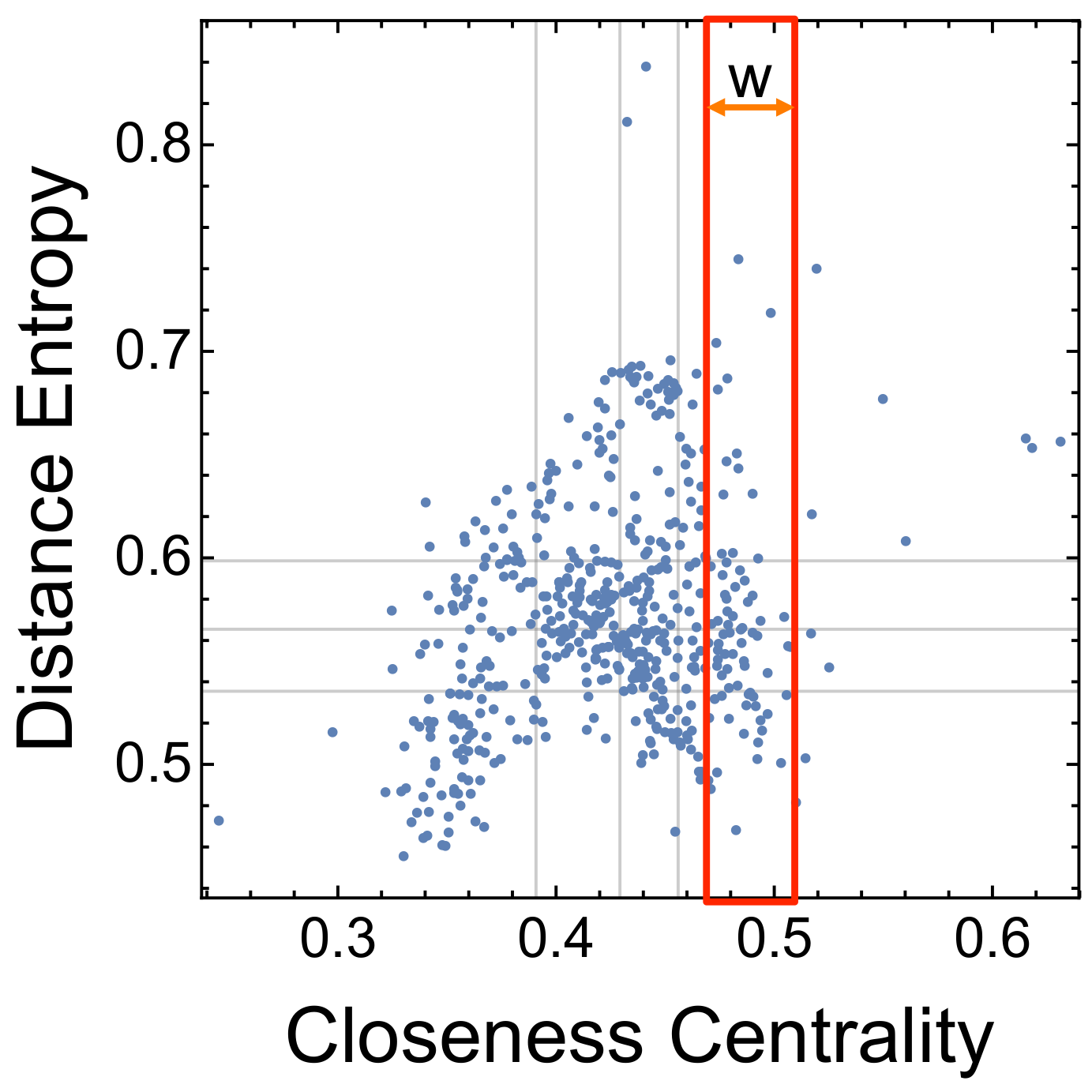
The distance entropy cartography indicates that many nodes with similar closeness centrality differ highly in their distance entropy. We quantify this notion of closeness similarity by considering nodes having closeness around within an interval . Here w represents an interval width, a tolerance parameter determining which nodes have closeness similar to up to a value w. If , then our definition of similarity would reduce to identifying ties (i.e., considering as similar nodes having the same value of closeness ). Provided its interpretation in terms of similarity, we consider values .
We use the cartography and closeness similarity for building artificial rankings of words based on both closeness centrality and distance entropy. Starting from the maximum value of closeness
in the network, we build bins
. A ranking
is produced by ranking all nodes in bin
in increasing order of distance entropy. Within each bin
we rank nodes from lower to higher distance entropy because the lower
, the more a node
j is connected to all other nodes in the network. Hence, nodes with lower distance entropy are expected to be more central in the network. Note that distance entropy provides different information compared to other multiplex centrality measures such as multidegree [
3] or PageRank versatility [
37], since the induced node rankings overlap with distance entropy only for
(Kendall Tau
) and
(Kendall Tau
) respectively.
Note also that when i increases the average closeness of the considered nodes decreases, so is a rank in which: (i) highest closeness nodes are on average ranked higher; (ii) nodes with closeness similar up to a tolerance w are ranked according to their distance entropy. Hence, in , words in the left-lower part of the entropic cartography are ranked higher (i.e., words with high closeness and low distance entropy).
This ranking is a function of the window w: when , then distance entropy has no effect and is equivalent to ranking nodes in descending order of closeness (); when , then all the nodes are ranked according to their distance entropy and closeness plays no role in affecting the ordering. We investigate the influence of w in providing ranks mixing distance entropy and closeness centrality for improving prediction performances (i.e., increasing the average word gain). We focus on the early stages of cognitive development between months 20 and 23, which are called the Early Learning Stage in which multiplex closeness centrality provided the highest word gains.
We measure increases or decreases in prediction power of which words are learned early by toddlers by considering a relative word gain improvement:
A relative word gain improvement means that when 150 have been learned, the ranking considering together closeness and distance entropy predicts as correctly learned more words than considering closeness only. Provided that improvements depend on the value of w, a scan of different values is essential. For each value of w, we compare the observed improvement against a distribution of random improvements obtained by fixing the same w and the same bins but ranking words at random rather than according to their distance entropy. These randomised ranks represent our null models and allow one to quantify the statistical significance of word gain improvements observed when using the cartography.
Table 1 reports the word gain improvements averaged between months 20 and 23 (the Early Learning Stage) for different values of
w. When
, positive improvements in word gain are registered, while for
only negative improvements are retrieved. The registered positive improvements are statistically significant at a 0.01 significance level when
, indicating the presence of a window where learning high closeness words with low distance entropy leads to marked improvements in predicting which words are learned by toddlers. In such cases, the average word gain achieved with the entropic cartography is
.
How do the results of the distance entropy cartography compare against other centrality measures? In order to test the importance of distance entropy, we binned nodes in terms of decreasing closeness centrality but ordered them in decreasing order of multidegree centrality within bins of the same width from the distance entropy cartography. Using degree rather than distance entropy remarkably worsened prediction performances, as it produced on average only negative improvements of word gain ().
These results indicate that considering distance entropy on top of the multiplex closeness centrality is beneficial for achieving better predictions of the way most English toddlers learn words. All in all, this application to real-world networks indicates that the topological information encapsulated in the distance entropy can provide additional insights in discovering and interpreting patterns of real-world complex systems.
6. Discussion
In this paper, we introduce a new type of distance entropy, characterising the distribution of path lengths from a given node in a network. Compared to previous important results in the field [
20,
21,
22,
23], our main novelty is in considering the entropy of paths of all lengths at local and global levels. We provide analytical results for the distance entropy of individual nodes in regular graphs and show that it is minimum when a node is adjacent to all other nodes in the network. From the analysis of the mean distance entropy in well-known network models such as ER random graphs, BA scale-free networks, and small-world networks, we observe that the creation of links either uniformly at random or through preferential attachment generally decreases the heterogeneity of path lengths, decreasing distance entropy. There is a noticeable exception in ER random graphs, where we observe a tipping point for distance entropy in increasingly denser ER random graphs. We attribute this change to the sudden emergence of short-cuts in the system. No tipping points have been detected in small-world and BA scale-free networks.
Note that our definition of distance entropy considers only shortest paths, in contrast to other information-theoretic network measures based on network distance such as the centrality information introduced in [
38] or the resistance centrality from [
39]. Both these quantities strongly correlate with closeness centrality, since they are mainly variations of this measure, at variance with the distance entropy measure proposed in this work.
In fact, we provide evidence that distance entropy carries different topological information compared to other measures based on distance, such as closeness centrality. Note that closeness is combined with distance entropy because they are both relative to shortest path lengths: closeness is the mean of the distribution of path lengths, while distance entropy is related to its variance (i.e., maximum entropy indicates paths of all possible path lengths, minimum entropy indicates null variance). Consequently, because of this strong tie, we focused mainly on closeness and distance entropy for defining the distance entropy cartography to better characterise nodes’ centrality in complex networks. The additional information carried by distance entropy allows one to further distinguish nodes with equal (or very similar) closeness centralities, thanks to the fact that such nodes can be more or less heterogeneously distant from the rest of the system.
In the current study, the concept of closeness similarity has been parametrised by means of a parameter w representing the tolerance up to which two nodes are considered having similar closeness centralities. We did not fix w in the current analysis in order to prevent overfitting, however its interpretation as a tolerance indicates that . Additional criteria from statistics such as using percentiles or data clustering techniques could be pursued in future work.
We use the information combined by the cartography to rank words in multiplex lexical networks [
6,
18,
19] and to predict the order with which toddlers learn words during cognitive development. We show that resolving the degeneracy of nodes with similar closeness centrality but (very) different distance entropy provides consistently positive improvements in predicting word learning strategies by at least
. Although these improvements might seem small, two additional elements must be considered. Firstly, multiplex closeness centrality is already an optimal measure of word prediction, in the sense that it vastly outperformed single- and multi-layer versions of degree, betweenness, local clustering, PageRank, and eigenvector centralities in early word prediction, so that improvements to its prediction performances are remarkable. Secondly, distance entropy provides positive improvements that are not captured by other network statistics such as degree, which conversely provides negative word gain (≈−15%) for the same values of
w. This result underlines the importance of considering distance entropy.
Our results provide evidence that English-speaking toddlers mainly tend to acquire words with high closeness centrality and low distance entropy early on during language acquisition. These words display less heterogeneous distributions of path lengths, with smaller central moments, on the whole multiplex lexical structure, and are thus easier to reach from other words in the mental lexicon. From the perspective of the cognitive sciences, the improvement in the prediction of word learning indicates a cognitive advantage in learning words more central for the spread of information within the mental lexicon of word-similarities. This finding is in agreement with other independent studies indicating that closer words in linguistic networks are more easily identified in healthy subjects [
17] and produced in subjects with aphasia [
19]. Note that a drawback of our modelling approach is that it does not account for individual differences in word learning, but rather refers to the average trend at the population level of healthy English-speaking toddlers. Quantifying the powerfulness of distance entropy cartography for predicting the word learning of individuals requires additional data, and it poses an interesting direction for future research.
From a network perspective, distance entropy provides different topological information compared to closeness centrality, but the two measures share the same computational cost. Hence, the proposed cartography can also be used for investigating large-scale networks, providing an important tool for the investigation of structural patterns in real-world networks where the distances among nodes matter.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}