Quantifying the Effects of Topology and Weight for Link Prediction in Weighted Complex Networks


Abstract
:1. Introduction
2. Data and Methods
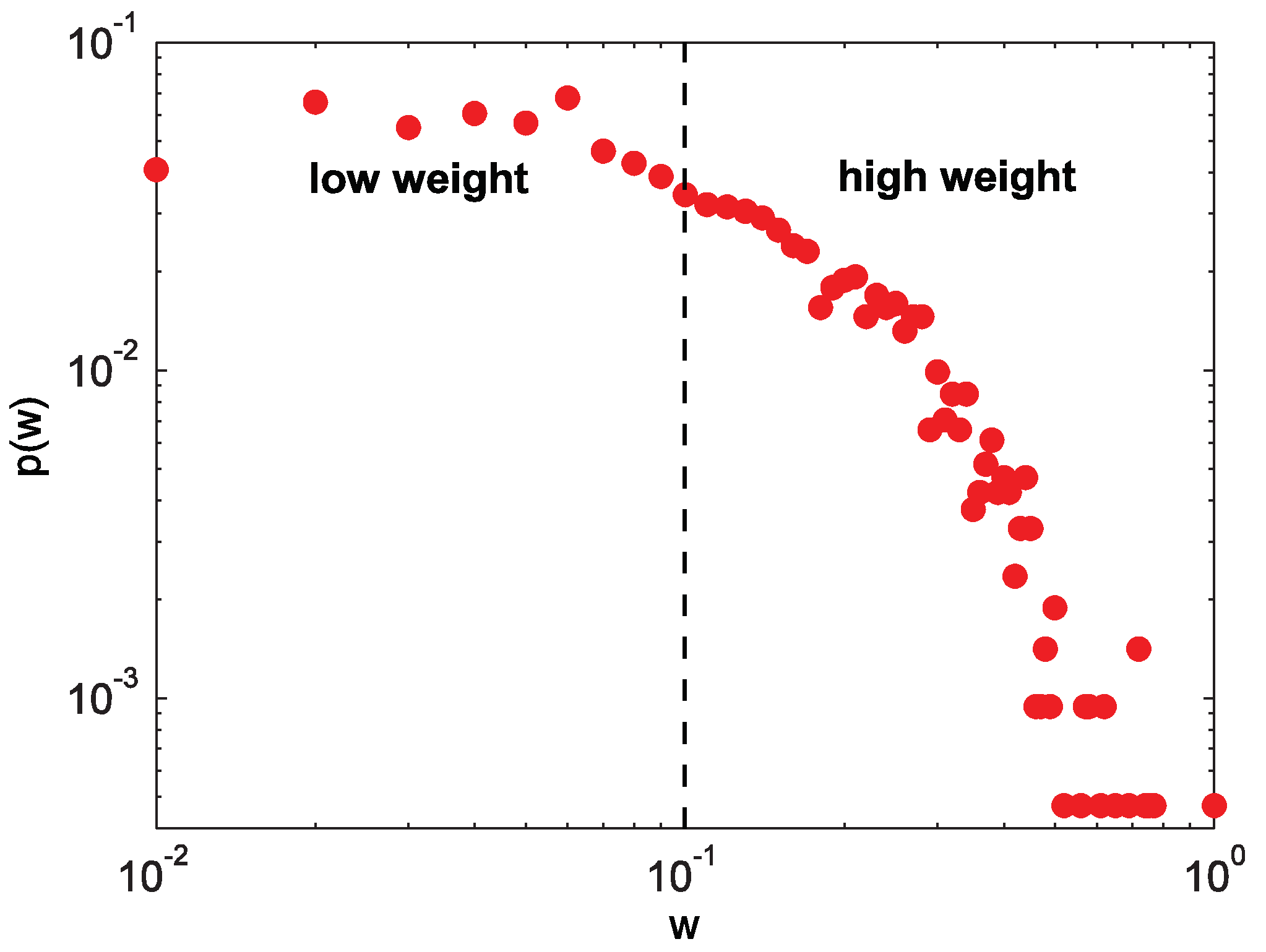
2.1. The Description of the Empirical Networks
2.2. Unweighted Similarity Indices Based on Local Information
2.3. Weighted Similarity Indices Based on Local Information
2.4. Two Evaluation Indexes of Link Prediction
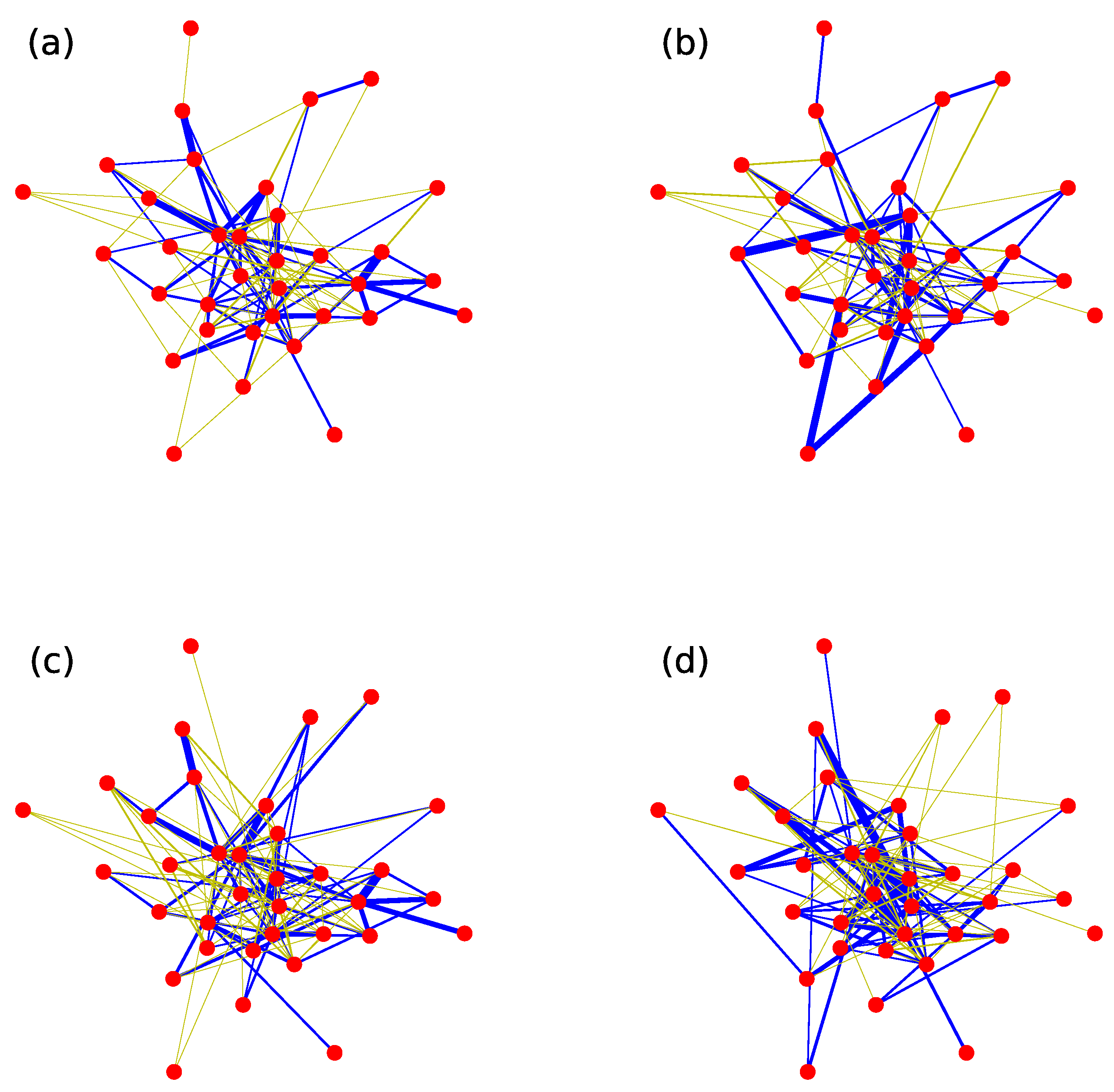
3. The Null Models of Weighted Networks
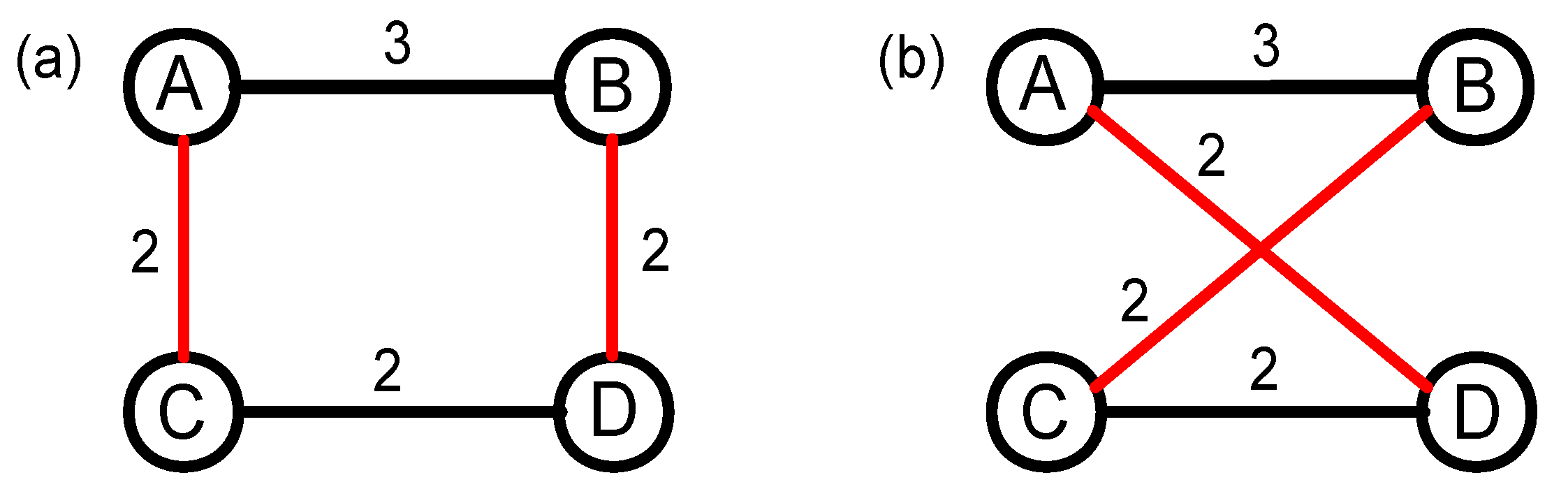
3.1. The 1k Null Model
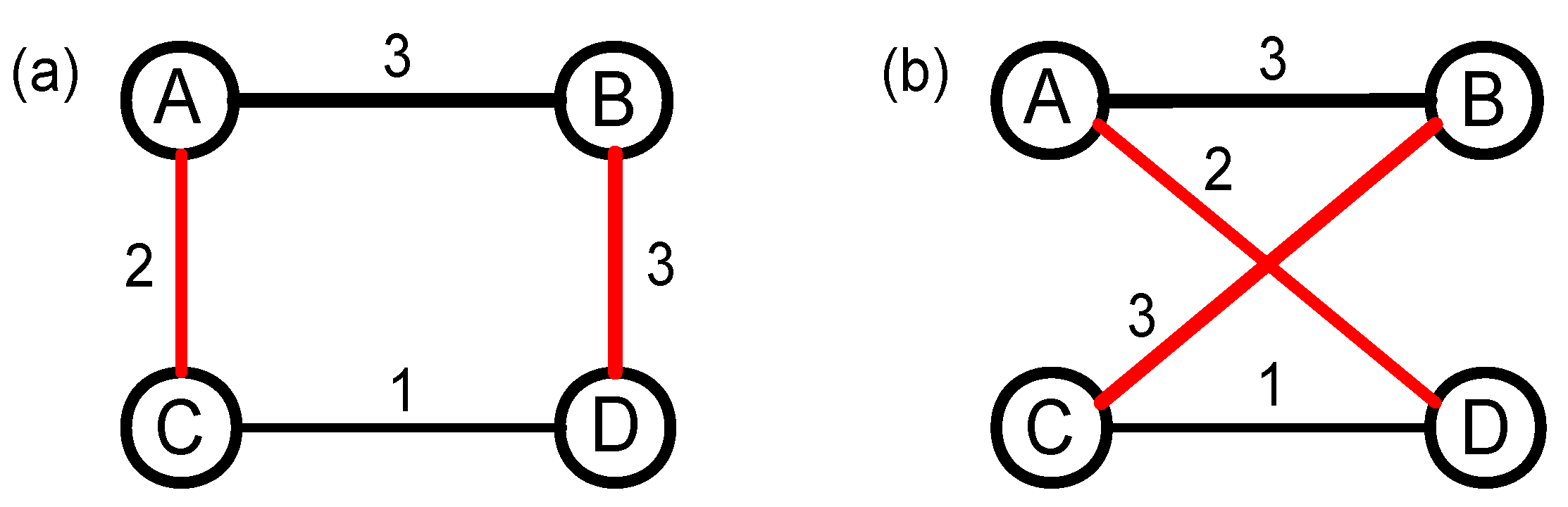
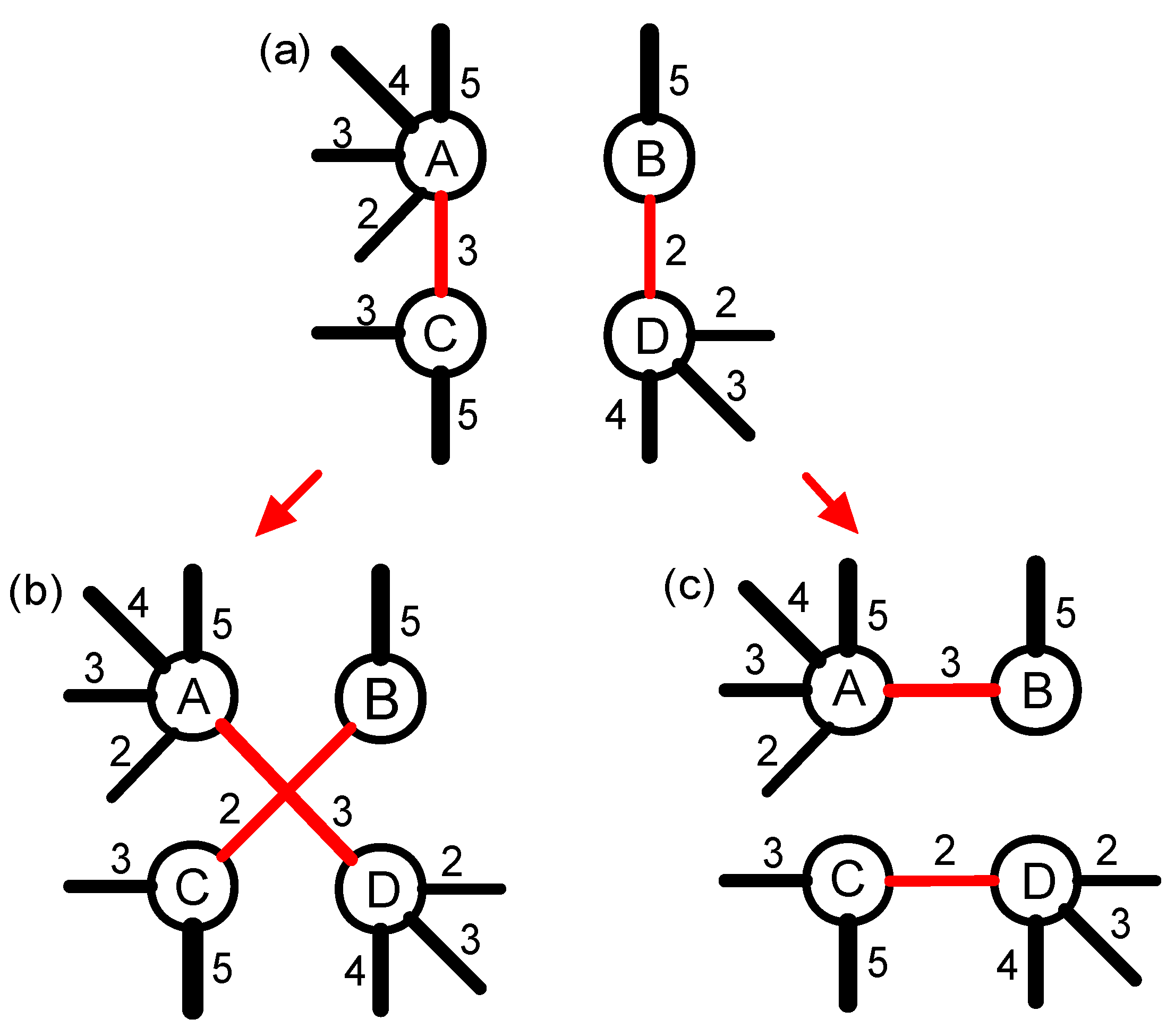
3.2. The Structure-Shuffling Null Network
3.3. The Weight-Shuffling Null Network
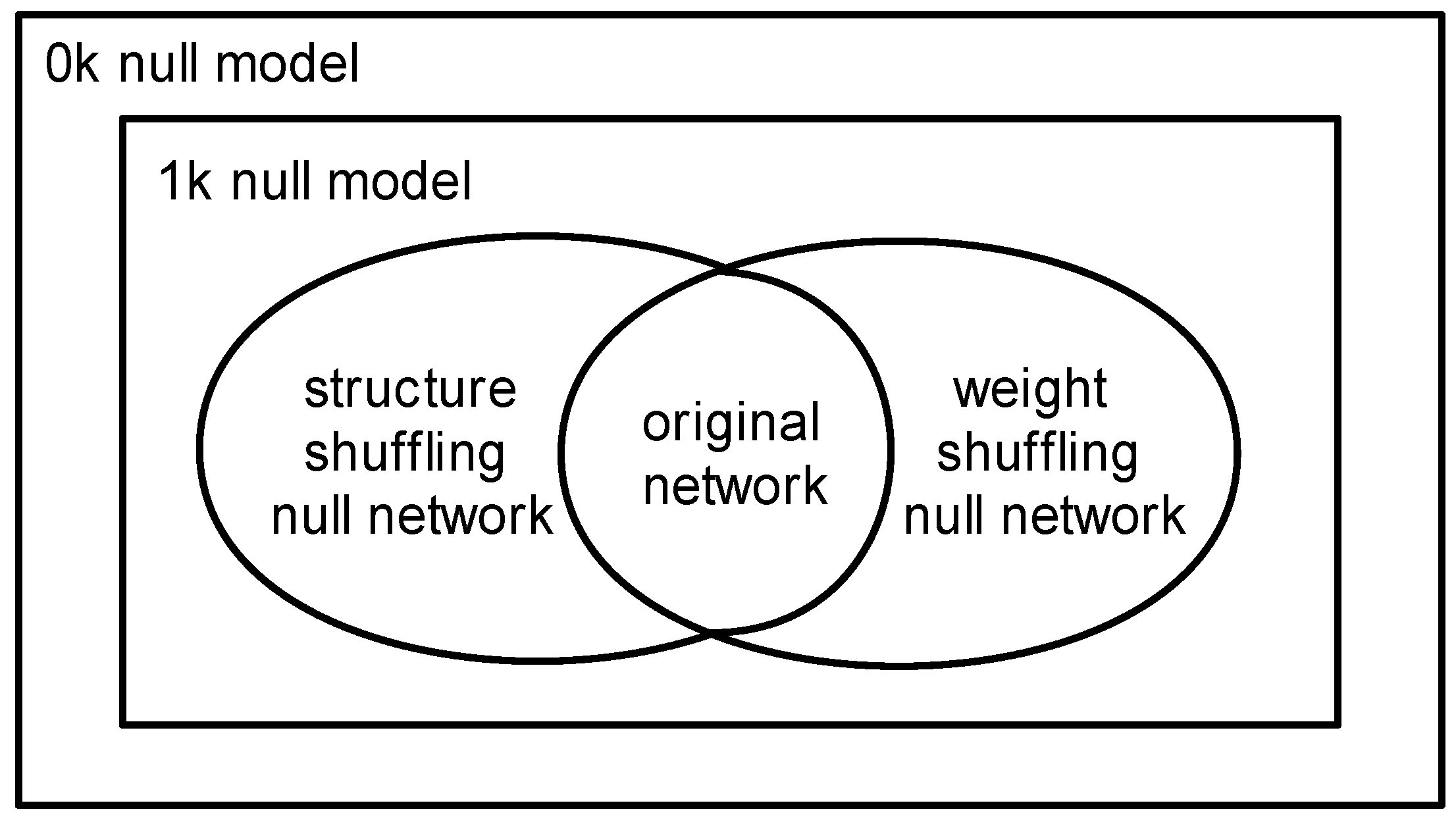
3.4. The Relationship between Three Null Models
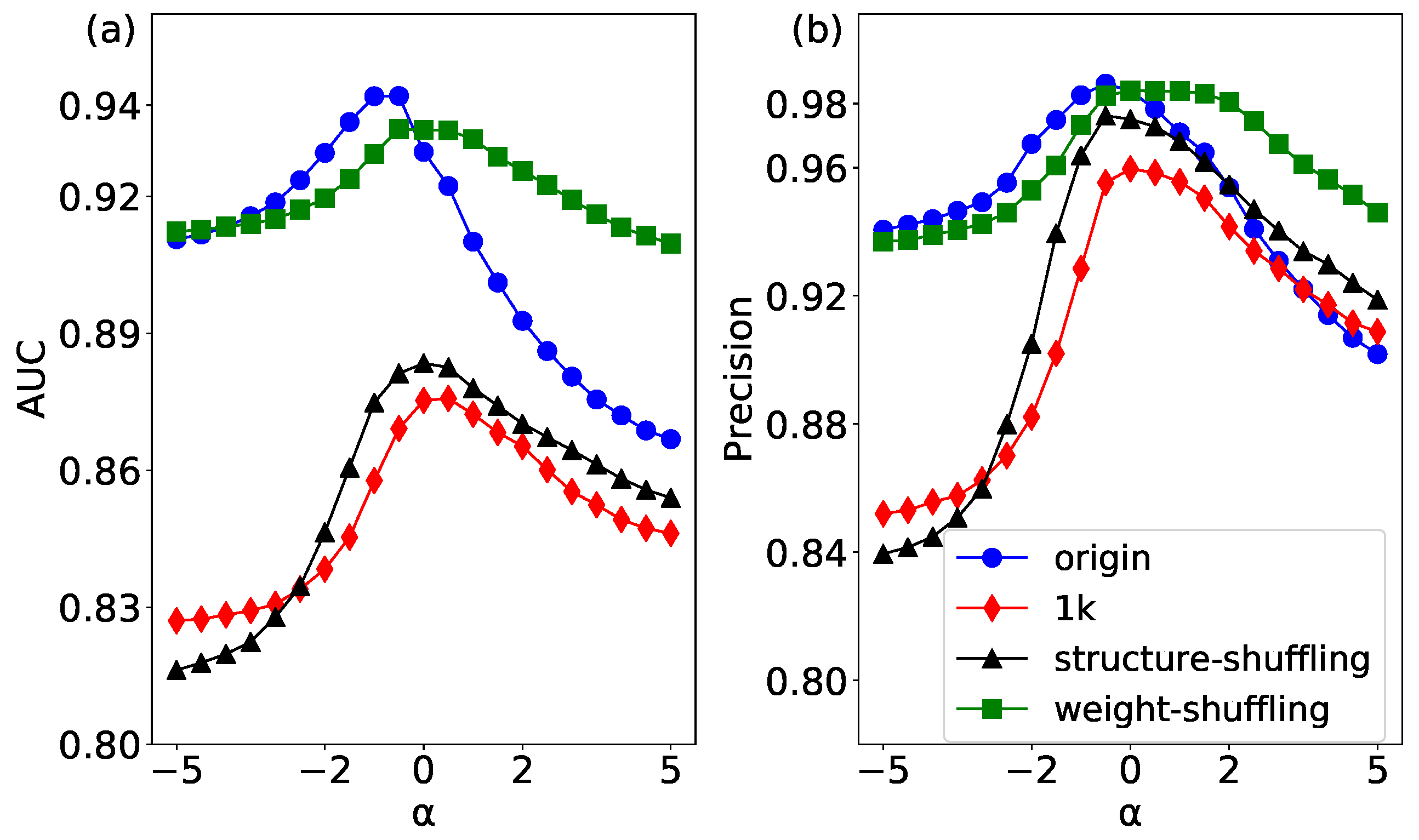
4. Link Prediction Based on Null Models of Weighted Networks
4.1. The Impact of Topology Structure and Weight on Link Prediction
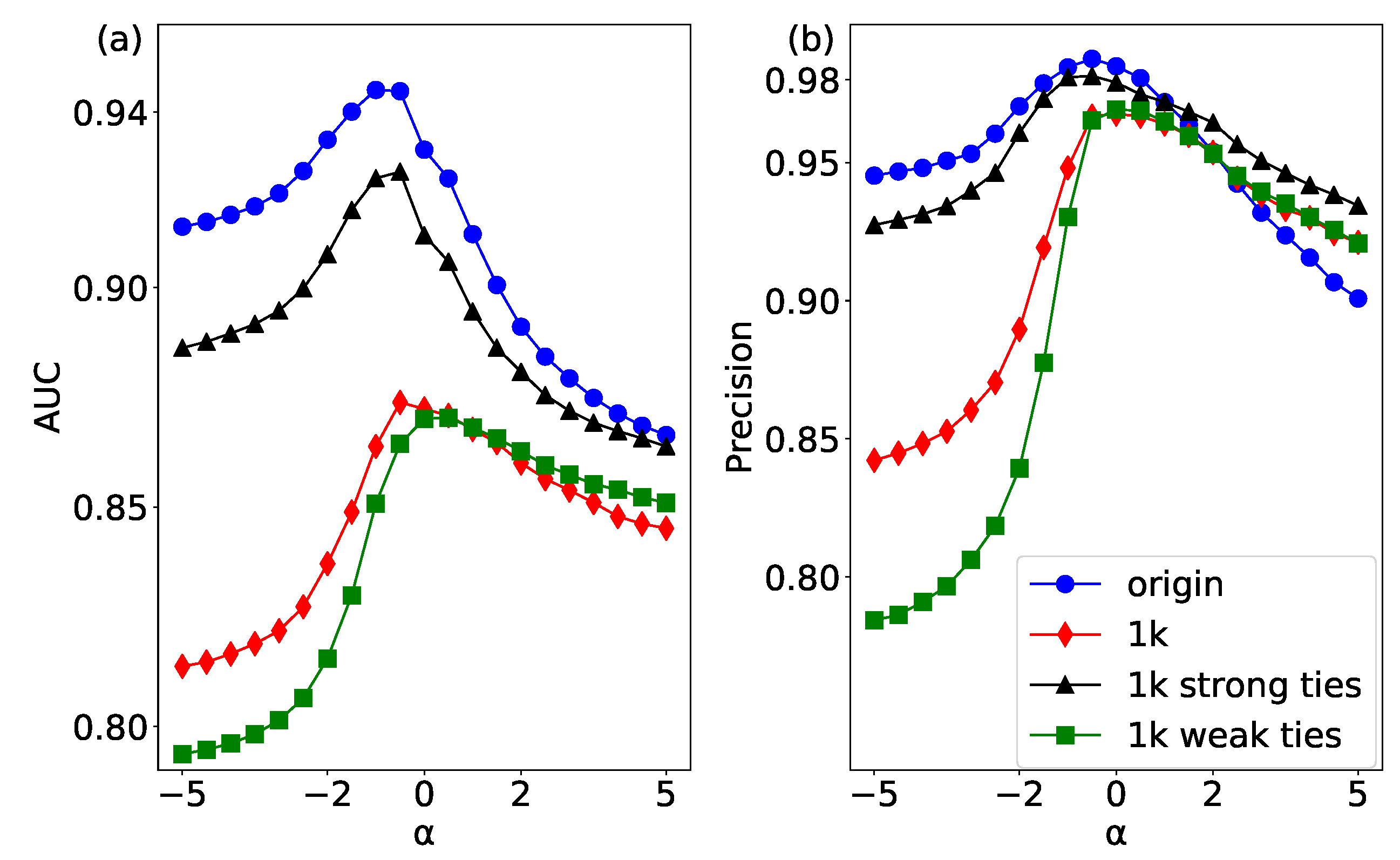
4.2. Predicting Strong and Weak Ties
4.3. The Strong Effect of Weak Ties
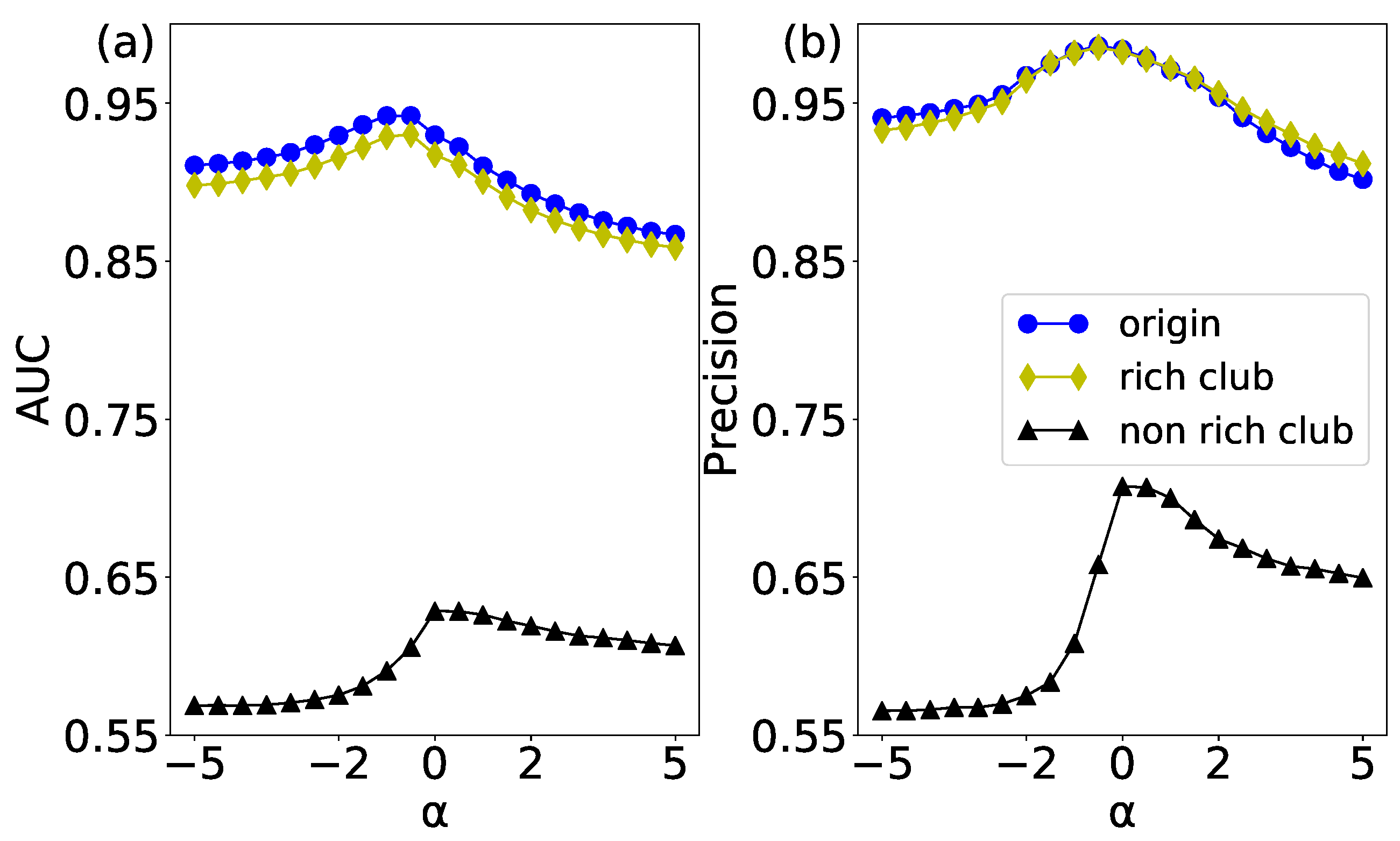
5. Link Prediction in the Null Network With Rich-Club Phenomenon
5.1. The Null Networks Based on Rich-Club Phenomenon
5.2. The Impact of the Rich-Club Phenomenon on Link Prediction
6. Link Prediction in the Null Network with Assortativity and Disassortativity
6.1. The Assortativity and Disassortativity Null Networks
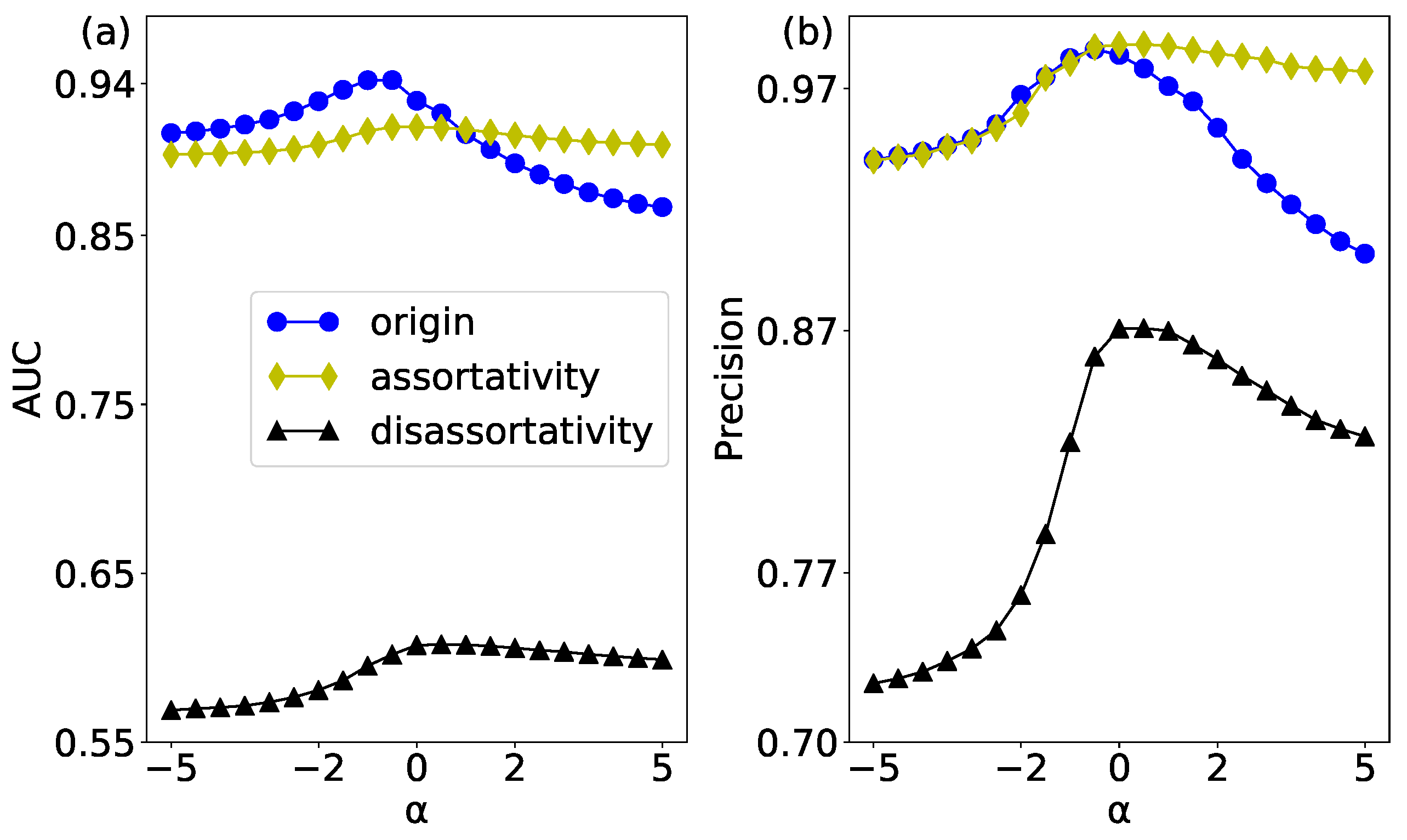
6.2. The Impact of Assortativity Mixing Patterns on Link Prediction
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Albert, R.; Barabasi, A. Statistical mechanics of complex networks. Rev. Mod. Phys. 2002, 74, 47–97. [Google Scholar] [CrossRef]
- Dorogovtsev, S.N.; Mendes, J.F. Evolution of networks. Adv. Phys. 2002, 51, 1079–1187. [Google Scholar] [CrossRef]
- Newman, M.E. The structure and function of complex networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef]
- Boccaletti, S.; Latora, V.; Moreno, Y.; Chavez, M.; Hwang, D.U. Complex networks: Structure and dynamics. Phys. Rep. 2006, 424, 175–308. [Google Scholar] [CrossRef]
- Costa, L.d.F.; Rodrigues, F.A.; Travieso, G.; Villas Boas, P.R. Characterization of complex networks: A survey of measurements. Adv. Phys. 2007, 56, 167–242. [Google Scholar] [CrossRef]
- Newman, M.E. The structure of scientific collaboration networks. Proc. Natl. Acad. Sci. USA 2001, 98, 404–409. [Google Scholar] [CrossRef] [PubMed]
- Guruharsha, K.; Rual, J.F.; Zhai, B.; Mintseris, J.; Vaidya, P.; Vaidya, N.; Beekman, C.; Wong, C.; Rhee, D.Y.; Cenaj, O.; et al. A protein complex network of Drosophila melanogaster. Cell 2011, 147, 690–703. [Google Scholar] [CrossRef] [PubMed]
- Scott, J. Social network analysis: A handbook. Contemp. Sociol. 2000, 22, 128. [Google Scholar]
- Brandão, M.A.; Moro, M.M. Social professional networks: A survey and taxonomy. Comput. Commun. 2017, 100, 20–31. [Google Scholar] [CrossRef]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Assoc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef]
- Huang, Z.; Li, X.; Chen, H. Link prediction approach to collaborative filtering. In Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries, Denver, CO, USA, 7–11 June 2005; pp. 141–142. [Google Scholar]
- Kaya, B.; Poyraz, M. Age-series based link prediction in evolving disease networks. Comput. Biol. Med. 2015, 63, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Afra, S.; Aksaç, A.; Õzyer, T.; Alhajj, R. Link prediction by network analysis. In Prediction and Inference from Social Networks and Social Media; Springer: Berlin, Germany, 2017; pp. 97–114. [Google Scholar]
- Wang, P.; Xu, B.W.; Wu, Y.R.; Zhou, X.Y. Link prediction in social networks: The state-of-the-art. Sci. China Inf. Sci. 2015, 58, 1–38. [Google Scholar] [CrossRef]
- Ma, C.; Bao, Z.K.; Zhang, H.F. Improving link prediction in complex networks by adaptively exploiting multiple structural features of networks. Phys. Lett. A 2017, 381, 3369–3376. [Google Scholar] [CrossRef]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef]
- Petri, G.; Scolamiero, M.; Donato, I.; Vaccarino, F. Topological strata of weighted complex networks. PLoS ONE 2013, 8, e66506. [Google Scholar] [CrossRef] [PubMed]
- Park, K.; Lai, Y.C.; Ye, N. Characterization of weighted complex networks. Phys. Rev. E 2004, 70, 026109. [Google Scholar] [CrossRef] [PubMed]
- Lin-yuan, L. Link Prediction on Complex Networks. J. Univ. Electron. Sci. Technol. China 2010, 39, 651–661. [Google Scholar]
- Yang, Y.; Zhang, J.; Zhu, X.; Tian, L. Link prediction via significant influence. Phys. A Stat. Mech. Appl. 2018, 492, 1523–1530. [Google Scholar] [CrossRef]
- Rubinov, M.; Kötter, R.; Hagmann, P.; Sporns, O. Brain connectivity toolbox: A collection of complex network measurements and brain connectivity datasets. NeuroImage 2009, 47, S169. [Google Scholar] [CrossRef]
- Zhao, J.; Miao, L.; Yang, J.; Fang, H.; Zhang, Q.M.; Nie, M.; Holme, P.; Zhou, T. Prediction of links and weights in networks by reliable routes. Sci. Rep. 2015, 5, 12261. [Google Scholar] [CrossRef] [PubMed]
- Bianconi, G. Emergence of weight-topology correlations in complex scale-free networks. Epl 2004, 71, 1029. [Google Scholar] [CrossRef]
- Opsahl, T.; Colizza, V.P.P. Prominence and Control: The Weighted Rich-club Effect. Phys. Rev. Lett. 2008, 101, 168702. [Google Scholar] [CrossRef] [PubMed]
- Leung, C.; Chau, H. Weighted assortative and disassortative networks model. Phys. A Stat. Mech. Its Appl. 2007, 378, 591–602. [Google Scholar] [CrossRef] [Green Version]
- Vladimir Batagelj, A.M. Pajek Datasets. Available online: http://vlado.fmf.uni-lj.si/pub/networks/data/ (accessed on 17 May 2017).
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Knuth, D.E. The Stanford GraphBase: A Platform for Combinatorial Computing; Addison-Wesley Reading: Boston, MA, USA, 1993; Volume 37. [Google Scholar]
- Kossinets, G. Effects of missing data in social networks. Soc. Netw. 2006, 28, 247–268. [Google Scholar] [CrossRef]
- Newman, M.E. Clustering and preferential attachment in growing networks. Phys. Rev. E 2001, 64, 025102. [Google Scholar] [CrossRef] [PubMed]
- Lü, L. Link Prediction; Higher Education Press: Beijing, China, 2013. [Google Scholar]
- Wang, Y.L.; Zhou, T.; Shi, J.J.; Wang, J.; He, D.R. Empirical analysis of dependence between stations in Chinese railway network. Phys. A Stat. Mech. Its Appl. 2009, 388, 2949–2955. [Google Scholar] [CrossRef]
- Pan, Y.; Li, D.H.; Liu, J.G.; Liang, J.Z. Detecting community structure in complex networks via node similarity. Phys. A Stat. Mech. Its Appl. 2012, 389, 2849–2857. [Google Scholar] [CrossRef]
- Soundarajan, S.; Hopcroft, J. Using community information to improve the precision of link prediction methods. In Proceedings of the International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 607–608. [Google Scholar]
- Xie, Y.B.; Wang, W.X.; Wang, B.H. Modeling the coevolution of topology and traffic on weighted technological networks. Phys. Rev. E 2007, 75, 026111. [Google Scholar] [CrossRef] [PubMed]
- Barrat, A.; Barthelemy, M.; Pastor-Satorras, R.; Vespignani, A. The architecture of complex weighted networks. Proc. Natl. Acad. Sci. USA 2004, 101, 3747–3752. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.X.; Wang, B.H.; Hu, B.; Yan, G.; Ou, Q. General dynamics of topology and traffic on weighted technological networks. Phys. Rev. lett. 2005, 94, 188702. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Mondragón, R.J. The rich-club phenomenon in the Internet topology. IEEE Commun. Lett. 2004, 8, 180–182. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Li, X.; Zhang, P.; Di, Z.; Fan, Y. Community structure in complex network. Complex Syst. Complex. Sci. 2008, 44, 14760–14771. [Google Scholar]
- Li, M.; Fan, Y.; Chen, J.; Gao, L.; Di, Z.; Wu, J. Weighted networks of scientific communication: The measurement and topological role of weight. Phys. A Stat. Mech. Its Appl. 2005, 350, 643–656. [Google Scholar] [CrossRef]
- Ma, C.; Zhou, T.; Zhang, H. Playing the role of weak clique property in link prediction: A friend recommendation model. Sci. Rep. 2016, 6, 30098. [Google Scholar] [CrossRef] [PubMed]
- Maslov, S.; Sneppen, K. Specificity and Stability in Topology of Protein Networks. Science 2002, 296, 910. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| USAir | Celegans | Netscience | Gemo | Lesmis | CatCortex | CScientists | ||
|---|---|---|---|---|---|---|---|---|
| AUC | Origin | 0.942 | 0.831 | 0.937 | 0.889 | 0.878 | 0.781 | 0.952 |
| Weight-shuffling | 0.935 | 0.832 | 0.935 | 0.888 | 0.865 | 0.763 | 0.951 | |
| Structure-shuffling | 0.883 | 0.679 | 0.634 | 0.573 | 0.703 | 0.697 | 0.586 | |
| 1k | 0.876 | 0.668 | 0.51 | 0.529 | 0.710 | 0.688 | 0.504 | |
| Precision | Origin | 0.986 | 0.94 | 0.997 | 0.999 | 0.911 | 0.925 | 0.999 |
| Weight-shuffling | 0.984 | 0.967 | 0.993 | 0.999 | 0.917 | 0.911 | 0.999 | |
| Structure-shuffling | 0.976 | 0.903 | 0.808 | 0.676 | 0.826 | 0.919 | 0.692 | |
| 1k | 0.960 | 0.915 | 0.525 | 0.579 | 0.807 | 0.903 | 0.510 |
| USAir | Celegans | Netscience | Gemo | Lesmis | CatCortex | CScientists | ||
|---|---|---|---|---|---|---|---|---|
| AUC | Strong ties | 0.983 | 0.891 | 0.912 | 0.925 | 0.943 | 0.810 | 0.935 |
| Weak ties | 0.927 | 0.799 | 0.999 | 0.882 | 0.789 | 0.780 | 0.999 | |
| Precision | Strong ties | 0.989 | 0.955 | 0.996 | 0.999 | 0.913 | 0.921 | 0.999 |
| Weak ties | 0.978 | 0.916 | 0.998 | 0.999 | 0.880 | 0.909 | 0.999 |
| USAir | Celegans | Netscience | Gemo | Lesmis | CatCortex | CScientists | ||
|---|---|---|---|---|---|---|---|---|
| AUC | 1k Strong ties | 0.916 | 0.689 | 0.726 | 0.700 | 0.748 | 0.696 | 0.756 |
| 1k Weak ties | 0.862 | 0.715 | 0.702 | 0.751 | 0.838 | 0.746 | 0.732 | |
| Precision | 1k Strong ties | 0.956 | 0.906 | 0.987 | 0.907 | 0.852 | 0.907 | 0.999 |
| 1k Weak ties | 0.941 | 0.909 | 0.952 | 0.923 | 0.895 | 0.919 | 0.997 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Xu, S.; Li, T.; Xiao, J.; Xu, X.-K. Quantifying the Effects of Topology and Weight for Link Prediction in Weighted Complex Networks. Entropy 2018, 20, 363. https://doi.org/10.3390/e20050363
Liu B, Xu S, Li T, Xiao J, Xu X-K. Quantifying the Effects of Topology and Weight for Link Prediction in Weighted Complex Networks. Entropy. 2018; 20(5):363. https://doi.org/10.3390/e20050363
Chicago/Turabian StyleLiu, Bo, Shuang Xu, Ting Li, Jing Xiao, and Xiao-Ke Xu. 2018. "Quantifying the Effects of Topology and Weight for Link Prediction in Weighted Complex Networks" Entropy 20, no. 5: 363. https://doi.org/10.3390/e20050363
APA StyleLiu, B., Xu, S., Li, T., Xiao, J., & Xu, X. -K. (2018). Quantifying the Effects of Topology and Weight for Link Prediction in Weighted Complex Networks. Entropy, 20(5), 363. https://doi.org/10.3390/e20050363