A Survey of Viewpoint Selection Methods for Polygonal Models

 , , , and
, , , and
Abstract
:1. Introduction
2. Background
3. Viewpoint Selection Measures
3.1. Notation
- Conditional probability matrix , where each element is defined by the normalized projected area of polygon z over the sphere of directions centered at viewpoint v.Conditional probabilities fulfill .
- Input distribution , where each element , which represents the probability of selecting each viewpoint, is obtained from the normalization of the object projected area at each viewpoint. The input distribution is interpreted as the importance assigned to each viewpoint v.
- Output distribution , given by , which represents the average projected area of polygon z.
3.2. Area Attributes
3.3. Silhouette Attributes
3.4. Depth Attributes
3.5. Stability Attributes
3.6. Surface Curvature Attributes
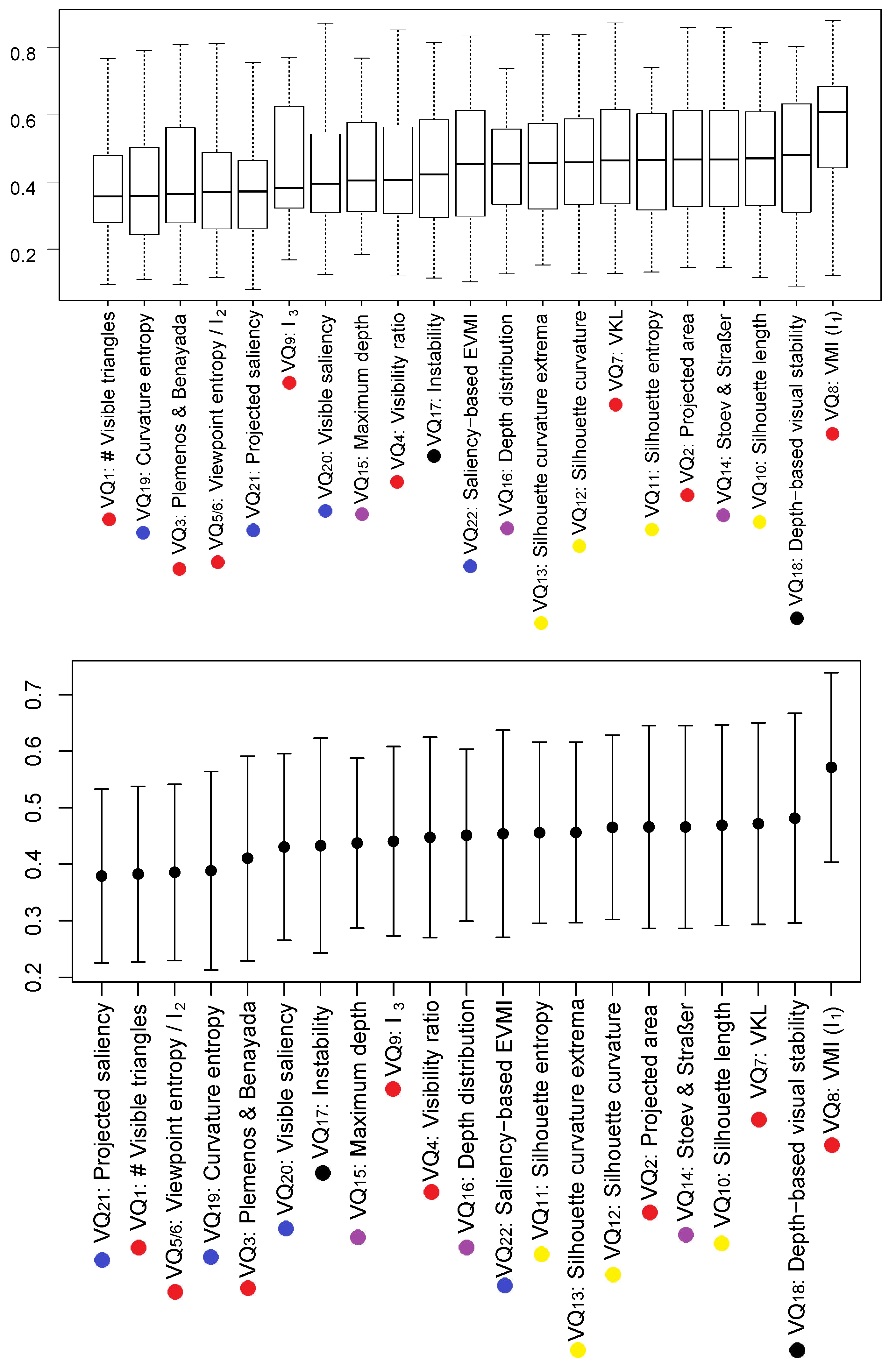
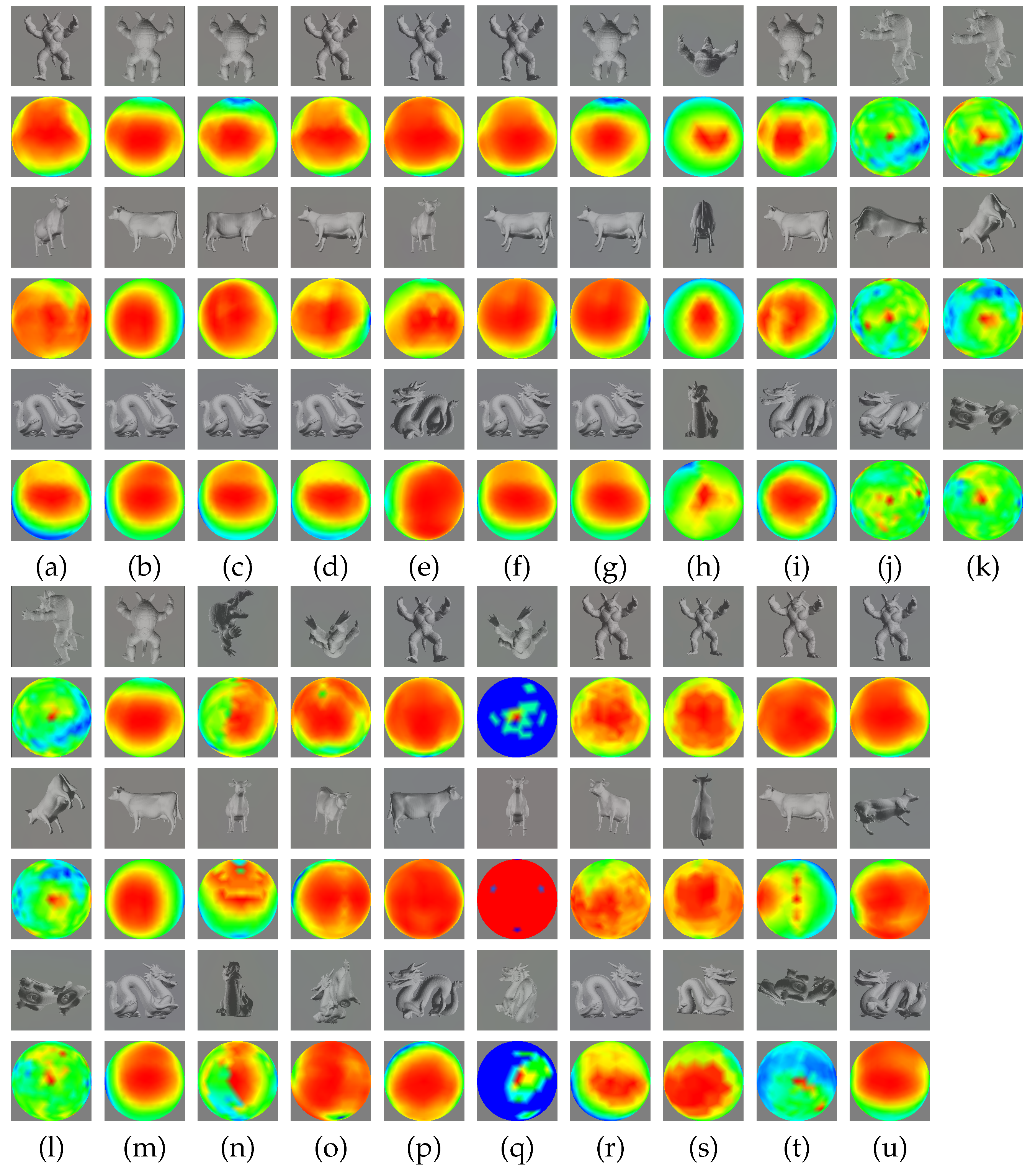
4. Results and Discussion
5. Applications
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Peters, G. Theories of Three-Dimensional Object Perception—A Survey. Recent Res. Dev. Pattern Recognit. 2000, 1, 179–197. [Google Scholar]
- Biederman, I. Recognition-by-components: A theory of human image understanding. Psychol. Rev. 1987, 94, 115–147. [Google Scholar] [CrossRef] [PubMed]
- Koenderink, J.J.; van Doorn, A.J. The internal representation of solid shape with respect to vision. Biol. Cybern. 1979, 32, 211–216. [Google Scholar] [CrossRef] [PubMed]
- Edelman, S.; Bülthoff, H.H. Orientation dependence in the recognition of familiar and novel views of three-dimensional objects. Vis. Res. 1992, 32, 2385–2400. [Google Scholar] [CrossRef]
- Bülthoff, H.H.; Edelman, S.Y.; Tarr, M.J. How are three-dimensional objects represented in the brain? Cereb. Cortex 1995, 5, 247–260. [Google Scholar] [CrossRef] [PubMed]
- Tarr, M.J.; Bülthoff, H.H.; Zabinski, M.; Blanz, V. To what extent do unique parts influence recognition across changes in viewpoint? Psychol. Sci. 1997, 8, 282–289. [Google Scholar] [CrossRef]
- Logothetis, N.K.; Pauls, J. Psychophysical and Physiological Evidence for Viewer-centered Object Representations in the Primate. Cereb. Cortex 1995, 5, 270–288. [Google Scholar] [CrossRef] [PubMed]
- Palmer, S.E.; Rosch, E.; Chase, P. Canonical perspective and the perception of objects. In Attention and Performance IX; Lawrence Erlbaum Associates: Hillsdale, NJ, USA, 1981; pp. 135–151. [Google Scholar]
- Harman, K.L.; Humphrey, G.K.; Goodale, M.A. Active manual control of object views facilitates visual recognition. Curr. Biol. 1999, 9, 1315–1318. [Google Scholar] [CrossRef]
- Perrett, D.I.; Harries, M.H. Characteristic views and the visual inspection of simple faceted and smooth objects: ‘Tetrahedra and potatoes’. Perception 1988, 17, 703–720. [Google Scholar] [CrossRef] [PubMed]
- Perrett, D.I.; Harries, M.H.; Looker, S. Use of preferential inspection to define the viewing sphere and characteristic views of an arbitrary machined tool part. Perception 1992, 21, 497–515. [Google Scholar] [CrossRef] [PubMed]
- Blanz, V.; Tarr, M.J.; Bülthoff, H.H. What object attributes determine canonical views? Perception 1999, 28, 575–600. [Google Scholar] [CrossRef] [PubMed]
- Polonsky, O.; Patané, G.; Biasotti, S.; Gotsman, C.; Spagnuolo, M. What’s in an image? Vis. Comput. 2005, 21, 840–847. [Google Scholar] [CrossRef]
- Dutagaci, H.; Cheung, C.P.; Godil, A. A benchmark for best view selection of 3D objects. In Proceedings of the ACM Workshop on 3D Object Retrieval, Firenze, Italy, 25 October 2010; pp. 45–50. [Google Scholar]
- Secord, A.; Lu, J.; Finkelstein, A.; Singh, M.; Nealen, A. Perceptual models of viewpoint preference. ACMToG 2011, 30, 109:1–109:12. [Google Scholar] [CrossRef]
- Attneave, F. Some informational aspects of visual perception. Psychol. Rev. 1954, 61, 183–193. [Google Scholar] [CrossRef] [PubMed]
- Connolly, C.I. The determination of next best views. In Proceedings of the IEEE International Conference on Robotics and Automation, St. Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 432–435. [Google Scholar]
- Kamada, T.; Kawai, S. A simple method for computing general position in displaying three-dimensional objects. Comput. Vis. Graph. Image Proc. 1988, 41, 43–56. [Google Scholar] [CrossRef]
- Plemenos, D.; Benayada, M. Intelligent Display Techniques in Scene Modelling. New Techniques to Automatically Compute Good Views. In Proceedings of the International Conference GraphiCon’96, St Petersbourg, Russia, 1 July 1996. [Google Scholar]
- Arbel, T.; Ferrie, F.P. Viewpoint selection by navigation through entropy maps. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 1, pp. 248–254. [Google Scholar]
- Vázquez, P.P.; Feixas, M.; Sbert, M.; Heidrich, W. Viewpoint Selection Using Viewpoint Entropy. In Proceedings of the Vision Modeling and Visualization Conference, Stuttgart, Germany, 21–23 November 2001; pp. 273–280. [Google Scholar]
- Weinshall, D.; Werman, M. On view likelihood and stability. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 97–108. [Google Scholar] [CrossRef]
- Stoev, S.L.; Straßer, W. A case study on automatic camera placement and motion for visualizing historical data. In Proceedings of the IEEE Visualization ’02, IEEE Computer Society, Washington, DC, USA, 27 October–1 November 2002; pp. 545–548. [Google Scholar]
- Yamauchi, H.; Saleem, W.; Yoshizawa, S.; Karni, Z.; Belyaev, A.G.; Seidel, H.P. Towards Stable and Salient Multi-View Representation of 3D Shapes. In Proceedings of the IEEE International Conference on Shape Modeling and Applications 2006 (SMI’06), Matsushima, Japan, 14–16 June 2006; pp. 265–270. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A Model of Saliency-Based Visual Attention for Rapid Scene Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Borji, A.; Itti, L. State-of-the-Art in Visual Attention Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 185–207. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.H.; Varshney, A.; Jacobs, D.W. Mesh saliency. ACMToG 2005, 24, 659–666. [Google Scholar]
- Gal, R.; Cohen-Or, D. Salient geometric features for partial shape matching and similarity. ACM Trans. Graph. (TOG) 2006, 25, 130–150. [Google Scholar] [CrossRef]
- Becker, M.W.; Pashler, H.; Lubin, J. Object-intrinsic oddities draw early saccades. J. Exp. Psychol. Hum. Percept. Perform. 2007, 33, 20–30. [Google Scholar] [CrossRef] [PubMed]
- Koulieris, G.A.; Drettakis, G.; Cunningham, D.; Mania, K. C-LOD: Context-aware Material Level-Of-Detail applied to Mobile Graphics. Comput. Graph. Forum 2014, 33, 41–49. [Google Scholar] [CrossRef]
- Gooch, B.; Reinhard, E.; Moulding, C.; Shirley, P. Artistic Composition for Image Creation. In Rendering Techniques; Springer: London, UK, 2001; pp. 83–88. [Google Scholar]
- Fu, H.; Cohen-Or, D.; Dror, G.; Sheffer, A. Upright orientation of man-made objects. TOG 2008, 27, 42:1–42:7. [Google Scholar] [CrossRef]
- Zusne, L. Visual Perception of Form; Academic Press: Cambridge, MA, USA, 1970. [Google Scholar]
- Podolak, J.; Shilane, P.; Golovinskiy, A.; Rusinkiewicz, S.; Funkhouser, T. A planar-reflective symmetry transform for 3D shapes. TOG 2006, 25, 549–559. [Google Scholar] [CrossRef]
- Feixas, M.; Sbert, M.; González, F. A unified information-theoretic framework for viewpoint selection and mesh saliency. ACM Trans. Appl. Percept. 2009, 6, 1–23. [Google Scholar] [CrossRef]
- Barral, P.; Dorme, G.; Plemenos, D. Visual understanding of a scene by automatic movement of a camera. In Proceedings of the International Conference GraphiCon’99, Moscow, Russia, 26 August 1999. [Google Scholar]
- Vázquez, P.P.; Feixas, M.; Sbert, M.; Heidrich, W. Automatic View Selection Using Viewpoint Entropy and its Applications to Image-based Modelling. Comput. Graph. Forum 2003, 22, 689–700. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley-Interscience: New York, NY, USA, 1991. [Google Scholar]
- Yeung, R.W. Information Theory and Network Coding; Springer: Berlin, Germany, 2008. [Google Scholar]
- Deweese, M.R.; Meister, M. How to measure the information gained from one symbol. Netw. Comput. Neural Syst. 1999, 10, 325–340. [Google Scholar] [CrossRef]
- Bonaventura, X.; Feixas, M.; Sbert, M. Viewpoint Information. In Proceedings of the 21st GraphiCon International Conference on Computer Graphics and Vision, Moscow, Russia, 26 September 2011; pp. 16–19. [Google Scholar]
- Sbert, M.; Plemenos, D.; Feixas, M.; González, F. Viewpoint Quality: Measures and Applications. In Proceedings of the First Eurographics Conference on Computational Aesthetics in Graphics, Visualization and Imaging, Girona, Spain, 18–20 May 2005; pp. 185–192. [Google Scholar]
- Viola, I.; Feixas, M.; Sbert, M.; Gröller, M.E. Importance-Driven Focus of Attention. IEEE Trans. Vis. Comput. Graph. 2006, 12, 933–940. [Google Scholar] [CrossRef] [PubMed]
- Butts, D.A. How much information is associated with a particular stimulus? Netw. Comput. Neural Syst. 2003, 14, 177–187. [Google Scholar] [CrossRef]
- Page, D.L.; Koschan, A.F.; Sukumar, S.R.; Roui-Abidi, B.; Abidi, M.A. Shape Analysis Algorithm Based on Information Theory. In Proceedings of the IEEE International Conference on Image Processing (ICIP’03), Barcelona, Spain, 14–18 September 2003; Volume 1, pp. 229–232. [Google Scholar]
- Vieira, T.; Bordignon, A.; Peixoto, A.; Tavares, G.; Lopes, H.; Velho, L.; Lewiner, T. Learning Good Views through Intelligent Galleries. Comput. Graph. Forum 2009, 28, 717–726. [Google Scholar] [CrossRef]
- Burbea, J.; Rao, C.R. On the Convexity of some Divergence Measures Based on Entropy Functions. IEEE Trans. Inf. Theory 1982, 28, 489–495. [Google Scholar] [CrossRef]
- Bordoloi, U.D.; Shen, H.W. View selection for volume rendering. In Proceedings of the IEEE Visualization (VIS 05), Minneapolis, MN, USA, 23–28 Octomber 2005; pp. 487–494. [Google Scholar]
- Vázquez, P.P. Automatic view selection through depth-based view stability analysis. Vis. Comput. 2009, 25, 441–449. [Google Scholar] [CrossRef] [Green Version]
- Taubin, G. Estimating the tensor of curvature of a surface from a polyhedral approximation. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 20–23 June 1995; pp. 902–907. [Google Scholar]
- Sokolov, D.; Plemenos, D. Viewpoint quality and scene understanding. In Proceedings of the 6th International Symposium on Virtual Reality, Archaeology and Cultural Heritage VAST, Pisa, Italy, 8–11 November 2005; pp. 67–73. [Google Scholar]
- Bonaventura, X.; Feixas, M.; Sbert, M. Information measures for object understanding. Signal Image Video Proc. 2013, 7, 467–478. [Google Scholar] [CrossRef]
- Serin, E.; Sumengen, S.; Balcisoy, S. Representational image generation for 3D objects. Vis. Comput. 2013, 29, 675–684. [Google Scholar] [CrossRef]
- A Framework for Viewpoint Selection. Available online: http://github.com/limdor/quoniam (accessed on 24 March 2018).
- Hayworth, K.J.; Biederman, I. Neural evidence for intermediate representations in object recognition. Vis. Res. 2006, 46, 4024–4031. [Google Scholar] [CrossRef] [PubMed]
- Hummel, J.E.; Biederman, I. Dynamic binding in a neural network for shape recognition. Psychol. Rev. 1992, 99, 480–517. [Google Scholar] [CrossRef] [PubMed]
- Barral, P.; Dorme, G.; Plemenos, D. Scene understanding techniques using a virtual camera. In Proceedings of Eurographics 2000, Short Presentations, Rendering and Visibility; Eurographics Association: Interlaken, Switzerland, 2000. [Google Scholar]
- Vázquez, P.P.; Sbert, M. Automatic indoor scene exploration. In Proceedings of the 6th International Conference on Computer Graphics and Artificial Intelligence (3IA), Limoges, France, 14–15 May 2003; pp. 13–24. [Google Scholar]
- Andújar, C.; Vázquez, P.P.; Fairén, M. Way-Finder: guided tours through complex walkthrough models. Comput. Graph. Forum 2004, 23, 499–508. [Google Scholar] [CrossRef]
- Ozaki, M.; Gobeawan, L.; Kitaoka, S.; Hamazaki, H.; Kitamura, Y.; Lindeman, R.W. Camera movement for chasing a subject with unknown behavior based on real-time viewpoint goodness evaluation. Vis. Comput. 2010, 26, 629–638. [Google Scholar] [CrossRef]
- Serin, E.; Adali, S.H.; Balcisoy, S. Automatic path generation for terrain navigation. Comput Graph. 2012, 36, 1013–1024. [Google Scholar] [CrossRef]
- Massios, N.A.; Fisher, R.B. A Best Next View Selection Algorithm Incorporating a Quality Criterion. In Proceedings of the British Machine Vision Conference; BMVA Press: Southampton, UK, 1998; pp. 78.1–78.10. [Google Scholar]
- Fleishman, S.; Cohen-Or, D.; Lischinski, D. Automatic Camera Placement for Image-Based Modeling. Comput. Graph. Forum 2000, 19, 101–110. [Google Scholar] [CrossRef]
- Takahashi, S.; Fujishiro, I.; Takeshima, Y.; Nishita, T. A Feature-Driven Approach to Locating Optimal Viewpoints for Volume Visualization. In Proceedings of the IEEE Visualization 2005, Minneapolis, MN, USA, 23–28 October 2005; pp. 495–502. [Google Scholar]
- Ji, G.; Shen, H.W. Dynamic View Selection for Time-Varying Volumes. IEEE Trans. Vis. Comput. Graph. 2006, 12, 1109–1116. [Google Scholar] [PubMed]
- Ruiz, M.; Boada, I.; Feixas, M.; Sbert, M. Viewpoint information channel for illustrative volume rendering. Comput. Graph. 2010, 34, 351–360. [Google Scholar] [CrossRef]
- Ruiz, M.; Bardera, A.; Boada, I.; Viola, I.; Feixas, M.; Sbert, M. Automatic Transfer Functions Based on Informational Divergence. IEEE Trans. Vis. Comput. Graph. 2011, 17, 1932–1941. [Google Scholar] [CrossRef] [PubMed]
- Itoh, M.; Yokoyama, D.; Toyoda, M.; Kitsuregawa, M. Optimal viewpoint finding for 3D visualization of spatio-temporal vehicle trajectories on caution crossroads detected from vehicle recorder big data. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 3426–3434. [Google Scholar]
- Tao, J.; Ma, J.; Wang, C.; Shene, C.K. A Unified Approach to Streamline Selection and Viewpoint Selection for 3D Flow Visualization. IEEE Trans. Vis. Comput. Graph. 2013, 19, 393–406. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.Y.; Mishchenko, O.; Shen, H.W.; Crawfis, R. View point evaluation and streamline filtering for flow visualization. In Proceedings of the 2011 IEEE Pacific Visualization Symposium, Hong Kong, China, 1–4 March 2011; pp. 83–90. [Google Scholar]
- Vázquez, P.P.; Feixas, M.; Sbert, M.; Llobet, A. Realtime automatic selection of good molecular views. Comput. Graph. 2006, 30, 98–110. [Google Scholar] [CrossRef]
- Sarikaya, A.; Albers, D.; Mitchell, J.C.; Gleicher, M. Visualizing Validation of Protein Surface Classifiers. Comput. Graph. Forum 2014, 33, 171–180. [Google Scholar] [CrossRef] [PubMed]
- González, F.; Feixas, M.; Sbert, M. View-Based Shape Similarity Using Mutual Information Spheres; EG Short Papers; Eurographics Association: Prague, Czech Republic, 2007; pp. 21–24. [Google Scholar]
- Eitz, M.; Richter, R.; Boubekeur, T.; Hildebrand, K.; Alexa, M. Sketch-based shape retrieval. TOG 2012, 31, 31:1–31:10. [Google Scholar] [CrossRef]
- Li, B.; Lu, Y.; Johan, H. Sketch-Based 3D Model Retrieval by Viewpoint Entropy-Based Adaptive View Clustering. In Proceedings of the Sixth Eurographics Workshop on 3D Object Retrieval; Eurographics Association: Aire-la-Ville, Switzerland, 2013; pp. 49–56. [Google Scholar]
- Bonaventura, X.; Guo, J.; Meng, W.; Feixas, M.; Zhang, X.; Sbert, M. 3D shape retrieval using viewpoint information-theoretic measures. Comput. Anim. Virtual Worlds 2015, 26, 147–156. [Google Scholar] [CrossRef]
- Castelló, P.; Sbert, M.; Chover, M.; Feixas, M. Viewpoint entropy-driven simplification. In Proceedings of the 15th International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision (WSCG 2007), Plzen, Czech Republic, 29 January–1 February 2007; pp. 249–256. [Google Scholar]
- Castelló, P.; Sbert, M.; Chover, M.; Feixas, M. Viewpoint-based simplification using f-divergences. Inf. Sci. 2008, 178, 2375–2388. [Google Scholar] [CrossRef]
- Castelló, P.; Sbert, M.; Chover, M.; Feixas, M. Viewpoint-driven simplification using mutual information. Comput. Graph. 2008, 32, 451–463. [Google Scholar] [CrossRef]
- Castelló, P.; González, C.; Chover, M.; Sbert, M.; Feixas, M. Tsallis Entropy for Geometry Simplification. Entropy 2011, 13, 1805–1828. [Google Scholar] [CrossRef]

| (a) | (b) | (c) |
| (d) | (e) | (f) |


| (a) | (b) | (c) | (d) | (e) | (f) | (g) | (h) | (i) | (j) | (k) |
| (l) | (m) | (n) | (o) | (p) | (q) | (r) | (s) | (t) | (u) |

{kind=link}
{kind=link}
{kind=link}
| z | polygon |
| set of polygons | |
| v | viewpoint |
| set of viewpoints | |
| projected area of polygon z from viewpoint v | |
| projected area of the model from viewpoint v | |
| visibility of polygon z from viewpoint v (0 or 1) | |
| number of polygons | |
| R | number of pixels of the projected image |
| area of polygon z | |
| total area of the model | |
| conditional probability of z given v | |
| probability of z | |
| conditional probability of v given z | |
| probability of v | |
| entropy of the set of viewpoints | |
| entropy of the set of polygons | |
| conditional entropy of the set of viewpoints given polygon z | |
| conditional entropy of the set of polygons given viewpoint v | |
| silhouette length from viewpoint v | |
| normalized silhouette curvature histogram | |
| turning angle bin | |
| a | turning angle between two consecutive pixels |
| set of turning angles | |
| number of turning angles | |
| normalized maximum depth of the scene from viewpoint v | |
| normalized histogram of depths | |
| d | depth bin |
| set of depth bins | |
| number of neighbors of v | |
| size of the compression of the depth image corresponding to viewpoint v | |
| size of the compression of the concatenation of the depth images | |
| corresponding to viewpoints and | |
| curvature of vertex i | |
| normalized histogram of visible curvatures from viewpoint v | |
| b | curvature bin |
| set of curvature bins | |
| saliency of vertex x |
| # | Measure | Polonsky05 | Dutagaci10 | Secord11 | V | D | Ref. |
|---|---|---|---|---|---|---|---|
| 1 | # Visible triangles | - | - | - | H | Y | [19] |
| 2 | Projected area | - | View area | Idem | H | N | [19] |
| 3 | Plemenos and Benayada | - | - | - | H | Y | [19] |
| 4 | Visibility ratio | Idem | Ratio of visible area | Surface visibility | H | N | [19] |
| 5 | Viewpoint entropy | Surface area entropy | Surface area entropy | Idem | H | Y | [21] |
| 6 | - | - | - | L | Y | [41] | |
| 7 | VKL | - | - | - | L | N | [42] |
| 8 | VMI () | - | - | - | L | N | [35] |
| 9 | - | - | - | H | Y | [41] | |
| 10 | Silhouette length | Idem | Idem | Idem | H | N | [13] |
| 11 | Silhouette entropy | Idem | Idem | - | H | N | [13] |
| 12 | Silhouette curvature | - | - | Idem | H | N | [46] |
| 13 | Silhouette curvature extrema | - | - | Idem | H | N | [15] |
| 14 | Stoev and Straßer | - | - | - | H | N | [23] |
| 15 | Maximum depth | - | - | Max depth | H | N | [23] |
| 16 | Depth distribution | - | - | Idem | H | N | [15] |
| 17 | Instability | - | - | - | L | Y | [35] |
| 18 | Depth-based visual stability | - | - | - | H | N | [49] |
| 19 | Curvature entropy | Idem | Idem | - | H | Y | [13] |
| 20 | Visible saliency | - | Mesh saliency | Mesh saliency | H | Y | [27] |
| 21 | Projected saliency | - | - | - | H | Y | [35] |
| 22 | Saliency-based EVMI | - | - | - | L | Y | [35] |
| Reference | [62] | [36] | [57] | [63] | [58] | [37] | [59] | [48] | [64] | [65] | [71] | [43] | [77] | [73] | [78] | [79] | [35] | [60] | [66] | [80] | [74] | [61] | [75] | [69] | [72] | [76] | [70] | [68] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Measure | 1 | 3 | 3,4 | 2 | 5 | 5 | 5 | 5,17 | 5 | 5,20 | 5 | 8,22 | 5 | 8 | 7 | 8 | 8 | 5 | 21 | 5,8 | 2,10,16 | 5 | 5 | 8 | 5 | 6,8 | 5 | 5 |
| SE/CP | X | X | X | X | X | X | X | |||||||||||||||||||||
| IBMR | X | X | X | |||||||||||||||||||||||||
| SV | X | X | X | X | X | X | X | X | X | X | ||||||||||||||||||
| SR | X | X | X | X | ||||||||||||||||||||||||
| MS | X | X | X | X |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bonaventura, X.; Feixas, M.; Sbert, M.; Chuang, L.; Wallraven, C. A Survey of Viewpoint Selection Methods for Polygonal Models. Entropy 2018, 20, 370. https://doi.org/10.3390/e20050370
Bonaventura X, Feixas M, Sbert M, Chuang L, Wallraven C. A Survey of Viewpoint Selection Methods for Polygonal Models. Entropy. 2018; 20(5):370. https://doi.org/10.3390/e20050370
Chicago/Turabian StyleBonaventura, Xavier, Miquel Feixas, Mateu Sbert, Lewis Chuang, and Christian Wallraven. 2018. "A Survey of Viewpoint Selection Methods for Polygonal Models" Entropy 20, no. 5: 370. https://doi.org/10.3390/e20050370
APA StyleBonaventura, X., Feixas, M., Sbert, M., Chuang, L., & Wallraven, C. (2018). A Survey of Viewpoint Selection Methods for Polygonal Models. Entropy, 20(5), 370. https://doi.org/10.3390/e20050370