Identification of Pulmonary Hypertension Using Entropy Measure Analysis of Heart Sound Signal



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
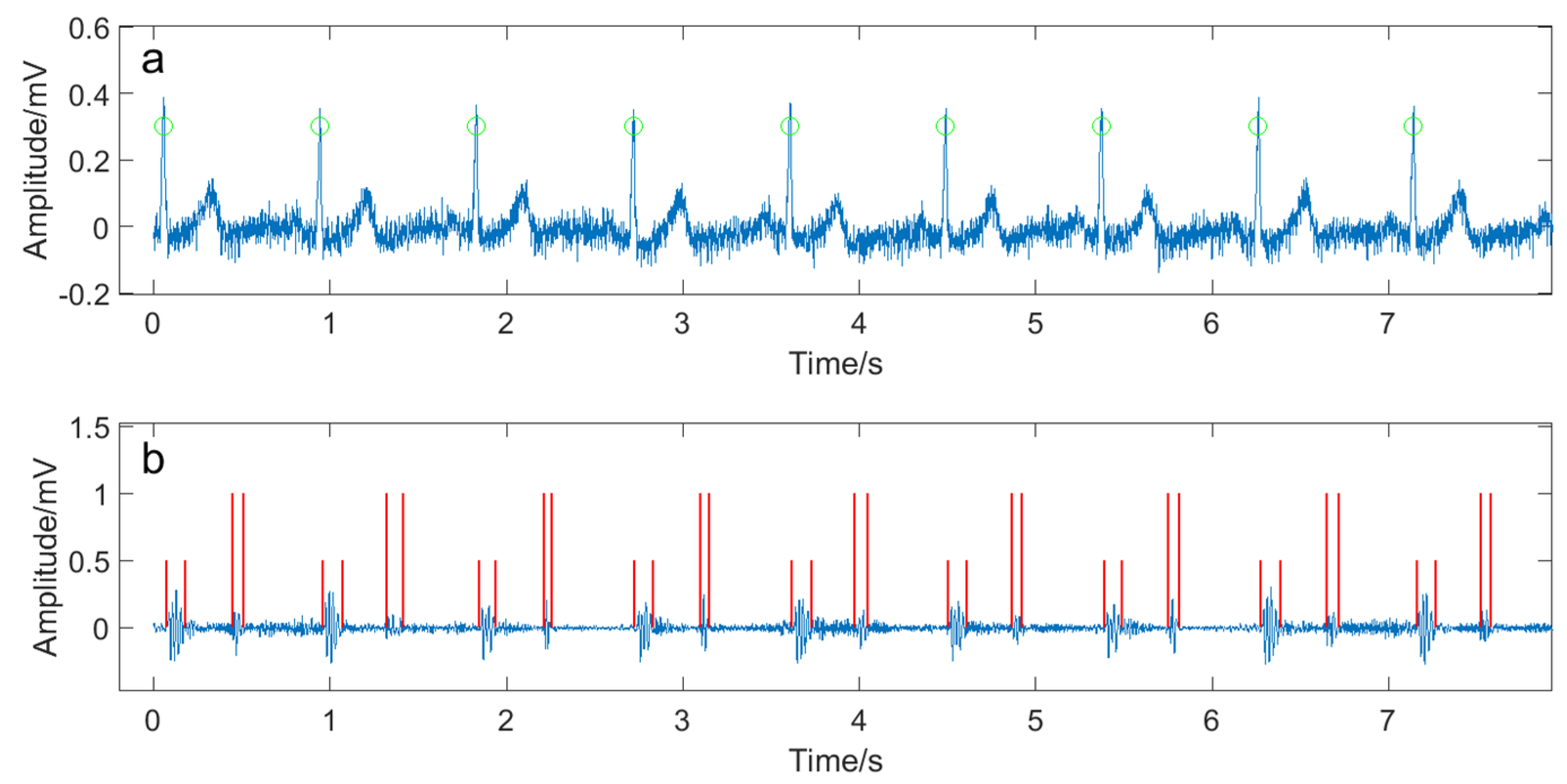
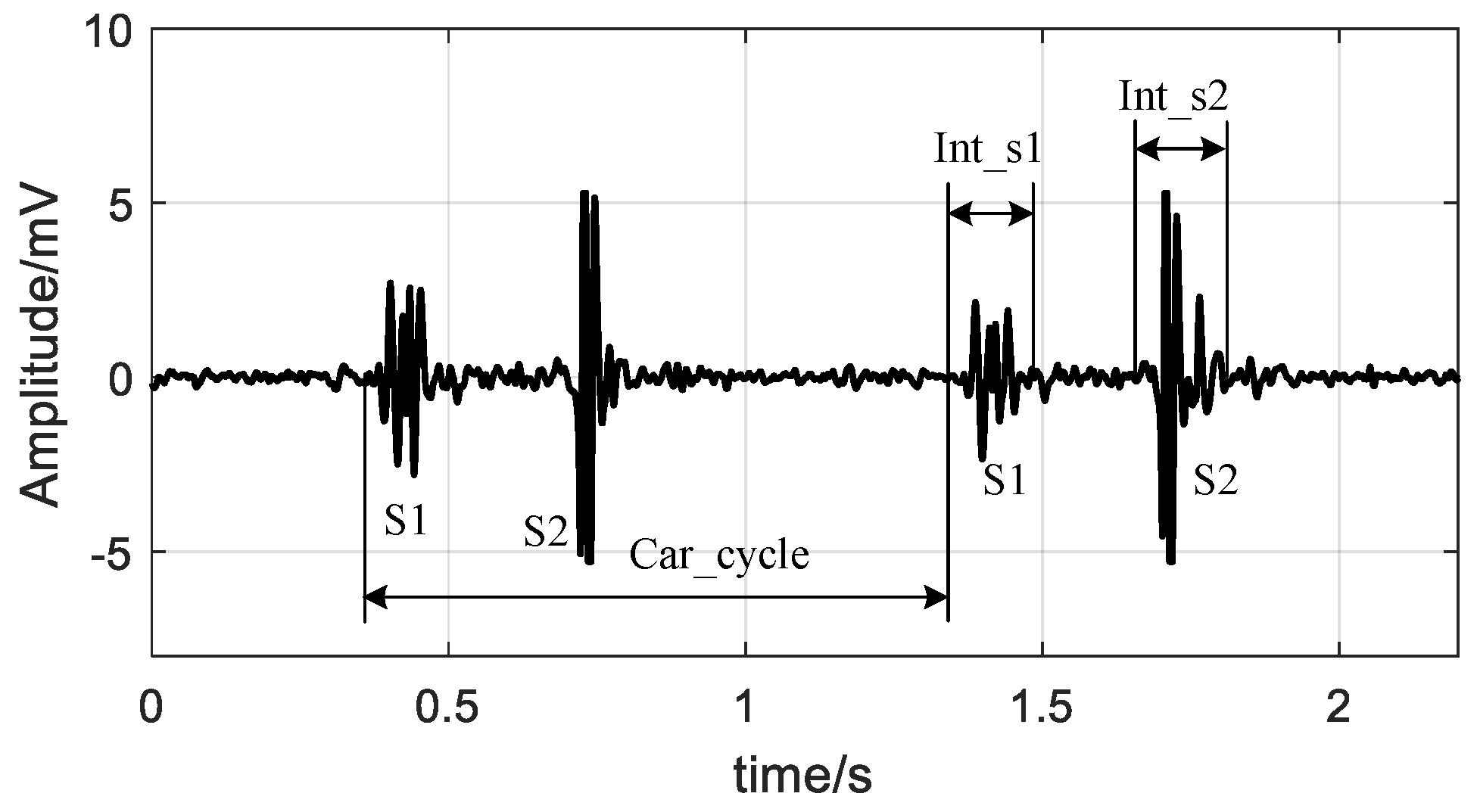
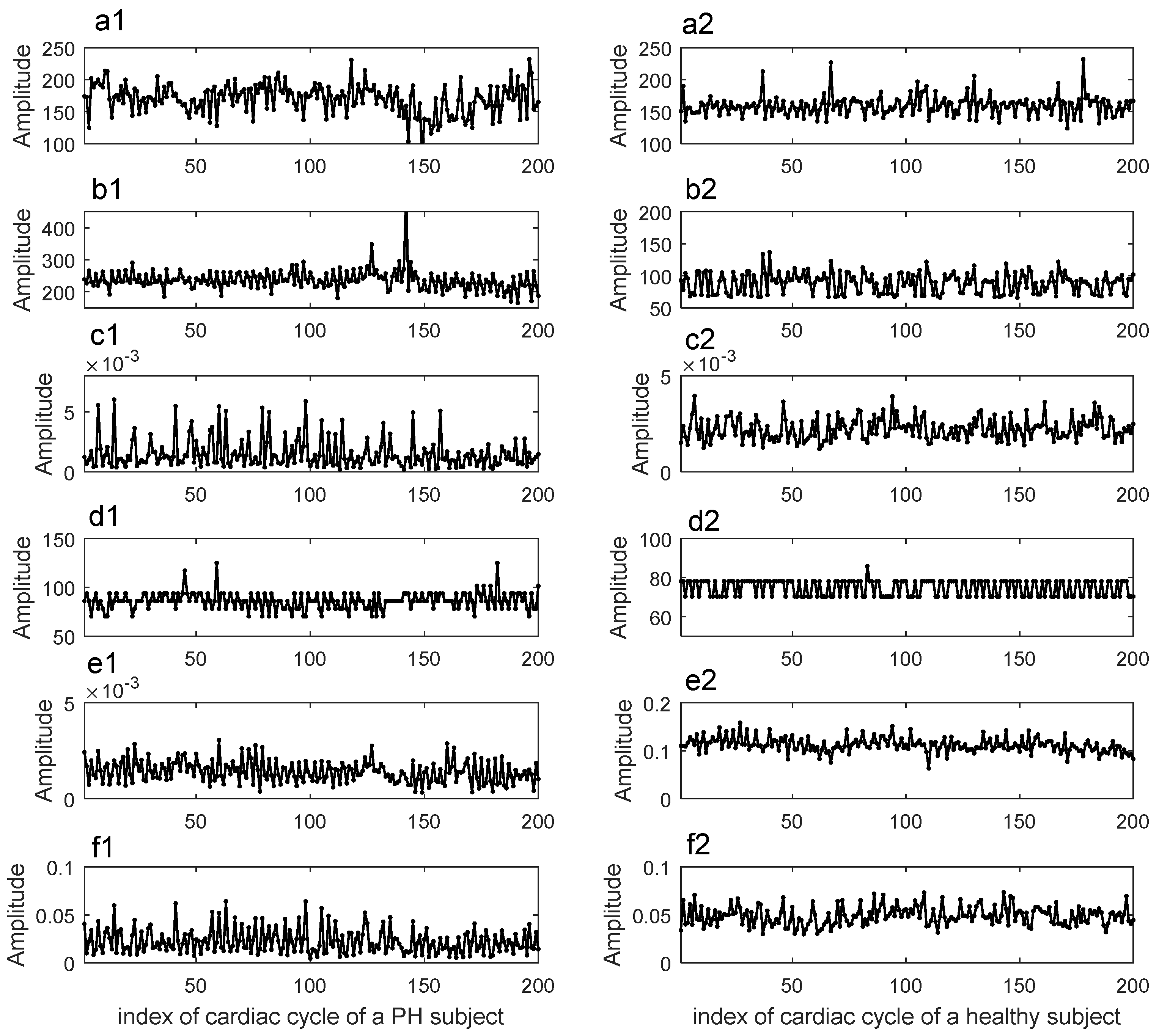
2.2. Feature Extraction
2.3. Entropy
2.3.1. Sample Entropy
2.3.2. Fuzzy Entropy
2.3.3. Fuzzy Measure Entropy
2.4. Statistical Tests
2.5. Probability Density Function of an Entropy Measure Fitted by Kernel Density Estimation
2.6. Identification of a PH Patient from a Healthy Subject Using the pdf Based on the Bayes’ Decision Rule
3. Results and Discussions
3.1. Significance of the Features and Reduction of the Age Confounding Factor
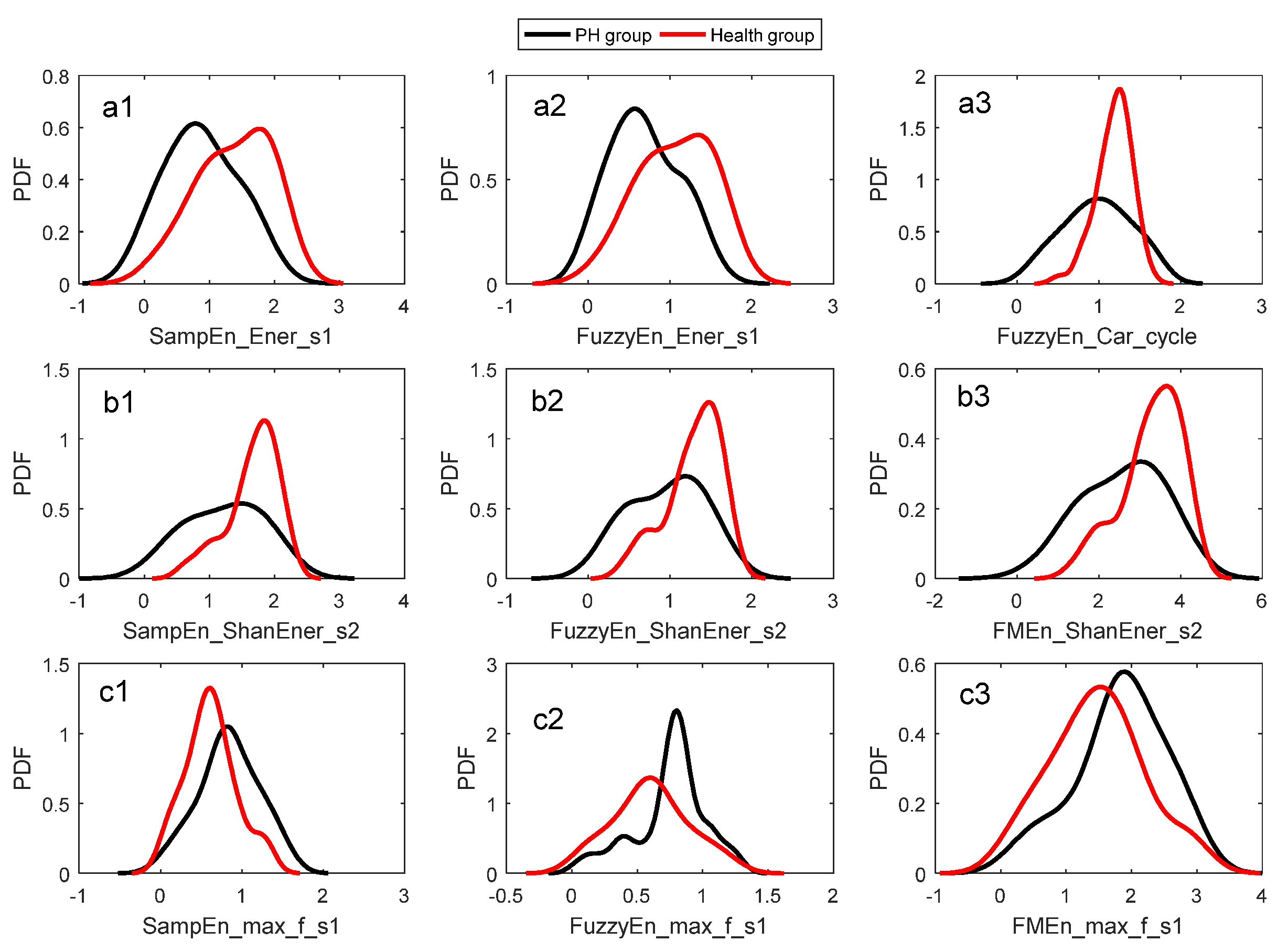
3.2. Identification Performance of a Single Entropy Measure
3.3. Identification Performance of Two Joint-Entropy Measures
3.4. Identification Performance of the Joint pdf of Multiple Entropy Measures
3.5. Summary and Discussions
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Ethical statement
Data availability
References
- Humbert, M.; Sitbon, O.; Chaouat, A.; Bertocchi, M.; Habib, G.; Gressin, V.; Yaïci, A.; Weitzenblum, E.; Cordier, J.F.; Chabot, F.; et al. Survival in patients with idiopathic, familial, and anorexigen-associated pulmonary arterial hypertension in the modern management Era. Circulation 2010, 122, 156–163. [Google Scholar] [CrossRef] [PubMed]
- Rich, S.; Dantzker, D.R.; Ayres, S.M.; Bergofsky, E.H.; Brundage, B.H.; Detre, K.M.; Fishman, A.P.; Goldring, R.M.; Groves, B.M.; Koerner, S.K.; et al. Primary pulmonary hypertension. A national prospective study. Ann. Intern. Med. 1987, 107, 216–223. [Google Scholar] [CrossRef] [PubMed]
- Leatham, A.; Weitzman, D. Auscultatory and phonocardiographic signs of pulmonary stenosis. Br. Heart J. 1957, 19, 303–317. [Google Scholar] [CrossRef] [PubMed]
- Longhini, C.; Baracca, E.; Brunazzi, C.; Vaccari, M.; Longhini, L.; Barbaresi, F. A new noninvasive method for estimation of pulmonary arterial pressure in mitral stenosis. Am. J. Cardiol. 1991, 68, 398–401. [Google Scholar] [CrossRef]
- Chen, D.; Pibarot, P.; Durand, L.G. Estimation of pulmonary artery pressure by spectral analysis of the second heart sound. Am. J. Cardiol. 1996, 78, 785–789. [Google Scholar] [CrossRef]
- Xu, J.; Durand, L.G.; Pibarot, P. A new, simple, and accurate method for non-invasive estimation of pulmonary arterial pressure. Heart 2002, 88, 76–80. [Google Scholar] [CrossRef] [PubMed]
- Nigam, V.; Priemer, R. A dynamic method to estimate the time split between the A2 and P2 components of the S2 heart sound. Physiol. Meas. 2006, 27, 553–567. [Google Scholar] [CrossRef] [PubMed]
- Elgendi, M.; Bobhate, P.; Jain, S.; Rutledge, J.; Coe, Y.; Zemp, R.; Schuurmans, D.; Adatia, I. Time-domain analysis of heart sound intensity in children with and without pulmonary artery hypertension: A pilot study using a digital stethoscope. Pulm. Circul. 2014, 4, 685–695. [Google Scholar] [CrossRef] [PubMed]
- Elgendi, M.; Bobhate, P.; Jain, S.; Guo, L.; Rutledge, J.; Coe, Y.; Zemp, R.; Schuurmans, D.; Adatia, I. Spectral analysis of the heart sounds in children with and without pulmonary artery hypertension. Int. J. Cardiol. 2014, 173, 92–99. [Google Scholar] [CrossRef] [PubMed]
- Elgendi, M.; Bobhate, P.; Jain, S.; Guo, L.; Kumar, S.; Rutledge, J.; Coe, Y.; Zemp, R.; Schuurmans, D.; Adatia, I. The unique heart sound signature of children with pulmonary artery hypertension. Pulm. Circul. 2015, 5, 631–639. [Google Scholar] [CrossRef] [PubMed]
- Dennis, A.; Arand, P.; Arand, P.; Dan, V. Noninvasive diagnosis of pulmonary hypertension using heart sound analysis. Comput. Biol. Med. 2010, 40, 758–764. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Tompkins, W.J. A real-time QRS detection algorithm. IEEE Trans. Biomed. Eng. 1985, 32, 230–236. [Google Scholar] [CrossRef] [PubMed]
- Liang, H.; Lukkarinen, S.; Hartimo, I. Heart sound segmentation algorithm based on heart sound envelogram. Comput. Cardiol. 1997, 24, 105–108. [Google Scholar]
- Luo, F.; Duan, P.P.; Wu, S.J. Research on short sequence power spectrum estimates based on the Burg algorithm. J. Xidian Univ. 2005, 32, 724–728. [Google Scholar]
- Alcaraz, R.; Rieta, J.J. A novel application of sample entropy to the electrocardiogram of atrial fibrillation. Nonlinear Anal. Real World Appl. 2010, 11, 1026–1035. [Google Scholar] [CrossRef]
- Lake, D.E.; Richman, J.S.; Griffin, M.P. Sample entropy analysis of neonatal heart rate variability. Am. J. Physiol. Regul. Integr. Comp. Physiol. 2002, 283, 789–797. [Google Scholar] [CrossRef] [PubMed]
- Schmid, S.E.; Hansen, J.; Hansen, C.H. Comparison of sample entropy and AR-models for heart sound-based detection of coronary artery disease. In Proceedings of the 2010 Computing in Cardiology, Belfast, UK, 26–29 September 2010; pp. 385–388. [Google Scholar]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Dawes, G.S.; Moulden, M.; Sheil, O. Approximate entropy, a statistic of regularity, applied to fetal heart rate data before and during labor. Obst. Gynecol. 1992, 80, 763–768. [Google Scholar]
- Castiglioni, P.; Rienzo, M.D. How the threshold “r” influences approximate entropy analysis of heart-rate variability. Comput. Cardiol. 2008, 35, 561–564. [Google Scholar]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circul. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Zhuang, J.; Yu, W.; Wang, Z. Measuring complexity using FuzzyEn, ApEn, and SampEn. Med. Eng. Phys. 2009, 31, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Xie, H.B.; He, W.X.; Liu, H. Measuring time series regularity using nonlinear similarity-based sample entropy. Phys. Lett. A 2008, 372, 7140–7146. [Google Scholar] [CrossRef]
- Liu, C.; Li, K.; Zhao, L.; Zheng, D.; Liu, C.; Liu, S. Analysis of heart rate variability using fuzzy measure entropy. Comput. Biol. Med. 2013, 43, 100–108. [Google Scholar] [CrossRef] [PubMed]
- Mann, H.B.; Whitney, D.R. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Sott, D.W. Density Estimation for Statistics and Data Analysis; Chapman and Hall: London, UK, 1986; Volume 39, pp. 296–297. [Google Scholar]
- Silverman, B.W. Multivariate Density Estimation: Theory, Practice, and Visualization; John Wiley & Sons Inc.: New York, NY, USA, 1992. [Google Scholar]
- Zhang, X.; King, M.L.; Hyndman, R.J. A Bayesian approach to bandwidth selection for multivariate kernel density estimation. Comput. Stat. Data Anal. 2006, 50, 3009–3031. [Google Scholar] [CrossRef]
- Sharma, D.; Yadav, U.B.; Sharma, P. The concept of sensitivity and specificity in relation to two types of errors and its application in medical research. J. Reliab. Stat. Stud. 2009, 2, 53–58. [Google Scholar]
- Curtin, F.; Schulz, P. Multiple correlations and Bonferroni’s correction. Biol. Psychiatry 1998, 44, 775–777. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Value | Range |
|---|---|---|
| Number (M/F) | 50 (26/24) | - |
| Age (year) | 69.4 ± 12.3 | 33–89 |
| Height (cm) | 164.0 ± 8.4 | 148–177 |
| Weight (kg) | 64.5 ± 12.6 | 32–90 |
| BMI (kg/m2) | 23.9 ± 4.3 | 14.2–35.3 |
| PSBP (mmHg) | 38.4 ± 11.8 | 20.4–68.0 |
| Item | Value | Range |
|---|---|---|
| Number (M/F) | 54 (47/7) | - |
| Age (year) | 32.6 ± 14.9 | 22–67 |
| Height (cm) | 172.5 ± 7.0 | 155–184 |
| Weight (kg) | 64.3 ± 7.8 | 43–76 |
| BMI (kg/m2) | 21.6 ± 2.3 | 17.6–26.9 |
| PSBP (mmHg) | <25 | - |
| No. | Name | Physical Meaning |
|---|---|---|
| 1 | Int_s1 | Time interval of S1 |
| 2 | Int_s2 | Time interval of S2 |
| 3 | Car_cycle | Cardiac cycle |
| 4 | Max_pow_s1 | Maximum magnitude of the power spectral density of S1 |
| 5 | Max_f_s1 | The frequency value corresponding to “Max_pow_s1” |
| 6 | Max_pow_s2 | Maximum magnitude of the power spectral density of S2 |
| 7 | Max_f_s2 | The frequency value corresponding to “Max_pow_s2” |
| 8 | Ener_s1 | Average energy of S1 |
| 9 | Ener_s2 | Average energy of S2 |
| 10 | ShanEner_s1 | Average Shannon energy of S1 |
| 11 | ShanEner_s2 | Average Shannon energy of S2 |
| Algorithm 1: identification using a single entropy measure |
| Let be the pdf of an entropy measure of the PH patient group and be the pdf of the entropy measure of the health control group. The entropy measure of an unknown subject is . If then the unknown subject is judged as a PH patient else the unknown subject is judged as a healthy subject |
| Algorithm 2: identification using joint entropy measures |
| Let be the pdf of joint entropy measures of the PH patient group and be the joint pdf of the entropy measures of the health control group. The entropy measure vector of an unknown subject is . If then the unknown subject is judged as a PH patient else the unknown subject is judged as a healthy subject |
| No. | Entropy Measure | p Value | CC. | No. | Entropy Measure | p Value | CC. |
|---|---|---|---|---|---|---|---|
| 1 | SampEn_Ener_s1 | 1.49 × 10−5 | −0.30 | 18 | SampEn_ShanEner_s1 | 9.79 × 10−7 | −0.37 |
| 2 | FuzzyEn_Ener_s1 | 2.12 × 10−5 | −0.29 | 19 | FuzzyEn_ShanEner_s1 | 3.67 × 10−6 | −0.35 |
| 3 | FMEn_Ener_s1 | 6.42 × 10−6 | −0.33 | 20 | FMEn_ShanEner_s1 | 1.60 × 10−6 | −0.38 |
| 4 | SampEn_ShanEner_s2 | 5.88 × 10−5 | −0.28 | 21 | FMEn_max_f_s2 | 1.52 × 10−6 | 0.41 |
| 5 | FuzzyEn_ShanEner_s2 | 6.57 × 10−5 | −0.27 | 22 | SampEn_Ener_s2 | 1.11 × 10−5 | −0.31 |
| 6 | FMEn_ShanEner_s2 | 1.29 × 10−4 | −0.26 | 23 | FuzzyEn_Ener_s2 | 1.76 × 10−5 | −0.31 |
| 7 | SampEn_max_f_s1 | 7.25 × 10−4 | 0.21 | 24 | FMEn_Ener_s2 | 3.36 × 10−5 | −0.31 |
| 8 | FuzzyEn_max_f_s1 | 3.52 × 10−3 | 0.14 | 25 | SampEn_max_pow_s1 | 1.58 × 10−5 | −0.40 |
| 9 | FMEn_max_f_s1 | 6.47 × 10−3 | 0.16 | 26 | FuzzyEn__max_pow_s1 | 1.14 × 10−5 | −0.40 |
| 10 | SampEn_Car_cycle | 4.90 × 10−3 | −0.31 | 27 | FMEn_max_pow_s1 | 3.91 × 10−6 | −0.40 |
| 11 | FuzzyEn_Car_cycle | 3.99 × 10−3 | −0.30 | 28 | SampEn_Int_s2 | 5.38 × 10−4 | 0.39 |
| 12 | FMEn_Car_cycle | 1.89 × 10−3 | −0.33 | 29 | FuzzyEn_Int_s2 | 5.06 × 10−4 | 0.42 |
| 13 | SampEn_max_pow_s2 | 1.20 × 10−9 | −0.41 | 30 | FMEn_Int_s2 | 9.26 × 10−3 | 0.37 |
| 14 | FuzzyEn__max_pow_s2 | 2.69 × 10−9 | −0.39 | 31 | SampEn_Int_s1 | 4.22 × 10−1 | 0.21 |
| 15 | FMEn_max_pow_s2 | 6.13 × 10−9 | −0.39 | 32 | FuzzyEn_Int_s1 | 2.35 × 10−1 | 0.22 |
| 16 | SampEn_max_f_s2 | 8.02 × 10−7 | 0.43 | 33 | FMEn_Int_s1 | 3.92 × 10−1 | 0.19 |
| 17 | FuzzyEn_max_f_s2 | 4.27 × 10−5 | 0.39 |
| No. | Entropy Measure | Sen. | Spe. | Acc. | AUC | Corresponding pdf Pair and ROC Curve |
|---|---|---|---|---|---|---|
| 1 | SampEn_Ener_s1 | 0.720 | 0.648 | 0.683 | 0.720 | Figure 6a1 and Figure 7a1 |
| 2 | FuzzyEn_Ener_s1 | 0.680 | 0.648 | 0.663 | 0.714 | Figure 6a2 and Figure 7a2 |
| 3 | FuzzyEn_Car_cycle | 0.600 | 0.852 | 0.731 | 0.709 | Figure 6a3 and Figure 7a3 |
| 4 | SampEn_ShanEner_s2 | 0.580 | 0.796 | 0.692 | 0.667 | Figure 6b1 and Figure 7b1 |
| 5 | FuzzyEn_ShanEner_s2 | 0.480 | 0.778 | 0.635 | 0.681 | Figure 6b2 and Figure 7b2 |
| 6 | FMEn_ShanEner_s2 | 0.500 | 0.796 | 0.654 | 0.670 | Figure 6b3 and Figure 7b3 |
| 7 | SampEn_Max_f_s1 | 0.540 | 0.759 | 0.654 | 0.629 | Figure 6c1 and Figure 7c1 |
| 8 | FuzzyEn_Max_f_s1 | 0.660 | 0.648 | 0.654 | 0.646 | Figure 6c2 and Figure 7c2 |
| 9 | FMEn_Max_f_s1 | 0.580 | 0.667 | 0.625 | 0.584 | Figure 6c3 and Figure 7c3 |
| No. | Joint Two Entropy Measures | Sen. | Spe. | Acc. | AUC | Corresponding pdfs |
|---|---|---|---|---|---|---|
| 1 | SampEn_Ener_s1/SampEn_ShanEner_s2 | 0.680 | 0.796 | 0.740 | 0.770 | Figure 8a |
| 2 | SampEn_Ener_s1/FuzzyEn_ShanEner_s2 | 0.680 | 0.796 | 0.740 | 0.759 | Figure 8b |
| 3 | SampEn_Ener_s1/FMEn_ShanEner_s2 | 0.640 | 0.778 | 0.712 | 0.756 | Figure 8c |
| 4 | FuzzyEn_Ener_s1/SampEn_ShanEner_s2 | 0.640 | 0.778 | 0.712 | 0.759 | Figure 8d |
| 5 | FuzzyEn_Ener_s1/FuzzyEn_ShanEner_s2 | 0.640 | 0.759 | 0.702 | 0.748 | Figure 8e |
| 6 | FuzzyEn_Ener_s1/FMEn_ShanEner_s2 | 0.620 | 0.778 | 0.702 | 0.741 | Figure 8f |
| 7 | FMEn_ShanEner_s2/SampEn_Max_f_s1 | 0.540 | 0.704 | 0.625 | 0.680 | Figure 8g |
| 8 | FMEn_ShanEner_s2/FuzzyEn_Max_f_s1 | 0.580 | 0.648 | 0.615 | 0.680 | Figure 8h |
| 9 | FMEn_ShanEner_s2/FMEn_Max_f_s1 | 0.520 | 0.722 | 0.625 | 0.666 | Figure 8i |
| No. | Joint Entropy Measures | Number of Joint Measures | Sen. | Spe. | Acc. | AUC |
|---|---|---|---|---|---|---|
| 1 | SampEn_Ener_s1/FuzzyEn_Ener_s1/SampEn_Max_f_s1/FuzzyEn_Car_cycle/FMEn_Max_f_s1 | 5 | 0.740 | 0.870 | 0.808 | 0.829 |
| 2 | SampEn_Ener_s1/SampEn_Max_f_s1/FuzzyEn_Max_f_s1/FuzzyEn_Car_cycle | 4 | 0.740 | 0.870 | 0.808 | 0.814 |
| 3 | SampEn_Ener_s1/SampEn_Max_f_s1/FuzzyEn_Car_cycle/FMEn_Max_f_s1 | 4 | 0.740 | 0.870 | 0.808 | 0.813 |
| 4 | SampEn_Ener_s1/FuzzyEn_Ener_s1/SampEn_Max_f_s1/FuzzyEn_Car_cycle | 4 | 0.720 | 0.870 | 0.798 | 0.839 |
| 5 | SampEn_Ener_s1/FuzzyEn_Ener_s1/SampEn_Max_f_s1/FuzzyEn_Max_f_s1/FuzzyEn_Car_cycle/FMEn_Max_f_s1 | 6 | 0.740 | 0.852 | 0.798 | 0.810 |
| 6 | SampEn_Ener_s1/FuzzyEn_Car_cycle/FMEn_Max_f_s1 | 3 | 0.720 | 0.870 | 0.798 | 0.798 |
| 7 | SampEn_Ener_s1/SampEn_Max_f_s1/FuzzyEn_Car_cycle | 3 | 0.720 | 0.852 | 0.788 | 0.821 |
| 8 | SampEn_Ener_s1/FuzzyEn_Ener_s1/SampEn_Max_f_s1/FuzzyEn_Max_f_s1/FuzzyEn_Car_cycle | 5 | 0.760 | 0.815 | 0.788 | 0.818 |
| 9 | SampEn_Ener_s1/SampEn_Max_f_s1/FuzzyEn_Max_f_s1/FuzzyEn_Car_cycle/FMEn_Max_f_s1 | 5 | 0.720 | 0.833 | 0.779 | 0.801 |
| 10 | FuzzyEn_Ener_s1/SampEn_Max_f_s1/FuzzyEn_Car_cycle | 3 | 0.680 | 0.852 | 0.769 | 0.815 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, H.; Jiang, Y.; Li, T.; Wang, X. Identification of Pulmonary Hypertension Using Entropy Measure Analysis of Heart Sound Signal. Entropy 2018, 20, 389. https://doi.org/10.3390/e20050389
Tang H, Jiang Y, Li T, Wang X. Identification of Pulmonary Hypertension Using Entropy Measure Analysis of Heart Sound Signal. Entropy. 2018; 20(5):389. https://doi.org/10.3390/e20050389
Chicago/Turabian StyleTang, Hong, Yuanlin Jiang, Ting Li, and Xinpei Wang. 2018. "Identification of Pulmonary Hypertension Using Entropy Measure Analysis of Heart Sound Signal" Entropy 20, no. 5: 389. https://doi.org/10.3390/e20050389
APA StyleTang, H., Jiang, Y., Li, T., & Wang, X. (2018). Identification of Pulmonary Hypertension Using Entropy Measure Analysis of Heart Sound Signal. Entropy, 20(5), 389. https://doi.org/10.3390/e20050389