1. Introduction
Oil and natural gas can be transported via pipeline at both lower cost and higher capacity when compared to rail and road transit. Pipeline ‘health’ involves unique challenges that include corrosion, leakage, and rupture, impacting transportation efficiency and safety. Through analysis of data gathered from health monitoring sensors and human inspections, pipeline health along with the efficiency and safety of oil and gas transportation can be monitored. However, practicality and cost limits sensing and monitoring, which in turn restricts data availability for health monitoring. This presents itself as a multi-objective sensor selection optimization problem involving the number, location, and type of sensors for a given pipeline network [
1]. This paper outlines a sensor selection optimization methodology that leverages the concept of information entropy within a Bayesian framework for system modeling and health monitoring. The overarching aim of this methodology is to obtain more system health information based on an efficient use of information sources.
The problem of optimizing sensor placement has received considerable attention in recent years [
2,
3]. The approaches of extant optimization models differ in their objective functions, assumptions regarding equation linearity, solution methods, and how they deal with uncertainty.
Table 1 lists and categorizes current literature in this regard.
Most of the studies have a single objective function and do not consider system uncertainties. The highlighted cells in
Table 1 identify optimization methodology characteristics that are common with the methodology developed herein.
Generally, all sensor optimization methodologies need to deal with trade-offs between sensor reliability, cost, weight, and number. This naturally lends itself to a multi-objective optimization problem involving objective functions with multiple indices. Unlike single objective optimization, multi-objective optimization problems could have multiple optimal solutions and the decision maker can select one of the feasible solutions depending upon the importance of the indices and system limitations [
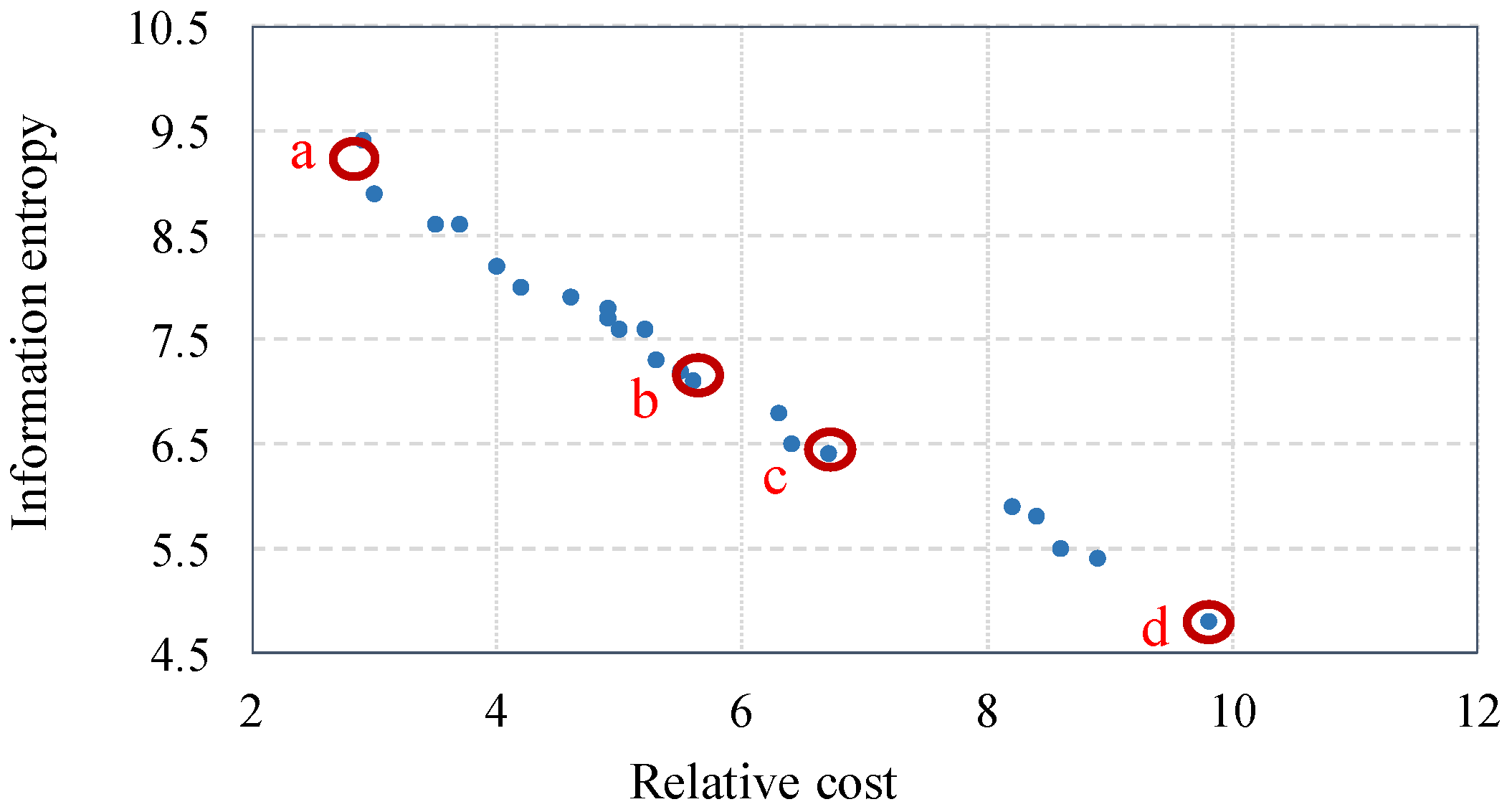
20]. In this paper, an approach that develops Pareto frontier is presented to derive optimal feasible solutions depending on the decision maker’s preference on sensor cost or system information certainty.
A feature of the approach developed herein is the ability to model uncertainties in system model and measurement process. These uncertainties are typically associated with leak location and environmental factors, process conditions, measurement accuracy, etc. The proposed methodology uses Bayesian networks (BNs), integrating representation of the system configuration and information sources, and associated uncertainties. There have been several studies focused on optimizing sensor placement using BN. Flynn et al. [
21] define two error types associated with damage detection and use BN to quantify two performance measures of a given sensor configuration. The so called genetic algorithm is used to derive the performance-maximizing configuration. In Li et al. [
22] a probabilistic model based on BN is developed that considers load uncertainty and measurement error. The optimal sensor placement is derived by optimizing three distinct utility functions that describe quadratic loss, Shannon information, and Kullback–Leibler divergence. Other studies that focus on BNs include objective functions that describe the minimum probability of errors [
23], and the smallest and largest local average log-likelihood ratio [
24]. In our study, sensor selection optimization methodology maximizes information metric on system health considering sensor costs. Information entropy quantifies the uncertainty of random variables [
25].
Minimizing the information entropy decreases the uncertainty. The effectiveness of any model-based condition monitoring scheme is a function of the magnitude of uncertainty in both the measurements and models [
26,
27]. In [
27], it is demonstrated that uncertainty affects all aspects of system monitoring, modelling, and control, and naturally the identification of the optimal sensor combination. The uncertainty stemming from modelling and sensors should therefore be considered in the optimization procedure.
Uncertainty can be quantified using different metrics. One of the popular metrics of uncertainty quantification is information entropy index. Minimizing the differential entropy decreases the uncertainty or disorder, and hence increases information value [
25].
A key feature of the method proposed in this paper is that here the optimization is based on answering the following question: which combination of sensor types and locations provides highest amount of information about the reliability metric of interest (e.g., probability of system failure)? The increase or decrease in information is measured by entropy. As a result, different types of sensors can be compared based on their information value, and the optimal sensor combination identified based on a common metric.
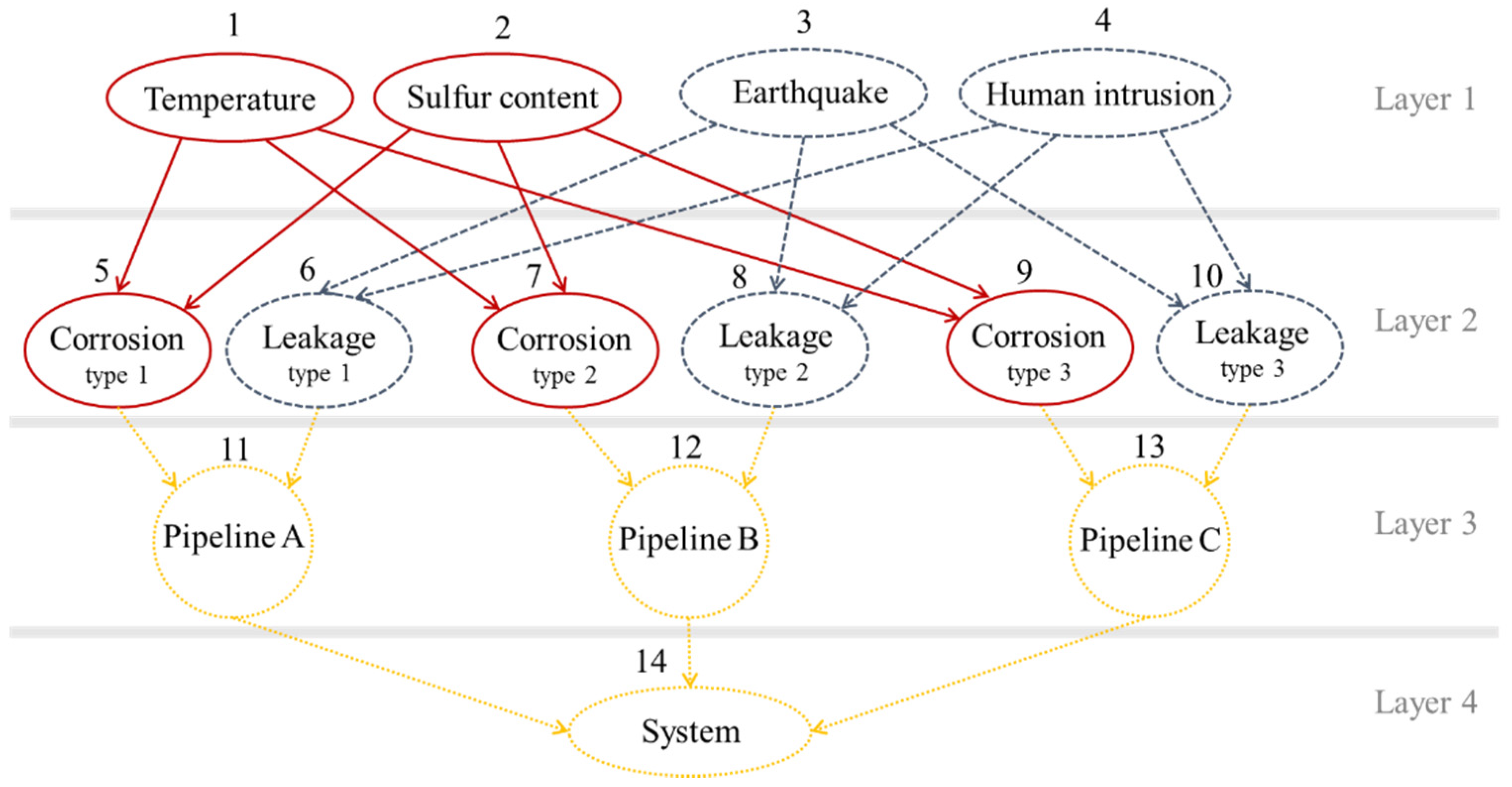
For instance, in a gas pipeline health monitoring context, detectors for temperature, sulfur content, seismic load, human intrusion, corrosion rate, and pipe leakage are compared based on how they change the information on pipe rupture probability (system state), and then the best combination in terms of information gain, considering budget limits, is identified.
We also note that other research presented in
Table 1, focus on the placement of one type of sensor, whereas in the present paper considers simultaneous use of different types sensor as part of optimization on information. For example, in [
10], contaminant detectors are optimally placed in a water network in order to reduce the detection time and increase the protected population from consuming contaminated water.
In
Section 2 of this paper, information entropy as it relates to BNs is explained. The proposed sensor selection model based on BNs is presented in
Section 3, and the optimization methodology is described in
Section 4. In order to illustrate the proposed methodology, it is applied to a very simple oil pipeline example with key features adequate to demonstrate the method and its results. The network model and results are discussed in
Section 5. Finally, the study is concluded with an overall discussion on key advantages of the proposed methodology in
Section 6.
2. An Overview of Information Entropy and BNs
Incomplete information and probabilistic representation of information are generally prevalent in system health monitoring applications. Quantification of the uncertainty is one of the primary challenges for measuring the extent to which you have information regarding a system.
In recent years, several authors have investigated uncertainty representation using the concept of entropy and information theory. Information entropy is used to quantify the average uncertainty of an information source. Let
X be a random variable with probability distribution of
P, where
pi is the probability of outcomes
. The information content associated with a particular value of this random variable, as defined by the probability distribution can be calculated as Equation (1) [
28].
The information function, computes the amount of information (measured in bits) conveyed by a particular state. The expected value of information is the information entropy function , which is calculated by Equation (2).
The expression for information entropy is developed further in Equation (3) for discrete random variables [
28].
Generalizing to continuous random variables, the information entropy of the random variable
is defined as
The information entropy increases with respect to the data uncertainty of a random variable. It also increases as the ‘dispersion’ of a random variable increase, as illustrated in
Figure 1 for the standard deviation of a normal distribution function
.
In methodology proposed below, the distribution of BN (or system) state variables [
10] can be constructed by domain experts or synthesized automatically from system operating data. Probability distributions of these state variables convey information uncertainty of the system status. In a BN with single valued probabilities of random variables
and joint probability,
, given by
the information entropy is calculated from Equation (6), [
25,
29].
3. Sensor Selection Optimization Based on Information Entropy in BNs
The assessment of system health and condition is based on our understanding of the BN node state variables, which are represented by their joint probability distributions.
Figure 2 illustrates the inference engine of a simple three-node BN in which each node has two states: success (green) and failure (yellow). The joint probabilities of this network are presented in
Table 2.
According to
Table 2, the failure probability of the pipeline node can be calculated as
The probability of the safe state of pipeline node is then equal to
, which is presented in
Figure 2 with a green box.
As a sensor is placed on a node, the posterior probability distribution of BN state variables can be computed using evidence nodes. Evidence contains information regarding a set of random variables, and the posterior probability of monitored state of an evidence node is equal to one at the observed value.
For instance, in
Figure 2, sensor on corrosion node updates the probabilities of this node. The sensor can detect two states of ‘corrosion’ (Scenario (a)) and ‘no corrosion’ (Scenario (b)) in the pipeline. For instance, in Scenario (a), the probability of corrosion is updated to 1, and the probability of no corrosion state is updated to 0, as presented in
Figure 2a. Consequently, the posterior probability distribution of BN states is updated.
In this paper, placing a sensor at a particular place in a system makes the corresponding node an evidence node. Moreover, it is assumed that the sensor reports all states of the evidence node. Therefore, total system information entropy can be calculated based on the probability distribution of the state of the evidence node as shown in Equation (9)
Here, is the number of node states, is the number of BN nodes and is the number of possible evidence observations scenarios based on selected sensor and is its probability.
Based on the prior knowledge of the state variables’ probability distribution, the total system information entropy is 0.77, which is equal to the sum of the all individual node information entropies.
By placing a sensor on the corrosion node, the system information entropy is calculated using all possible sensor observations (evidence). In the example below, possible sensor evidence observations are two scenarios (a) and (b), and the total system information entropy would be 0.44
As can be seen, corrosion node has two states. Therefore, two evidence observation scenarios are possible. Scenario (a) is the failure state of the corrosion node (sensor does not detect corrosion) and scenario (b) is its success (sensor detects corrosion). In Equation (11), and are the prior probabilities of corrosion node states for (a) and (b) scenarios, respectively.
3.1. Information Value
In the example of
Figure 2, it is assumed that information associated with all nodes have the same weight (value). The weight of a node information reflects the extent to which it informs a subsequent decision, or yields value to an organization or activity, such as the modification of inspection plan. In most cases, the expected cost of failure of different system elements (represented by BN nodes) are not identical. Consequently, the information entropy importance of different nodes would not be equal. To accommodate such situations, information entropy of each node can be weighted via Equation (12).
where
is the number of nodes with different information value. The weights sum to one. The total system information entropy is then calculated using Equation (13).
3.2. Sensor Reliability and Measurement Uncertainty
BN state variable probability distributions are continually updated using sensor data, noting that they can be uncertain [
25]. This uncertainty may be inherent to the process of gathering data (condition variability and human observation uncertainty) or it may stem from the sensor uncertainty. To consider these uncertainties, sensors can be represent as ‘soft evidence’ nodes, which carry two additional piece of information: the operational mode and the probability of its occurrence [
30].
The state of knowledge about BN ‘soft evidence’ nodes are usually modelled by probability distributions using Jeffrey’s rule [
29]. The posterior probability of node B’s state variable presented in
Figure 3 is defined as
where,
is the conditional probability of A given ‘soft evidence’, and
is the conditional probability of B given A, before evidence.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}