1. Introduction
Over the last decade, clustering algorithms have played an important role in signal processing and data mining in applications such as community detection [
1,
2], image segmentation [
3,
4,
5], remote image processing [
6], big data network clustering [
7] and subspace analysis [
8]. Cluster analysis attempts to partition data points into disjoint groups such that data points that correspond to the same label are similar and the cross-group similarity is small.
In large-scale clustering, Nyström approximation is a common choice for approximating the eigensystem of a large matrix. Given a training set and its eigensystem, to perform Nyström approximation, one calculates the similarity values between the training set and the remaining data and uses the resulting similarity matrix to approximate the eigenvectors of the remaining data points.
A fundamental problem in Nyström approximation is the measurement of the similarity between a training set and its remaining data points. Given a new data point and a Gaussian kernel parameter
, most methods employ the empirical affinity vector,
k, to evaluate the links between this new point and the training set:
where
is the
i-th element in
k,
denotes the new point and
is the
i-th point in the training set.
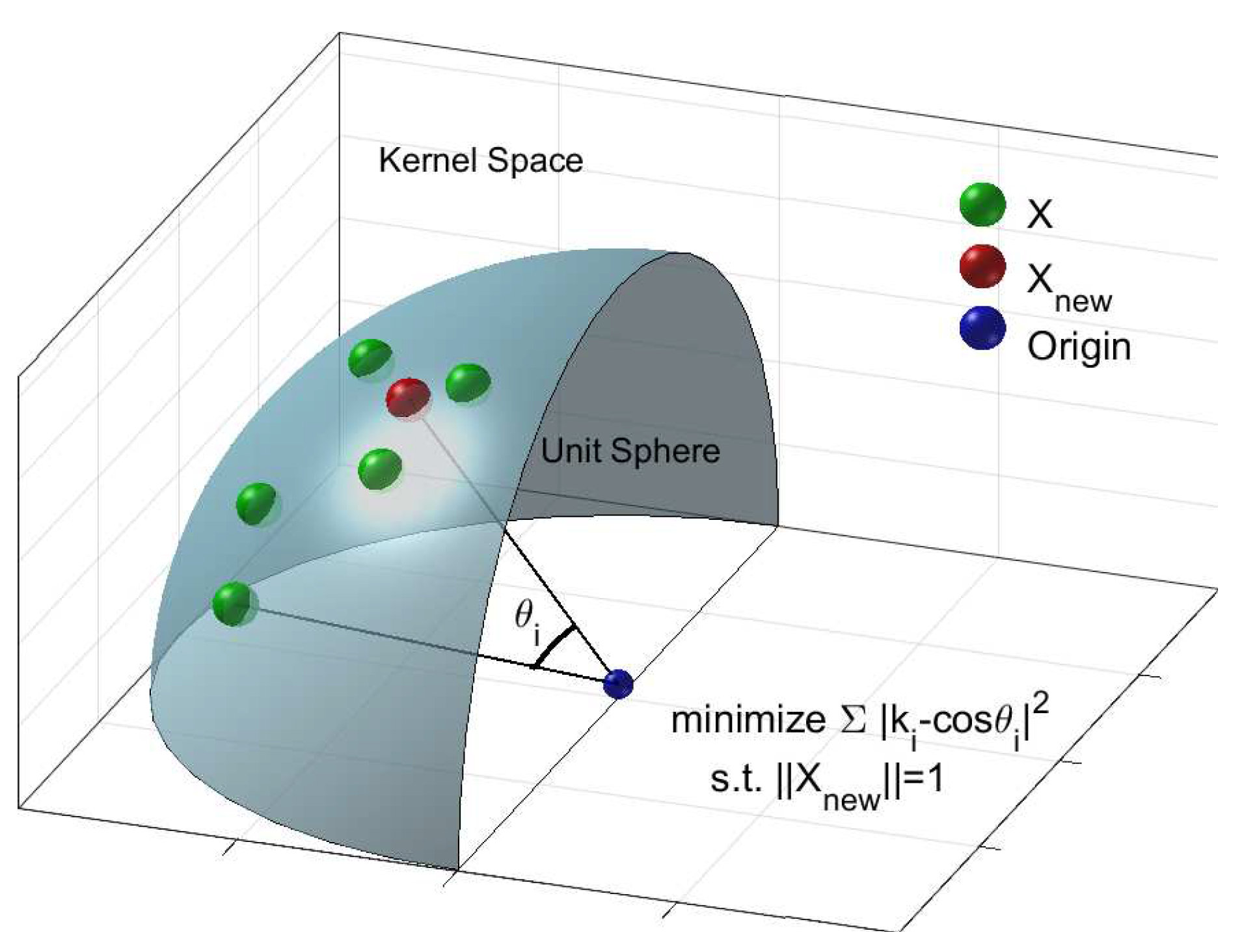
Despite its broad applications in kernel approximation, in this paper, we still focus our attention on the construction of k. We begin our argument with the following question: Given the eigensystem of a training set, should we evaluate the similarity by the Euclidean distance, which is isometric? With the training set eigensystem in hand, we determine the underlying structure of the data or, more specifically, the manifold on which the data points lie. Thus, we prefer to evaluate similarities on the manifold, instead of using an isometric metric, such as the Euclidean distance. In this paper, we analyse the construction of k, which comports with the learned manifold. Our goal in this paper is to construct a new k for Nyström approximation and, consequently and ultimately, improve the clustering performance.
Many works on the modification of k have been proposed in recent years. Sparse representation is one of the most promising techniques in the literature. Sparse representation describes data in a low-dimensional subspace in which data are self-expressive. Data in such a subspace can be efficiently encoded as a linear or affine combination of other points. Sparse spectral clustering and its variants employ various cost functions that differ in their sparsity measurement and constraints.
In this paper, we propose replacing
k with its projections on the leading eigenvectors:
. As our motivation, we consider the
k-construction as the optimal solution that satisfies the following: (a) its corresponding kernel space data point
minimizes
, and (b)
is on the unit sphere defined by the Gaussian kernel, where
X stands for the training points in the kernel space. The cost function guarantees that the optimal
is close to
k and the constraint ensures that
is on the unit sphere defined by the Gaussian kernel. We illustrate our motivation in
Figure 1.
Our contributions include the following:
We show that in Nyström approximation, the projections of k on the leading training set eigenvectors are more suitable for clustering.
The projections, entitled in this paper, are the solution to the Quadratic Optimization Over a Sphere (QOOS) problem defined by Nyström approximation.
Experimental results show that replacing k with generates slight improvements on clustering.
The rest of this paper is organized as follows:
Section 2 reviews related works in large-scale data spectral clustering. Our algorithm is described in
Section 3.
Section 4 shows the experimental results on several real-world datasets. We present our conclusions in
Section 5.
2. Related Works
The spectral clustering problem is identical to solving for the eigenvectors of a kernel matrix
, which is generated to reveal similarities among data. To speed up the eigenvector solution on
K, Nyström-based methods [
9] are frequently used. The basic idea of Nyström is to sample various data points and construct the low-rank approximation to
K from the sampled data points. In addition to Nyström, in the subspace clustering community, building the affinity matrix
K correctly is a fundamental problem. The intrinsic characteristics of the dataset, such as sparsity or nearest neighbours, are employed to modify the affinity matrix
K. In this section, we categorize the related works into two classes: (a) Nyström methods and (b) subspace clustering. Nyström is the most popular method in approximating eigenvectors in spectral clustering. Subspace clustering, on the other hand, is a general topic that covers spectral clustering and applies Nyström for acceleration.
2.1. Nyström
Nyström is an efficient way to generate a low-rank representation of the desired kernel matrix of a large dataset. Without loss of generality, the columns and rows of
K can be arranged according to the selected columns and:
where
is the similarity matrix among the sampled data,
is the similarity matrix of the remaining data to the sample set and
the matrix of similarities among the remaining data.
Nyström uses an
matrix
and an
matrix
E to approximate
K by:
and approximates the leading
l eigenvalues
and eigenvectors
by:
where
m is the size of the sample set,
represents the Moore–Penrose pseudo-inverse of
and
are the leading
l eigenvalues of
with the corresponding eigenvectors
.
Given the desired number of classes
l, the corresponding Laplacian matrix should be of rank
l. Nie et al. [
10] accounted for the rank-
l constraint by minimizing a cost function, which is composed of two parts: the first part ensures that the new affinity matrix is close to the original one, and the second part enforces the rank-
l constraint. A similar approach is proposed in [
11], where adaptive neighbours, instead of the nearest neighbours, were linked in
S. Recently, Langone and Suykens [
12] represented spectral clustering in a weighted kernel PCA formulation, which is well defined in [
13]. To reduce the time cost, Zhu et al. [
14] proposed Balanced
k-means based Hierarchical
k-means (BKHK), which adopts a balanced binary tree, thereby reducing the training computational complexity to
, where
d is the dimension of the input data and
i here is the iteration BKHK stopped. A dense similarity matrix always requires
in pairwise similarity calculations. Luo et al. [
15] estimated the sparse similarity matrix using
k-means accumulative consensus, which is locality-preserving and of low complexity. Langone et al. [
16] proposed an entropy-based Incomplete Cholesky Decomposition (ICD) method to handle the large-scale data clustering. The main idea in [
16] is to approximate the Laplacian matrix by ICD and efficiently solve the eigensystem of the approximated Laplacian matrix iteratively.
Most existing Nyström methods focus on a new structure in approximating eigenvectors of
K, e.g., [
12] with kernel PCA and [
14] of BKHK in sampling. Our proposed method, however, aims to modify
K, which is the input to Nyström approximation. Thus, we consider our method as a pre-processing benefiting the follow-ups, such as sampling [
14,
17] or approximating [
16].
2.2. Subspace Clustering
Another popular way to modify k is subspace clustering, in which different approaches are proposed for evaluating similarity values among data points. The affinity matrix is constructed by using the typical Gaussian kernel or another local-information-based method, which may not be a good choice for subspace clustering. Therefore, several affinity matrix construction methods have been proposed in recent years.
Sparse Subspace Clustering (SSC) [
18] searches for a sparse representation matrix
C as:
where
Y is the data matrix. It is proven that the optimal solution
C by SSC satisfies the block diagonal property when the subspaces are independent. Despite its advantages in clustering a dataset with a highly complex structure, SSC may suffer from the so-called “graph connectivity” issue [
19]. The
-norm in SSC ensures not only the sparsity in inter-class affinities, but also the inner-class similarities; in the latter case, we typically prefer a dense and well-linked similarity matrix for clustering. Similar to SSC, different cost functions are introduced for
C. Other than the sparsity cost, i.e., the
-norm in SSC, Least Squares Regression (LSR) [
20] minimizes the Frobenius norm of the representation matrix
C:
LSR tends to group highly correlated data together.
In addition to SSC and LSR, similarity by neighbourhood evaluation is a popular
K-construction approach. Locally Linear Representation (LLR) [
21] seeks to solve the following optimization problem for each data point
:
where
is the coefficient of
relative to its neighbours and
consists of the Euclidean distances
to its
k nearest neighbours.
3. Projections on Leading Eigenvectors as the Solution to the QOOS Problem
There is a critical issue that remains largely unresolved in the literature: given an affinity vector k from a Gaussian-kernel-mapped new point, is there a corresponding point in the kernel space such that and ? The first equality ensures that is the corresponding point to k and the second one ensures that is on the unit sphere specified by the Gaussian kernel. In this section, we present our main result: the projection of k on the leading eigenvectors u, which is calculated as , is a solution to the two equalities, where c is the user-assigned number of classes in clustering.
3.1. Quadratic Optimization Over a Sphere Problem
Instead of focusing on the two equalities directly, we focus on the following substitute question: given
k and
X, what is the optimal point
that satisfies:
Given the fixed value of
k, it is natural to take this
to represent the new data point in the kernel space. Furthermore, if the cost function in Equation (
9) reaches zero, then we prove the existence of the kernel-mapped point
with respect to
k.
The study of the optimality of
is the foundation for many applications. For example, in recent research on explicit feature mapping, Nyström extensions were applied to obtain points in the kernel space explicitly [
12]. Then, the EFM of points can be used for further clustering or classification, with the benefit of extremely low computational costs. A detailed analysis on
provides theoretical guarantees for those methods that employ
. In addition, as discussed in the next section, the projections of
k on the leading eigenvectors, namely
, are good substitutes to
k in the QOOS problem.
By defining
and
, Equation (
9) can be represented as:
Equation (
10) is a QOOS problem, which was well studied by Hager in [
22]. In the coming section, we will see that in Nyström approximation, Equation (
10) follows the degenerate case of Lemma 2.2 in [
22]. Then we present the closed form of
.
3.2. Degenerate Case of the Gaussian Kernel
As our theoretical foundation, we review the main results in [
22] in the following lemma.
Lemma 1. (Lemmas 2.1, 2.2 in [22], Lemmas 2.4 and 2.8 in [23]) Let be the eigendecomposition of A, where Λ is a diagonal matrix with diagonal elements and Φ consists of corresponding eigenvectors . Define , and . Then, the vector is a solution to Equation (10) if and only if c is chosen in the following way: (a) Degenerate case: If for all and:then for all ; for are arbitrary scalars that satisfy the condition: (b) Nondegenerate case: If (a) does not hold, then where is chosen so that: We will see in this section that our problem is the degenerate case in solving Equation (
10). Suppose that we are given the
affinity matrix
K and its eigendecomposition
, where
is a diagonal matrix with diagonal elements
and column vectors
as the corresponding eigenvectors. Similarly, the eigensystem of
is
, where
and
are the eigenvalues and eigenvectors, respectively. It is easy to verify that the leading
n eigenvalues of
and
are identical, namely
, with the corresponding eigenvectors
. The remaining
eigenvalues of
are all equal to zero. Thus,
In many applications such as clustering, the similarity matrix K is always a rank-deficient matrix, which indicates that the smallest eigenvalue is zero: .
Let
or the analogue to
in Lemma 1,
and
where
. The degeneracy condition in [
22] requires that (a) for all
,
and (b)
.
We show in the following theorem that if there exists that satisfies both and , then satisfies the degeneracy condition in Lemma 1.
Theorem 1. If there exists an satisfying and , then the QOOS problem of Equation (9) in the Gaussian kernel Nyström approximation satisfies the degeneracy condition in [22]. Proof. The last equality uses that is an eigenvector of whose corresponding eigenvalue is zero when . Thus, (a) is satisfied.
Let
be the angle between
and
. For
,
where in the last equality, we use the constraint
. Therefore,
, where equality holds if and only if the eigenvectors in
span the complete kernel space, i.e.,
. Thus, (b) is satisfied. ☐
3.3. Solution to the QOOS Problem
As shown in Lemma 1, the vector
is a solution to Equation (
9) if
a is chosen in the following way [
22]: (a) for all
, or
,
and (b)
for
are arbitrary scalars that satisfy the following condition:
Suppose there are p non-zero eigenvalues when ,
Recall that
. Then, for
, we set:
or, we set all scalars
,
, of the
zero eigenvalues to be equal. Then, we have:
Finally, we obtain the solution to Equation (
9) by:
3.4. Projections of k on the Leading Eigenvectors
In this section, we present our main result that
is a proper affinity vector with corresponding
that satisfies Equation (
9). Given the closed form of
from Equation (
17), we want to obtain the affinity vector of
, namely,
, and determine whether
.
Notice that:
and recall the definition of
, namely,
, where in the second equality, we use Equation (
18). Then,
follows:
where in the last equality, we use that
for
.
Equation (
19) shows that the projection of
k on any non-zero eigenvector, namely,
, is a proper affinity vector with corresponding
that satisfies both
and
. Thus, we can replace
k with
in the Nyström approximation.
In clustering tasks, we always use the leading eigenvectors to reveal the underlying structure of the data. For an ideal clustering task, i.e., a task in which the affinity value is one of two data points in the same class and zero for cross-class data points, there are exactly
c non-zero eigenvalues/eigenvectors, where
c is the number of classes. For a general clustering task in which affinity values are distorted, we assume that the leading
c eigenvectors span the proper subspace for clustering. Thus, instead of projecting
k on all
p non-zero eigenvectors as shown in Equation (
19), we use
in our work. We summarize our
-based clustering approach in Algorithm 1.
| Algorithm 1 Projected Affinity Values (PAVs) for Nyström spectral clustering. |
INPUT: Dataset x, Gaussian kernel parameter , training set size s, number of classes c
OUTPUT: Class labels of data.
Randomly select s data points from x as the training set and build the affinity matrix W of the training set. Eigendecomposition of W, . Calculate affinity vector k for one testing data point. // Projections Run NCut on W and use in the Nyström approximation to obtain the embeddings of the testing data point. Run k-means clustering on the embeddings of the entire dataset.
|
According to Algorithm 1, compared with the traditional Nyström method, we only replace the affinity vector k with and adopt all other processes. Since both k and u are also used in Nyström, our construction of introduces very few additional operations.
As can be seen from Algorithm 1, the time consumption of our method is very close to that of the standard Nyström. In general, Nyström requires in time complexity, where n stands for the volume of the dataset and m is the size of the training set; d here is the dimension of the input data. In the time complexity of Nyström, the first part stands for the Nyström approximation, the second refers to the eigen-solver of processing with the training set and the last comes from the final embeddings of all n data points. In our method, we take the eigenvectors of K as input, and such eigenvectors are also required in the standard Nsytröm. That means we require no additional time cost for our input. Given , we project k on , and such vector projections take very limited operations.
4. Experiment
In this section, the proposed affinity projection method is verified on several real-world datasets. All experiments were carried out in MATLAB R2016b. Our platform for running these experiments was a workstation equipped with sixteen 2.10-GHz CPUs and eight 16-GB RAM.
4.1. Competing Methods and Evaluation Metrics
Experiments were executed on several benchmark datasets from the UCI machine learning repository [
24], MNIST-8M [
25] and EMNIST Digits (training set) [
26,
27]. Details of the employed datasets are shown in
Table 1.
To evaluate the performance of our PAV, we compare it with four popular clustering methods on several benchmark datasets. The competing methods are listed as follows:
Standard Nyström (Nys), in which we use half of the data for training.
Sparse Spectral Clustering [
18] (SSC), in which we adopt the default settings in the original code.
Local Subspace Analysis [
28] (LSA), in which we set the number of neighbours as 6 and the number of subspaces as
, or the number of classes plus one.
RANSAC for Subspace Clustering [
29] (RAN), in which we use the default settings.
Our Projected Affinity Values on all non-zero eigenvectors (PAV+), in which we project the empirical affinity vector k onto all non-zero eigenvectors.
Our Projected Affinity Values on c eigenvectors (PAV), in which we project k onto only c leading eigenvectors.
The ground-truth labels of data are used as the benchmark for all algorithms for comparison. We use the clustering accuracy [
30] and Normalized Mutual Information (NMI) [
31] to evaluate the clustering results of all algorithms, although many other metrics are available [
32].
Accuracy is defined as:
where
is the true label and
is the derived label of the
i-th data;
is the delta function where
if
and
=0 otherwise; and
is the best mapping function that matches the true labels and the derived labels. A larger value of accuracy indicates a better clustering performance. Accuracy is known to be improper for evaluation if data are unbalanced. Therefore, we also show in
Table 1 the ratio of class sizes the maximum vs. the minimum. As shown in
Table 1, the most unbalanced case occurs on Ionosphere with a ratio of 1.7857. Since there is not a significant unbalanced data distribution occurring in our employed datasets, we use accuracy to evaluate the clustering performance.
NMI is the second performance measure used in this paper. Let
M and
N be the random variables represented by the clustering labels generated by two competing methods. Denote by
the mutual information between
M and
N and by
the entropy of
M. Then, NMI is defined as:
NMI ranges from 0–1 and takes the unitary value when two clustering labels are perfectly matched.
In our experiments, we adopt Gaussian kernel
in calculating the affinity matrix of a dataset. Although there are several
adaptive selection methods [
33,
34], in general, the selection of a proper
is a challenging problem. In our experiments, we set the Gaussian scale parameter
as the square root of the average distance among the data. In the performance evaluation, we compare all methods with the ground-truth labels.
4.2. Real-World Dataset Experiment
In this section, we employ the competing methods on several benchmark datasets in clustering tasks. We run each method 100 times and report the average values in
Table 2 and
Table 3. We also list the average time cost in
Table 4. In
Table 4, we show the time cost in seconds of the standard Nyström approximation, which serves as a benchmark method in our test. Then, we show the time cost ratio, compared with Nyström, in
Table 4, where
indicates a ten-times higher running time compared with Nyström. Several results are missing due to a failure to complete clustering or speed concerns.
- (1)
Nyström-based clustering methods, namely the standard Nyström, our proposed PAV+ and PAV, show comparable or lower performances than the subspace pursuit methods (SSC, LSA and RAN) in terms of accuracy and NMI. A set of carefully selected subspaces that are suitable for clustering was identified in previous work and is shown in
Table 2 and
Table 3. However, as shown in
Table 4, such advantages are always accompanied by additional time costs, which, in most cases, makes such approaches at least one order of magnitude slower than Nyström methods.
- (2)
SSC outperforms the other subspace-based methods. On the Wine dataset, SSC obtains much higher accuracy than any other method, and on Ionosphere, SSC obtains the highest NMI. The highest performance of SSC has been verified on many clustering tasks, particularly if one dataset can be sparsely self-represented. A sparse representation in SSC reveals the subspaces on which the classes lie. However, if a dataset is not sparse, the self-representation matrix C, as the substitute for the similarity matrix in spectral clustering, is more similar to a dense matrix. In this case, SSC may show similar performance to the traditional spectral clustering methods.
- (3)
Projection on all non-zero eigenvectors, or PAV+, shows similar results compared with the standard Nsytröm method. In contrast, once we project k onto the leading c eigenvectors, the corresponding results are slightly better than both standard Nyström and PAV+. The proposed PAV method, or using instead of k in Nyström, improves the clustering performance.
- (4)
The proposed method obtains a narrow margin over others in term of accuracy. Compared with the standard Nyström, we only replace k with , and such changes may be very limited if the leading eigenvectors are well structured. However, considering the also very limited additional time burden introduced by ours, a slight improvement over the standard one is still a promising solution to Nyström.
- (5)
Nyström-based methods run much faster than subspace-pursuit methods perform. Among the three Nyström methods, the proposed PAV incurs limited additional time cost and, in return, obtains higher accuracy and NMI. Compared with SSC, the proposed PAV achieves comparable and occasionally superior performance with a running time that is at least one order of magnitude shorter. SSC needs to solve the sparse representation matrix
C of data, or equivalently solving the
optimization of input data. Such optimization is known to be time consuming. LCA requires additional local sampling that takes time to build a sparse connection matrix. RAN repeatedly samples a small subset of points, and such loops require a long running time. In contrast, the standard Nyström randomly samples the training data points and solves the eigenvectors of the small training set, a process with low computational burden. Our proposed method requires similar time consumption as that of Nyström, as discussed in
Section 3.4. Thus, the time costs of Nyström and ours are much lower than those of SSC, LSA and RAN.
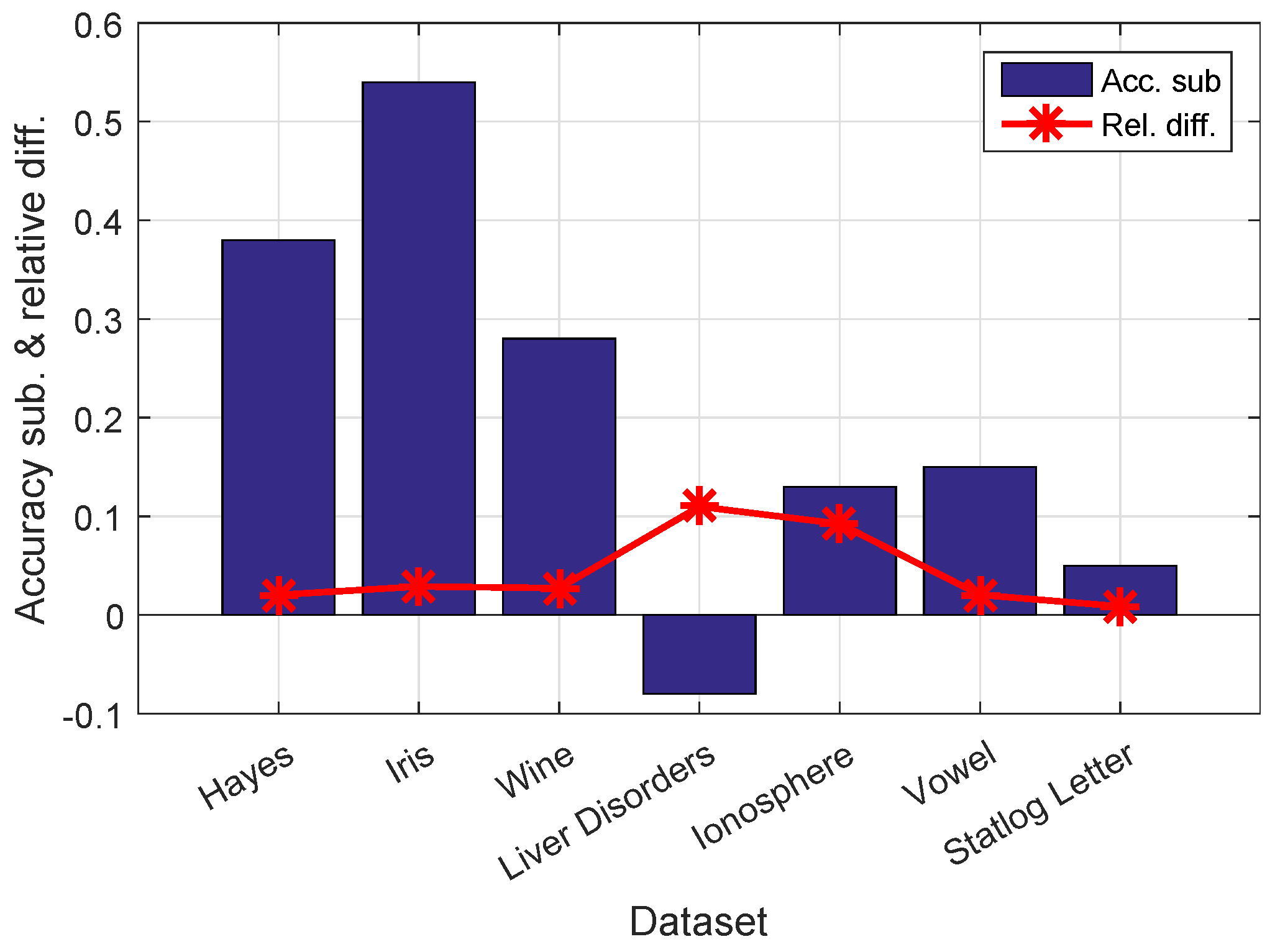
Our main contribution is to replace
k with
. In this test, we calculate the relative difference between
k and
, namely,
, on each dataset. The relative differences for all seven datasets are shown in
Figure 2. In addition, we subtract the accuracy of standard Nyström from that of our proposed method and show the results in
Figure 2.
By projecting k onto leading eigenvectors, the relative affinity difference between k and ranges from 0.87% on Statlog Letter to 10.99% on Liver Disorders. In return, our improves the accuracy values on six of the seven datasets. The proposed method obtains an average improvement of 0.21 over all datasets, and the average difference is 4.4%. Our method improves accuracy even with a slight change of k. For example, on the Iris dataset, our differs by only 2.89% from k, but the accuracy improvement is 0.54.
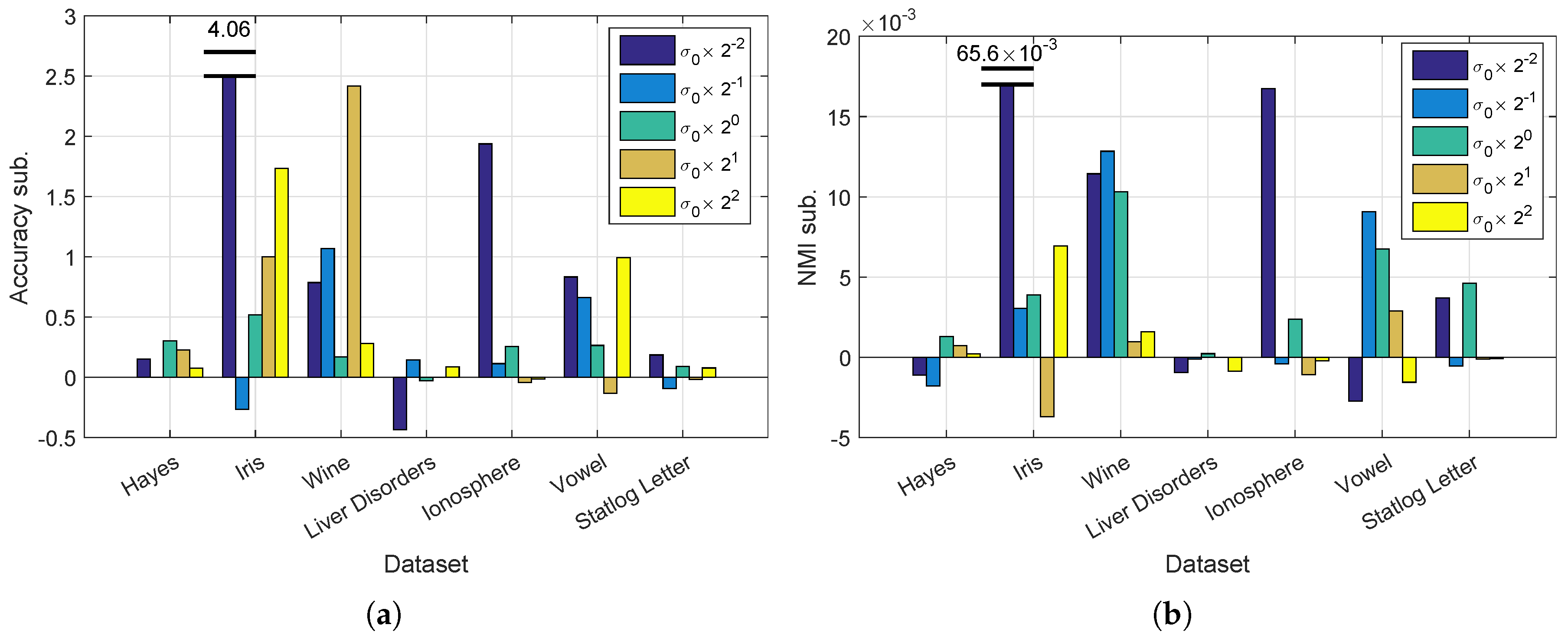
4.3. Various Values of Gaussian Scale Parameter
In the Gaussian kernel,
is a key parameter for clustering. The selection of
is a difficult problem and always demands careful consideration. In this experiment, we test the performance of our method with various values of
. We set
, where
is the square root of the average distance among the data as used in previous experiments. We show in
Figure 3 the clustering performances for different values of
. Similar to our previous experiments, we subtract the performance value, i.e., accuracy or NMI, of Nyström from that of our method and show the results in
Figure 3. On the Iris dataset with
, the proposed method obtains improvements of 4.06 for accuracy and 0.065 for NMI; both values are much higher than their counterparts. For a better visualization, the corresponding bars are truncated.
In
Figure 3, the proposed
achieves the largest improvements in accuracy of 4.06 and NMI of 0.065 on Iris with
. In the worst case, our method decreases accuracy by 0.43 on Liver Disorders and NMI by 0.004 on Iris. Our method shows average improvements of 0.45 in accuracy and 0.003 in NMI.
As changes, the structure of K may also change accordingly, and so of its eigenvectors. We assume that the leading eigenvectors of K and the spanned eigenspace that our projected to are more robust than the original K. Such robustness ensures a stable clustering even with an improper defined by users.
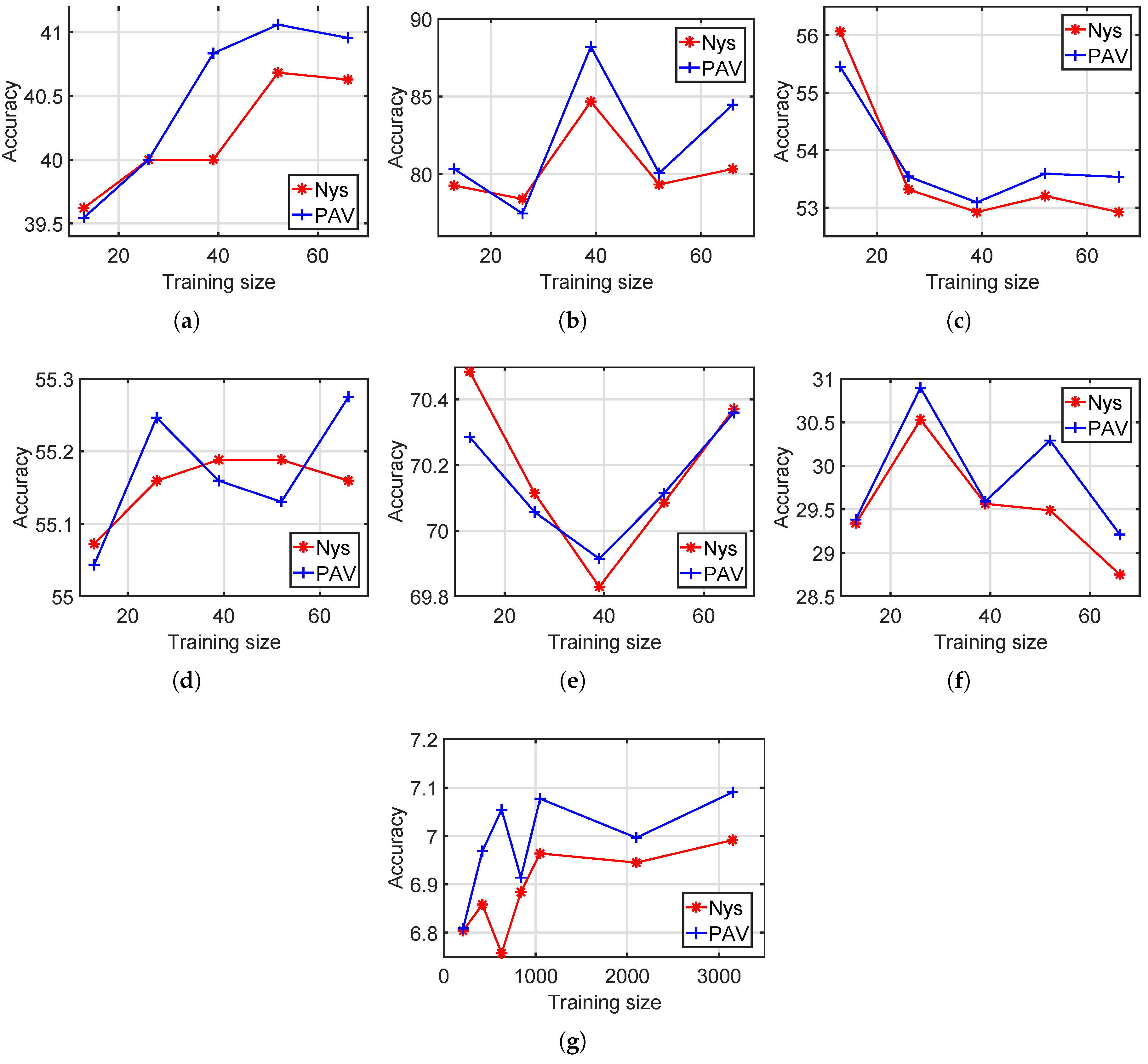
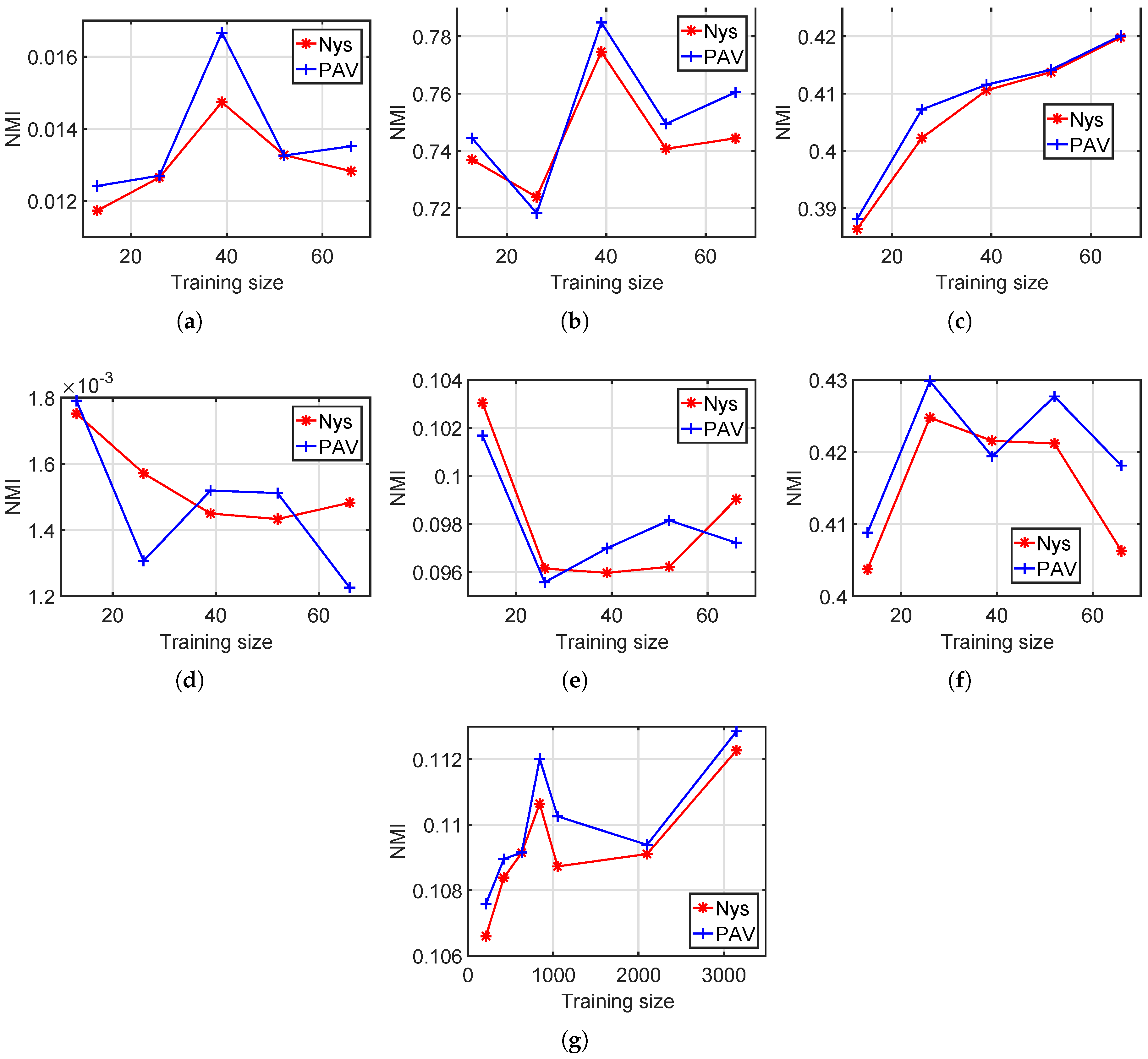
4.4. Various Training Set Sizes
In this experiment, we test both standard Nyström and our method with various training set sizes. We set the training set sizes for the six small datasets, namely, Hayes, Iris, Wine, Liver Disorders, Ionosphere and Vowel, with
. On Statlog Letter, we set the training set size as
. We run each method 10 times and show the average performances in
Figure 4 and
Figure 5.
According to
Figure 4 and
Figure 5, for most training set sizes, the proposed PAV performs slightly better than the standard Nyström. For example, on Statlog Letter, the average accuracy among all seven training sizes is 6.88 for Nyström and 6.99 for our method. The average NMI values of Nyström and our PAV are 0.1093 and 0.11, respectively, on Statlog Letter.
In
Figure 4 and
Figure 5, there are roughly two types on clustering results with respect to the training size: (a) better performance with more training data and (b) fairly unchanged. It is expected in general that more training points will improve the clustering results, as shown in
Figure 4a. If one dataset has a clear structure suitable for clustering, then the potential improvement from increasing training points is limited since a small training set, in this case, is already sufficient enough for a good partition. Thus, clustering performances of increasing training points are fairly unchanged in
Figure 4c–f.
4.5. Large-Scale Embedding
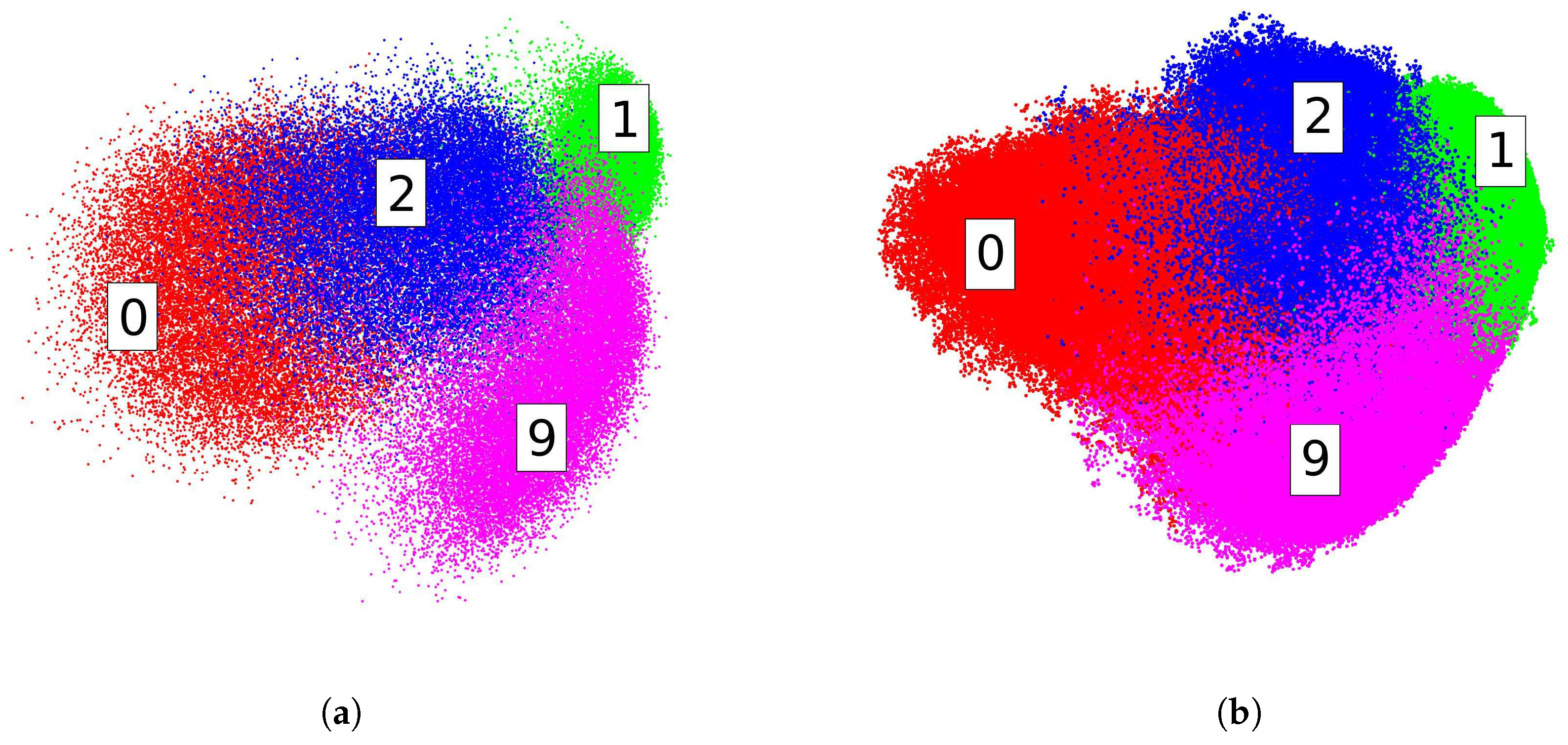
In this experiment, we test the embedding performances of our method on two large-scale datasets. We evaluate our method on EMNIST-Digits and MNIST-8M. MNIST-8M contains 8.1 M data points, which are constructed by the elastic deformation of the original MNIST training set. To facilitate visualization, we only employ Digits 0, 1, 2 and 9, which yields a subset of approximately 3.3 M data points. We limit our test to 0, 1, 2 and 9 on EMNIST-Digits for the same reason.
Figure 6 shows our embedding results on the first two dimensions with
. Digits in the embedding space are well structured. In this test, we use two GeForce GTX TITAN Black GPUs with 6 GB memory for acceleration. The running time of MNIST-8M is 25.68 s and 9.84 s for EMNIST-Digits.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}