2.1. Computability/Recursivity
In computability theory, computable (or Turing-computable) functions are also called recursive functions. Computable functions are the mathematical formalization of the intuitive notion of an algorithm.
Definition 10. A function is computable if and only if there is a Turing machine that, given any k-tuple x of natural numbers, will produce the value .
In other words, a function is computable if there exists an algorithm (a Turing machine) that can implement the the function.
Definition 11. A set of natural numbers is called recursively enumerable if there is a computable function f such that for each number n, is defined if and only if n is in the set.
Thus, a set is recursively enumerable if and only if it is the domain of some computable function.
Operations or transformations that are recursively enumerable simply implies that such operations can be implemented as a computer program running on a universal Turing machine.
2.2. Group-Theoretic Symmetry
Definition 12. Let X be an object in . A symmetry axe l of X is a line about which there exists such that the object X is rotate by an angle θ, which appears to be identical to X.
Definition 13. A symmetry plane P of X is a reflected mirror image of the object X appearing unchanged.
In group theory, the symmetry group of an object is the group of all transformations under which the object is invariant under composition of the group operations. Here, we consider symmetry groups in Euclidean geometry and polyhedral networks.
For example, given an equilateral triangle, the counterclockwise rotation by 120 degrees around the centre leaves the triangle invariant as it maps every vertex and edge of the triangle to another one occupying exactly the same space.
Definition 14. The direct symmetry group of an object X, denoted , is a group of symmetry of X if only rotation is allowed.
Definition 15. The full symmetry group of an object X, denoted , is the symmetry group of X of rotations and reflections.
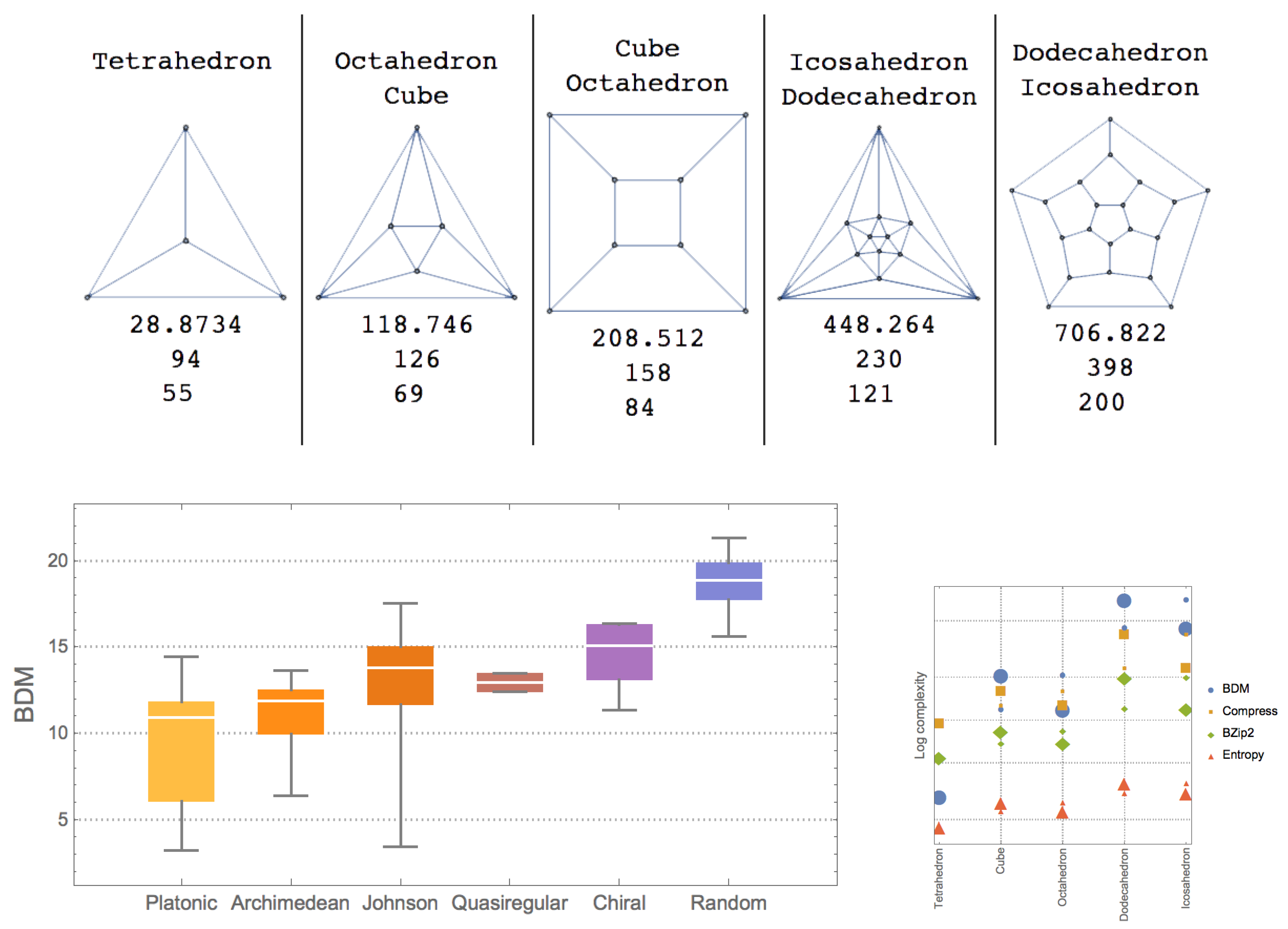
A (full) symmetry group is thus a set of symmetry-preserving operations, such as rotations and reflections. Dual polyhedra have the same symmetry group. For example, a tetrahedron has a total of 24 symmetries, that is, .
While symmetry groups are continuous or discrete, here we are interested in recursively enumerable discrete symmetry groups and actions such that, for every point of the space, the set of images of the point under the isometries in the full symmetry group is a recursively enumerable set.
In what follows, we will use this recursively enumerable variation of the group-theoretic characterization of mathematical symmetry, and symmetry will be taken thus as a space or graph-theoretic invariant under recursively enumerable defined transformations.
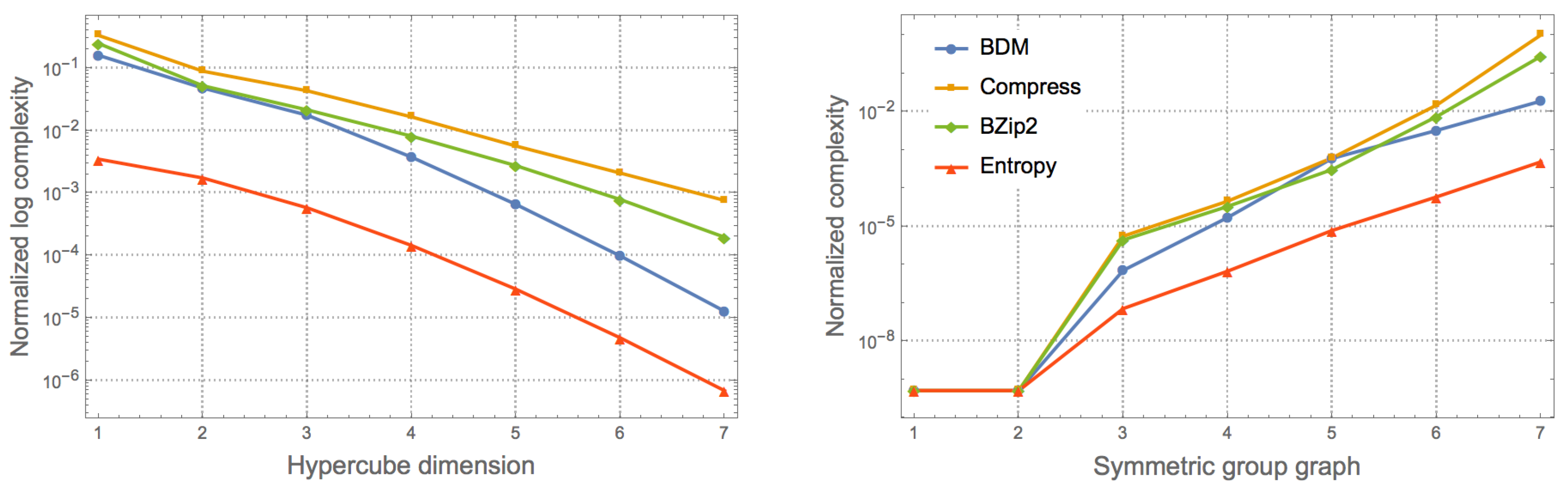
The direct and full symmetry groups of tetrahedra, cubes and octahedra, and dodecahedra and icosahedra are, respectively, and , and , and and suggesting a natural but limited symmetry partial order, the largest the group subindex the more symmetric. However, it is not clear how to compare different types of symmetry.
In the case of the sphere, it is characterized by spherical symmetry, a type of continuous symmetry as it has an infinite number of symmetries (both for rotations and reflections), here we will only require that the scalars and reflections lines involved are recursively enumerable.
Here, we will advance a notion of symmetry based both on group theoretic and algorithmic information to find the correspondences between each other. As a result, we will provide a proposal of a total order of symmetry.
2.3. Information Theory
A random configuration of, let us say a gas in a room, has little symmetry but high entropy, but a specific symmetric configuration will have high entropy because any change will destroy the symmetry towards a more likely disordered configuration. However, the extent to which entropy can be used to characterize symmetry is limited to only apparent symmetry, and it is not robust in the face of object description, due to its dependence on probability distributions [
5]. Entropy measures the uncertainty associated with a random variable, i.e., the expected value of the information in a message (e.g., a string) in bits. Formally,
Definition 16. The Shannon entropy of a string x is defined by: Shannon entropy allows the estimation of the average minimum number of bits needed to encode a string (or object) based on the alphabet size and the occurrence of the alphabet symbolsbased on a probability distribution. Despite its limitations, classical information theory (Shannon entropy) can be consistent with symmetry. One of its main properties is the property of symmetry given by , where is any permutation from 1 to n, and this property also holds for variations of H such as block entropy, where the string bits are taken up by tuples, e.g., bytes. In other words, H remains invariant amidst the reordering of elements. While entropy may look as if it preserves certain properties for symmetrical objects, it also fails to some extent to characterize symmetry. For example, and have because there is a permutation that sends onto and vice versa. However, H misses the fact that looks significantly less symmetrical than , which has a reflection symmetry at the centre bit. When taking 2-bit elements as units for H, hence applying what we will call block entropy denoted by for blocks of size two bits), this is solved and , but then we will miss possible 2-bit symmetries, and so on. Taking for , where . We will see that, for algorithmic complexity, there are nearly similar results, but with far more interesting subtleties.
2.5. Algorithmic Complexity
The algorithmic (Kolmogorov–Chaitin) complexity of a string
x is the length of the shortest effective description of
x. There are several versions of this notion. Here, we use mainly the plain complexity, denoted by
, and the conditional plain complexity of a string
x given a string
y, denoted by
, which is the length of the shortest effective description of
x given
y. The formal definitions are as follows. We work over the binary alphabet
. A string is an element of
. If
x is a string,
denotes its length. Let
M be a universal Turing machine that takes two input strings and outputs one string. For any strings
x and
y,
Definition 19. The algorithmic complexity of x conditioned by y with respect to M is defined as We will often drop the subscript M in because of the invariance theorem, and we will also write instead of (where is the empty string). If n is a natural number, denotes the algorithmic complexity of the binary representation of n. Prefix-free complexity K is defined in a similar way, the difference being that the universal machine is required to be prefix-free. That is, only self-delimited programs are valid programs; no program is a prefix of any other, a property necessary to keep a (semi-) probability measure.
2.6. Algorithmic Probability
Algorithmic Probability is a seminal concept in the theory of algorithmic information. The algorithmic probability of a string s is a measure that describes the probability that a valid random program p produces the string s when run on a universal Turing machine U. In equation form, this can be rendered as
That is, the sum over all the programs p for which U outputs s and halts.
The Algorithmic Probability [
6,
7,
8] measure
is related to algorithmic complexity
in that
is at least the maximum term in the summation of programs, given that the shortest program carries the greatest weight in the sum.
Definition 21. The Coding Theorem further establishes the connection between and as follows:
where
c is a fixed constant independent of
s. The Coding Theorem implies that [
9,
10] one can estimate the algorithmic complexity of a string from its frequency. By rewriting Equation (
1) as:
where
is a constant, one can see that it is possible to approximate
K by approximations to
m (such finite approximations have also been explored in [
11] on integer sequences), with the added advantage that
is more sensitive to small objects [
12] than the traditional approach to
K using lossless compression algorithms, which typically perform poorly for small objects (e.g., small graphs).
As shown in [
13], estimations of algorithmic complexity are able to distinguish complex from random networks (of the same size, or asymptotically growing), which are both in turn distinguished from regular graphs (also of the same size).
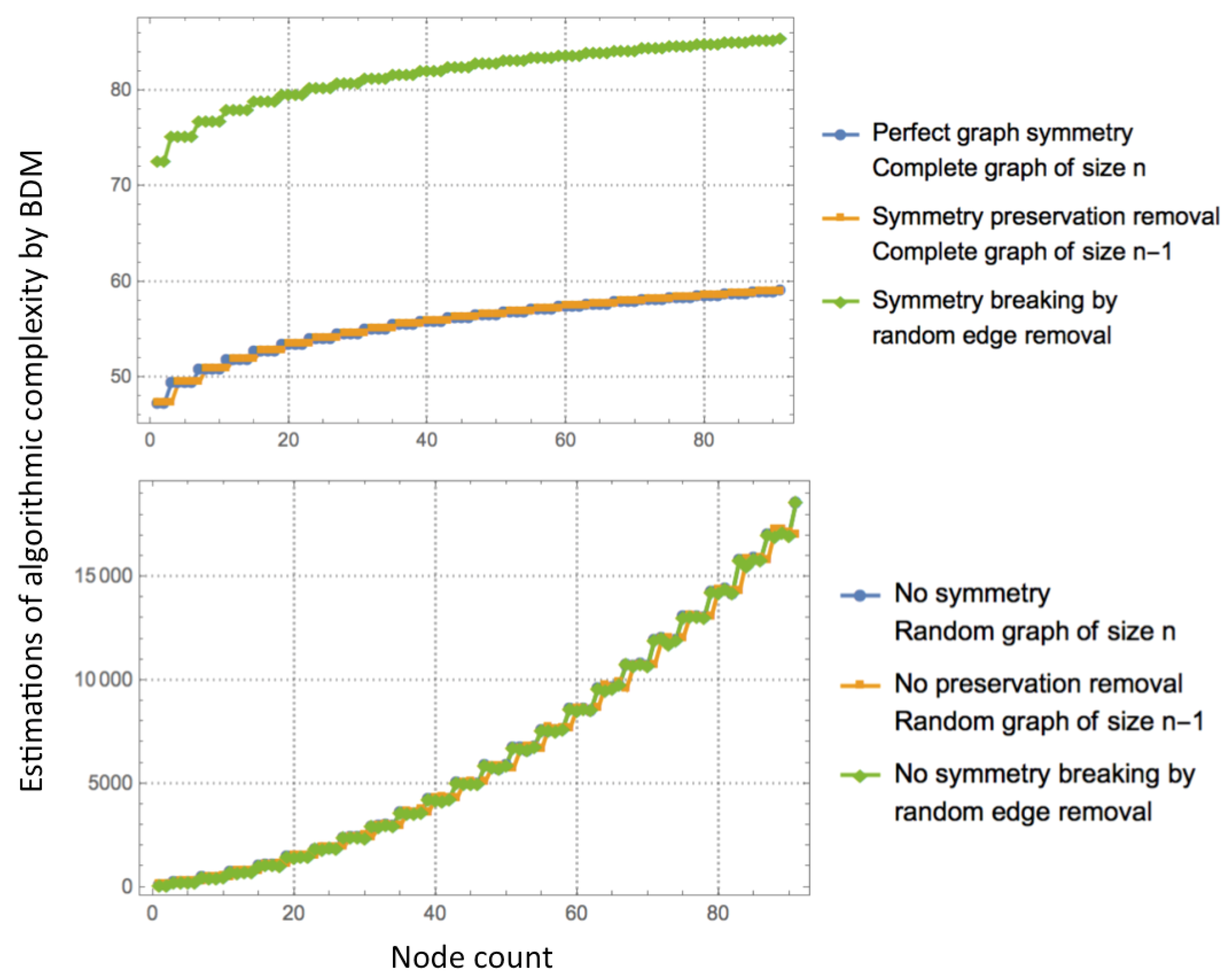
K calculated by the BDM assigns low algorithmic complexity to regular graphs, medium complexity to complex networks following Watts–Strogatz or Barabási–Albert algorithms, and higher algorithmic complexity to random networks. That random graphs are the most algorithmically complex is clear from a theoretical point of view: nearly all long binary strings are algorithmically random, and so nearly all random unlabelled graphs are algorithmically random [
13].
The Coding Theorem and Block Decomposition Methods
The Coding Theorem Method (CTM) [
12,
14] is rooted in the relation provided by Algorithmic Probability between frequency of production of a string from a random program and its Kolmogorov complexity (Equation (
1), also called the algorithmic Coding theorem, as distinct from another coding theorem in classical information theory). Essentially, it uses the fact that the more frequent a string (or object), the lower its algorithmic complexity; and strings of lower frequency have higher algorithmic complexity.
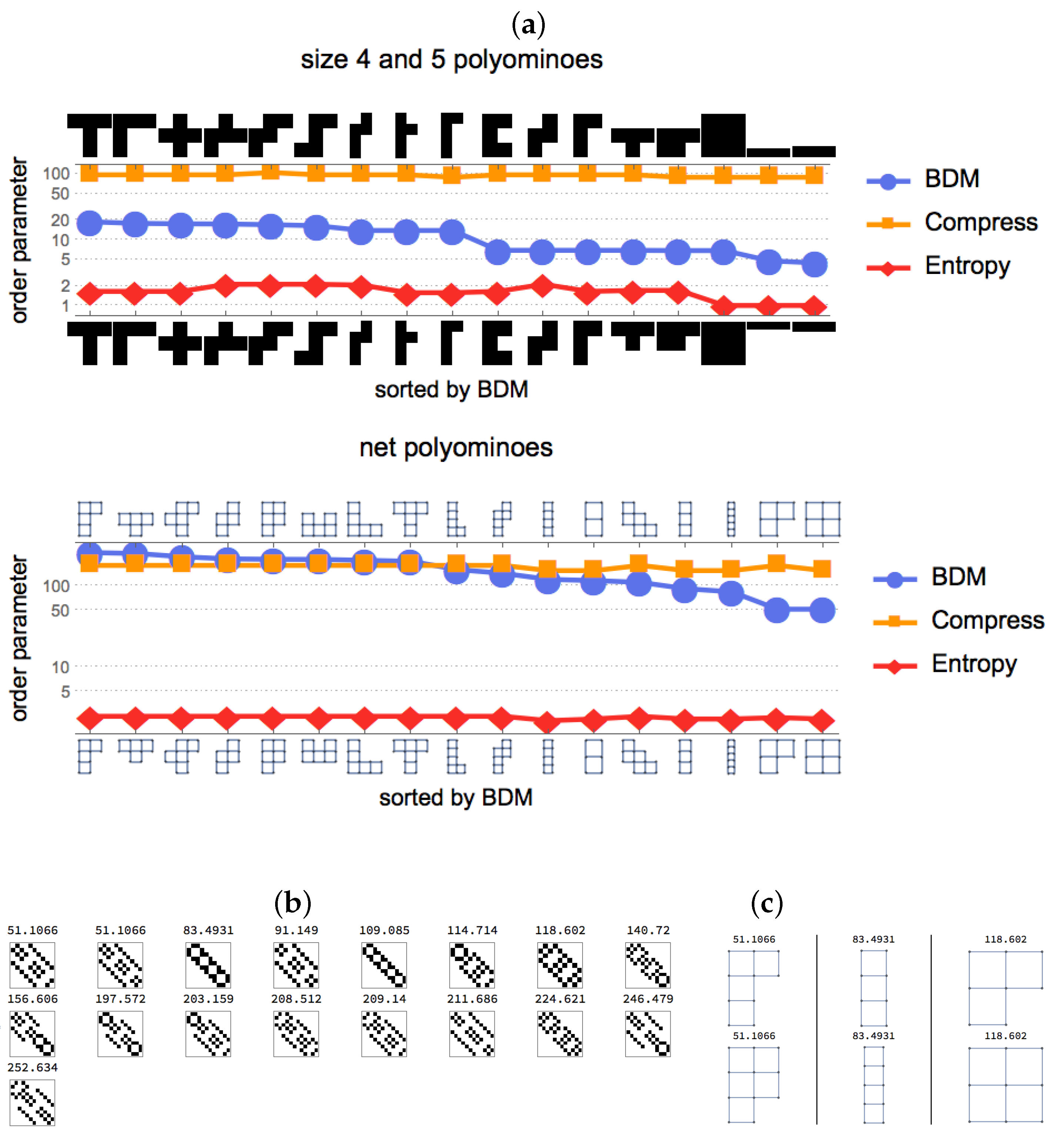
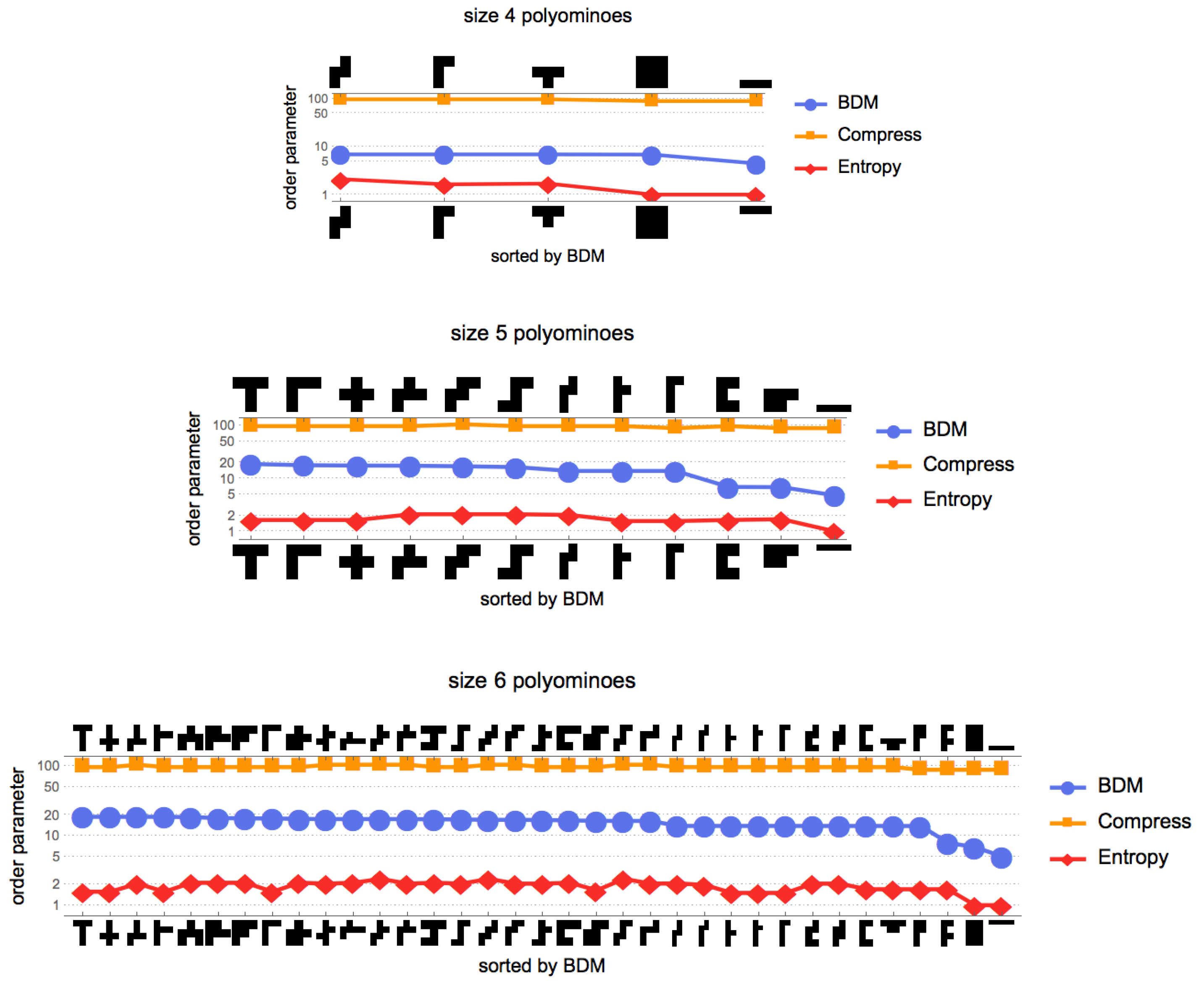
Here, we report results that would not have been possible if they were not specific enough to correctly identify small patterns that represent signatures of the algorithmic content of an object by using CTM and BDM. We show that the AP-based measures either constitute an equivalent or a superior alternative to other more limited measures, such as lossless compression algorithms, widely used as estimators of algorithmic complexity, and to Shannon entropy and related measures that are based on traditional statistics and require that broad assumptions be encoded in their underlying probability distributions.
The Block Decomposition method (BDM) consists of determining the algorithmic complexity of a matrix by quantifying the likelihood that a random Turing machine operating on a two-dimensional tape (also called a termite or Langton’s ant [
15]) can generate it and halt. The Block Decomposition Method (BDM) decomposes the adjacency matrix of a graph into smaller matrices for which we can numerically calculate its algorithmic probability by running a large set of small two-dimensional deterministic Turing machines, and therefore its algorithmic complexity upon application of the Algorithmic Coding Theorem. Then, the overall complexity of the original adjacency matrix is the sum of the complexity of its parts, albeit a logarithmic penalization for repetitions, given that
n repetitions of the same object only add
complexity to its overall complexity, as one can simply describe a repetition in terms of the multiplicity of the first occurrence. The following graph complexity definition will also introduce BDM.
2.7. The Algorithmic Complexity of a Graph
We define the algorithmic complexity estimation of a graph as follows:
Definition 22. The Kolmogorov complexity of a graph G is defined as follows:
where
is the approximation of the algorithmic (Kolmogorov–Chaitin) complexity of the subarrays
using the Algorithmic Coding Theorem (Equation (
2)) method that we denote by CTM,
represents the set with elements
obtained when decomposing the adjacency matrix
of
G into non-overlapping squares of size
d by
d denoted by
. In each
pair,
is one such square and
is its multiplicity (number of occurrences). From now on,
may be denoted only by
, but it should be taken as an approximation to
unless otherwise stated (e.g., when referring to the theoretical true
value).
Considering relabellings, the correct evaluation of the algorithmic complexity of a graph is given by:
where
is the adjacency matrix of
and
is the group of all possible labellings of
G.
One contribution of these algorithmic-based measures is that the two-dimensional versions of both CTM and BDM are native bidimensional measures of complexity and thus do not destroy the two-dimensional structure of an adjacency matrix.
By making a generalization of the Algorithmic Coding Theorem using two-dimensional Turing machines. This makes it possible to define the probability of production of an adjacency matrix as the result of a randomly chosen deterministic two-dimensional-tape Turing machine without any array transformations to a string, thus making it dependent on yet another mapping between graphs and strings, unlike our approach that natively deals directly with the complexity of the graph adjacency matrix.
Most algorithms implementing a computable measure of graph complexity are based either on a graph-theoretic/topological feature that is computable or upon Shannon entropy. An example of an improvement on Shannon entropy is the introduction of graph lossless compression such as Graphitour [
16]. A drawback of graph compression is that lossless compression based on popular algorithms such as LZW (Gzip, PNG, Compress), which are traditionally considered to be approximations to algorithmic (Kolmogorov) complexity, are more closely related to Shannon entropy than to algorithmic complexity (which we will denote by
K). This is because these popular algorithms implement a method that traverses an object looking for trivial repetitions from which a basic grammar is produced based on frequency.
A major improvement in the means of approximating the algorithmic complexity of strings, graphs and networks, based on the concept of algorithmic probability (AP), offers different and more stable and robust approximations to algorithmic complexity by way of the so-called Algorithmic Coding Theorem (c.f. below). The method, called the Coding Theorem Method, suffers the same drawback as other approximations of
K, including lossless compression, related to the additive constant involved in the Invariance Theorem as introduced by Kolmogorov, Chaitin and Solomonoff [
7,
8,
17,
18], which guarantees convergence towards
K though its rate of convergence is unknown. The chief advantage of the algorithm is, however, that algorithmic probability (AP) [
6,
7,
8] not only looks for repetitions but for algorithmic causal segments, such as in the deterministic nature of the digits of
, without the need of distribution assumptions. As with
, a graph that is produced recursively enumerable will be eventually characterized by algorithmic probability as having low algorithmic complexity, unlike traditional compression algorithms that implement a version of classical block Shannon entropy. In previous work, this kind of recursively enumerable graph [
5] has been featured, illustrating how inappropriate Shannon entropy can be when there is a need for a universal, unbiased measure where no feature has to be pre-selected.
The method studied and applied here was first defined in [
2,
19] and is in many respects independent of the observer to the greatest possible extent. For example, unlike popular implementations of lossless compression used to approximate algorithmic complexity (such as LZW), the method based on Algorithmic Probability averages over a large number of computer programs found to reproduce the output, thus making the problem of the choice of enumeration less relevant compared to the more arbitrary choice of lossless compression algorithm. The advantage of the algorithmic complexity measure is that when it diverges from algorithmic complexity (because it requires unbounded increasing computational power) it then collapses into Shannon entropy [
2].
We have previously reported connections between algebraic and topological properties using algorithmic complexity [
13], where we introduced a definition and numerical method for labelled graph complexity; and in applications to the clustering capabilities of network superfamilies in [
20], as well as in applications to biology [
21], where we also introduced a generalization of unlabelled graph complexity. We have also provided theoretical estimations of the error of approximations to the algorithmic complexity of graphs and complex networks in [
21], offering both exact and numerical approximations.
The algorithm here considered can deal with a variety of graph types including directed graphs and weighted graphs. The resulting structure could be used for representation and classification as we will see.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




