1. Introduction
A channel is defined as a conditional distribution, modelling the probability of outputs that an adversary can observe given secret inputs. Important examples of channels are side-channels in computer security where an attacker, for example by observing the running time of an encryption program, can reconstruct the encryption keys.
At a high level, the problem of optimal channel design is the following: given a prior on the secret and some operational constraints, design a channel that minimises the leakage of information about the secret. In simple terms, an optimal channel can be seen as an optimal countermeasure to information leakage.
To explore this design problem, one needs to specify what constraints should be considered and how the leakage of information is quantified. In the cryptographic example above, one may want, for example, to design a channel of minimal leakage (in terms of the number of key bits that can be reconstructed by an adversary) under the constraint that the average encryption per block should take less time than some given duration. This work will consider two general classes of constraints which we refer to them as “hard” and “soft”. Hard constraints are the ones establishing which outputs are allowed given each inputs. These constraints must be satisfied for each realisation of input–output pairs. Soft constraints, on the other hand, must be satisfied in the expected value sense, as they relate to the expected utility of the channel.
Leakage of information is defined as the difference between the adversary’s prior and posterior uncertainty, i.e., the uncertainty before and after observing the outputs of the channel. The leakage quantifies how much the attacker can learn about the secret input from observing the outputs. Therefore, any entropy function, seen as a measure of uncertainty, can induce a candidate function for quantifying leakage. For Shannon entropy, the leakage is just the mutual information. To capture the widest class of entropies, and hence leakages, this work uses core-concavity [
1,
2], a generalisation of concavity which allows for capture of entropies which are not concave (like Rényi entropies when
).
Once the optimal channel design problem is formally set, it is possible to address some basic questions. The first question regards how difficult it is to solve this problem. Based on Reference [
2], it can be shown that, for any choice of the entropy measure, this problem is solved via convex programming with zero duality gap, for which the Karush–Kuhn–Tucker (KKT) conditions can be used to solve for the optimal channel.
1.1. Literature Review
The problem of information leakage outside of the communication setting has been studied in the quantitative information flow (QIF) literature [
3,
4,
5,
6], works on private information retrieval (PIR) [
7], and private search queries [
8,
9], as well as research on privacy-utility trade-offs [
10,
11,
12]. Particularly important from the field of QIF are advances on fundamental security guarantees of leakage measures (what security can be achieved) and robust techniques and results (how much a technique or result is valid across different notions of leakage). However, most of the theoretical effort has been focused on analysing a given system as opposed to a design problem.
Information leakage in the context of game theory has been studied in Reference [
13]. Their work focuses on modelling the interplay between attacker and defender in regard to information leakage of given channels, and to reason about their optimal strategies. In contrast our focus is on the design of optimal channels within operational constraints.
The authors in Reference [
14] also use a zero-sum game between a forecaster against Nature to show that the celebrated maximum entropy principle in statistics, i.e., that one should choose a distribution that has the highest entropy from a family without any further knowledge, is the dual of solving a robust Bayes decision problem. This was the inspiration for our duality connection in
Section 5.2.
This work builds and extends on our two conference papers [
1,
2]. However, there are several differences compared to those papers. For example, we have now simplified the definition of core-concavity without loss of generality. In addition, the games in Reference [
1] are different; e.g., they do not include soft constraints. Moreover, the connection of convex optimisation to a two-person game for “any” core-concave entropic leakage was not explored in either works. Finally, the relation of the dual problem, that of the adversary, to a robust information extraction problem is unique to this manuscript.
1.2. Contributions
The main contribution of this paper is to present the problem of designing optimal channels for minimum information leakage in a game-theoretical framework for a generalised class of quantifying leakage. In this way, the optimal channel design can be studied both from the defender (the channel designer) and the adversary (the inference maker, or the information extractor) point of view. The main technical contribution is Theorem 1, which shows that the convex programming solutions as in Reference [
2] correspond to the defender’s optimal strategies in these games. Moreover, this game-theoretical framework reveals that there is a tight duality relationship between the problem of designing a minimal leakage channel and choosing a “robust inference extraction” strategy. In particular, knowing only the specification of a channel given by some constraints and a prior distribution, the optimal strategy to extract the maximum amount of information about the input from the output of the channel, where the exact realisation of the channel is unknown, needs to be found. Hence, the strategy should be robust to any realisation of the channel within its constraints. When the game is finite, efficient solutions for both the defender and adversary’s strategies can be found using linear programming.
This work also establishes a result to deal with uncertainty about the prior. By Theorem 2, it follows that, when the prior is not unique, but is known to depend on a hidden “context”, the Nash equilibrium is not given by customising with respect to the context, but rather by treating the multi-prior problem as a single-prior one, where the prior is the average prior over all contexts.
1.3. Roadmap
After introducing notations and the information-theoretical background, including the important definitions of core-concavity and gain functions, the optimal channel design problem is presented in
Section 3. It is then shown, in
Section 4, that the problem is solved by convex programming for any entropy belonging to this generalised class.
The main contribution of the paper, i.e., the game-theoretical framework, is presented in
Section 5. The games under study here are two persons sequential zero-sum games with asymmetric information. A notion of utility is introduced based on gain functions and soft constraints and the saddle-point equilibria are defined. The main result of this section, Theorem 1, shows the correspondence between equilibria and convex optimisation from
Section 4. The section concludes with a discussion of the problem from the adversary point of view and its relation to robust inference.
In
Section 6, our framework is extended to the case of uncertainty about the prior. It is first analysed as a convex optimisation problem, culminating in Theorem 2, which is followed by a discussion of the game-theoretical implication of that result.
2. Notational Conventions and Preliminaries
We will denote sets, random variables, and realisations with calligraphic, capital, and small letters, respectively, e.g., , X, and x. We will denote the cardinality of a set by . For a vector p, we use to denote the i-th largest element of p, where ties are broken arbitrarily. In addition, we will use the notation for the -norm of vector p, that is, . The limit case of ∞-norm is .
Let X represent the secret as a discrete random variable that can take one of the n possibilities from with the (categorical) distribution of , where is the probability simplex in . For the rest of the paper, as is the convention, we may omit the subscript X whenever it is not ambiguous and simply use p to refer to . Without loss of generality, assume that every secret has a strictly positive probability of realisation and that ’s are sorted in non-increasing order; that is, .
A system that generates
observable Y from the discrete set
that can probabilistically depend on a secret can be modelled as a probabilistic discrete channel (henceforth referred to simply as a “channel”) denoted by the triplet
. Specifically,
and
are the
input and
outputalphabets, respectively, and
denotes the conditional probability distribution, also known as the transition matrix. That is,
is the probability with which the channel produces the output (the observable)
y given that its input (the secret) is
x. In particular, they satisfy the following:
In other words, the transition matrix is “row-stochastic”. In the rest of the paper, we will use the terms secret and input, as well as observables and outputs interchangeably.
Central to this work is the notion of leakage of information. In order to define leakage formally we will start by defining entropy and posterior (conditional) entropy in a general context.
2.1. Entropy
The classical choice for entropy and posterior entropy are (
Gibbs)–
Shannon’s:
where
is the set of outputs that have a strictly positive probability of realisation, that is
. In addition,
is the (total) probability that
y is observed by the adversary, i.e.,
, and
is the
posterior probability of the secret
x given that
y is observed as given by the
Bayes’ rule:
.
However, as we mentioned in the introduction, there are many candidates for entropy. Some are more fitting for specific operational scenarios, such as Min-entropy and guesswork. A generalisation of Shannon and Min-entropy is the Rényi family, which itself is a special case of the Kolmogorov–Nagumo family. Rather than taking a specific entropy, we construct a general entropy from an axiomatic description.
Consider a random variable
X whose distribution depends on the realisation of a “context”
C, which is a binary random variable. In particular,
and
, with
; moreover,
and
. Compare the following two scenarios: (1) we observe the realisation of the context and (2) we cannot see the realisation of the context. Intuitively, our uncertainty about
X in the first scenario should be lower than that in the second. In particular, if we measure the uncertainty of a random variable with distribution
p by function
, we should have
; that is,
F should be a
concave function. However, we note that this intuitive inequality still holds even if an increasing
function
is applied to both sides; that is,
The function
can be thought of as capturing our risk attitude. This motivates the following definitions.
Definition 1. Let H be a function from probability distributions to . Then we call H to be core-concave if we can write , where is strictly increasing and F is concave.
Throughout the paper, we will consider concave functions to also be continuous; specifically, their value on the boundaries are their limit values. Note that any concave function is also core-concave, by simply taking
. However, the converse is not true. A notable example is the Rényi entropies:
For
, this function is neither concave nor convex (it is only pseudo-concave). However, it is core-concave. This can be shown as follows:
For
, core-concavity can be shown by
and
. As another example, consider Sharma–Mittal entropies [
15], defined as
This family generalises Rényi
, Shannon
), and Havrda–Tsallis entropies [
16,
17]:
.
is also core-concave. This can be seen by
In this paper, we take any function that is core-concave as a candidate for entropy.
2.2. Posterior Entropy
Motivated by the equivalence of our core-concave entropies with generalised induced entropies, we define the posterior entropy to take the following form:
Note that the above definition is deliberately
different from
. In particular,
is outside of the expectation. Now, the (information) leakage can be defined as
The above structure of the posterior entropy is strongly motivated by the following result:
Proposition 1. For any core-concave H, leakage is non-negative.
Proof. Replacing from definitions, we have
For a core-concave
H,
F is concave; hence, following Jensen’s inequality,
. Therefore, since
is a monotonically increasing function, we have
, i.e., leakage is non-negative. ☐
In fact, our leakages satisfy a stronger property:
Proposition 2. The conditional entropy defined in Equation (4) satisfies the data-processing inequality (DPI).
Proof. Reference [
1] (Lemma 1). ☐
2.3. Gain Functions and g-Leakage
An alternative foundational approach to information leakage is in term of gain functions. As we will use gain functions in our results, we give here a primer on this approach.
A classical interpretation for Shannon entropy is in terms of guessing a secret by asking set membership questions (“is the secret in set X?”). Often in the security community, another guessing model is more appropriate, which is individual guesses: “is the secret x”?
Information-theoretically, the individual guesses scenario is modelled by Min-entropy. This guessing scenario is, however, an
all-or-nothing scenario: the attacker either guesses the secret or does not, and right guesses always yield the same reward. In many real world scenarios, however, even guessing part of the secret may be valuable, or guessing different secrets may yield different rewards. These scenarios have motivated the introduction of gain functions and
g-vulnerability [
18].
A gain function is a real valued function g whose arguments are an attacker guess and the secret: quantifies the gain of the attacker for guessing a when the secret is x.
The
g-vulnerability is defined as the attacker expected gain for an optimal guess:
where
is a countable set (the attacker guesses). From
g-vulnerability, one can define posterior
g-vulnerability by considering the average vulnerability over all possible outputs, i.e.,
Further derived notions are
g-entropy and
g-leakage.
g-entropy is defined as the negative log of the vulnerability:
. Similarly, posterior
g-entropy is defined as the negative log of the posterior vulnerability:
.
g-leakage is the difference between the
g-entropy and the
g-posterior entropy. An important property of gain functions, which we use in the game-theoretical analysis, is that any convex function can be defined using gain functions ([
19] (Theorem 5)).
3. Optimal Channel Design
The general setting in our paper is the following: Given a prior distribution on input (secret) variable X as p, we (the defender) would like to design a channel within some operational constraints, such that the channel leaks minimally about the secret X through its output Y.
Let
define the permissible outputs (observable) for each input (secret). Specifically, if
, then, for input
x, the designer cannot produce output
y. This can represent the “hard” operational constraints on the channel. Hence, the channel, along with Equation (1), should satisfy:
We will refer to Equation (
6) as “hard” constraints, as they strictly forbid some input–output pairs “path-wise”, that is, for each realisation of the input. As a consequence, an adversary can eliminate the forbidden inputs for an observable when making an inference. For ease of notation, for any given
, we will denote the space of channels that satisfy Equations (1) and (
6) by
. That is,
The design requirement for a legitimate channel that satisfies the hard constraints can now be expressly represented as
.
The naming of hard constraints is to contrast with the “soft” constraints, which are expressed in terms of an expected value. In particular, there are many interesting cases where it may be “feasible” to assign the same observable for all secrets, but such a move may result in a huge deterioration in the system’s quality of the service (QoS). In such cases, the goal is to strike an optimal “balance” between information leakage and QoS. This is for instance the setting in geo-location privacy-utility trade-off [
10,
11,
20] and secrecy-delay trade-off in bucketing as a defence against timing attacks [
21,
22].
In its most basic form, the QoS can be captured as an expected value of a “payoff” (desirability) function. In particular, let
, where
represents how good the realised output is for a particular input. Then the expected value of the pay-off is simply:
, which can be a metric for the QoS of the channel. The channel design problem then becomes a “two-objective” optimisation: (a) minimising leakage and (b) maximising the QoS. The solution concept for multi-objective optimisations is of “Pareto-efficiency” (Pareto-optimality), which are the solutions with a guarantee that no alternative can simultaneously improve all of the objectives (at least one of them strictly). One of the standard methods of converting a multi-objective optimisation (MOO) to (a series of) single-objective optimisations (SOOs) is to present all but one of the objectives as inequality constraints. Specifically, we can introduce a lower threshold
on the QoS by imposing:
. Then by varying the value of
and solving the resulting SOOs, the Pareto-frontier (the set of Pareto-optimal solutions) will be found (see e.g., [
23]). Hence, with this in mind, for the rest of the paper, we will be dealing with SOOs. We will refer to the constraint of
as the “soft” constraint, since it is expressed in terms of the expected value, distinguishing it from the “hard” constraints represented by
(or equivalently,
), for each realisation of the secret.
As we argued before, the aim is to design channels that have the lowest leakage of information about the input while satisfying a set of operational constraints, and the leakage is defined as the difference between the posterior and prior entropies. The first point to note is that the choice of the channel cannot change the prior entropy, as the prior entropy of the input is entirely governed by its prior distribution, which we assume is a “given” parameter that the defender cannot control. Therefore, the problem of minimising the leakage becomes equivalent to maximising the posterior entropy (equivocation).
Putting things together, the optimal channel design problem in its most general form becomes
where the main notations are described in
Table 1.
Before we get to our analysis, we present two minimalistic examples to instantiate the constraints. Note that each of these contexts of course have their idiosyncrasies that are abstracted away for the purpose of this paper. The first toy example is motivated by geo-location privacy.
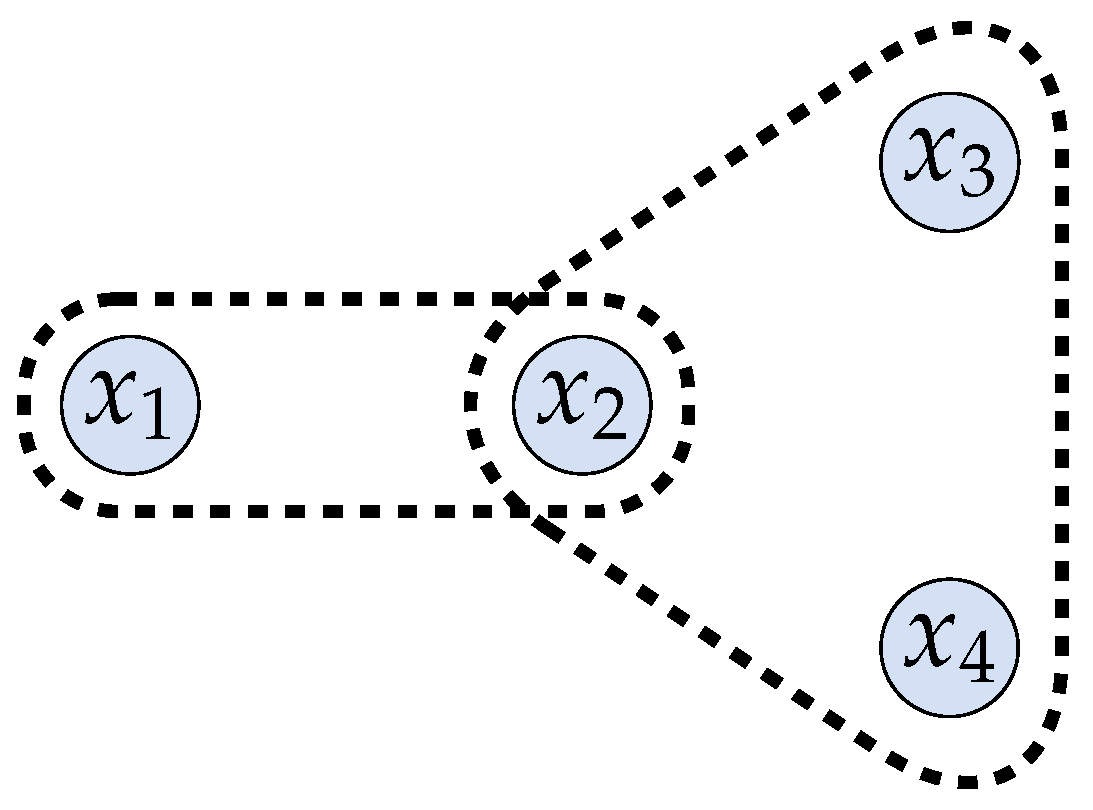
Figure 1 depicts four locations
to
, where the configuration is a representation of their relative positions. The defender is in one of these four locations and generates an observable, which can be its reported coordinates, based on which it receives a location-based service (LBS). Suppose, in particular, that
and
are near enough that the same observable can be reported for both of them, but
is too far from
and
such that reporting the same coordinates with them is either infeasible (e.g., it will not get any network connectivity from an access point) or it will be unacceptable (the quality of the received utility will be too poor). Moreover,
,
, and
are close enough to produce the same observable. If we label the observables simply by the subset of the secrets that can produce them, then the set of admissible secret-observable pairs, i.e.,
, is
. This
determines the hard constraints on the problem, e.g., we must have
because
.
As another example, consider a minimalistic bucketing example depicted in
Figure 2. The axis denotes time duration, and
to
represent the distinct execution times of four distinct (encryption or decryption) processes, i.e., Process 1 takes
time to finish, and so on. If the result of each process is released immediately upon finishing, then they can be uniquely identified just by the timing “side channel”. The result of a finished process can be deferred and released at a later time, to become identical to other processes that take longer to finish. This superset duration time constitutes a
bucket. In the figure, the arrows represent whether a secret can be deferred till the finishing time of a longer processes. Specifically, suppose that the delay limitation for Process 1 does not allow it to be released as late as
or
. Therefore, the hard constraints can be identically represented as in the previous toy example.
5. Game-Theoretical Interpretation
We now present a game-theoretical framework for the general optimal channel design problem. The problem solution is shown to be a Nash equilibrium in a sequential zero-sum game. The main result proved in this section is a correspondence between any defender Nash equilibrium in these games and convex programming problems from Proposition 3. Moreover, when the game is finite, the solution can be found with linear programming and, hence, in a more efficient way than the general case. An important property of the game interpretation is that it provides not only the optimal channel design but also the attacker optimal attack strategy.
Consider the following two-player zero-sum game between a defender and an adversary: “Nature” chooses a realisation of a random variable X from the finite set according to the publicly known probability distribution p. The defender, observes the realisation of x, and chooses an action from the finite set . Hence, the space of the pure strategies of the defender are all functions from to , i.e., . Each pure strategy of the defender corresponds to a deterministic channel. Similarly, a behavioural strategy of the defender corresponds to a probabilistic channel, , whose space is . The adversary, after observing y, makes a guess a from the countable (but potentially infinitely-sized) set . Hence, the space of the adversary’s pure strategies (deterministic plans of action) is . A behavioural strategy of the adversary, designated by , assigns a potentially probabilistic guess to each output. Hence, the space of adversary’s behavioural strategies is . A pure and behavioural strategy profile of the game are respectively the pairs and .
The
payoff of the game can in general be represented by the (bounded) function
. That is, the outcome of each instance of the game is that the adversary wins, and the defender loses,
units; if the (realisations) of the channel input, the channel output and the adversary’s guess have been
x,
y, and
a, respectively. Let
V represent the expected payoff of the game. The expectation is taken with respect to the random realisation of the input according to the prior
p as well as any randomisation present in the strategies of the two players. Specifically,
The defender wants to minimise
V while the adversary wants to maximise it. Unlike the defender, the adversary does not observe the realisation of
X; for this reason, this is a game of asymmetric information.
5.1. Nash Equilibria and Saddle-Point Strategies
A Nash equilibrium (NE) is a standard solution concept in game theory, which states that each strategy should be the best response assuming the strategy of the other player(s) is fixed. For two-player zero-sum games (2PZSGs), the set of NEs has a stronger interpretation—that of a saddle point. We first briefly describe this solution concept.
The defender may adopt the following worst-case scenario argument: assuming that any strategy that is adopted by the defender is going to be revealed to the adversary to best respond to it, the “robust” optimisation of the defender (the minimiser) becomes the following:
We denote the value of the above optimisation with
to indicate that this is the highest expected payoff to the adversary. On the other hand, the best-case scenario of the defender is derived from the following argument: suppose the strategy of the adversary is given and the defender can design their strategy accordingly. Then this optimistic scenario for the defender (which is the worst-case for the adversary) leads to the following problem:
Clearly, we have
. If we have
, we say the game has a
value . Further, a saddle-point strategy pair
is a strategy pair that satisfies the following:
That is, a saddle-point strategy attains the value of the game:
. Then the argument for the saddle-point strategies as the solution concept of the 2PZSG is strong: the saddle-point strategy gives each player a guarantee of the utility no-matter what the other player’s strategy is. In what follows, we derive the condition for the saddle-point strategy of the defender and adversary, respectively.
For the defender, a saddle-point strategy solves
. As before, let
be the set of outputs with a strictly positive probability of realisation. Since only these “on-path” outputs contribute to the expected payoff, we can rewrite Equation (
9) as
Hence,
In particular, for each
y, the adversary can put all the probability weight on an action that maximises the expected value of
with
, where
follows Bayes’ rule. Note that, although we started from an agnostic stance, Bayes’ rule turns out to be indeed the optimal belief update of the adversary. The saddle-point strategy of the defender hence solves the following optimisation:
For the saddle-point of the adversary, we can rewrite Equation (
9) as
Therefore, the best strategy of the defender for a given
x is to put all the probability weight of
of the
y that achieves the smallest
across all feasible
y’s for that
x, i.e.,
Hence, the saddle-point strategy of the adversary comes from solving the following optimisation:
We will consider the following payoff function:
where
and
are real valued functions. This payoff function can be understood as a weighted difference between the gain of the attacker in guessing the secret and the utility of the channel.
We will refer to such zero-sum game between a defender and an adversary as
(also
G-game), which is specified by
. For such a game, the optimisation problem for saddle-point strategy of the defender in Equation (
10) becomes
Theorem 1. For any optimal channel design problem in Equation (7), there is an induced game , where the optimal channel is the saddle-point strategy of the defender. Conversely, for any game , the saddle-point strategy of the defender is a solution to an induced optimal channel design problem.
Proof. We showed in Proposition 3 that the optimal channel design problem for any core-concave
H is a convex optimisation. Since
is an increasing function, it can be removed from the optimisation without any effect. Now, from convex optimisation theory, we know that there exists a Lagrange multiplier
such that the solutions of the original optimisation matches those of the following Lagrange relaxation problem:
Or equivalently,
Now, since
is a convex function of
, there is a countable set
and a function
such that
In particular,
can be constructed as follows: This follows from application of the supporting hyperplanes and a limit argument, as presented, e.g., in [
19] (Theorem 5). Therefore, the optimisation can be written as
Now, note that the minimisation is defining exactly the saddle-point strategy of the defender in a game
as given in Equation (
12).
Now, for the reverse direction, consider the game
. The saddle-point strategy of the defender is a solution of the optimisation in Equation (
12). Note that the
characterises a convex function, or a negative of a concave function, which we call
, i.e., let
With this notation, the saddle-point strategy of the defender solves
Let a saddle-point strategy of the defender be denoted by
. Now consider the the following convex optimisation:
where
. We claim that these two convex optimisations are equivalent. To see this, note that the KKT conditions are necessary and sufficient for optimality in both optimisations. Moreover, if we take the
in Equation (
13) to be the Lagrange multiplier of the minimum utility constraint in Equation (
14), these KKT conditions are exactly identical, except that Equation (
14) has an additional complementary slackness condition:
. Since
, we should have, for an optimum of Equation (
14),
, which holds for the saddle-point strategy by our specific choice of
. ☐
When the action-space of the adversary is finite, the saddle point strategies can be computed using linear programming. Specifically:
Proposition 5. If the game has a finite number of pure strategies, then the saddle point strategies expressed by Equations (10) and (11) can be computed as the solution to the following linear program (LP) and its dual:Introducing variables for , the dual of the above LP is Proof. In the first LP, the constraints
and
guarantee that, for each
y, the optimisation chooses
; hence, the objective function becomes exactly as in Equation (
10).
Similarly, for the second LP, the constraints
and
guarantee that the optimisation chooses
, which is exactly the optimisation problem of the adversary as in Equation (
11). ☐
5.2. The Adversary’s Problem: Robust Inference
One important advantage of the game-theoretical analysis is that it connects the problem of the defender and attacker. Here, we provide a practical interpretation of the adversary’s problem: Suppose we would like to extract information (i.e., infer) about X by observing Y. We know the prior over X, but we do not know , i.e., the channel. All we know is that the channel has to respect some hard and/or soft operational constraints. What is the best inference about X in the absence of the channel? One approach is to consider the worst case among all possible channels that satisfy the constraints. The resulting “robust” strategy will have the minimum inference guarantee for any feasible realisation of the channel. The game-theoretical analysis reveals that the optimal channel design problem and the robust inference problem are equivalent; i.e., they are duals of each other.
5.3. Measure-Invariant Optimality
Notice that in all cases seen so far the optimal solution depends on the choice of entropy. There is, however, a particular case studied in Reference [
1] where the optimiser is universal, i.e., is the same for all entropies:
Proposition 6. (Theorem 1 in Reference [1]) When there are no soft constraints and the hard constraints are equivalent to just a size-cap of k on the pre-images of the outputs, there is a closed form solution for the Nash equilibrium. Moreover, this solution is universally optimal, i.e., it is optimal for any choice of entropy.
6. Uncertainty about the Prior
We have assumed that the input is realised according to a single distribution p that is known to the adversary. We now analyse the setting where the prior distribution of the input can be one of a number of possibilities, each happening with a known probability (a distribution over distributions. That is, the distribution of the input itself depends on a hidden random variable, which we refer to as the context. The adversary knows the joint statistics of the hidden context and the input, but does not get to observe the realisation of the context.
At a high level, the main result of this section is the following: the best strategy for the defender is not to “customise” its strategy with respect to the context depending on the particular prior given each context, but rather to build an “averaged prior”, and design the best strategy over this averaged prior and play it irrespective of the contexts. This result implies that the context-dependent optimal channel design problem reduces to an equivalent context-independent channel design problem over the mixed prior.
This result may not be immediately intuitive, as there can be a counterargument as follows: Among the available priors, there are some particularly “good” ones, in the sense that they are very conducive to hide the secret (e.g., they are very close to uniform in a symmetric constraint setting). Then shouldn’t the defender adopt the optimal channel for such priors in those contexts—especially if they have a high probability weight of occurrence? Our result refutes this intuitive argument.
To formalise the setting, let the space of the discrete random variable of the context be . Without loss of generality, we assume that the context has full support, i.e., . The channel designer (the defender) knows the true distribution of the secret. Technically speaking, the defender “observes” the realisation of the context. The adversary, on the other hand, does not directly observe the context, but knows the probability of the realisation of each context, , as well as the (conditional) probability distribution of the secret given each context, . Note that knowledge of and is equivalent to the knowledge of the “joint” probability distribution of the context and the secret .
The adversary only sees the output
Y and wants to “infer” about the input
X. In the worst case, one can assume that the adversary knows
and hence, using his knowledge of
, can use Bayes’ rule to update his best belief about the secret after observing
Y, i.e., constructing his
posterior:
Note that the defender is not directly interested in not leaking information about the context and only cares about
X, but should be wary of how the adversary can use their information about the joint distribution of the context and input to intuit the input based on the observation. In addition, for clarity, we repeat that the adversary does not “observe” the context nor the secret. (For the scenario where the adversary can directly observe the context, the problem will reduce to designing
optimal channels according to optimisations as in Equation (
7) with priors
for each
.)
The defender decides what observable to produce per each secret in each context, potentially using randomisation and benefit from the ambiguity that it can inject. As before, the strategy has to satisfy some operational constraints. We may have hard constraints prescribing which secrets can produce which observables, which in part determine which subsets of secrets can be conflated with each other. In the previous sections, we expressed these “hard” operational constraints through , representing the set of permissible secret-observable pairs. In the presence of contexts, in the most general form, the permissible observables for a secret may depend on the context as well; thus, should be now a subset of . However, for the result of this section, we assume that these constraints are context-independent, i.e., the same subset of observables is permissible for a secret irrespective of the context, so we keep to be a subset of .
Likewise, there can be soft operational constraints in the form of satisfying a minimum expected utility. The expectation is now taken with respect to the context as well, that is, we must have expectation of the payoff with respect to
to be no less than
. However, for the result of this section, we assume that the payoff function
u, i.e., the measure of “goodness” of each observable for each secret, does not depend on the context. Hence,
As before, without loss of generality, assume that we are dealing with core-concave functions, i.e.,
F is concave and
is increasing. Moreover, note that, again, the choice of the strategy cannot affect the prior entropy of the secret. Hence, the problem of designing for minimum leakage is again equivalent to maximising the posterior entropy. Ignoring
, since it is just an increasing scalar function, the posterior entropy (as the objective of the maximisation) can hence be written as
The constraints of the optimisation are:
Given any “context-dependent” strategy
p, we define a corresponding “context-independent” strategy
as follows:
To be precise, the strategy is
such that for any
,
, i.e.,
represents playing the same randomised strategy of
irrespective of the context. This context-free strategy is a mixing of the context-dependent strategies with weights equal to conditional probability of the context given the secret. In other words,
“marginalises away” the dependence of
p on the context. Note however, that we cannot marginalise away the dependence on
X, because of the input-dependent constraints: these input-dependent constraints are exactly why the trivial solutions like
are not acceptable.
First, we show that is itself a legitimate strategy:
: trivially (product of non negative terms).
; this is because
where we first exchanged the order of the summations, and then respectively used the facts that
and
are conditional distributions.
We show that the expected payoff under strategy
is the same as the expected payoff under strategy
. Therefore, if
satisfies the minimum expected payoff constraint, so does
. For this purpose, we establish the following lemma, which we will user later:
Lemma 1. Let and denote the induced (joint) distribution on where, respectively, strategies and are employed. Then we have .
Proof. . ☐
Now, the equality of the expected payoff under these two strategies follows as a simple corollary:
The second equality holds because
does not depend on
c, and
. The third equality is due to Lemma 1.
, trivially. Note that we made the assumption that the hard constraints do not depend on the context, and only on the input.
Next, we show that replacing any context-dependent strategy with its context-independent counterpart would lead to same leakage (irrespective of the choice of the entropy).
Lemma 2. Let and denote the posterior entropies where strategies and its corresponding are used. Then we have .
Proof. This is also a direct consequence of Lemma 1, once we notice that is completely determined by . ☐
This in turn implies that the search for optimal channels can be restricted to the context-independent ones. We are now ready for the main result of this section: that the (informally) optimal channel problem with uncertainty can be reduced to the classical case of Equation (
7):
Theorem 2. The optimisation in Equation (15) subject to Equation (16) can be simplified to an instance of Equation (7) where the prior distribution is the context-average prior, i.e., . In particular, if is an optimal solution of Equation (7) with the average prior, then an optimal solution of Equation (15) subject to Equation (16) is to play for all .
Proof. This proof follows a similar argument as above. In particular, if we let
for all
, the constraints of Equations (16a)–(16c) follow directly from feasibility of
for Equation (
7). Now, let the joint probability on
induced by
and
be respectively denoted by
and
. Then
. On the other hand,
, where
is the prior used in Equation (
7). Hence, by taking this prior to be
, we ensure that
. This in turn implies that
satisfies Equation (16d) and, further, has the same
as of
, which by construction has the highest value. Finally, from Lemma (2),
is also the highest value across all (potentially context-dependent) channels. ☐
6.1. Game-Theoretical Interpretation
Let us consider now the implications of Theorem 2 with respect to our game-theoretical interpretation: Notice first we can cast the uncertainty on the prior in terms of a Bayesian game over
games as defined in
Section 5: Nature chooses one of the possible priors, and the players then play in the
game corresponding to that prior. Theorem 2 says that the defender optimal strategy in this Bayesian game is to play the Nash equilibrium strategy from the
game corresponding to the average prior.
The adversary has to best respond to the defender move (as the defender plays first), and, as the attacker does not know the subgame chosen by Nature but only sees the move played by the defender (all sub-games in the Bayesian game have the same set of moves), he can only best respond over the average prior.
Hence, the Nash equilibrium in the Bayesian game over a set of priors is given by the Nash equilibrium over the game over the average prior specified in Theorem 2.
6.2. Discussion
As mentioned in the beginning of this section, an alternative heuristic is to play the best channel per each context. One can argue that, if the “good” priors that lead to a particularly strong channel have a high probability, it may be better to play this heuristic. However, as we established in Theorem 2, this heuristic is wrong. For a numerical depiction, in
Figure 3, we have plotted the posterior entropy that is achieved by the optimal strategy
per Theorem 2 against this heuristic strategy of playing the best channel for each prior. As we can see, for any weight of the two priors (except trivially when the weight is either 0 or 1, where the two strategies become the same), the
strictly outperforms the heuristic strategy.





{kind=link}
{kind=link}
{kind=link}