Big-Data-Mining-Based Improved K-Means Algorithm for Energy Use Analysis of Coal-Fired Power Plant Units: A Case Study

Abstract
:1. Introduction
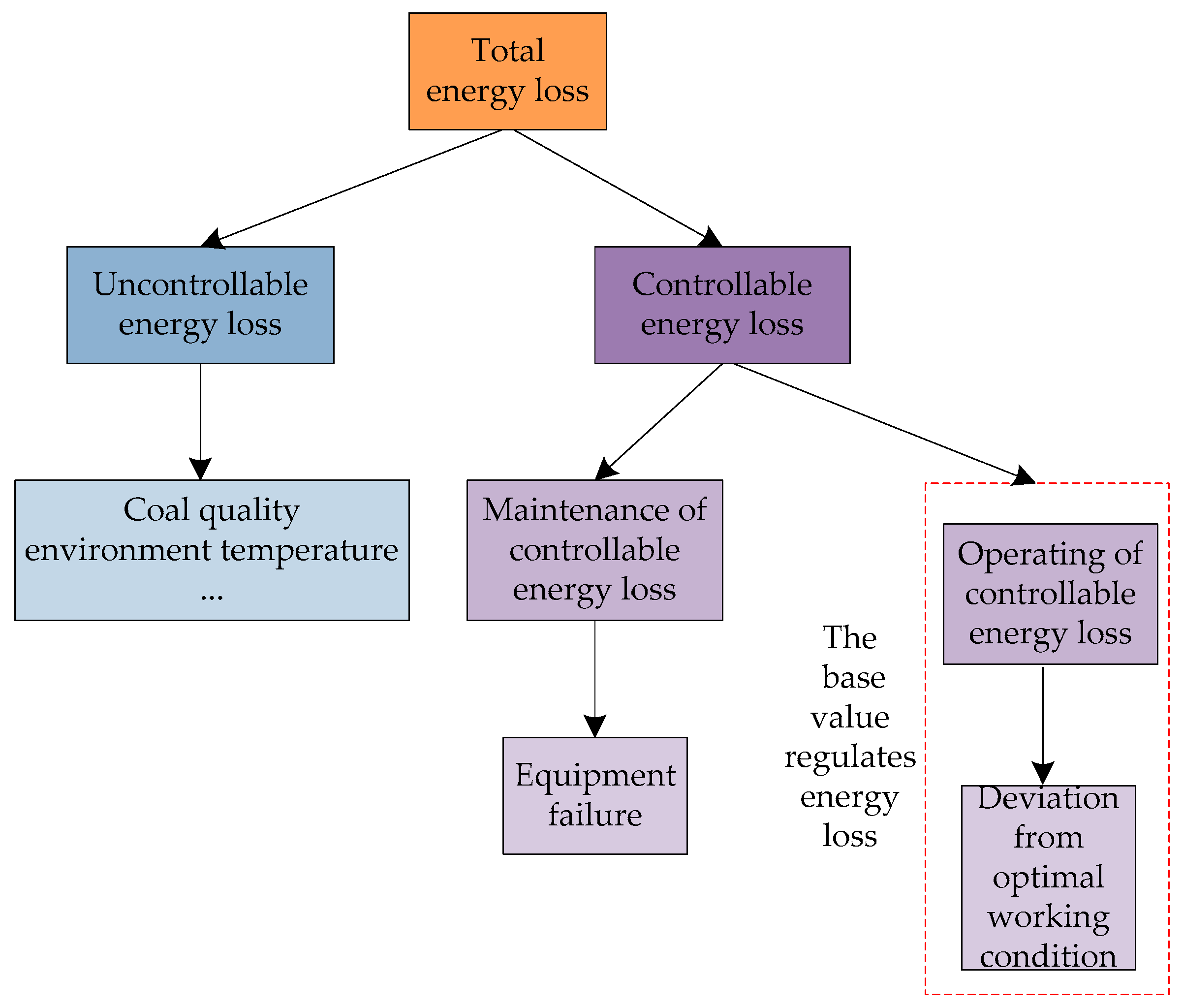
2. Analysis of Energy Loss of Thermal Generators
3. Relevant Theories of New Algorithm
3.1. Fuzzy and Rough Sets Theory
| Algorithm 1. The QuickReduct attribute reduction algorithm. |
| 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: |
3.2. Canopy Algorithm
3.3. K-Means Clustering
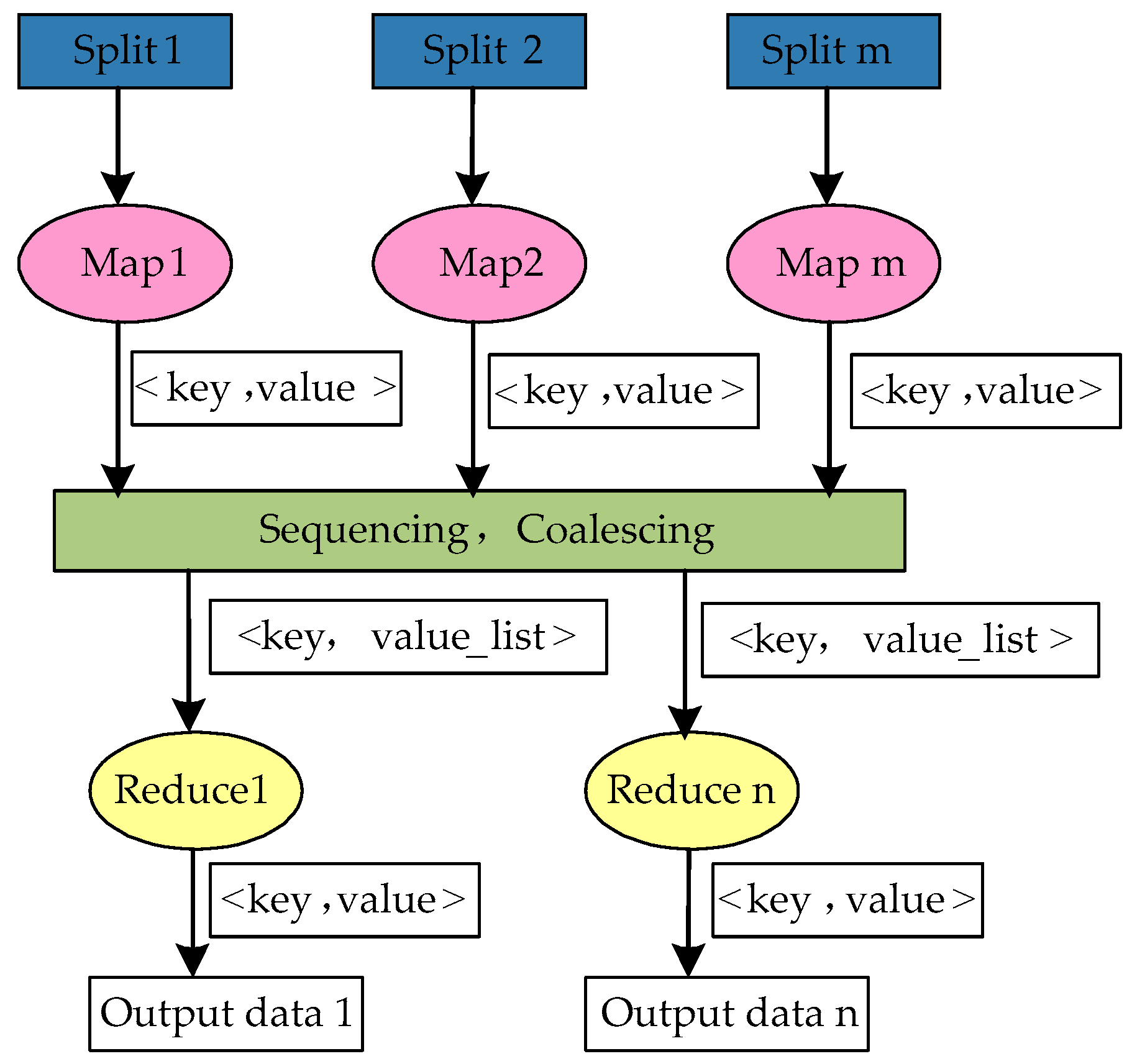
3.4. Hadoop Platform
4. Calculation Process of FMK-Means Algorithm
- (1)
- Establish a decision table of energy use. Consider the various factors that may affect power supply coal consumption and divide the operating conditions according to external conditions, such as load, coal type, and environment temperature. Take the coal consumption rate as the decision attribute, and the controllable operating parameters, which have a close relation with the former, as the condition attribute.
- (2)
- Clarify the fuzzy membership function in accordance with the attributes of each parameter and convert the parameter data into set y of fuzzy data.
- (3)
- Reduce the operating parameters that affect the coal consumption rate by using the QuickReduct method. After the simplest set of attributes has been calculated, compute the importance of each condition attribute to the coal consumption rate.
- (4)
- In the Map stage of Canopy, convert the simplest set of attributes into the form of <key, value> and send these key values to m in Map functions. Then, calculate the distance threshold of each data point and compare these distances with D1 and D2. After being classified, these distances are iterated into the Canopy set.
- (5)
- In the Reduce stage of Canopy, unite and calculate the output of the Map stage and form the dataset Q; then, process the set Q using Canopy. Repeat the above steps until the dataset becomes empty, and then obtain the cluster K and its center point, which is taken as the input value of the K-means framework.
- (6)
- In the Map stage of K-means, convert the reduced new data set into the form of <key, value> and send it to m in Map functions. Calculate the distance between each node data and each cluster center, and then allocate these nodes to the cluster that is nearest to them. Mark each cluster type and output them in the form of <key, value>.
- (7)
- The Combine function is used to divide the output value of the Map function, then merges the data that belong to the same cluster. Sum the corresponding dimension of the data in one cluster and count the number of data objects. Finally, the calculated results are output in the form of <key, value>. “Key” is the type of cluster, whereas “value” is the corresponding dimension of data and the accumulated number of the data objects.
- (8)
- In the Reduce stage of K-means, receive the output value of the Combine function, then analyze the sum of the corresponding dimension of the data in each cluster, as well as the total number of data objects. Thus, new cluster centers will be obtained, and a new round of iteration will be conducted until the function converges.
5. Energy Use Sensitivity Analysis Using Support Vector Machine (SVM)
6. Example Analysis
6.1. Object and Goals of Study
- (1)
- Main steam pressure: When the main steam temperature, exhaust pressure, and reheat stream parameter remain unchanged and the main steam pressure is lowered, the ideal enthalpy drop of the unit decreases and the turbine steam rate increases, which are accompanied by a drop in unit power. Thus, the efficiency and security of the unit inevitably degrades. It can be concluded that the deviation of main steam pressure from the reference value affects the efficiency and security of the unit.
- (2)
- Main stream temperature: When the parameters of main stream pressure, exhaust pressure, and reheat steam are constant, and the main steam temperature is reduced, the ideal enthalpy drop of the unit and its efficiency decrease and exhaust humidity increase, resulting in a decrease in unit power. Thus, the economy of the unit decreases. It can be seen that the changes in main stream temperature influence the coal consumption rate.
- (3)
- Reheat stream temperature: Similar to the main stream temperature analysis, the changes in reheat stream temperature influence unit economy and safety. When the reheat stream temperature deviates from the reference value, the work capacity loss and coal consumption rate increase.
- (4)
- Emission capacity of oxygen content: The emission capacity of oxygen content is the excess air coefficient. If the excess air coefficient is too small, it increases the incomplete combustion loss of the unit and reduces combustion capacity, thereby reducing unit efficiency. If the coefficient is too large, it cannot only reduce the incomplete combustion loss and unit efficiency; it will increase the exhaust smoke loss. Therefore, choosing an appropriate range for the excess air coefficient is crucial for improving the efficiency and economic operation of the unit.
- (5)
- Feedwater temperature: The change in feedwater temperature also leads to economic changes in the unit. Reducing the feedwater temperature increases the heat absorption of the working substance in the water-cooled wall and lower the exhaust temperature to a certain extent. However, the amount of fuel must be increased to maintain a certain amount of evaporation, which leads to an increase in furnace outlet temperature and each part of gas temperature. As a result of the two effects, the economy of the unit decreases. Therefore, it is necessary to maintain the appropriate feedwater temperature.
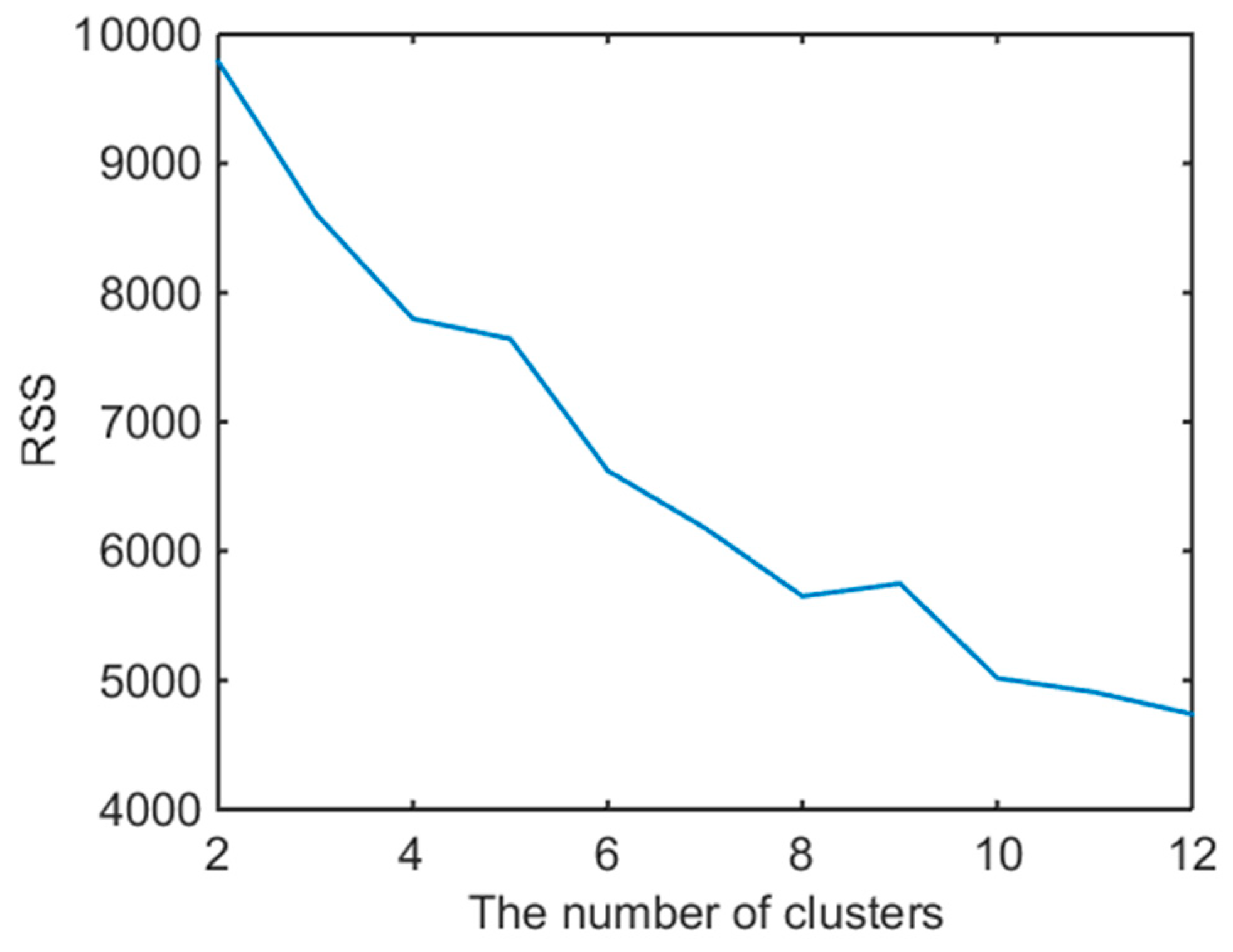
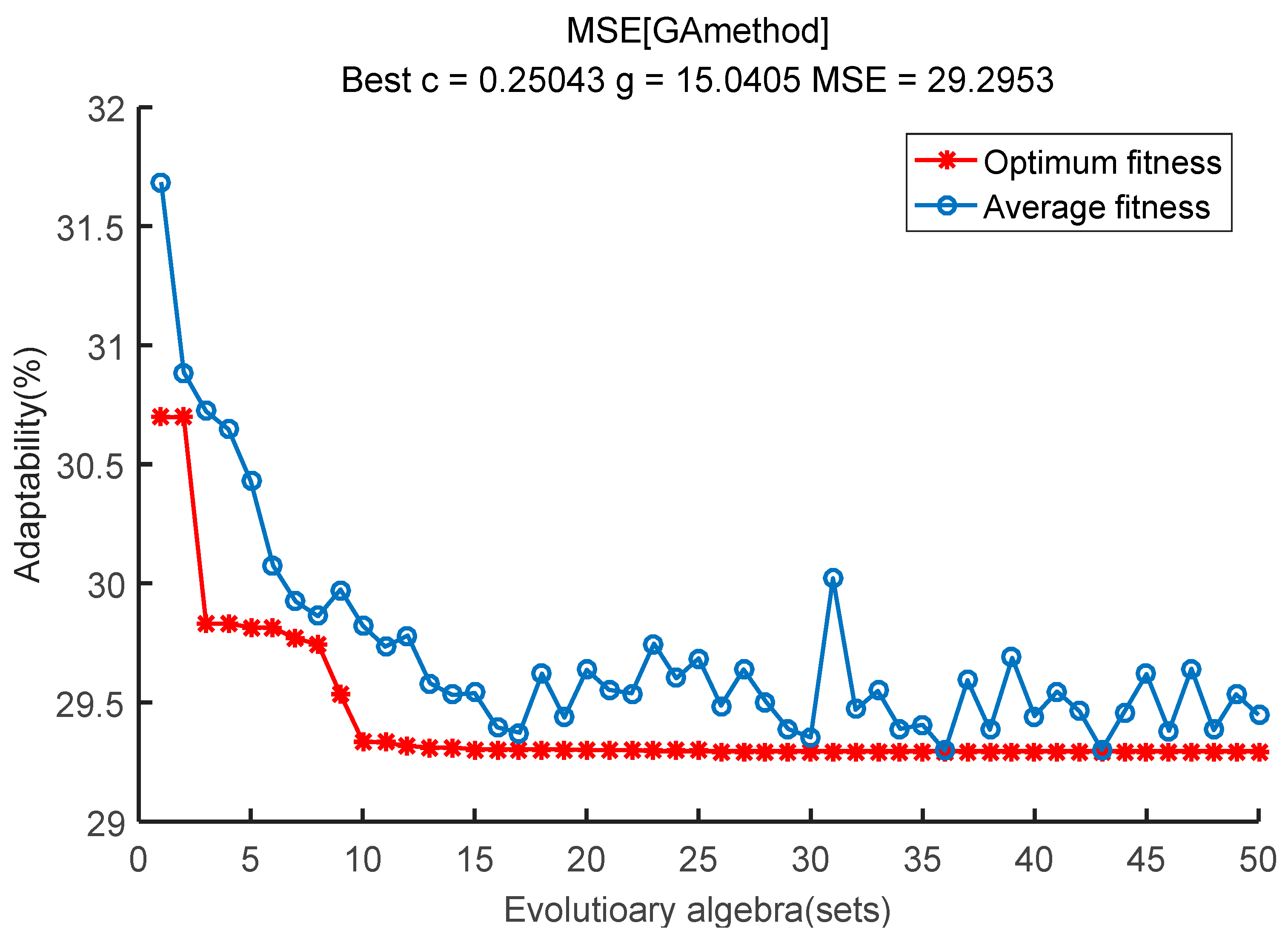
6.2. Algorithm Application and Calculation Result
6.3. Analysis of Energy Use Sensitivity Under Different Loads
- (1)
- The number of samples in each load interval was larger than that of the modeling support vectors (Table 6). Instead of using all the samples, the typical sample training model that can be used as a support vector is applied to modeling, which can not only reduce the complexity of training samples but also the time spent in modeling.
- (2)
- The model accuracy of the 300, 350, and 400 MW load condition was lower than that of the 450, 500, 550, and 600 MW load condition (Table 6). The reason is that the higher the load, the more stable the units, which results in the reduction in noise data in the high load area and decreased influence on modeling. Thus, the model accuracy in the high load area is higher.
- (3)
- The operating parameters under different load sensitivity coefficients on the power supply coal consumption was constantly changing (Table 7), which indicates that the influence of all operating parameters on coal consumption is different if the load condition is not the same. In addition, the relationship between the sensitivity coefficient and the load was non-linear; therefore, it is necessary to analyze the sensitivity coefficient of each parameter for the coal consumption under typical load conditions. In actual unit operating processes, corresponding measures should be adopted to reduce the coal consumption in accordance with different load conditions, and measures should be taken first for the parameters with high sensitivity coefficients.
7. Discussion
8. Conclusions
- (1)
- The introduction of the Fuzzy and Rough Sets Theory and the Canopy algorithm improved the K-means clustering algorithm. The improved K-means algorithm was then subjected to parallel processing by the MapReduce programming model to study the new FMK-means algorithm, which eliminated redundant data and greatly improved clustering accuracy and efficiency.
- (2)
- The multi-index data mining of the historical data of a 600 MW coal-fired generating units was conducted by using the new FMK-means algorithm. The algorithm was able to determine the controllable operating parameter reference values and the actual reachable values of coal consumption under the optimal working conditions and provides guidance regarding how to adjust the operation of the unit. Under load conditions of 300, 400, 500, and 600 MW, the actual values of the unit coal consumption rate were 320.69, 312.76, 310.90, and 307.95 g/(kW·h), respectively.
- (3)
- The SVM technique was used to develop an energy use analysis model and to calculate the sensitivity coefficient of each parameter for coal consumption under different load conditions. The model accuracy of the 300, 350, and 400 MW load condition was lower than that of the 450, 500, 550, and 600 MW load condition. This activity serves as a method to optimize thermal unit operation and minimize energy use.
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Yang, Y.P.; Yang, Z.P.; Xu, G.; Wang, N.L. Situation and prospect of energy use for China’s thermal power generation. Proc. CSEE 2013, 33, 1–12. [Google Scholar]
- Information Development Department of China Electricity Council. China’s Electric Power Industry Annual Development Report; China Electricity Council: Beijing, China, 2016. [Google Scholar]
- National Development and Reform Commission. Transformation and Upgrading Action Plan of Energy Saving and Emissions Reduction for Coal-Fired Power Plants (2014–2020); National Energy Administrator: Beijing, China, 2014.
- Xu, J.; Gu, Y.; Chen, D.; Li, Q. Data mining-based plant-level load dispatching strategy for the coal-fired power plant coal-saving: A case study. Appl. Therm. Eng. 2017, 119, 553–559. [Google Scholar] [CrossRef]
- Li, J.Q.; Zhao, K.; Chen, X.X.; Zhang, Y.Y. Combined optimization of optimal oxygen content and second air distribution in 600 MW coal-fired unit. Proc. CSEE 2017, 37, 4422–4429. [Google Scholar]
- Fu, P.; Wang, N.L.; Wang, L.G.; Morosuk, T.; Yang, Y.P.; Tsatsaronis, G.B. Performance degradation diagnosis of thermal power plants: A method based on advanced exergy analysis. Energy Convers. Manag. 2016, 130, 219–229. [Google Scholar] [CrossRef]
- Arora, P.; Varshney, S. Analysis of K-Means and K-Medoids algorithm for big data. Procedia Comput. Sci. 2016, 78, 507–512. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, P.H.; Qian, J.; Su, Z.G.; Peng, X.Y. Modeling for target-value of boiler monitoring parameters based on fuzzy C-Means clustering algorithm. Proc. CSEE 2011, 31, 16–22. [Google Scholar]
- Qian, J.; Wang, P.H.; Li, L. Application of clustering algorithm in target-value analysis for boiler operating parameter. Proc. CSEE. 2007, 27, 71–74. [Google Scholar]
- Fang, B.L.; Yin, X.; Tan, Y.; Li, C.B.; Gao, Y.P.; Gao, Y.J.; Li, J.L. The contributions of cloud technologies to smart grid. Renew. Sustain. Energy Rev. 2016, 59, 1326–1331. [Google Scholar] [CrossRef]
- Tsai, C.F.; Lin, W.C.; Ke, S.W. Big data mining with parallel computering: A comparison of distributed and MapReduce methodologies. J. Syst. Softw. 2016, 122, 83–92. [Google Scholar] [CrossRef]
- Nyashina, G.S.; Kurgankina, M.A.; Strizhak, P.A. Environmental, economic and energetic benefits of using coal and oil precessing waste instead of coal to produce the same amount of energy. Energy Convers. Manag. 2018, 174, 175–187. [Google Scholar] [CrossRef]
- Glushkov, D.; Paushkina, K.; Shabardin, D.; Strizhak, P. Environmental aspects of converting municipal solid waste into energy as part of composite fuels. J. Clean. Prod. 2018, 201, 1029–1042. [Google Scholar] [CrossRef]
- Zhou, K.L.; Yang, S.L.; Shen, C.; Ding, S.; Sun, C.P. Energy conservation and emission reduction of China’s electric power industry. Renew. Sustain. Energy Rev. 2015, 45, 10–19. [Google Scholar] [CrossRef]
- Yang, Y.P.; Yang, K. Theory of energy conservation potential diagnosis for a coal-fired unit and its application. Proc. CSEE 1998, 18, 131–134. [Google Scholar]
- Xia, J.; Peng, P.; Hua, Z.G.; Lu, P.; Zhang, C.; Chen, G. Optimization of Pulverizers Combination for Power Plant Based on Blended Coal Combustion. Proc. CSEE 2011, 31, 1–8. [Google Scholar]
- Xiao, X.B.; Liu, J.; Gao, A.N.; Zhouyu, M.Q.; Liu, B.H.; Gao, M.D.; Zhang, X.L.; Lu, Q.; Dong, C.Q. The performance of nickel-loaded lignite residue for steam reforming of toluene as the model compound of biomass gasification tar. J. Energy Inst. 2017. [Google Scholar] [CrossRef]
- Wang, N.; Wen, Z.G.; Liu, M.Q.; Guo, J. Constructing an energy efficiency benchmarking system for coal production. Appl. Energy 2016, 169, 301–308. [Google Scholar] [CrossRef]
- Wang, N.L.; Yang, Y.P.; Yang, Z.P. Energy-consumption Benchmark Diagnosis of Thermal Power Units Under Varying Operation Boundary. Proc. CSEE 2013, 33, 1–7. [Google Scholar]
- Dubois, D.; Prade, H. Rough fuzzy sets and fuzzy rough sets. J. Gen. Syst. 1990, 17, 191–209. [Google Scholar] [CrossRef]
- Chris, C.; Jesus, M.; Nele, V. Multi-adjoint fuzzy rough sets: Definition, properties and attribute selection. Int. J. Approx. Reason. 2014, 55, 412–426. [Google Scholar]
- Cao, J.N.; Shao, Z.F.; Guo, J.; Wang, B.; Dong, Y.W.; Wang, P.L. A multi-scale method for urban tree canopy clustering recognition using high-resolution image. Optik 2015, 126, 1269–1276. [Google Scholar] [CrossRef]
- Gerhard, Z.; Usman, H.; Max, B.; Florian, J.; Thomas, L. Sanitation and analysis of operation data in energy systems. Energies 2015, 8, 12776–12794. [Google Scholar]
- Singh, S.; Garg, R.; Mishra, P.K. Performance optimization of MapReduce-based a priori algorithm on Hadoop cluster. Comput. Electr. Eng. 2018, 67, 348–364. [Google Scholar] [CrossRef]
- Qi, M.F. Big Data Technology and Its Application on the Analysis of Power Plant Units; North China Electric Power University: Beijing, China, 2016. [Google Scholar]
- Li, J.Y.; Zhang, B.H.; Shi, J.F. Combining a genetic algorithm and support vector machine to study the factors influencing CO2 emissions in Beijing with scenario analysis. Energies 2017, 10, 1520. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Parameter Name | Unit | Label | Parameter Name | Unit |
|---|---|---|---|---|---|
| A1 | Main steam pressure | MPa | A7 | Average smoke temperature | °C |
| A2 | Main steam temperature | °C | A8 | Feedwater temperature | °C |
| A3 | Reheat steam temperature | °C | A9 | First degree heat desuperheated water | °C |
| A4 | Reheat steam pressure | MPa | A10 | Second degree heat desuperheated water | °C |
| A5 | Condenser vacuum | % | A11 | Condensate water pressure | MPa |
| A6 | Average smoke oxygen | % | A12 | Condensate water temperature | °C |
| Rank | Parameter | Dependence |
|---|---|---|
| 1 | Average smoke oxygen | 0.2537 |
| 2 | Main steam temperature | 0.2509 |
| 3 | Reheat steam temperature | 0.2183 |
| 4 | Feedwater temperature | 0.1774 |
| 5 | Condenser vacuum | 0.1372 |
| 6 | Main steam pressure | 0.1168 |
| 7 | Average smoke temperature | 0.0855 |
| Label | Cluster-1 | Cluster-2 | Cluster-3 | Cluster-4 | Cluster-5 |
|---|---|---|---|---|---|
| Main steam temperature (°C) | 539.78 | 538.12 | 539.15 | 527.86 | 538.94 |
| Main steam pressure (MPa) | 15.65 | 15.72 | 15.65 | 15.88 | 15.76 |
| Reheat steam temperature (°C) | 536.48 | 537.50 | 534.67 | 523.07 | 538.67 |
| Average smoke oxygen (%) | 5.14 | 5.54 | 5.27 | 5.39 | 5.15 |
| Average smoke temperature (°C) | 113.78 | 111.90 | 110.76 | 115.51 | 117.38 |
| Condenser vacuum (%) | 0.92 | 0.97 | 0.95 | 0.92 | 0.93 |
| Feedwater temperature (°C) | 252.50 | 250.40 | 251.38 | 252.93 | 251.85 |
| Coal consumption rate (g/(kW·h)) | 314.53 | 312.76 | 315.77 | 323.53 | 320.86 |
| Load (MW) | 300 | 400 | 500 | 600 |
|---|---|---|---|---|
| Main steam temperature (°C) | 537.91 | 538.12 | 538.52 | 539.13 |
| Main steam pressure (MPa) | 8.35 | 15.72 | 16.33 | 16.55 |
| Reheated steam temperature (°C) | 537.71 | 537.50 | 538.12 | 539.78 |
| Average smoke oxygen (%) | 6.53 | 5.54 | 4.59 | 3.82 |
| Average smoke temperature (°C) | 104.52 | 111.90 | 117.23 | 120.40 |
| Condenser vacuum (%) | 0.98 | 0.97 | 0.96 | 0.94 |
| Feedwater temperature (°C) | 237.96 | 250.40 | 262.18 | 272.60 |
| Coal consumption rate (g/(kW·h)) | 320.69 | 312.76 | 310.90 | 307.95 |
| Parameter | Main Steam Temperature (MPa) | Main Steam Pressure (°C) | Reheated Steam Temperature (°C) | Feedwater Temperature | Average Smoke Oxygen (%) | Average Smoke Temperature (°C) | Condenser Vacuum (%) |
|---|---|---|---|---|---|---|---|
| Sensitivity valve | 0.0245 | 0.1427 | 0.0976 | 0.2202 | 0.1178 | 0.0146 | 0.3827 |
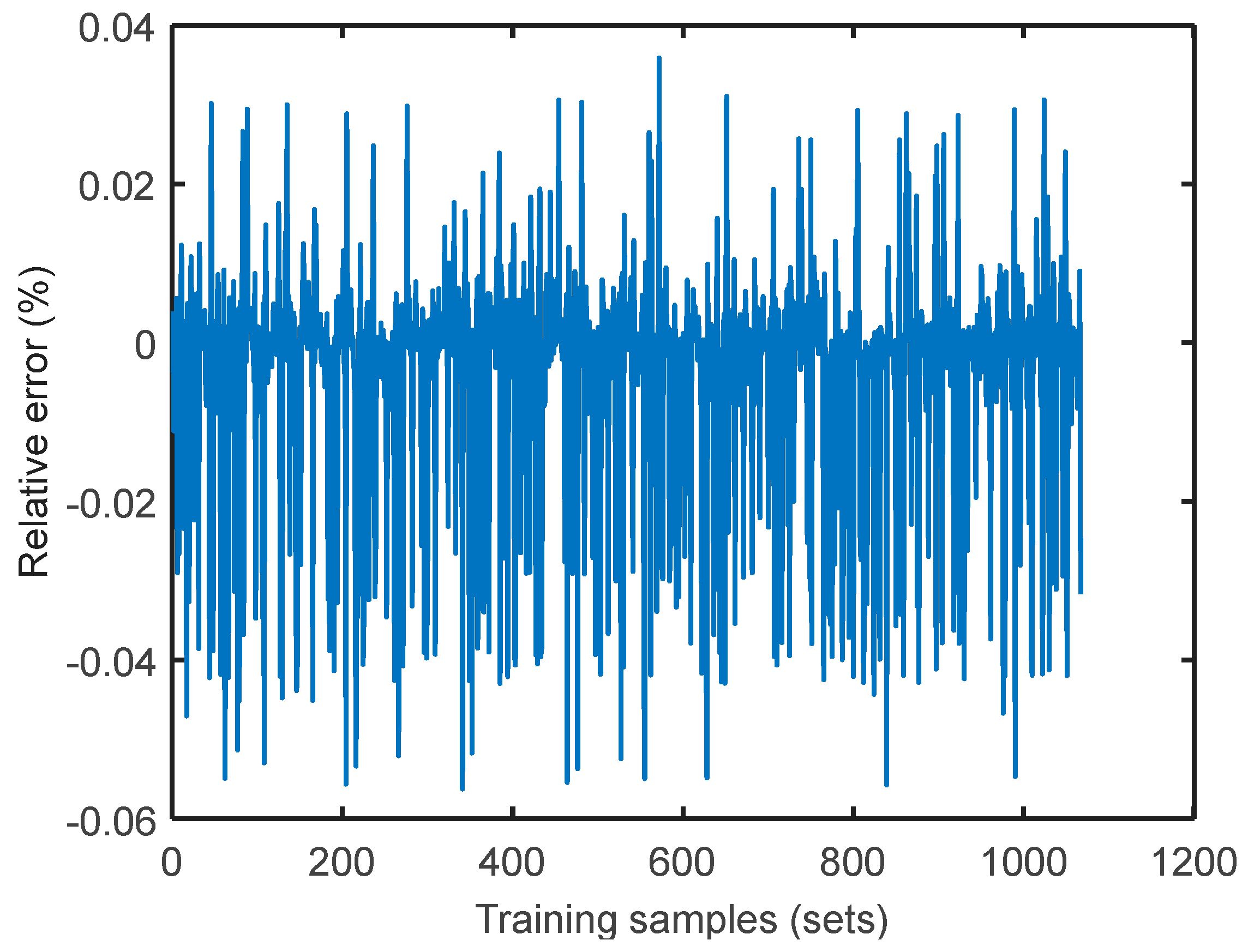
| Load/MW | Quantity of Training Datasets | Quantity of Test Datasets | Quantity of Support Vector Machines | Average Training Data Error/% | Average Test Data Error Data/% |
|---|---|---|---|---|---|
| 300 | 1549 | 387 | 1465 | 0.7606 | 0.7396 |
| 350 | 1055 | 264 | 1038 | 1.3994 | 1.2580 |
| 400 | 1067 | 267 | 1006 | 1.0019 | 0.9232 |
| 450 | 272 | 68 | 253 | 0.3441 | 0.3875 |
| 500 | 194 | 49 | 175 | 0.2235 | 0.2390 |
| 550 | 125 | 31 | 114 | 0.2409 | 0.2412 |
| 600 | 256 | 64 | 241 | 0.4679 | 0.4477 |
| Load (MW) | 300 | 350 | 400 | 450 | 500 | 550 | 600 |
|---|---|---|---|---|---|---|---|
| Main steam pressure (MPa) | 0.0028 | 0.1349 | 0.0245 | 0.0856 | 0.0386 | 0.0337 | 0.0288 |
| Main steam temperature (°C) | 0.1405 | 0.1265 | 0.1427 | 0.0974 | 0.1361 | 0.0862 | 0.1069 |
| Reheated steam temperature (°C) | 0.0026 | 0.1483 | 0.0976 | 0.1571 | 0.1476 | 0.1381 | 0.0973 |
| Feedwater temperature (°C) | 0.1698 | 0.1345 | 0.2202 | 0.1749 | 0.1790 | 0.2427 | 0.2859 |
| Average smoke oxygen (%) | 0.0551 | 0.1024 | 0.1178 | 0.0355 | 0.0303 | 0.0211 | 0.0190 |
| Average smoke temperature (°C) | 0.0929 | 0.0225 | 0.0146 | 0.0326 | 0.0759 | 0.1591 | 0.1739 |
| Condenser vacuum (%) | 0.5364 | 0.2910 | 0.3827 | 0.2170 | 0.4525 | 0.3933 | 0.2883 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Fu, Z.; Wang, P.; Liu, L.; Gao, M.; Liu, J. Big-Data-Mining-Based Improved K-Means Algorithm for Energy Use Analysis of Coal-Fired Power Plant Units: A Case Study. Entropy 2018, 20, 702. https://doi.org/10.3390/e20090702
Liu B, Fu Z, Wang P, Liu L, Gao M, Liu J. Big-Data-Mining-Based Improved K-Means Algorithm for Energy Use Analysis of Coal-Fired Power Plant Units: A Case Study. Entropy. 2018; 20(9):702. https://doi.org/10.3390/e20090702
Chicago/Turabian StyleLiu, Binghan, Zhongguang Fu, Pengkai Wang, Lu Liu, Manda Gao, and Ji Liu. 2018. "Big-Data-Mining-Based Improved K-Means Algorithm for Energy Use Analysis of Coal-Fired Power Plant Units: A Case Study" Entropy 20, no. 9: 702. https://doi.org/10.3390/e20090702
APA StyleLiu, B., Fu, Z., Wang, P., Liu, L., Gao, M., & Liu, J. (2018). Big-Data-Mining-Based Improved K-Means Algorithm for Energy Use Analysis of Coal-Fired Power Plant Units: A Case Study. Entropy, 20(9), 702. https://doi.org/10.3390/e20090702