1. Introduction
In the last few decades, complex network theory [
1,
2,
3,
4,
5,
6,
7,
8] has undergone vast developments since the first reports of small world networks [
9] and scale free networks [
10]. The theory of complex networks provides us with a new perspective to understand complex systems. A resulting application field of these theories is the use of complex network methods to identify the characteristics of time series. Zhang and Small [
11,
12] first attempted the transformation from the pseudo-periodic time series to a complex network, which considered each cycle of a time series as a node in the network. Lacasa et al. [
13] proposed a visibility graph method by taking individual observations as nodes and establishing connectivity according to a partial convexity constraint. McCullough et al. and Sun et al. [
14,
15] proposed ordinal partition networks that divide the phase space of a dynamical system into
K disjoint sets and transform the evolution of the system into a sequence of symbols. The network construction methods mentioned above have the specific advantage of a low cost in computations because the embedding step can be avoided, but it may be difficult for them to obtain sufficient information from high-dimensional systems.
Takens’ embedding theorem [
16] for phase space reconstruction states that, if the time delay and embedding dimension are chosen appropriately, the distribution of state vectors in phase space will reflect the underlying dynamics of the original systems. Donner et al. [
17] provided a full classification of networks based on neighborhood relationships between state vectors in the reconstructed phase space of a dynamical system, distinguishing between the
k-nearest neighbor networks [
18], adaptive nearest neighbor networks [
19], and epsilon-recurrence networks [
20,
21,
22]. The epsilon-recurrence networks form the class of recurrence networks in the strict sense, according to the most common definition of recurrences in phase space [
23]. In this type of time series networks, nodes represent state vectors in the reconstructed phase space, and the distance thresholds that determine the connection between nodes are chosen according to a fixed link density or a fixed phase space distance [
20,
21,
22]. If the distance between two nodes is smaller than or equal to the threshold, two nodes are considered to be connected. The traditional statistical characteristics of recurrence networks only reflect the static properties of a time series, such as the homogeneity of the spatial filling, but the time-ordering information is lost in this framework.
In this paper, a novel method based on epsilon-recurrence networks is proposed for the study of the evolution properties of dynamical systems. For each time series, a high-dimensional recurrence network and a corresponding low-dimensional recurrence network were constructed. The network dimension represents the number of state vectors that form a node in the network. Specifically, the nodes of the -dimensional recurrence network are defined by the sequence of consecutive state vectors, while the nodes of the low-dimensional recurrence network represent single state vectors in phase space. The connection is determined by the distance between the nodes. Two topological statistics, the correlation coefficient of the node degrees and edge similarity, were proposed to characterize the similarity between the high-dimensional recurrence network and the corresponding low-dimensional recurrence network. By analyzing numerical data derived from the Hénon map, lkeda map, folded-towel map, and white noise, the capability of these measures to characterize the dynamic properties of time series in the presence of significant noise was demonstrated. Finally, the application to human electrocardiogram (ECG) recordings showed that network-based statistics can effectively distinguish the cardiac system in both the healthy and ventricular tachycardia (VT) states.
The remainder of this paper is organized as follows:
Section 2 introduces the procedures required for the transformation of time series into networks and some topological parameters, which were used to study the similarity between networks; the applications of the proposed method to synthetic data and ECG data are shown in
Section 3 and
Section 4, respectively; and finally, conclusions are drawn in
Section 5.
2. Network Construction from Time Series
We first introduce the procedures required for the construction of complex networks. The process is shown in
Figure 1.
Beginning with the phase space reconstruction, according to Takens’ embedding theorem [
16], a time delay can be used to reconstruct the phase space from a time series. For a time series with
N samples, {
ri}, the state vectors in a phase space, can be defined as follows:
where
is the time delay;
is the embedding dimension; and
is the number of reconstructed state vectors, which is equal to
.
By reconstructing the phase space from a given time series, a series of state vectors
can be obtained. Using these state vectors, we can then construct a high-dimensional recurrence network and a corresponding low-dimensional recurrence network, respectively. A node of the
-dimensional recurrence network is defined by the sequence of
consecutive state vectors, for example,
is the
i-th node in the
-dimensional recurrence network. Each node represents a segment of the phase space trajectory. The distance matrix
between nodes can be obtained by the equation below:
where
denotes the maximum norm. For all nodes in the network, this generates a distance matrix,
, which reflects the distance between segments of the phase space trajectories with length
. By choosing a threshold
for the
-dimensional recurrence network, we obtain the adjacency matrix,
:
if
, while
if
. The conditions
and
correspond to connection and disconnection, respectively. The constructed network contains
nodes.
Subsequently, a corresponding low-dimensional recurrence network, with the same number of nodes
as the
-dimensional network, is constructed. Each node of the low-dimensional recurrence network is defined as a state vector in the reconstructed phase space, for example,
is the
i-th node in the network. The connection between nodes
and
is determined by their distance, which is defined below:
A threshold is set for the low-dimensional recurrence network. The distance matrix, , can then be converted to an adjacency matrix, : if , while if . Similar to the high-dimensional case, and correspond to connection and disconnection, respectively. To avoid self-connection of nodes, we defined .
The construction of the network is highly dependent on the threshold, Δ, which should be tailored to specific questions that need to be solved. Several strategies for the selection of the threshold have been proposed. It was suggested that choosing a fixed link density is helpful for the estimation of the dynamical properties in many systems [
23,
24,
25]. Therefore, we determined the threshold for the
L-dimensional recurrence network, Δ
L, by setting a fixed link density,
ρL, which is defined as follows:
According to the procedures for network construction introduced above, it is known that the nodes in low-dimensional recurrence networks correspond to the first components of the state vectors—represented by the nodes in high-dimensional recurrence networks. For chaotic (deterministic) systems, the evolution trajectories of two close state vectors remain close together for several time steps, thus the high-dimensional recurrence network and the corresponding low-dimensional network are similar. As for random systems, the evolution trajectories starting from nearby initial conditions diverge rapidly over time, leading to a large difference between the high-dimensional network and corresponding low-dimensional network. Therefore, the similarity between the two networks can reflect the evolution properties of the studied dynamical systems that are captured in a single observational time series. In this study, the link densities of the high-dimensional recurrence network and the corresponding low-dimensional recurrence network were set at the same value, so that the two networks were comparable.
According to the analysis above, it can be seen that the similarity between the high-dimensional recurrence network and the corresponding low-dimensional recurrence network is related to the evolution properties of dynamical systems. A quantitative measure is thus proposed to characterize the similarity between networks by considering the correlation of node degrees. The degree of node
in an
-dimensional recurrence network represents the number of nodes that are directly connected with
, as represented below:
The correlation coefficient of the node degree between an
-dimensional recurrence network and the corresponding low-dimensional recurrence network is defined as follows:
where
and
represent the average node degrees of an
-dimensional recurrence network and the corresponding low-dimensional recurrence network, respectively. The correlation measure correlation coefficient of node degrees (CCND) is restricted to the range
and CCND = 1, 0, and −1 represent perfect correlation, no correlation, and perfect anti-correlation, respectively. It should be noted that in a low-dimensional recurrence network (i.e.,
), only the first
nodes are considered. This is because of the fact that the main purpose of Equation (6) is to study to what extent the node degrees of an
-dimensional recurrence network are related to their initial states (corresponding low-dimensional recurrence network) after
time steps. Because of the finite length of the studied time series, there were no corresponding nodes in
-dimensional recurrence networks for nodes
, therefore, these nodes could be neglected.
The degree of a node in low-dimensional recurrence networks reflects the local phase space density, while the degree of a node in high-dimensional recurrence networks represents the density of state vectors in the high-dimensional phase space. For a deterministic system, two close state vectors remain close together during the evolution for several time steps, so the node degrees of high-dimensional recurrence networks are strongly correlated with those of the corresponding low-dimensional recurrence networks. However, if the system is uncorrelated or weakly correlated, the evolution trajectories are random and unpredictable. This results in a smaller correlation of node degrees between the high-dimensional recurrence network and the corresponding low-dimensional recurrence network. Therefore, the CCND can characterize the evolution properties of dynamical systems.
Another measure called the edge similarity is proposed to study the relationship between the distance of the state vectors and the similarity of their evolution trajectories, which cannot be characterized by CCND. For an edge between two nodes
and
in the low-dimensional recurrence network, a weight,
, is assigned according to its distance,
. The weighted edges are partitioned into
groups according to a mapping rule,
, and each group is labeled by an index,
. The mapping rule,
, is defined as follows:
where
indicates the size of each group. The index,
, reflects the values of edge weights that belong to that group (i.e., an edge with a smaller weight is assigned to a group with a smaller index and vice versa). The edge similarity between the
-dimensional recurrence network and the low-dimensional recurrence network in the
I-th group is then defined as follows:
where
is the number of edges that belong to the
I-th group and
is the number of edges that satisfy
in the
I-th group. Thus, the edge similarity,
, represents the probability that an edge in the low-dimensional recurrence network will also remain in the high-dimensional recurrence network within group
. The dynamic properties of time series are characterized by the differences of edge similarities between different groups.
3. Analysis of Synthetic Data
We first illustrated the potential of the proposed method by several typical dynamic systems; namely, the (1) Hénon map, (2) lkeda map, (3) folded-towel map, and (4) white noise.
The Hénon map [
26] is a discrete-time dynamical system. It is one of the examples of dynamical systems that exhibit chaotic behavior, which has been studied the most. The Hénon map takes a point
in the plane and maps it to a new point, as shown below:
The map depends on two parameters and . We chose and , which determined that the Hénon map is chaotic.
The lkeda map was first proposed by lkeda [
27] as a model of light going around a nonlinear optical resonator, which is defined as follows:
where
is a parameter and
. For
, this system has a chaotic attractor. In this study, we chose
.
We also considered the following folded-towel map, introduced by Rössler [
28]:
For and , this map is hyper-chaotic with two positive Lyapunov exponents, so it can generate more complex dynamics than the Hénon map and lkeda map.
We applied the proposed method to time series from different models and characterized the system dynamics by the network-based measures proposed in the last section. All the data were derived from the
x components of the chaotic maps. For each case, we computed a time series of length 6000 and the first 1000 data points were removed in order to exclude transient dynamics. Moreover, the mutual information method [
29] was used to determine the time delay
τ and a large embedding dimension
was chosen to reliably unfold the fine structure [
19]. It should be noted that the mutual information method cannot be directly applied to the discrete chaotic time series. This is because the sampling interval of the discrete chaotic time series is large, which causes rapid variations in the mutual information with respect to
. The resulting curves of the mutual information calculated from the discrete chaotic series are thus similar to the curves from the white noise series. Thus, the discrete chaotic time series should be interpolated before determining its time delay. For any two adjacent data points,
data points were interpolated with a spline function in this study. The data and the reconstructed state vectors after interpolation can be represented as
and
, respectively, where
and
. Thus, each node of an
-dimensional recurrence network is formed by
consecutive state vectors, which can be represented as
, where
. In this study, we chose
. As the white noise series has no attractor structure, its time delay was set to 1, while for other dynamical systems, the time delay was determined by the mutual information method [
29].
According to previous studies [
25,
30], a small distance threshold may be preferable for the construction of recurrence networks from a time series. Because a large threshold may obscure or conceal the local characteristics by over-connecting the nodes, we began the analysis with a relatively small link density by setting
to 0.05.
Figure 2a shows the CCND as a function of the network dimension
. The CCNDs derived from different systems all decreased with the increase of
. This indicates that higher-dimensional recurrence networks are less correlated with the corresponding low-dimensional recurrence networks. Moreover, the CCNDs generated from different types of time series exhibited distinct decreasing patterns. For chaotic series, an exponential behavior was observed between the CCND and
(i.e.,
). The parameter
is an exponential scaling factor, which indicates the rate of decrease of the CCND. It was found that the scaling factor,
, resulting from the folded-towel map, was larger than those from the lkeda map and the Hénon map. In comparison, the CCND resulting from white noise series was smaller than that of the chaotic series, especially for small values of
, and no exponential relationship was observed.
These observations indicate that the dynamic properties of the system under study play an important role in shaping the corresponding network properties. The findings can be explained by the evolutionary processes of different systems. One possible reason for the exponential decrease of the CCND is its dependence on the variation in the number of nearby trajectories of nodes over time. For chaotic systems, it is largely dominated by the characteristic of the exponential divergence of nearby state vectors, so the CCND derived from chaotic series also shows a similar exponential behavior. However, the reasoning is heuristic and not yet supported by some deep theories, which needs further research in the future. The semi-logarithmic plot
can be observed as being approximate to a straight line, with a slope that exhibits a statistical relationship with the largest Lyapunov exponent,
. The largest Lyapunov exponents of time series derived from the lkeda map, Hénon map, and folded-towel map were 0.453, 0.418, and 0.693, respectively, which were calculated by the Time Series Analysis (TISEAN) software (TISEAN 2.1) package [
31]. It is clear that a chaotic series with larger
results in a steeper slope of the CCND because the chaotic series with a larger
is less regular and less predictable, leading to a rapid decrease in the correlation of node degrees between a high-dimensional recurrence network and the corresponding low-dimensional recurrence network. As for white noise series, the process is completely stochastic and unrelated to its previous state. The irregularity and unpredictability imply that there is no statistical relationship between the distance of the two state vectors and the similarity of their evolution trajectories. Hence, the CCND resulting from the white noise series decreased rapidly with the increase of
. It should be noted that the CCNDs derived from different time series tended to saturate for the high-dimensional recurrence network. This is because higher-dimensional recurrence networks change fewer and fewer of the distance values between the nodes [
24], which was also observed in numerical investigations associated with the false nearest neighbor method [
32]. In addition, the saturation behavior observed was also partially the result of the finite sample size.
We then considered the choice of the link density in order to make sure that the constructed networks can truly represent the characteristics of dynamical systems. To study this, we further calculated the CCNDs from different systems by varying
from 0.1 to 0.4, as shown in
Figure 2b–e. It was found that for
, the differences between the curves of CCNDs from various time series were large, which was similar to the case of
. This indicates that the results are robust for a relatively small
. However, if
continues to increase, the curves of CCNDs for different series will approach each other and gradually become difficult to distinguish. This is because, with the increase of
, many nodes that are far away from each other are connected. This results in obscuration or concealment of the evolution properties of dynamical systems [
33]. Therefore, a value of link density
that does not exceed 0.1 is preferable for a feasible analysis of the constructed network.
The effectiveness of the CCND analysis for the evaluation of the evolution properties of dynamical systems was confirmed. We also illustrated that the edge similarity introduced in
Section 2 can further characterize different time series. In
Figure 3a, we show the edge similarities of different
with network dimension
, link density
, and number of groups
. The edge similarities,
, derived from the lkeda map and the Hénon map remained around 1 until
and then decreased rapidly with
, while the edge similarity,
, resulting from the folded-towel map remained at around 1 for
and decreased at smaller
. As for white noise series, the edge similarity,
, was independent of
and remained stable at around 0.681. These interesting results are relevant to the evolutionary processes of different dynamical systems. It is well known that a chaotic map is a deterministic system, with the nature of sensitivity to initial conditions. The short-term evolution of trajectories starting from nearby initial conditions is strongly correlated. Thus, for chaotic systems, close state vectors remain close together for several time steps and the edge similarities for small
are large. In comparison, the trajectories evolving from far away state vectors will decrease in similarity, resulting in small edge similarities
for large
. The edge similarities,
, resulting from the folded-towel map were obviously smaller than those from the lkeda and the Hénon maps for
, because the time series derived from the folded-towel map was more chaotic and unpredictable. As for the white noise series, the evolution was totally random and independent of the previous states, so the edge similarities of different groups were similar.
From the above analysis, it can be seen that the evolution properties of different dynamical systems can be well characterized by the edge similarity. Moreover, the effect of the network dimension,
, on the edge similarity was further evaluated. The edge similarities of different
resulting from various time series with
are shown in
Figure 3b–d, respectively. The edge similarity was found to decrease with an increase of the network dimension,
, because close state vectors diverge quickly over time as a result of the randomness of the studied dynamical systems. For chaotic series, the edge similarities of smaller
remained relatively large for higher-dimensional recurrence networks, because state vectors with smaller distances were more similar during the evolutionary process and their trajectories remained close for a longer period of time. As for white noise series, the edge similarities of different groups decreased to a similar extent with the increase of
. The distance threshold
of the
-dimensional recurrence networks from white noise series corresponding to
is equal to the maximum distance of the nearest
pairs of sampling data, where
and
denotes the largest integer no more than
. The edge similarity of white noise series for the network dimension,
, can then be represented as
. Thus, for
, the edge similarities resulting from the white noise series were around 0.681, 0.518, 0.422, and 0.359, respectively. According to
Figure 3, the distinctions of edge similarities between chaotic time series and white noise time series were maintained when
changed from 2 to 5.
It should be noted that the results shown above were dependent of the number of groups,
, so the choice of this parameter needs to be studied carefully. As introduced in
Section 2, the edge similarity was proposed to study the relationship between the distances of the connected state vectors and the similarity of their evolution trajectories. The aim of the grouping is a simplification of the distances between connected state vectors. It is clear that increasing the number of groups,
, leads to the increase of the resolution of edge weights (i.e., the distances between connected state vectors). However, because of the finite sample size, the number of edges in each group deceases in accordance with the increase of
, which may cause a large statistical fluctuation in the edge similarity. Considering that the edges in adjacent groups have similar weights, the edge similarities of adjacent groups were also supposed to be similar. In this study, we defined the maximum fluctuation (MF) of edge similarities for neighboring edge groups as follows:
The choice of
should make the value of MF small, which indicates that there is a higher resolution of the edge weights and a small statistical fluctuation in edge similarities.
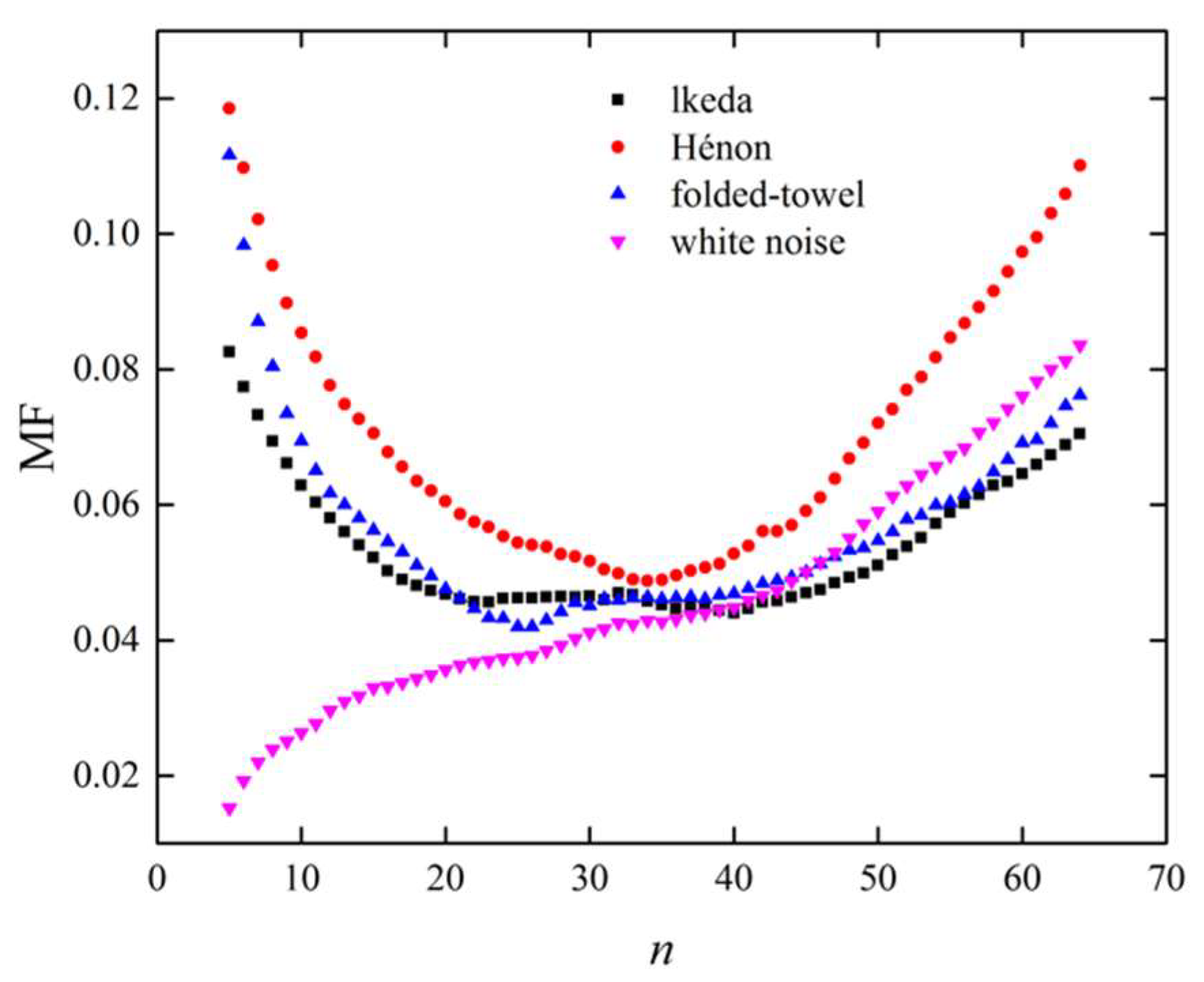
Figure 4 shows the MFs derived from different time series as a function of
with sample length
, network dimension
, and link density
. For the chaotic series, the MFs decreased rapidly when
increased from 5 to 20. This is because the edges in adjacent groups tend to have greater similarity in weight with the increase of
, leading to a smaller difference of edge similarities between adjacent groups. In the range
, the MFs resulting from chaotic series were stable at a relatively small value. The small difference of edge similarities between adjacent groups indicates that the resolution of edge weights was relatively high. However, when continuing to increase
, the MFs increased. This is because a large
causes a decrease in the number of edges in each group, which leads to increased statistical fluctuations. As for the white noise series, the MF increased monotonously with
. This is because the edge similarities in different groups are similar and increasing
simply leads to fewer edges in each group, which results in larger statistical fluctuations. According to the results shown in
Figure 4, it was concluded that the number of groups,
, should be set at
—where the MFs derived from different time series exhibited relatively small values.
Because empirical data were contaminated by noise, in this section, we also studied the robustness of the proposed method against noise by analyzing the chaotic series corrupted by white noise. The corrupted signal,
, was formed by the composition of the normalized time series,
, and Gaussian white noise,
, i.e.,
, where
is the mean,
is the standard deviation, and
is the noise level. We numerically studied the variations in the CCND with
under different noise levels,
, by fixing
. The results for the lkeda, Hénon, and folded-towel maps are shown in
Figure 5a–c, respectively. When the noise level,
, was lower than 0.1, the variations in the CCND as a function of
were similar to those derived from the time series without noise and the exponential behaviors between the CCND and
were maintained when the noise level,
, was less than 0.2. However, when the noise level increased to 0.3, the corresponding topological structures of networks were distorted from the original series and the exponential relationships were weakened. This is because high levels of noise obscure the dynamic characteristics of chaotic systems, which causes the decline patterns of CCND derived from the chaotic series to approach that obtained from the white noise.
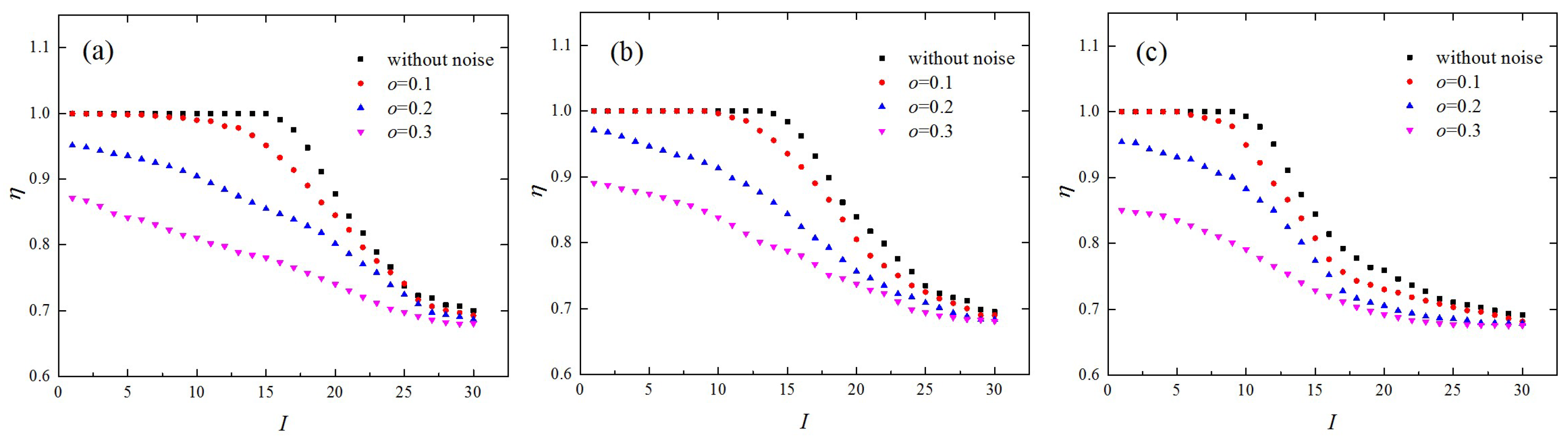
The influence of noise on the edge similarity was also evaluated.
Figure 6 depicts the edge similarities derived from different chaotic maps in the presence of various levels of noise, where the network dimension was set as
and the link density was set as
. With the increase of
, edge similarities in different groups decreased, especially for small values of
. The edge similarities generated from the lkeda map and the Hénon map without noise were about 1 for
, but they decreased to below 0.9 when the noise level,
, increased to 0.3 (
Figure 6a,b). As for the folded-towel map, the edge similarities for
had large values when
and decreased to less than 0.86 when the noise level,
, increased to 0.3 (
Figure 6c). This was because two state vectors that are nearby in phase space may become distant from each other for the next time step because of the influence of Gaussian white noise. However, there remains an obvious dependence of the edge similarity,
, on the group index,
, in the presence of noise with level
, which is distinct from a white noise series.
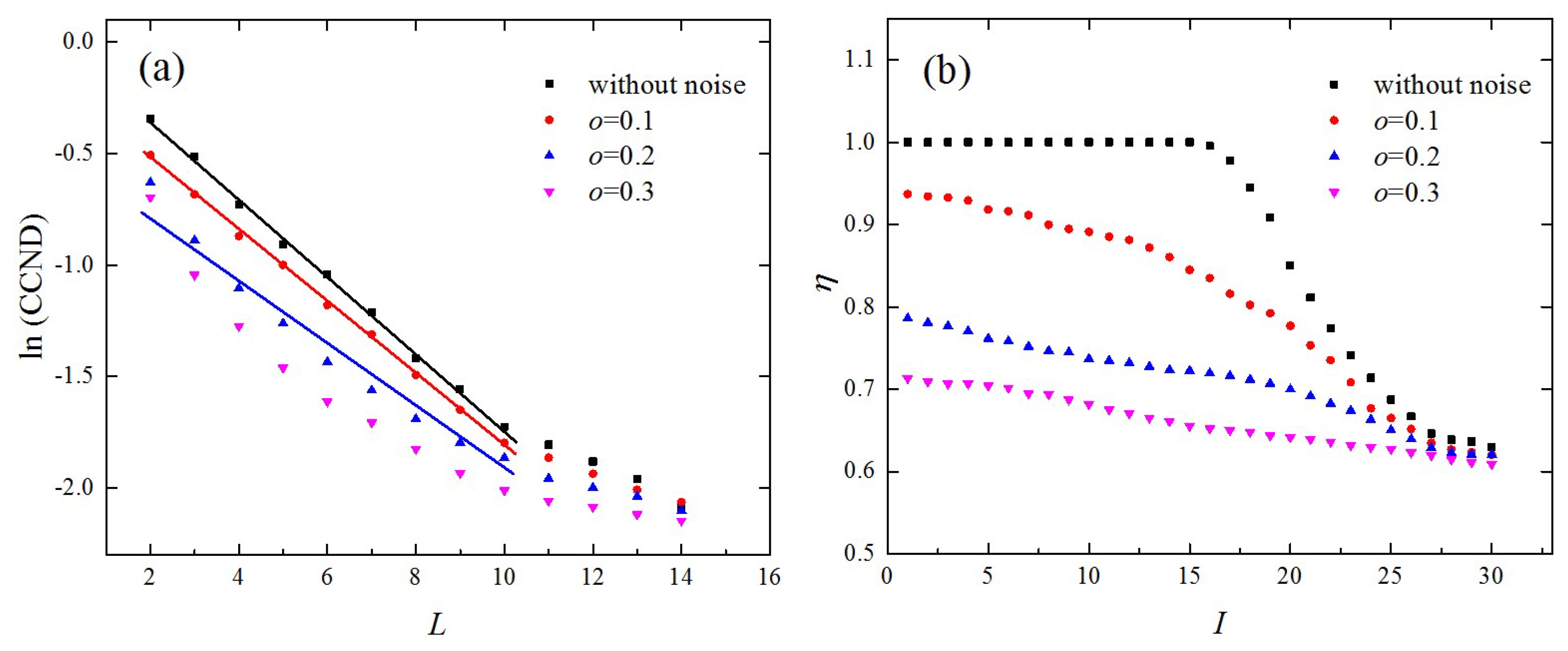
We also studied the robustness of the CCND and edge similarity against noise with
. The time series from the lkeda map was used as an example and the results are shown in
Figure 7. According to
Figure 7a, although the exponential behavior between the CCND and
was maintained for noise level
, the variations in the CCND as a function of
deviated obviously from those without noise. When
further increased to 0.2, the exponential relationship weakened and no exponential behavior was observed for
. The edge similarity,
, as shown in
Figure 7b, decreased significantly with the increase of
. When
increased to 0.3, the edge similarities were small even for small values of
. From
Figure 5b,
Figure 6b, and
Figure 7, it can be seen that both the CCND and edge similarity with
were more sensitive to noise compared with those of
. This is because when choosing a small link density, the connections between nodes are more easily affected by noise. Therefore, the proposed topological statistics are more robust under additive noise when the link density,
, is set to 0.1.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








