1. Introduction
Fractional-order systems incorporating fractional-order derivatives (or differences) have attracted considerable research interest as their specific nature can be more adequate to describe some complex physical phenomena [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13]. Since the fractional-order derivative is not defined at a point as in the case of its integer-order counterpart, impulse responses of fractional-order systems are not, in general, a class of exponential functions. In addition, a fractional-order derivative affects the properties of the system in the frequency domain. This is due to the fact that the modulus characteristic of a derivative of the fractional order
is increased by
dB per decade instead of 20 dB per decade for the integer-order derivative, whereas the phase characteristic is equal to
. Therefore, the dynamic properties of the fractional-order system are more adjustable than for integer-order systems and can be more accurate in modeling various physical processes involving electrical circuits [
4,
6], thermal and diffusion processes [
14,
15], medicine [
8,
16], and others [
17,
18,
19,
20]. Among them, a lot of interest has been devoted to fractional-order generalizations of various entropy definitions and functions, i.e., Rényi entropy [
11,
21], Tsallis entropy [
11,
22], etc. The fractional generalizations of entropy definitions have led to different probability distribution functions as compared with the Shannon entropies [
5]. However, the main problem encountered in the fractional-order systems is the fact that calculation of fractional-order derivative/difference may lead to computational problems. Namely, the Grünwald-Letnikov (GL) fractional-order derivative/difference, which is considered here, may lead to computational explosion related to the infinite summation. That is why truncated or finite-length implementation is used in approximators to the fractional-order derivative/difference [
3,
10]. Still, high modeling accuracy requirements often end up with high (upper) summation limits, which may be computationally burdensome for a single-core application. In spite of this, there is little discussion about using the multi-core architectures in calculations of fractional-order derivatives/differences. Therefore, the fractional-oriented parallel implementation issue is the main motivation for this paper.
Recently, trends in the development of more powerful computing hardware have focused on increased numbers of cores rather than the increased performance of an individual unit. For this reason, parallel computing has emerged as a research domain with the capability of meeting time requirements in both real-time applications and offline simulations. Despite the increased difficulty of coding, parallel programming has become very popular due to the ever-growing computational scale [
23,
24].
There are some papers considering the parallelization process for the fractional-order derivative/difference and fractional-order systems. In [
25], a parallel computing application has been proposed for calculation of the Caputo derivative by use of the Adams–Bashforth–Moulton method. That method is extended to modeling of the fractional-order state-space system in [
26]. Another approach for solving the Caputo derivative problem in the specific fractional-diffusion equation has been presented in [
27], with a parallel algorithm based on linear tridiagonal equations. Yet another example is the use of parallel computing for solving nonlinear time-space fractional partial differential equations [
28]. In that case, the authors have studied the efficiency of parallelizations for shared and distributed memory systems.
In this work, we use two strategies for parallel calculation of fractional-order state-space systems, the Grünwald-Letnikov derivative and the fixed-step discretization scheme. The first one is the use of a Central Processing Unit (CPU) with OpenMP (OMP) Application Programming Interface (API) [
29]. The second one incorporates a Graphical Processing Unit (GPU) with Compute Unified Device Architecture (CUDA) API.
OMP is a set of compiler directives, library routines, and environment variables enabling shared-memory parallelism. With minimum latency, each thread or process can have direct access to memory throughout the system. It can be used to develop applications in programming languages C, C++, and Fortran on many platforms including Solaris, AIX, HP-UX, Linux, macOS, and Windows. OMP is supported by major computer hardware and software vendors, and is characterized by high-level parallelism, portability, scalability, and simplicity of use.
CUDA is an API developed by Nvidia Corporation. The CUDA platform (Nvidia Corporation, Santa Clara, CA, USA) is a software layer that provides a dramatic increase in computing performance by using the power of CUDA-enabled GPUs. It is designed to work with programming languages such as C, C++, and Fortran. In contrast to APIs like Direct3D and OpenGL, which require advanced skills in graphics programming, CUDA makes it easier for specialists to use GPU resources by use of virtual instruction set and parallel computational elements. It also supports programming frameworks such as OpenACC and OpenCL.
The paper is organized as follows. Having introduced the problem in
Section 1, representations of the fractional-order derivative/difference and the fractional-order state-space system are presented in
Section 2.
Section 3 gives an introduction to the different parallel architectures that are considered in this paper. The detailed description, pseudo-code, and implementation method for the used parallel algorithms are also presented in
Section 3. Simulation examples of
Section 4 provide a comparative analysis of the introduced algorithm approaches as well as presented architectures. The analysis is accomplished in terms of high modeling accuracy and high time efficiency. Conclusions in
Section 5 complete the paper.
2. Preliminaries
Consider a continuous-time linear time-invariant (LTI) state-space fractional-order system described by the following equations:
where
,
,
, and
are the system matrices;
and
are the number of inputs and outputs, respectively;
t is the continuous time; and
is the matrix
consisting of a fractional-order derivative
of order
,
. The system (
1) is commonly considered in a simplified commensurate fractional-order form, where the fractional-order
,
. In this case,
denotes a fractional-order derivative of order
. The fractional-order state-space system (
1) is one of the most popular methods used to describe fractional-order processes. By using Equation (
1), we can present fractional-order differential equations in a simple, matrix/vector form. Therefore, we can find many uses of the state-space system (
1) in practical applications, e.g., in electrical circuits [
4,
6], in modeling of thermal and diffusion processes [
12,
13,
15], in medicine [
8,
16], etc.
The fractional-order derivative is often described by using one of three definitions, that is, the Riemman-Liouville (RL), Caputo, or Grünwald-Letnikov (GL) definitions. Regarding the practical implementation point of view, in this paper, we use the Grünwald-Letnikov derivative defined as
where
∈
,
h is the sampling period,
denotes the Gamma function and
,
, are the Newton binomial coefficients. Taking into account poor numerical feasibility of the Gamma function, we use the definition as in Equation (3). The GL definition is equivalent to the RL definition discretized by the use of the fixed-step discretization scheme. Additionally, in the case of homogenous initial value, the GL is equivalent to the Caputo definition. Moreover, by using specific correction coefficients, we can easily calculate the Caputo derivative by the use of the extended GL definition [
30]. Therefore, the GL derivative based on finite length implementation can be used as the approximation of the Riemann–Liouville and Caputo derivatives. The main advantages of the GL definition are (1) they can be easily calculated in the recursive way, by using robust and numerically stable algorithms; and (2) an error of the finite-length GL approximation can be easily calculated, both for fractional-order difference/derivative and for the whole fractional-order system [
31]. The main disadvantage of the finite-length GL is a low convergence rate. A detailed analysis of the effectiveness of finite-length GL as compared to other approximation methods can be found in [
32]. In the literature, we can find several other definitions of fractional-order derivatives/differences [
15,
18,
32]. In particular, He’s derivative is shown to provide a good numerical performance in specific applications [
12,
15]. Analysis of the state-space system using this definition will be a topic of our further work.
In order to solve the system (
1) incorporating the GL derivative (3), a typical way is to use the simple fixed-step Euler method for calculation of fractional-order equation. Assuming that
, we obtain
or using a discrete-time formulation for
where
is the state vector defined in discrete time
k and
denotes the discrete-time fractional difference
with
∈ (0,2),
being the backward shift operator and
Note that the Newton binomials can be calculated by use of the simple, well-known formula
Usually, in the fractional-order state-space systems, we use a forward-shifted form of the fractional-order difference (see e.g., [
7]).
Combining Equations (
6) and (
9), we obtain the formula for calculating a fractional-order discrete-time state equation:
Note that each incoming sample of the signal
increases the complexity of both the fractional-order difference (Equation (
11)) and the whole fractional-order system (Equations (
9) and (
10)). This leads to the computational explosion for
. To avoid this, a finite-length version of the fractional-order difference is used (see e.g., [
7,
10,
33])
where
L is the upper bound for
j.
Now, combining Equations (
9) and (
12), we obtain the finite-length formula for calculation of the state equation
It is important to note that the results presented in Equations (
12) and (
13) for
define the approximations of the fractional-order difference and fractional-order state-equation, respectively.
Problem formulation: It is important that convergence of the series
depends on the order
and is quite slow, in particular for a low value of
. Therefore, accurate approximation of Equation (
5), and consequently Equation (
12), requires a very high implementation length
L. Exemplary norm
, where
is the Heaviside step function, is
, but to obtain the similar accuracy for
we need as high a length as
L = 2,000,000 (i.e.,
h(0.3, 2,000,000) = 0.01). Moreover, implementation of the fractional-order difference into the state-space system may require much higher
L to obtain the same accuracy [
31]. Therefore, real-time applications of both fractional-order difference and fractional-order state-space system for ’fast’ systems (with small sampling periods
h) may require realization of the parallelization scheme for the calculation process.
4. Simulation Examples
In this section, we present the implementation results of parallelization methods both for the fractional-order difference and the fractional-order state-space system. For analysis, the CPU- and GPU-based hardware environments have been used.
In simulation experiments, we consider the fractional-order state-space system
as follows:
with both the fractional-order difference and fractional-order system excited by the Heaviside step function
.
4.1. CPU-Based Hardware
In case of calculation on the CPU-based hardware, numerical simulations are carried out on a computing node equipped with the Ubuntu
(Canonical Ltd., London, UK) operating system and an Intel Xeon E5−2650 v3 CPU (Intel Corporation, Santa Clara, CA, USA) with a basic frequency of 2.3 GHz. The hardware system offers 10 physical cores (20 threads based on the hyperthreading technology). During the simulations, we use one thread per physical core only, since the hyperthreading technology is not suitable in our task (see [
34,
35]). All the calculation algorithms in this subsection are implemented by use of the C++ programming language and the OMP library. The OMP library is based on the shared memory concept, therefore, explicit data distribution techniques are not desirable in this case. For evaluation of parallelization efficiency, solely the simulation times have been taken into consideration because all the methods provide the same calculation results.
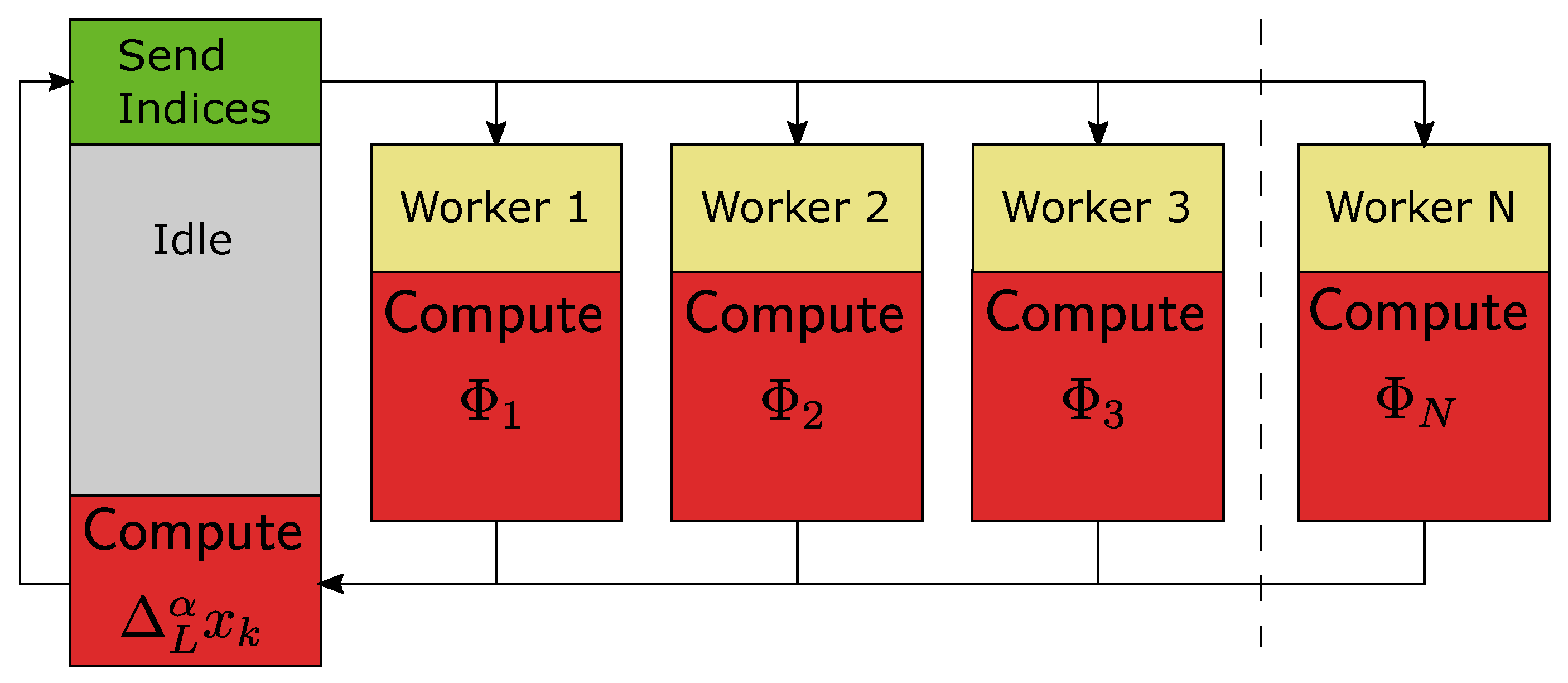
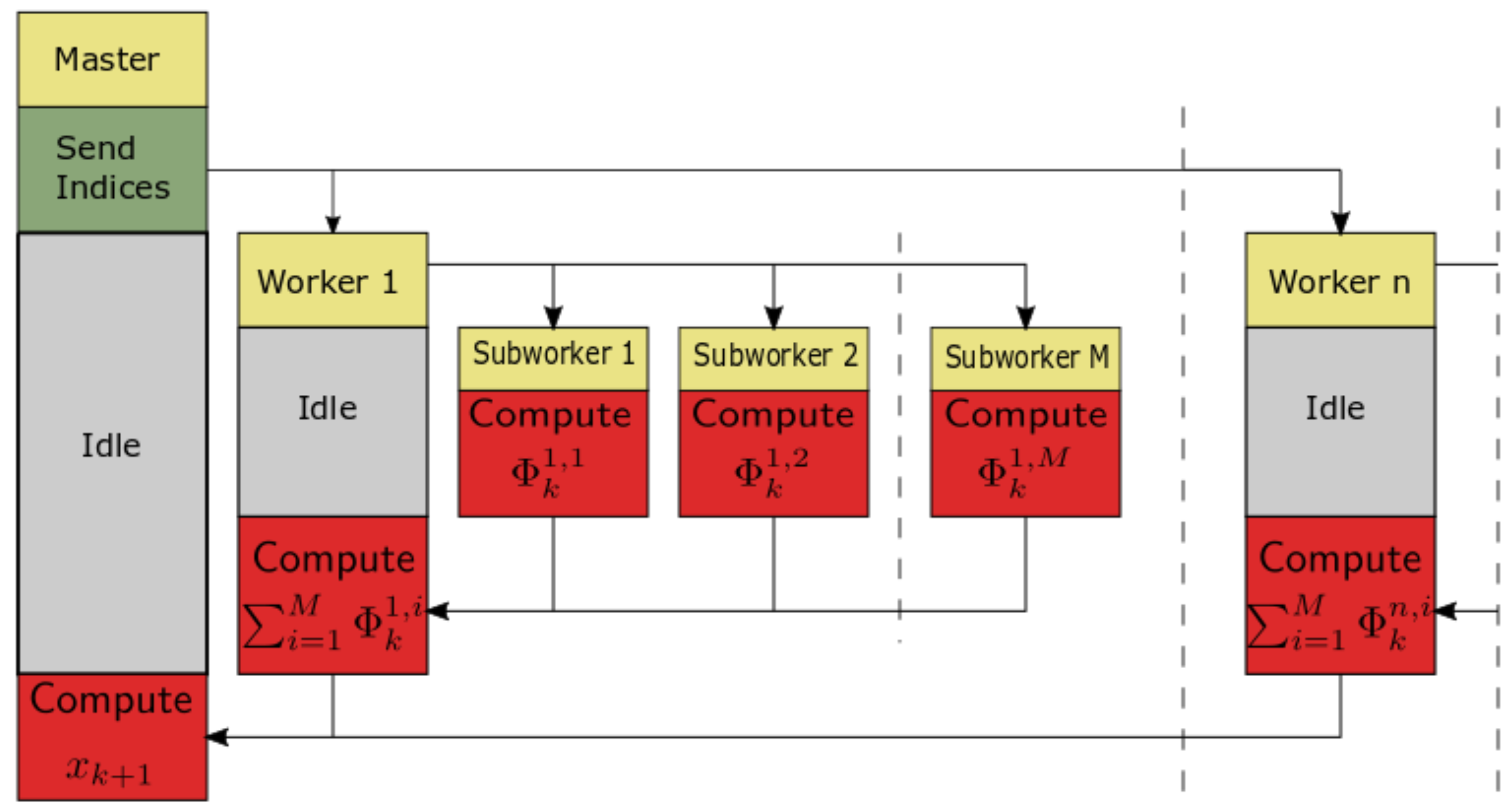
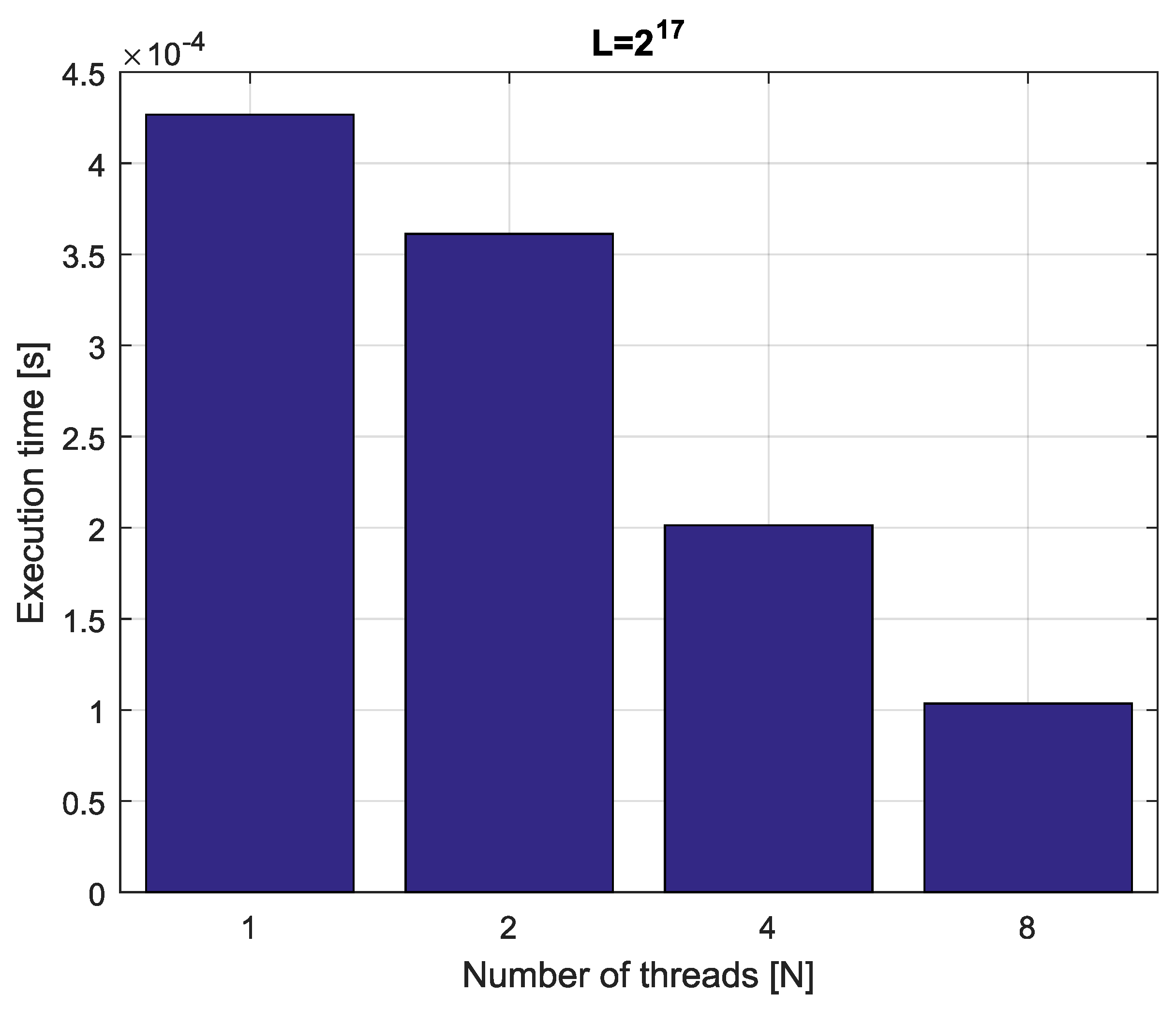
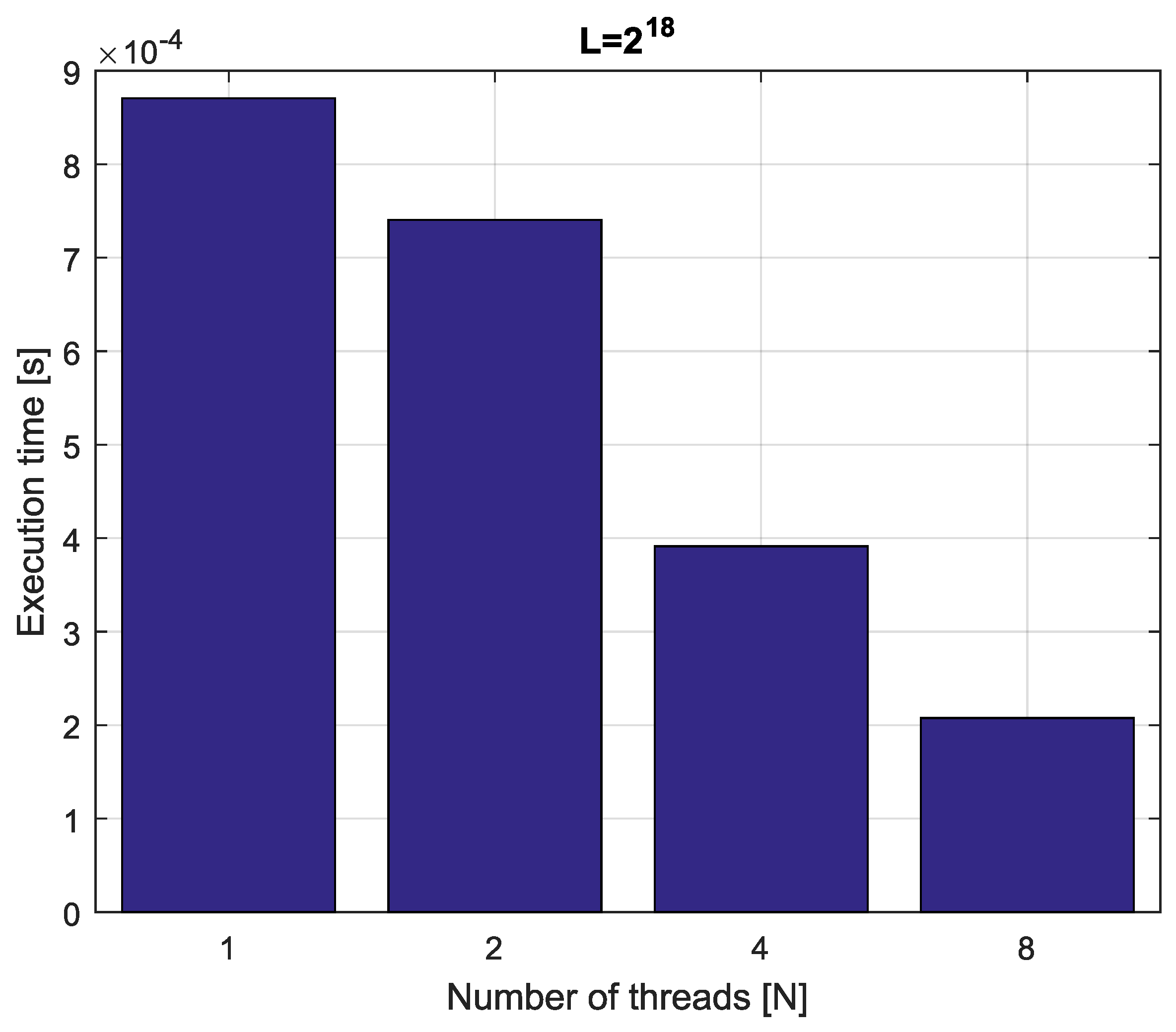
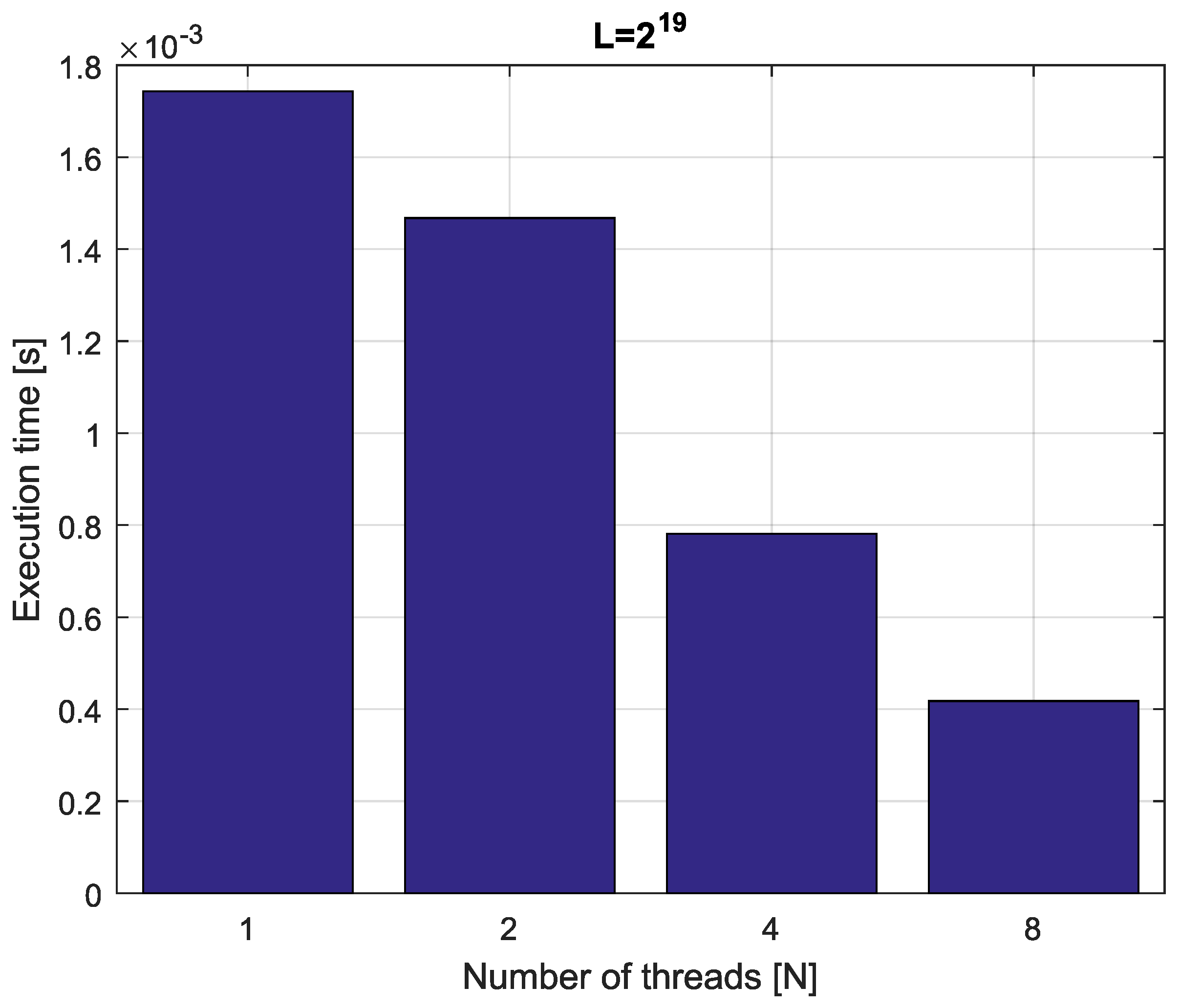
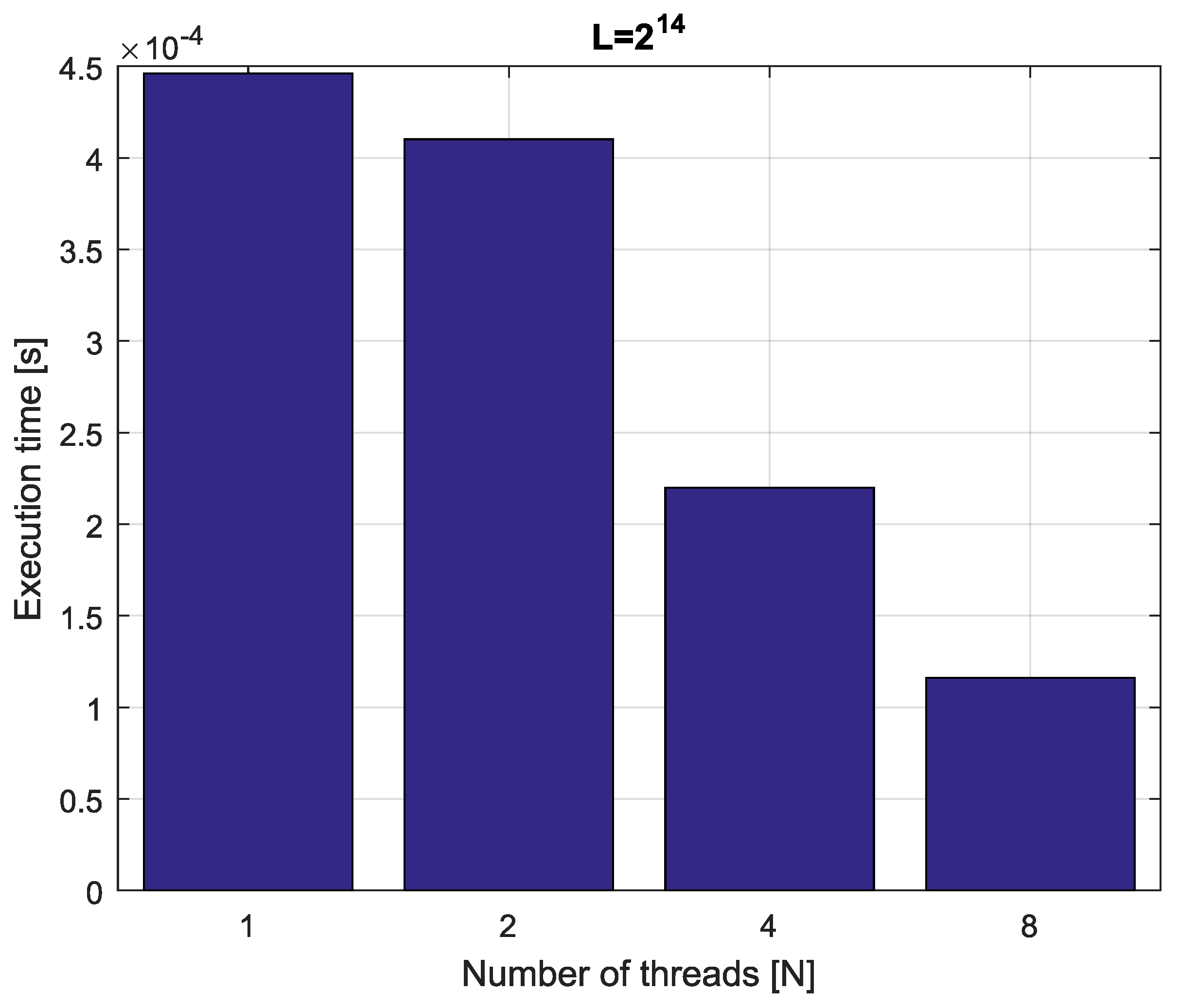
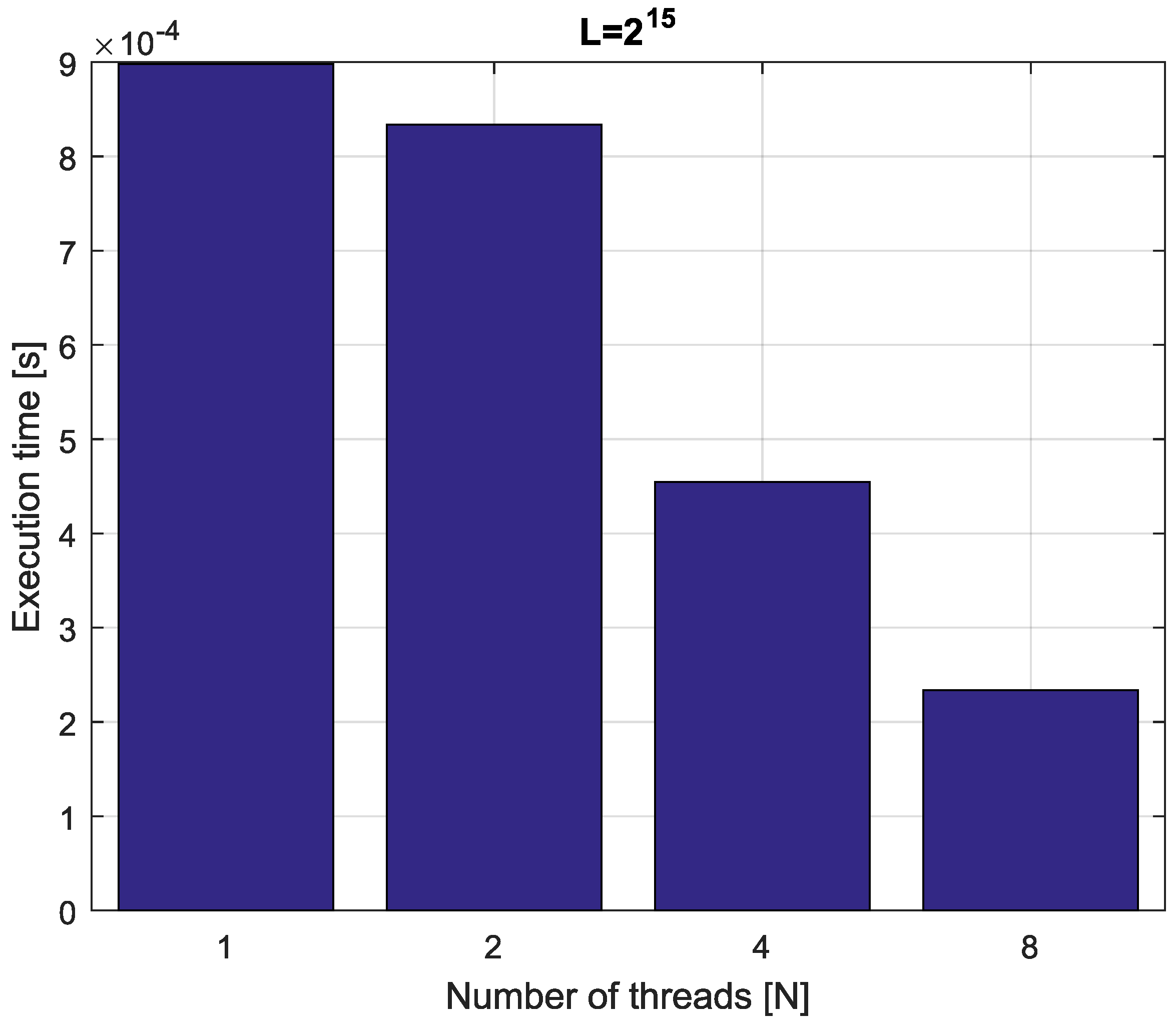
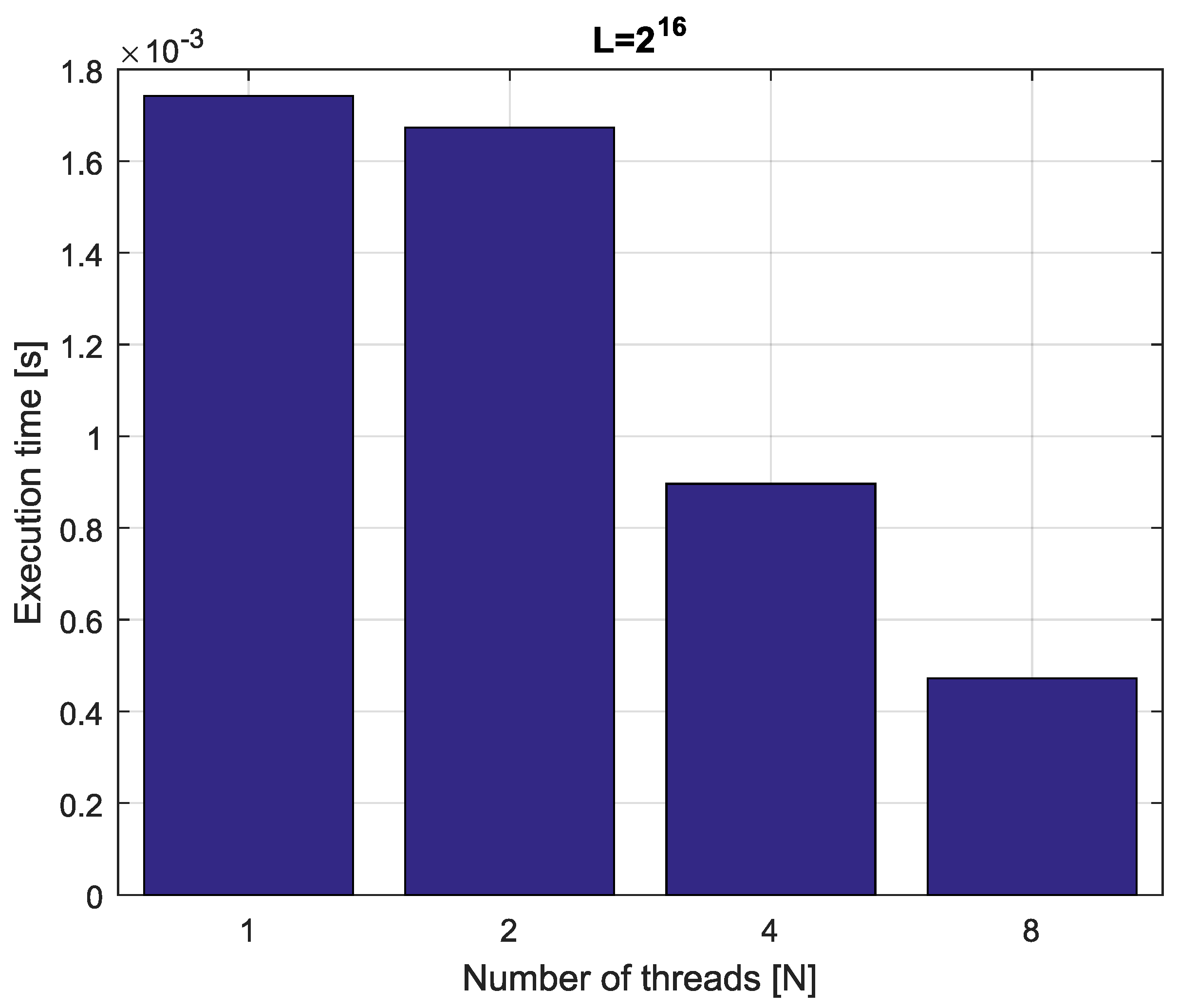
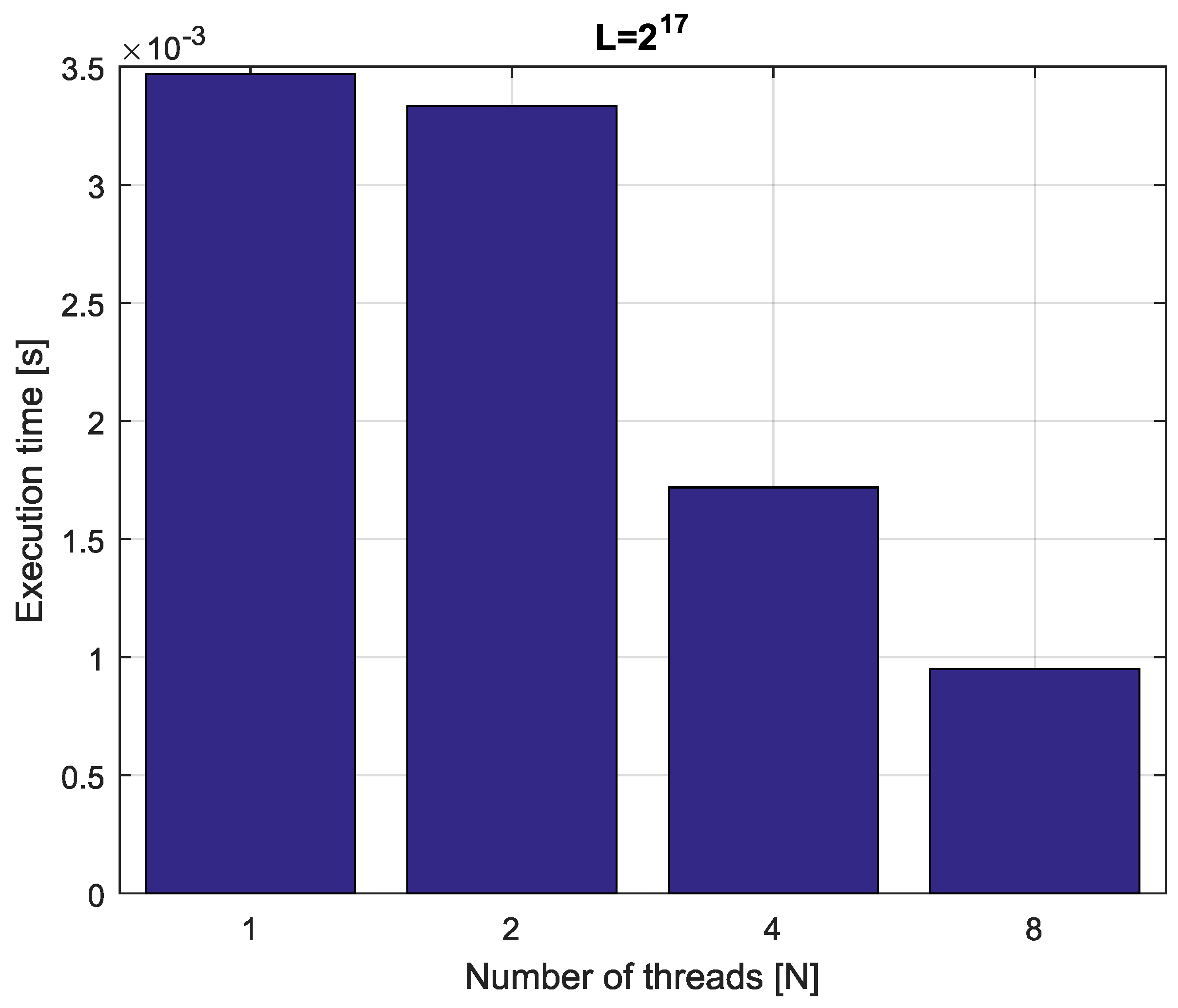
Example 4. Consider fractional-order difference (12) with . The difference is implemented by use of the parallelization Algorithm 1. The simulation times for various implementation lengths and various numbers of cores are presented in Figure 3, Figure 4, Figure 5 and Figure 6. As we can see in Figure 3, Figure 4, Figure 5 and Figure 6, the parallelization process decreases execution times of the one-step calculation process for fractional-order difference. The speedup for 8 cores varies from for to for . So, the acceleration is similar for the considered lengths. Example 5. Consider the fractional-order state-space system presented in the introduction of Section 4. The system is calculated by the parallel scheme introduced in Algorithm 2. The calculation process is executed in CPU-based hardware for implementation lengths . Results in terms of execution times for number of cores are presented in Figure 7, Figure 8, Figure 9 and Figure 10. We can see from Figure 7, Figure 8, Figure 9 and Figure 10 that, again, the parallelization process decreases execution times of the one-step calculation process for the fractional-order system. The speedup for 8 cores in this case varies from for to for . This means, again, that the effectiveness of the parallelization is similar for the considered lengths. We compared results obtained by the introduced methodology with time effectiveness of model implementation in the Matlab environment. In the case of using a single-core method, we obtain times from for to for , therefore, the times are significantly higher than in the case where the OpenMP environment is used. Moreover, the implementation of parallel computing by the use of Parallel Computing Toolbox increases calculation times compared to a single-core approach. This is a result of the specific construction of CPU-based parallelization methods in the Matlab environment.
4.2. GPU-Based Hardware
In the case of GPU-based implementation, we use hardware with two Tesla K80 (Nvidia Corporation, Santa Clara, CA, USA) accelerators with a dual-GPU design that consists of 4992 Nvidia CUDA threads, 24GB of GDDR5 memory, 480GB/s aggregate memory bandwidth, and up to 2.91 teraflops of double-precision operations. Accelerators operate on a computing node equipped with the operating system Windows Server 2012 R2 (Microsoft Corporation, Redmond, WA, USA) and an Intel Xeon v3 CPU (Intel Corporation, Santa Clara, CA, USA) with a basic frequency of GHz. In contrast to OMP, CUDA does not support globally shared memory, so data distribution and memory allocation must be performed manually by proper data transfers between all processing units. CUDA enables the overlapping of some operations without losing much performance, but still, improper management of data distribution can result in poor time results. CUDA GPUs have many parallel processors grouped into Streaming Multiprocessors (SMs), creating a grid of threads arranged within blocks. Each SM can run multiple concurrent thread blocks. Tesla K80 GPU can support up to 1024 active threads in one working block. To take full advantage of all these threads, the program code must be executed with multiple thread blocks.
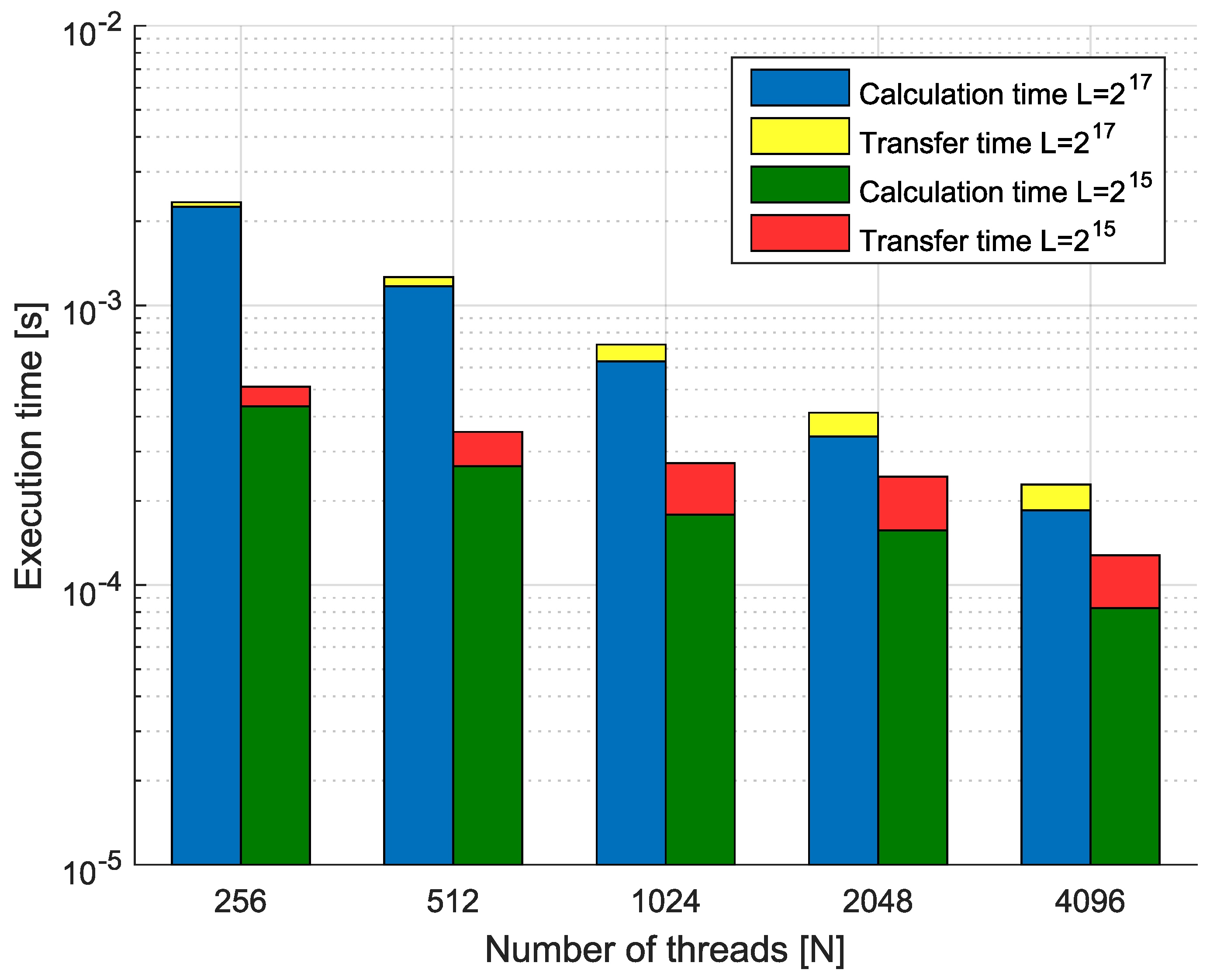
Example 6. Consider the fractional-order state-space system presented in the introduction of this section. The system is calculated by use of parallelization Algorithm 3. Times of the one-step calculation process for implementation lengths and various numbers of cores are presented in Figure 11. Moreover, Figure 11 presents data transfer times (red and yellow) and execution times (blue and green). We can see that in the case of using GPU-based hardware and Algorithm 3, we obtain an effective tool for the distributed calculation of the fractional-order systems. For instance, increasing the number of processors 16 times (from 256 to 4096) for implementation length leads to speedup . In contrast, for in the same case, we obtain . Therefore, the parallelization process is much more effective for longer implementations of fractional-order systems. Additionally, we can see that the data transfer times are longer for high numbers of threads, but are still relatively short compared to the times of calculation.
Again, we compared the effectiveness of the proposed methodology with implicit GPU-support tools in the Matlab Parallel Computing Toolbox. Finally, we obtain execution times from for to for . The times are higher in the case of the use of 256 workers for the hierarchical parallelization scheme introduced in the paper. Taking into account that Matlab is a high-level environment, where GPU-support is based on the same CUDA software as we use in our implementation, we can see that the Matlab parallelization algorithms are visibly less effective than for those considered in the paper.


{kind=link}
{kind=link}
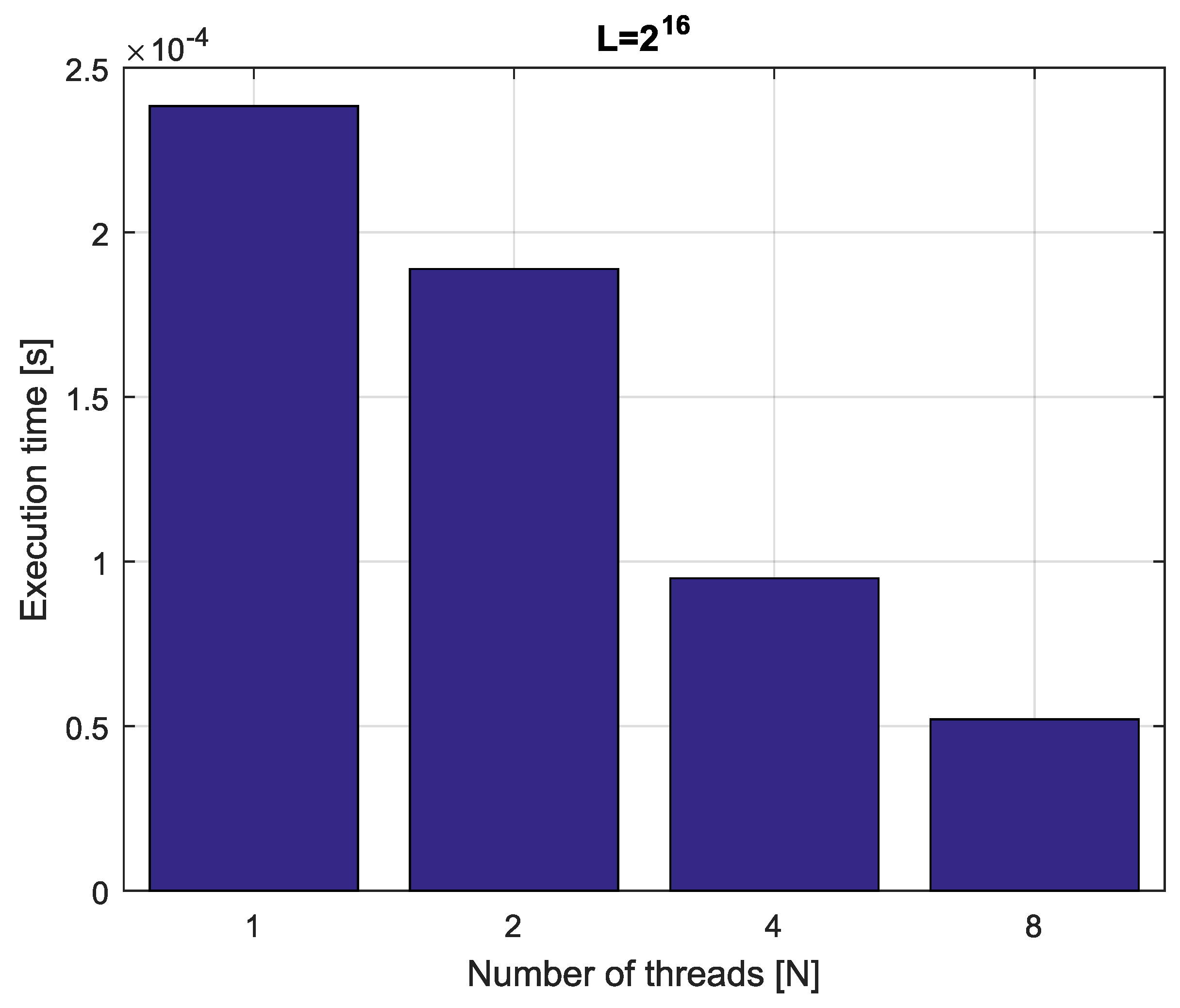{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













