1. Introduction
Text mining is one of the distinguished fields of data mining which possesses the potential to extract useful information from raw data. In a world where 2.5 quintillion bytes of data are generated every day, text mining has become a key tool to retrieve meaningful data and organize them into profitable information [
1,
2]. Text classification is becoming a prominent field of research in text mining, especially after the inception and penetration of social platforms such as Facebook, Twitter, etc. People express their views on such platforms and their opinions serve as the guideline to design and govern the policies of various companies. For example, the tweets can be analyzed to find the sentiments of the users about a specific company or product, which helps to devise policies to increase the acceptance of products or improve user services. The wide use of such social platforms leads to generate many data that contain a variety of potential information.
The last few years have witnessed a growing interest in social network databases due to their richness and versatility. One iconic use of such data is to analyze user sentiments about a particular product or company. Such analysis of user sentiments from text is called “
sentiment analysis’ [
3]. Sentiment analysis is a famous method that is used to extract people’s reactions, opinions, reviews and feedback towards a specific product or service of a company. The user feedback on social platforms serves two broad purposes. First, the companies can model policies to attract new potential customers and revise the existing policies to increase the acceptance of their products/services based on sentiment analysis. For example, Rainie and Horrigan [
4] pointed out that US presidential campaigns are planned according to the political reviews analyzed from Twitter data. In the same way, sentiment analysis is important for different companies to analyze customer reviews about products and make better decisions for the future [
5,
6]. Second, online reviews about various products and services have a significant influence on purchase trends [
7]. Horrigan [
8] pointed out that consumers are willing to pay more for a specific product which has a five-star rating than one that has a four-star rating.
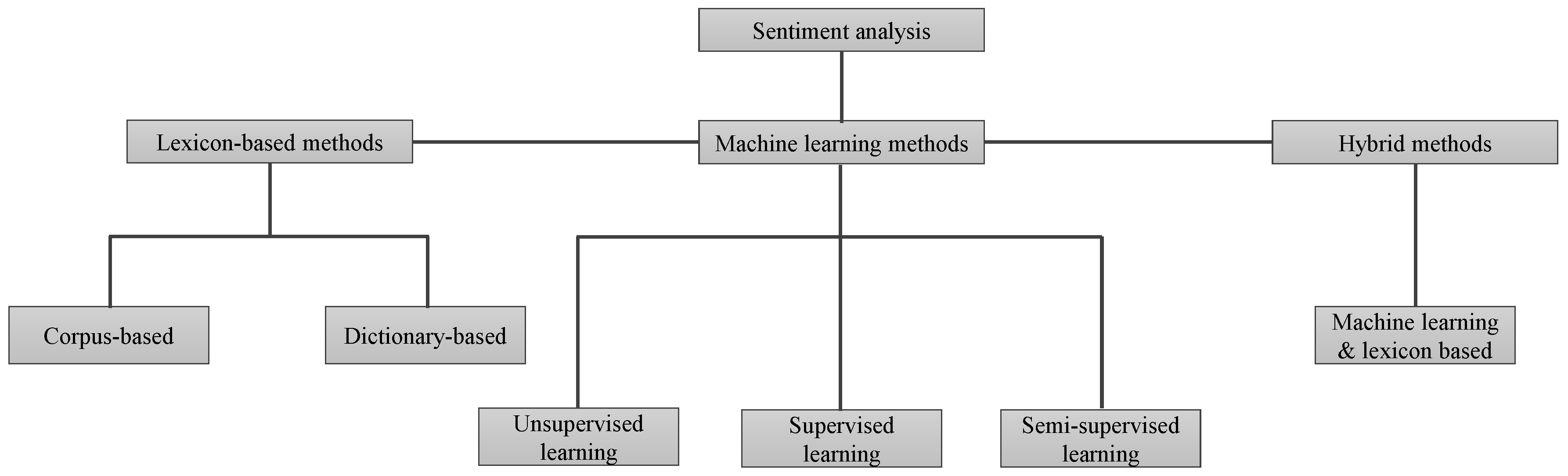
Sentiment analysis can be divided into lexicon sentiment analysis technique, machine learning-based sentiment analysis, and hybrid methods [
9], as shown in
Figure 1. Lexicon sentiment analysis mainly works on the polarity of tokens (words) in a sentence. A lexicon is a dictionary or a container that contains a large set of standard words that are categorized based on the polarity score. However, most people use very informal words in reviews that are not present in lexicons. Therefore, researchers emphasize applying alternative techniques for sentiment detection in the text. Hence, the second category utilizes machine learning approaches for sentiment analysis. Models can be trained on a sample dataset and later can be used to perform predictions on a different dataset. The problem is formulated as a classification task, for example, a document can be represented by a set of features [
5]. After that, these documents are labeled based on the polarity (i.e., positive, negative, or neutral), and converted into a feature matrix. In this way, machine learning approaches give better performance than that of lexicon-based method to detect sentiments [
10].
The competition has been rising in every domain of life and airlines are no exception. They aim to generate more revenue by improving offered services and devising new schemes and policies for the future. Social networks play a very important role in such improvements, as the customer’s reviews serve as the feedback to such companies. Customers’ reviews are analyzed based on the expressions given in the reviews. The volume of such reviews is very high and it requires a large number of experts for analysis and classification. Thus, a variety of machine learning classifiers have been proposed which can help mitigate human effort to classify these reviews. However, improvements are still necessary to further increase the classification accuracy. This research proposes the use of a voting classifier to this end and aims to evaluate the performance of famous machine learning classifiers on a number of twitter datasets. This research serves the following key contributions:
Machine learning-based classifiers including calibrated classifier (CC), support vector classifier (SVC), AdaBoost (ADB), decision tree classifier (DTC), Gaussian naive Bayes (GNB), extra trees classifier (ETC), random forest (RF), logistic regression (LR), stochastic gradient descent classifier (SGDC), and gradient boosting machine (GBM) are trained on US airline twitter dataset.
A voting classifier (VC) is devised to perform tweets classification which is constituted by LR and SGDC.
Complete and partial pre-processing schemes are adopted to evaluate the impact of pre-processing on models’ classification accuracy.
Tweets are classified as positive, negative, or neutral and the results are compared against the actual classification to evaluate models’ performance.
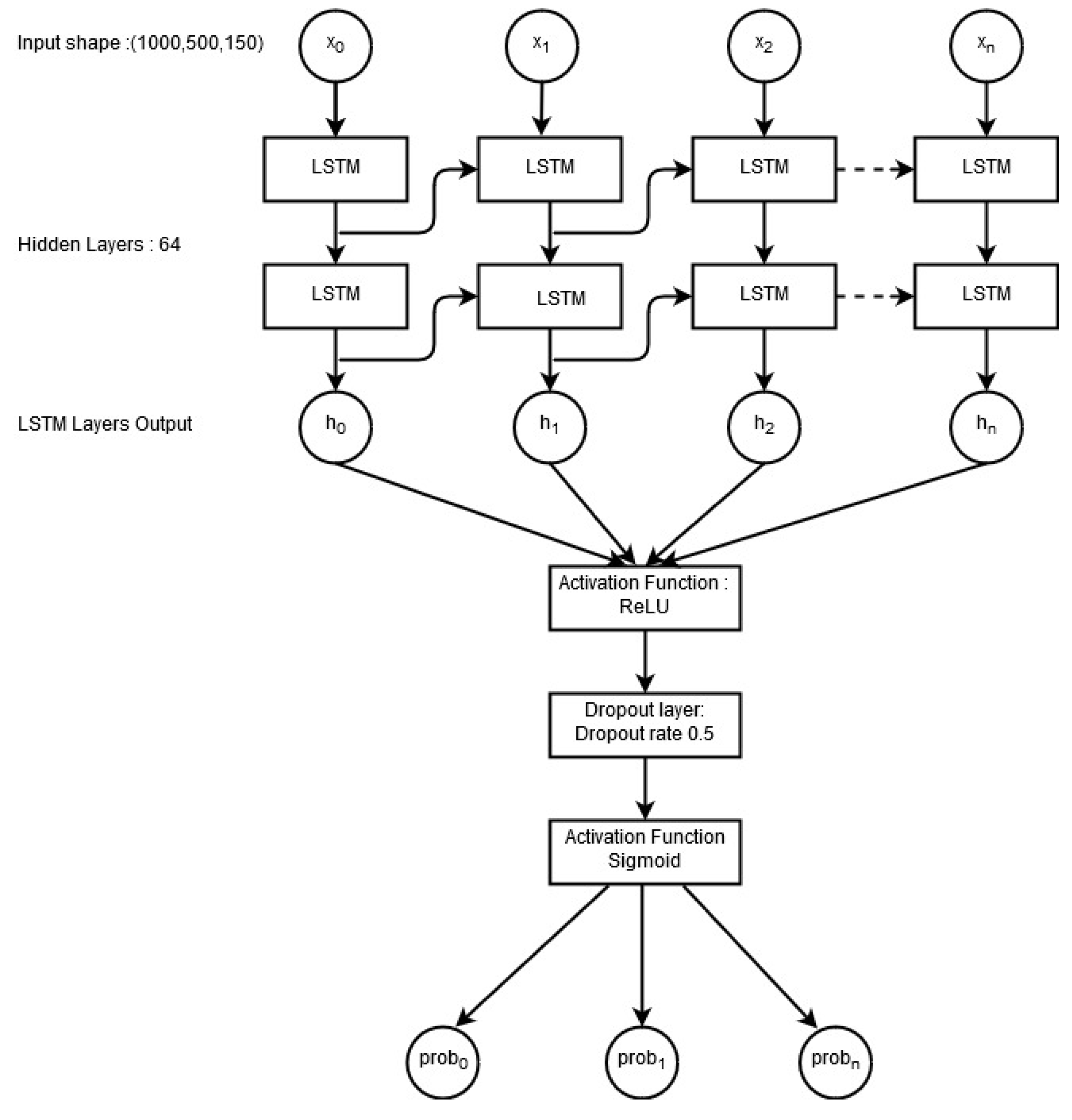
A deep learning long short-term memory (LSTM) network is implemented as well to analyze its performance on the selected dataset.
The rest of the paper is organized as follows.
Section 2 describes a few pieces of research related to the current study.
Section 3 gives an overview of the methodology adopted for the current research as well as a description of the dataset used for the experiment. Results are discussed in
Section 4 while the conclusion is given in
Section 5.
2. Literature Review
The area of text classification possesses a huge potential to analyze sentiments and many researchers have investigated the process of sentiment analysis by detecting emotions found in the text [
11,
12]. Others have proposed sentiment evaluation methods that are formulated by observing human responses to a certain experience [
13]. The use of machine learning techniques including naïve Bayes (NB), maximum entropy (ME), and support vector machines (SVM) for sentiment classification has also been studied [
14]. For example, the authors of [
15] applied NB, ME, and SVM on the Internet Movie Database (IMDb), which consists of movie reviews expressed either with stars or in numerical values. The approach is evaluated using accuracy and recall measures. This work has served as a baseline for many authors and the same techniques have been utilized across different domains.
Similarly, the authors of [
16] performed sentiment analysis on travelers’ feedback about airlines. The authors found that the feature selection and over-sampling techniques are equally important to achieve refined results. Feature analysis is performed to select the best features which not only improves the overall performance of the model but reduces the training time as well. In addition, the skewed distribution of the classes found in most of the smaller datasets is reduced without causing over-fitting. The results of the research show the compelling evidence that the proposed model has a higher classification accuracy when predicting the three classes of positive, negative, and neutral. The authors of [
17] followed a similar approach and performed a multi-class sentiment classification. A feature selection process is used to extract the important features that are later used to train a machine learning-based algorithm. The performance of DTC, NB, SVM, radial basis function neural network, and k nearest neighbor is tested with 10-fold cross-validation.
In another research [
18], the authors used customers feedback to investigate different aspects such as loyalty, satisfaction, etc. The loyalty is determined through airline attributes, namely operational factors (punctuality, aircraft, and safety), attractive factors (food and beverages and the staff service), competitive factors (schedule, ticket prices, reputation, and flyer program), etc. The research concludes that the customer’s higher satisfaction can be achieved through company reputation, staff service, frequent flyer program, aircraft, and punctuality. Kumar and Sebastian [
19] presented a novel approach for the sentiment analysis of Twitter data. To uncover the sentiment, the authors extracted the opinion words (a combination of the adjectives along with the verbs and adverbs) in the tweets. The corpus-based method is used to find the semantic orientation of adjectives and the dictionary-based method to find the semantic orientation of verbs and adverbs. The overall tweet sentiment is then calculated using a linear equation that also incorporates emotion intensifiers. A score is calculated for the overall sentiment of the tweet and tweets are classified as positive, neutral and negative based on the calculated score.
The authors of [
20] performed sentiment analysis using a machine learning technique. The polarity is found using TextBlob, SentiWordNet and word sense disambiguation (WSD) sentiment analyzers. TextBlob comes with the basic features of natural-language processing essentials, which are used for the polarity and subjectivity calculation of tweets. SentiWordNet is a publicly available analyzer for the English language that contains opinions extracted from a wordnet database. In addition, W-WSD has the ability to detect the correct word sense within a specified context.
The authors of [
21] presented a meta-heuristic method called CSK, which is based on cuckoo search (CS) and k-means (K). Since clustering plays a vital role in analyzing the viewpoints and sentiments in user tweets, the research proposes a method that is used to find the optimum cluster head from the twitter dataset. Experimental results show promising outcomes. The authors of [
22] investigated the impact of multiple classifier systems on Turkish sentiment classification. The voting algorithm is used with NB, SVM, and bagging to evaluate their efficacy. The results demonstrate that the use of multiple classifiers elevates the performance of individual classifiers. The research approves that multiple classifier systems have more potential for sentiment classification.
In addition to the use of multiple classifiers for classification, employing various pre-processing techniques helps to improve the classification as well. For example, the authors of [
23] proved that the selection of an appropriate pre-processing technique may produce enhanced classification performance. They investigated a variety of pre-processing techniques including term weighting, frequency cut, stemming, and stopword elimination to analyze their impact on machine learning-based classification methods. Their research shows that the combination of various pre-processing methods plays a decisive role in finding the best classification rates. They also studied the pre-processing techniques and their relevant impact on the feature space through visualization.
In the same fashion, the use of various feature extraction techniques has proven to improve classification accuracy. Text mining has many feature extraction methods but term frequency (TF), inverse document frequency (IDF), TF-IDF, word2vec and doc2vec are among the most commonly used feature extraction techniques [
24]. The authors of [
25] investigated the use of TF, IDF, and TF-IDF with linear classifiers including SVM, LR, and perceptron with a native language identification system. Experiments are carried out with ten-fold cross-validation on different languages. The TF-IDF is applied to n-gram words/characters/ parts-of-speech tags. The TF-IDF weighting on features proves to outperform other techniques when applied with uni-grams and bi-grams of words. Similarly, the authors of [
26] analyzed the use of three feature extraction techniques with a neural network for the text analysis. TF-IDF along with its two modifications, namely latent semantic analysis (LSA) and linear discriminant analysis (LDA), is applied to evaluate the performance of each feature analysis technique. The experiment shows that TF-IDF helps the model to achieve higher accuracy with large dataset. For smaller datasets, the combination of TF-IDF and LSA is appropriate to achieve similar accuracy.
Machine learning techniques perform better for classification than that of traditional approaches. However, machine learning methods for classification problems commonly assume that the class values are unordered. However, in many practical applications, the class values exhibit a natural order, for example, when learning how to grade. The standard ordinal classification approach converts the class value into a numeric quantity, applies a regression learner to the transformed data and translates the output back into a discrete class value in a post-processing step. The authors of [
27] presented a simple method that enables standard classification algorithms to make use of ordering information in class attributes. Tree induction methods and linear models are popular techniques for supervised learning tasks, both for the prediction of nominal classes and numeric values. For predicting numeric quantities, research has been conducted on combining two schemes into “model trees”, i.e., trees that contain linear regression functions at the leaves. The authors of [
28] presented an algorithm that performs classification using logistic regression instead of linear regression. A stage-wise fitting process is used to construct the logistic regression models that can select relevant attributes in the data in a natural way and shows how this approach can be used to build the logistic regression models at the leaves by incrementally refining those constructed at higher levels in the tree. In the current research, supervised learning algorithms are used, wherein some algorithms perform individually while others use ensemble learning techniques.
3. Materials and Methods
This section contains the description of the dataset used for sentiment analysis, its visualization, as well as the proposed methodology to perform the sentiment analysis on the selected dataset.
3.1. Data Description
In this study, the dataset from Kaggle was used, which contains tweets for six airlines of the United States (US). The dataset name is “twitter-airline-sentiment” and it contains a total of 14,640 records. Every record is labeled as
,
, or
according to the sentiment polarity. The selected dataset contains different features and its description is given in
Table 1.
3.2. Data Visualization
The dataset is visualized to help understand its attributes.
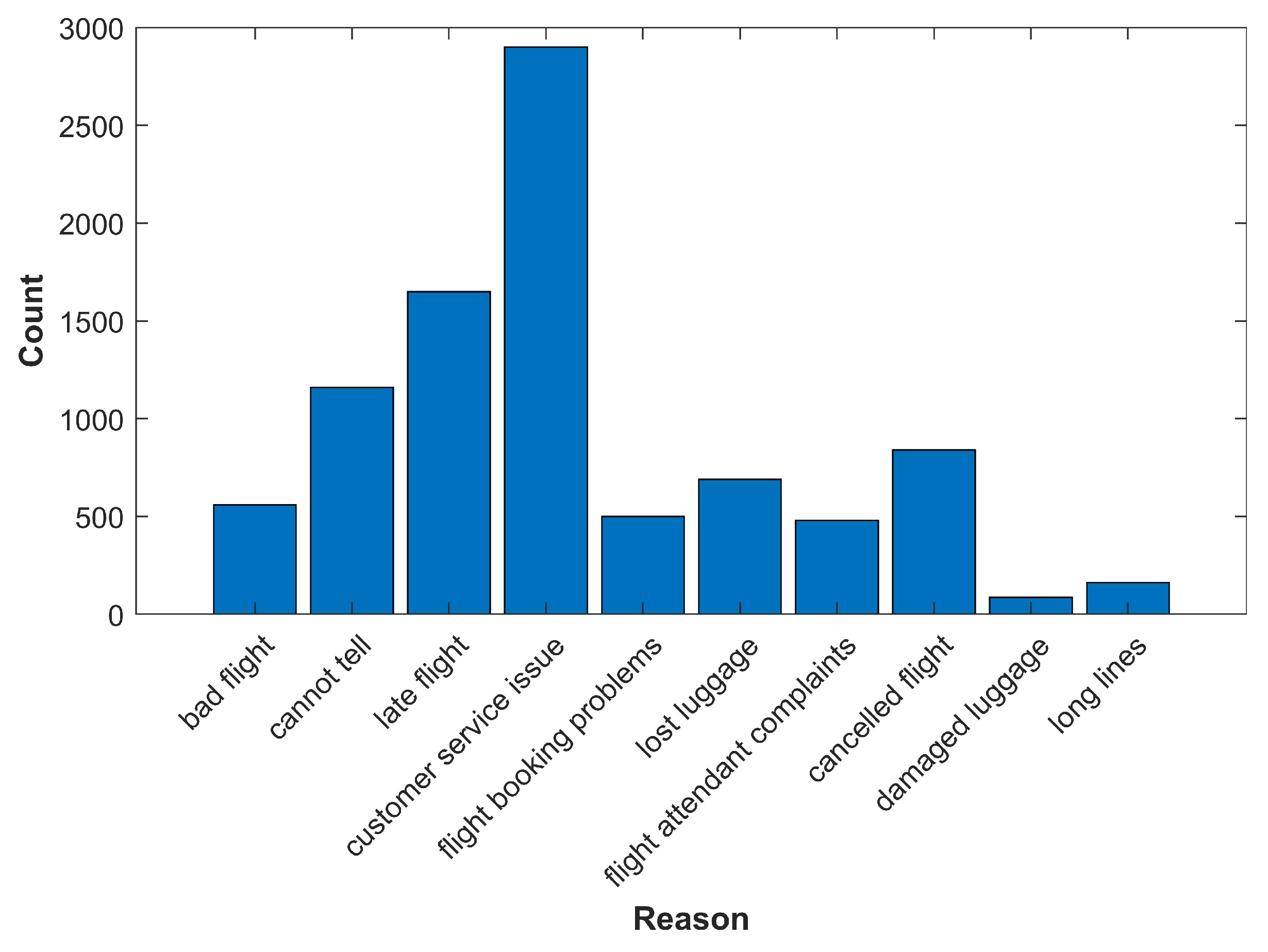
Figure 2 shows the most frequent reasons for customer complaints about the airline. The dataset visualization shows that the highest number of tweets are about “customer service issues”.
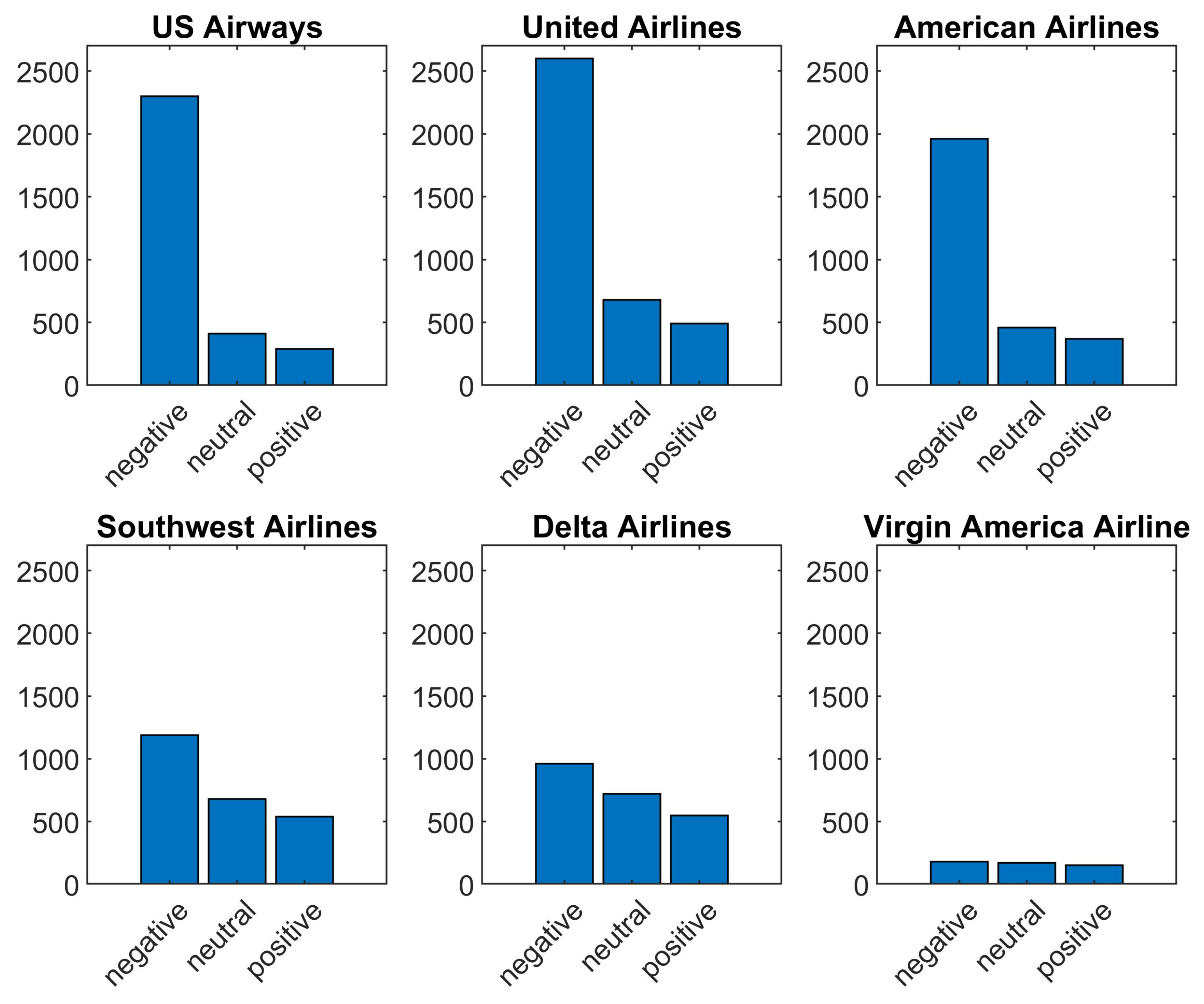
Figure 3 shows sentiment polarity for six airlines used as the standard to evaluate the performance of the selected classifiers.
3.3. Methodology
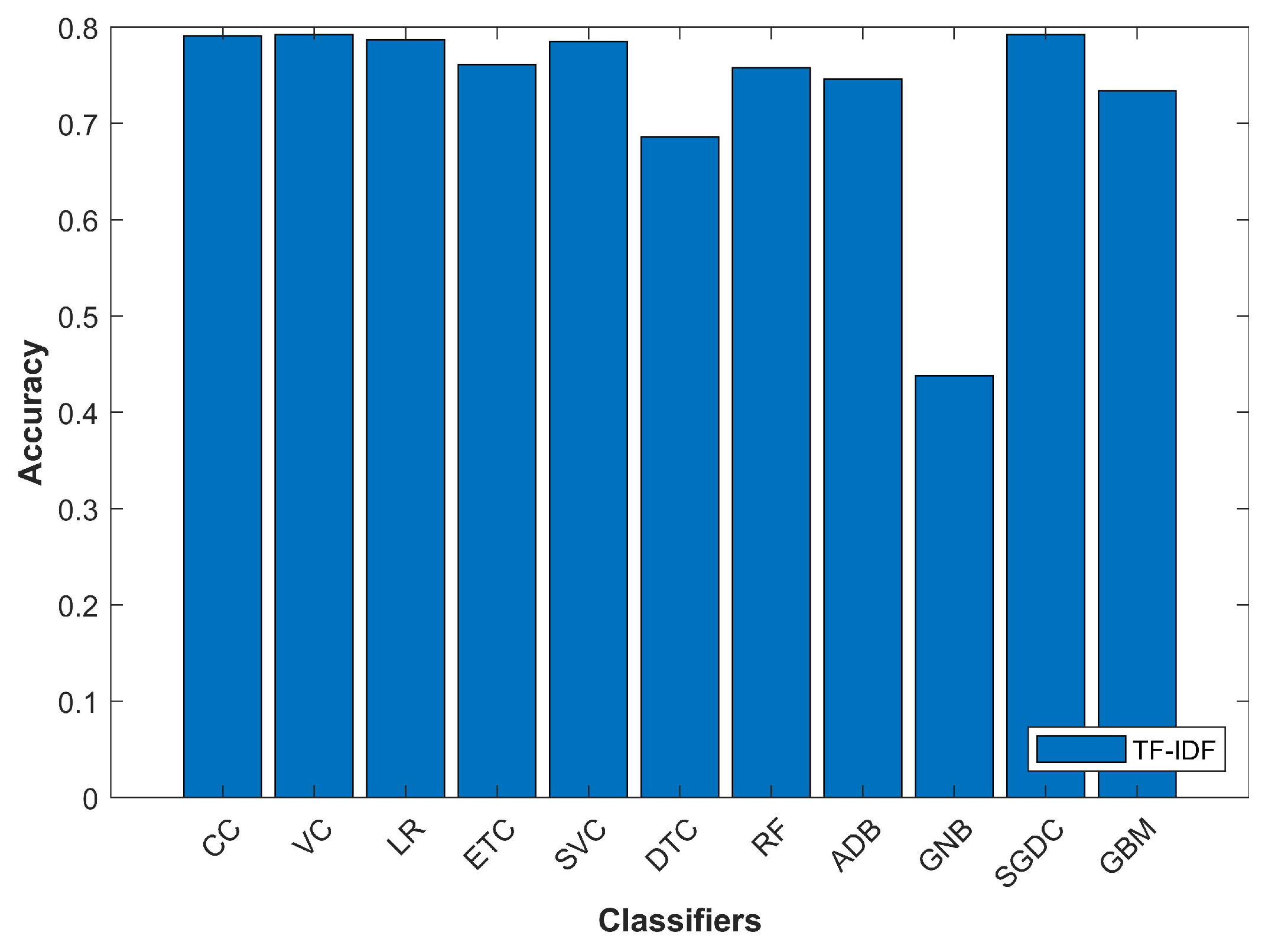
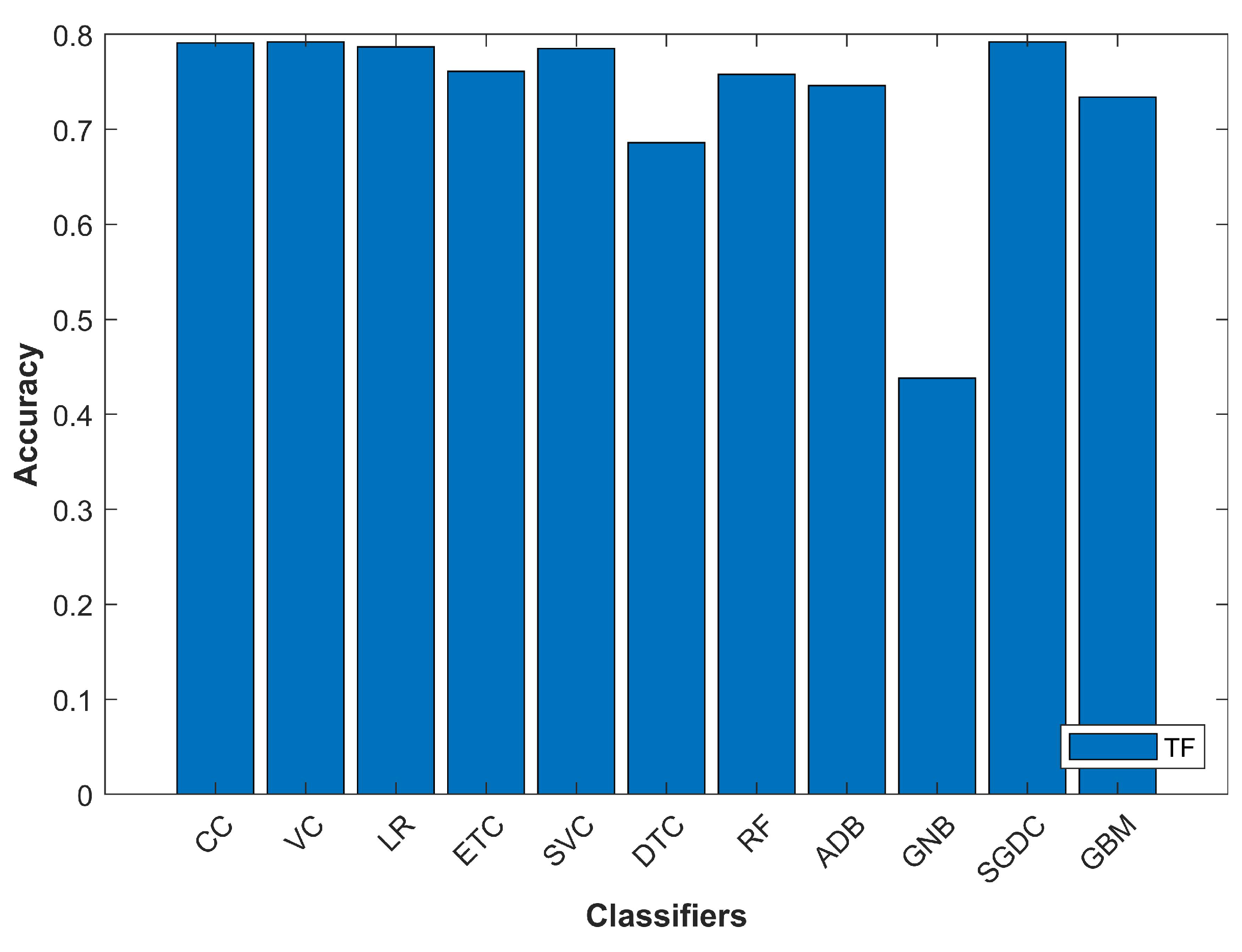
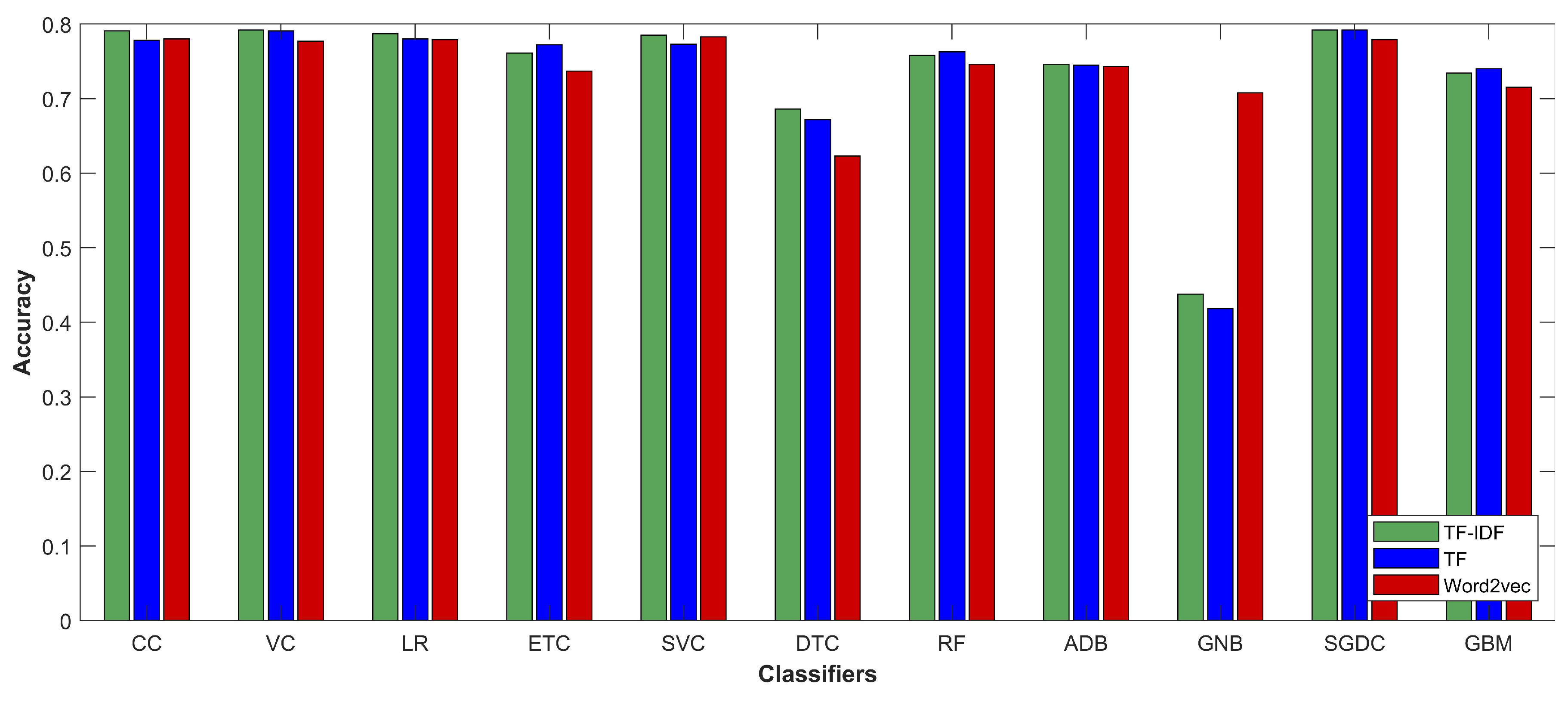
In the current research, different classifiers and feature extraction techniques were investigated. CC, LR, ETC, SVC, DTC, RF, ADB, GNB, SGDC, and GBM were evaluated on the selected dataset with term frequency (TF), term frequency-inverse document frequency (TF-IDF) and word2vec features. The phases followed during the experiments are described here briefly.
In the methodology steps of this research, pre-processing was carried out on the dataset. Different tools and libraries were utilized in this step, e.g., natural language toolkit. This study considered two strategies at the pre-processing level:
Complete pre-processing
Partial pre-processing
3.3.1. Complete Pre-processing
In complete pre-processing, data cleaning was performed to improve the learning efficiency of machine learning models. Machine learning models show improved classification accuracy if the data are pre-processed. The pre-processing was done using the natural language toolkit of Python [
29]. Tweets contain punctuation, stopwords, and the combination of lower- and uppercase words, which can affect the model learning capability. Two tweets are shown in
Table 2 as a means to show the pre-processing steps followed in this study.
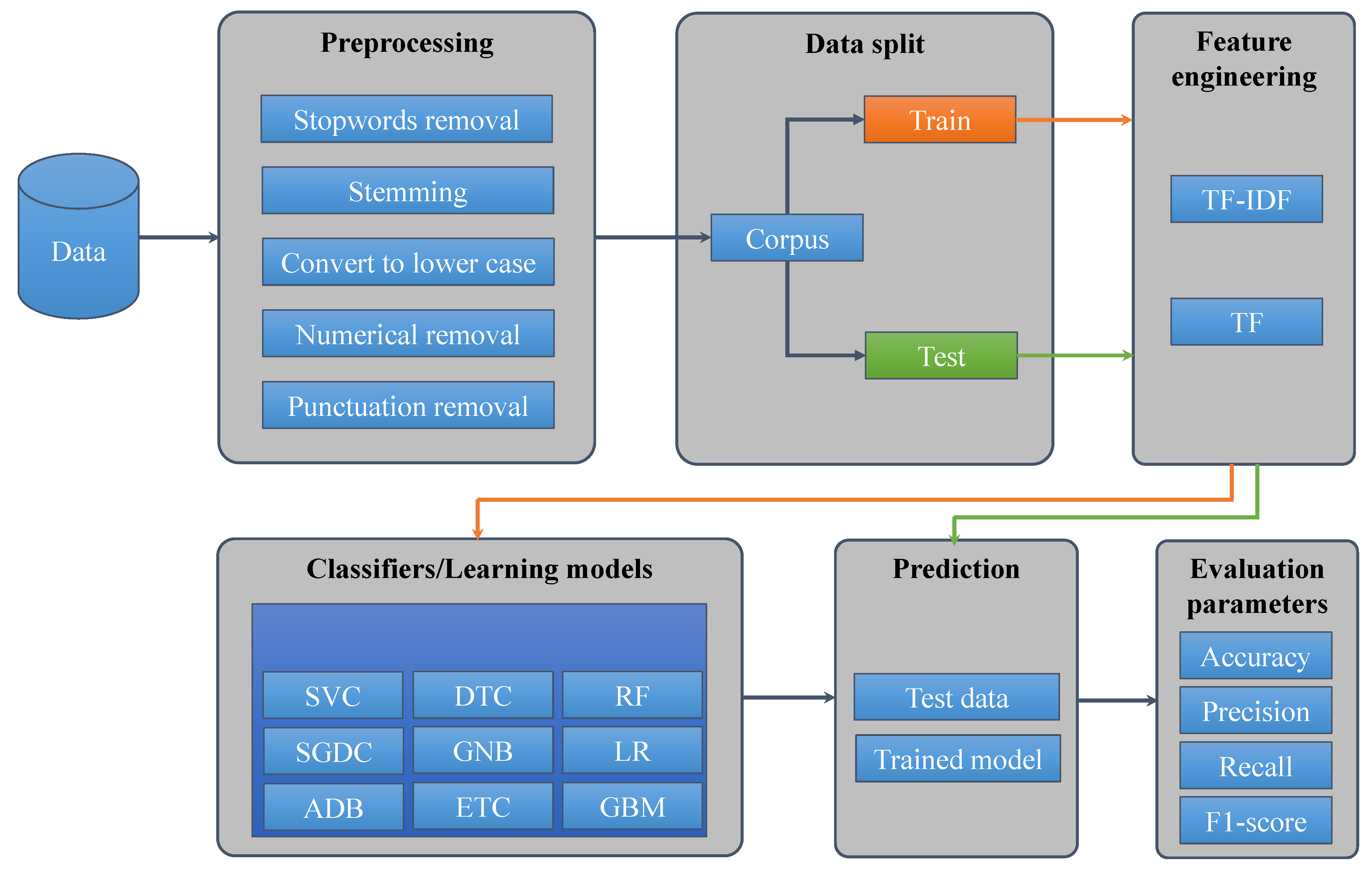
Figure 4 shows the sequence of the pr-processing steps followed for the selected twitter dataset. As a first step, punctuation has to be removed from tweets. The following punctuation was removed from text: []() \/ | , ; . ’. In addition, twitter assigned @user to each user was also removed during this phase.
Table 3 shows the tweets before and after punctuation removal.
Punctuation was removed from data because it does not contribute to text analysis in the study. Punctuation helps to make sentences readable but it impairs the models’ ability to differentiate between punctuation and other characters [
30]. In the next step, numeric values from the tweets were removed as they have no impact on text analysis. Removing numeric values decreases the complexity of training the models.
Table 4 shows the output of before and after numbers were removed from tweets.
After numeric removal, all text in the tweets was converted to lowercase. This step is important because text analysis is case sensitive. Yang and Zhang [
30] stated that the probabilistic machine learning models count the occurrence of each word, which means that, e.g., “Good”, and “good” are considered two different words if changing all text to lowercase is not performed. It could decrease the importance of more frequent terms in the text.
Table 5 shows the example of before and after the tweets have been converted to lower case.
Stemming is an important technique in pre-processing because removing affixes from words and converting them into their root form helps to increase the performance of the model [
31]. For example, words may have many forms with essentially the same meaning in the text. For example, “goes” and “going” are modified forms of “go”. Stemming converts these types words into their root form. Stemming was performed using Porter stemmer algorithms in current study [
32].
Table 6 shows the sample of tweets before and after stemming.
The last step in the pre-processing phase is the removal of stopwords in the tweets. Stopwords have no analytic value for text analysis, so they need to be removed to reduce the complexity of input features.
Table 7 shows the output of the tweets after stopwords were removed.
3.3.2. Partial Pre-processing
Other than the complete pre-processing, this study considered the use of partial pre-processing as well, to analyze the impact of pre-processing steps on classifiers’ accuracy. The partial pre-processing does not involve “stemming” and “stopwords removal”. Thus, the pre-processing was carried out in the order given in
Figure 5.
3.3.3. Feature Extraction Methods
After the pre-processing phase, the corpus was divided into “training subset” and “testing subset”. It was divided in the ratio of 3:1 for training and testing, respectively. Feature extraction methods were then applied to the training subset, as shown in
Figure 6, which represents the adopted methodology.
Feature extraction techniques were applied to both training and testing data: on the training data to train the selected models and on the testing data when classification was performed. TF-IDF is a scoring measure widely used in information retrieval (IR) and summarization. TF-IDF is intended to reflect how relevant a term is in a given document. TF-IDF feature extraction considers TF and IDF. IDF rewards the tokens that are rare overall in a dataset. If a rare word appears in two documents, then it is more important to the meaning of each document. IDF weights a token
t in a set of documents
U and is computed as follows:
where
is the frequency of
t in
U and
is the inverse frequency. Thus, the total TF-IDF weight for a token in a document is given as:
TF-IDF is used with parameter “ngram_ range”. TF-IDF is used to measure the importance weight of terms which give the weights of each term in the corpus. The term weighted matrix is the output of TF-IDF. With the TF-IDF vectorizer, the value increases proportionally to the count but is offset by the frequency of the word in the corpus.
Table 8 shows the output of three sentences when TF-IDF technique is applied to the pre-processed form of these sentences. The sentences are:
“good companies”
“bad services”
“I have seen good management”
Similar to TF-IDF, the TF technique is used for feature extraction as well and is commonly applied in document classification where the (frequency) occurrence of each word is used as a feature for training a classifier. However, contrary to TF-IDF where more frequent words get smaller weight, the TF feature does not care if a word is common or not. The output of TF for the above-given sentences is shown in
Table 9.
This study also considers the use of word2vec as the feature extraction technique [
33]. Word2vec is a famous two-layer neural net which produces the feature vectors from a text corpus. It utilizes the continuous bag-of-words (CBOW) or the skip-gram (SG) model for this purpose. This study employed SG because SG has been tested and shown good performance in NLP tasks [
34,
35]. The use of SG model aims at finding the word representations that are used to predict the adjacent word in a sentence. The SG model was considered in this study based on its suitability for small- to medium-sized datasets. Jang et al. [
36] stated that the SG model is advantageous over CBOW when data size is not too large.
3.4. Classifiers Used for Tweet Classification
This section describes the necessary details for the machine learning classifiers used in this study for tweet classification.
3.4.1. Machine Learning Classifiers
Multiple classifiers were used in the current study. The DTC is one of the used classifiers. The DTC algorithm falls under the category of supervised learning and can be used to solve both regression and classification problems. In DTC, the major challenge is the identification of the attribute for the root node at each level [
37]. This process is known as attribute selection. The two most popular attribute selection measures are “information gain” and “Gini index” [
38]. To calculate Gini, this study considered the probability of finding each class after a node and then the sum of the square of those values was calculated and subtracted from 1. Thus, when a subset is pure (i.e., there is only one class in it), Gini will be 0, because the probability of finding that class is 1; indeed, it is concluded that we have reached a leaf. To calculate Gini value, the following equation is used:
Besides Gini, information gain was also used for the selection of the best attribute. Whereas the Gini value gives the impurity of data in the dataset, information gain provides the purity of data in the dataset. There are two steps for calculating information gain for each attribute:
Step 1. Calculate the entropy of the target.
Step 2. Calculate the entropy for every attribute.
Using information gain formula, entropy was subtracted from the entropy of target. Given a set of examples
D, entropy is calculated using:
where
is the probability of class
in dataset
D.
The entropy is used as the measure of impurity or disorder of a dataset (or a measure of information in a tree). If an attribute
is made with
v values, this will partition
D into
v subsets
. If
is used as the current root, the expected entropy is:
Thus, information gain for selecting attribute
to branch or partition the data is:
The attribute with the highest gain was selected to branch/split the current tree in this study. The Gini value and information gain were used to construct the trees for all tree-based classifiers used in this study.
SVM is another machine learning classifier utilized in the current study. It is a linear model for classification and regression problems. It can solve linear and non-linear problems and works well for many practical applications [
39]. SVM creates a line or a hyper-plane which separates the data into classes. SVM has functions called kernels which take low-dimensional input space and transform it into a higher-dimensional space, i.e., it converts not separable problems to separable problems. It is mostly useful in non-linear separation problems. Simply put, it does some extremely complex data transformations and finds the process to separate the data based on the defined labels.
Two voting classifiers, namely LR and SGDC, were evaluated as well. Both LR and SGDC are able to estimate class probabilities on their outputs, i.e., they predict if the input is class-A with probability a and class-B with probability b. If , then it outputs predicted class is A, otherwise B. In voting, the classifier sets the voting parameter to soft enable them in order to calculate their probability (also known as confidence score) individually and presents it to the voting classifier. Then, the voting classifier averages them and outputs the class with the highest probability. The GBM, on the other hand, trains many models in a gradual, additive and sequential manner. The major difference between ADB and GBM is how the two algorithms identify the shortcomings of weak learners (e.g., decision trees). The ADB model identifies the shortcomings by using high weight data points, while the GBM model performs the same by using gradients in the loss function , where e is the error term. The loss function is a measure indicating how good the model’s coefficients are at fitting the underlying data. A logical understanding of loss function would depend on what we are trying to optimize.
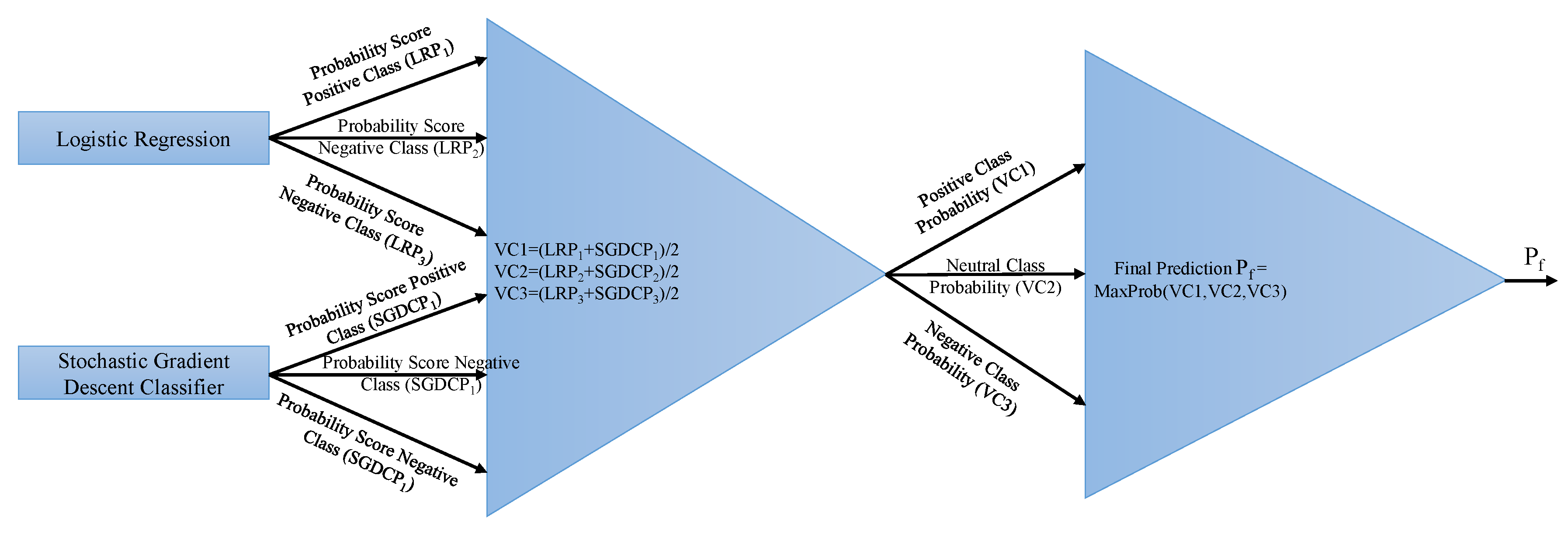
3.4.2. Proposed Voting Classifier (LR + SGDC)
The voting classifier (VC) is an ensemble model that combines different base models to perform the classification through different voting schemes (e.g., soft voting and hard voting). It gets final results by aggregating the results from the classifiers. In this study, two classifiers, LR and SGDC, were ensembled through soft voting criteria for the final prediction of target class. SGDC is useful for big data, especially when there are redundancies in the dataset. It solves the classification problems by specifying a loss and penalty function [
40]. It works similarly to regular gradient descent, except that it looks at only one sample at each step [
41]. LR, on the other hand, derives the posterior class probability (PCP)
implicitly to perform the binary classification. LR derives PCP through the sigmoid function
by using a linear combination of the input [
42]. VC can be expressed as:
where
and
give
n prediction probabilities for given samples. After each given probability for sample text, the probability passes through soft voting criteria, as shown in
Figure 7.
The functioning of the VC can be described with the help of an example. Let the following be the probability scores of each class given by LR:
Negative class = 0.1126337
Neutral class = 0.35984473
Positive class = 0.52889191
Similarly, SGDC probability scores against each class are:
Negative class = 0.17610406
Neutral class = 0.42969437
Positive class = 0.39420157
The VC gives probability scores against each class using the probabilities of LR and SGDC as follows:
Negative class = (0.1126337+0.17610406)/2 = 0.143683715
Neutral class = (0.35984473 + 0.42969437)/2 = 0.39476955
Positive class = (0.52889191 + 0.39420157)/2 = 0.46154674
The VC classifies it as the “positive” class for the given tweet using the maximum of the given probability. The tweet tested with the VC classifier also belongs to the “positive” class in the dataset.
3.5. Performance Evaluations Parameters
Different performance evaluation parameters have been utilized to analyze the performance of the classifiers. Four basic notations used in these parameters are as follows [
43,
44,
45]:
True Positives (TP): These are the positive predictions of a class made by a classifier which are correctly predicted.
True Negatives (TN): These are the negative predictions about a class which are correctly labeled so by the classifier.
False Positives (FP): These are the negative instances of a class which are incorrectly predicted as positive by the classifier.
False Negatives (FN): These are the positive instances of a class which are incorrectly predicted as negative by the classifier.
These quantities are used to calculate accuracy, F1 score, recall, and precision of each classifier to evaluate its performance. Accuracy is defined as:
Recall shows the completeness of a classifier and is calculated as:
Precision is the exactness of the classifiers and involves TP to the sum of TP and FP. It is calculated using:
The F1 score conveys the balance between the precision and the recall and is calculated as:
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}