Distribution Structure Learning Loss (DSLL) Based on Deep Metric Learning for Image Retrieval


Abstract
:1. Introduction
- We propose a novel and effective metric learning method. To the best of our knowledge, it introduces the concept of structural preservation and structural consistency for the first time. Structural preservation deals with the intraclass distribution of positive samples, while structural consistency accounts for the structural distribution information of negative samples.
- To solve the problem of shrinking each feature vector of positive samples into the same point, we set a hypersphere learning for every class. The method uses the hardest positive sample to train the network by adjusting its distance from the query sample. This effectively preserves the structure of the positive sample.
- We add the entropy weight based on structural distribution to the loss function. The algorithm considers the distribution characteristics of the negative samples, captures the feature structure, addresses the relative similarity of each sample, which has been ignored in past works, and calculates the loss by using weight to rank the negative samples. The proposed method deals well with sample similarity and structural distribution of each sample.
2. Related Work
2.1. Image Retrieval
2.2. Deep Metric Learning
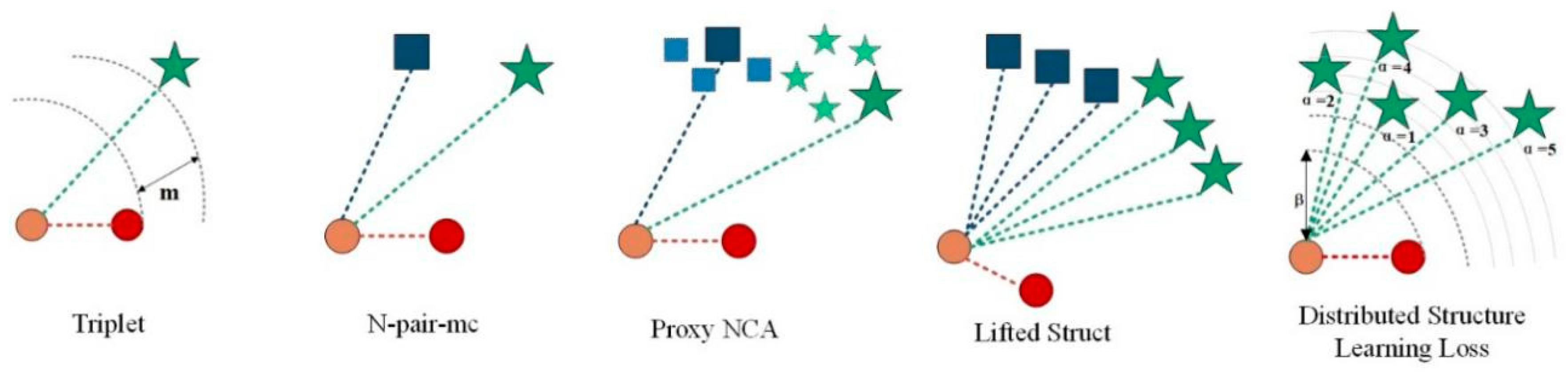
2.2.1. Contrastive Loss
2.2.2. Triplet Loss
2.2.3. N-Pair Loss
2.2.4. Lifted Structured Loss
2.2.5. Proxy-NCA
3. Proposed Method
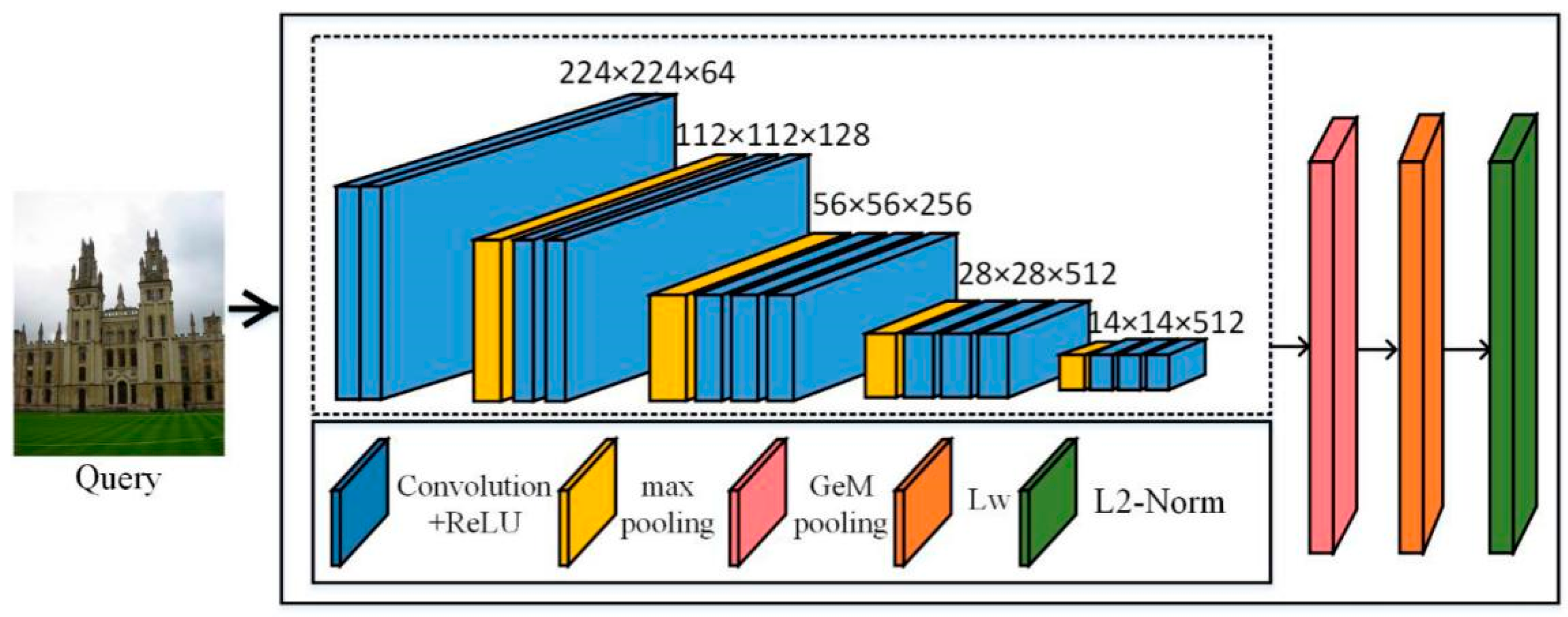
3.1. Network for Image Retrieval
3.1.1. CNN Network Architecture
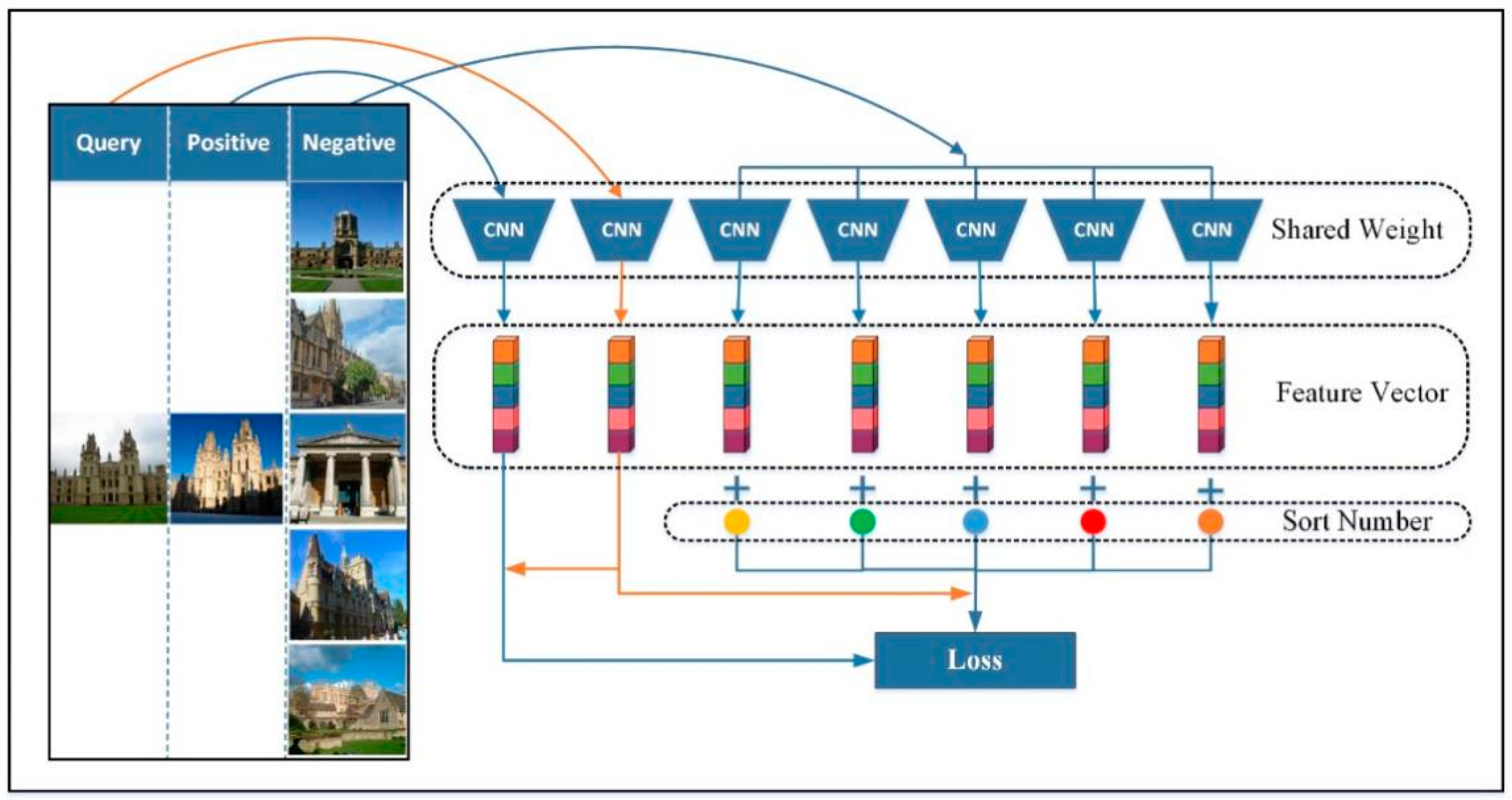
3.1.2. The Architecture of Network Training
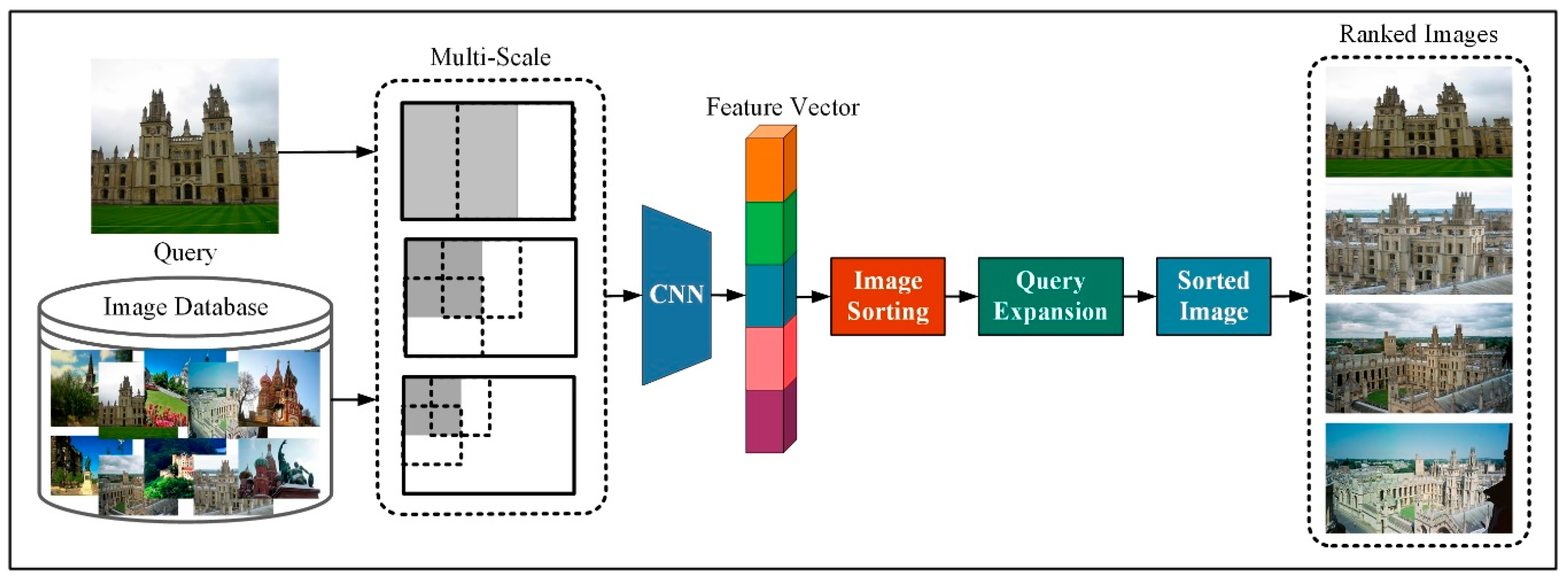
3.1.3. Network Evaluting Architecture
3.2. Distributed Structure Learning Loss
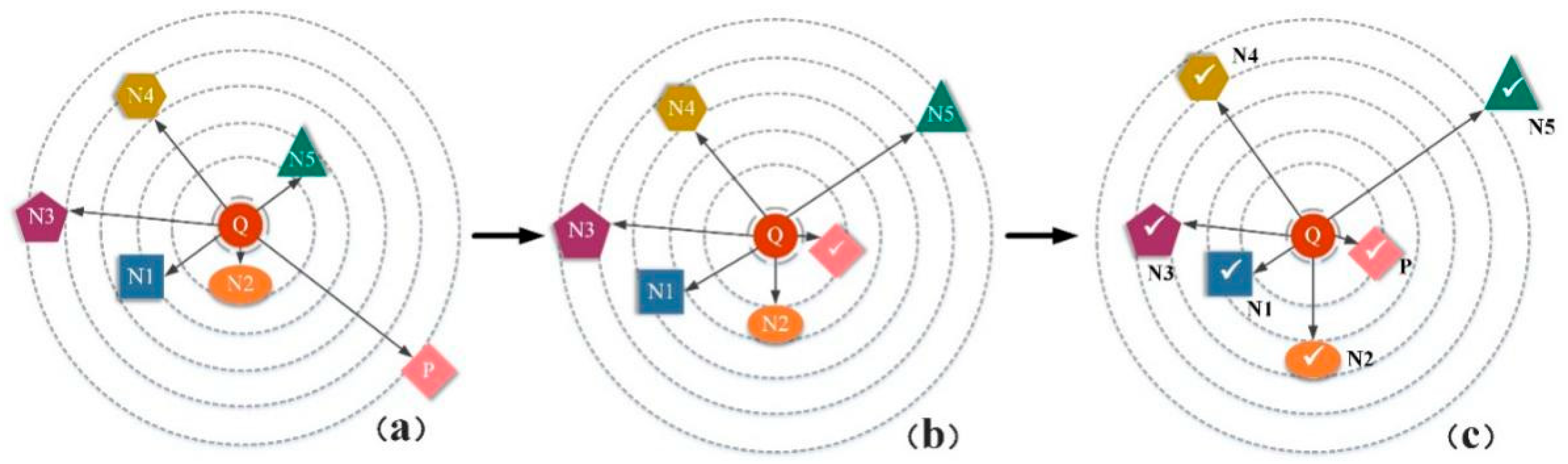
3.2.1. The Process of Distributed Structure Learning Loss
3.2.2. The Training Process of DSLL
4. Experiments
4.1. Training Datasets
4.2. Training Configurations
4.3. Test Datasets
4.4. Performance Evaluation Metrics
4.5. Results and Analysis
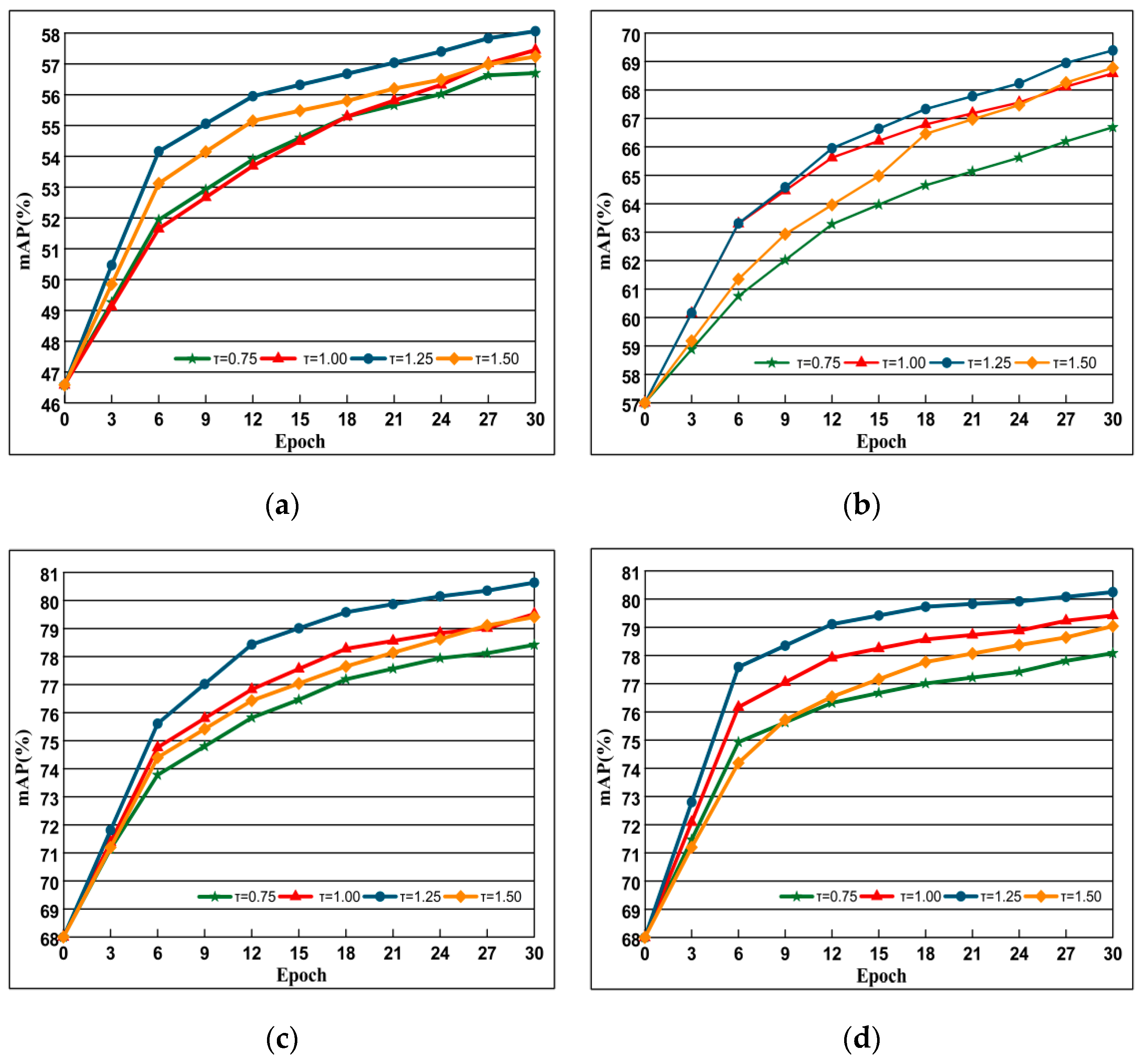
4.5.1. The Impact of Margin Parameter τ
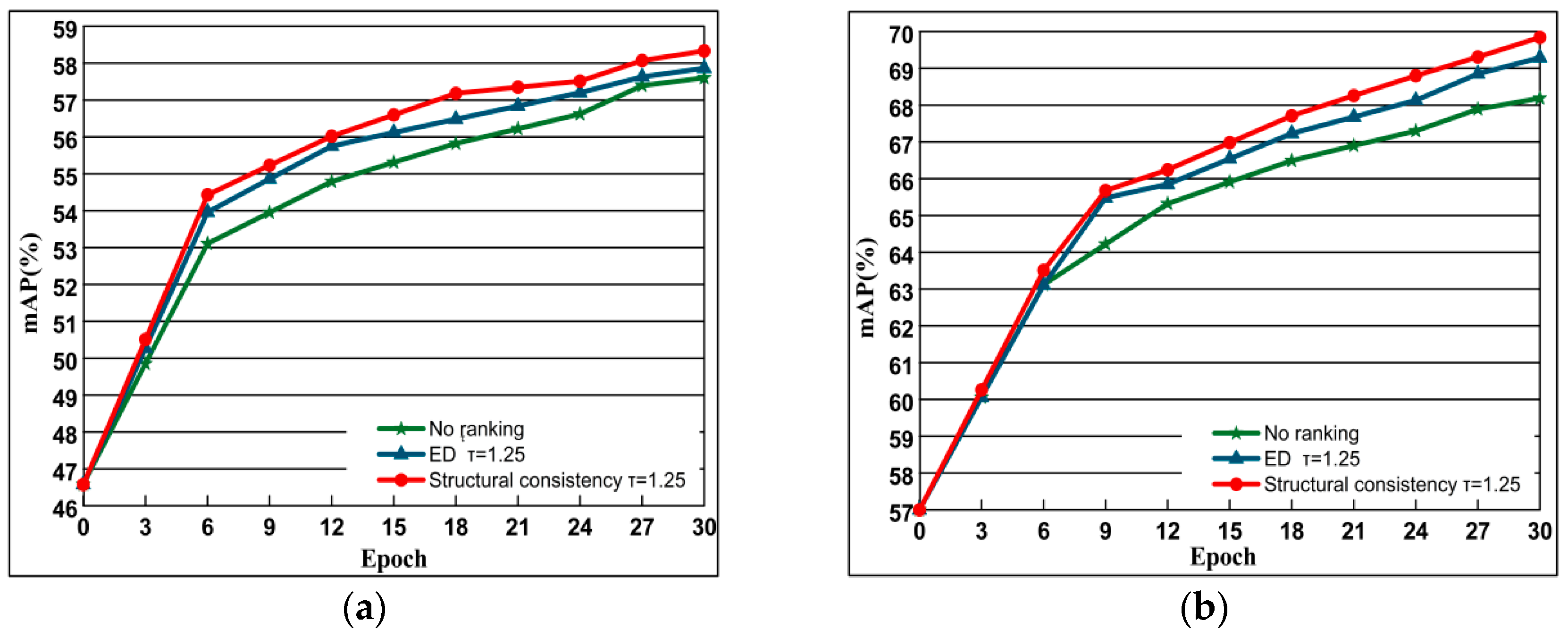
4.5.2. The Role of Structural Similarity Ranking Consistency
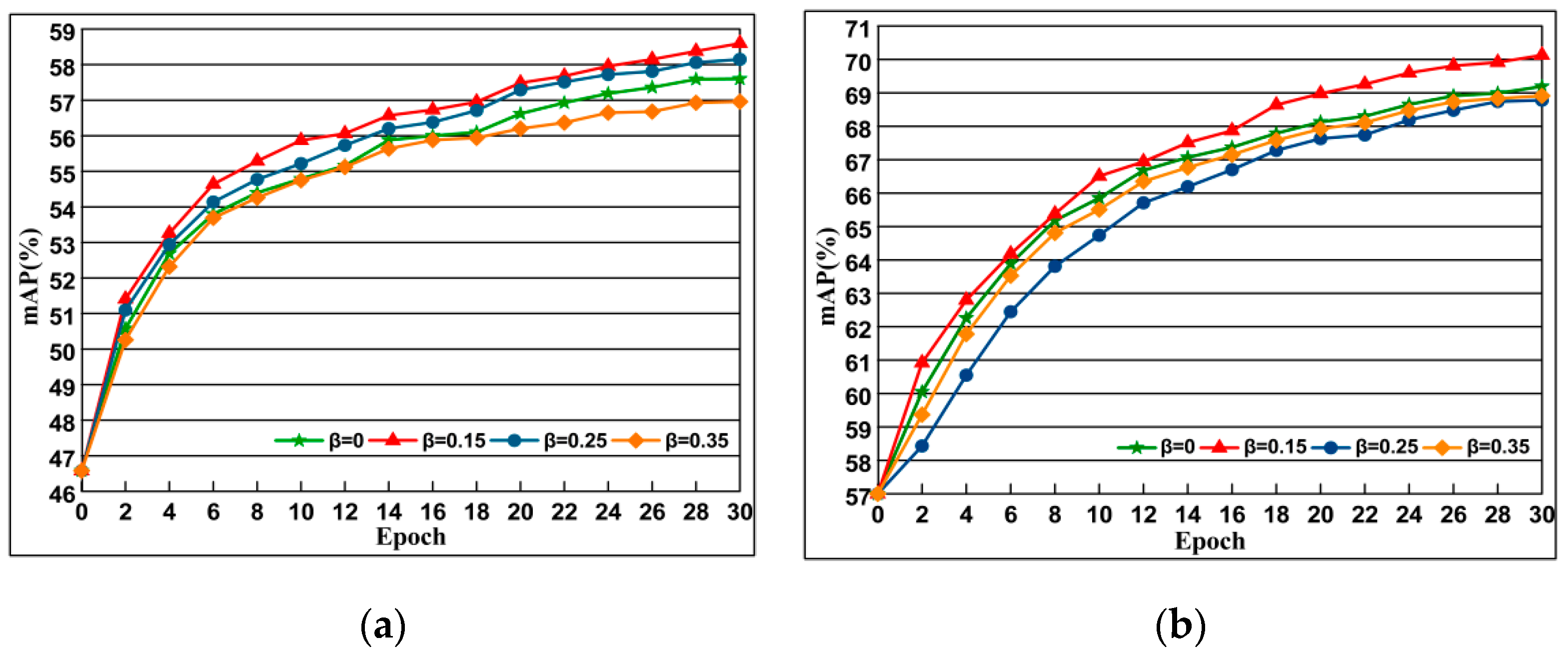
4.5.3. Imapact of Margin Parameter β
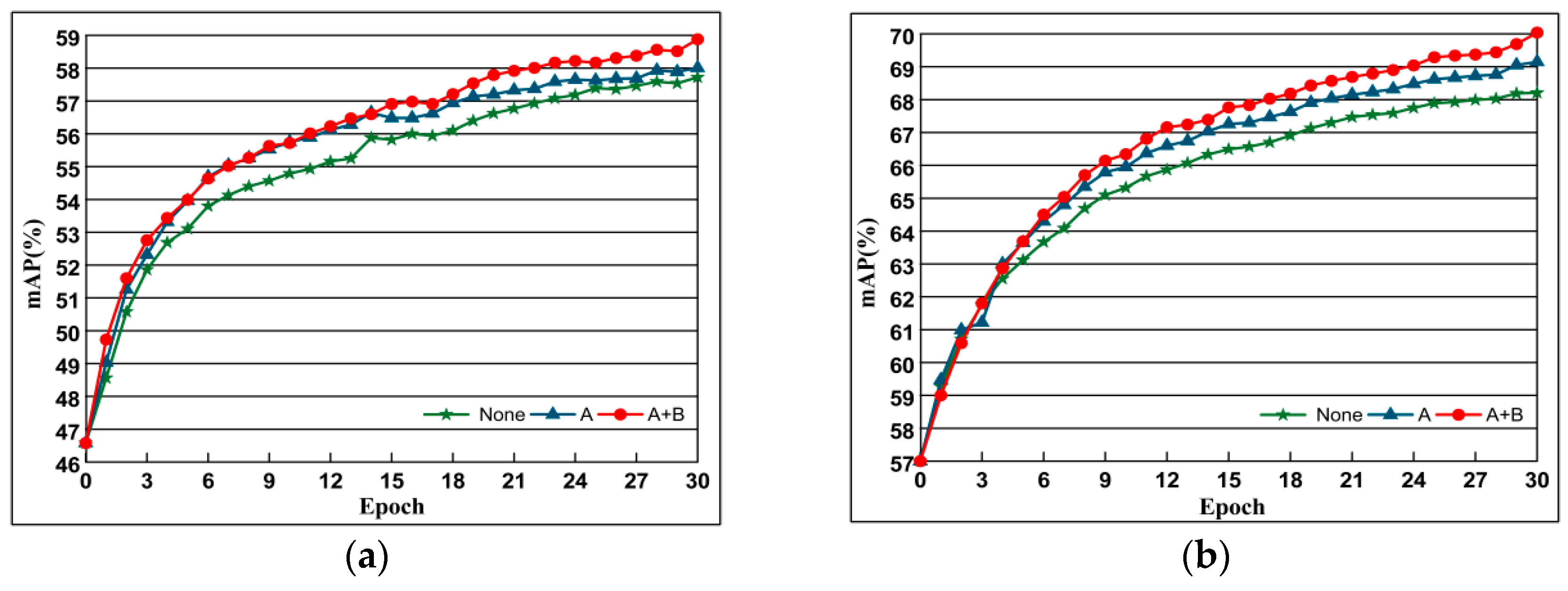
4.5.4. The Combined Impact of DSLL
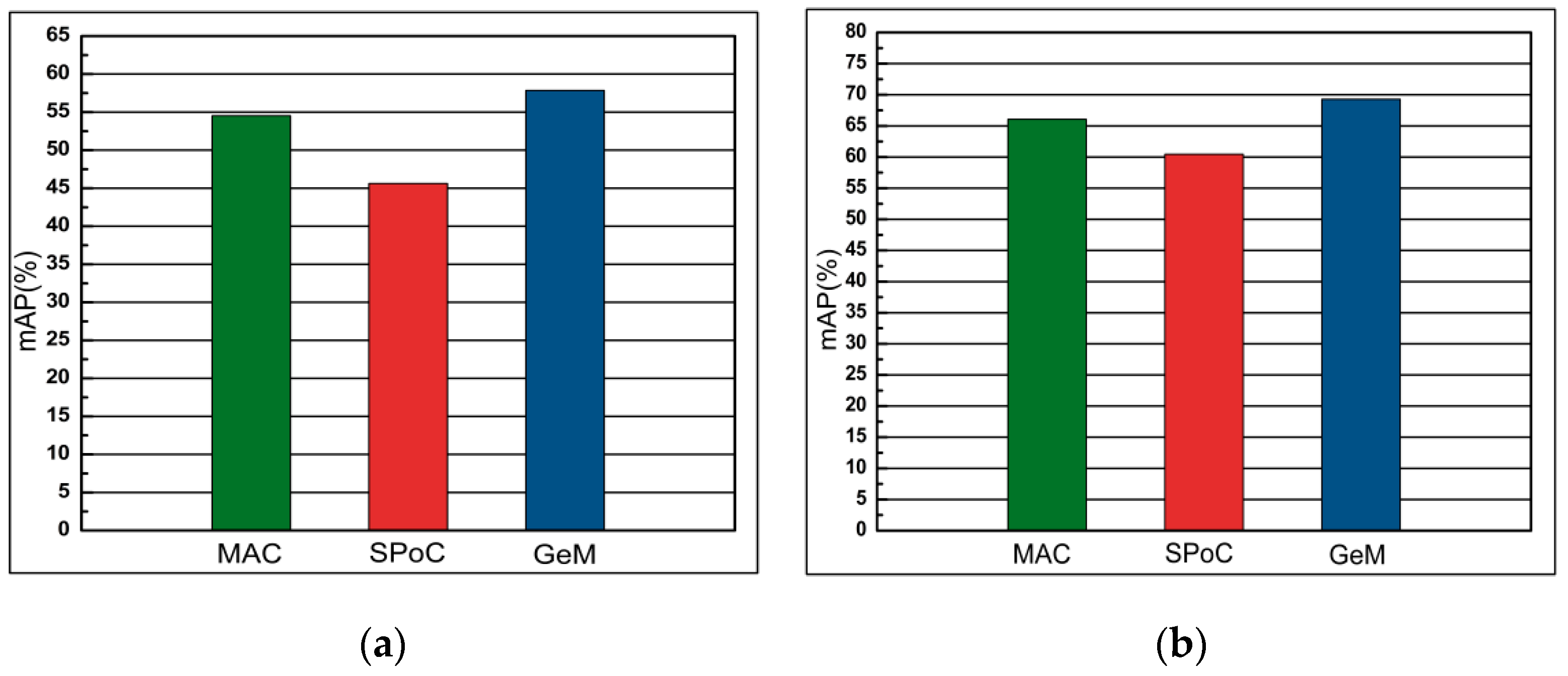
4.5.5. Comparison of MAC, SPoC and GeM
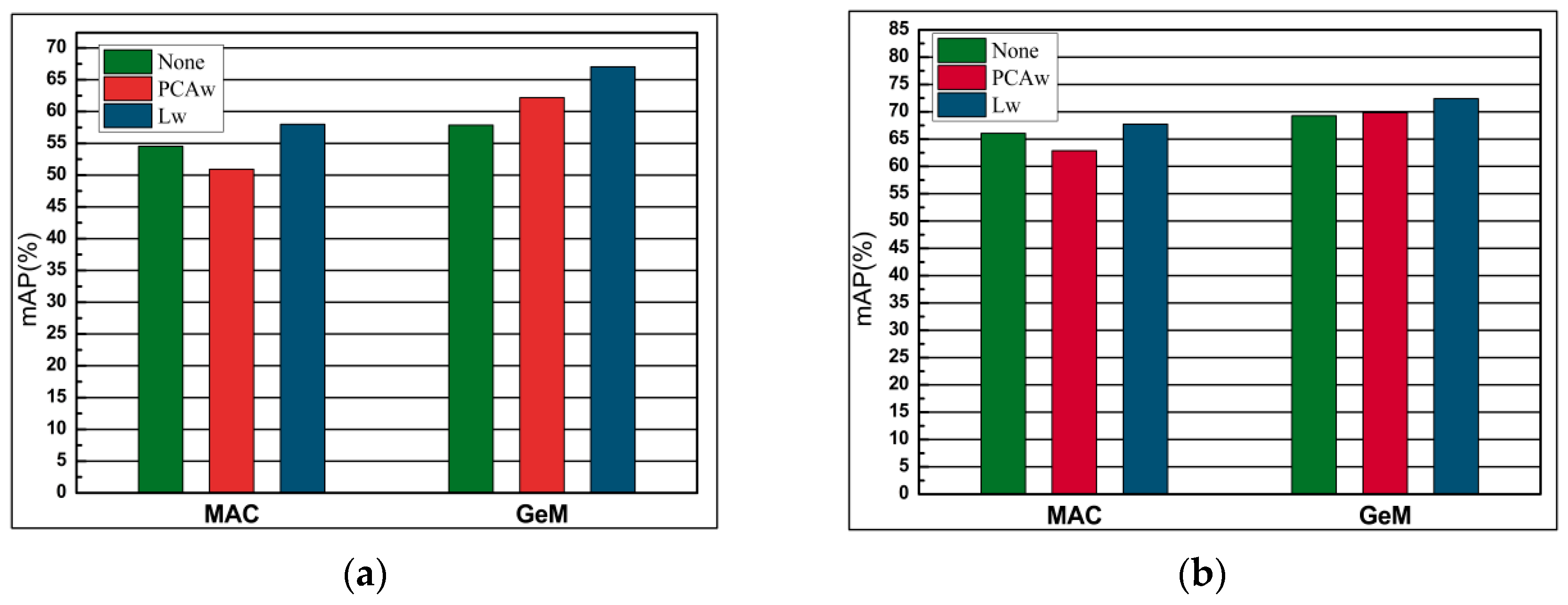
4.5.6. Comparison of PCA-Whitening and Learned Discriminative Whitening
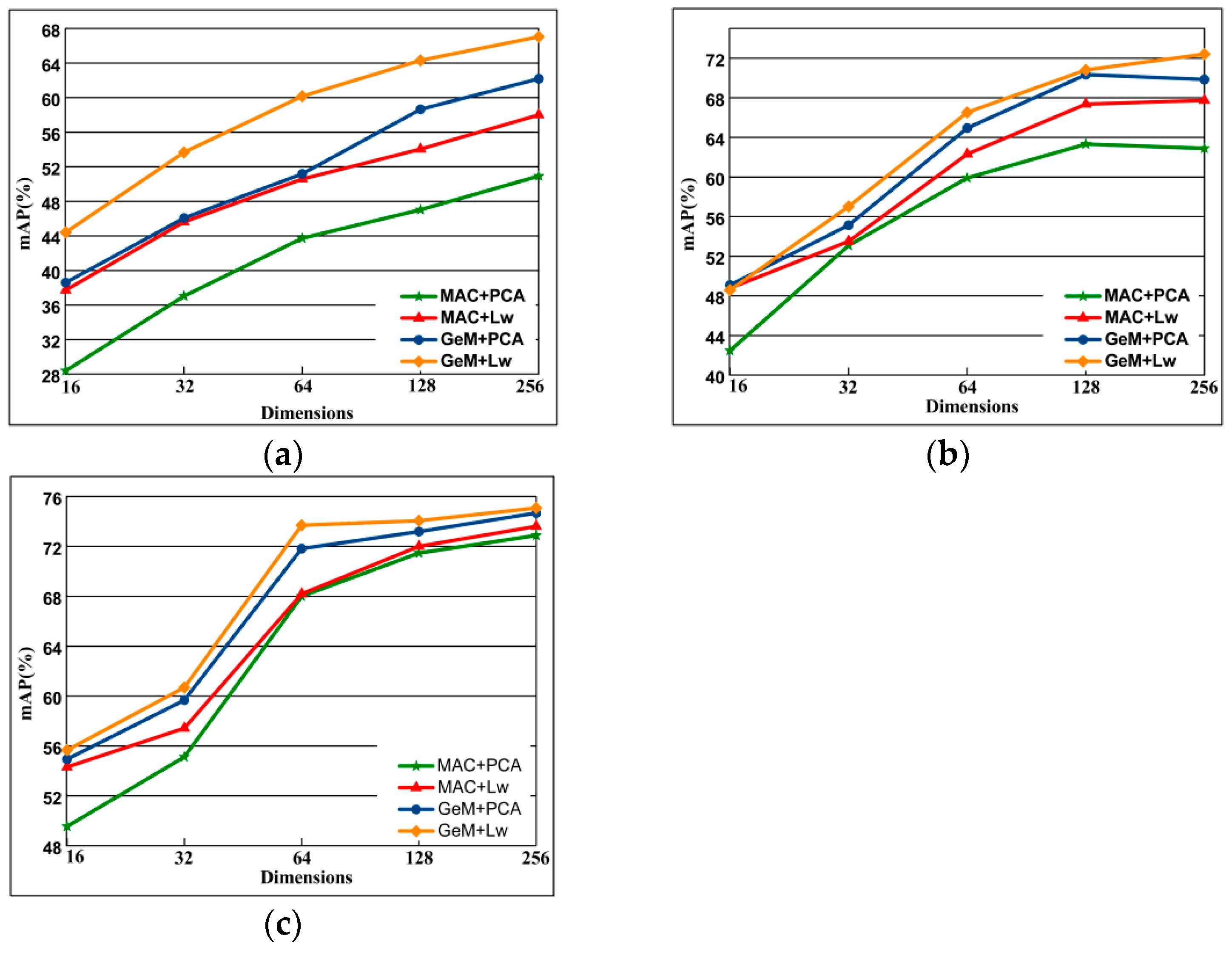
4.5.7. Gradient Value Selection
4.5.8. Comparison with the State of the Art
4.5.9. Visualization Purposes
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object retrieval with large vocabularies and fast spatial matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; Volume 1–8, pp. 1545–1588. [Google Scholar]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Perronnin, F.; Dance, C. Fisher Kernels on Visual Vocabularies for Image Categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Ke, Y.; Wang, Y.; Liang, D.; Huang, T.; Tian, Y. CNN vs. SIFT for Image Retrieval: Alternative or Complementary? In Proceedings of the ICMR’16 Acm International Conference on Multimedia Retrieval, New York, NY, USA, 6–9 June 2016; pp. 407–411. [Google Scholar]
- Seddati, O.; Dupont, S.; Mahmoudi, S.; Parian, M. Towards Good Practices for Image Retrieval Based on CNN Features. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1246–1255. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-drivenvisualnavigationin indoor scenes using deep reinforcement learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Cvpr), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Weinberger, K.Q.J.J. Distance Metric Learning for Large Margin Nearest Neighbor Classification. In Proceedings of the Advances in Neural Information Processing Systems 19 (Nips 2006), Vancouver, BC, Canada, 3–6 December 2006; Volume 10. [Google Scholar]
- Zhong, G.; Zheng, Y.; Li, S.; Fu, Y. Scalable large margin online metric learning. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 2252–2259. [Google Scholar]
- Song, H.O.; Yu, X.; Jegelka, S.; Savarese, S. Deep Metric Learning via Lifted Structured Feature Embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4004–4012. [Google Scholar]
- Lu, J.; Hu, J.; Tan, Y.-P. Discriminative deep metric learning for face and kinship verification. IEEE Trans. Image Proc. 2017, 26, 4269–4282. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Lu, J.; Tan, Y.P. Sharable and Individual Multi-View Metric Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2281–2288. [Google Scholar] [CrossRef] [PubMed]
- Gordo, A.; Almazán, J.; Revaud, J.; Larlus, D.J. End-to-End Learning of Deep Visual Representations for Image Retrieval. Int. J. Comput. Vis. 2017, 124, 237–254. [Google Scholar] [CrossRef]
- Duan, Y.; Lu, J.; Feng, J.; Zhou, J. Deep Localized Metric Learning IEEE Transactions on Circuits and Systems for Video Technology. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2644–2656. [Google Scholar] [CrossRef]
- Yumin, S.; Bohyung, H.; Wonsik, K.; Kyoung, K. Stochastic Class-Based Hard Example Mining for Deep Metric Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Denton, TX, USA, 18–20 March 2019; pp. 7251–7259. [Google Scholar]
- Hadsell, R.; Chopra, S.; Lecun, Y. Dimensionality Reduction by Learning an Invariant Mapping. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition (CVPR), New York, NY, USA, 17 June 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Chopra, S.; Hadsell, R.; Lecun, Y. Learning a Similarity Metric Discriminatively, with Application to Face Verification. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition (CVPR), Toronto, ON, Canada, 20 June 2005; pp. 539–546. [Google Scholar]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning Fine-Grained Image Similarity with Deep Ranking. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 1386–1393. [Google Scholar]
- Yin, C.; Feng, Z.; Lin, Y.; Belongie, S. Fine-grained Categorization and Dataset Bootstrapping using Deep Metric Learning with Humans in the Loop. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Cvpr), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1153–1162. [Google Scholar]
- Sohn, K. Improved Deep Metric Learning with Multi-class N-pair Loss Objective. In Proceedings of the Advances in Neural Information Processing Systems 29 (Nips 2016), Barcelona, Spain, 6–7 December 2016; Volume 29. [Google Scholar]
- Song, H.O.; Jegelka, S.; Rathod, V.; Murphy, K. Deep Metric Learning via Facility Location. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5382–5390. [Google Scholar]
- Movshovitz-Attias, Y.; Toshev, A.; Leung, T.K.; Ioffe, S.; Singh, S. No Fuss Distance Metric Learning using Proxies. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 360–368. [Google Scholar]
- Wang, X.; Hua, Y.; Kodirov, E.; Hu, G.; Robertson, N.M. Ranked List Loss for Deep Metric Learning. arXiv 2019, arXiv:1903.03238. [Google Scholar]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Lost in quantization: Improving particular object retrieval in large scale image databases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AL, USA, 24–26 June 2008; Volume 1–12, pp. 2285–2298. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. Hamming embedding and weak geometric consistency for large scale image search. I. In Proceedings of the 10th European Conference on Computer Vision, ECCV, Marseille, France, 12–18 October 2008; Volume 5302, pp. 304–317. [Google Scholar]
- Wu, C.Y.; Manmatha, R.; Smola, A.J.; Krähenbühl, P. Sampling Matters in Deep Embedding Learning. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2840–2848. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Mohedano, E.; McGuinness, K.; O’Connor, N.E.; Salvador, A.; Marques, F.; Giro-I-Nieto, X. Bags of Local Convolutional Features for Scalable Instance Search. In Proceedings of the ICMR’16: Acm International Conference on Multimedia Retrieval, New York, NY, USA, 6–9 June 2016; pp. 327–331. [Google Scholar]
- Wei, S.; Wu, X.; Dong, X. Partitioned K-Means Clustering for Fast Construction of Unbiased Visual Vocabulary. In The Era of Interactive Media; Springer: New York, NY, USA, 2013; pp. 483–493. [Google Scholar]
- Yandex, A.B.; Lempitsky, V. Aggregating Local Deep Features for Image Retrieval. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1269–1277. [Google Scholar]
- Tolias, G.; Sicre, R. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2015, arXiv:1511.05879. [Google Scholar]
- Jegou, H.; Chum, O. Negative evidences and co-occurences in image retrieval: The benefit of pca and whitening. Pt II. In Proceedings of the Computer Vision—ECCV, Florence, Italy, 7–13 October 2012; Volume 7573, pp. 774–787. [Google Scholar]
- Gordo, A.; Almazan, J.; Revaud, J.; Larlus, D. Deep image retrieval: Learning global representations for image search. VI. In Proceedings of the Computer Vision—Eccv 2016, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9910, pp. 241–257. [Google Scholar]
- Radenović, F.; Tolias, G.; Chum, O. CNN Image Retrieval Learns from BoW: Unsupervised Fine-Tuning with Hard Examples. In Proceedings of the Computer Vision—Eccv 2016, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 3–20. [Google Scholar]
- Simonyan, K.; Zisserman, A.J.C.S. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Schönberger, J.L.; Radenović, F.; Chum, O.; Frahm, J.M. From single image query to detailed 3d reconstruction. In Proceedings of the Computer Vision & Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Radenović, F.; Tolias, G.; Chum, O. Fine-tuning CNN Image Retrieval with No Human Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1655–1668. [Google Scholar] [CrossRef] [PubMed]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1437–1451. [Google Scholar] [CrossRef] [PubMed]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar]
- Huang, R.; Jiang, X. Off-Feature Information Incorporated Metric Learning for Face Recognition. IEEE Signal Process. Lett. 2018, 25, 541–545. [Google Scholar] [CrossRef]
- Feng, G.; Liu, W.; Tao, D.; Zhou, Y. Hessian Regularized Distance Metric Learning for People Re-Identification. Neural Process. Lett. 2019. [Google Scholar] [CrossRef]
- Rui, W.; Wu, X.J.; Chen, K.X.; Kittler, J. Multiple Manifolds Metric Learning with Application to Image Set Classification. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 627–632. [Google Scholar]
- Min, T.; Jun, Y.; Zhou, Y.; Fei, G.; Yong, R.; Tao, D. User-Click-Data-Based Fine-Grained Image Recognition via Weakly Supervised Metric Learning. In Proceedings of the ICMR’20: Acm International Conference on Multimedia Retrieval, Galway, Ireland, 22–24 October 2018; pp. 1–23. [Google Scholar]
- Cao, R.; Zhang, Q.; Zhu, J.; Li, Q.; Qiu, G. Enhancing Remote Sensing Image Retrieval with Triplet Deep Metric Learning Network. arXiv 2019, arXiv:1902.05818. [Google Scholar] [CrossRef]
- Xiang, J.; Zhang, G.; Hou, J.; Nong, S.; Rui, H. Multiple Target Tracking by Learning Feature Representation and Distance Metric Jointly. arXiv 2018, arXiv:1802.03252. [Google Scholar]
- Yang, J.; She, D.; Lai, Y.-K.; Yang, M.-H. Retrieving and classifying affective images via deep metric learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 491–498. [Google Scholar]
- Yi, S.; Jiang, N.; Wang, X.; Liu, W.J.N. Individual Adaptive Metric Learning for Visual Tracking. Neurocomputing 2016, 191, 273–285. [Google Scholar] [CrossRef]
- Zhong, G.; Zheng, Y.; Li, S.; Fu, Y. SLMOML: Online Metric Learning With Global Convergence. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2460–2472. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Radenovic, F.; Schonberger, J.L.; Ji, D.; Frahm, J.-M.; Chum, O.; Matas, J. From Dusk Till Dawn: Modeling in the Dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Cvpr), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5488–5496. [Google Scholar]
- Papandreou, G.; Kokkinos, I.; Savalle, P.A. Modeling Local and Global Deformations in Deep Learning: Epitomic Convolution, Multiple Instance Learning, and Sliding Window Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Cvpr), Boston, MA, USA, 7–12 June 2015; pp. 390–399. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Jose, CA, USA, 18–20 June 2009; pp. 248–255. [Google Scholar]
- Razavian, A.S.; Sullivan, J.; Maki, A.; Carlsson, S. Applications a Baseline for Visual Instance Retrieval with Deep Convolutional Networks. ITE Trans. Media Technol. Appl. 2016, 4, 251–258. [Google Scholar] [CrossRef] [Green Version]
- Kalantidis, Y.; Mellina, C.; Osindero, S. Cross-Dimensional Weighting for Aggregated Deep Convolutional Features. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 685–701. [Google Scholar]
- Ong, E.J.; Husain, S.; Bober, M. Siamese Network of Deep Fisher-Vector Descriptors for Image Retrieval. arXiv 2017, arXiv:1702.00338. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Net | Method | F-Tuned | Oxford5k | Oxford105k | Paris6k | Paris106k | Holidays | Hol101k |
|---|---|---|---|---|---|---|---|---|
| Compact Representation using Deep Networks | ||||||||
| VGG | MAC [54] † | no | 56.4 | 47.8 | 72.3 | 58.0 | 79.0 | 66.1 |
| SPoC [30] † | no | 68.1 | 61.1 | 78.2 | 68.4 | 83.9 | 75.1 | |
| CroW [55] | no | 70.8 | 65.3 | 79.7 | 72.2 | 85.1 | - | |
| R-MAC [24] | no | 66.9 | 61.6 | 83.0 | 75.7 | 86.9 | - | |
| BoW-CNN [28] | no | 73.9 | 59.3 | 82.0 | 64.8 | - | - | |
| NetVLAD [38] | yes | 71.6 | - | 79.7 | - | 87.5 | - | |
| Fisher Vector [56] | yes | 81.5 | 76.6 | 82.4 | - | - | - | |
| R-MAC [33] | yes | 83.1 | 78.6 | 87.1 | 79.7 | 89.1 | - | |
| GeM [37] | yes | 87.9 | 83.3 | 87.7 | 81.3 | 89.5 | 79.9 | |
| *ours | yes | 88.4 | 84.7 | 88.9 | 81.5 | 90.8 | 83.1 | |
| Res | R-MAC [24] ‡ | no | 69.4 | 63.7 | 85.2 | 77.8 | 91.3 | - |
| GeM [37] | yes | 87.8 | 84.6 | 92.7 | 86.9 | 93.3 | 87.9 | |
| *ours | yes | 88.4 | 84.9 | 93.9 | 87.8 | 93.7 | 90.7 | |
| Re-ranking (R) and Query Expansion (QE) | ||||||||
| VGG | CroW+QE [55] | no | 74.9 | 70.6 | 84.8 | 71.0 | - | - |
| R-MAC+R+QE [24] | no | 77.3 | 73.2 | 86.5 | 79.8 | - | - | |
| BoW-CNN+R+QE [28] | no | 78.8 | 65.1 | 84.8 | 64.1 | - | - | |
| R-MAC+QE [33] | yes | 89.1 | 87.3 | 91.2 | 86.8 | - | - | |
| GeM+αQE [37] | yes | 91.9 | 89.6 | 91.9 | 87.6 | - | - | |
| *ours | yes | 92.2 | 89.8 | 94.8 | 89.5 | - | - | |
| Res | R-MAC+QE [24] ‡ | no | 78.9 | 75.5 | 89.7 | 85.3 | - | - |
| R-MAC+QE [13] | yes | 90.6 | 89.4 | 96.0 | 93.2 | - | - | |
| GeM+αQE [37] | yes | 91.0 | 89.5 | 95.5 | 91.9 | - | - | |
| *ours | yes | 92.4 | 90.0 | 96.7 | 93.9 | - | - | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, L.; Zhao, H.; Zhao, H.; Liu, P.; Hu, H. Distribution Structure Learning Loss (DSLL) Based on Deep Metric Learning for Image Retrieval. Entropy 2019, 21, 1121. https://doi.org/10.3390/e21111121
Fan L, Zhao H, Zhao H, Liu P, Hu H. Distribution Structure Learning Loss (DSLL) Based on Deep Metric Learning for Image Retrieval. Entropy. 2019; 21(11):1121. https://doi.org/10.3390/e21111121
Chicago/Turabian StyleFan, Lili, Hongwei Zhao, Haoyu Zhao, Pingping Liu, and Huangshui Hu. 2019. "Distribution Structure Learning Loss (DSLL) Based on Deep Metric Learning for Image Retrieval" Entropy 21, no. 11: 1121. https://doi.org/10.3390/e21111121
APA StyleFan, L., Zhao, H., Zhao, H., Liu, P., & Hu, H. (2019). Distribution Structure Learning Loss (DSLL) Based on Deep Metric Learning for Image Retrieval. Entropy, 21(11), 1121. https://doi.org/10.3390/e21111121