1. Introduction
Owing to the growing amount of data from various applied fields and unstoppable computer progress, there is increasing motivation on developing efficient and flexible statistical models. Such models can be derived from general families of distributions having desirable properties, such as those constructed from a generator distribution. The main idea of this construction is to add shape parameter(s) to a baseline distribution with the aim to upgrade its flexibility level. Among the well-known examples of such families, there are the beta-G [
1], Kumaraswamy-G [
2], Weibull-GG [
3], Garhy-G [
4], type II half logistic-G [
5], Transmuted Topp–Leone G [
6], generalized odd log-logistic-G [
7], odd Fréchet-G [
8], power Lindley-G [
9], Fréchet Topp–Leone-G [
10], exponentiated generalized Topp–Leone-G [
11], and truncated inverted Kumaraswamy-G [
12]. We also refer to the exhaustive survey in [
13]. Recently, several researchers used the Topp–Leone (TL) distribution as generator distribution to develop new general families, reaching the aims of simplicity and flexibility. Among them, Ref. [
14] proposed the Topp–Leone-G (TL-G) family, Ref. [
15] introduced the power TL-G (PTL-G) family, Ref. [
16] introduced the generalized TL-G family, Ref. [
17] studied the type II TL-G family, and [
18] proposed the type II generalized TL-G family.
For the purposes of this paper, let us describe in detail the PTL-G family from [
15]. The PTL-G family is defined by the following cumulative distribution function (cdf):
with
, where
is a cdf of a baseline continuous distribution which may depend on a vector parameter
; i.e.,
. As indicated by the name, the construction of the family uses the so-called power Topp–Leone distribution as the generator distribution. In comparison to the (power one) TL-G family, Ref. [
15] demonstrated the significant impact of the parameter
on the shapes of the probability density and hazard rate functions, providing desirable modeling properties. This is particularly flagrant with the consideration of the gamma distribution as the baseline distribution, as illustrated by the graphics and applications of [
15].
In a parallel work, beyond the TL distribution and its extensions, Ref. [
19] introduced the inverse exponential-G (IE-G) family, based on the inverse exponential distribution as the generator distribution, and defined by the following cdf:
The main features of this family are being simple, with no new, additional parameters, and having a completely different nature of the former baseline cdf
owing to the combination the exponential (implicit) odd functions. An immediate remark illustrating this claim is the following: it has a fastest rate of decay to 0 when
. By the consideration of a practical data set and the exponential distribution as baseline distribution, Ref. [
19] shows that the corresponding model is better than the Lindley and exponential models (all having the same number of parameters). The nice results behind the IE-G family have been the driver for more investigations, with extended or modified versions of this family. We refer the reader to [
8,
20] for the odd Fréchet-G family, Ref. [
21] for the extended odd Fréchet-G family, and [
22] for the modified odd Fréchet-G family.
In this paper, in view of the previously mentioned literature, we introduce a new family of distributions by combining, in some senses, the PTL-G and IE-G families. It is defined by composition of their respective cdfs, i.e., by the cdf given by
with
. Thus, this cdf can be view as a polyno-exponential transformation of the baseline cdf
. The new family is called the new power TL-G (NPTL-G) family. Thus, by construction, we aim to combine the benefits of the PTL-G and IE-G families, and thus, create new statistical perspectives of various kinds. The key motivations behind the NPTL-G family are the following.
To provide very simple models and create new simple distributions.
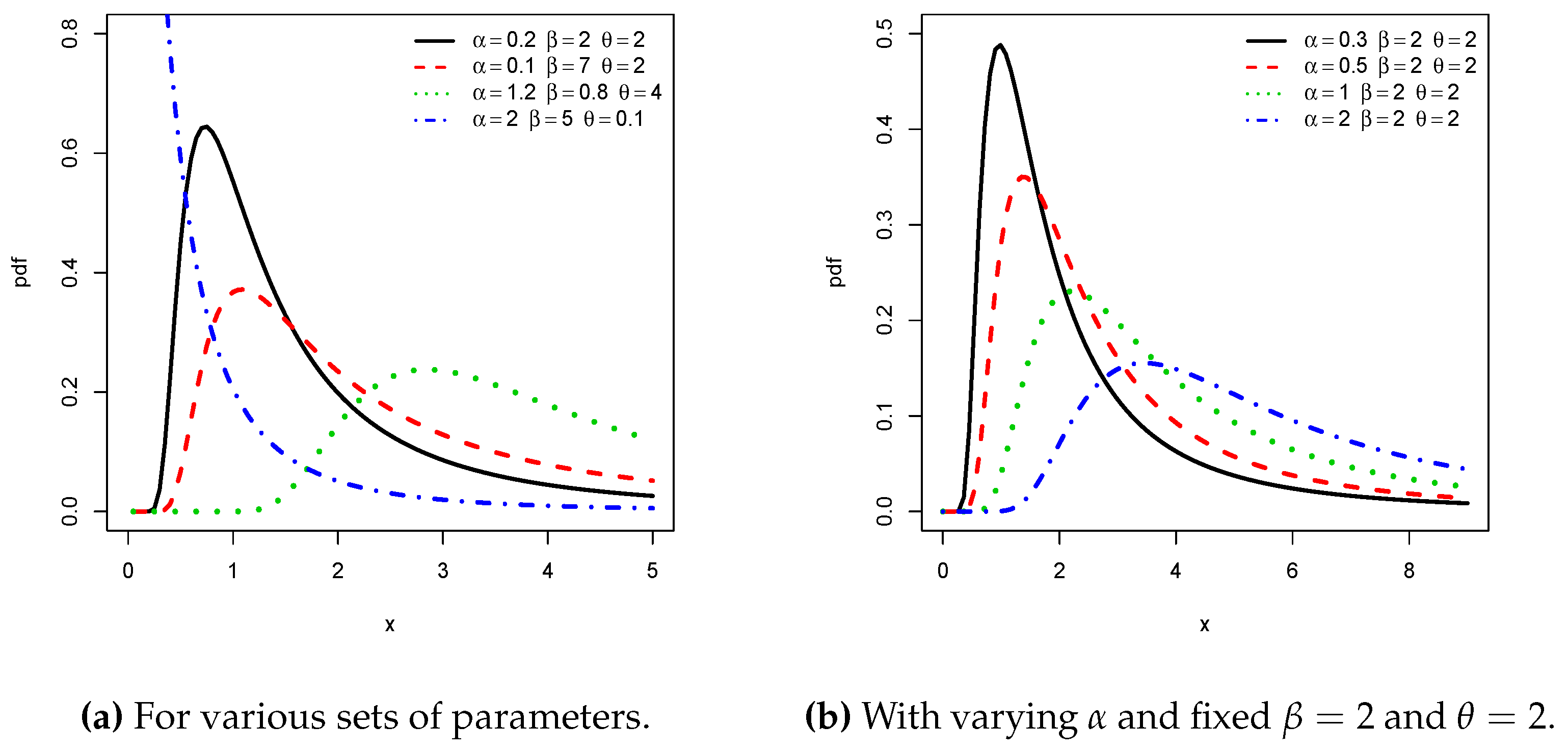
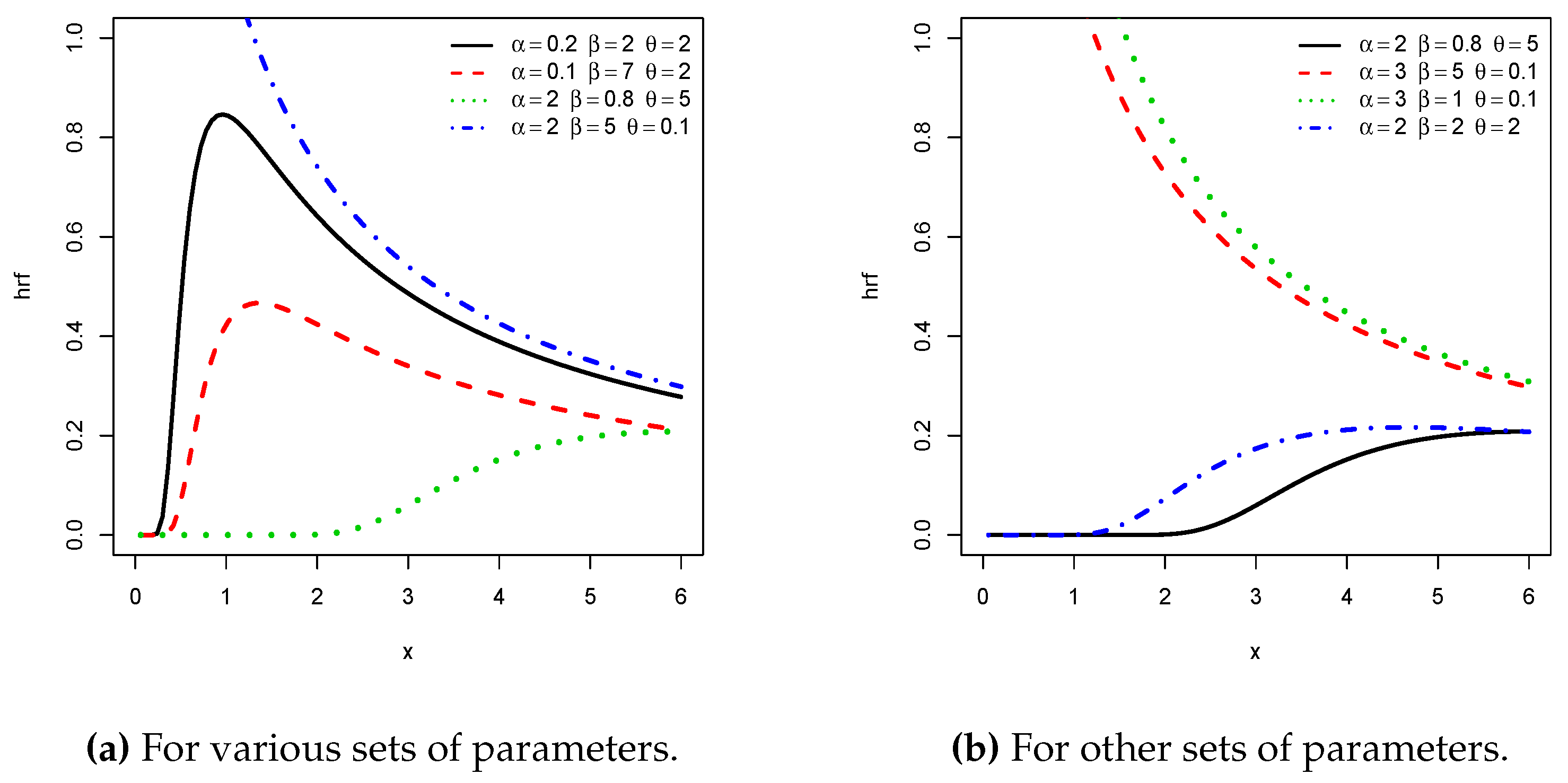
To improve the flexibility of existing distributions on various aspects (such as mode, median, skewness, and kurtosis…).
To provide better fits than competing modified models having the same of higher number of parameters.
We support these claims both in full generality and by putting the light on the special member of the NPTL-G family defined with the inverse Lomax (ILx) distribution as the baseline distribution (the reason of this choice will be explained later). The resulting distribution, called the new power Topp–Leone inverse Lomax (NPTLILx) distribution, offers a new three-parameter lifetime distribution, with a high potential of applicability. We illustrate that by the means of two practical data sets with different features: the first one is from [
23] and is about active repair times for airborne communication transceiver, and the second one is from [
24] and is about actual tax revenue in Egypt. Favorable results were obtained for the proposed model in comparison to serious competitors, motivating its use wider statistical uses.
The contents of this paper are organized as follows. In
Section 2, the basics of the NPTL-G family are presented, as is the NPTLILx distribution. Various mathematical properties of the family are discussed in
Section 3.
Section 4 is devoted to the estimation of the unknown parameters from the NPTLILx model, with a comprehensive simulation study. The data analyses are shown in
Section 5 with numerical and graphical illustrations. A conclusion and perspectives are formulated in
Section 6.
4. Estimation with Numerical Results
In this section, we investigate the NPTLILx model characterized by the cdf given by (
3). Thanks to its attractive theoretical and practical properties, the maximum likelihood method is used to estimate the parameters
,
, and
. Numerical results attest to the efficiency of the estimates obtained.
Hereafter, we consider a random variable X following the NPTLILx distribution with parameters , , and .
4.1. Maximum Likelihood Estimation
Let
be a random sample of size
n of
X. Then, by using the pdf given by (
4), the likelihood and log-likelihood functions are, respectively, given by
and
The maximum likelihood estimates (MLEs) of
,
, and
, say
,
, and
, respectively, are defined such that
or
. Let us work with the function
for the sake of simplicity. Since
is differentiable with respect to
, and
, the MLEs can obtained by solving the non-linear equations defined by the first partial derivatives of
with respect to
, and
equal to 0, with
and
The complexity of these expressions do not allow us to provide closed-forms for the MLEs. However, several numerical solutions exist to maximize based on Newton–Raphson algorithms, one of which is employed in this study.
The corresponding Fisher information matrix we observed is given by
(the elements of
are upon request from the authors). When
n is large, the distribution of the subjacent random vector behind
can be approximated by a three dimensional normal distribution with mean vector
and covariance matrix
. By denoting
,
and
, the diagonal elements of this matrix, we are able to construct asymptotic confidence intervals for
,
, and
. Indeed, with the adopted notations, the asymptotic (equitailed) confidence intervals (CIs) of
,
, and
at the level
are given by, respectively,
and
where
is the upper
-th percentile of the normal distribution
. For practical purposes, if lower bounds of these intervals are negative, we can put it at 0, since all the parameters are supposed to be positive. All the technical details can be found in [
33].
4.2. Numerical Results
Here, we provide a simulation study to show the nice behavior of the MLEs for the NPTLILx model presented in the subsection above. First of all, let us mention that a random sample from X can be obtained by the use of the qf: for any random sample of size n from the uniform distribution , say , the corresponding random sample of size n of X is given by with .
From N random samples of X, let be either , , or and be the MLE of constructed from the i-th sample. Then, we define the (mean) MLE, bias, and mean square error (MSE) by, respectively,
Additionally, the asymptotic (mean) confidence intervals of
,
, and
at the level
can be determined. We define the (mean) lower bounds (LBs), (mean) upper bounds (UBs), and (mean) average length (ALs) by, respectively,
where
. For the purposes of this study, we consider the levels
and
, so
and
, respectively. The software
Mathematica 9 was employed.
Our simulation study was based on the the following plan.
random samples of size , 200, 300, and 1000 are to be generated from X.
Values of the true parameters are taken as, in order, , , and .
The MLEs, MSEs, biases, LBs, UBs, and ALs for the selected values of the parameters are to be calculated.
From
Table 4,
Table 5 and
Table 6, we can see that, when
n increases, biases, MSEs, and ALs decrease. This observation is consistent with the well-known convergence properties of the MLEs.
5. Data Analysis
In this section, we prove the flexibility of the NPTLILx model by analyzing two practical datasets. The fits of the NPTLILx model are compared to the competitive models listed in
Table 7. The common point of all of them is the use the inverse Lomax distribution as the baseline distribution.
Except the former inverse Lomax distribution, the considered models possess three or four parameters. The comparison of these models was performed by using the following well-known statistical benchmarks: CVM (Cramér–von Mises); AD (Anderson–Darling); KS (Kolmogorov–Smirnov) statistic with the corresponding p-value, minus log-likelihood ; AIC (Akaike information criterion); CAIC (corrected Akaike information criterion); BIC (Bayesian information criterion); and HQIC (Hannan–Quinn information criterion). For the CVM, AD, KS, , AIC, CAIC, BIC, and HQIC, the smaller the value is, the better the fit to the data. Additionally, the higher the p-values of the KS test are, the better the fit to the data. All these measures were computed by using the R software.
Dataset I: The first data refer to [
23]. It consists of 40 observations of the active repair times for airborne communication transceiver. The unit is the hour. The data are: 0.50, 0.60, 0.60, 0.70, 0.70, 0.70, 0.80, 0.80, 1.00, 1.00, 1.00, 1.00, 1.10, 1.30, 1.50, 1.50, 1.50, 1.50, 2.00, 2.00, 2.20, 2.50, 2.70, 3.00, 3.00, 3.30, 4.00, 4.00, 4.50, 4.70, 5.00, 5.40, 5.40, 7.00, 7.50, 8.80, 9.00, 10.20, 22.00, 24.50.
A basic statistical description of the data gives: , mean , standard deviation , median , skewness , and kurtosis . One can notice that the data are skewed to the right with a high kurtosis.
Dataset II: Next, we use the actual taxes dataset as described in [
24]. The data consist of the monthly actual taxes revenue in Egypt from January 2006 to November 2010. The unit is the 1000 million Egyptian pounds. The data are: 5.9, 20.4, 14.9, 16.2, 17.2, 7.8, 6.1, 9.2, 10.2, 9.6, 13.3, 8.5, 21.6, 18.5,5.1,6.7, 17, 8.6, 9.7, 39.2, 35.7, 15.7, 9.7, 10, 4.1, 36, 8.5, 8, 9.2, 26.2, 21.9, 16.7, 21.3, 35.4, 14.3, 8.5, 10.6, 19.1, 20.5, 7.1, 7.7, 18.1, 16.5, 11.9, 7, 8.6, 12.5, 10.3, 11.2, 6.1, 8.4, 11, 11.6, 11.9, 5.2, 6.8, 8.9, 7.1, 10.8.
A basic statistical description of the data gives: , mean , standard deviation , median , skewness , and kurtosis . Thus, these data are skewed to the right with a moderate kurtosis.
The graphical and numerical analyses of these two datasets are as follows.
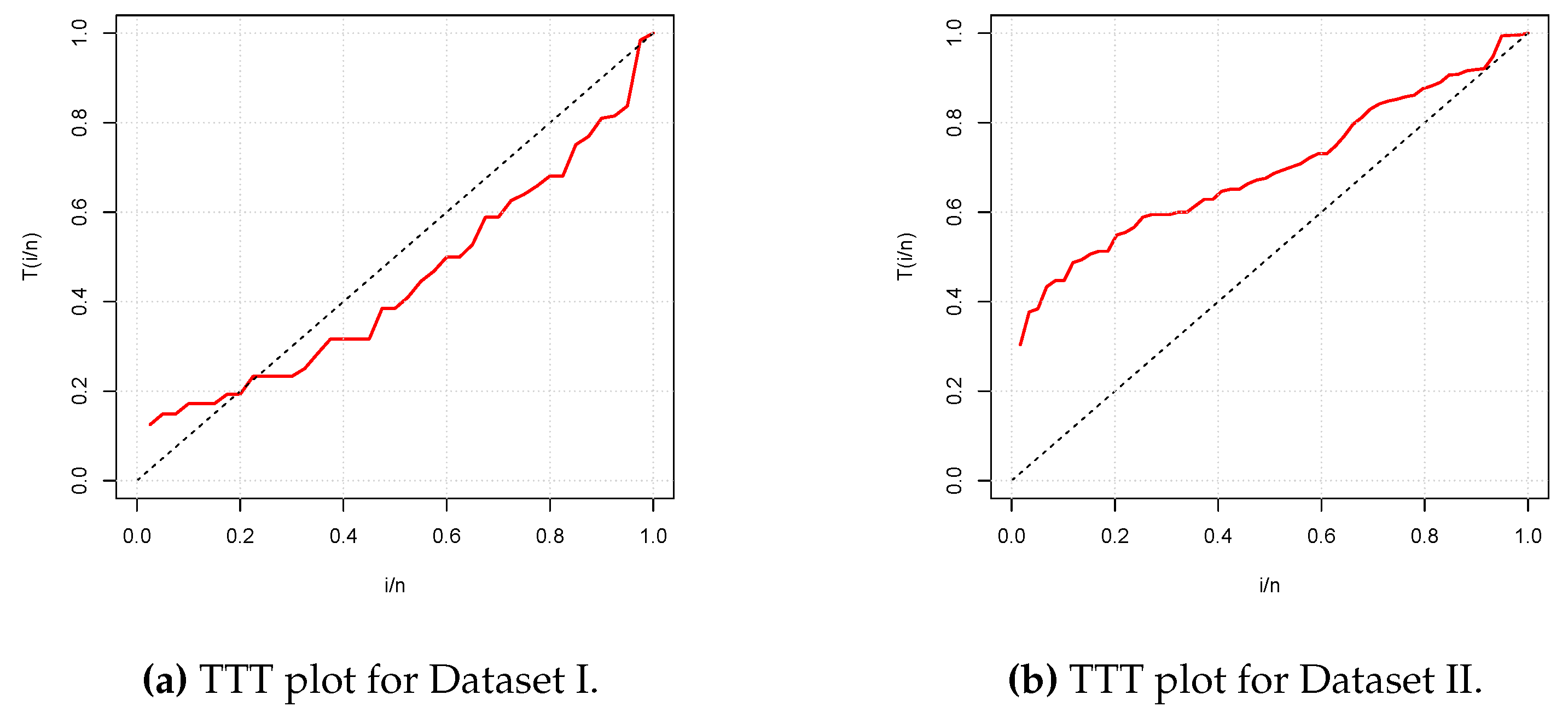
Figure 3 presents the total test time (TTT) plots of the two datasets. The first plot shows a convex curve, indicating that a decreasing hrf for the fitting model is appropriate for Data set I, whereas the second plot shows a concave curve, indicating that an increasing hrf for the fitting model is appropriate for Data set II. These cases are covered by the NPTLILx model, as shown in
Figure 2.
Table 8 and
Table 9 present the CVM, AD, KS, and the related
p-value, and the MLEs of the models’ parameters for Datasets I and II, respectively. The obtained
p-values indicate that the NPTLILx model is the best.
Table 10 and
Table 11 communicate the
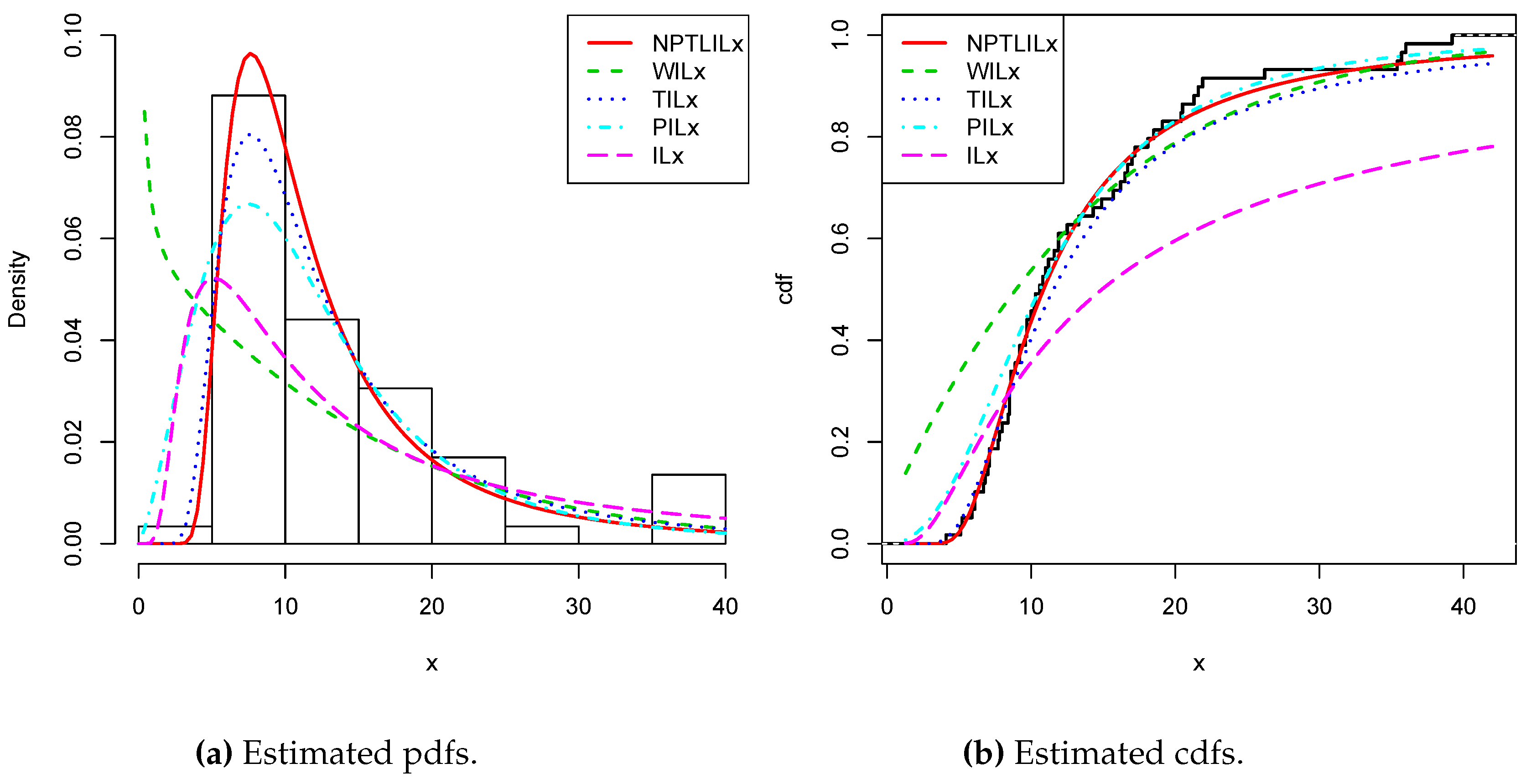
, AIC, BIC, CAIC, BIC, and HQIC of the models for Datasets I and II, respectively. Since the smallest values are obtained for the NPTLILx model, it can be considered the best with these criteria. The estimated pdfs and cdfs for the considered models are displayed in
Figure 4 and
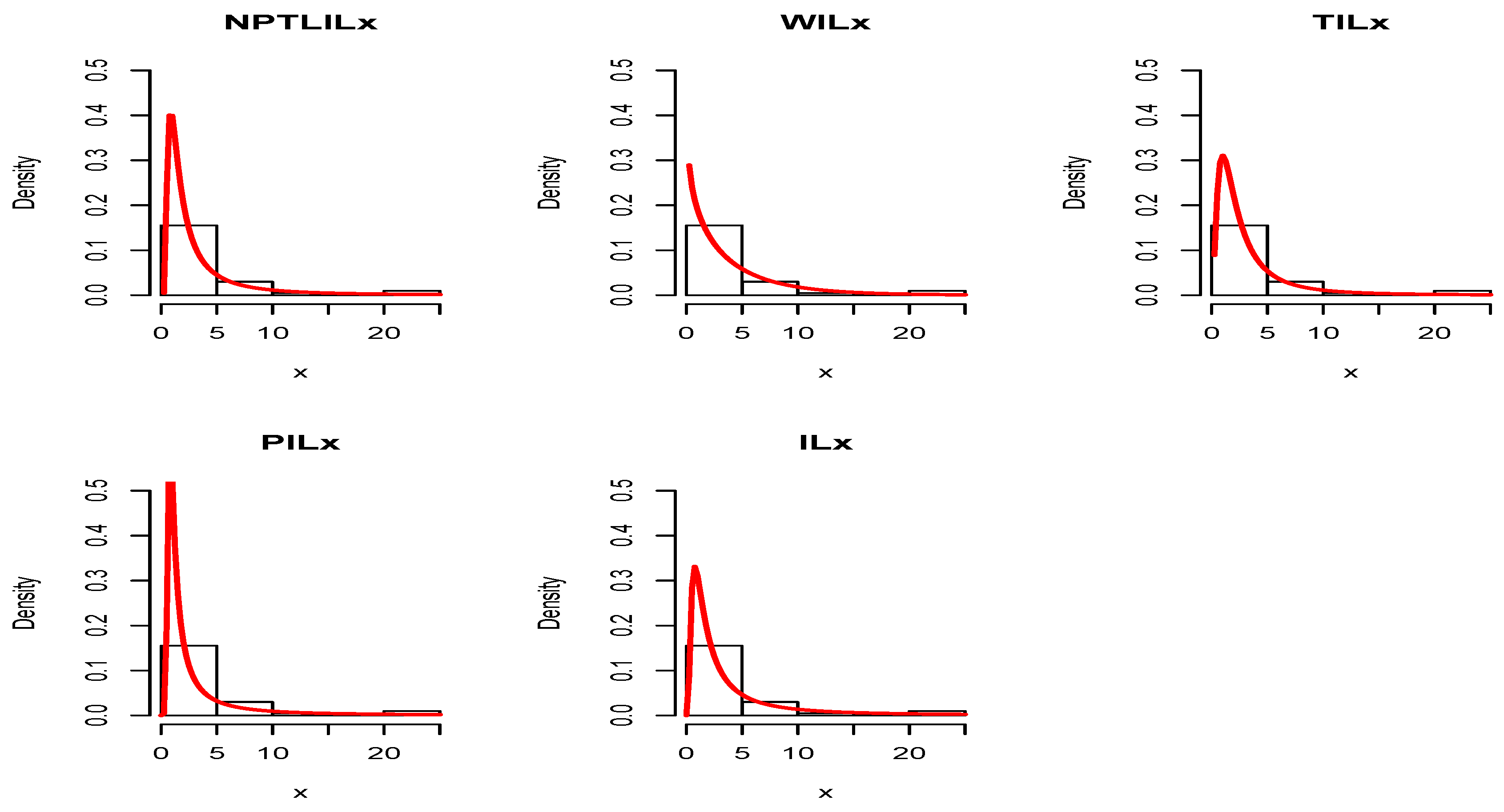
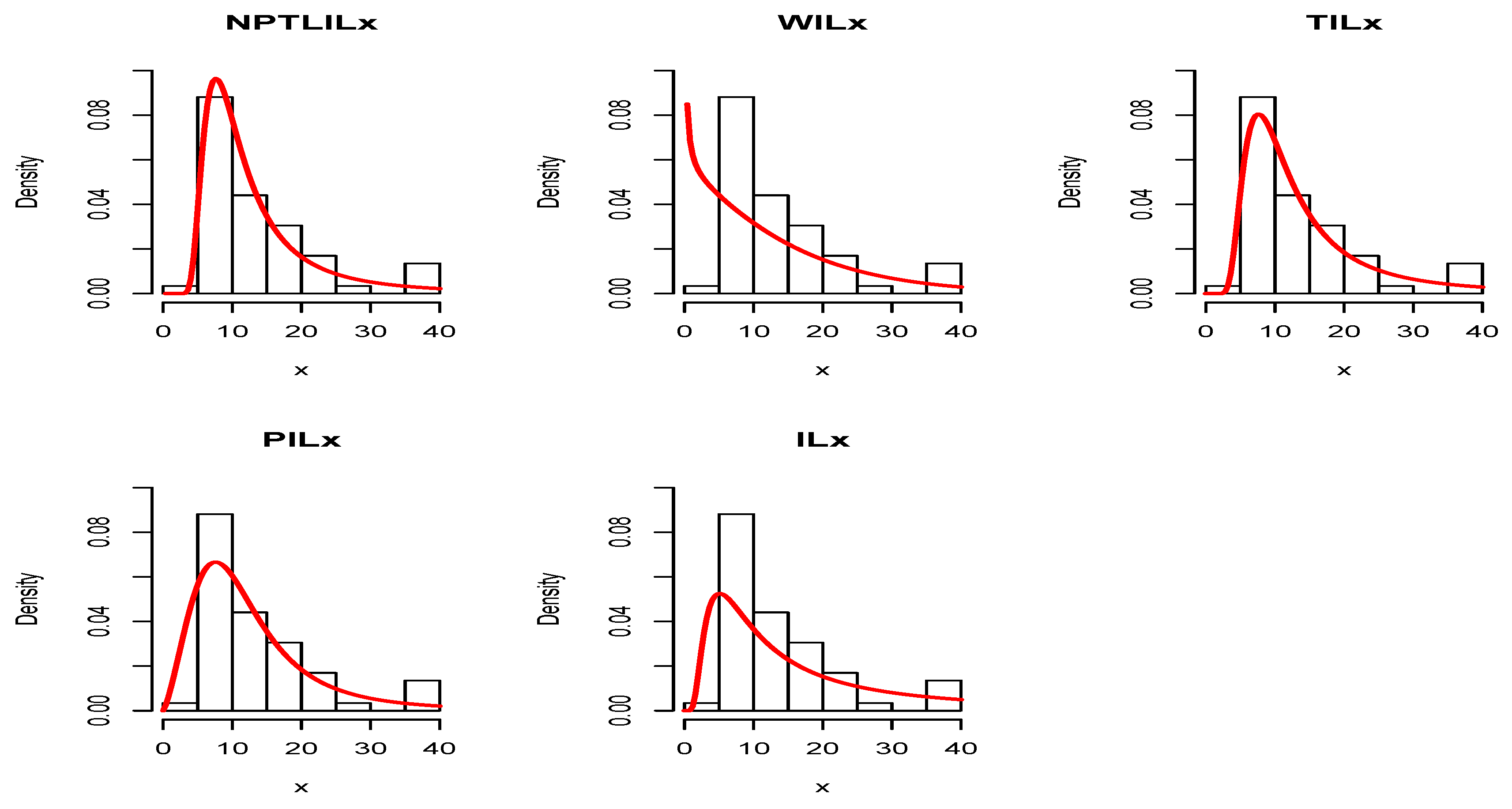
Figure 5 for Datasets I and II, respectively. The plots of the estimated pdfs are visually refined via an individual treatment in
Figure 6 and
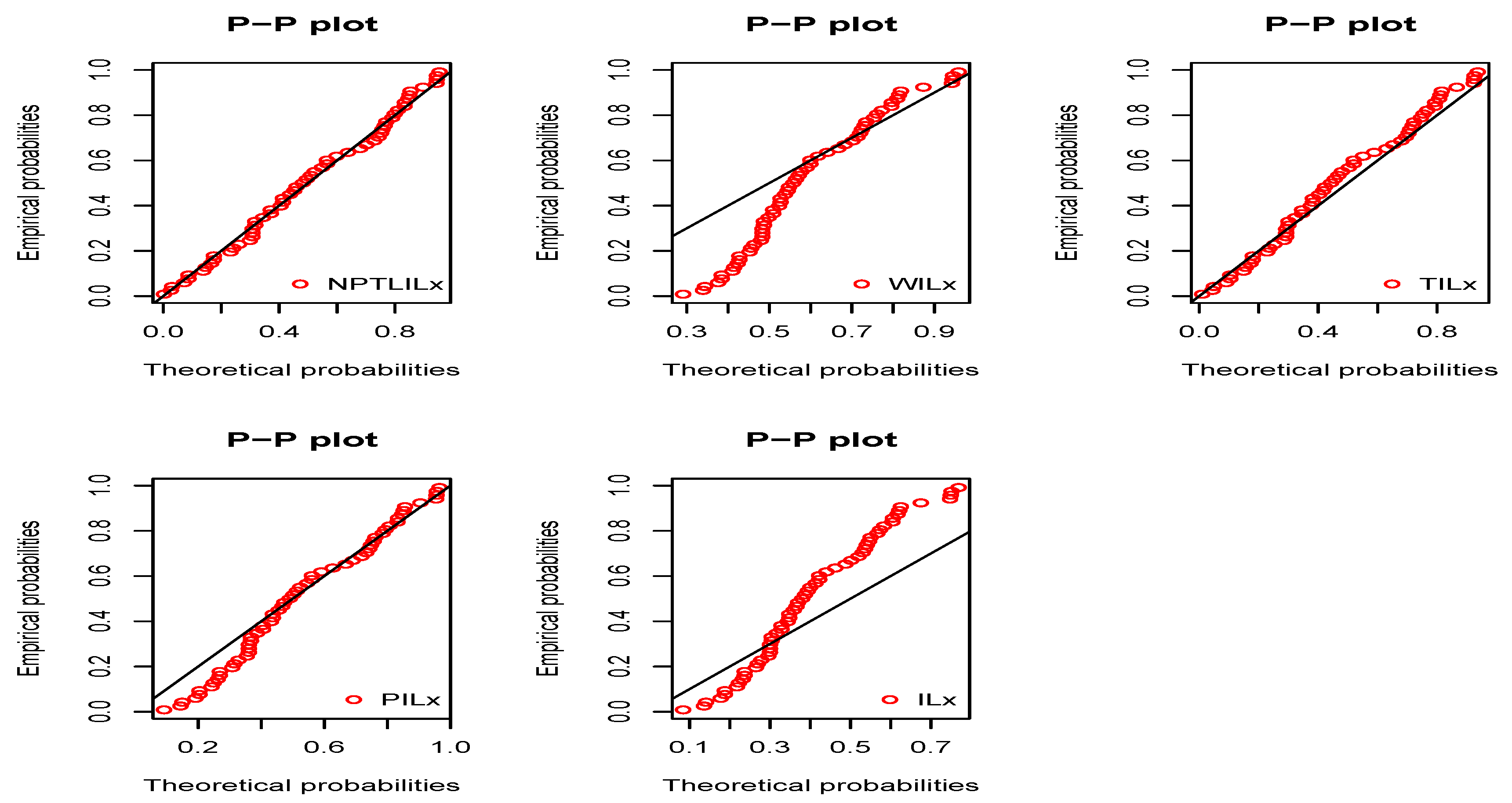
Figure 7. In order to give another point of view, we illustrate the adequateness of the models via the use of probability–probability (PP) plots in
Figure 8 and
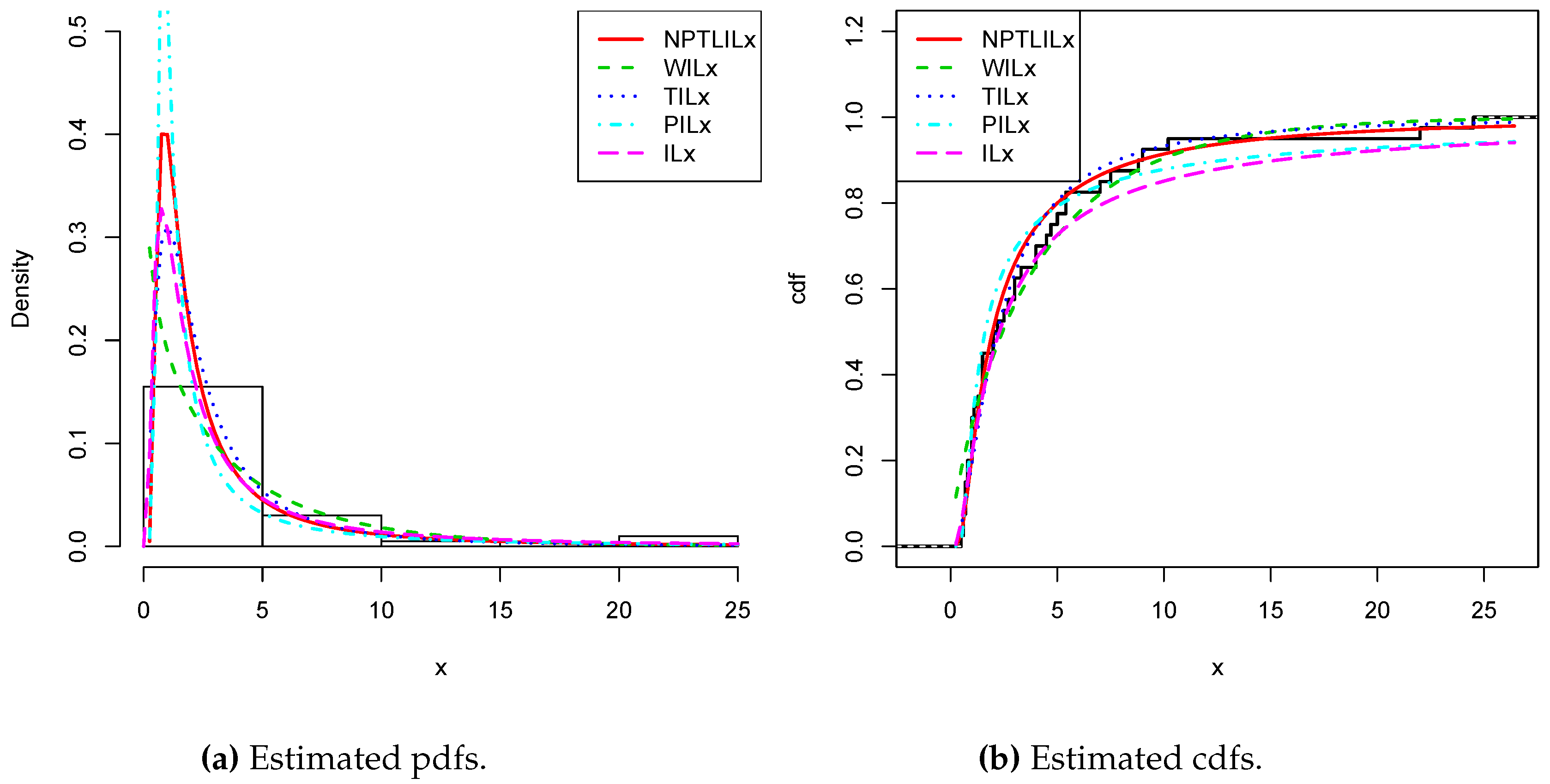
Figure 9, for Datasets I and II, respectively. In particular, for Dataset II, in view of the perfect adjustment of the scatter plot by the PP line, it is clear that the NPTLILx model provides a better fit in comparison to the other models. To resume, the NPTLILx model reveals itself to be the more appropriate model for the two datasets, illustrating its applicability in a concrete setting.
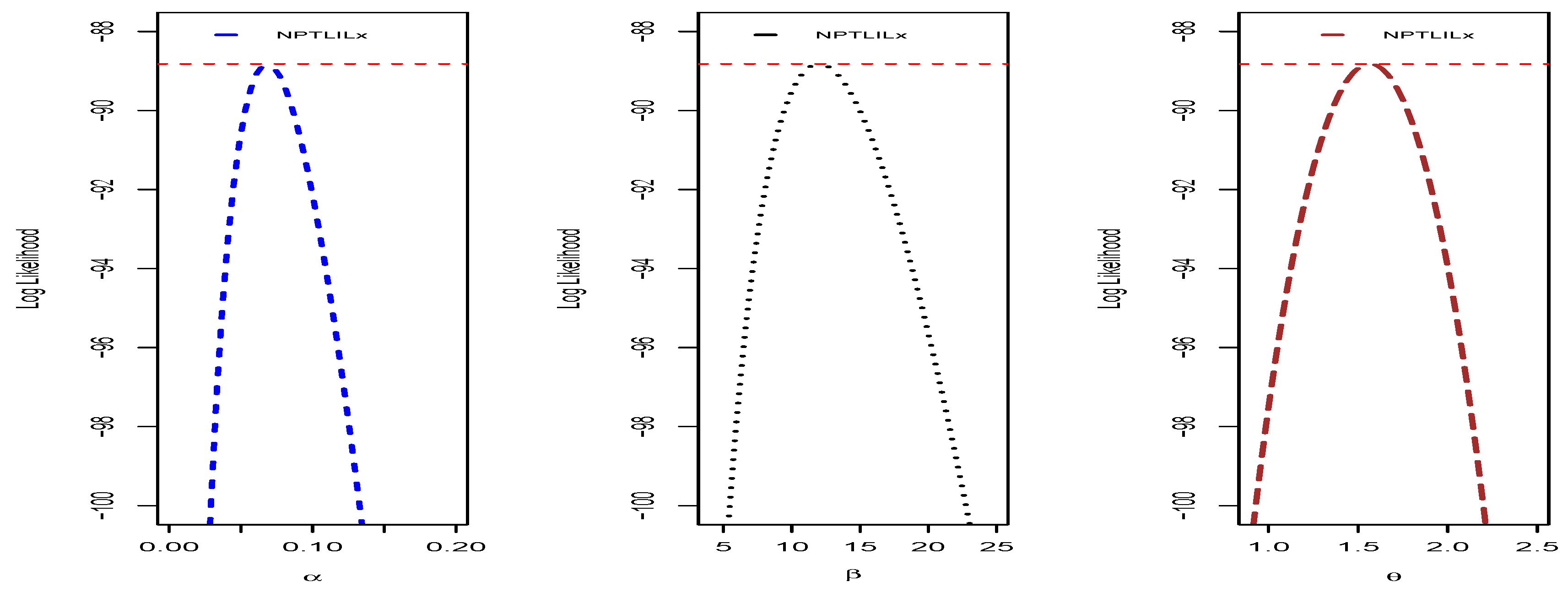
We end this section by providing some additional graphical and numerical elements on the NPTLILx model, related to the quantities presented in
Section 4.1. To illustrate the uniqueness of the MLEs of
,
and
, the profiles of the log-likelihood function are proposed in
Figure 10 and
Figure 11 for Datasets I and II, respectively. The Fisher information matrices of the NPTLILx model taken at the MLEs for Datasets I and II are, respectively, given by
Then, the confidence intervals for
,
, and
at the levels
and
are provided in
Table 12.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}