
An Information Theory-Based Approach to Assessing Spatial Patterns in Complex Systems


Abstract
:1. Introduction
2. Materials and Methods
2.1. Fisher Information
2.2. Assessing Geospatial Patterns with FI
2.3. Distance as an Ordering Parameter
- Gather data for the study area. Data should include the route (survey station) number, route location (latitude and longitude) and values for measured variables.
- Use the latitude and longitude for each station to compute the distance from a reference location. Here, the reference location is defined as the minimum latitude and longitude from the data. The Haversine distance from the reference location is computed for all routes.
- Order the data into a sequence of points by the Haversine distance from the reference location (from close to far).
- Divide the data into windows which capture small geographical “sections” of the area based on the proximity to the reference station. Essentially, the first window will contain the data from the stations that are closest to the reference site. The following window will advance forward to the next closest station, and so on. As noted in Section 2.1., each window will contain at least 8 stations.
- Estimate the measurement uncertainty for each variable (size of states) using the amount of variation in a stable portion of the study dataset or within a similar system as a proxy [70].
- In each window, bin points into states of the system using the sost.
- Count the number of points grouped into each state and divide this value by the total number of points in the window to produce p(s).
- Compute q(s) = √p(s) and calculate FI using Equation (2).
- Repeat steps 6–8 for each window.
2.4. Case Studies
3. Results
3.1. Case Study: Simulating Geospatial Dynamics
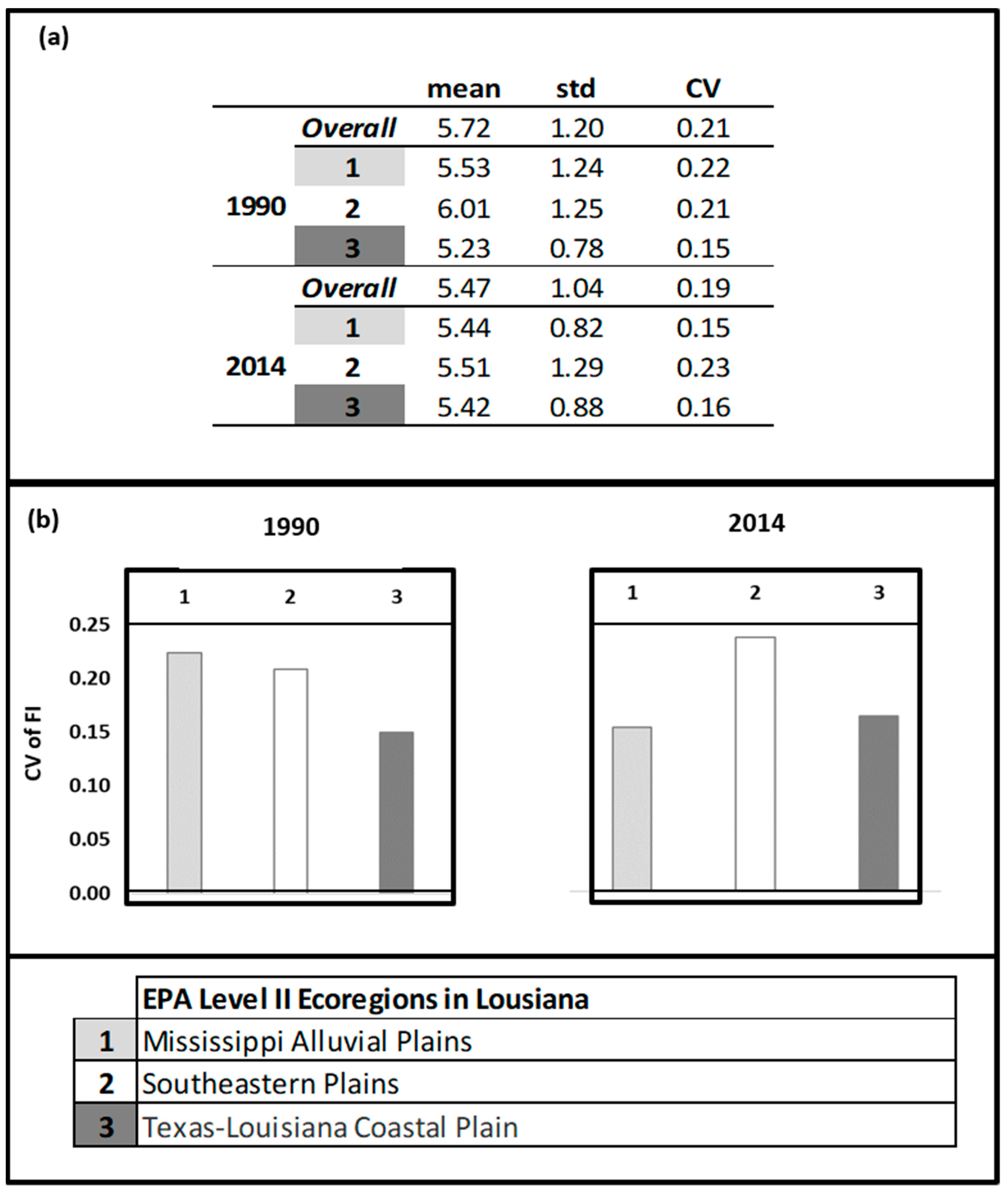
3.2. Case Study: Breeding Bird Survey Data
4. Discussion and Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Disclaimer
References
- Ahmad, N.; Derrible, S.; Eason, T.; Cabezas, H. Using Fisher information to track stability in multivariate systems. R. Soc. Open Sci. 2016, 3, 160582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Demšar, U.; Harris, P.; Brunsdon, C.; Fotheringham, A.; McLoone, S. Principal Component Analysis on Spatial Data: An Overview. Ann. Assoc. Am. Geogr. 2013, 103, 106–128. [Google Scholar] [CrossRef] [Green Version]
- Ward, M.D.; Gleditsch, K.S. Spatial Regression Models; Sage Publications: Thousand Oaks, CA, USA, 2008; 99p. [Google Scholar]
- Ceneda, D.; Gschwandtner, T.; May, T.; Miksch, S.; Schulz, H.J.; Streit, M.; Tominski, C. Characterizing Guidance in Visual Analytics. IEEE Trans. Vis. Comput. Graph. 2017, 23, 111–120. [Google Scholar] [CrossRef] [PubMed]
- Cook, K.A.; Thomas, J.J. Illuminating the Path: The Research and Development Agenda for Visual Analytics; Pacific Northwest National Lab. (PNNL): Richland, WA, USA, 2005. [Google Scholar]
- Andrienko, G.; Andrienko, N.; Chen, W.; Maciejewski, R.; Zhao, Y. Visual Analytics of Mobility and Transportation: State of the Art and Further Research Directions. IEEE Trans. Intell. Transp. 2017, 18, 2232–2249. [Google Scholar] [CrossRef]
- Chandrasegaran, S.; Badam, S.K.; Kisselburgh, L.; Ramani, K.; Elmqvist, N. Integrating Visual Analytics Support for Grounded Theory Practice in Qualitative Text Analysis. Comput. Graph. Forum 2017, 36, 201–212. [Google Scholar] [CrossRef]
- Grahn, K.; Westerlund, M.; Pulkkis, G. Analytics for Network Security: A Survey and Taxonomy. Stud. Comput. Intell. 2017, 691, 175–193. [Google Scholar] [CrossRef]
- Szewranski, S.; Kazak, J.; Sylla, M.; Swiader, M. Spatial Data Analysis with the Use of ArcGIS and Tableau Systems. In The Rise of Big Spatial Data; Springer: Cham, Switzerland, 2017; pp. 337–349. [Google Scholar]
- Robertson, G.; Ebert, D.; Eick, S.; Keim, D.; Joy, K. Scale and complexity in visual analytics. Inf. Vis. 2009, 8, 247–253. [Google Scholar] [CrossRef]
- Clements, C.F.; Ozgul, A. Indicators of transitions in biological systems. Ecol. Lett. 2018, 21, 905–919. [Google Scholar] [CrossRef] [Green Version]
- Scheffer, M. Critical Transitions in Nature and Society; Princeton University Press: Princeton, NJ, USA, 2009; 384p. [Google Scholar]
- Dakos, V.; Carpenter, S.R.; Brock, W.A.; Ellison, A.M.; Guttal, V.; Ives, A.R.; Kefi, S.; Livina, V.; Seekell, D.A.; van Nes, E.H.; et al. Methods for Detecting Early Warnings of Critical Transitions in Time Series Illustrated Using Simulated Ecological Data. PLoS ONE 2012, 7, e41010. [Google Scholar] [CrossRef]
- Scheffer, M.; Carpenter, S.R.; Dakos, V.; van Nes, E.H. Generic Indicators of Ecological Resilience: Inferring the Chance of a Critical Transition. Annu. Rev. Ecol. Evol. Syst. 2015, 46, 145–167. [Google Scholar] [CrossRef]
- Batt, R.D.; Brock, W.A.; Carpenter, S.R.; Cole, J.J.; Pace, M.L.; Seekell, D.A. Asymmetric response of early warning indicators of phytoplankton transition to and from cycles. Theor. Ecol. 2013, 6, 285–293. [Google Scholar] [CrossRef]
- Eason, T.; Garmestani, A.S.; Cabezas, H. Managing for resilience: Early detection of regime shifts in complex systems. Clean. Technol. Environ. 2014, 16, 773–783. [Google Scholar] [CrossRef]
- Eason, T.; Garmestani, A.S.; Stow, C.A.; Rojo, C.; Alvarez-Cobelas, M.; Cabezas, H. Managing for resilience: An information theory-based approach to assessing ecosystems. J. Appl. Ecol. 2016, 53, 656–665. [Google Scholar] [CrossRef]
- Perretti, C.T.; Munch, S.B. Regime shift indicators fail under noise levels commonly observed in ecological systems. Ecol. Appl. 2012, 22, 1772–1779. [Google Scholar] [CrossRef] [PubMed]
- Seekell, D.A.; Carpenter, S.R.; Pace, M.L. Conditional Heteroscedasticity as a Leading Indicator of Ecological Regime Shifts. Am. Nat. 2011, 178, 442–451. [Google Scholar] [CrossRef] [PubMed]
- Boettiger, C.; Ross, N.; Hastings, A. Early warning signals: The charted and uncharted territories. Theor. Ecol. 2013, 6, 255–264. [Google Scholar] [CrossRef]
- Burthe, S.J.; Henrys, P.A.; Mackay, E.B.; Spears, B.M.; Campbell, R.; Carvalho, L.; Dudley, B.; Gunn, I.D.M.; Johns, D.G.; Maberly, S.C.; et al. Do early warning indicators consistently predict nonlinear change in long-term ecological data? J. Appl. Ecol. 2016, 53, 666–676. [Google Scholar] [CrossRef]
- Dakos, V.; van Nes, E.H.; Donangelo, R.; Fort, H.; Scheffer, M. Spatial correlation as leading indicator of catastrophic shifts. Theor. Ecol. 2010, 3, 163–174. [Google Scholar] [CrossRef]
- Guttal, V.; Jayaprakash, C. Changing skewness: An early warning signal of regime shifts in ecosystems. Ecol. Lett. 2008, 11, 450–460. [Google Scholar] [CrossRef]
- Donangelo, R.; Fort, H.; Dakos, V.; Scheffer, M.; Van Nes, E.H. Early Warnings for Catastrophic Shifts in Ecosystems: Comparison between Spatial and Temporal Indicators. Int. J. Bifurcat. Chaos 2010, 20, 315–321. [Google Scholar] [CrossRef]
- Eby, S.; Agrawal, A.; Majumder, S.; Dobson, A.P.; Guttal, V. Alternative stable states and spatial indicators of critical slowing down along a spatial gradient in a savanna ecosystem. Glob. Ecol. Biogeogr. 2017, 26, 638–649. [Google Scholar] [CrossRef]
- Ratajczak, Z.; D’Odorico, P.; Nippert, J.B.; Collins, S.L.; Brunsell, N.A.; Ravi, S. Changes in spatial variance during a grassland to shrubland state transition. J. Ecol. 2017, 105, 750–760. [Google Scholar] [CrossRef]
- Streeter, R.; Dugmore, A.J. Anticipating land surface change. Proc. Natl. Acad. Sci. USA 2013, 110, 5779–5784. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kefi, S.; Guttal, V.; Brock, W.A.; Carpenter, S.R.; Ellison, A.M.; Livina, V.N.; Seekell, D.A.; Scheffer, M.; van Nes, E.H.; Dakos, V. Early Warning Signals of Ecological Transitions: Methods for Spatial Patterns. PLoS ONE 2014, 9, 213–217. [Google Scholar] [CrossRef] [PubMed]
- Génin, A.; Majumder, S.; Sankaran, S.; Schneider, F.D.; Danet, A.; Berdugo, M.; Guttal, V.; Kéfi, S. Spatially heterogeneous stressors can alter the performance of indicators of regime shifts. Ecol. Indic. 2018, 94, 520–533. [Google Scholar] [CrossRef]
- Schneider, F.D.; Kefi, S. Spatially heterogeneous pressure raises risk of catastrophic shifts. Theor. Ecol. 2016, 9, 207–217. [Google Scholar] [CrossRef]
- Berdugo, M.; Kefi, S.; Soliveres, S.; Maestre, F.T. Plant spatial patterns identify alternative ecosystem multifunctionality states in global drylands. Nat. Ecol. Evol. 2017, 1, 0003. [Google Scholar] [CrossRef]
- Kefi, S.; Rietkerk, M.; Alados, C.L.; Pueyo, Y.; Papanastasis, V.P.; ElAich, A.; de Ruiter, P.C. Spatial vegetation patterns and imminent desertification in Mediterranean arid ecosystems. Nature 2007, 449, 213–215. [Google Scholar] [CrossRef]
- Pueyo, S. Desertification and power laws. Landsc. Ecol. 2011, 26, 305–309. [Google Scholar] [CrossRef]
- Corrado, R.; Cherubini, A.M.; Pennetta, C. Signals of critical transitions in ecosystems associated with fluctuations of spatial patterns. In Proceedings of the 2013 22nd International Conference on Noise and Fluctuations (ICNF), Montpellier, France, 24–28 June 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Saravia, L.A.; Momo, F.R. Biodiversity collapse and early warning indicators in a spatial phase transition between neutral and niche communities. Oikos 2018, 127, 111–124. [Google Scholar] [CrossRef]
- Weissmann, H.; Kent, R.; Michael, Y.; Shnerb, N.M. Empirical analysis of vegetation dynamics and the possibility of a catastrophic desertification transition. PLoS ONE 2017, 12, e0189058. [Google Scholar] [CrossRef] [PubMed]
- Weissmann, H.; Shnerb, N.M. Predicting catastrophic shifts. J. Theor. Biol. 2016, 397, 128–134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buelo, C.; Carpenter, S.; Pace, M. A modeling analysis of spatial statistical indicators of thresholds for algal blooms. Limnol. Oceanogr. Lett. 2018, 3, 384–392. [Google Scholar] [CrossRef]
- Rindi, L.; Dal Bello, M.; Dai, L.; Gore, J.; Benedetti-Cecchi, L. Direct observation of increasing recovery length before collapse of a marine benthic ecosystem. Nat. Ecol. Evol. 2017, 1, 0153. [Google Scholar] [CrossRef] [PubMed]
- Yin, Z.; Dekker, S.C.; Rietkerk, M.; van den Hurk, B.J.J.M.; Dijkstra, H.A. Network based early warning indicators of vegetation changes in a land-atmosphere model. Ecol. Complex. 2016, 26, 68–78. [Google Scholar] [CrossRef]
- Dai, L.; Korolev, K.S.; Gore, J. Slower recovery in space before collapse of connected populations. Nature 2013, 496, 355–358. [Google Scholar] [CrossRef] [Green Version]
- Brock, W.A.; Carpenter, S.R. Early Warnings of Regime Shift When the Ecosystem Structure Is Unknown. PLoS ONE 2012, 7, e45586. [Google Scholar] [CrossRef]
- Litzow, M.A.; Mueter, F.J.; Urban, J.D. Rising catch variability preceded historical fisheries collapses in Alaska. Ecol. Appl. 2013, 23, 1475–1487. [Google Scholar] [CrossRef]
- Seekell, D.A.; Carpenter, S.R.; Cline, T.J.; Pace, M.L. Conditional Heteroskedasticity Forecasts Regime Shift in a Whole-Ecosystem Experiment. Ecosystems 2012, 15, 741–747. [Google Scholar] [CrossRef]
- Lindegren, M.; Dakos, V.; Groger, J.P.; Gardmark, A.; Kornilovs, G.; Otto, S.A.; Mollmann, C. Early Detection of Ecosystem Regime Shifts: A Multiple Method Evaluation for Management Application. PLoS ONE 2012, 7, e38410. [Google Scholar] [CrossRef] [Green Version]
- Brock, W.A.; Carpenter, S.R. Variance as a leading indicator of regime shift in ecosystem services. Ecol. Soc. 2006, 11, 9. [Google Scholar] [CrossRef]
- Anand, M.; Orloci, L. On hierarchical partitioning of an ecological complexity function. Ecol. Model. 2000, 132, 51–62. [Google Scholar] [CrossRef]
- Fath, B.D.; Cabezas, H. Exergy and Fisher Information as ecological indices. Ecol. Model. 2004, 174, 25–35. [Google Scholar] [CrossRef] [Green Version]
- Svirezhev, Y.M. Thermodynamics and ecology. Ecol. Model. 2000, 132, 11–22. [Google Scholar] [CrossRef]
- Ulanowicz, R.E. Ecology, the Ascendent Perspective; Columbia University Press: New York, NY, USA, 1997; 201p. [Google Scholar]
- Batty, M. Spatial entropy. Geogr. Anal. 1974, 6, 1–31. [Google Scholar] [CrossRef]
- Frank, A.U.; Campari, I. Spatial Information Theory: A Theoretical Basis for GIS. In Proceedings of the European Conference, COSIT’93, Marciana Marina, Italy, 19–22 September 1993; Springer Science & Business Media: Berlin, Germany, 1993; Volume 716. [Google Scholar]
- Pászto, V.; Tuček, P.; Voženílek, V. On spatial entropy in geographical data. In Proceedings of the GIS Ostrava, Ostrava, Czech Republic, 25–28 January 2009; pp. 25–28. [Google Scholar]
- Rocchini, D.; Delucchi, L.; Bacaro, G.; Cavallini, P.; Feilhauer, H.; Foody, G.M.; He, K.S.; Nagendra, H.; Porta, C.; Ricotta, C.; et al. Calculating landscape diversity with information-theory based indices: A GRASS GIS solution. Ecol. Inform. 2013, 17, 82–93. [Google Scholar] [CrossRef]
- Scott, N.M.; Sera, M.D.; Georgopoulos, A.P. An information theory analysis of spatial decisions in cognitive development. Front. Neurosci. 2015, 9, 14. [Google Scholar] [CrossRef] [PubMed]
- Tsangaratos, P.; Ilia, I.; Hong, H.Y.; Chen, W.; Xu, C. Applying Information Theory and GIS-based quantitative methods to produce landslide susceptibility maps in Nancheng County, China. Landslides 2017, 14, 1091–1111. [Google Scholar] [CrossRef]
- Eason, T.; Cabezas, H. Evaluating the sustainability of a regional system using Fisher information in the San Luis Basin, Colorado. J. Environ. Manag. 2012, 94, 41–49. [Google Scholar] [CrossRef] [PubMed]
- Karunanithi, A.T.; Cabezas, H.; Frieden, B.R.; Pawlowski, C.W. Detection and Assessment of Ecosystem Regime Shifts from Fisher Information. Ecol. Soc. 2008, 13, 22. [Google Scholar] [CrossRef]
- Spanbauer, T.L.; Allen, C.R.; Angeler, D.G.; Eason, T.; Fritz, S.C.; Garmestani, A.S.; Nash, K.L.; Stone, J.R. Prolonged instability prior to a regime shift. PLoS ONE 2014, 9, e108936. [Google Scholar] [CrossRef] [PubMed]
- RA Fisher, M. On the mathematical foundations of theoretical statistics. Philos. Trans. R. Soc. Lond. A 1922, 222, 309–368. [Google Scholar] [CrossRef]
- Mayer, A.L.; Pawlowski, C.; Fath, B.D.; Cabezas, H. Applications of Fisher information to the management of sustainable environmental systems. In Exploratory Data Analysis Using Fisher Information; Springer: Berlin/Heidelberg, Germany, 2007; pp. 217–244. [Google Scholar]
- Eason, T.; Garmestani, A.S. Cross-scale dynamics of a regional urban system through time. Reg. Dev. 2012, 36, 55–77. [Google Scholar]
- Gonzalez-Mejia, A.M.; Eason, T.N.; Cabezas, H.; Suidan, M.T. Social and economic sustainability of urban systems: Comparative analysis of metropolitan statistical areas in Ohio, USA. Sustain. Sci. 2014, 9, 217–228. [Google Scholar] [CrossRef]
- Karunanithi, A.T.; Garmestani, A.S.; Eason, T.; Cabezas, H. The characterization of socio-political instability, development and sustainability with Fisher information. Glob. Environ. Chang. 2011, 21, 77–84. [Google Scholar] [CrossRef] [Green Version]
- Mayer, A.L.; Pawlowski, C.W.; Cabezas, H. Fisher information and dynamic regime changes in ecological systems. Ecol. Model. 2006, 195, 72–82. [Google Scholar] [CrossRef]
- Vance, L.; Eason, T.; Cabezas, H.; Gorman, M.E. Toward a leading indicator of catastrophic shifts in complex systems: Assessing changing conditions in nation states. Heliyon 2017, 3, e00465. [Google Scholar] [CrossRef] [PubMed]
- Sundstrom, S.M.; Eason, T.; Nelson, R.J.; Angeler, D.G.; Barichievy, C.; Garmestani, A.S.; Graham, N.A.; Granholm, D.; Gunderson, L.; Knutson, M.; et al. Detecting spatial regimes in ecosystems. Ecol. Lett. 2017, 20, 19–32. [Google Scholar] [CrossRef] [PubMed]
- Fath, B.D.; Cabezas, H.; Pawlowski, C.W. Regime changes in ecological systems: An information theory approach. J. Theor. Biol. 2003, 222, 517–530. [Google Scholar] [CrossRef]
- Gonzalez-Mejia, A.M. Fisher Information-Sustainability Analysis of Several US Metropolitan Statistical Areas. Ph.D. Thesis, University of Cincinnati, Cincinnati, OH, USA, 2011. [Google Scholar]
- Cabezas, H.; Eason, T. Fisher information and order. In San Luis Basin Sustainability Metrics Project: A Methodology for Assessing Regional Sustainability; Heberling, M., Hopton, M., Eds.; EPA Report Number: EPA/600/R-10/182; U.S. Environmental Protection Agency: Washington, DC, USA, 2010; pp. 163–222. Available online: http://nepis.epa.gov/Exe/ZyPURL.cgi?Dockey=P100BSKA.txt (accessed on 29 November 2018).
- Gonzalez-Mejia, A.M.; Eason, T.N.; Cabezas, H.; Suidan, M.T. Assessing sustainability in real urban systems: The Greater Cincinnati Metropolitan Area in Ohio, Kentucky, and Indiana. Environ. Sci. Technol. 2012, 46, 9620–9629. [Google Scholar] [CrossRef]
- Veness, C. Calculate Distance, Bearing and More between Latitude/Longitude Points. Available online: https://www.movable-type.co.uk/scripts/latlong.html (accessed on 29 November 2018).
- Sohrabinia, M. LatLon Distance (Function: Ldistkm.m). Available online: https://www.mathworks.com/matlabcentral/fileexchange/38812-latlon-distance (accessed on 29 November 2018).
- Pardieck, K.L.; Ziolkowski, D.J., Jr.; Lutmerding, M.; Hudson, M.A.R. North American Breeding Bird Survey Dataset 1966–2017, Version 2017.0. Available online: https://doi.org/10.5066/F76972V8 (accessed on 5 March 2018).
- U.S. Geological Survey. Land Cover Data Portal. Available online: https://gapanalysis.usgs.gov:443/index.php (accessed on 12 December 2018).
- U.S. Environmental Protection Agency. Ecological Regions of North America Level II Map. Available online: https://www.epa.gov/eco-research/ecoregions-north-america (accessed on 29 November 2018).
- Gonzalez-Mejia, A.M.; Eason, T.; Cabezas, H.; Suidan, M.T. Computing and interpreting Fisher Information as a metric of sustainability: Regime changes in the United States air quality. Clean. Technol. Environ. 2012, 14, 775–788. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
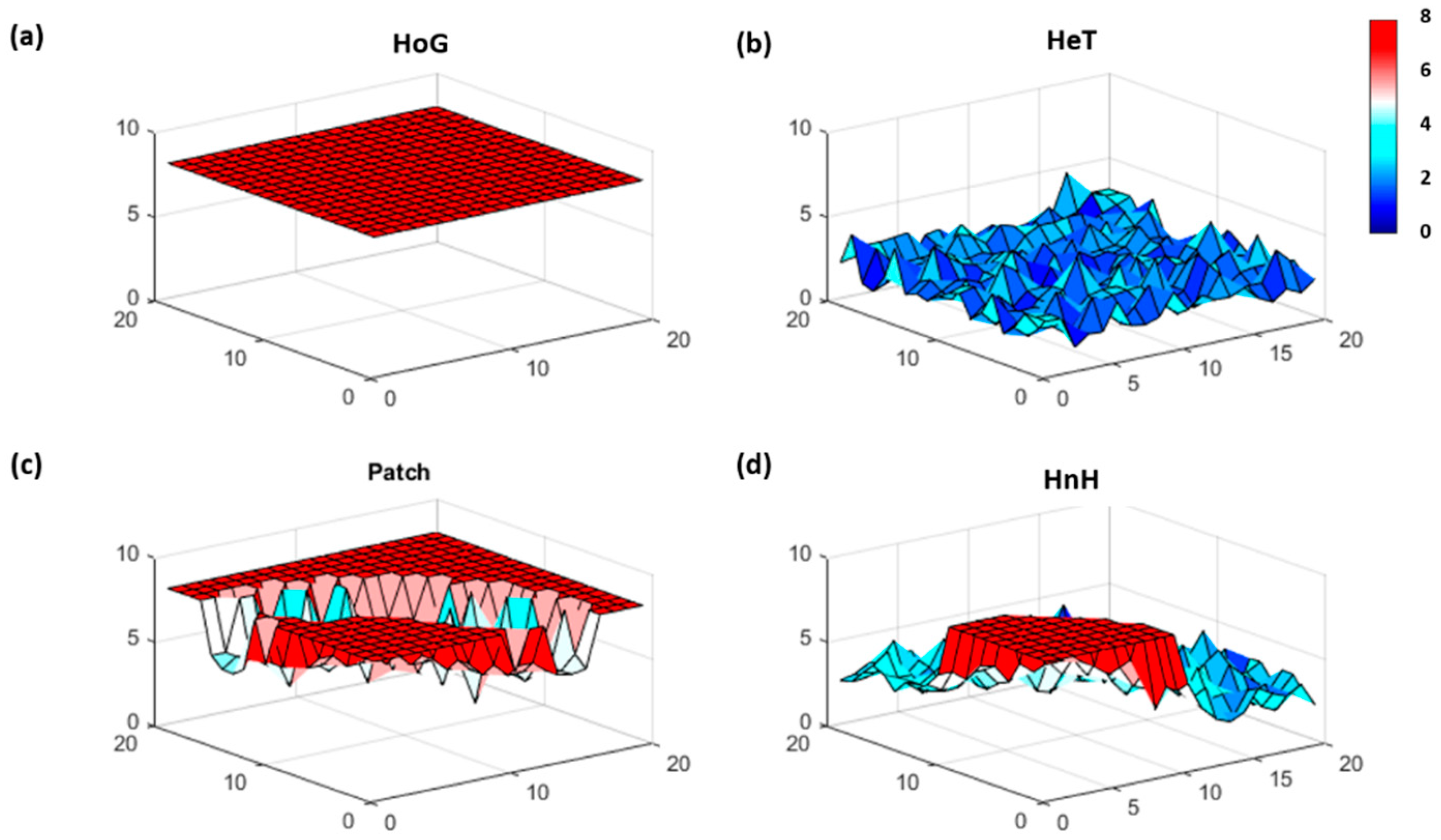
| Pattern | Variable Dynamics | Simulation Parameters | Expected FI |
|---|---|---|---|
| Homogeneous (HoG) | Relatively stable | HoG: mean (μ) = 50, STD (σ) = 2 | FI→∞ (8) |
| Heterogeneous (HeT) | Highly variable | HeT: μ = 50, σ = 20 | FI→0 |
| Half and Half (HnH) | Half stable and half variable | HnH: Half HoG and Half HeT | FI→0 & FI→∞ |
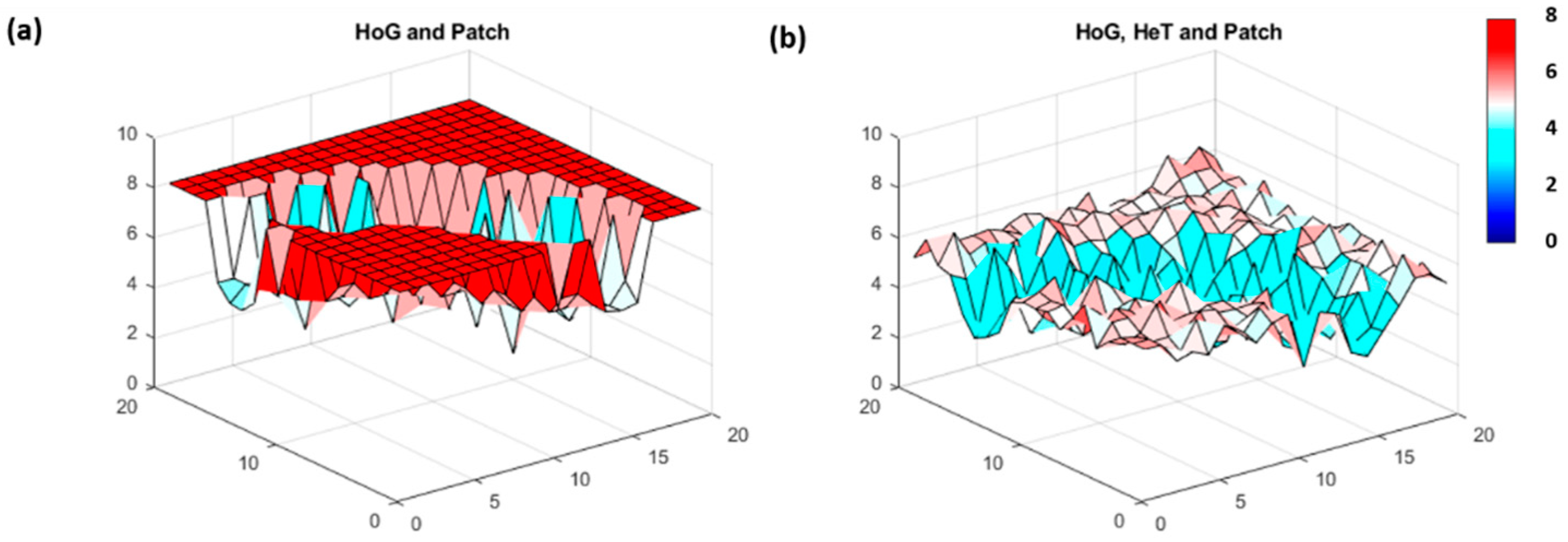
| Patch | Distinctly different patterns in a particular section | HoG with a HeT region | FI→∞ around edges and FI low toward the center |
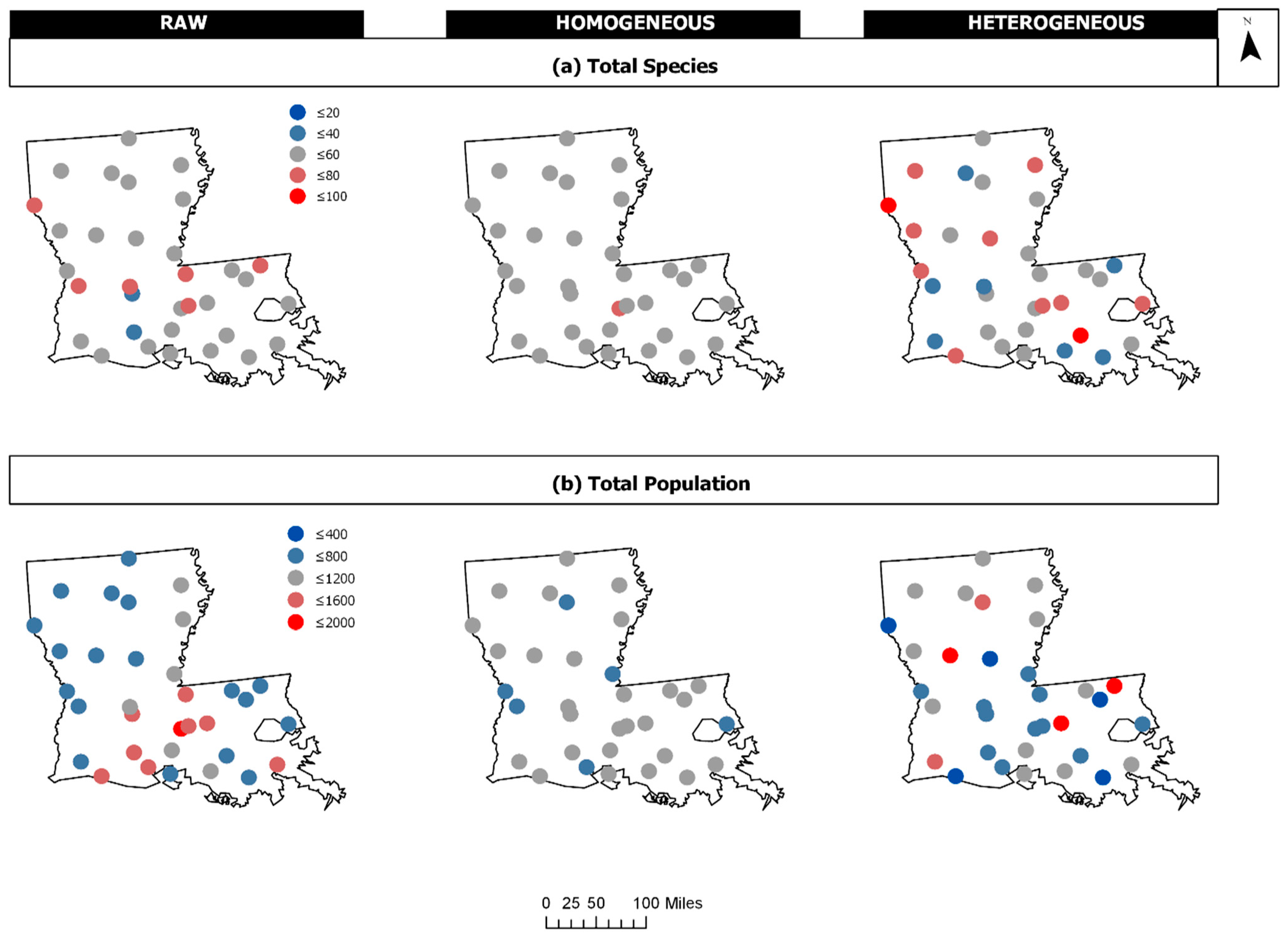
| Raw | HoG | HeT | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Route | Lon | Lat | H.dist | TS | TP | TS | TP | TS | TP |
| 15 | −93.34 | 30.01 | 49.49 | 44 | 691 | 49.92 | 834.73 | 35.87 | 1523.52 |
| 106 | −93.02 | 29.77 | 59.60 | 43 | 1290 | 52.27 | 883.70 | 63.92 | 153.10 |
| 16 | −93.32 | 30.83 | 97.00 | 61 | 613 | 52.51 | 731.16 | 31.75 | 825.01 |
| 34 | −92.45 | 30.08 | 98.51 | 37 | 1489 | 51.68 | 1041.32 | 54.66 | 791.37 |
| 31 | −92.23 | 29.85 | 106.56 | 56 | 1281 | 46.93 | 794.17 | 51.85 | 775.60 |
| 122 | −93.50 | 31.07 | 108.75 | 41 | 506 | 49.87 | 790.54 | 74.38 | 468.32 |
| 113 | −92.43 | 30.65 | 119.70 | 35 | 1557 | 50.57 | 823.04 | 50.43 | 640.17 |
| 14 | −92.46 | 30.76 | 123.33 | 72 | 1063 | 58.23 | 879.98 | 32.06 | 435.44 |
| 30 | −91.88 | 29.72 | 126.53 | 47 | 715 | 55.19 | 821.39 | 55.90 | 1044.21 |
| 11 | −91.82 | 30.06 | 133.99 | 44 | 1157 | 52.26 | 876.80 | 43.09 | 828.21 |
| 37 | −93.57 | 31.67 | 148.55 | 56 | 651 | 46.67 | 877.61 | 60.41 | 833.15 |
| 905 | −91.64 | 30.37 | 151.11 | 59 | 1620 | 61.81 | 826.36 | 49.43 | 781.67 |
| 119 | −92.96 | 31.56 | 151.78 | 60 | 743 | 57.15 | 808.26 | 50.15 | 1747.23 |
| 33 | −91.51 | 30.40 | 158.82 | 62 | 1489 | 52.50 | 904.18 | 63.54 | 769.14 |
| 20 | −92.30 | 31.46 | 165.96 | 47 | 494 | 57.40 | 1002.60 | 76.91 | 319.07 |
| 105 | −91.21 | 29.70 | 166.57 | 52 | 993 | 52.03 | 1158.78 | 24.09 | 1127.89 |
| 12 | −91.51 | 30.87 | 173.17 | 67 | 1240 | 55.97 | 852.82 | 57.46 | 664.27 |
| 27 | −93.97 | 32.07 | 174.56 | 65 | 794 | 53.39 | 909.53 | 88.35 | 391.30 |
| 903 | −91.20 | 30.41 | 176.76 | 54 | 1299 | 49.47 | 902.70 | 65.62 | 1671.22 |
| 17 | −91.67 | 31.19 | 178.09 | 55 | 941 | 53.46 | 705.92 | 56.06 | 550.18 |
| 3 | −90.92 | 29.90 | 184.86 | 53 | 544 | 56.39 | 847.28 | 91.87 | 683.87 |
| 29 | −90.59 | 29.55 | 203.67 | 47 | 728 | 48.36 | 936.93 | 26.17 | 280.84 |
| 128 | −93.48 | 32.55 | 209.80 | 54 | 644 | 54.00 | 1018.93 | 64.31 | 1059.71 |
| 125 | −92.35 | 32.31 | 213.66 | 59 | 581 | 51.46 | 772.81 | 43.86 | 1380.79 |
| 32 | −90.73 | 30.86 | 213.72 | 60 | 642 | 47.21 | 958.19 | 41.02 | 810.06 |
| 26 | −92.62 | 32.46 | 216.65 | 47 | 538 | 50.43 | 934.38 | 37.17 | 997.79 |
| 9 | −90.51 | 30.70 | 221.84 | 56 | 579 | 55.57 | 1008.05 | 56.33 | 374.07 |
| 18 | −91.44 | 31.98 | 225.42 | 49 | 929 | 51.29 | 941.20 | 50.20 | 973.77 |
| 4 | −90.10 | 29.69 | 233.14 | 55 | 1322 | 50.62 | 1071.73 | 46.51 | 1102.13 |
| 10 | −90.25 | 30.88 | 240.76 | 65 | 621 | 57.23 | 892.86 | 35.60 | 1707.91 |
| 208 | −89.85 | 30.27 | 252.32 | 52 | 493 | 54.61 | 780.47 | 65.70 | 432.20 |
| 38 | −91.43 | 32.49 | 252.94 | 41 | 1007 | 54.56 | 876.27 | 66.42 | 1163.80 |
| 39 | −92.28 | 32.95 | 255.62 | 57 | 650 | 55.31 | 908.47 | 41.62 | 1036.88 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eason, T.; Chuang, W.-C.; Sundstrom, S.; Cabezas, H. An Information Theory-Based Approach to Assessing Spatial Patterns in Complex Systems. Entropy 2019, 21, 182. https://doi.org/10.3390/e21020182
Eason T, Chuang W-C, Sundstrom S, Cabezas H. An Information Theory-Based Approach to Assessing Spatial Patterns in Complex Systems. Entropy. 2019; 21(2):182. https://doi.org/10.3390/e21020182
Chicago/Turabian StyleEason, Tarsha, Wen-Ching Chuang, Shana Sundstrom, and Heriberto Cabezas. 2019. "An Information Theory-Based Approach to Assessing Spatial Patterns in Complex Systems" Entropy 21, no. 2: 182. https://doi.org/10.3390/e21020182
APA StyleEason, T., Chuang, W. -C., Sundstrom, S., & Cabezas, H. (2019). An Information Theory-Based Approach to Assessing Spatial Patterns in Complex Systems. Entropy, 21(2), 182. https://doi.org/10.3390/e21020182