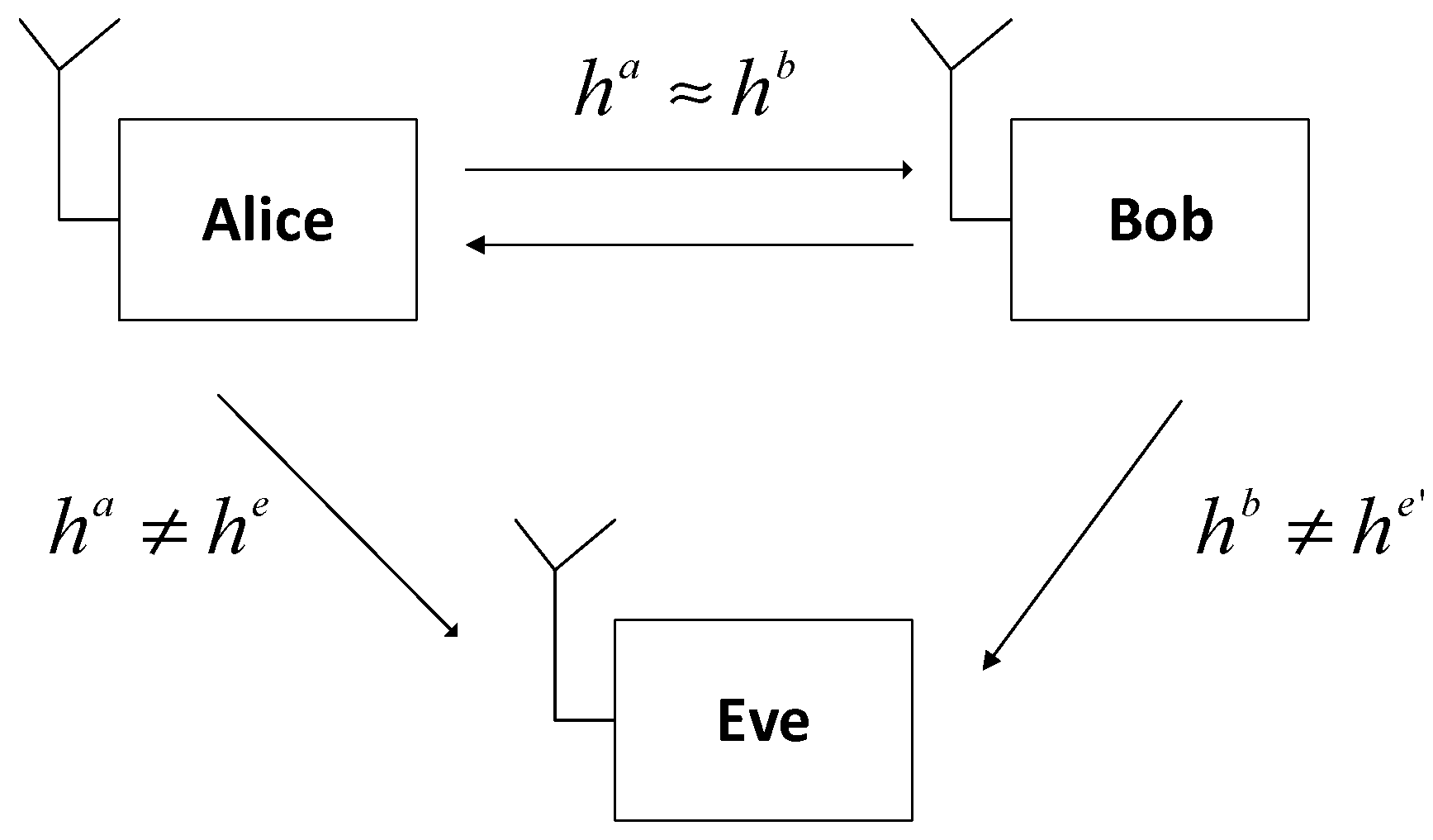
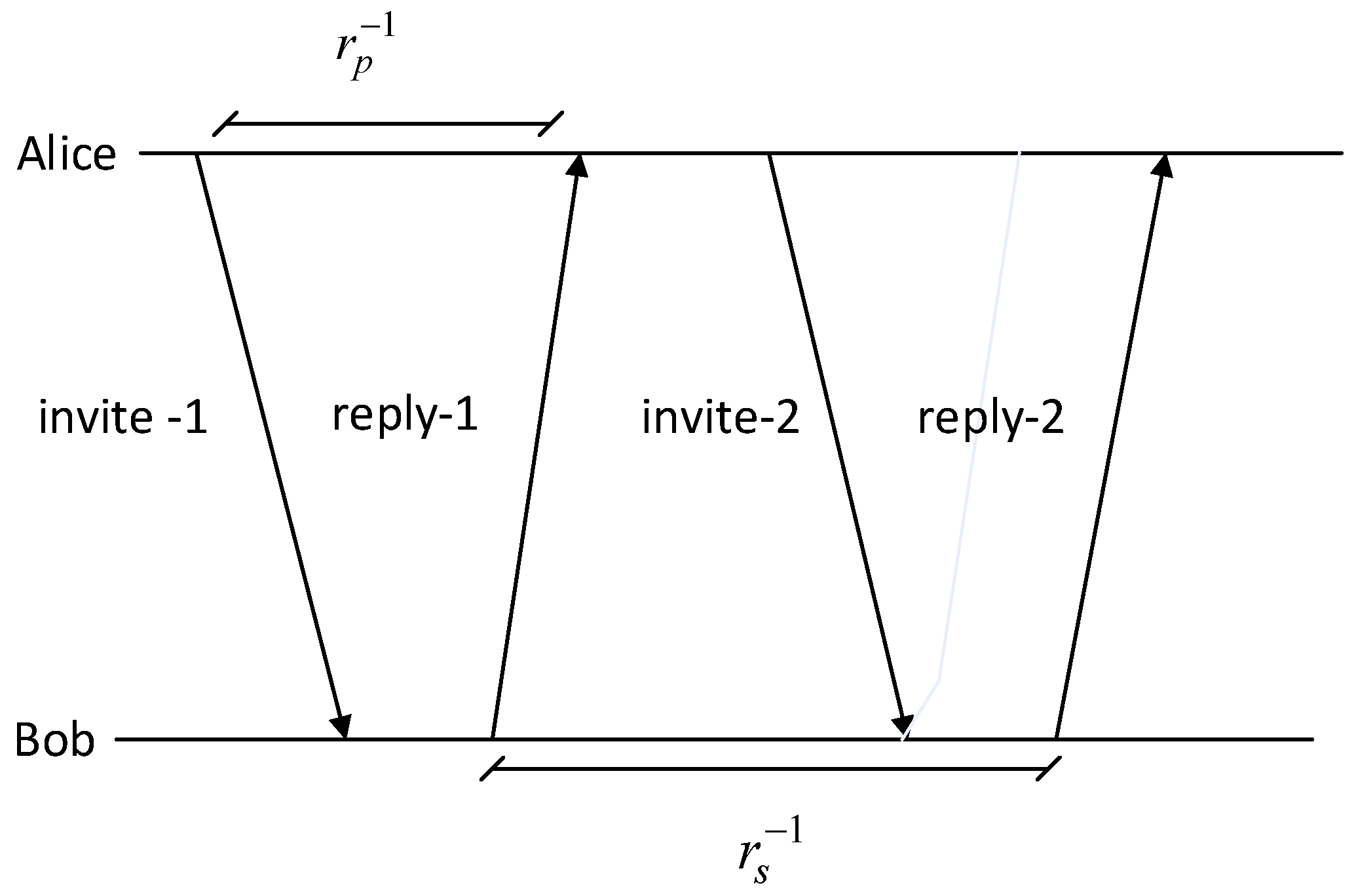
5.1. Performance Evaluation of the Modified Kalman (MK) Method
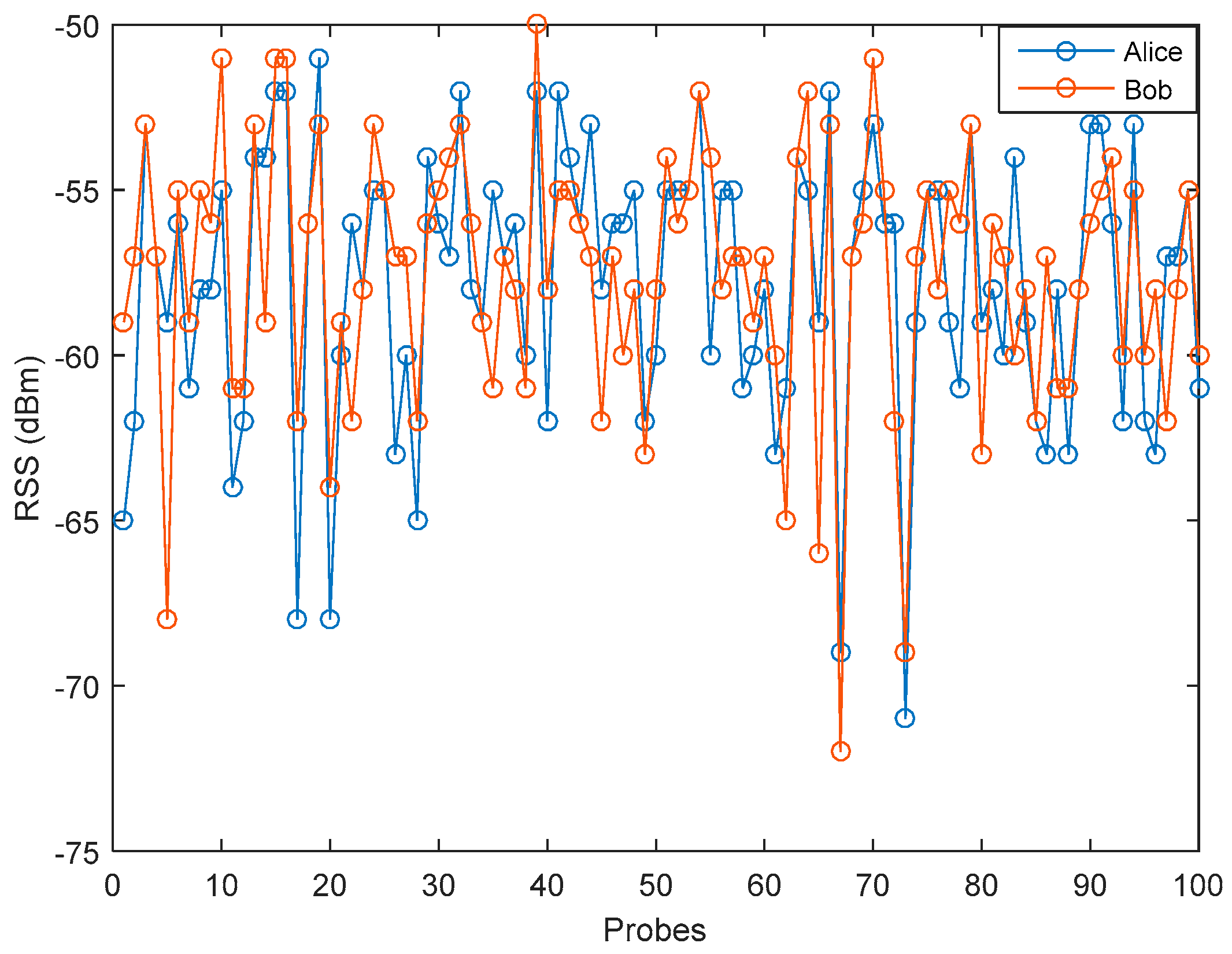
In this test, we divided the RSS data into several data blocks, i.e., 64 and 128. The purpose of this data block distribution is to ensure an improvement in the correlation of each data block so as to increase the similarity of the secret key produced. The selection of the amount of RSS data on each block is based on the quantization method used. We used a multilevel quantization method that converts 1 RSS data into 2 bits, so if 1 block contains 64 RSS data, then it will be converted to 128 bits. If 1 block contains 128 RSS data, then it will be converted to 256 bits. Because the length of the secret key used is 128 bits, the data block will be divided into 2 so each block contains 128 bits.
Table 2 demonstrates the achievement of the MK algorithm as opposed to the existing measurement results for all RSS data. The correlation coefficient obtained is the value of the entire RSS data after processing the RSS data for each block by using the MK method. The results of the experiment show that the RSS data distribution into several data blocks gives an increase in a correlation coefficient of the legitimate user in both LOS and NLOS environments. In the NLOS environment, blocks of data containing 64 RSS data resulted in a higher significant improvement in the correlation coefficient compared to the blocks of data containing 128 RSS data. However, there is a decrease in the correlation coefficient in the LOS environment. This condition occurs because of a decrease in the correlation coefficient when processing data using the adopted polynomial regression (Algorithm 1), so when the data were processed using the Modified Kalman Filter (Algorithm 2) there is no improvement in the correlation coefficient even tends to decline. In this paper, we select blocks of data containing 128 RSS data because of the improvement in the correlation coefficient in all environments. Eavesdropper’s correlation coefficients also increase, but the results obtained are still far below the correlation coefficient obtained by legitimate users. Therefore, it is still difficult for eavesdroppers to get an identical secret key as legitimate users.
We conducted a detailed analysis of the improvement in the correlation coefficient of the legitimate user with each block of data containing 128 RSS data as seen in
Figure 8. Testing is conducted by comparing the correlation coefficients of each measured block of data with the pre-process results by using the MK method. The results of an experiment in the LOS environment indicate that most measurement data blocks have a correlation coefficient of 0.7. After the pre-process stage, there is a significant increase in the number of data blocks that have a correlation coefficient of 0.9 with a range value between 0.9016 to 0.9996. There are 2 blocks of data that have the correlation coefficients of 0.9993 and 0.9996, so it is possible to obtain an identical secret key from the two blocks of data without requiring the information reconciliation stage.
The test results of RSS data for each block in the NLOS environment as seen in
Figure 9 also showed an improvement in the correlation coefficient of the pre-processes results when compared with the measured data. From the pre-process results, there are 9 blocks of data that have a correlation coefficient of 0.9 with a range of values between 0.9053 to 0.9976. One block has a correlation coefficient of 0.9976 so it is possible to obtain an identical secret key without requiring an information reconciliation stage. Generally, the MK method produces a better improvement in the correlation coefficient of the pre-process results in the LOS environment. This can be seen from the increasing number of data blocks that have a correlation coefficient of 0.9 when compared to the NLOS environment, so it has a greater probability of producing identical secret keys.
From the overall tests that have been conducted, it can be concluded that our proposed pre-process method, i.e., the MK method, is able to increase the significant correlation coefficient in some data blocks to 0.9. This increase has an effect on the greater the possibility of getting an identical secret key because of the increased similarity of the RSS data block resulting from the pre-processing stage. The increased number of data blocks with the correlation coefficient can reach up to 35.48% in the LOS environment and 29.03% in the NLOS environment. This shows the success of the addition of the MK method in the built SKG scheme since the method was able to increase the reciprocity of measured RSS data.
5.2. Performance Evaluation of the Combined Multilevel Quantization (CMQ) Method
In this segment, we oppose the achievement evaluation between our proposed method, i.e., CMQ and several existing methods/schemes. In our proposed method we utilize RSS data from the pre-process using the MK method
as the input to be processed into the initial key
. The quantization method used is a multilevel quantization [
48] that uses mean
and variance
to determine the level of each RSS data. There are 4 existing schemes used as a comparison, i.e., schemes [
36,
48,
49,
50]. Scheme [
48] also uses mean and variance to determine the level of each RSS data, but the mean and variance are obtained from blocks of data containing 10 RSS data. The scheme uses RSS data from the pre-process using the existing Kalman as the input to be processed into the initial key. Scheme [
49] uses intervals from sorted RSS data, where this scheme uses
values as the number of bits to be extracted at each interval. Scheme [
50] uses guard bands in each RSS data interval with values
as guard band comparison ratios with the total RSS data. We select
value of 0.1. The last existing scheme is [
36], wherein this scheme is an enrichment of the scheme [
48]. Compared to scheme [
48] which uses 2 parameters, scheme [
36] uses 3 parameters, namely the mean, standard deviation and
as a parameter that will be multiplied by the standard deviation. The
value used in this scheme is 0.01.
Performance evaluation of the SKG scheme is seen from several parameters, namely BDR, KGR, and randomness. BDR testing aims to determine bit incompatibility of total bits in one RSS data block. Since the built SKG scheme does not use the information reconciliation stage, the candidate secret key can be obtained if the BDR value is 0. KGR shows the number of bits produced at one time in the SKG scheme stage. The higher the KGR value is, the faster is the time needed to get the secret key. The randomness parameter aims to determine the level of randomness of the secret key generated. The level of randomness generated can be seen from the significance level . The higher is the value generated, the more random the secret key value is. In cryptographic systems, the minimum value that must be fulfilled is 0.01 ().
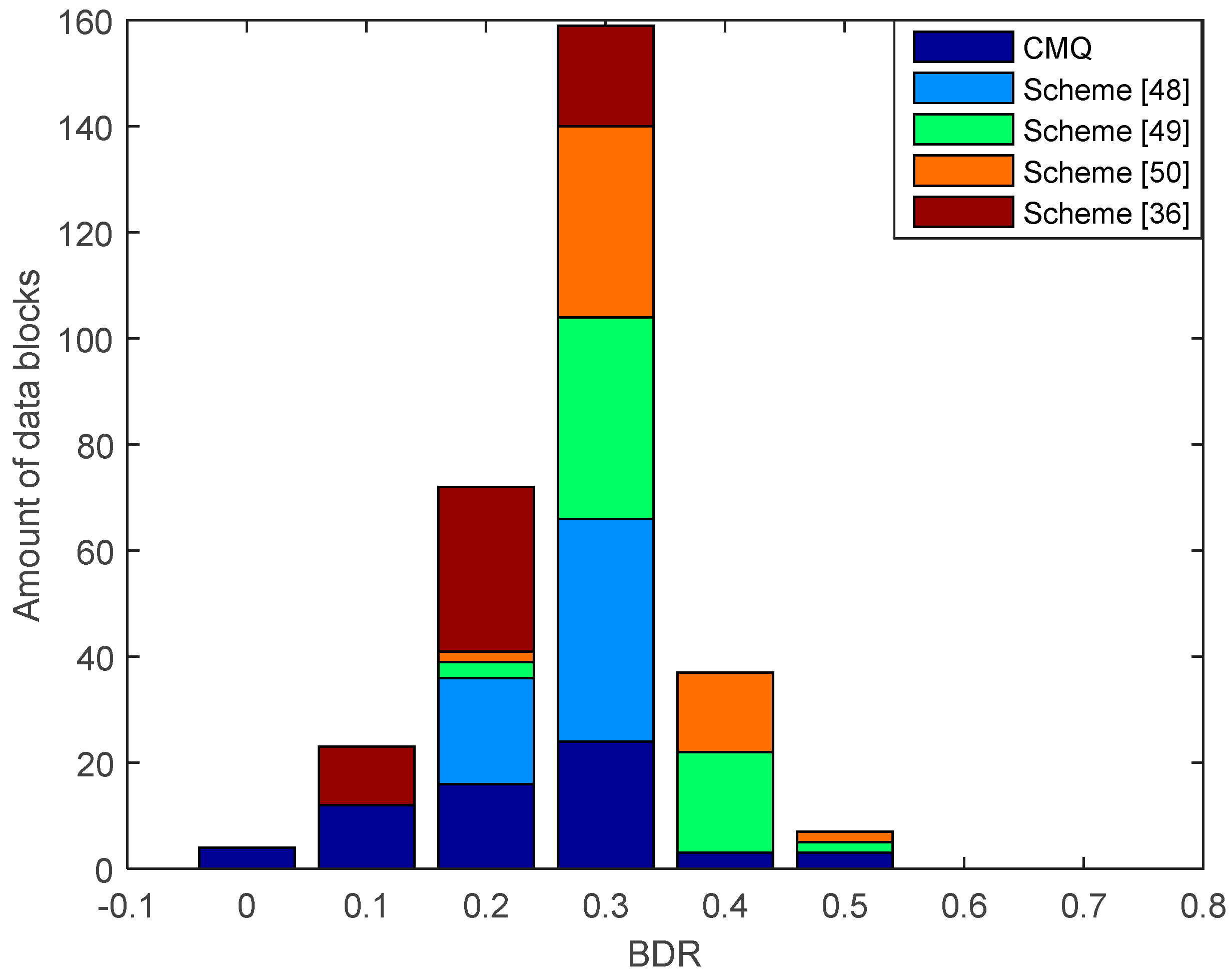
Figure 10 shows the results of the comparison of BDR between our proposed scheme, i.e., CMQ and several existing schemes in the LOS environment. BDR test results of the legitimate user indicate that our proposed scheme is capable of producing 4 identical candidate secret keys without requiring an information reconciliation stage since the BDR value is 0. This condition occurs because of an improvement in the correlation coefficient up to 0.9999 in several data blocks using the MK method. Increasing the correlation coefficient also increases the similarity of the pre-process RSS data results, thus improving the possibility to obtain an identical secret key without requiring an information reconciliation stage. The test outcomes also present that all of the existing schemes produce the non-identical secret key because all data blocks generate BDR values that exceed 0. Therefore, error correcting techniques are still needed to reconcile information.
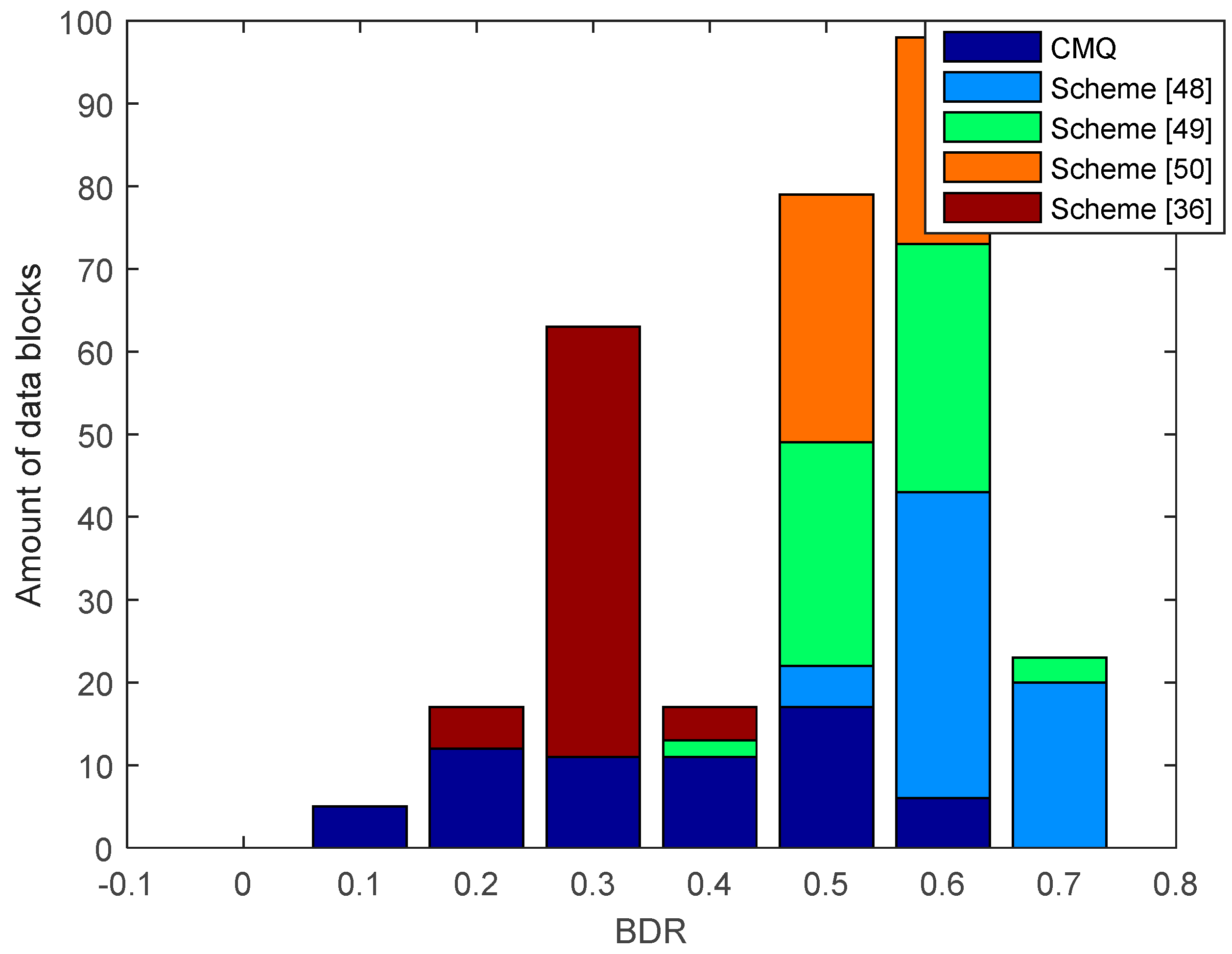
Figure 11 and
Figure 12 show the BDR value between eavesdroppers and legitimate users. Many eavesdropper’s blocks of data have different bits with the legitimate user, so there is no BDR value that is worth 0. This shows that the eavesdropper does not get an identical secret key with the legitimate user.
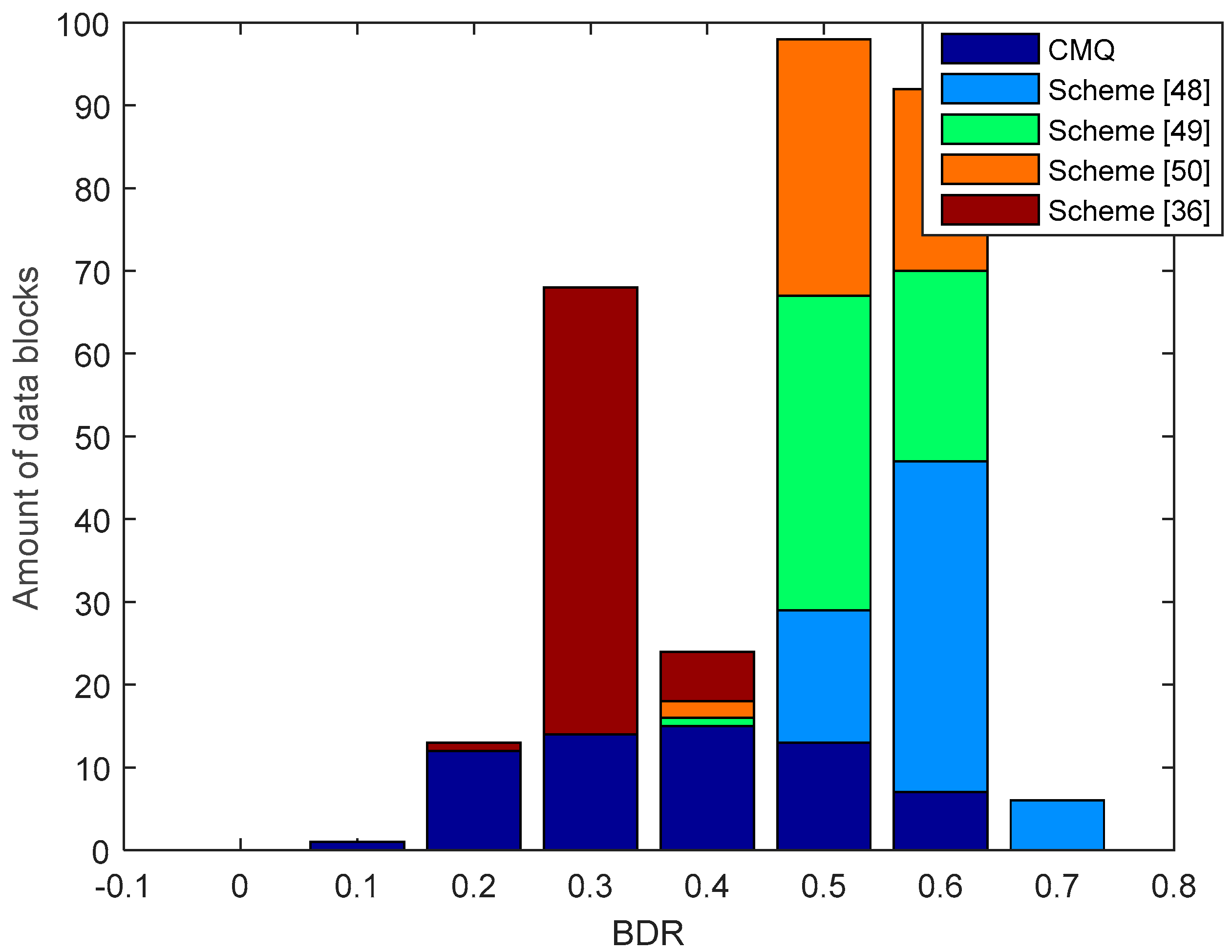
Figure 13 presents the results of the comparison of BDR between our proposed scheme i.e., CMQ and several existing schemes in the LOS environment. BDR test results of the legitimate user indicate that our proposed scheme is capable of producing 2 identical candidate secret keys without requiring an information reconciliation stage because the BDR value is 0. The number of identical secret keys produced is still less when compared to testing in the LOS environment. This occurs because the overall correlation coefficient in the NLOS environment is still smaller when compared to the LOS environment. Besides, the number of data blocks that have increased the correlation coefficient up to 0.9 is also less when compared to the LOS environment. The test outcomes also show that all of the existing schemes produce the non-identical secret key because all data blocks generate BDR values that exceed 0. Therefore, error correcting techniques are still needed to reconcile the information. Overall, it can be appreciated that our scheme is able to produce a simpler SKG scheme compared to the existing scheme. This is indicated by the ability to obtain identical secret keys without going through the information reconciliation stage.
Figure 14 and
Figure 15 show BDR between legitimate users and eavesdroppers. The results of the tests indicate that there is no BDR that has a value of 0, so the eavesdropper does not get an identical secret key with the legitimate user. It shows that our proposed scheme is also able to warrant the security of the secret key generated by the legitimate user. The same with the testing in the LOS environment, the BDR values obtained by eavesdropper in the NLOS environment range between 0.5 and 0.7.
The next tested parameter is randomness by using the NIST statistical suite. There are 6 tests are carried out to ensure the randomness of a candidate secret key, which is generated from the privacy amplification stage. We provide a brief explanation of the objectives of each test as follows [
46]. The approximate entropy test is used to determine the frequency of all possible overlapping bit patterns in a key sequence. The purpose of the frequency (monobit) test is to determine whether the proportions of 0 and 1 in a key sequence are the same. A frequency test within a block is used to determine whether the proportion of 1 in one block is around half a block. A run test is used to determine whether the oscillations of 1 and 0 of a key sequence are too fast or slow compared to a random sequence. A longest-run-of-ones in a block test determines whether the length of the 1 from the test sequence is consistent with the expected length of 1 from the random sequence. Cumulative sums test is used to determine whether the cumulative number of parts of the sequence is too large or too small for the expected cumulative number of a random sequence. Cumulative sums (forward) test use mode 0 by changing 0 to −1, while cumulative sums (reverse) test use mode 1 by changing 1 to +1.
From the test outcomes presented in
Table 3, it can be ensured that all secret keys fulfill the randomness requirements with
p value exceeding 0.01 for all types of tests. The priority of the selected key sequence as the shared secret key is key 4, key 3, key 1, and key 2. This selection is based on the approximate value of each key. If the first priority key failed in the verification stage, then the next key utilized as the secret key is the second priority, i.e., key 3. Generally, key 4 has a greater value for each type of test when compared to the other key. The approximate entropy test results show
p values up to 0.980078. The higher the value of the test shows the higher the irregularity of the resulting bit so the resulting key sequence is more random. The highest
p value of the frequency (monobit) test is 0.859684. The higher the test results show the proportions of 1 and 0 are almost the same or close to ½, so the distribution can be obtained in accordance with the requirements of randomness. On the frequency test within a block, the highest value is obtained on key 1 which is equal to 0.529508. This shows that key 1 has a proportion of 1, which is closer to half the block, so it is as expected on the randomness assumption. The results of the key 1 run test also show a greater
p value compared to the other keys which are equal to 0.920091. These results indicate that the oscillations occurring in the key are faster when compared to other keys. The longest-run-of-ones in a block test shows that key 4 has a length of 1 that is more invariant with the expected length of 1 from a random key set. The results of cumulative sums testing (forward and backward) indicate that the cumulative number of produced keys corresponds to the expected cumulative number of a random sequence. Too many 1 or 0 at the beginning of the key sequence (mode 0) and at the end of the key sequence (mode 1) will result in the
p value being too small, so it does not meet the randomness requirements.
The results of the NIST statistical suite randomization test in the NLOS environment are shown in
Table 4. There are 2 keys with the first priority as a shared secret key, i.e., key 1 with an approximate entropy value of 0.916730. If the verification stage fails, key 2 can be used as an alternative key. Overall, it can be seen that the produced secret keys have fulfilled the randomness requirements because the
p value has exceeded 0.01. Key 1 shows a higher irregularity compared to key 2. This is indicated by a higher
p value of key 1 when compared to key 2 in the approximate entropy test. To fulfill randomization requirements, the key obtained must have a proportion of 1 and 0 that are close to ½. The results of testing frequency (monobit) indicate that key 1 has a proportion of 1 and 0 that are closer to ½, so it has a higher
p value than key 2. The same results were also obtained in testing the frequency test within a block, where key 1 has a proportion of 1 which is closer to half the block so it has a higher value than key 2. In run testing it appears that key 2 oscillates faster than key 1, besides that key 2 also has a length of 1 which is more consistent with the expected length of 1 from a random key sequence. The same results were also obtained in the frequency test within a block, where key 1 has a proportion of 1 which is closer to half the block so it has a higher
p value than key 2. In run testing it appears that key 2 oscillates faster than key 1, besides that key 2 also has a length of 1 which is more invariant with the expected length of 1 from the random key sequence. In cumulative sums testing it appears that key 2 has too many 1 or 0 at the beginning and at the end of the key sequence, so the resulting
p value is smaller than key 1. Overall, the results of the NIST testing in the LOS and NLOS environment show
p values that have exceeded 0.01. It means that the generated secret keys have meets the randomness requirements with confidence level reaching up to 99%.
KGR is a performance parameter that aims to determine the speed of the SKG scheme built to obtain the secret key. The KGR test results as shown in
Table 5 showed a higher KGR result in the LOS environment, i.e., 0.92 bps so that it took approximately 2.32 min to get a 128-bit secret key that would be utilized to encrypt the message using the AES-128 method. In accordance with the recommendations of 802.1x, the secret key must be refreshed every 1 h so that the SKG scheme built has fulfilled the recommendation [
45]. This is because the secret key generated is still less than 1 h, which is 2.32 min. The test results in the NLOS environment also still fulfill the requirements for the refresh key, because the time needed to obtain the 128-bit secret key is 4.74 min. The average of approximate entropy in both test environments ranges from 0.5 to 0.6, with a lower average of approximate entropy obtained in the NLOS environment. In the built SKG scheme, we eliminate the information reconciliation stage. The total computation time needed is 18.3 s (LOS) and 18.6 s (NLOS), while the information reconciliation stage using BCH (31.6) requires computing time up to 7.139 s (LOS) and 7.068 s (NLOS). We assume that the scheme was tested in good network conditions. The elimination of these stages can reduce computational time to 39.1% (LOS) and 38% (NLOS). If network conditions are poor, then the possibility of decreasing computational time is also greater than good network conditions because of the longer time needed to exchange parity bits.
From the overall test to determine the success of the CMQ method, it can be concluded that our proposed method is able to produce a simple SKG scheme by eliminating information reconciliation stage. This condition is indicated by the production of several blocks of data that have a BDR value of 0. The results of tests carried out in the LOS and NLOS environments also show that the time required to obtain the secret key is far below 1 h which is 2.32 min (LOS) and 4.74 min (NLOS) with KGR values reaching 0.92 bps (LOS) and 0.45 bps (NLOS). Therefore, it can be said that the built SKG scheme has been able to meet the recommendations of 802.1x because the secret key could be refreshed under 1 h. Reducing the stage of information reconciliation also affects the decrease in computational and communication cost.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}