Anchor Link Prediction across Attributed Networks via Network Embedding


Abstract
:1. Introduction
2. Related Work
3. Methods
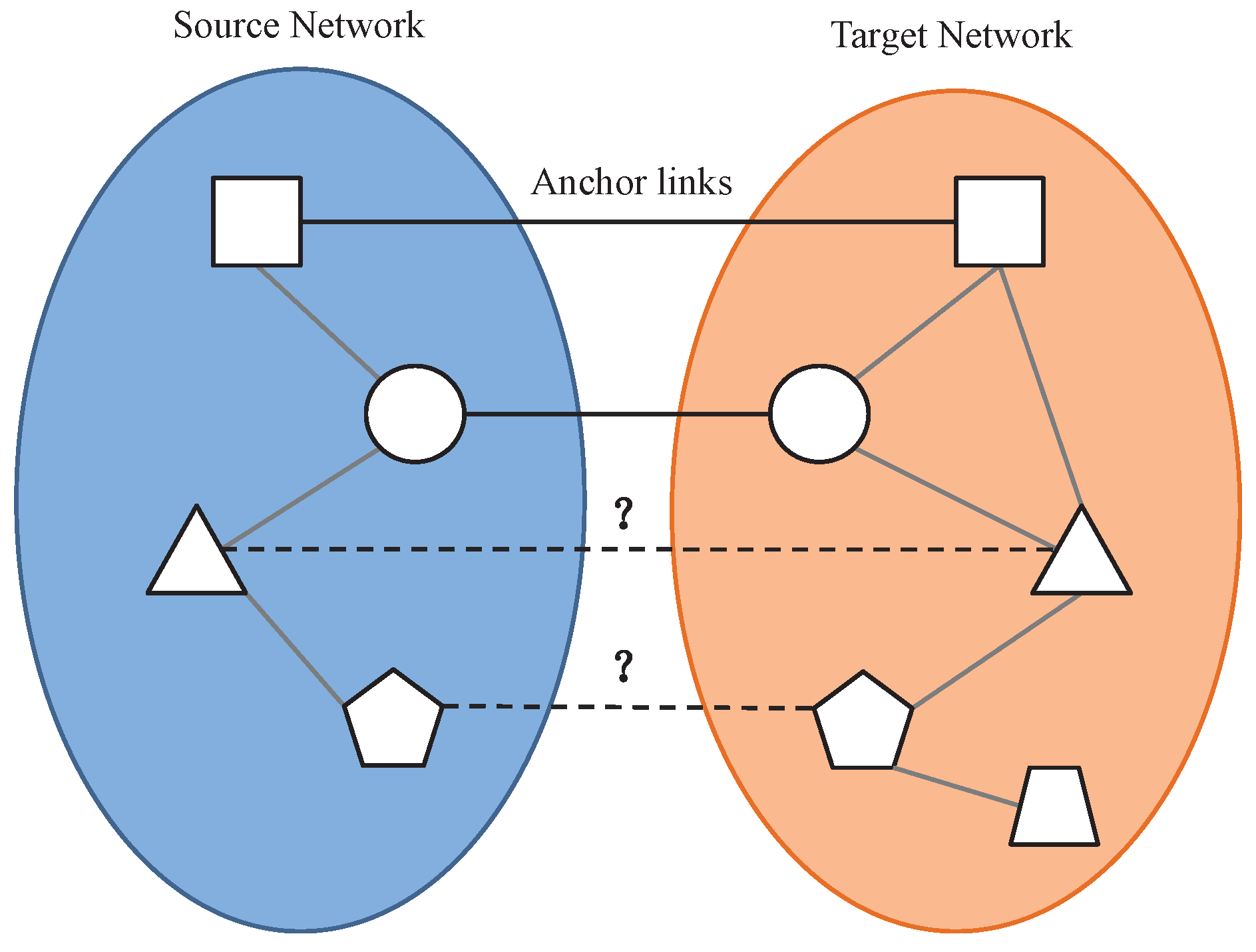
3.1. Problem Formulation
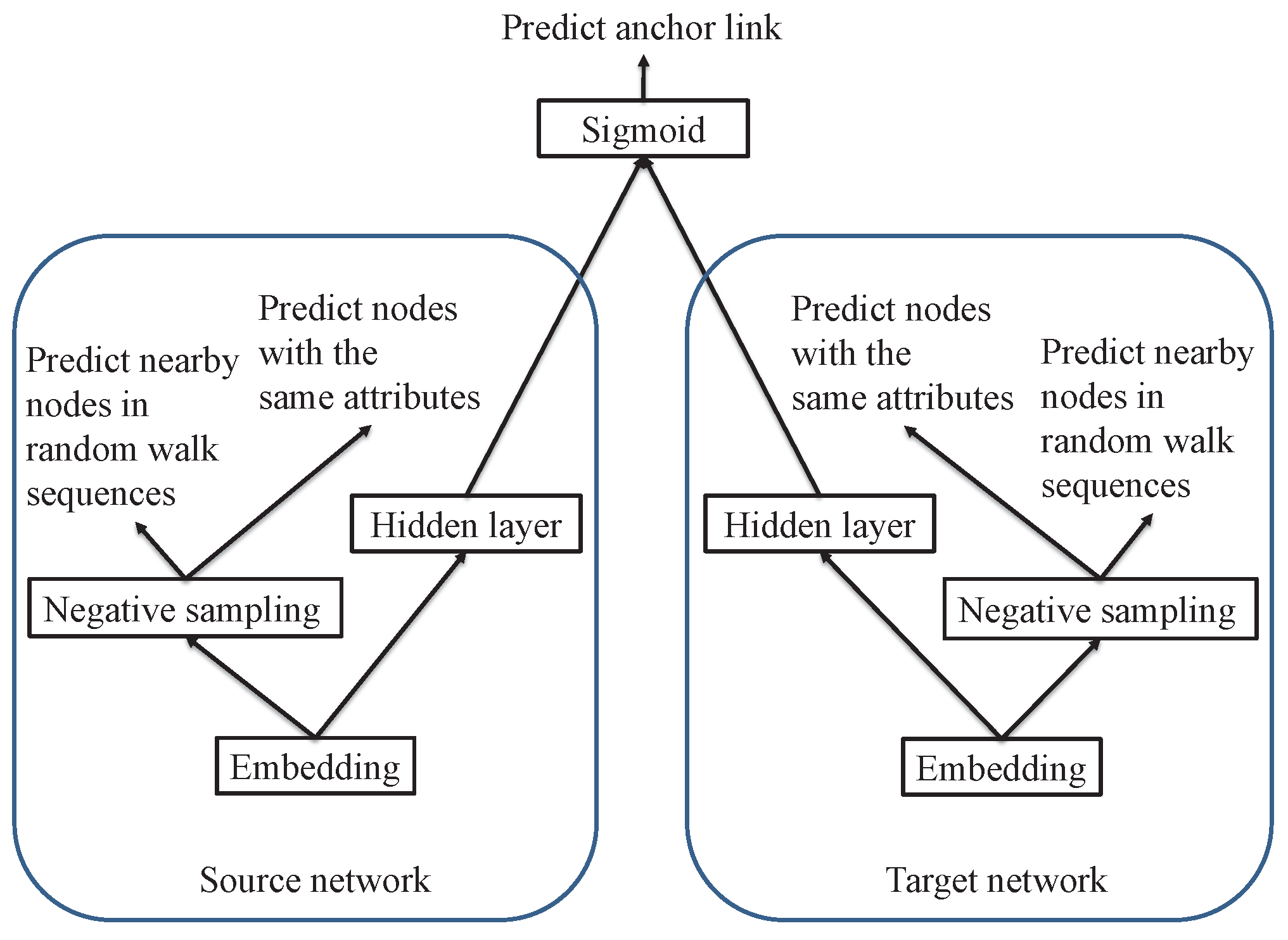
3.2. Learning Attributed Network Embedding
| Algorithm 1 Sampling context algorithm |
| Input: Network G, node attributes A, parameters , , q, e and d; Output: ;
|
3.3. Semi-Supervised Anchor Link Prediction
| Algorithm 2 Model training |
| Require: Attributed networks and , parameters and , batch sizes , and ; |
|
4. Experiments
4.1. Datasets and Baselines
- PALE [13]: This algorithm is a network-embedding-based anchor link prediction algorithm. PALE employs network embedding with awareness of observed anchor links as supervised information to capture the structural regularities and further learns a stable cross-network mapping for anchor link prediction.
- ULink [27]: ULink is a projection algorithm designed based on latent user space modelling. They build the latent user space through projection matrix.
- FINAL [23]: FINAL is proposed to solve the attributed network alignment problem. It leverages the node attribute information to guide (topology-based) alignment process.
- APAN-N: This algorithm is a variant of our proposed APAN algorithm. When predicting context using negative sampling, APAN-N only predicts context based on network structure and does not use nodes’ attributes.
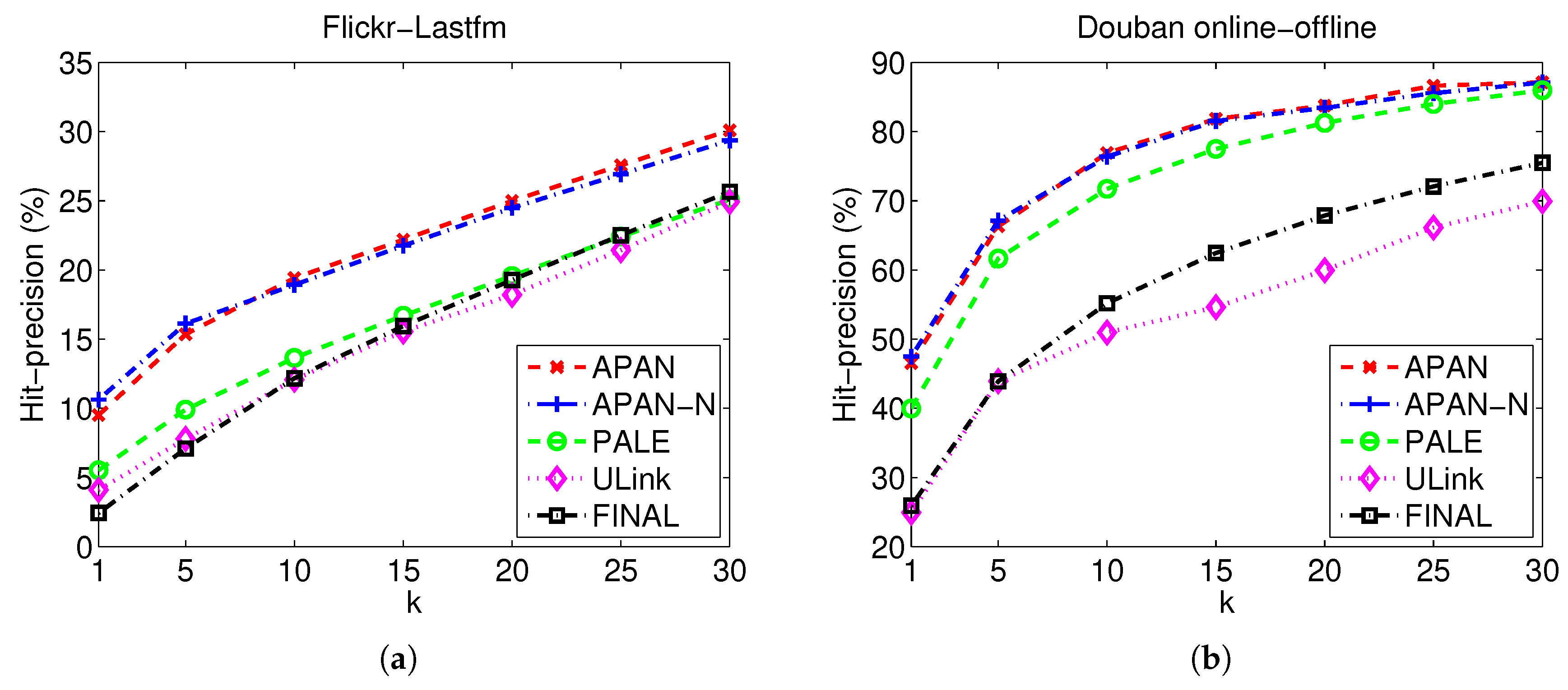
4.2. Experimental Results
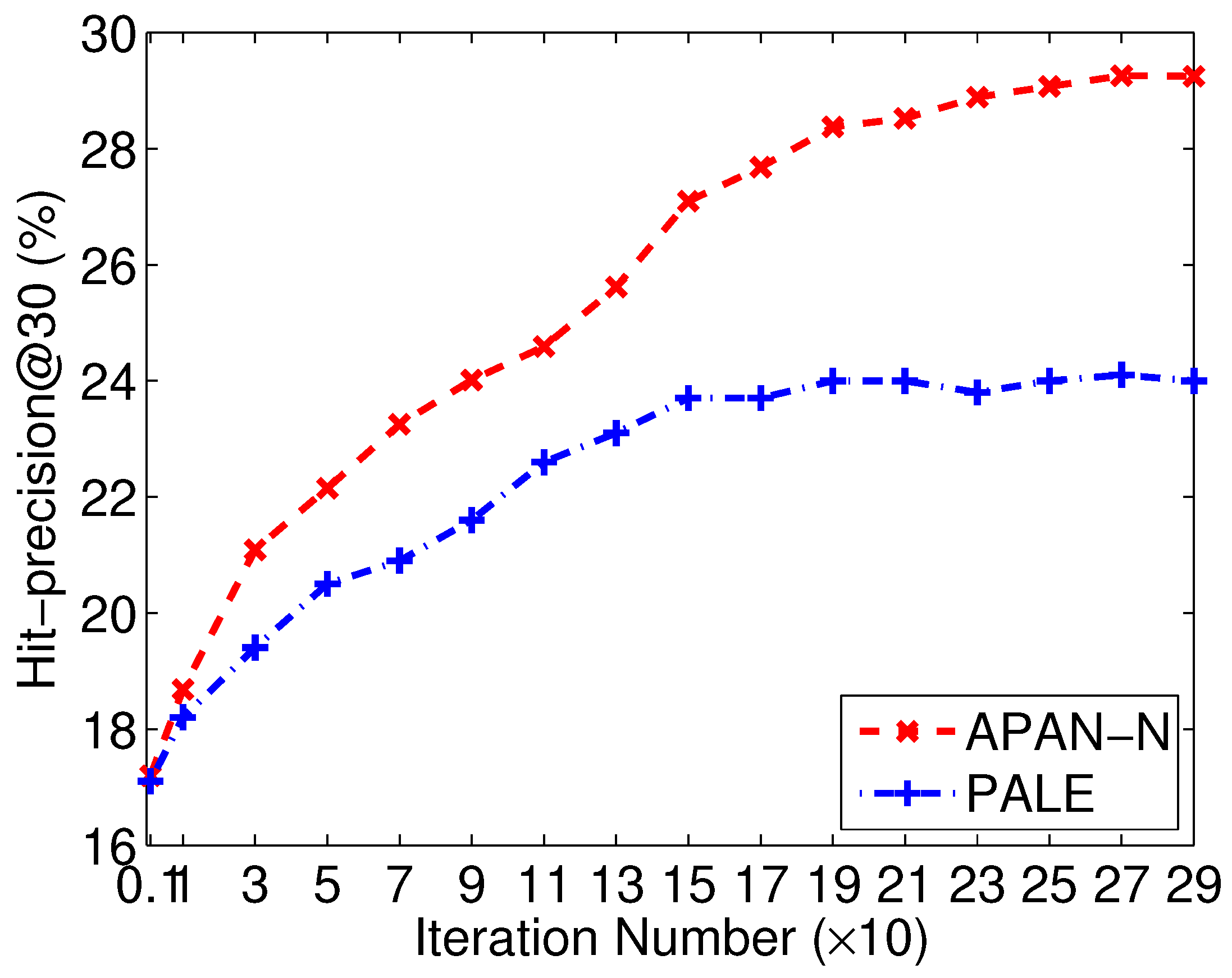
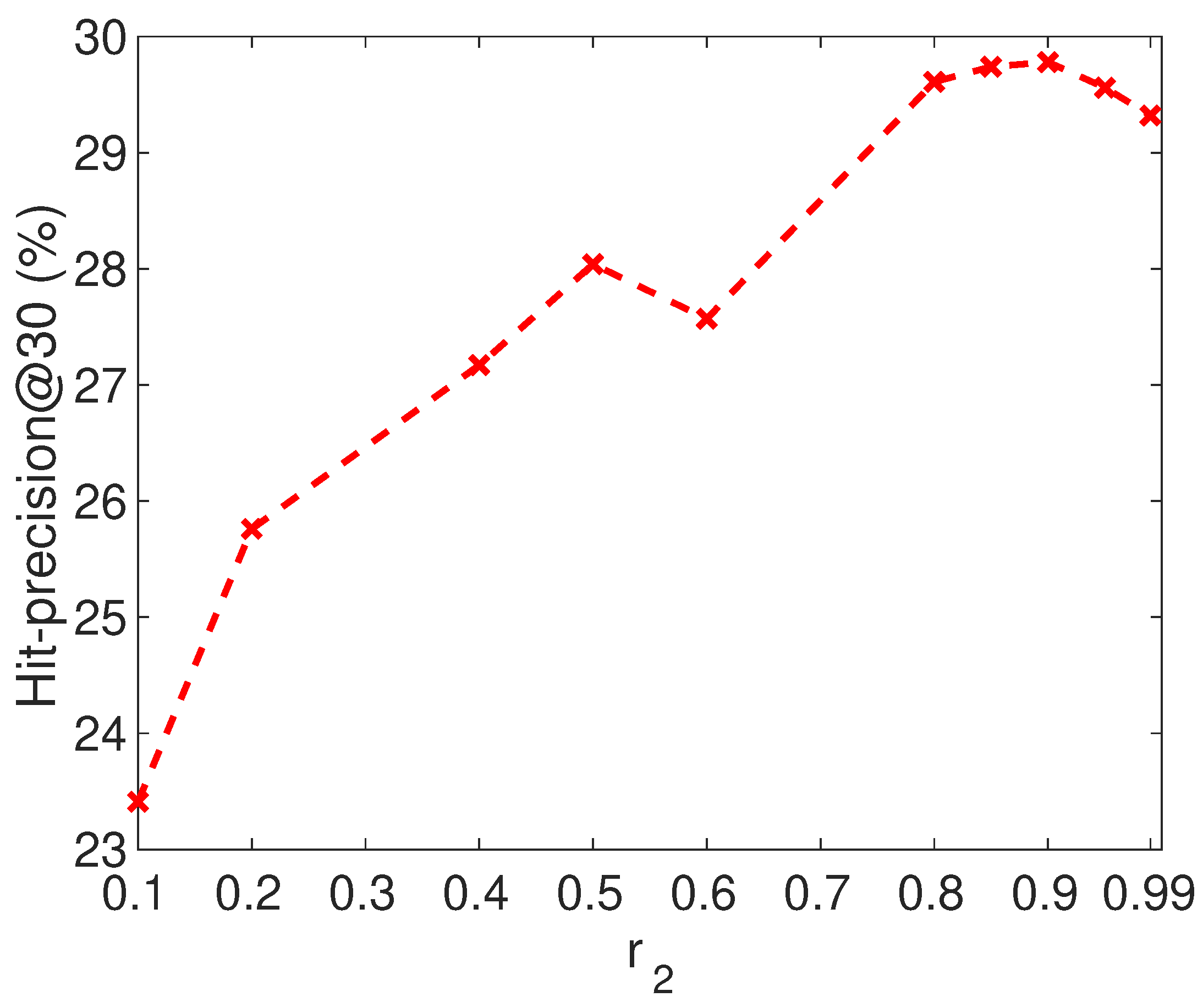
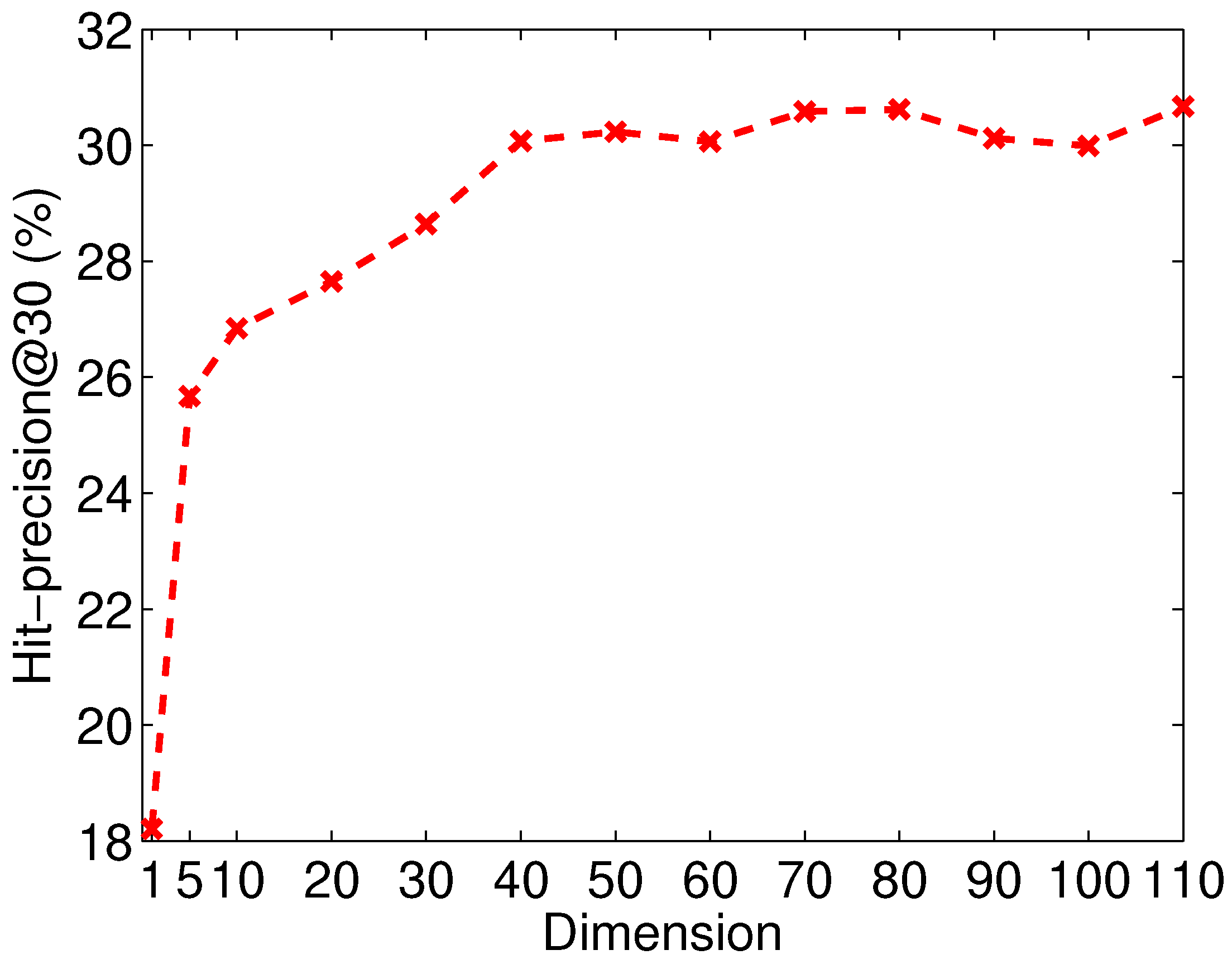
4.3. Parameter Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Manikonda, L.; Meduri, V.V.; Kambhampati, S. Tweeting the Mind and Instagramming the Heart: Exploring Differentiated Content Sharing on Social Media. In Proceedings of the International Conference on Weblogs and Social Media, Cologne, Germany, 17–20 May 2016; pp. 639–642. [Google Scholar]
- Shu, K.; Wang, S.; Tang, J.; Zafarani, R.; Liu, H. User Identity Linkage across Online Social Networks: A Review. ACM SIGKDD Explor. Newslett. 2017, 18, 5–17. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, F.; Song, X.; Song, Y.I.; Lin, C.Y.; Hon, H.W. What’s in a name?: An unsupervised approach to link users across communities. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 495–504. [Google Scholar]
- Zhang, J.; Yu, P.S. Multiple Anonymized Social Networks Alignment. In Proceedings of the IEEE International Conference on Data Mining, Atlantic City, NJ, USA, 14–17 November 2015; pp. 599–608. [Google Scholar]
- Malhotra, A.; Totti, L.; Meira, W., Jr.; Kumaraguru, P.; Almeida, V. Studying User Footprints in Different Online Social Networks. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Beijing, China, 17–20 August 2013; pp. 1065–1070. [Google Scholar]
- Novak, J.; Raghavan, P.; Tomkins, A. Anti-aliasing on the web. In Proceedings of the 13th International Conference on World Wide Web, Beijing, China, 18–20 October 2004; pp. 30–39. [Google Scholar]
- Zhou, X.; Liang, X.; Zhang, H.; Ma, Y. Cross-Platform Identification of Anonymous Identical Users in Multiple Social Media Networks. IEEE Trans. Knowl. Data Eng. 2016, 28, 411–424. [Google Scholar] [CrossRef]
- Narayanan, A.; Shmatikov, V. De-anonymizing Social Networks. In Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 17–20 May 2009; pp. 173–187. [Google Scholar]
- Sergey, B.; Anton, K.; Seungtaek, P.; Wonho, R.; Hyungdong, L. Joint link-attribute user identity resolution in online social networks. In Proceedings of the 6th International Conference on Knowledge Discovery and Data Mining, Workshop on Social Network Mining and Analysis, Beijing, China, 12–16 August 2012. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014; pp. 701–710. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. LINE: Large-scale Information Network Embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Liu, L.; Cheung, W.K.; Li, X.; Liao, L. Aligning Users Across Social Networks Using Network Embedding. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 1774–1780. [Google Scholar]
- Man, T.; Shen, H.; Liu, S.; Jin, X.; Cheng, X. Predict Anchor Links across Social Networks via an Embedding Approach. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 1823–1829. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 24–27 August 2016; pp. 855–864. [Google Scholar]
- Yang, C.; Liu, Z.; Zhao, D.; Sun, M.; Chang, E.Y. Network representation learning with rich text information. In Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25 July–1 August 2015; pp. 2111–2117. [Google Scholar]
- Pan, S.; Wu, J.; Zhu, X.; Zhang, C.; Wang, Y. Tri-party deep network representation. Network 2016, 11, 12. [Google Scholar]
- Huang, X.; Li, J.; Hu, X. Label informed attributed network embedding. In Proceedings of the 10th ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 731–739. [Google Scholar]
- Klau, G.W. A new graph-based method for pairwise global network alignment. BMC Bioinform. 2009, 10, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Foggia, P.; Gennaro, P.; Mario, V. Graph matching and learning in pattern recognition in the last 10 years. Int. J. Pattern Recognit. Artif. Intell. 2014, 28, 1450001. [Google Scholar] [CrossRef]
- Melnik, S.; Garcia-Molina, H.; Rahm, E. Similarity flooding: A versatile graph matching algorithm and its application to schema matching. In Proceedings of the International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 117–128. [Google Scholar]
- Kong, X.; Zhang, J.; Yu, P.S. Inferring anchor links across multiple heterogeneous social networks. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 179–188. [Google Scholar]
- Zhang, S.; Tong, H. FINAL: Fast Attributed Network Alignment. In Proceedings of the 22th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 24–27 August 2016; pp. 1345–1354. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the 19th International Symposium on Computational Statistics, Paris, France, 22–27 August 2010; Springer: New York, NY, USA, 2010; pp. 177–186. [Google Scholar]
- Zhang, Y.; Tang, J.; Yang, Z.; Pei, J.; Yu, P.S. COSNET: Connecting heterogeneous social networks with local and global consistency. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1485–1494. [Google Scholar]
- Zhong, E.; Fan, W.; Wang, J.; Xiao, L.; Li, Y. Comsoc: Adaptive transfer of user behaviors over composite social network. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 696–704. [Google Scholar]
- Mu, X.; Zhu, F.; Wang, J.; Wang, J.; Wang, J.; Zhou, Z.H. User Identity Linkage by Latent User Space Modelling. In Proceedings of the 22th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 24–27 August 2016; pp. 1775–1784. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | #Nodes | #Edges |
|---|---|---|
| Flickr | 4935 | 15,884 |
| Lastfm | 4496 | 10,628 |
| Douban Online | 3906 | 16,328 |
| Douban Offline | 1118 | 3022 |
| Dataset | Evaluation Metric | APAN | APAN-N | PALE | ULink | FINAL |
|---|---|---|---|---|---|---|
| Hit-p@1 | 9.51 ± 2.82 | 10.63 ± 1.17 | 5.53 ± 1.57 | 4.10 ± 1.22 | 2.43 ± 0.90 | |
| Hit-p@5 | 15.35 ± 2.58 | 16.12 ± 2.25 | 9.91 ± 2.73 | 7.79 ± 2.06 | 7.10 ± 0.60 | |
| Hit-p@10 | 19.42 ± 2.73 | 18.93 ± 2.37 | 13.65 ± 3.00 | 12.07 ± 1.92 | 12.18 ± 1.76 | |
| Flickr-Lastfm | Hit-p@15 | 22.18 ± 2.70 | 21.75 ± 2.41 | 16.70 ± 2.81 | 15.55 ± 3.24 | 15.95 ± 2.45 |
| Hit-p@20 | 24.98 ± 2.57 | 24.48 ± 2.41 | 19.57 ± 2.51 | 18.20 ± 2.91 | 19.28 ± 3.04 | |
| Hit-p@25 | 27.57 ± 2.25 | 26.92 ± 2.23 | 22.42 ± 2.20 | 21.42 ± 2.88 | 22.51 ± 3.28 | |
| Hit-p@30 | 30.09 ± 1.94 | 29.36 ± 2.04 | 25.08 ± 2.07 | 24.93 ± 1.81 | 25.65 ± 3.63 | |
| Hit-p@1 | 46.53 ± 2.80 | 47.49 ± 2.98 | 39.98 ± 3.30 | 24.95 ± 3.05 | 25.93 ± 2.17 | |
| Hit-p@5 | 66.31 ± 3.23 | 67.12 ± 1.29 | 61.66 ± 2.04 | 43.93 ± 4.03 | 43.90 ± 1.20 | |
| Hit-p@10 | 76.91 ± 3.09 | 76.38 ± 0.95 | 71.72 ± 2.06 | 50.95 ± 2.74 | 55.19 ± 2.27 | |
| Douban online-offline | Hit-p@15 | 81.84 ± 2.79 | 81.54 ± 0.98 | 77.49 ± 2.24 | 54.62 ± 1.85 | 62.44 ± 2.81 |
| Hit-p@20 | 83.76 ± 2.39 | 83.43 ± 1.00 | 81.25 ± 2.24 | 59.94 ± 2.36 | 67.86 ± 2.77 | |
| Hit-p@25 | 86.62 ± 2.12 | 85.55 ± 1.12 | 83.99 ± 2.17 | 66.11 ± 3.22 | 72.08 ± 2.64 | |
| Hit-p@30 | 87.12 ± 1.99 | 87.09 ± 1.03 | 85.98 ± 2.14 | 69.92 ± 4.39 | 75.49 ± 2.34 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Li, X.; Ye, Y.; Feng, S.; Lau, R.Y.K.; Huang, X.; Du, X. Anchor Link Prediction across Attributed Networks via Network Embedding. Entropy 2019, 21, 254. https://doi.org/10.3390/e21030254
Wang S, Li X, Ye Y, Feng S, Lau RYK, Huang X, Du X. Anchor Link Prediction across Attributed Networks via Network Embedding. Entropy. 2019; 21(3):254. https://doi.org/10.3390/e21030254
Chicago/Turabian StyleWang, Shaokai, Xutao Li, Yunming Ye, Shanshan Feng, Raymond Y. K. Lau, Xiaohui Huang, and Xiaolin Du. 2019. "Anchor Link Prediction across Attributed Networks via Network Embedding" Entropy 21, no. 3: 254. https://doi.org/10.3390/e21030254
APA StyleWang, S., Li, X., Ye, Y., Feng, S., Lau, R. Y. K., Huang, X., & Du, X. (2019). Anchor Link Prediction across Attributed Networks via Network Embedding. Entropy, 21(3), 254. https://doi.org/10.3390/e21030254