On the Diversity-Based Weighting Method for Risk Assessment and Decision-Making about Natural Hazards

Abstract
:1. Introduction
2. Materials and Methods
2.1. EWM
2.2. VCM
2.3. New Indicator Representing the Dipartite Degree
3. Results and Discussions
3.1. Comparison between EWM and VCM
3.1.1. Similarity
3.1.2. Difference
3.2. Comparison of DCM, EWM and VCM
3.2.1. Case 1: Drought-Risk Assessment
3.2.2. Case 2: Decision-Making for a Prevention Programme for Debris Flow
3.3. Discussions
4. Conclusions
- (1)
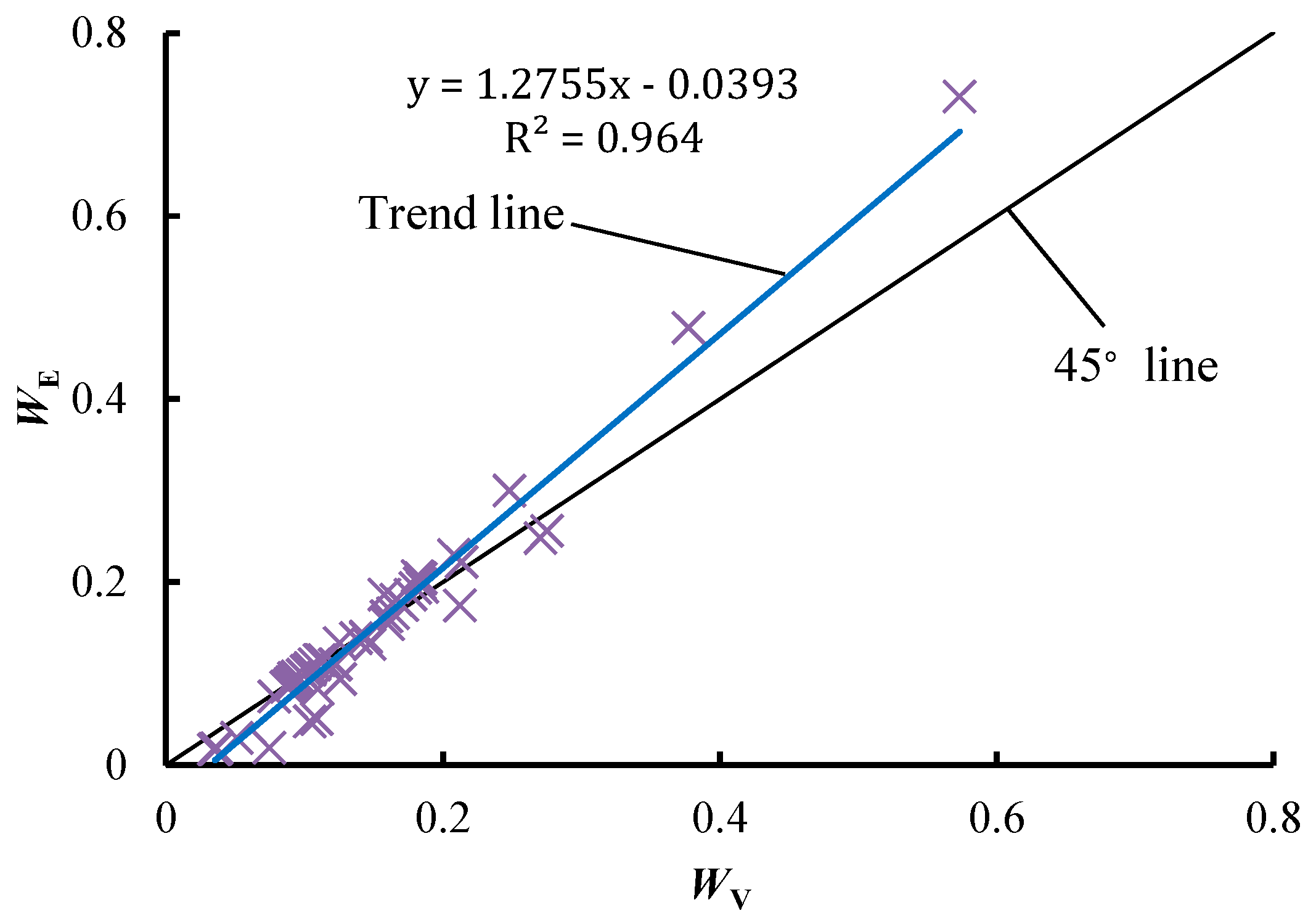
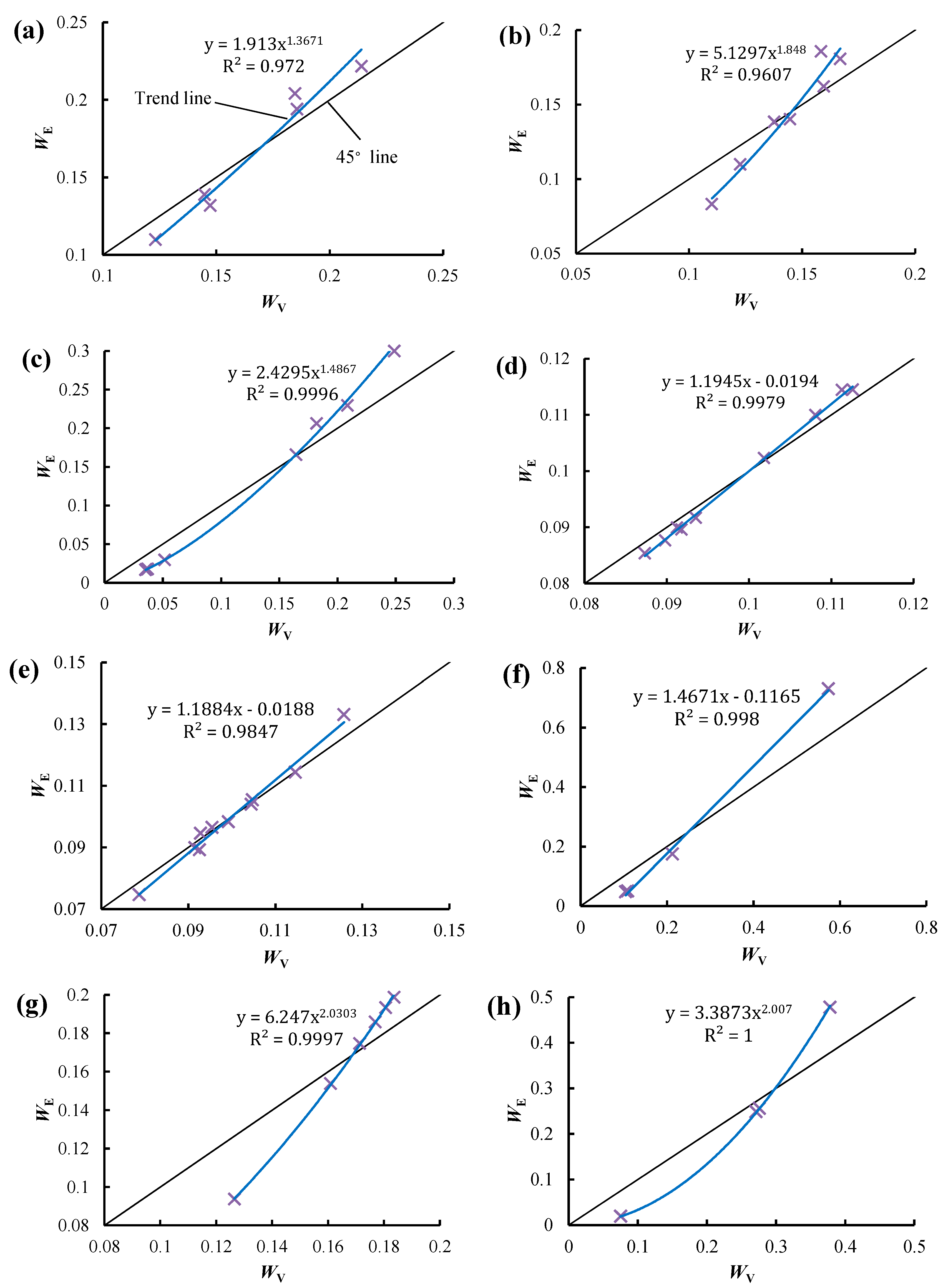
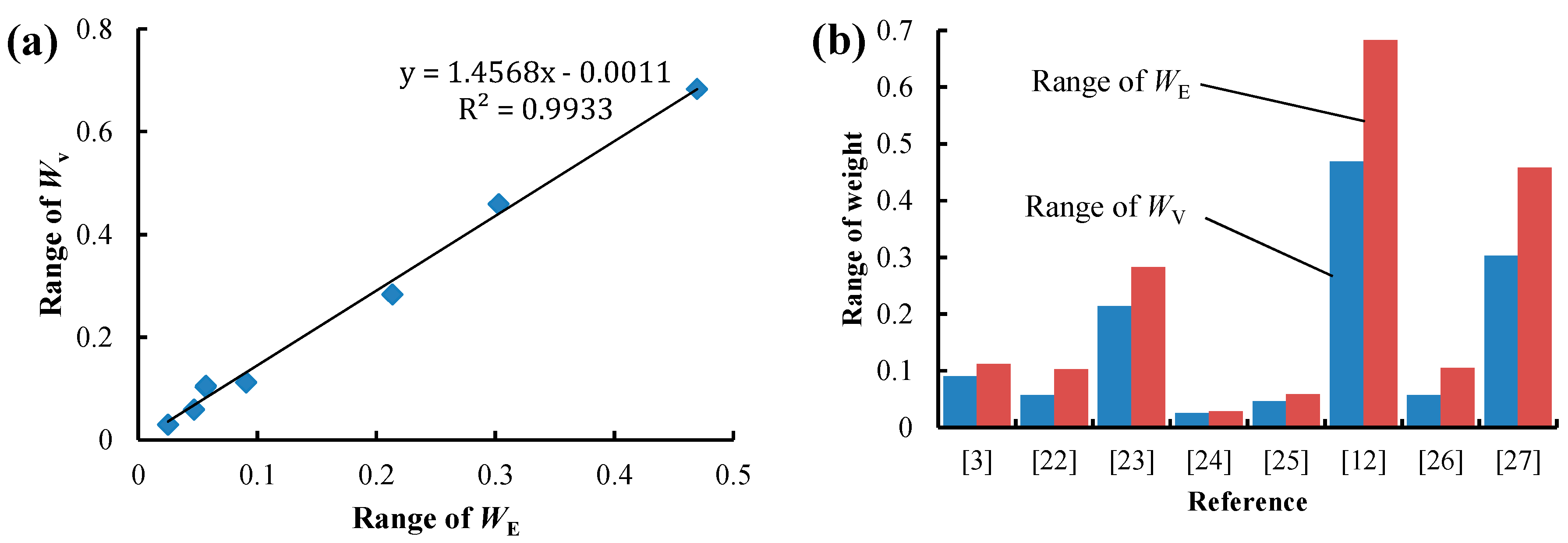
- Significant linear and power function relationships are observed between WE and WV, which indicates that there is a strong correlation between them. WE and WV are usually close to each other, but in some cases the difference between them is large. Especially when the diversity of an attribute is high, WE may be much larger than WV, which may result in an irrational decision when using the EWM. Compared to the VCM, the EWM is more sensitive to the diversity of attributes, as the range of WE is always larger than that of WV.
- (2)
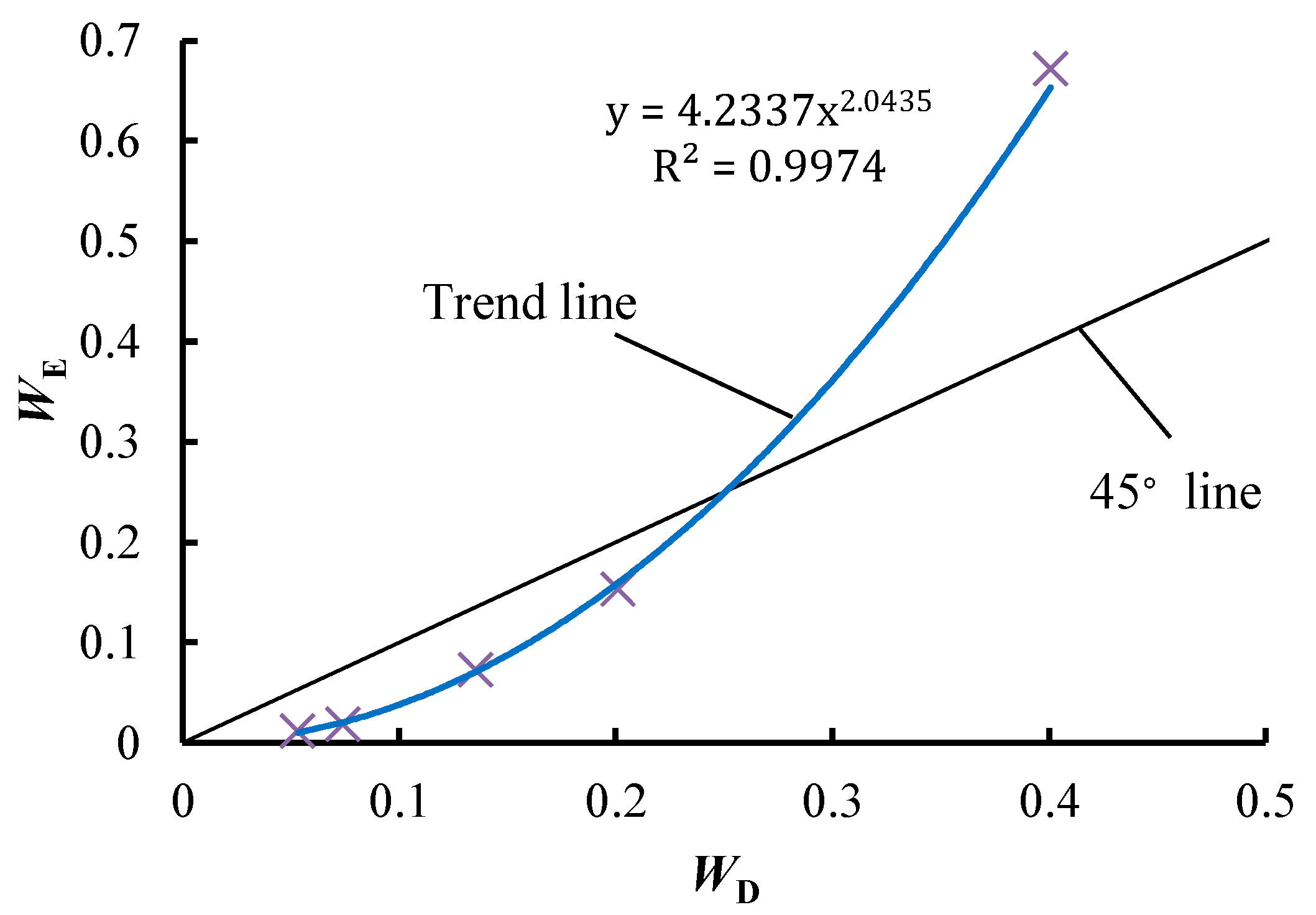
- The IE and CV may not accurately represent the dipartite degree of an attribute with a specific RV, as the dipartite degree of an attribute is related to its RV. The DCM is preferred for determining the weights of attributes with a specific RV, as the CDD can represent the dipartite degree of this kind of attribute correctly.
- (3)
- If the values of attributes are large enough, the EWM and VCM are both able to determine the weights of attributes with a specific RV. Compared to the VCM and DCM, the EWM is more suitable for distinguishing the alternatives due to its sensitivity to the diversity of attributes. However, when the diversity of an attribute is too high, its decision result may be seriously affected by this attribute, which may lead to an irrational decision result.
- (4)
- In natural hazards risk assessment, the dipartite degree of an attribute may not accurately represent its importance; thus, prudence is required when using the dipartite degree of an attribute to represent its importance. It is recommended to use the diversity-based weighting method in combination with a subjective weighting method for risk assessment in natural hazards.
Funding
Conflicts of Interest
References
- Nyimbili, P.H.; Erden, T.; Karaman, H. Integration of GIS, AHP and TOPSIS for earthquake hazard analysis. Nat. Hazards 2018, 92, 1523–1546. [Google Scholar] [CrossRef]
- Palchaudhuri, M.; Biswas, S. Application of AHP with GIS in drought risk assessment for Puruliya district, India. Nat. Hazards 2016, 84, 1905–1920. [Google Scholar] [CrossRef]
- Liu, W.; Li, Q.; Zhao, J. Application on floor water inrush evaluation based on AHP variation coefficient method with GIS. Geotech. Geol. Eng. 2018, 36, 2799–2808. [Google Scholar] [CrossRef]
- Yang, W.C.; Xu, K.; Lian, J.J.; Ma, C.; Bin, L.L. Integrated flood vulnerability assessment approach based on TOPSIS and Shannon entropy methods. Ecol. Indic. 2018, 89, 269–280. [Google Scholar] [CrossRef]
- Xu, H.; Ma, C.; Lian, J.; Xu, K.; Chaima, E. Urban flooding risk assessment based on an integrated k-means cluster algorithm and improved entropy weight method in the region of Haikou, China. J. Hydrol. 2018, 563, 975–986. [Google Scholar] [CrossRef]
- Lin, H.-M.; Chang, S.-K.; Wu, J.-H.; Juang, H.C. Neural network-based model for assessing failure potential of highway slopes in the Alishan, Taiwan Area: Pre- and post-earthquake investigation. Eng. Geol. 2009, 104, 280–289. [Google Scholar] [CrossRef]
- Chang, S.-K.; Lee, D.-H.; Wu, J.-H.; Juang, H.C. Rainfall-based criteria for assessing slump rate of mountainous highway slopes: A case study of slopes along Highway 18 in Alishan, Taiwan. Eng. Geol. 2011, 118, 63–74. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Zhang, S.; Khosravi, K.; Shirzadi, A.; Chapi, K.; Pham, B.T.; Zhang, T.; Zhang, L.; Chai, H.; et al. Landslide susceptibility modeling based on GIS and novel bagging-based kernel logistic regression. Appl. Sci. 2018, 8, 2540. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Hong, H.; Akgun, A.; Tian, Y.; Liu, J.; Zhu, A.-X.; Li, S. Novel hybrid artificial intelligence approach of bivariate statistical-methods-based kernel logistic regression classifier for landslide susceptibility modeling. Bull. Eng. Geol. Environ. 2018. [Google Scholar] [CrossRef]
- Chen, W.; Panahi, M.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Panahi, S.; Li, S.; Jaafari, A.; Ahmad, B.B. Applying population-based evolutionary algorithms and a neuro-fuzzy system for modeling landslide susceptibility. CATENA 2019, 172, 212–231. [Google Scholar] [CrossRef]
- Zhang, Y.; Nie, L.; Wang, Y. Research on the early-warning model with debris flow efficacy coefficient based on the optimal combination weighting law. In Progress of Geo-Disaster Mitigation Technology in Asia; Wang, F., Miyajima, M., Li, T., Shan, W., Fathani, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 567–576. [Google Scholar]
- Li, Q.; Meng, X.X.; Liu, Y.B.; Pang, L.F. Risk assessment of floor water inrush using entropy weight and variation coefficient model. Geotech. Geol. Eng. 2018. [Google Scholar] [CrossRef]
- Ding, L.; Shao, Z.; Zhang, H.; Xu, C.; Wu, D. A comprehensive evaluation of urban sustainable development in China based on the TOPSIS-entropy method. Sustainability 2016, 8, 746. [Google Scholar] [CrossRef]
- Cao, C.; Xu, P.; Chen, J.; Zheng, L.; Niu, C. Hazard assessment of debris-flow along the Baicha River in Heshigten Banner, Inner Mongolia, China. Int. J. Environ. Res. Public Health 2017, 14, 30. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.Z.; Sun, C.Z. Application of entropy-weight and matter-element extension model in hazard assessment for debris flow. J. Liaoning Normal Univ. 2016, 39, 553–560. [Google Scholar]
- Wang, Y.M.; Yin, K.L. A study of the typhoon-triggered debris flow hazard degree of a single gully. Hydroge. Eng. Geol. 2018, 45, 124–130. [Google Scholar]
- Huang, S.; Chang, J.; Leng, G.; Huang, Q. Integrated index for drought assessment based on variable fuzzy set theory: A case study in the Yellow River basin, China. J. Hydrol. 2015, 527, 608–618. [Google Scholar] [CrossRef] [Green Version]
- Yi, F.; Li, C.; Feng, Y. Two precautions of entropy-weighting model in drought risk assessment. Nat. Hazards 2018, 93, 339–347. [Google Scholar] [CrossRef]
- Liu, J.; Duan, Z. Quantitative assessment of landslide susceptibility comparing statistical index, index of entropy, and weights of evidence in the Shangnan area, China. Entropy 2018, 20, 868. [Google Scholar] [CrossRef]
- Seong, J.; Byun, Y. A study on the weights of the condition evaluation of rock slope used in entropy and AHP method. J. Korean Soc. Saf. 2016, 31, 61–66. [Google Scholar] [CrossRef]
- Zeng, J.; Huang, G. Set pair analysis for karst waterlogging risk assessment based on AHP and entropy weight. Hydrol. Res. 2018, 49, 1143–1155. [Google Scholar] [CrossRef]
- Qian, C.; Zhang, M.; Chen, Y.; Wang, R. A quantitative judgement method for safety admittance of facilities in chemical industrial parks based on G1-variation coefficient method. Procedia Eng. 2014, 84, 223–232. [Google Scholar]
- Zhou, Z.; Kizil, M.; Chen, Z.; Chen, J. A new approach for selecting best development face ventilation mode based on G1-coefficient of variation method. J. Cent. South Univ. 2018, 25, 2462–2471. [Google Scholar] [CrossRef]
- Wang, L.; Shao, X. Study on the safety production evaluation of the coal mine based on entropy-TOPSIS. J. Coal Sci. Eng. 2010, 16, 284–287. [Google Scholar] [CrossRef]
- Hafezalkotob, A.; Hafezalkotob, A. Extended MULTIMOORA method based on Shannon entropy weight for materials selection. J. Ind. Eng. Int. 2016, 12, 1–13. [Google Scholar] [CrossRef]
- Wu, S.; Fu, Y.; Shen, H.; Liu, F. Using ranked weights and Shannon entropy to modify regional sustainable society index. Sustain. Cities Soc. 2018, 41, 443–448. [Google Scholar] [CrossRef]
- Boroushaki, S. Entropy-based weights for multicriteria spatial decision-making. Yearbook Assoc. Pac. Coast Geogr. 2017, 79, 168–187. [Google Scholar] [CrossRef]
- Zhao, A.; Wu, C.; Wang, E. Research on Energy consumption evaluation combined with endogenous pollutants of China based on entropy-TOPSIS. Chin. J. Popul. Res. Environ. 2011, 9, 71–76. [Google Scholar]
- Liang, X.; Liu, C.; Li, Z. Measurement of scenic spots sustainable capacity based on PCA-entropy TOPSIS: A case study from 30 provinces, China. Int. J. Environ. Res. Public Health 2018, 15, 10. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Zhu, X.; Chen, H. Research on Optimization of Equipment Maintenance Plan Based on Entropy and TOPSIS. In Proceedings of the 2011 International Conference on Informatics, Cybernetics, and Computer Engineering (ICCE2011), Melbourne, Australia, 19–20 November 2011; Jiang, L., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 145–150. [Google Scholar]
- Wang, N.Q.; Cao, H.L.; Yang, P.P. Optimization model of prevention plans for debris flow disaster. Soil Water Conserv. Chin. 2016, 46–48. [Google Scholar]
- Rosi, A.; Tofani, V.; Tanteri, L.; Stefanelli, C.T.; Agostini, A.; Catani, F.; Casagli, N. The new landslide inventory of Tuscany (Italy) updated with PS-InSAR: Geomorphological features and landslide distribution. Landslides 2018, 15, 5–19. [Google Scholar] [CrossRef]
- Chen, P.Y. Analysis of the critical rainfall for regional group-occurring debris flows in Luanchuan County of Henan. Sci. Technol. Eng. 2016, 16, 134–138. [Google Scholar]
- Moon, Y.; Lee, S.; Kim, S.; Kim, M. Determining the location of urban planning measures for preventing debris-flow risks: Based on the MCDM method. J. Korean Soc. Saf. 2017, 32, 103–114. [Google Scholar]
- Ma, J.; Guo, J.; Liu, X. Water quality evaluation model based on principal component analysis and information entropy: Application in Jinshui River. J. Resour. Ecol. 2010, 1, 249–252. [Google Scholar]
- Hsu, L.-C. Investment decision making using a combined factor analysis and entropy-based topsis model. J. Bus. Econ. Manag. 2013, 14, 448–466. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | MPAP | MRAP | MSMAP | ||
|---|---|---|---|---|---|
| Observation data | Watershed 1 | 0 (no drought) | −40 (moderate drought) | −40 (moderate drought) | |
| Watershed 2 | 0 (no drought) | −55 (severe drought) | −45 (moderate drought) | ||
| Watershed 3 | 0 (no drought) | −70 (severe drought) | −60 (severe drought) | ||
| Watershed 4 | 0 (no drought) | −85 (extreme drought) | −85 (extreme drought) | ||
| Watershed 5 | −1 (no drought) | −90 (extreme drought) | −90 (extreme drought) | ||
| RV | [−100, 0] | [−100, 0] | [−100, 0] | ||
| Calculated results | EWM | IE | 0.000 | 0.9756 | 0.9692 |
| WE | 0.9477 | 0.0231 | 0.0292 | ||
| VCM | CV | −2.0000 | −0.2736 | −0.3179 | |
| WV | 0.7718 | 0.1056 | 0.1227 | ||
| DCM | CDD | 0.0040 | 0.1860 | 0.2035 | |
| WD | 0.0102 | 0.4727 | 0.5171 | ||
| Attribute (Translation Value) | MPAP | MPAP (−0.1) | MPAP (−1) | MPAP (−10) | MPAP (−50) | |
|---|---|---|---|---|---|---|
| Translated data | Watershed 1 | 0 | −0.1 | −1 | −10 | −50 |
| Watershed 2 | 0 | −0.1 | −1 | −10 | −50 | |
| Watershed 3 | 0 | −0.1 | −1 | −10 | −50 | |
| Watershed 4 | 0 | −0.1 | −1 | −10 | −50 | |
| Watershed 5 | −1 | −1.1 | −2 | −11 | −51 | |
| Calculated results | IE | 0.0000 | 0.5900 | 0.9697 | 0.9995 | 1.0000 |
| CV | −2.0000 | −1.3333 | −0.3333 | −0.0392 | −0.0080 | |
| CDD | 0.0040 | 0.0040 | 0.0040 | 0.0040 | 0.0040 |
| Attribute | Programme 1 | Programme 2 | Programme 3 | Programme 4 |
|---|---|---|---|---|
| Safe reliability | 75 | 70 | 94 | 95 |
| Environmental harmony | 84 | 86 | 82 | 85 |
| Economic rationality | 88 | 85 | 90 | 80 |
| Design standardization | 90 | 94 | 95 | 95 |
| Construction complexity | 88 | 85 | 90 | 80 |
| Later maintainability | 85 | 80 | 90 | 95 |
| Attribute | Safe Reliability | Environmental Harmony | Economic Rationality | Design Standardization | Construction Complexity | Later Maintainability | |
|---|---|---|---|---|---|---|---|
| EWM | IE | >0.9935 | 0.9999 | 0.9993 | 0.9998 | 0.9993 | 0.9985 |
| WE | 0.6715 | 0.0116 | 0.0728 | 0.0183 | 0.0728 | 0.1530 | |
| VCM | CV | 0.1335 | 0.0176 | 0.0439 | 0.0220 | 0.0439 | 0.0639 |
| WV | 0.4110 | 0.0540 | 0.1352 | 0.0679 | 0.1352 | 0.1967 | |
| DCM | CDD | 0.1115 | 0.0148 | 0.0377 | 0.0206 | 0.0377 | 0.0559 |
| WD | 0.4008 | 0.0532 | 0.1354 | 0.0741 | 0.1354 | 0.2010 | |
| Proposed Programme | Programme 1 | Programme 2 | Programme 3 | Programme 4 | |
|---|---|---|---|---|---|
| EWM | Total score | 78.801 | 74.339 | 92.685 | 92.701 |
| Ranking | 3 | 4 | 2 | 1 | |
| VCM | Total score | 81.987 | 78.517 | 91.551 | 90.403 |
| Ranking | 3 | 4 | 1 | 2 | |
| DCM | Total score | 82.122 | 78.703 | 91.548 | 90.405 |
| Ranking | 3 | 4 | 1 | 2 | |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P. On the Diversity-Based Weighting Method for Risk Assessment and Decision-Making about Natural Hazards. Entropy 2019, 21, 269. https://doi.org/10.3390/e21030269
Chen P. On the Diversity-Based Weighting Method for Risk Assessment and Decision-Making about Natural Hazards. Entropy. 2019; 21(3):269. https://doi.org/10.3390/e21030269
Chicago/Turabian StyleChen, Pengyu. 2019. "On the Diversity-Based Weighting Method for Risk Assessment and Decision-Making about Natural Hazards" Entropy 21, no. 3: 269. https://doi.org/10.3390/e21030269
APA StyleChen, P. (2019). On the Diversity-Based Weighting Method for Risk Assessment and Decision-Making about Natural Hazards. Entropy, 21(3), 269. https://doi.org/10.3390/e21030269