1. Introduction
Goal recognition—the ability to recognize the plans and goals of other agents—enables humans, AI agents, or command and control systems to reason about what the others are doing, why they are doing it, and what they will do next [
1]. Until now, goal recognition system has worked well in many applications such as human–robot interaction [
2], intelligent tutoring [
3], system-intrusion detection [
4] and security applications [
5].
Though this technique has been successfully applied to many application domains, new problems arise when goal recognition encounters a goal uncertainty discovered in certain environmental settings.
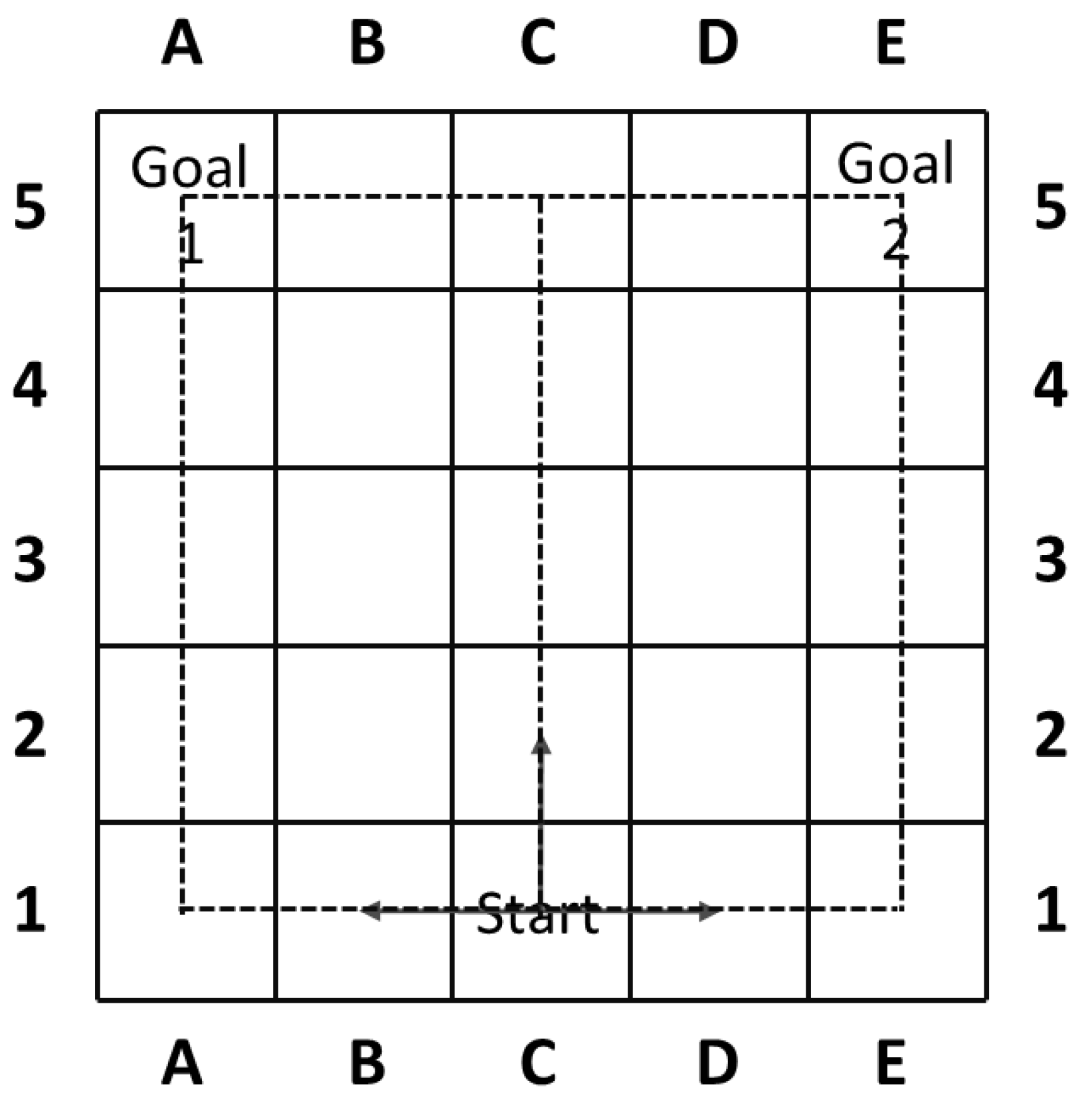
Figure 1 offers a simple example that is first mentioned in [
6] and will help to clarify the concepts of our work, which is extended from our original [
7].
The model consists of a simple room (or airport) with a single entry point, marked as ‘Start’ and two possible exit points (boarding gates), marked as ‘Goal 1’ (domestic flights) and ‘Goal 2’ (international flights). An agent can move vertically or horizontally from ‘Start’ to one of the goals. Notice that in this model, the goal of the agent becomes clear once turning left or right, while moving vertically would impose goal uncertainty on goal recognizers and postpone the goal identification. Therefore, in the worst case an optimal agent can move up 4 steps before it is obliged to turn towards its goal.
The goal uncertainty showed in the above example could be viewed as an inherent property of one particular goal recognition task, and pose a new challenge to effective goal reasoning. The problem finds itself relevant in many of the similar applications of goal recognition tasks where goal uncertainty exists. Also, it should be noted that apart from the friendly situation in
Figure 1 and works in [
6], the goal uncertainty could further be used as a potential backdoor for the adversary to delay goal identification.
Therefore, this paper focuses on effective control of the goal identification process. As a first stage of our exploration, we assume agents are optimal and that the actions of the agent are fully observable and deterministic. To achieve our objective, we introduce a new concept called relative goal uncertainty (rgu), with which we assess the goal-related information that each action contains. The rgu is a relative value associated with each action that agent would take and represents the goal uncertainty quantified by information entropy after the action is taken compared to other executable ones in each state.
The rgu value associated with each action helps in assessing the uncertainty that exists in goal recognition task, and our goal is to provide methods for agents to control it. Towards this end, we define two optimization models based on mixed-integer programming, one of which reduces the goal uncertainty through limiting the set of available actions an agent can perform, the other one delays goal identification through balancing the reward and goal uncertainty during mission planning.
Goal identification control, while relevant to goal recognition [
1] or goal reasoning, is a different task. While goal recognition aims at discovering the goals of an agent according to observations, goal identification control rather offers an offline and online combined solution for assessing and controlling the goal uncertainty to assure the goal of any optimal agent in the system is recognized. Also, different from goal recognition design problem [
6,
8,
9] which purely focuses on facilitating goal recognition offline, goal identification control provides a more compact solution for agents to control the goal uncertainty and allows this additional information to be incorporated into ongoing missions.
Finally, considering the situation where both confronting sides are trying to control the goal identification process (i.e., both sides are behaving in a strategic game-theoretic manner), the paper then proposes the Shortest-Path Largest-Uncertainty Network Interdiction model (SPLUNI), which could be viewed as a bilevel mixed-integer program.
The SPLUNI model is transformed into its dual form using KKT conditions and computed using mixed-integer programming method.
The paper is organized as follows. We start by providing the necessary background on probabilistic goal recognition. We continue by introducing the formal model representing the goal identification control problem, and the rgu value. The following sections present the methods we developed for calculating rgu and controlling the goal uncertainty of a given goal identification control problem. We conclude with an empirical evaluation, a discussion of related work, and a conclusion.
2. Background and Related Work
2.1. Probabilistic Goal Recognition
The goal recognition problem has been formulated and addressed in many ways, as a graph covering problem upon a plan graph [
10], a parsing problem over grammar [
11,
12,
13,
14], a deductive and probabilistic inference task over a static or Dynamic Bayesian Network [
15,
16,
17,
18,
19,
20] and an inverse planning problem over planning models [
21,
22,
23,
24,
25].
Among the approaches viewing the goal or plan recognition as an uncertainty problem, two formulations appear and solve the problem from different perspectives. One focuses on constructing a suitable library of plans or policies [
16,
17], while the other one takes the domain theory as an input and use planning algorithms to generate problem solutions [
21,
23]. Before reviewing these two formulations, we would first give the definition of probabilistic goal recognition (or plan recognition) as follows:
Definition 1. A probabilistic goal recognition problem or theory is a tuple where D is the problem domain, is the set of possible goals G, is an observation sequence (which may or may not be adjacent) with each being an action, and represents the prior probabilities over .
And generally, the posterior goal distribution
will be computable from the Bayes Rule as:
where
is a normalizing constant, and
is
.
The uncertainty problem is first addressed by the work [
16] which phrases the plan recognition problem as the inference problem in a Bayesian network representing the process of executing the actor’s plan. It is followed by more work considering dynamic models for performing plan recognition online [
12,
13,
26,
27]. While this offers a coherent way of modelling and dealing with various sources of uncertainty in the plan execution model, the computational complexity and scalability of inference is the main issue, especially for dynamic models. In [
17], Bui et al. proposed a framework for online probabilistic plan recognition based on the Abstract Hidden Markov Models (AHMM), which is a stochastic model for representing the execution of a hierarchy of contingent plans (termed
policies). Scalability in policy recognition in the AHMM, and the inference upon its transformed Dynamic Bayesian Network (DBN), is achieved by using an approximate inference scheme known as the Rao-Blackwellized Particle Filter (RBPF) [
28]. Generally, in a particle system, the posterior distribution is empirically represented using a weighted sum of
samples
drawn independent identically distributed from the proposal distribution [
29]:
where the importance weights
should be updated recursively.
Within this formulation, following research continues to improve the model’s expressiveness and computational attractiveness, as in [
18,
20,
30,
31,
32,
33,
34,
35,
36]. Notably, research in [
33,
36] proposes a CSSMs model which allow simple system model definition in the form of planning problem and can reason in large state spaces by using approximate inference. Also, recently machine learning methods including reinforcement learning [
35], deep learning [
3,
37] and inverse reinforcement learning [
38,
39] have already been successfully applied in learning the agents’ decision models for goal recognition tasks. These efforts once again extend the usability of policy-based probabilistic goal recognition methods by constructing agents’ behavior models from real data.
Recently, the work [
21,
22] shows that plan recognition can be formulated and solved using off-the-shelf planners, follows by work considering suboptimality [
23] and partial observability [
24]. Not working over libraries but over the domain theory where a set
of possible goals is given, this generative approach solves the probabilistic goal recognition efficiently, provided that the probability of goals is defined in terms of the
cost difference of achieving the goal under two conditions: complying with the observations, and not complying with them.
By comparing cost differences across goals, a probability distribution is generated that conforms to the intuition: the lower the cost difference, the higher the probability. Concretely, they propose the assumption of a Boltzmann distribution and take
, thus arriving at the following posterior:
where
,
is a normalizing constant across all goals, and
a positive constant which captures a ‘soft rationality’ assumption.
Several works followed this approach [
25,
40,
41,
42,
43,
44] by using various automated planning techniques to analyze and solve goal or plan recognition problems. Its basic ideas have also been applied in new problems such as Goal Recognition Design [
6], Deceptive Path-Planning [
45], etc. The advantages of the latter formulation are two-fold: one is that by using plenty of off-the-shelf model-based planners the approach scales up well, handling domains with hundreds of actions and fluents quite efficiently; the other one lies in the fact that the model-based method has no concerns about the recognition of joint plans for achieving goal conjunctions. Joint plans come naturally in the generative approach from conjunctive goals, but harder to handle in library-based methods.
According to the relationships between the observer and the observed agent, the goal or plan recognition could be further divided into
keyhole,
intended and
adversarial types [
4,
46,
47,
48]. In keyhole plan recognition, the observed agent is indifferent to the fact that its plans are being observed and interpreted. The presence of a recognizer who is watching the activity of the planning agent does not affect the way he plans and acts [
26,
49]. Intended recognition arises, for example, in cooperative problem-solving and in understanding indirect speech acts. In these cases, recognizing the intentions of the agent allows us to help or respond appropriately [
46]. In adversarial recognition, the observed agent is hostile to the observation of his actions and attempts to thwart the recognition [
50,
51].
2.2. Goal Recognition Design
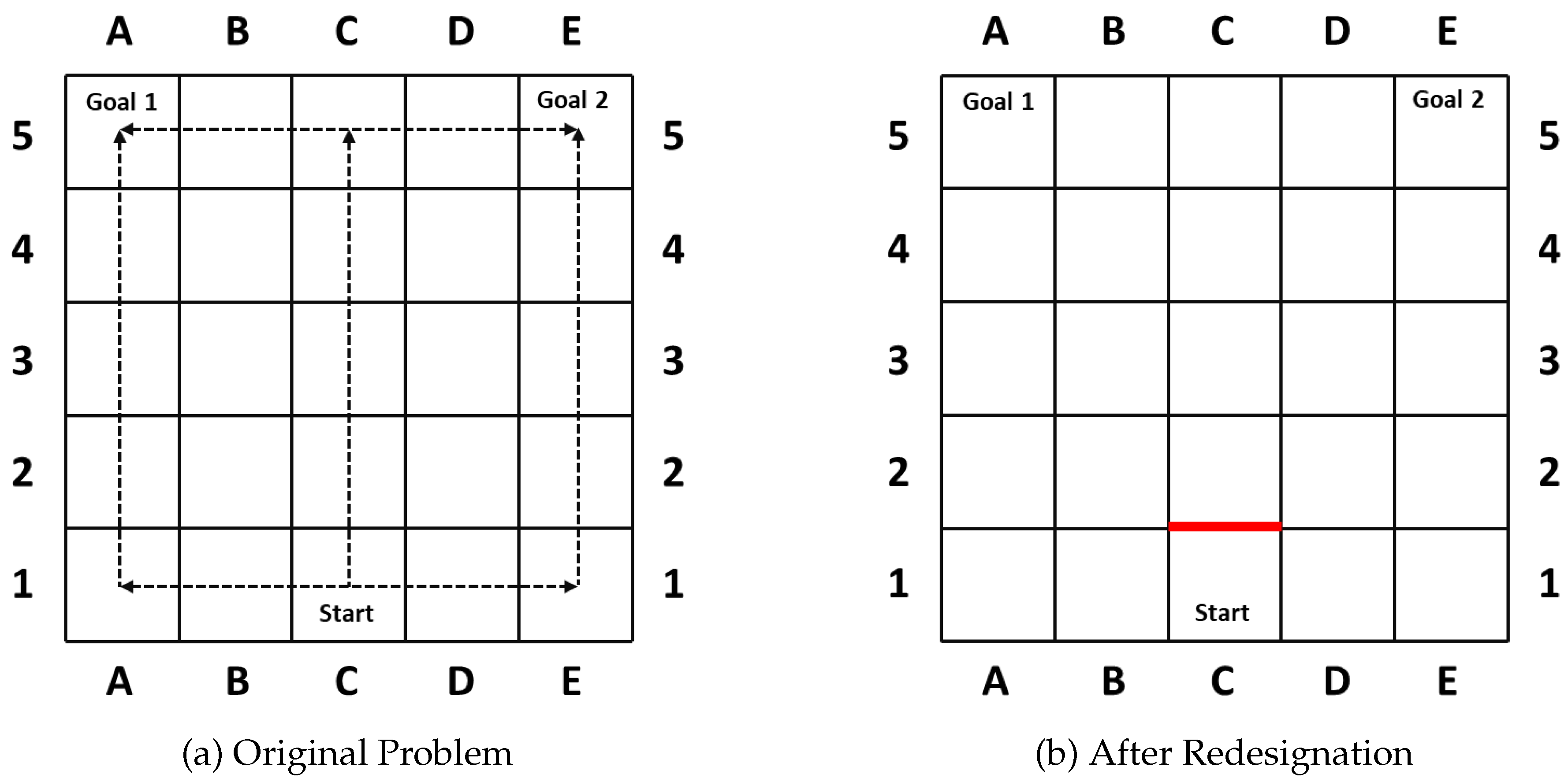
Goal recognition design was first introduced in [
6] to reduce goal uncertainty and advance the correct recognition through redesigning the underlying environment. It could be seen as an inverse problem to deceptive path-planning. Standing on the side of the observer, the GRD problem tries to reduce goal uncertainty and advance the correct recognition through redesigning the domain layout. To do so, they introduce a concept named
worst-case distinctiveness (wcd), measuring the maximal length of a prefix of a plan an agent may take within a domain before its real goal has been revealed. As in their first case [
6] shown in
Figure 2, the goal of the agent becomes clear once turning left or right, while it maintains the longest ambiguity if the agent moves straight up 4 steps (
) before it is obliged to turn towards its real goal. Thus, the blockade of the action moving the agent from
to
(
Figure 2b) successfully reduces the
wcd from 4 to 0, and prohibits the agent from hiding key information.
Since then, lots of research has been carried out. The work described in [
6,
52] extends the previous work by accounting for agents that behave non-optimally and non-observably. The work in [
53] further allows the outcomes of agents’ actions to be non-deterministic, and proposes a
Stochastic GRD problem. Apart from the relaxation of assumptions, researchers try to solve the GRD from different aspects, or use newly established metrics. Answer Set Programming [
8] was first used to address the same problem, resulting in higher scalability and efficiency. Mirsky et al. [
54] extend GRD to the Plan Recognition Design (PRD), which is the task of designing a domain using plan libraries to facilitate fast identification of an agent’s plan. Noticing the inconsistency between the original
wcd (
worst-case distinctiveness) and Stochastic GRD model, a new metric, namely
all-goals wcd (), is proposed by [
9]. Also, based on new assumption of the availability of prior information about the agent’s true goal, they further propose a
expected-case distinctiveness (ecd) metric that weighs the possible goals based on their likelihoods. Mirsky et al. [
55] further study the goal and PRD for plan libraries.
The general GRD problem [
6] is represented as a tuple
, where
captures the domain information and
G is a set of possible goal states of the agent. Except that all actions have the same cost of 1, the elements in the tuple
D are as the definitions in classical planning where
S is a finite and discrete state space;
is the start state of the agent;
A is the set of actions;
is a deterministic state transition function; and
G is a set of goal states. The
wcd of problem
P is the length of a longest sequence of actions
that is the prefix in cost-minimal plans
and
to distinct goals
. GRD’s objective is to find a subset of actions
such that if they are removed from the set of actions
A, then the wcd of the resulting problem is minimized. As summarized in [
53], the GRD task could be formulated into an optimization problem which is subject to the constraint that the cost of cost-minimal plans to achieve each goal
is the same before and after removing the subset of actions:
where
is the problem with the resulting domain
after removing actions
,
is a cost-minimal plan to achieve goal
g in the original problem
P, and
is a cost-minimal plan to achieve goal
g in
.
3. Probabilistic Goal Recognition
The authors in [
20] shows a simple yet effective probabilistic goal recognizer based on Markov Decision Process (MDP). The probabilistic goal recognition model is defined by a tuple
, where
S is a finite and discrete state space;
is the start state of the agent;
A is the set of actions;
is a deterministic state transition function;
G is a set of goal states;
e is the goal termination variable and
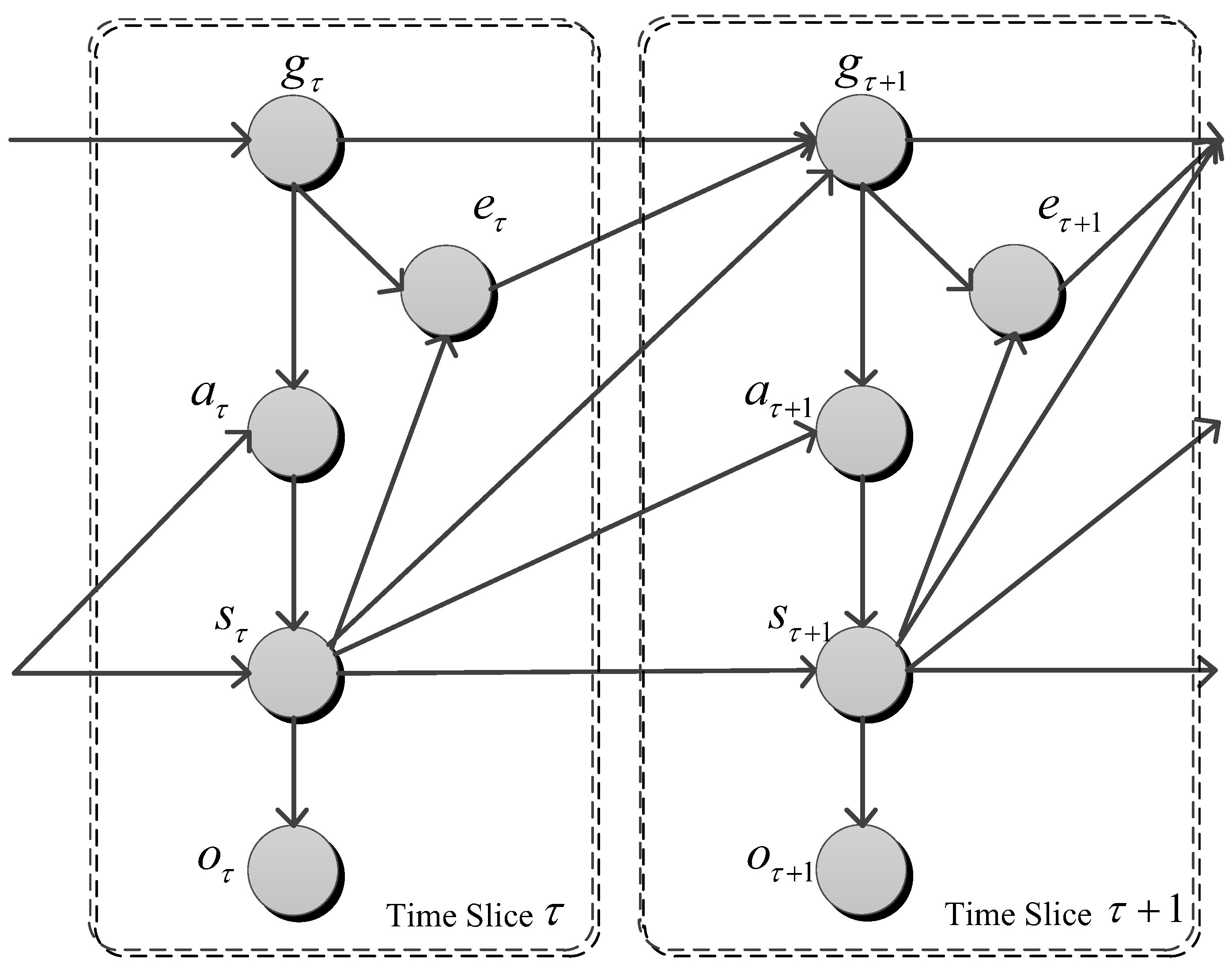
O is a non-empty observation set. Essentially, the model is a DBN, in which all causalities could be depicted. We introduce a full DBN structure depicting two time slices is presented in
Figure 3.
The behaviors of system evolution are described using functions or parameters.
state transition function is ,
observation function is ,
agent action policy ,
goal transition probability ,
goal termination probability .
Recognizing the evader’s goal is an inference problem trying to find the real goal behind agent actions based on observations online. In essence, the task is to compute the posterior distribution
of goal
given observation
. This could be achieved either by accurate inference or by approximate methods. Accurate inference, however, is not scalable when state space of the domain problem becomes large, nor can it tackle partially missing or noisy data. Widely applied in sequential state estimation, particle filter is a kind of approximate inference methods designed to handle non-Gaussian and nonlinear problems [
29]. As for the problem with a large-scale state space, methods such as [
28,
56] are preferred. In this work, we would like to simply show how the probabilistic goal recognition works, and thus the basic particle filter would be enough. In this work, the MDP or agent action model is assumed to be known by both the evader and the indicator, except for the current goal
of the evader. Instead, the set of possible goals is given along with the priors
. Similar assumptions also exist in [
24] in which the posterior goal probabilities
is obtained from Bayes Rule
where
is a normalizing constant. In particle filter however, a posterior distribution is empirically represented using a weighted sum of
samples [
29] drawn from the proposal distribution:
where
are assumed to be
i.i.d drawn from
. The importance weights
should be updated recursively
As we use simplest sampling, the
is set to be
, which could be computed directly using the agent action model:
Thus, the
in Equation (7) would be sampled from
. As the observation
only depends on
, the importance weights
can be updated by
In this work, a sequential importance sampling (SIS) filter with resampling is used in evader’s goal inference. Notably, in the resampling process, we apply the estimated
effective sample size,
, according to
where
is the normalized weight. The resampling process returns if
, where
is the pre-defined threshold which is set to
, otherwise generates a new particle set by resampling with replacement
times from the previous set with probabilities
, and then reset the weights to
.
4. Relative Goal Uncertainty
Given the set of possible goal states G and the current observation , the probability distribution over possible goals actually reflects the goal uncertainty the agent will encounter after selecting actions and reaches the next state (assuming fully observable and deterministic) according to f. This enlightens us to use the goal inference information one step ahead to measure the goal uncertainty associated with available actions at each state, specifically the adjacent edges directing out of each node in the road network example.
Defined over each possible action at state s, the metric rgu is a relative value describing the overall uncertainty performance of state s before and after the action a’s interdiction. Intuitively, this could be done by summing up the information entropy of the pre-computed, next-step goal probability which are reasoned about in the goal recognition problem , where and , the set of states that could arrive at according to .
Definition 2. (Entropy-based rgu) The Entropy-based
rgu () over a goal identification control problem is defined as:where , and . The entropy computes the goal uncertainty contained in the reasoning result, and . Technically, we also need to remove zero entries of , followed by normalization guaranteeing that . The
quantified by entropy
H evaluates the goal uncertainty in a natural and compact way. More uncertainty introduced after the agent takes its action gives less information to goal recognizer and postpones the goal identification process. As the example in
Figure 1 and assuming the agents are fully optimal, the
for three actions leading to states
,
and
are
,
and
respectively. Also, the definition of
could easily be applied to tasks where
. It should be noted that the definition of
makes sure that this metric can be naturally applied to the situation where the agent changes its goal during the midway.
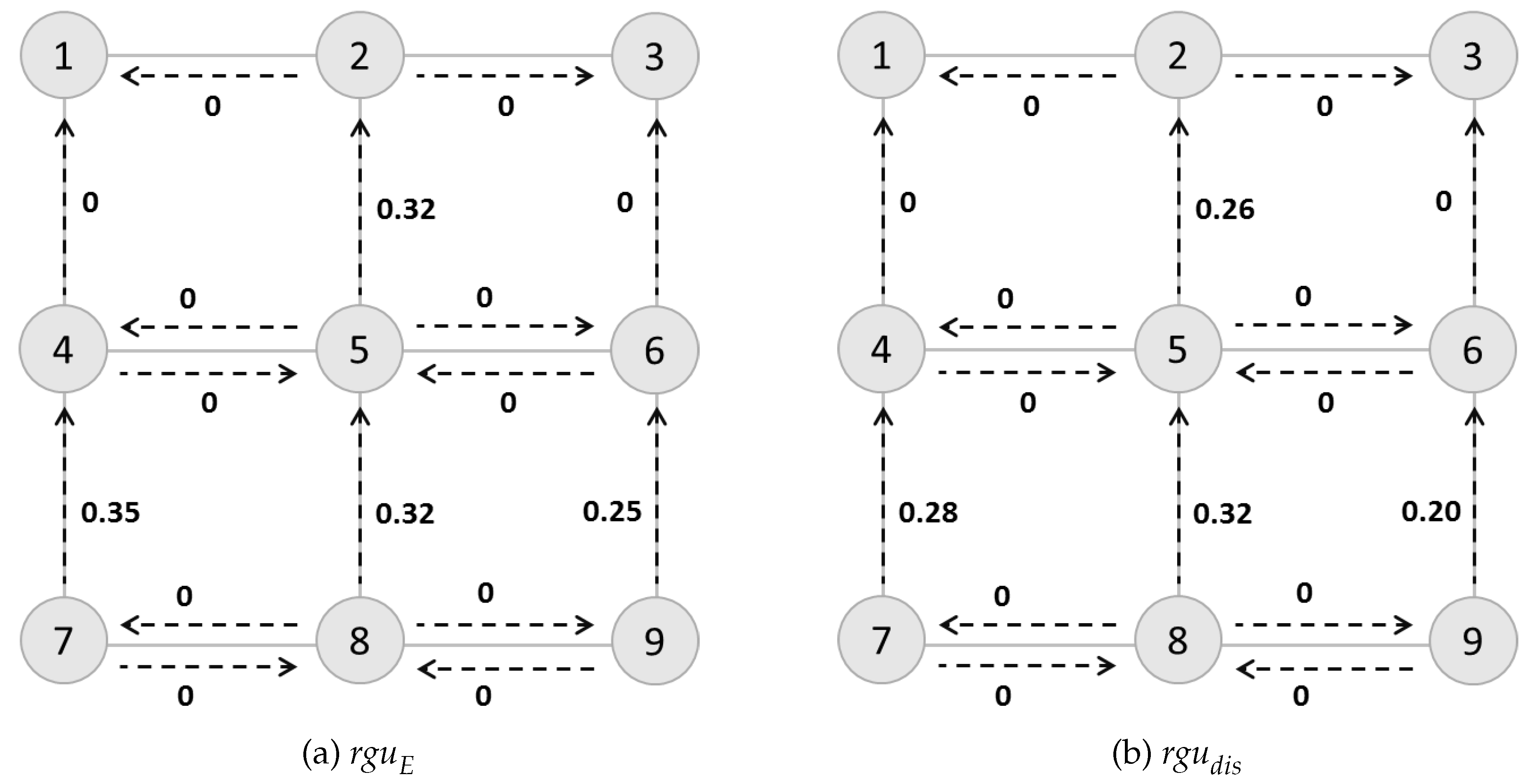
To illustrate how
would be used in goal identification control problem and for clarity, we compute the values upon a
grid network (
Figure 4a) with nodes representing grids and dashed edges connecting nodes. Selecting absorbing nodes No.1 and No.3 as possible goals, we compute
for each action depicted as dashed line, as shown in
Figure 4a. Higher
means greater uncertainty associated with that action. Here we discuss two path-planning tasks
T and
, where the agent has different starting points (
or
). The tasks are defined as
, with
to model the road barrier, patrolling police or other methods the goal recognizer could use in order to control the goal identification process.
For the first task, the agent would choose for goal No.1 and for goal No.2. While for the second task, using the definition of , the agent would choose one of the two optimal routes ( or ), other than for goal No.1, and or other than for goal No.3. For the latter case, we find that cannot help the agent capture the fact in goal identification control that early interdiction would be more important than a later one.
To solve this problem, we define a discounted so as to reduce the value along with the increase of the number of steps that agent has taken from the start. For agent changing its goal during the midway, we could recompute this value from the original . Case 3.1 shown in Section 4.1, which is talked about in the next section, gives a good indication of this situation occurrence.
Definition 3. (Discountedrgu rgu) The discounted rgu () of a goal identification control problem is defined as:where β is the discount factor and d is the number of steps that agent has taken from the start. With the discount factor equals to
,
Figure 4b shows the discounted
values which have been adjusted according to its importance to the goal identification control task.
5. Goal Identification Control
In this section, we show how to control the
using the optimization technique. Instead of requiring the cost of cost-minimal plans to achieve each goal
be the same before and after removing the subset of actions, as researched about in goal recognition design problem [
6], we are more interested in deliberate changing goal uncertainty under adversarial settings where the resource constraint compared to optimality conservation is more applicable. Also, the original way of removing actions permanently is changed “softer” by adding additional costs to actions.
5.1. Reduction and Improvement of rgu
The goal identification control models based on optimization techniques are introduced. We first present models which are individually used for reducing and improving goal uncertainty for the different sides of the goal recognition task. Then we talk about the applicability of the offline-computed in the online goal identification control.
The models could be transformed into the problem of maximizing (minimizing) the expectation of “s–t” path length, with the
being proportionally added to the original length. The mathematical-programming formulation of our new goal identification control model is as follows:
The formulation of
rgu reduction problem (
[RGUR-P]) for the observer is:
where
, Equation (
14) is the flow-balance constraint.
While the formulation of
rgu improvement problem (
[RGUI-P]) for the observed agent is:
where
. Thus, with additional goal uncertainty information, the problem could be transformed into network interdiction models, which are of a typical mixed-integer program (MIP) and solved using linear programming algorithms.
Figure 5 shows two moving traces of the observed agent under [RGUR-P] and [RGUI-P] problems. The observer could use [RGUR-P] to reduce the enemy’s goal uncertainty and accelerate situation awareness, while the observed agent, after analyzing the observer’s goal recognition task, could actually use [RGUI-P] to cover its real intention to the maximum extent. General results would be given in
Section 6.
Please note that until now, the metric used for assessing goal uncertainty is defined over actions available at each state in an offline manner, i.e., are computed according to with prior probability following Uniform distribution, instead of over agent’s full course of actions where the real-time contains history information, this may incur uncertainty inconsistency among individual states and the whole task. Fortunately, our definition of rgu has no effect on problem-solving of the goal identification control,
Case 1: If the real-time prior cannot help observer distinguish the right goal, meaning that is relatively high. Then it is naturally established for agents choosing actions with either high or low uncertainty.
Case 2: If distinguishes the goals clearly where is relatively low, and agent chooses the action that has high uncertainty, i.e., , then highly uncertain action would input little information to the original beliefs about agent goals. The agent’s belief of the right goal would still maintain. However, in this case, resource needed for action interdiction would be wasted as little information would be given and agent’s intention usually maintains for a period.
Case 3: Also, if distinguishes the goals clearly, e.g., the prior for goal g with the largest value, while agent chooses the action that has low uncertainty rgu, then two cases should be considered. Firstly, agent’s belief of the right goal has changed according to the posterior (Case 3.1). This happens when the agent is changing its goal from g to during the midway, and thus chooses the action that will lead to . Secondly, the computed posterior still capture the right goal g (Case 3.2). For both cases, the rgu works properly.
5.2. The SPLUNI Model and Its Dual Form
After individually talk about rgu reduction and improvement, in this section we propose a SPLUNI model, where uncertainty becomes another optimization objective along with path length. The SPLUNI model could be viewed as a bilevel mixed-integer program (BLMIP).
The problem description of SPLUNI is similar to [RGUR-P] and [RGUI-P], whereas it is described as maximizing the expectation of the shortest
path length while minimizing the largest uncertainty and
. Its mathematical-programming formulation is given as:
with the same constraints as Equations (
14) and (
15) and
.
are parameters controlling the importance of goal uncertainty between two objectives.
As a BLMIP problem, which cannot be solved directly using the MIP approaches, we propose a dual reformulation of SPLUNI. Fix the outer variable
x and take the dual of the inner minimization using KKT conditions, the final MIP formulation is given as:
where
is the network matrix controlling
as in Equation (
14),
,
,
and
.
6. Experiments
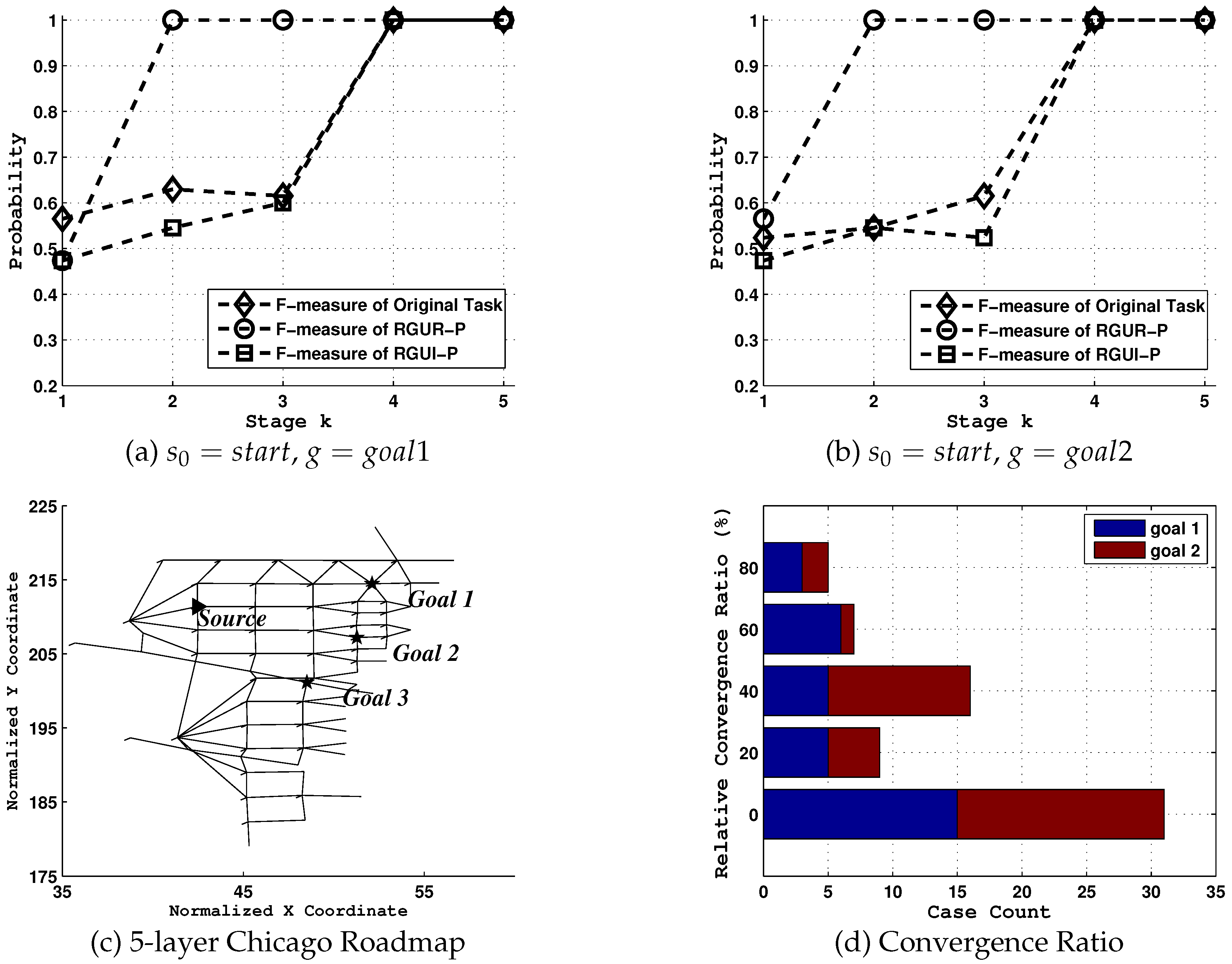
For simplicity, we select a reduced Chicago Sketch Road Network [
20] expanded from the vertex No.368 to its neighbors and neighbors’ neighbors for 5 times, consisting of 51 vertexes and 113 edges. The computations of the RGUR and RGUI are formulated into a BLMIP, and SPLUNI into a BLMIP and solved using the MIP solvers of CPLEX 11.5 and YALMIP toolbox of MATLAB [
57]. Nontrivial details are omitted.
6.1. Tests on Uncertainty Reduction
Upon the reduced Chicago Sketch Road Network, a goal recognition task is defined where
,
as shown in
Figure 6c. We first show the influence of uncertainty on the goal recognition system and how
rgu reduction model could be used in advancing situation awareness.
In this test, a dataset consisting of 100 labeled traces for each goal is collected using agent decision model, and we use
F-measure which is a frequently used metric to measure the overall accuracy of the recognizer [
1], computed as:
where
N is the number of possible goals,
,
and
are the true positives, total of true labels, and the total of inferred labels for class
i respectively. Equations (
20) to (
22) show that
F-measure is an integration of precision and recall, where
precision is used to scale the reliability of the recognized results and
recall to scale the efficiency of the algorithm applied in the test dataset. The value of
F-measure will be between 0 and 1, and a higher metric value means a better performance. As to evaluate traces with different lengths, the paper applies the method in [
35], and partitions each trace into
k stages. The corresponding sequences are
.
From the results shown in
Figure 6a,b, goal uncertainty associated with certain domains indeed seriously impedes effective goal identification. Under [RGUR-P] model, the values of
F-measure after the network redesignation increases to almost 1 the moment agent selects its first action, compared to values under tasks with no network changes and the most ambiguous situation ([RGUI-P]). While for the RGUI-P model, its
F-measure values are equal or greater than those of the original task in most times. Note the big difference of
F-measure values between two models, i.e., [RGUR-P] and [RGUI-P], this simple case not only proves that the goal uncertainty could be purposefully controlled in both directions, but also shows the potential advantage that the observer could take off during the goal identification process.
Next, we statistically evaluate the maximum early prediction that our model enables according to
Convergence Point metric [
1], defined as
,
.
denote the time step at which the posterior of the agent’s true goal is greater or equal to
. For tests in
Figure 6d,
is set to
. We test recognition tasks
for
, where
U is the set of nodes with no available paths to
G, and compare the early convergence ability of goal identification between [RGUR-P] and [RGUI-P] using a new metric
, which describes the relative convergence ratio (
) between two models given the
path length,
where
is the length of path starting from
while ending at the real goal
.
Clearly, both for tasks where equals to and , there are considerable reductions of goal uncertainty. For example, there are total 5 cases in these two tasks whose relative convergence ratio is greater than or equal to . In addition, 7 cases in total fall within the 60%–80% interval, 16 at 40%–60% and 9 at 20%–40%. It should also be noted that there are more than 30 cases whose RelConvergeRatio equals to 0. This means that although the goal uncertainty widely exists in many identification tasks, it does not exist in every case.
Further for generality, we test 3 more cases where
,
and
, as shown in
Table 1. From these results, we could conclude that:
goal uncertainty exists in normal goal recognition task, and it could be purposefully controlled to affect the agent’s situation awareness.
the possible reduction of goal uncertainty differs in each scenario.
6.2. Performance of SPLUNI
Finally, we test the performance of SPLUNI (set
), which is the game between the observer (interdictor) and the observed agent (evader), in maximizing the expectation of the shortest
path length while minimizing the largest uncertainty, as shown in
Table 2. We first define the path interdiction efficiency as
where
is the increased path length for evader after interdiction and
is the total length increase in the network. The tests are conducted over those ambiguous cases in three goal settings.
and
help us understand the impact of SPLUNI model on both network interdiction and goal uncertainty reduction.
Clearly, SPLUNI model works well for observer by adding the evader’s path length and at the same time reducing the goal uncertainty during the process. In all three goal settings, the average path interdiction efficiencies are more than 50%. Especially when , reaches to almost for and more than for . This proves the effectiveness of SPLUNI model in network interdiction. Also, the model successfully reduces the goal uncertainty to a certain level in three different settings, as we could find in the data of . The above results show that the SPLUNI model that we propose is of great value for security domains where high-value targets need to be timely recognized meanwhile the intruder’s actions be delayed.
7. Conclusions
We present a new perspective of goal identification control using off-the-shelf probabilistic goal recognizer, and introduce the relative goal uncertainty (rgu) value for actions in a goal recognition task. We present ways of controlling goal uncertainty, followed by a presentation of the method in an adversarial setting using a SPLUNI model. Empirical evaluation shows the effectiveness of the proposed solution in controlling goal uncertainty in recognition tasks.
The work grounds the behaviors of the agents on clear, well-founded computational models. Inference over graphic models and mixed-integer programming is brought together to provide a compelling solution to the goal identification problem. Though this work is quite suggestive but still simple, which means there are many open problems in our future work. Currently, as there exists inconsistency of goal uncertainty between the offline which follows Uniform distribution and the real-time assessed online according to the agent’s observations, how to incorporate the goal uncertainty information into the goal identification control process online has not yet been solved. Also, we will also try to incorporate rgu definition into the plan identification process to improve the method’s applicability.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}