Reduction of Markov Chains Using a Value-of-Information-Based Approach



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Literature Review
3. Methodology
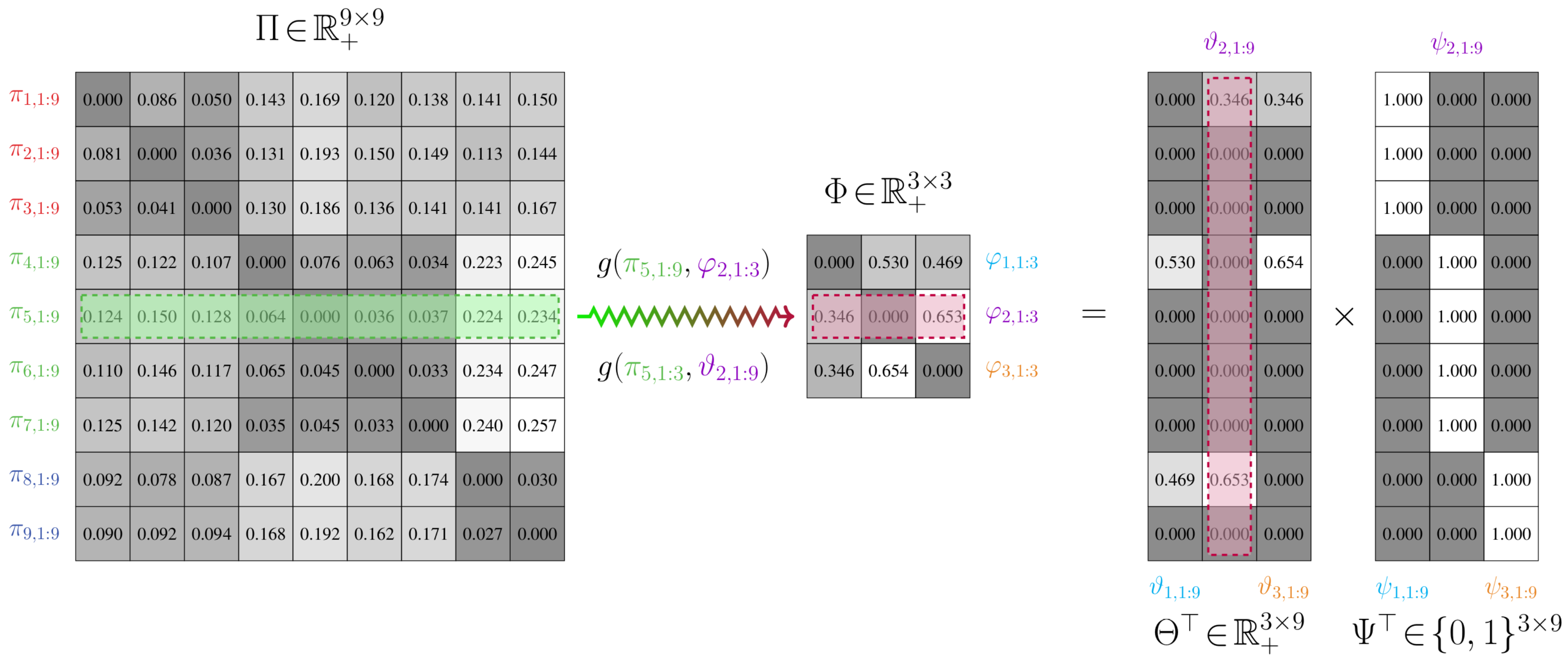
3.1. Aggregating Markov Chains
3.1.1. Preliminaries
- (i)
- A set of n vertices representing the states of the Markov chain.
- (ii)
- A set of edge connections between reachable states in the Markov chain.
- (iii)
- A stochastic transition matrix . Here, represents the non-negative transition probability between states i and j. We impose the constraint that the probability of experiencing a state transition is independent of time.
- (i)
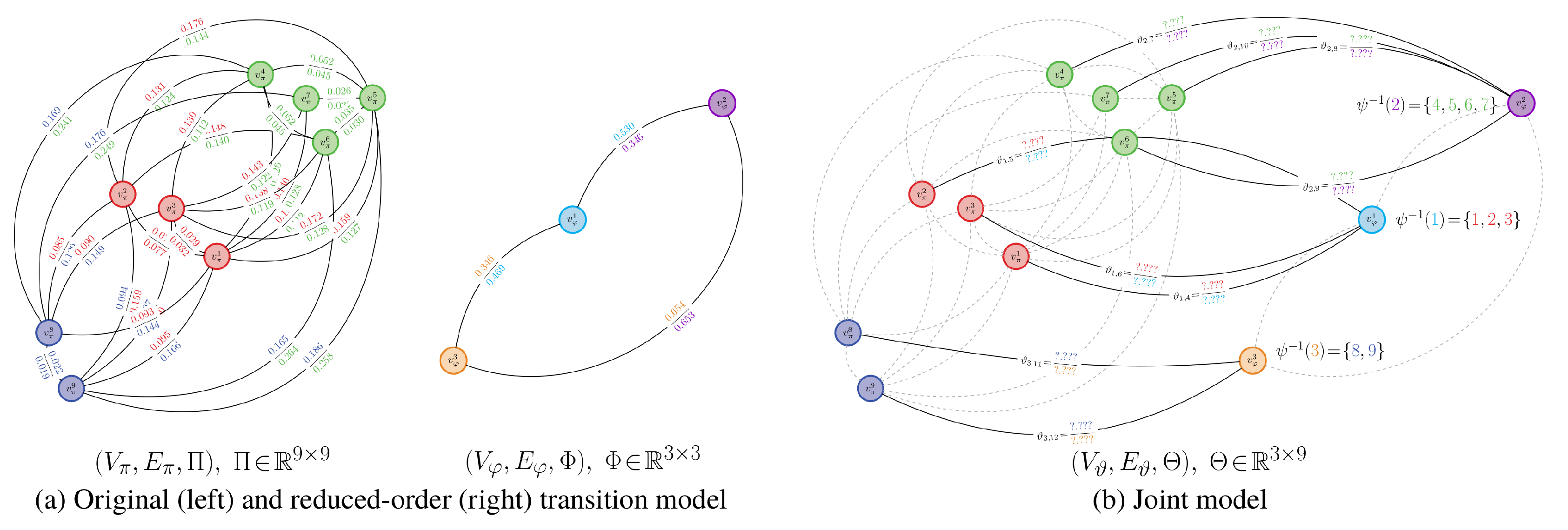
- A vertex set , which is the union of all state vertices in and . For simplicity, we assume that the vertex set for the intermediate transition model is indexed such that the first m nodes are from and the remaining n nodes are from .
- (ii)
- An edge set , which are one-to-many mappings from the states in the original transition model to the reduced-order transition model .
- (iii)
- A weighting matrix Θ, which is such that , . The partition function ψ provides a relationship between the stochastic matrices Φ and Θ of and , respectively. This is given by , or, rather, , where .
3.1.2. Partitioning Process and State Aggregation
- (i)
- Optimal partitioning: Find a binary partition matrix Ψ that leads to the least total distortion between the models and . As well, find the corresponding weighting matrix Θ that satisfiesSolving this problem partitions the n vertices of the relational matrix into m groups.
- (ii)
- Transition matrix construction: Obtain the transition matrix for from the following expression: using the optimal weights Θ and the binary partition matrix Ψ from step (i).
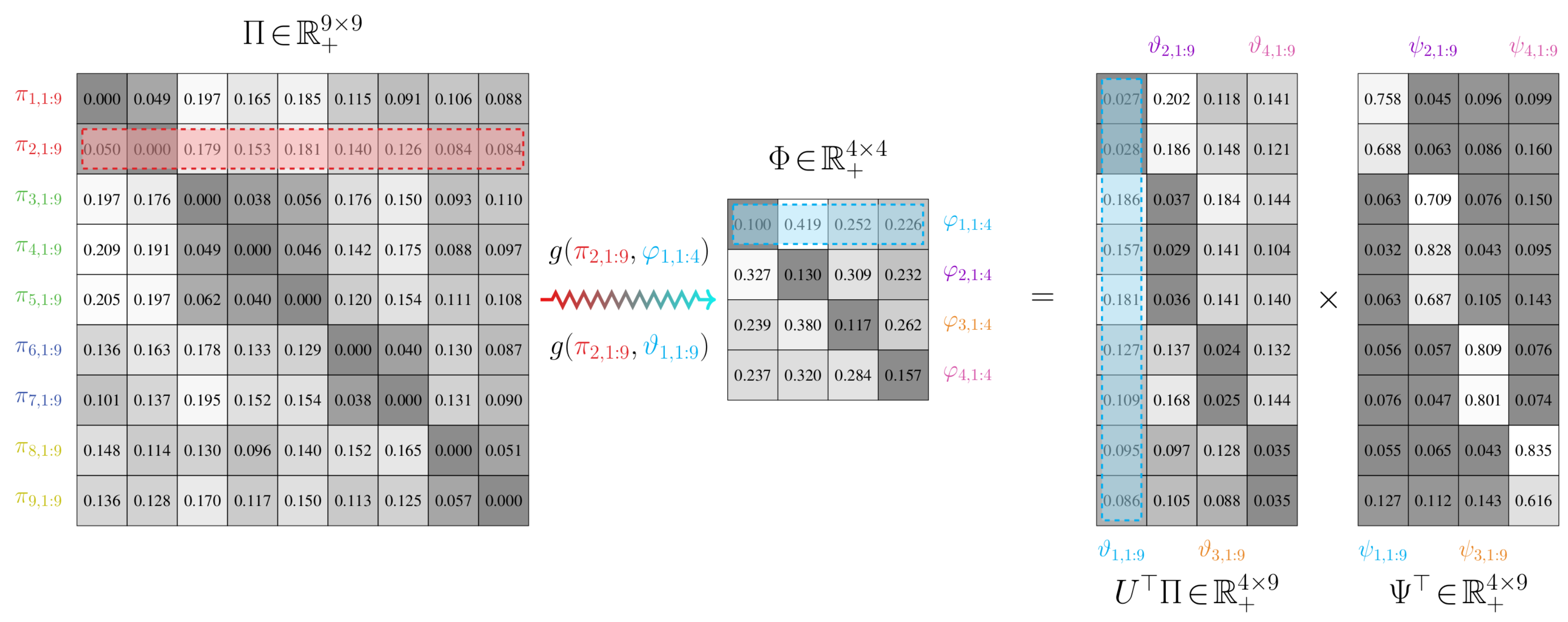
3.2. Approximately Aggregating Markov Chains
3.2.1. Preliminaries
- (i)
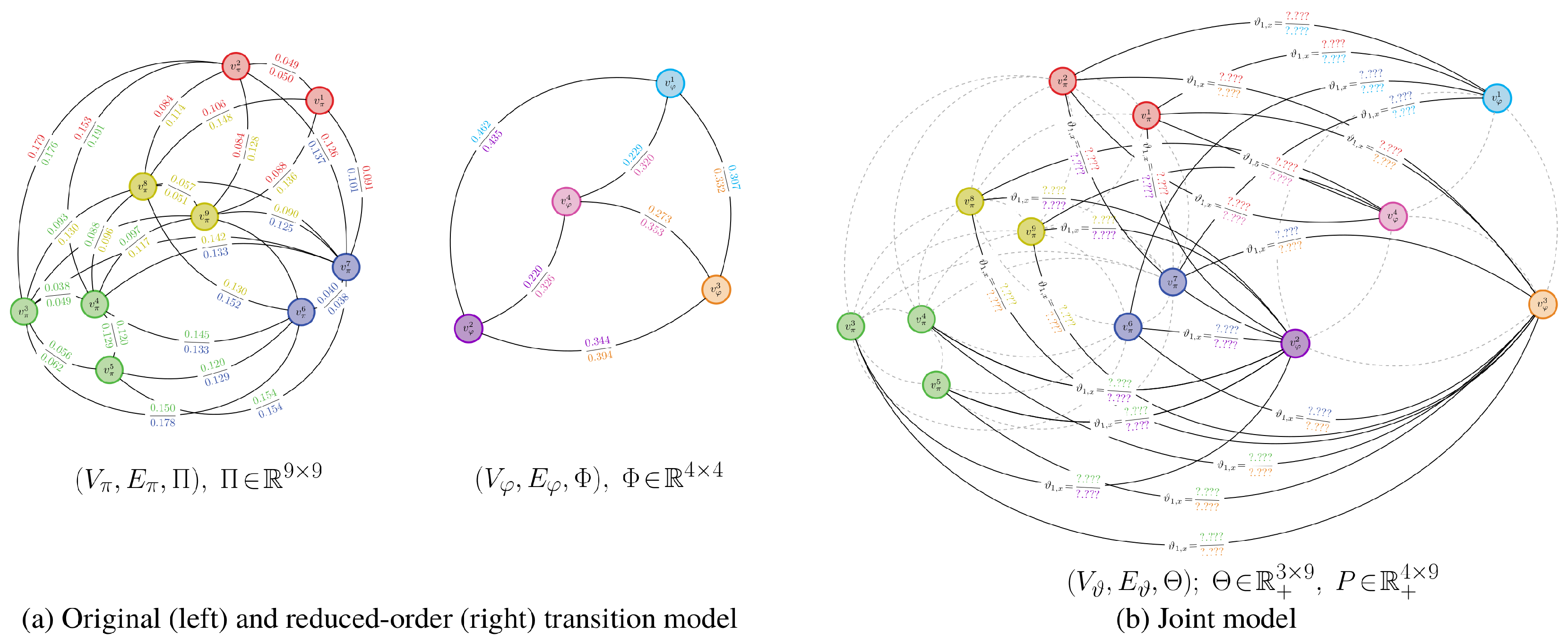
- A vertex set , which is the union of all state vertices in and .
- (ii)
- An edge set , which are one-to-many mappings from the states in the original transition model to the reduced-order transition model .
- (iii)
- A weighting matrix . The partition function ψ provides a relationship between the stochastic matrices Φ and Θ of and , respectively. This is given by , or, rather, , where is the probabilistic partition matrix.
3.2.2. Partitioning Process and State Aggregation
- (i)
- Optimal partitioning: Find a probabilistic partition matrix Ψ that leads to the least expected distortion between the models and . As well, find the corresponding weighting matrix Θ that satisfiesfor some positive value of r; r has an upper bound of . The variables α, γ, and ψ all have probabilistic interpretations: and correspond to marginal probabilities of states and , while is the conditional probability of state mapping to state .
- (ii)
- Transition matrix construction: Obtain the transition matrix for from the following expression: using the optimal weights Θ and the probabilistic partition matrix Ψ from step (i).
- (i)
- The approximation error is non-negative
- (ii)
- The modified free energy monotonically decreases across all iterations k.
- (iii)
- For any , we have the following bound for the sum of approximation errors
- (i)
- The transition matrix Φ of a low-order Markov chain over states m is given by , where . Here, for the probabilistic partition matrix found using the updates in Proposition 1.
- (ii)
- Suppose that we have a low-order chain over m states with a transition matrix Φ and weight matrix Θ given by (i). For some , suppose , the matrix Θ for that value of , satisfies the following inequality . Here, is a matrix such that and . A critical value , occurs whenever the minimum eigenvalue of the matrixis zero. The number of rows in Θ and columns in Ψ needs to be increased for .
3.2.3. Partitioning Process and State Aggregation
- (i)
- A set of n vertices representing the states of the Markov chain.
- (ii)
- A set of edge connections between reachable states in the Markov chain.
- (iii)
- A stochastic transition matrix . Here, represents the non-negative transition probability between states i and j. We impose the constraint that the probability of experiencing a state transition is independent of time. Moreover, for a block-diagonal matrix with zeros along the diagonal, we have that . Here, is a completely-decomposable stochastic matrix with m indecomposable sub-matrix blocks of order .Since Π and are both stochastic, the matrix must satisfy the equality constraint , for blocks and . That is, they must obey . Additionally, the maximum degree of coupling between sub-systems and , given by the perturbation factor ε, must obey .
- (i)
- The associated low-order stochastic matrix found by solving the value of information is given by , where represent state indices associated with block i, while represents a state index into block j. The variable denotes the invariant-distribution probability of state p in block i of Π.
- (ii)
- Suppose that is approximated by the entries of the first left-eigenvector for block i of . We then have thatwhere the first term is the invariant distribution of the low-order matrix , under the simplifying assumption, and is the probabilistic partition matrix found by solving the value of information.
4. Simulations
4.1. Simulation Protocols
4.2. Simulation Results and Analyses
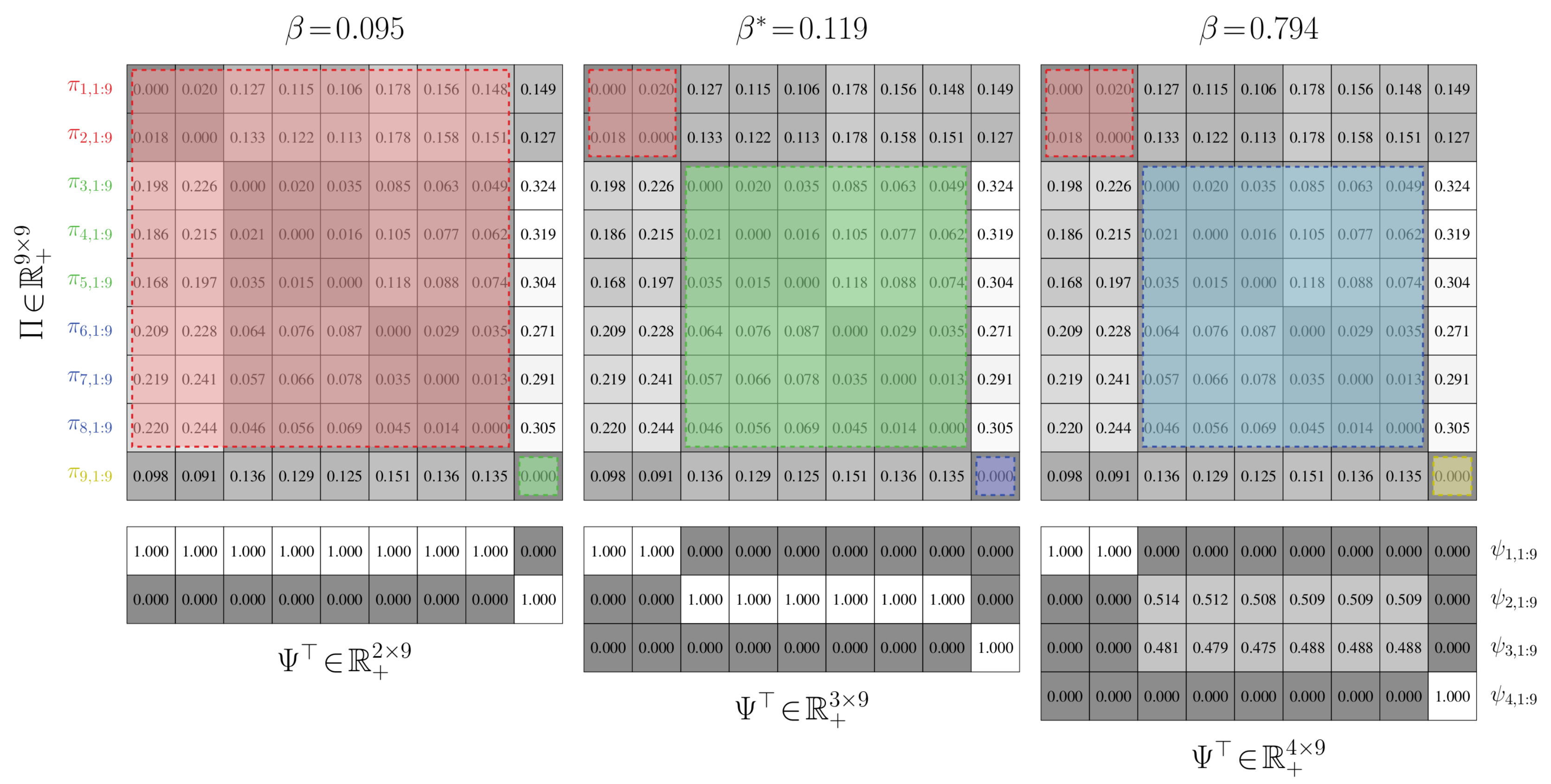
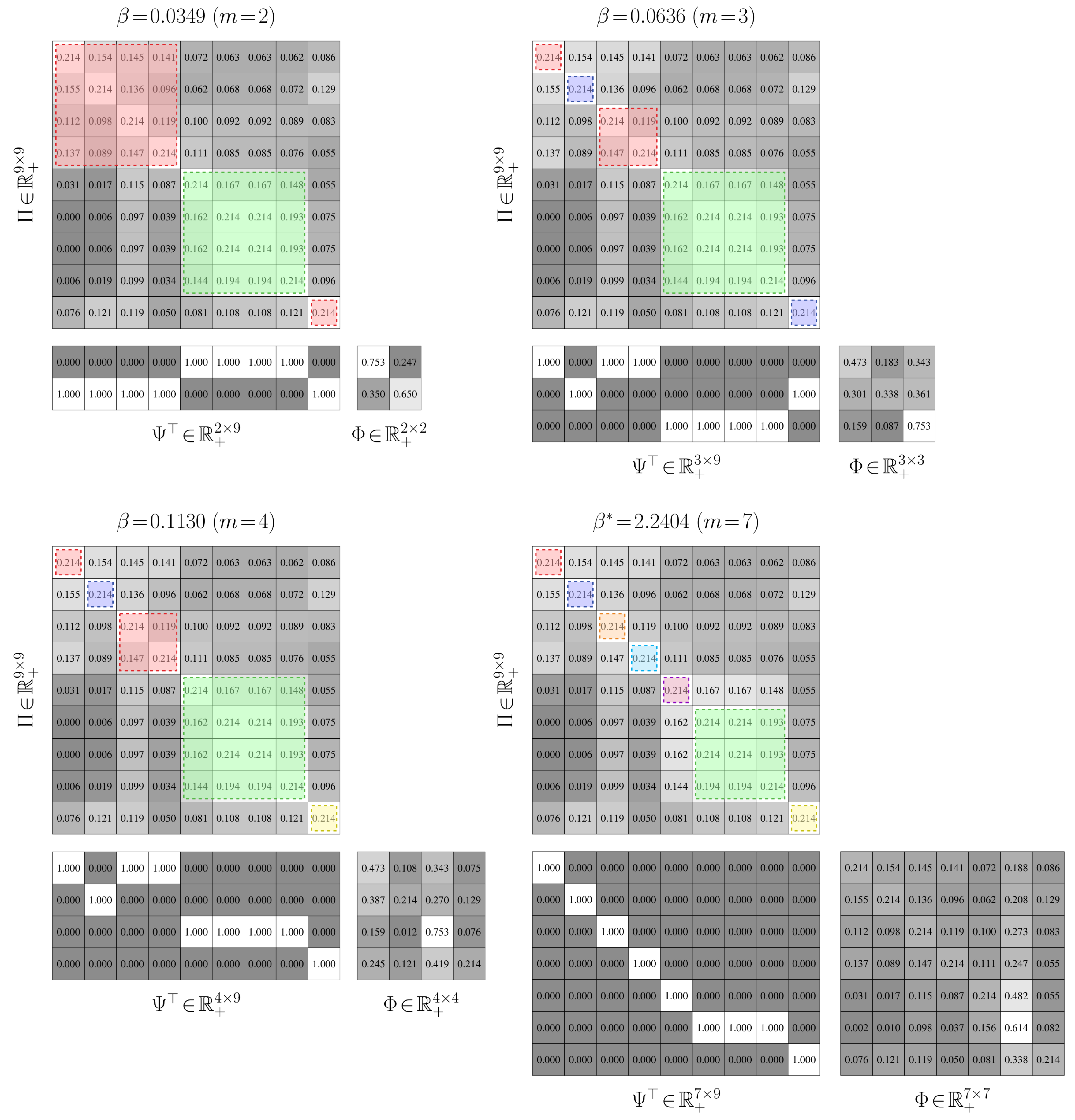
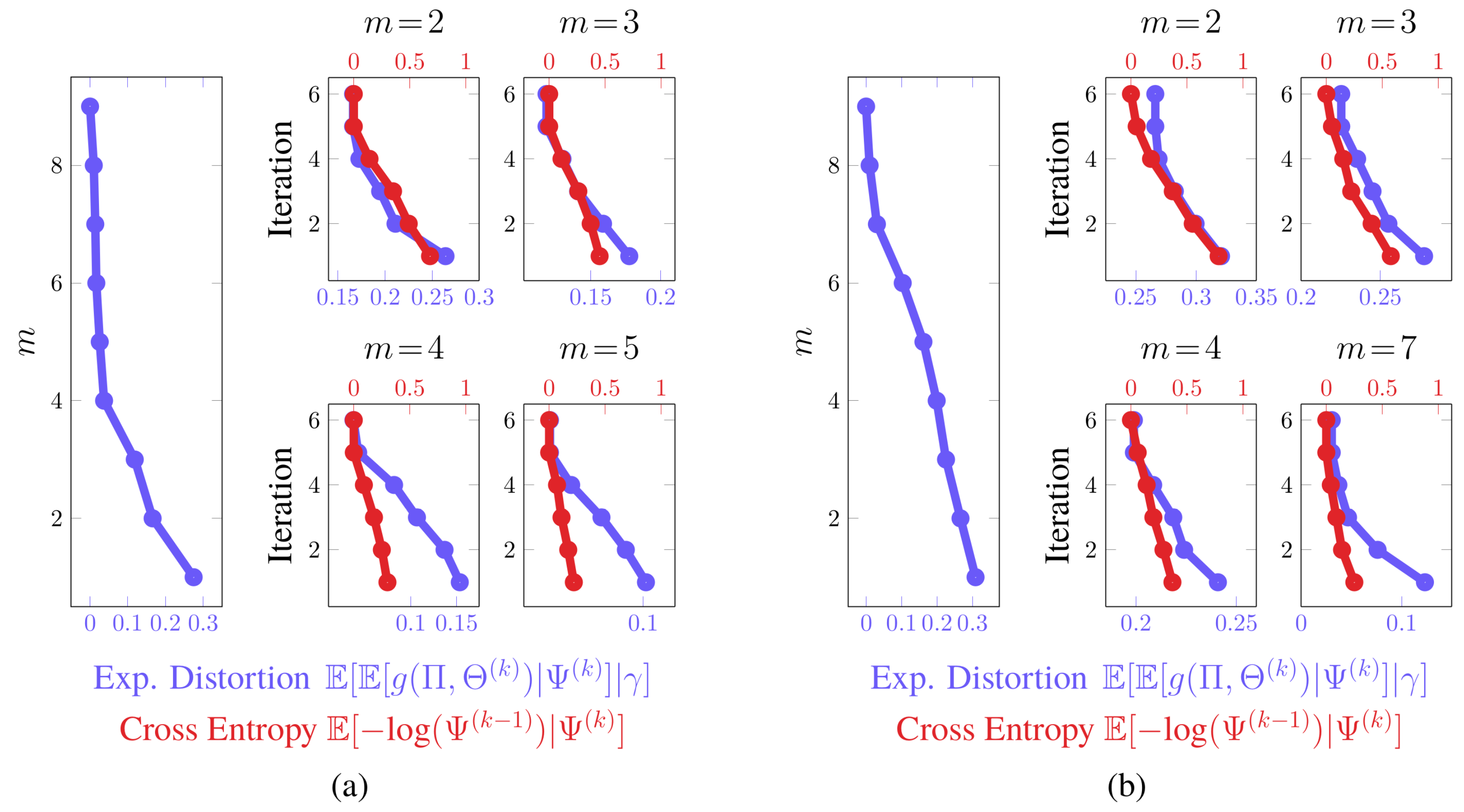
4.2.1. Value-of-Information Aggregation
4.2.2. Value-of-Information Aggregation Discussions
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Nomenclature
| Weighted, directed graph associated with a stochastic matrix | |
| Vertex set for ; represents the n states of the original Markov chain, with the ith state denoted by | |
| Edge set for ; represents the reachability between states of the original Markov chain | |
| A stochastic matrix of size for the original Markov chain; the i-jth entry of this matrix is denoted by | |
| The ith row of ; describes the chance to transition from state i to all other states in the original chain | |
| Weighted, directed graph associated with a stochastic matrix | |
| Vertex set for ; represents the m states of the reduced-order Markov chain, with the jth state denoted by | |
| Edge set for ; represents the reachability between states of the reduced-order Markov chain | |
| A stochastic matrix of size for the reduced-order Markov chain; the i–jth entry of this matrix is denoted by | |
| The jth row of ; describes the chance to transition from state j to all other states in the reduced-order chain | |
| The unique invariant distribution associated with the original Markov chain; the ith entry is denoted by and describes the probability of being in state | |
| g | A divergence measure; written either as , when comparing the entirety of to , or , when comparing rows and of the stochastic matrices |
| A partition function | |
| A partition matrix; the i–jth entry of this matrix is denoted by and represents the conditional probability between states and | |
| Weighted, directed graph associated with a stochastic matrix | |
| Vertex set for ; represents the states of the original Markov chain, with the kth state denoted by | |
| Edge set for ; represents the reachability between states of the original Markov chain | |
| A stochastic matrix of size ; the j–kth entry of this matrix is denoted by | |
| U | A matrix of size ; the i–jth entry of this matrix is denoted by |
| e | A unit vector; the ith unit vector is denoted by |
| q | The total distortion; written as for the weighted, directed graphs and |
| The marginal probability; the jth entry, describes the probability of being in state | |
| r | A non-negative value for the Shannon-mutual-information bound |
| F | The value of information |
| The corresponding hyperparameter associated with r | |
| , | The initial and critical values of |
| Q | An offset matrix; the j–ith entry of this matrix is denoted by |
| An offset amount | |
| C | An offset matrix; the p–kth entry of this matrix is denoted by |
Appendix A
- (i)
- The approximation error is non-negative
- (ii)
- The modified free energy monotonically decreases across all iterations k.
- (iii)
- For any , we have the following bound for the sum of approximation errors
- (i)
- The transition matrix Φ of a low-order Markov chain over states m is given by , where . Here, for the probabilistic partition matrix found using the updates in Proposition A1.
- (ii)
- Suppose that we have a low-order chain over m states with a transition matrix Φ and weight matrix Θ given by (i). For some , suppose , the matrix Θ for that value of , satisfies the following inequality . Here, is a matrix such that and . A critical value , occurs whenever the minimum eigenvalue of the matrixis zero. The number of rows in Θ and columns in Ψ needs to be increased once .
- (i)
- The associated low-order stochastic matrix found by solving the value of information is given by , where represent state indices associated with block i, while represents a state index into block j. The variable denotes the invariant-distribution probability of state p in block i of Π.
- (ii)
- Suppose that is approximated by the entries of the first left-eigenvector for block i of . We then have thatwhere the first term is the invariant distribution of the low-order matrix , under the simplifying assumption, and is the probabilistic partition matrix found by solving the value of information.
References
- Arruda, E.F.; Fragoso, M.D. Standard dynamic programming applied to time aggregated Markov decision processes. In Proceedings of the IEEE Conference on Decision and Control (CDC), Shanghai, China, 15–18 December 2009; pp. 2576–2580. [Google Scholar] [CrossRef]
- Aldhaheri, R.W.; Khalil, H.K. Aggregation of the policy iteration method for nearly completely decomposable Markov chains. IEEE Trans. Autom. Control 1991, 36, 178–187. [Google Scholar] [CrossRef]
- Ren, Z.; Krogh, B.H. Markov decision processes with fractional costs. IEEE Trans. Autom. Control 2005, 50, 646–650. [Google Scholar] [CrossRef]
- Sun, T.; Zhao, Q.; Luh, P.B. Incremental value iteration for time-aggregated Markov decision processes. IEEE Trans. Autom. Control 2007, 52, 2177–2182. [Google Scholar] [CrossRef]
- Jia, Q.S. On state aggregation to approximate complex value functions in large-scale Markov decision processes. IEEE Trans. Autom. Control 2011, 56, 333–334. [Google Scholar] [CrossRef]
- Aoki, M. Some approximation methods for estimation and control of large scale systems. IEEE Trans. Autom. Control 1978, 23, 173–182. [Google Scholar] [CrossRef]
- Príncipe, J.C. Information Theoretic Learning; Springer-Verlag: New York, NY, USA, 2010. [Google Scholar]
- Rached, Z.; Alajaji, F.; Campbell, L.L. The Kullback-Leibler divergence rate between Markov sources. IEEE Trans. Inf. Theory 2004, 50, 917–921. [Google Scholar] [CrossRef]
- Donsker, M.D.; Varadhan, S.R.S. Asymptotic evaluation of certain Markov process expectations for large time I. Commun. Pure Appl. Math. 1975, 28, 1–47. [Google Scholar] [CrossRef]
- Donsker, M.D.; Varadhan, S.R.S. Asymptotic evaluation of certain Markov process expectations for large time II. Commun. Pure Appl. Math. 1975, 28, 279–301. [Google Scholar] [CrossRef]
- Deng, K.; Mehta, P.G.; Meyn, S.P. Optimal Kullback-Leibler aggregation via spectral theory of Markov chains. IEEE Trans. Autom. Control 2011, 56, 2793–2808. [Google Scholar] [CrossRef]
- Geiger, B.C.; Petrov, T.; Kubin, G.; Koeppl, H. Optimal Kullback-Leibler aggregation via inforamtion bottleneck. IEEE Trans. Autom. Control 2015, 60, 1010–1022. [Google Scholar] [CrossRef]
- Sledge, I.J.; Príncipe, J.C. An analysis of the value of information when exploring stochastic, discrete multi-armed bandits. Entropy 2018, 20, 155. [Google Scholar] [CrossRef]
- Sledge, I.J.; Príncipe, J.C. Analysis of agent expertise in Ms. Pac-Man using value-of-information-based policies. IEEE Trans. Comput. Intell. Artif. Intell. Games 2018. [Google Scholar] [CrossRef]
- Sledge, I.J.; Emigh, M.S.; Príncipe, J.C. Guided policy exploration for Markov decision processes using an uncertainty-based value-of-information criterion. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2080–2098. [Google Scholar] [CrossRef]
- Stratonovich, R.L. On value of information. Izv. USSR Acad. Sci. Technical Cybern. 1965, 5, 3–12. [Google Scholar]
- Stratonovich, R.L.; Grishanin, B.A. Value of information when an estimated random variable is hidden. Izv. USSR Acad. Sci. Technical Cybern. 1966, 6, 3–15. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley and Sons: New York, NY, USA, 2006. [Google Scholar]
- Von Neumann, J.; Morgenstern, O. Theory of Games and Economic Behavior; Princeton University Press: Princeton, NJ, USA, 1953. [Google Scholar]
- Simon, H.A.; Ando, A. Aggregation of variables in dynamic systems. Econometrica 1961, 29, 111–138. [Google Scholar] [CrossRef]
- Courtois, P.J. Error analysis in nearly-completely decomposable stochastic systems. Econometrica 1975, 43, 691–709. [Google Scholar] [CrossRef]
- Pervozvanskii, A.A.; Smirnov, I.N. Stationary-state evaluation for a complex system with slowly varying couplings. Kibernetika 1974, 3, 45–51. [Google Scholar] [CrossRef]
- Gaitsgori, V.G.; Pervozvanskii, A.A. Aggregation of states in a Markov chain with weak interaction. Kibernetika 1975, 4, 91–98. [Google Scholar] [CrossRef]
- Teneketzis, D.; Javid, S.H.; Sridhar, B. Control of weakly-coupled Markov chains. In Proceedings of the IEEE Conference on Decision and Control (CDC), Albuquerque, NM, USA, 10–12 December 1980; pp. 137–142. [Google Scholar] [CrossRef]
- Delebecque, F.; Quadrat, J.P. Optimal control of Markov chains admitting strong and weak interactions. Automatica 1981, 17, 281–296. [Google Scholar] [CrossRef]
- Zhang, Q.; Yin, G.; Boukas, E.K. Controlled Markov chains with weak and strong interactions. J. Optim. Theory Appl. 1997, 94, 169–194. [Google Scholar] [CrossRef]
- Courtois, P.J. Decomposability, Instabilities, and Saturation in Multiprogramming Systems; Academic Press: New York, NY, USA, 1977. [Google Scholar]
- Aldhaheri, R.W.; Khalil, H.K. Aggregation and optimal control of nearly completely decomposable Markov chains. In Proceedings of the IEEE Conference on Decision and Control (CDC), Tampa, FL, USA, 13–15 December 1989; pp. 1277–1282. [Google Scholar] [CrossRef]
- Kotsalis, G.; Dahleh, M. Model reduction of irreducible Markov chains. In Proceedings of the IEEE Conference on Decision and Control (CDC), Maui, HI, USA, 9–12 December 2003; pp. 5727–5728. [Google Scholar] [CrossRef]
- Dey, S. Reduced-complexity filtering for partially observed nearly completely decomposable Markov chains. IEEE Trans. Signal Process. 2000, 48, 3334–3344. [Google Scholar] [CrossRef]
- Vantilborgh, H. Aggregation with an error of O(ϵ2). J. ACM 1985, 32, 162–190. [Google Scholar] [CrossRef]
- Cao, W.L.; Stewart, W.J. Iterative aggregation/disaggregation techniques for nearly uncoupled Markov chains. J. ACM 1985, 32, 702–719. [Google Scholar] [CrossRef]
- Koury, J.R.; McAllister, D.F.; Stewart, W.J. Iterative methods for computing stationary distributions of nearly completely decomposable Markov chains. SIAM J. Algebraic Discrete Methods 1984, 5, 164–186. [Google Scholar] [CrossRef]
- Barker, G.P.; Piemmons, R.J. Convergent iterations for computing stationary distributions of Markov chains. SIAM J. Algebraic Discrete Methods 1986, 7, 390–398. [Google Scholar] [CrossRef]
- Dayar, T.; Stewart, W.J. On the effects of using the Grassman-Taksar-Heyman method in iterative aggregation-disaggregation. SIAM J. Sci. Comput. 1996, 17, 287–303. [Google Scholar] [CrossRef]
- Phillips, R.; Kokotovic, P. A singular perturbation approach to modeling and control of Markov chains. IEEE Trans. Autom. Control 1981, 26, 1087–1094. [Google Scholar] [CrossRef]
- Peponides, G.; Kokotovic, P. Weak connections, time scales, and aggregation of nonlinear systems. IEEE Trans. Autom. Control 1983, 28, 729–735. [Google Scholar] [CrossRef]
- Chow, J.; Kokotovic, P. Time scale modeling of sparse dynamic networks. IEEE Trans. Autom. Control 1985, 30, 714–722. [Google Scholar] [CrossRef]
- Filar, J.A.; Gaitsgory, V.; Haurie, A.B. Control of singularly perturbed hybrid stochastic systems. IEEE Trans. Autom. Control 2001, 46, 179–180. [Google Scholar] [CrossRef]
- Deng, K.; Sun, Y.; Mehta, P.G.; Meyn, S.P. An information-theoretic framework to aggregate a Markov chain. In Proceedings of the American Control Conference (ACC), St. Louis, MO, USA, 10–12 June 2009; pp. 731–736. [Google Scholar] [CrossRef]
- Deng, K.; Huang, D. Model reduction of Markov chains via low-rank approximation. In Proceedings of the American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; pp. 2651–2656. [Google Scholar] [CrossRef]
- Vidyasagar, M. Reduced-order modeling of Markov and hidden Markov processes via aggregation. In Proceedings of the IEEE Conference on Decision and Control (CDC), Atlanta, GA, USA, 15–17 December 2010; pp. 1810–1815. [Google Scholar] [CrossRef]
- Vidyasagar, M. A metric between probability distributions on finite sets of different cardinalities and applications to order reduction. IEEE Trans. Autom. Control 2012, 57, 2464–2477. [Google Scholar] [CrossRef]
- Zangwill, W.I. Nonlinear Programming: A Unified Approach; Prentice-Hall: Upper Saddle River, NJ, USA, 1969. [Google Scholar]
- Treves, A.; Panzeri, S. The upward bias in meausres of information derived from limited data samples. Neural Comput. 1995, 7, 399–407. [Google Scholar] [CrossRef]
- Kato, T. Perturbation Theory for Linear Operators; Springer-Verlag: New York, NY, USA, 1966. [Google Scholar]









© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sledge, I.J.; Príncipe, J.C. Reduction of Markov Chains Using a Value-of-Information-Based Approach. Entropy 2019, 21, 349. https://doi.org/10.3390/e21040349
Sledge IJ, Príncipe JC. Reduction of Markov Chains Using a Value-of-Information-Based Approach. Entropy. 2019; 21(4):349. https://doi.org/10.3390/e21040349
Chicago/Turabian StyleSledge, Isaac J., and José C. Príncipe. 2019. "Reduction of Markov Chains Using a Value-of-Information-Based Approach" Entropy 21, no. 4: 349. https://doi.org/10.3390/e21040349
APA StyleSledge, I. J., & Príncipe, J. C. (2019). Reduction of Markov Chains Using a Value-of-Information-Based Approach. Entropy, 21(4), 349. https://doi.org/10.3390/e21040349