1. Introduction
With the rapid development of computer technologies, business and government organizations create large amounts of data, which need to be processed and analyzed. Over the past decade, to satisfy the urgent need of mining knowledge hidden in the data, numerous machine learning models [
1,
2] (e.g., decision tree [
3], Bayesian network [
4,
5], support vector machine [
6] and Neural network [
7]) have been proposed.
To mine all “right” knowledge that exist in a database, researchers mainly proposed two kinds of learning strategies to address this issue. (1) Increase structure complexity to represent more dependence relationships, e.g., convolutional neural network [
8] and
k-dependence Bayesian classifier (KDB) [
9]. However, as structure complexity grows overfitting will inevitably appear, which will result in redundant dependencies and performance degradation. Sometimes the overly complex structures hide the internal working mechanism and make them criticized for being used as “black box”. (2) Build ensemble of several individual members having relatively simple network structure, e.g., Random forest [
10] and averaged one-dependence estimators (AODE) [
11]. Ensembles can generally perform better than any individual member. However, it is difficult or even impossible to give a clear semantic explanation of the combined result since the working mechanisms of individual members may differ greatly. In practice, people would rather use models with simple and easy-to-explain structures, e.g., decision tree [
12] and Naive Bayes (NB) [
13,
14,
15], although they may perform poorer.
Bayesian networks (BNs) have long been a popular medium for graphically representing the probabilistic dependencies, which exist in a domain. Recently, work in Bayesian methods for classification has grown enormously. Numerous Bayesian network classifiers (BNCs) [
9,
16,
17,
18,
19,
20] have been proposed to mine the significant dependence relationships implicated in training data. With solid theoretic support, they have strong potential to be effective for practical application in a number of massive and complex data-intensive fields such as medicine [
21], astronomy [
22], biology [
23], and so on. A central concern for BNC is to learn conditional dependence relationships encoded in the network structure. Some BNCs, e.g., KDB, use conditional mutual information
to measure the conditional dependence relationships between
and
, which is defined as follows [
24],
For example,
indicates that attributes
and
are conditionally independent. However, in practice, for any specific event or data point, the situation will be much more complex. Taking
Waveform dataset as an example, attributes
and
are conditionally dependent, since
always holds.
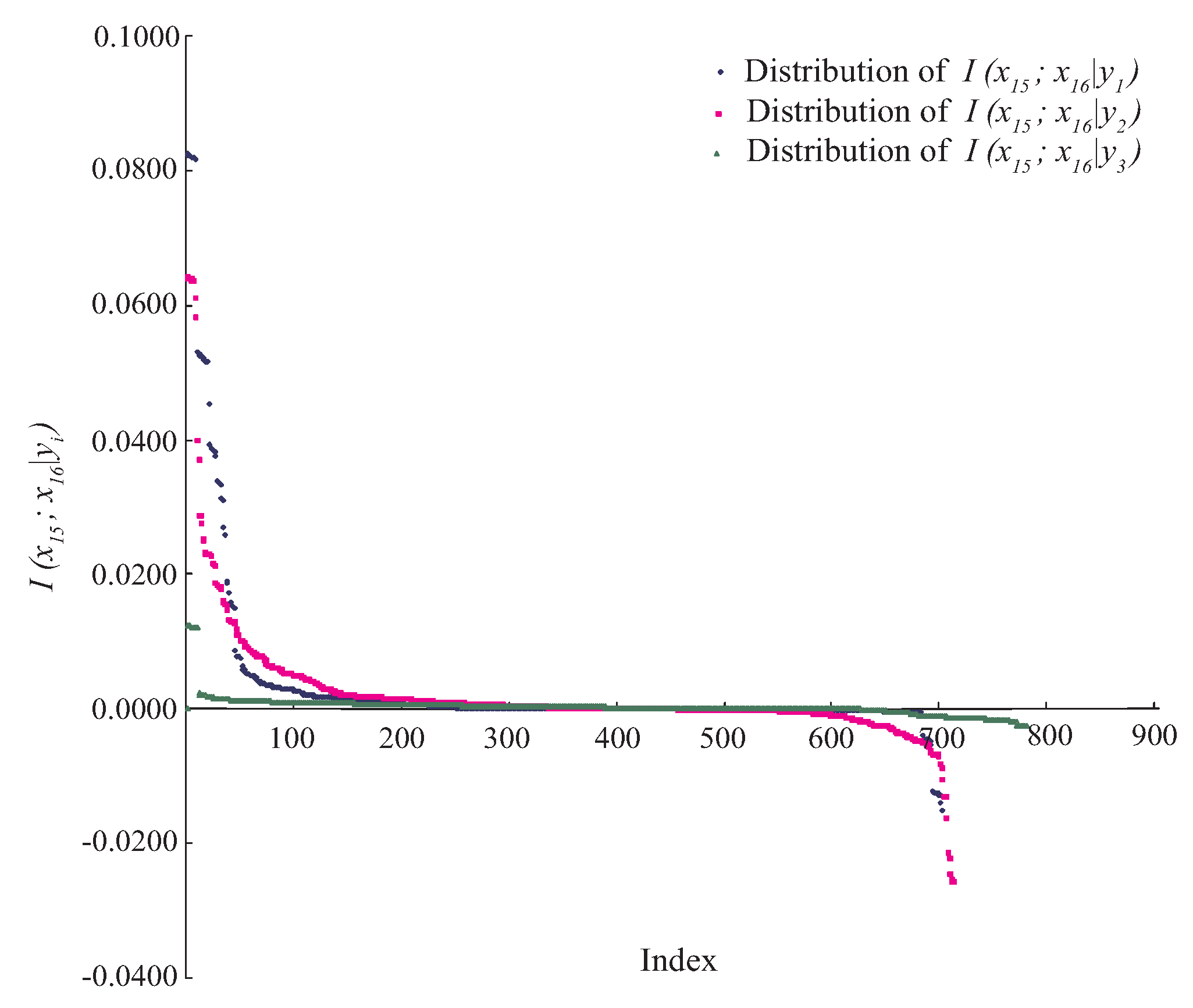
Figure 1 shows the distributions of
, where
. As can be seen, there exist some positive values of
and
. However, for the class label
, the negative or zero values of
have a high proportion among all values. That is, for different class labels, the conditional dependence relationships may be different rather than invariant when attributes take different values. We argue that most BNCs (e.g., NB and KDB), which build only one model to fit training instances, cannot capture this difference and cannot represent the dependence relationships flexibly, especially hidden in unlabeled instances.
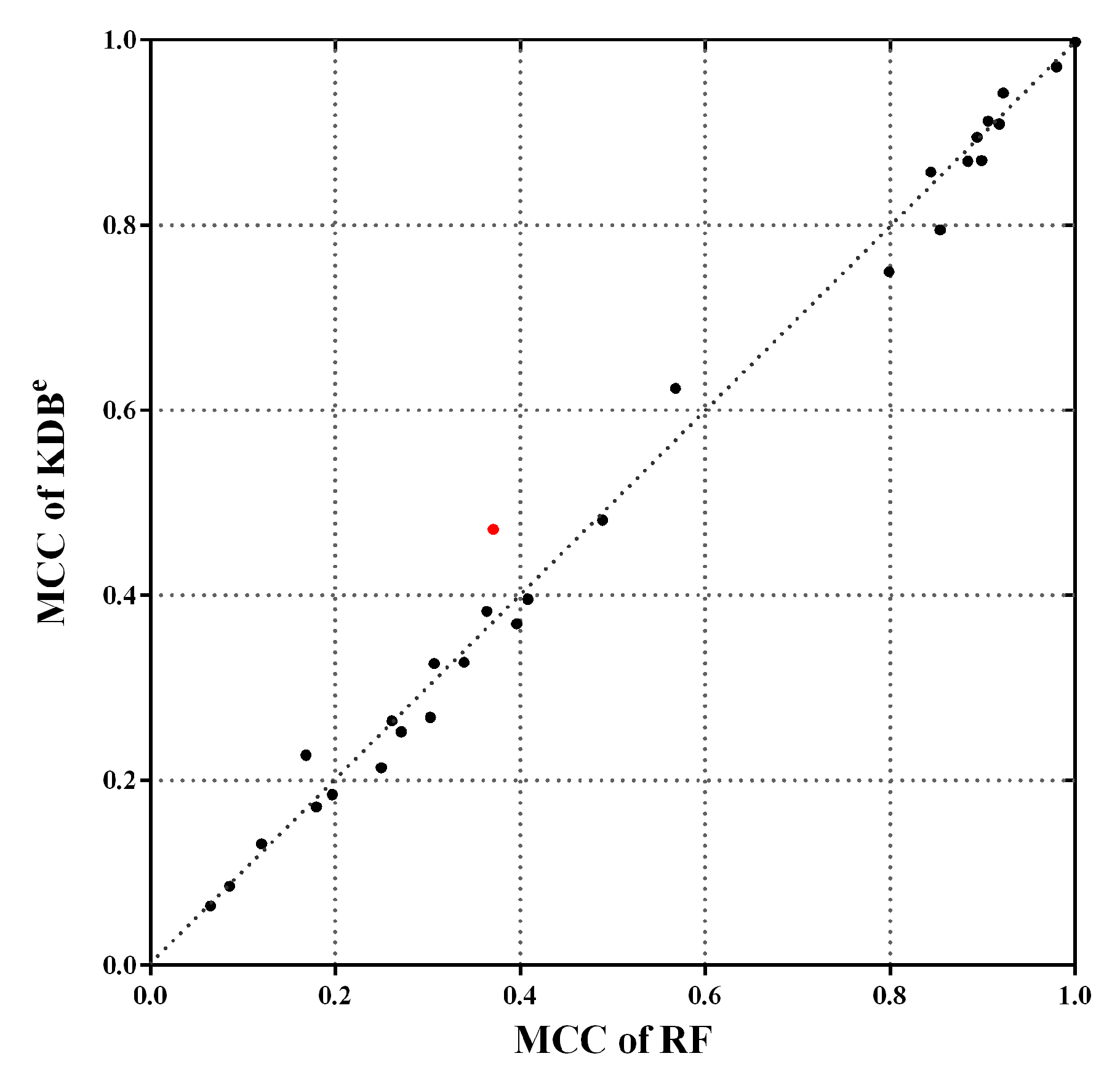
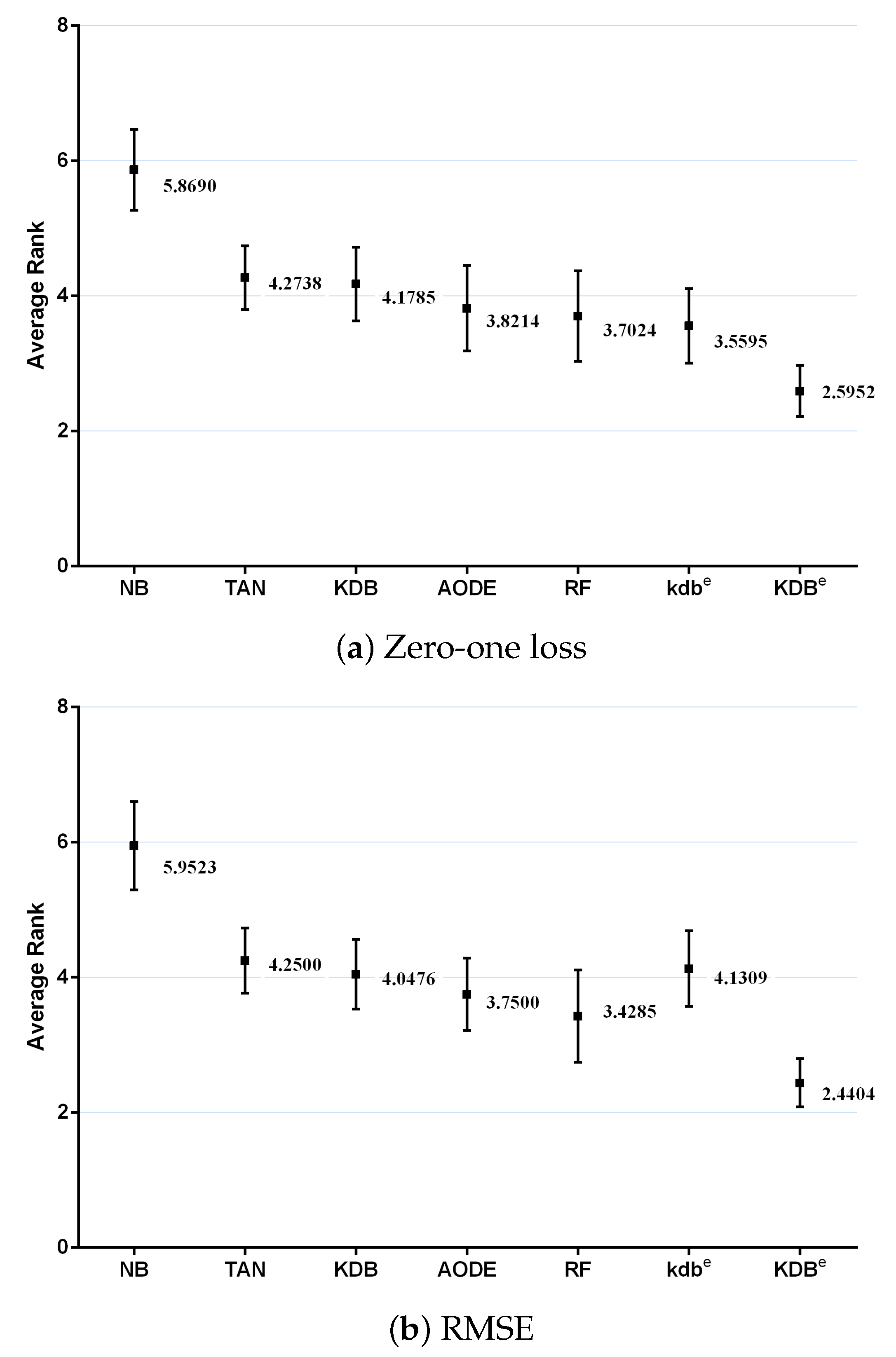
The scientific data can be massive, and labeled training data may account for only a small portion. In this paper, we propose a novel learning framework, called discriminatory target learning, for achieving better classification performance and high-level of dependence relationships while not increasing structure complexity. KDB is taken as an example to illustrate the basic idea and prove the feasibility of discriminatory target learning. By redefining mutual information and conditional mutual information, we build a “precise” model kdbi for each unlabeled instance with respect to class label . The ensemble of kdbi, i.e., kdbe, can finely describe the dependency relationships hidden in . The final ensemble of kdbe and regular KDB can fully and discriminately describe the dependence relationships in training data and unlabeled instance.
The rest of the paper is organized as follows:
Section 2 introduces some state-of-the-art BNCs.
Section 3 introduces the basic idea of discriminatory target learning. Experimental study on 42 UCI machine learning datasets is presented in
Section 4, including a comparison with seven algorithms. The final section draws conclusions and outlines some directions for further research.
2. Bayesian Network Classifiers
The structure of a BN on the random variables
is a directed acyclic graph (DAG), which represents each attribute in a given domain as a node in the graph and dependencies between these attributes as arcs connecting the respective nodes. Thus, independencies are represented by the lack of arcs connecting particular nodes. BNs are powerful tools for knowledge representation and inference under conditions of uncertainty. BNs were considered as classifiers only after the discovery of NB, a very simple kind of BN on the basis of conditional independence assumption. It is surprisingly effective and efficient for inference [
5]. The success of NB has led to the research of Bayesian network classifiers (BNCs), including tree-augmented naive Bayes (TAN) [
16], averaged one-dependence estimators (AODE) [
18] and
k-dependence Bayesian classifier (KDB) [
9,
17].
Let each instance
x be characterized with
n values
for attributes
, and class label
is the value of class variable
Y. NB assumes that the predictive attributes are conditional independent of each other given the class label, that is
Correspondingly for any value pair of arbitrary two attributes
and
,
always holds. From Equation (
1) there will be
and this can explain why there exist no arc between attributes for NB. However, in the real world, it will be much more complex when considering different specific event or data point. We now formalize our notion of the spectrum of point dependency relationship in Bayesian classification.
Definition 1. For unlabeled data point , the conditional dependence between and with respect to label y on point is measured by pointwise y-conditional mutual information, which is defined as follows, Equation (
2) is a modified version of pointwise conditional mutual information that is applicable to labeled data point [
25]. By comparing Equations (
1) and (
2),
is a summation of expected values of
given all possible values of
and
Y. The traditional BNCs, e.g., TAN and KDB, use
to roughly measure the conditional dependence between
and
.
is non-negative,
iff
and
are conditionally dependent given
Y. However, only considering
as the criterion for identifying the conditional independent relationship is too strict for BN learning, which may lead to classification bias, since
may hold for specific data point
. That may be the main reason why NB performs better in some research domains. To address this issue, in this paper
is applied to measure the extent to which
and
are relatively conditionally dependent when
or relatively conditionally independent or irrelevant when
, respectively.
Definition 2. For unlabeled data point with respect to label y, if , then and are y-conditionally dependent on point ; if , then they are y-conditionally independent on point ; and if , then they are y-conditionally irrelevant on point .
TAN maintains the structure of NB and allows each attribute to have at most one parent. Then, the number of arcs encoded in TAN is
. During the constructing procedure of maximum weighted spanning tree, TAN sorts the arcs between arbitrary attributes
and
by comparing
, and adds them in turn to the network structure if no cycle appears. KDB further relaxes NB’s independence assumption and can represent arbitrary degree of dependence while capturing much of the computational efficiency of NB. KDB first sorts attributes by comparing mutual information
, which is defined as follows [
24],
Suppose the attribute order is
. By comparing
,
select its parents, e.g.,
, from attributes that ranks before it in the order. KDB requires that
must have
parents and there will exist
arcs between
and its parents. The number of arcs encoded in KDB is
and will grow as
k grows. Thus, KDB can represent more dependency relationships than TAN. For TAN or KDB, they do not evaluate the extent to which the conditional dependencies are weak enough and should be neglected. They simply specify the maximum number of parents that attribute
can have before structure learning. Some arcs corresponding to weak conditional dependencies will inevitably be added to the network structure. The prior and joint probabilities in Equations (
1) and (
3) will be estimated from training data as follows:
where
N is the number of training instances. Then,
and
in Equations (
1) and (
3) can be computed as follows:
Sahami [
9] suggested that, if
k is large enough to capture all “right” conditional dependencies that exist in a database, then a classifier would be expected to achieve optimal Bayesian accuracy. However, as
k grows, KDB will encode more weak dependency relationships, which correspond to smaller value of
. That increases the risk of occurrence of negative values of
and may introduce redundant dependencies, which will mitigate the positive effect from significant dependencies that correspond to positive values of
. On the other hand, conditional mutual information
cannot finely measure the conditional dependencies hidden in different data points. The arc
in BNC learned from training data corresponds to positive value of
and represents strong conditional dependence between
and
. However, for specific labeled instance
,
may hold. Then,
and
are
-conditionally independent or irrelevant on point
and the arc
should be removed. For unlabeled instance, the possible dependency relationships between nodes may differ greatly with respect to different class labels.
Thus, BNCs with highly complex network structure do not necessarily beat those with simple ones. The conditional dependencies hold for training data in general do not necessarily hold for each instance. BNCs should discriminate between conditionally dependent and irrelevant relationship for different data points. Besides, BNC should represent all possible spectrums of point dependency relationship that correspond to different class labels for dependence analysis.
3. Discriminatory Target Learning
In probabilistic classification, Bayes optimal classification suggests that, if we can determine the conditional probability distribution
with true distribution available, where
y is one of the
m class labels and
is the
n-dimensional data point
that represents an observed instance, then we could achieve the theoretically optimal classification.
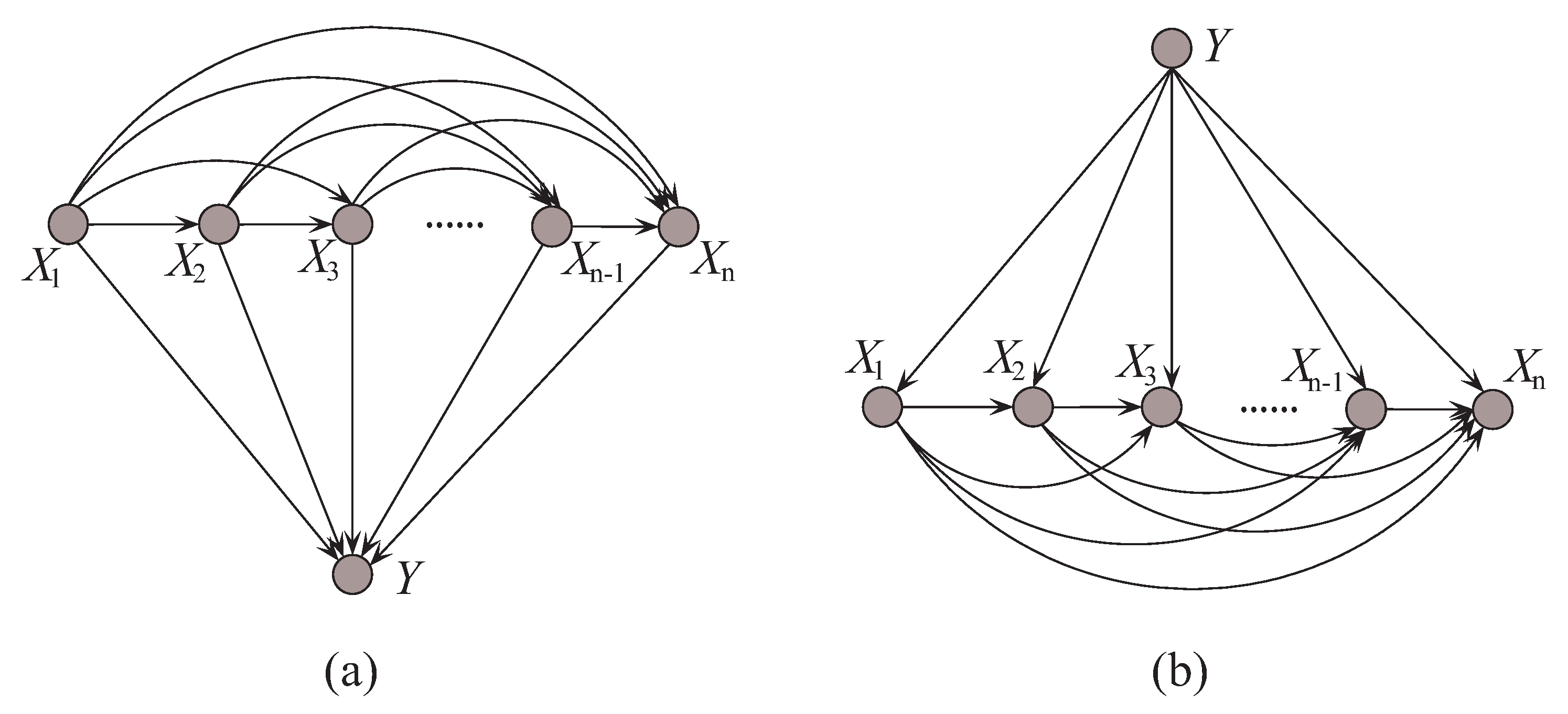
can be described in an unrestricted Bayesian network, as shown in
Figure 2a. By applying arc reversal, Shachter [
26] proposed to produce the equivalent dependence structure, as shown in
Figure 2b. The problem is reduced to estimating the conditional probability
.
Figure 2a,b represents two inference processes that run in the opposite directions.
Figure 2a indicates the causality that runs from the state of
(the cause) to the state of
Y (the effect). In contrast, if the causality runs in the opposite direction as shown in
Figure 2b and the state of
Y (the effect) is uncertain, the dependencies between predictive attributes (the causes) should be tuned to match with different states of
Y. That is, the restricted BNC shown in
Figure 2b presupposes the class label first and then the conditional dependencies between attributes can verify the presupposition.
For different class labels or presuppositions, the conditional dependencies should be different. It is not reasonable that, no matter what the effect (class label) is, the relationships between causes (predictive attributes) remain the same. Consider an unlabeled instance
; if
, then the conditional dependence between
and
on data point
with respect to class label
y is reasonable, otherwise it should be neglected. Since the class label for
is uncertain and there are
m labels available, we take
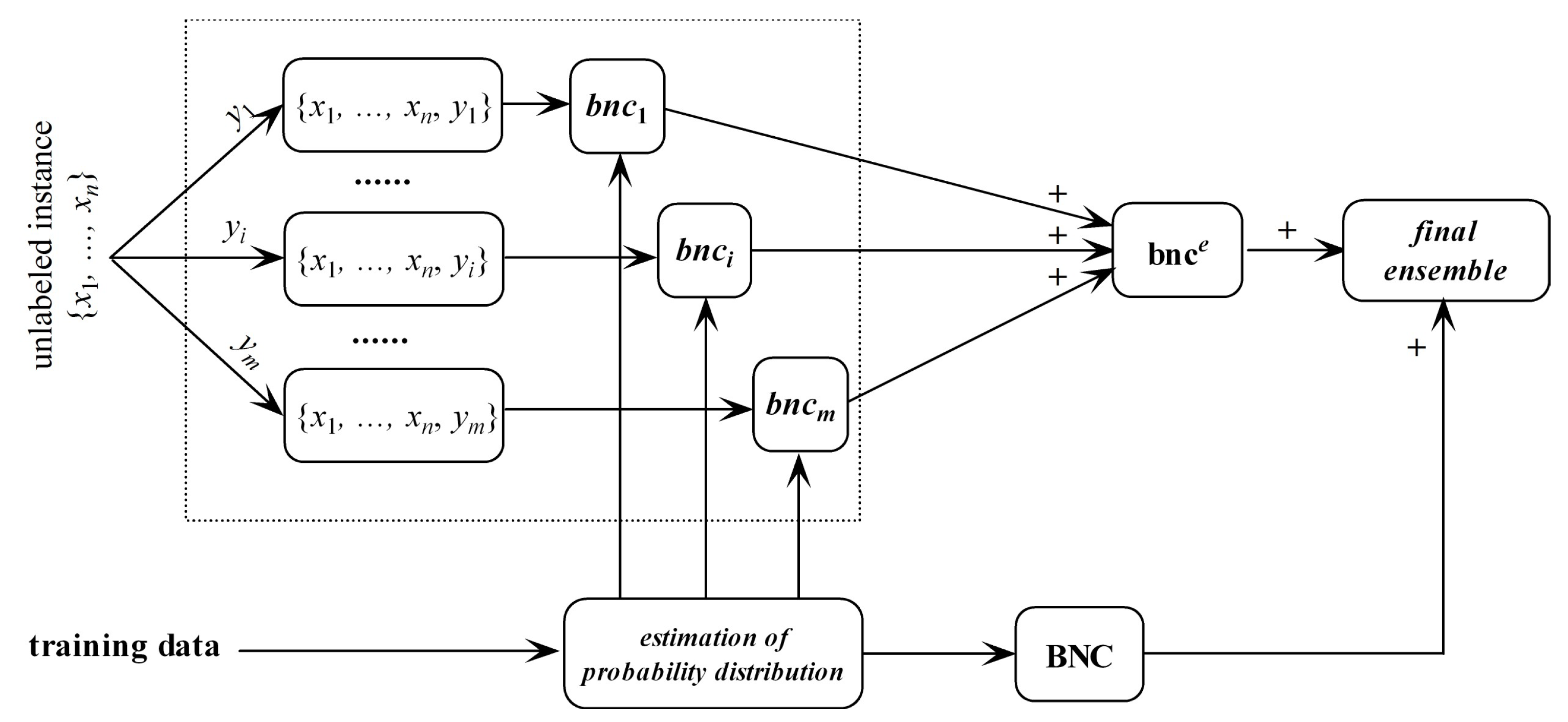
as the target and learn an ensemble of
m micro BNCs, i.e., bnc
e = {bnc
1, ⋯, bnc
m}, each of them fully describes the conditional dependencies between attribute values in
with respect to different class labels. The linear combiner is used for models that output real-valued numbers, thus is applicable for bnc
e. The ensemble probability estimate for bnc
e is,
bnc
e may overfit the unlabeled instance and underfit training data. In contrast, regular BNC learned from training data may underfit the unlabeled instance. Thus, they are complementary in nature. After training bnc
e and regular BNC, the final ensemble that estimates the class membership probabilities by averaging both predictions will be generated. The framework of discriminatory target learning is shown in
Figure 3.
Because in practice it is hardly possible to find the true distribution of from data, KDB approximates the estimation of by allowing for the modeling of arbitrarily complex dependencies between attributes. The pseudocode of KDB is shown in Algorithm 1.
| Algorithm 1 Structure learning of KDB. |
![Entropy 21 00537 i001]() |
From the definition of
in Equation (
3), we can have
Definition 3. For unlabeled data point , the dependence between and any given label y is measured by pointwise y-mutual information, which is defined as follows, Equation (
8) is a modified version of pointwise mutual information that is applicable to labeled data point [
25]. The prior and joint probabilities in Equations (
2) and (
8) will be estimated as follows
Conditional probabilities in Equations (
2) and (
8) can be estimated by:
Similar to the Laplace correction [
27], the main idea behind Equation (
9) is equivalent to creating a “pseudo” training set
by adding to the training data a new instance
with multi-label by assuming that the probability that this new instance is in class
y is
for each
Definition 4. For unlabeled data point with respect to label y, if , then is y-dependent on point ; if , then is y-independent on point ; and if , then is y-irrelevant on point .
KDB uses
to sort the attributes and
to measure the conditional dependence. Similarly, for unlabeled instance
, the corresponding micro KDB with respect to class label
, called kdb
t, uses
(see Equation (
8)) to sort the attribute values and
(see Equation (
2)) to measure the conditional dependence. The learning procedure of kdb
t is shown in Algorithm 2.
| Algorithm 2 Structure learning of kdbt with respect to class label . |
![Entropy 21 00537 i002]() |
Breiman [
28] revealed that ensemble learning brings improvement in accuracy only to those “unstable” learning algorithms, in the sense that small variations in the training set would lead them to produce very different models. bnc
e is obviously an example of such learners. For individual members of kdb
e, the difference in network structure is the result of change of
or
, or, more precisely, the conditional probability defined in Equations (
2) and (
8). Given unlabeled instance
and binary class labels
and
, if
, i.e.,
, then
is
-dependent on
. Because
and
we have
and
Thus,
is
-irrelevant on
.
plays totally different roles in the relationships with different class labels on the same instance. Supposing that before small variations in the training set
and after that
, the attribute values will be resorted and correspondingly the network structures of kdb
1 and kdb
2 for
will change greatly. The sensitivity to the variation makes kdb
e finely describe the dependencies hidden in
.
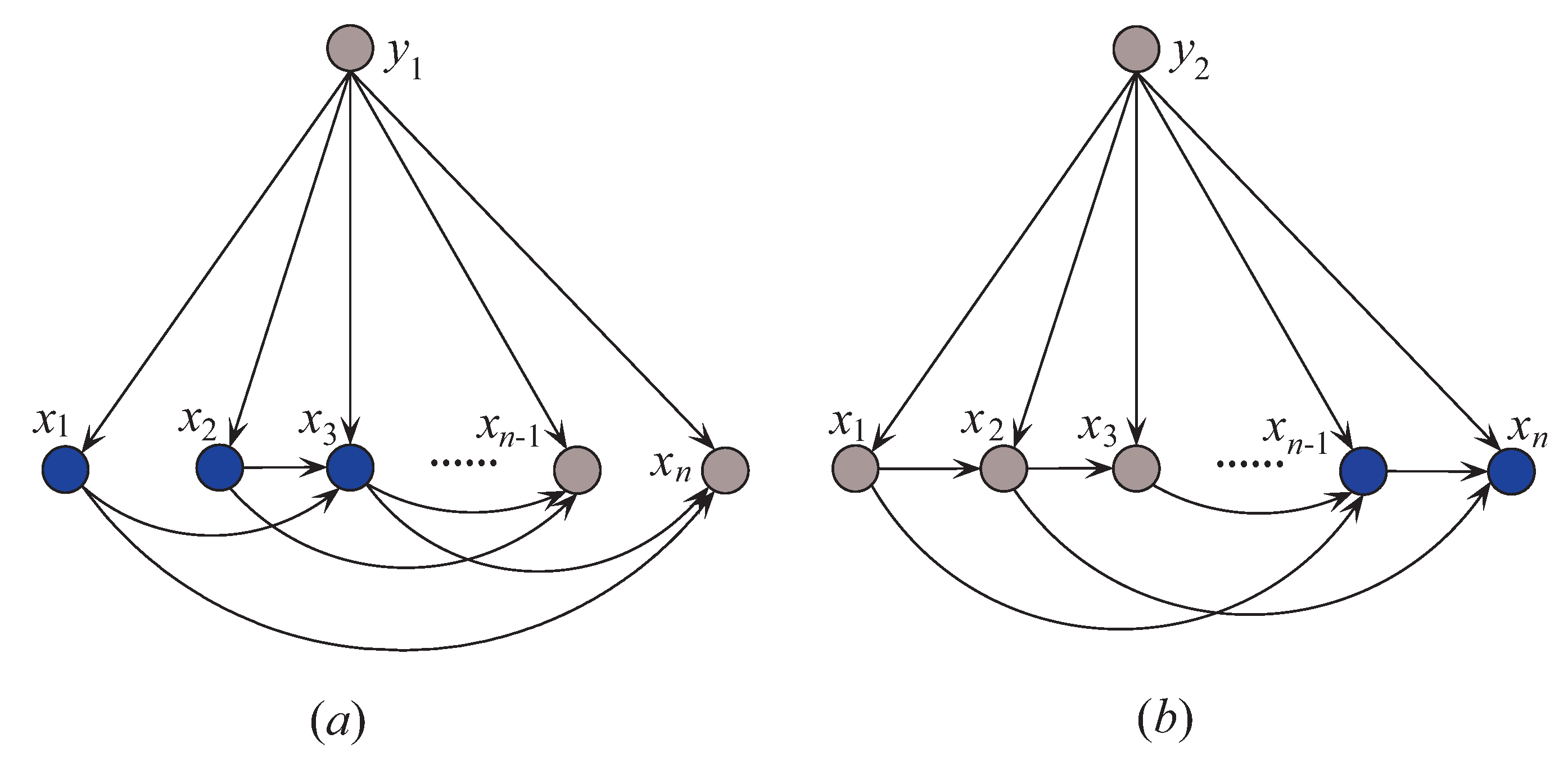
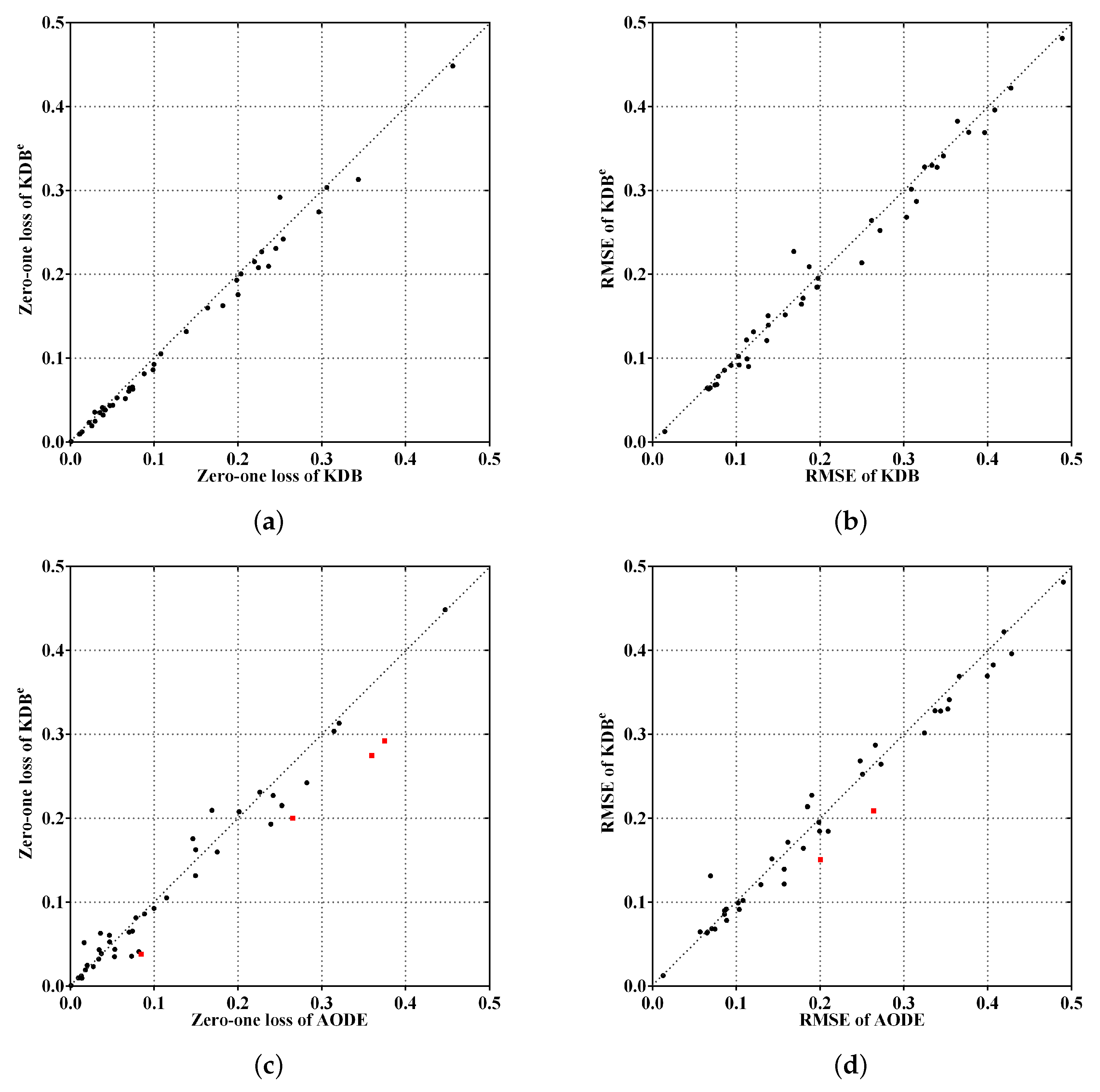
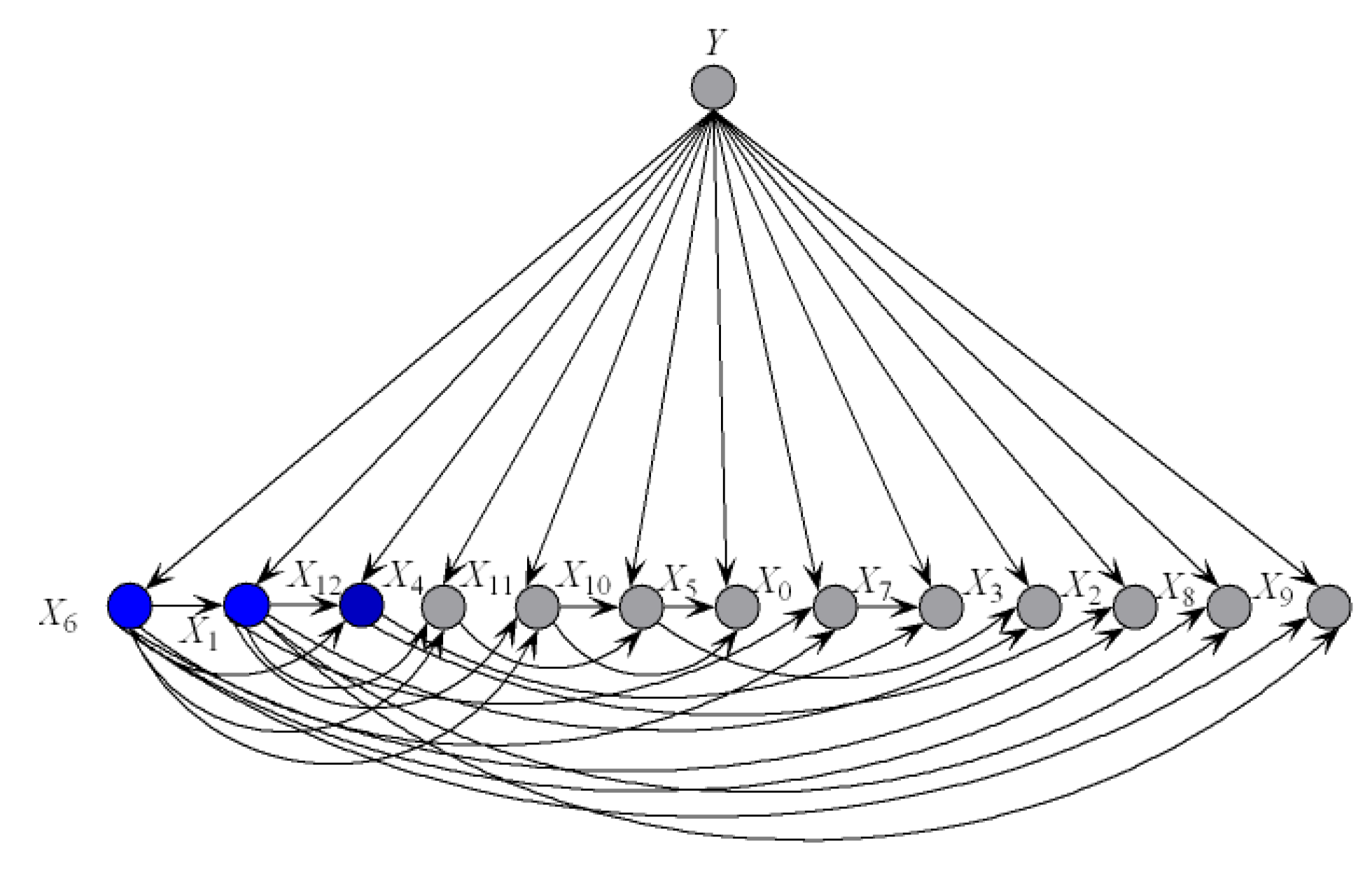
Figure 4 shows examples of kdb
1 and kdb
2 corresponding to class labels
and
, respectively. If the decision of the final ensemble is
, then we will use
Figure 4a for dependence analysis. Otherwise, we will use
Figure 4b instead. The attribute values annotated in black correspond to positive values of
or 2) and they should be focused on.
KDB requires training time complexity of
(dominated by the calculations of
) and classification time complexity of
[
9] for classifying a single unlabeled instance, where
n is the number of attributes,
N is the number of data instances,
m is the number of class labels, and
v is the maximum number of discrete values that an attribute may take. Discriminatory target learning requires no additional training time, thus the training time complexity of final ensemble is the same as that of regular KDB. At classification time it requires
to calculate
, and the same time complexity for classifying a single unlabeled instance.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











