1. Introduction
Making predictions on the dynamics of time series of a system is a very interesting topic. Up to now, over thousands of methods have been proposed for the prediction of the systems’ evolution [
1]. A fundamental prerequisite of these works is to evaluate the predictability of the system over a wide range of time. For an isolated system, which does not exchange information with other systems, the predictability of the output time series is only determined by the degree of memory from the past values. In such a case, the time series in unpredictable if it is purely random, like Gaussian white noise; whereas, information can be extracted for prediction by analyzing the temporal structure of a time series with memory. In another way, examples of irreversible processes include typically chaotic dissipative processes, nonlinear stochastic processes, and processes with memory, operating away from thermodynamic equilibrium. One should be able to make easier predictions on irreversible processes, where the arrow of time is playing a role, than on reversible ones [
2,
3]. For a real-world system that may exchange information with other systems, the past values of other systems can also be utilized for prediction, except the past values of the underlying system itself [
4,
5].
In time series analysis, the multiscale analysis of time series has been broadly studied, which relies on the fact that the time series of complex systems, associated with a hierarchy of interacting regulatory mechanisms, usually generate complex fluctuations over multiple time scales. Analyzing the financial time series by amplification in different proportions with a coarse-graining algorithm [
6] makes it possible to reveal both small-scale information and large-scale information at multiple resolutions. This paper contributes to evaluating the multiscale predictability of financial time series. Another piece of evidence of this consideration is that the multiscale complexity (a tool of time series analysis that is associated with factors of the degree of memory, the temporal structure, and auto-correlations) have been measured [
6,
7], and hence, the predictability of time series, which is also closely related to those factors, can be analyzed on multiple time scales as well.
Financial time series analyses have played an important role in developing some of the fundamental economic theories. Furthermore, the understanding and analysis of financial time series, especially the evolution of stock markets, has been attracting the close attention of economists, statisticians, and mathematicians for many decades [
8,
9,
10,
11,
12,
13,
14]. Recent research mostly focuses on the long-term average behavior of a market, and thus sheds little light on the temporal changes of a market. This type of method for analyzing financial time series may lead to a lack of analysis on the short-term predictability of time series, thus ignoring the critical information that is contained in the financial data, which may be used for the portfolio selection and pursuing an arbitrage opportunity [
15].
If the efficient market hypothesis (EMH) is of some relevance to reality, then a market would be very unpredictable due to the possibility for investors to digest any new information instantly [
16]. When a market behaves as the EMH stipulates, the market will be purely random without memory, and the variation of price will be very unpredictable. For an extensive review of the EMH, please see [
17]. However, new evidence challenges the EMH with many empirical facts from observations, e.g., the leptokurtosis and fat tail of the non-Gaussian distribution, especially the fractal market hypothesis (FMH) [
18]. The FMH asserts that (i) a market consists of many investors with different investment horizons, and (ii) the information set that is important to each investment horizon is different. As long as the market maintains this fractal structure, with no characteristic time scale, the market remains stable. When the market’s investment horizon becomes uniform, the market becomes unstable because everyone is trading based on the same information set. In addition, Beben and Orlowski [
19] and Di Matteo et al. [
20,
21] found that emerging markets were likely to have a stronger degree of memory than developed markets, suggesting that the emerging markets had a larger possibility of being predicted.
In this paper, we incorporate the multiscale analysis with an information-theoretic approach for characterizing the degree of memory of time series, so as to evaluate the predication of financial time series. We make use of the entropy rate in order to test the predictability of some synthetic data and of the Chinese stock markets. It is an interesting alternative to regression models, which are often used in financial time series. One advantage is that the method proposed is mainly model independent; another is that it deals with nonlinear systems, as well as with linear ones. The remainder of the paper is organized as follows. In the Methodology Section, we introduce a new entropy difference (ED) and its multiscale case, multiscale entropy difference (MED). We then apply these new methods to the numerical analysis of artificial simulations, including the logistic map, the Hénon map, the Lorenz system, and most importantly, the financial time series analysis. Finally, we give a brief conclusion.
2. Methodology
2.1. Entropy Difference
(i) For an isolated system, which does not exchange information with other systems, the degree of predictability of the time series can only be explained by the memory effects of its past values.
As the output of the underlying system, a time series
,
is considered. First, the uncertainty of the time series at time
t can be quantified by the Shannon entropy:
represents the probability distribution of
;
is the space of samples; and
describes the information of
x at time
t in bits.
The entropy rate measures the net information generated by the system at time
t, given by
. We assume that the underlying system can be approximated by a
p-order Markov process. That is to say, the value of the output time series at time
t is only related to its nearest
p neighbors and is independent of further values. Therefore, we obtain
, where:
The uncertainty of the time series at time
t is non-increasing given the past values, and hence, the entropy rate is no larger than the entropy itself:
.
The difference between the Shannon entropy and the entropy rate represents the contributions of the past values to reducing the uncertainty (and improving the predictability) of the time series at time
t. It is given by:
We name
D the entropy difference (
). For any (nonlinear) time series,
. For a random walk process, the contribution of past values is negligible; hence,
, and
.
D equal to zero indicates that the time series cannot be predicted at all, as no past information can be utilized; whereas, if there exist autocorrelations/memory effects within the time series, the past values can be used to reduce the uncertainty of time series at time
t, so
.
The entropy difference
D is non-negative, while the upper bound of
D is uncertain. Thus, we further normalize
D to the range of
, divided by its maximum value
:
Here,
. The normalized
,
, quantifies the degree of predictability of the time series. Similarly, when
is approximately 0, the time series is unpredictable. When
attains a value of one,
is approximately 0. Therefore, there exists no uncertainty of
in the presence of the past values
, and the time series is completely specified (well predicted) at time
t.
(ii) Next, consider a real-world system that exchanges information with other systems. Except the past values of the underlying system itself, the past values of other systems can also be exploited. Revisit the Granger causality, which is a statistical concept of causality that is based on prediction [
22,
23]. If a signal
y “Granger-causes” a signal
x, then past values of
y should contain information that helps predict
y above and beyond the information contained in past values of
x alone. In the Granger causality, the value of
is predicted by two equations, respectively,
The Granger causality is normally tested in the context of linear regression models. If the second forecast is found to be more successful, according to standard cost functions, then the past of
y appears to contain information helping in forecasting
that is not in past
. The Akaike information criterion (AIC) or Bayesian information criterion (BIC) can be adopted to determine the lagged ranks
p and
q. The residual terms
and
, as a matter of fact, contain the information generated by the system at time
t. A nonlinear extension of the Granger causality is the information-theoretic tool of transfer entropy [
24,
25], which measures the information flow from
y to
x:
Both the Granger causality and the transfer entropy indicate that the past values of another related system can be used to infer the trajectory of the underlying system. Hence, the
of the isolated system can be extended to the multiple systems case.
The entropy rate of one system in the presence of another coupled system is given by
. We further assume that these two systems can be approximated by the generalized Markov processes [
24], that is
, and:
The uncertainty of system x can be given by the conditional probability distribution . The conditional probability distribution describes the data range and the occurrence probability of by knowing the past values of . Consider an extreme case. If , where c is a constant, then is fixed at point c with no uncertainty. Further, when the conditional distribution is fixed within a narrow range, the system is more deterministic at time t by knowing , which can thus be well predicted. If the conditional distribution is still wide in the range, the system is full of uncertainty at time t and has a low possibility of being predicted.
The reduced uncertainty by knowing the past values of both
x and
y is estimated by the
:
Further, the
is normalized by:
ranges between 0 and 1.
being approximately 0 indicates a low degree of predictability of the time series, and
close to 1 indicates a large degree of predictability. In addition, to set the
in a fixed range, the normalization of
also has other merits. Below is the explanation.
The predictability of a system is mainly subjected to the contributions of two aspects:
- (i)
The degree of the memory of the underlying system, that the past information can be well utilized to infer the future evolution of the system;
- (ii)
Whether a system is more deterministic than other systems. This is related to the range of the fluctuations of the time series, which can be partly explained by the variance of the time series. A time series with large variance (entropy) tends to be more difficult to predict than a time series with much small variance. Both the variance and the entropy reflect the diversity of the system. A system with more diverse states is likely to have large variance and entropy, whereas a system with few states tends to have small ones. Obviously, a system with fewer states is easier to predict than that with diverse states.
Therefore, the normalization of by dividing D by makes it possible to compare the degree of predictability between different systems, even if they have different ranges of fluctuations. Moreover, regarding the estimation of entropy values from time series, there may exist biases for different estimators. The normalization can offset those biases caused by the estimation of entropy if the numerator and the denominator use the same estimator.
Further, for a more complicated case of multiple subsystems (larger than 2 subsystems), e.g., the Lorenz system, the predictability of the time series can be given by:
when the past values of
x,
y, and
z can be used to predict
. Here,
could be a vector of possible explanatory variables.
2.2. Multiscale Entropy Difference
The predictability of time series estimated by
and the normalized version is given on a unique time scale, on which the data are sampled. Here, we further evaluate that the multiscale predictability of time series relies on the fact that the time series of complex systems, associated with a hierarchy of interacting regulatory mechanisms, usually generate complex fluctuations over multiple time scales. There exist many approaches for the multiscale analysis in the framework of fractal theory [
26], e.g., the data segments of detrended fluctuation analysis (DFA) [
27], coarse-graining [
6], and the time delay of phase space reconstruction [
28,
29], where the coarse-graining is one of the simplest methods.
We coarse grained the original data onto multiple time scales with a scale parameter
s [
2,
6,
7]. By the non-overlapping coarse-graining, the original time series
x (with length
T) is rescaled to
:
t ranges from 1 to
.
represents the moving average of the system
x at time
t on the temporal scale
s. The coarse-graining process is a low-pass filter, where the high-frequency fluctuations are filtered out. At small time scales, the details of the time series can be reserved, while at large scales, the details are ignored and only the profile of the time series is retained.
The procedure of the multiscale entropy difference () mainly includes 3 steps:
Step 1. Coarse grain the original time series () to the coarse-grained time series (), with a time scale s.
Step 2. Estimate the and the normalized for the coarse-grained time series (), respectively.
Step 3. Change the time scale s and observe the changes of , and the normalized , on different time scales.
When the scale
s is equal to 1, the MED method retrieves back the ED method. For other scales, the MED can evaluate the multiscale predictability of the time series. To be noted, for a short time series of length
T, the multiscale analysis may be affected by the finite size effects at large time scales, which can be solved by the refined entropy estimators during the coarse-graining process. For more details, please see [
5,
30,
31].
3. Numerical Simulations
In this section, we consider three examples to test our new methods, including one isolated system and two open systems.
We first consider the logistic map. It is a polynomial mapping of degree two, which consists of only one nonlinear system: . For , can be used to represent the ratio of existing population to the maximum possible population in ecology. The values of interest for the parameter are those in the interval [0, 4]. Complex, chaotic behavior can arise from this very simple non-linear dynamical equation. Most values of beyond 3.56995 exhibit chaotic behavior. Here, we set and let the data length . The initial value of was set to 0.5.
As only one equation is described in the logistic map, changes no information with other variables. We added Gaussian white noises on the original time series with different strengths to obtain a composite time series: . is the Gaussian white noise (with zero mean and unit variance). is a parameter that tunes the strength of noises. is the real signal corrupted by the external noise , and determines the signal-noise ratio. The larger , the smaller the signal-noise ratio is.
We used
k-means clustering [
32] to discretize the original data into
k symbols, so as to estimate the entropies.
k is a pre-defined parameter that determines the number of clusterings. Here, the parameter
k for the
k-means clustering was 10, i.e., we symbolized the original continuous time series as 10 discrete symbols. In
Figure 1, we show the values of normalized
on multiple time scales
, with the noise strength parameter
from 0.01 to 0.1 with a step of 0.01, since the variance of the original time series
x of the logistic map (
was only 0.0412, the original data length was
, therefore, even at
, this ensured that the coarse-grained data length was
. For
and
, corresponding to the original time series
x, the degree of predictability was larger than 0.7. This indicates that the logistic map had a large possibility of being predicted, which coincides well with what the equation describes. When the scale increased, the predictability of the coarse-grained time series decreased, since the relationship between
and
became weaker on large scales. Moreover, the predictability of the time series also decreased with increasing
, as the signal-noise ratio became lower.
reached a value very close to zero when
, so the composite time series could not be predicted. We also tested other values of
k, for which it turned out that the values of larger
k gave more reliable results; however, this was limited by the original data length. We further generated several groups of Gaussian white noises to add on the original time series and obtained very similar results, which verified the robustness of our new methods.
Next, we considered the Hénon map, which consists of two subsystems: and . The map depends on two parameters, a and b. For the classical Hénon map, it has values of and . There exists nonlinear information flow from and to , i.e., a one-step transition from the past data of one variable y to the current the data of another variable x. The initial values were set to .
We generated data with the classical Hénon map, with the data length
. In
Figure 2, we show the values of normalized
on multiple time scales
. For
, which corresponds to the original time series
x and
y, the degree of predictability was 0.77. This indicates that
can be well predicted by using the past values of
x and
y. When the scale increased, the predictability of the coarse-grained time series decreased, as the relationship among
,
, and
became weaker on large scales. We also compare
with
in
Figure 2. Here, the lagged ranks
p and
q were both set to one. Obviously, if we only used the past values of
x to predict
, the predictability of the time series would be much lower than if we incorporated both the past values of
x and
y. Therefore, we always obtained
. Actually,
is just the normalized multiscale transfer entropy [
5], and its unique scale case
is the normalized transfer entropy [
24,
33], from
y to
x.
Third, we studied the Lorenz system [
34], which consists of three subsystems:
,
, and
. Here,
x,
y, and
z make up the system states,
t time, and
,
r, and
b the parameters:
,
,
. We integrated these equations numerically, applying a fourth-order Runge–Kutta method with the initial values of
.
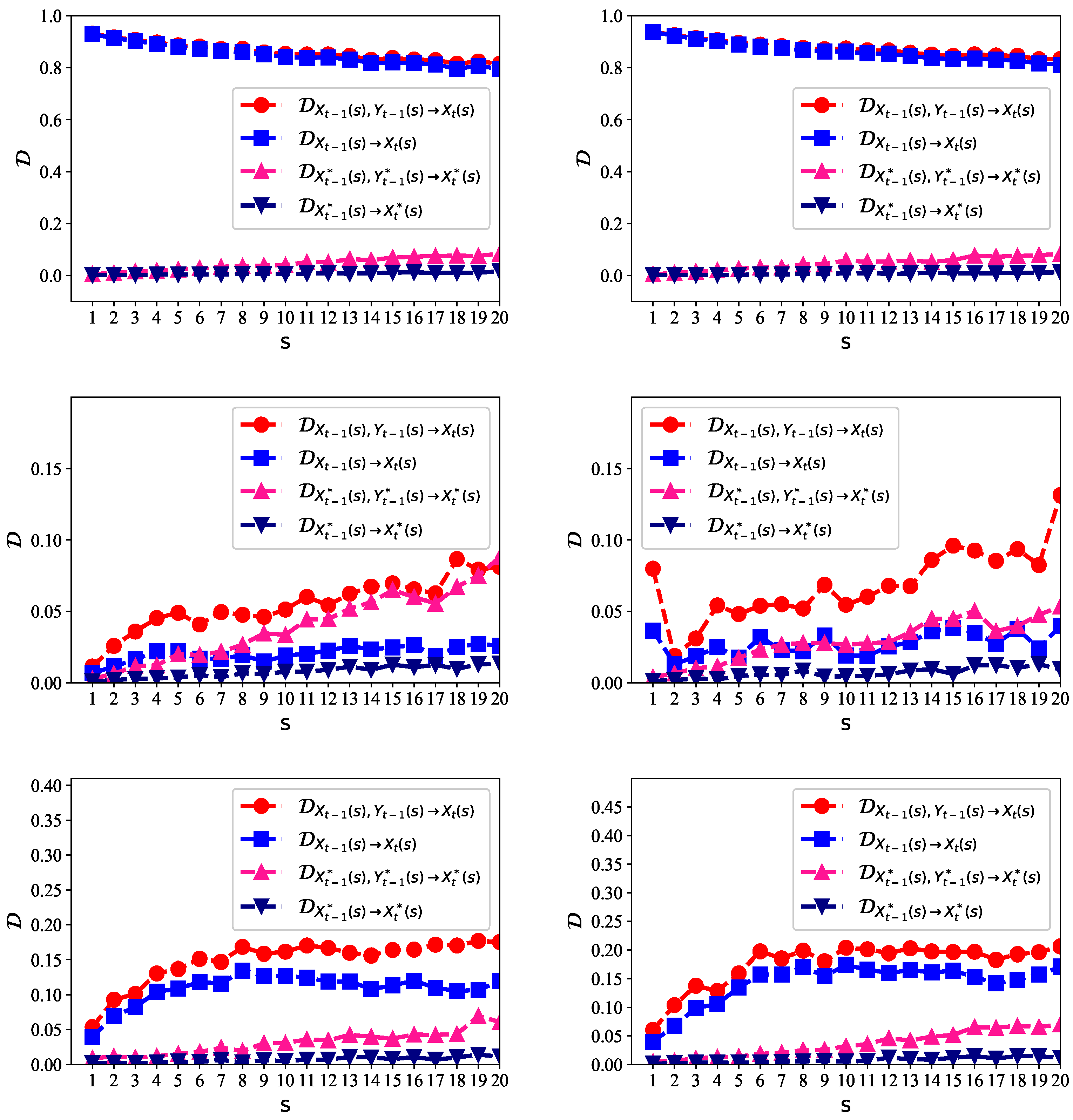
We used the Lorenz system to generate data of length
. In
Figure 3, we give the values of normalized
on multiple time scales
. For
, which corresponds to the original time series
x,
y, and
z, the degree of predictability of
reached 0.88. This indicates that
can be well predicted by using the past values of
x,
y, and
z. When the scale increased, the predictability of the coarse-grained time series decreased, as the relationship among
,
,
and
became weaker on large scales. We also compared
with
,
, and
. Here, the lagged ranks
p,
q, and
l were all set to one. We found that
can be well predicted giving the past values of
x and
y. Interestingly, the past values of
z contributed much less to predicting
y, although in the second equation of the Lorenz system, the change of
y (
) is also explained by
z. This can be explained as follows. In the
x–
y phase plane,
x is closely related to
y in the “diagonal” direction, as shown in
Figure 3. However, in the
y–
z phase plane, no obvious relationship appears between
y and
z. Therefore, both the past values of
x and
y contribute to predicting
y, rather than
z. To predict other variables like
x and
z, we obtained very similar results.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




