Information Geometrical Characterization of Quantum Statistical Models in Quantum Estimation Theory


{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Preliminaries
2.1. Tangent Space and Quantum Fisher Metric
2.2. Commutation Operator
2.3. Basic Lemmas
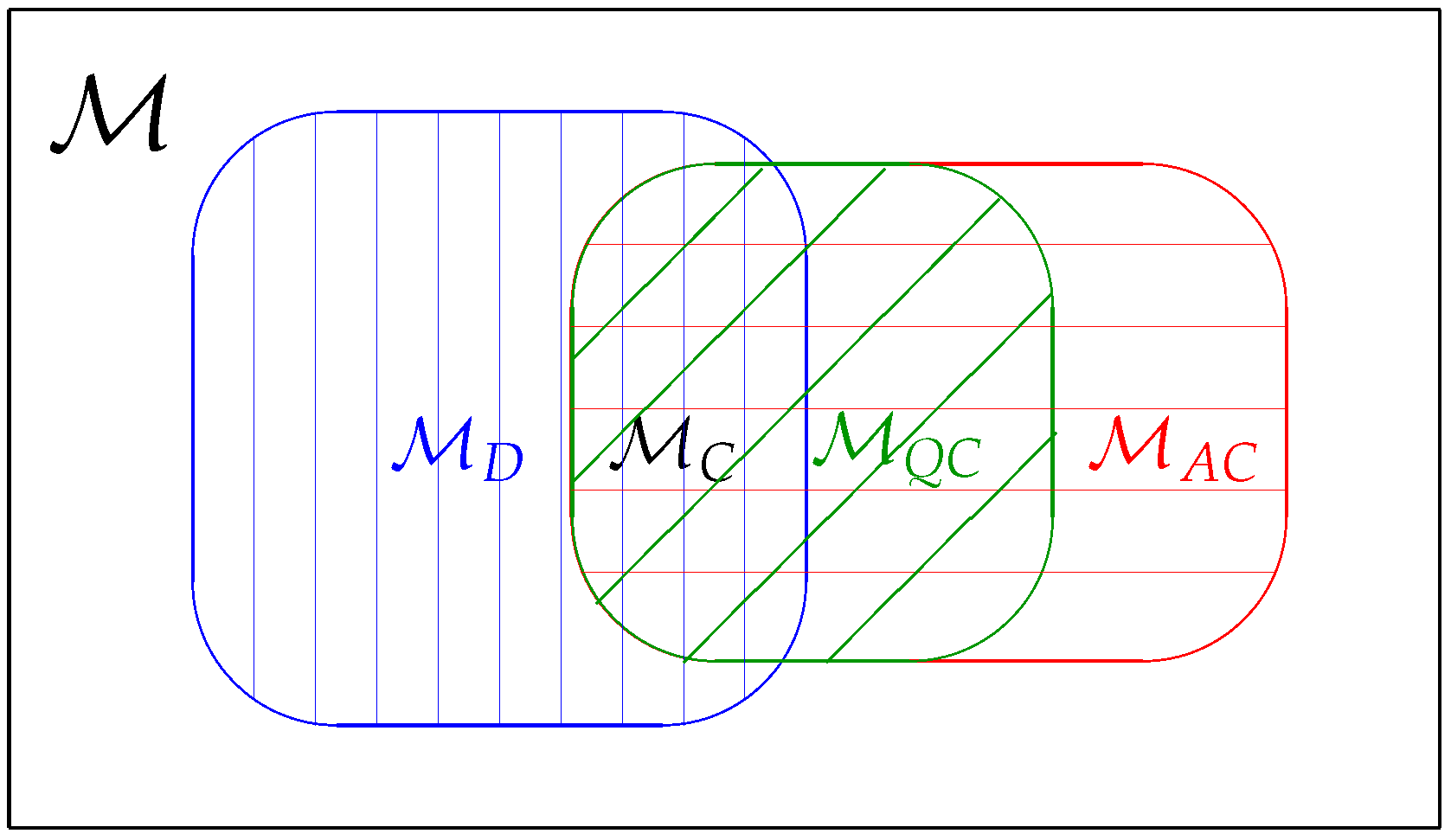
3. Model Class in Quantum Statistical Models
3.1. Asymptotic Bound: Holevo Bound
3.2. Classical Model
3.3. Quasi-Classical Model
3.4. D-Invariant Model
3.5. Asymptotically Classical Model
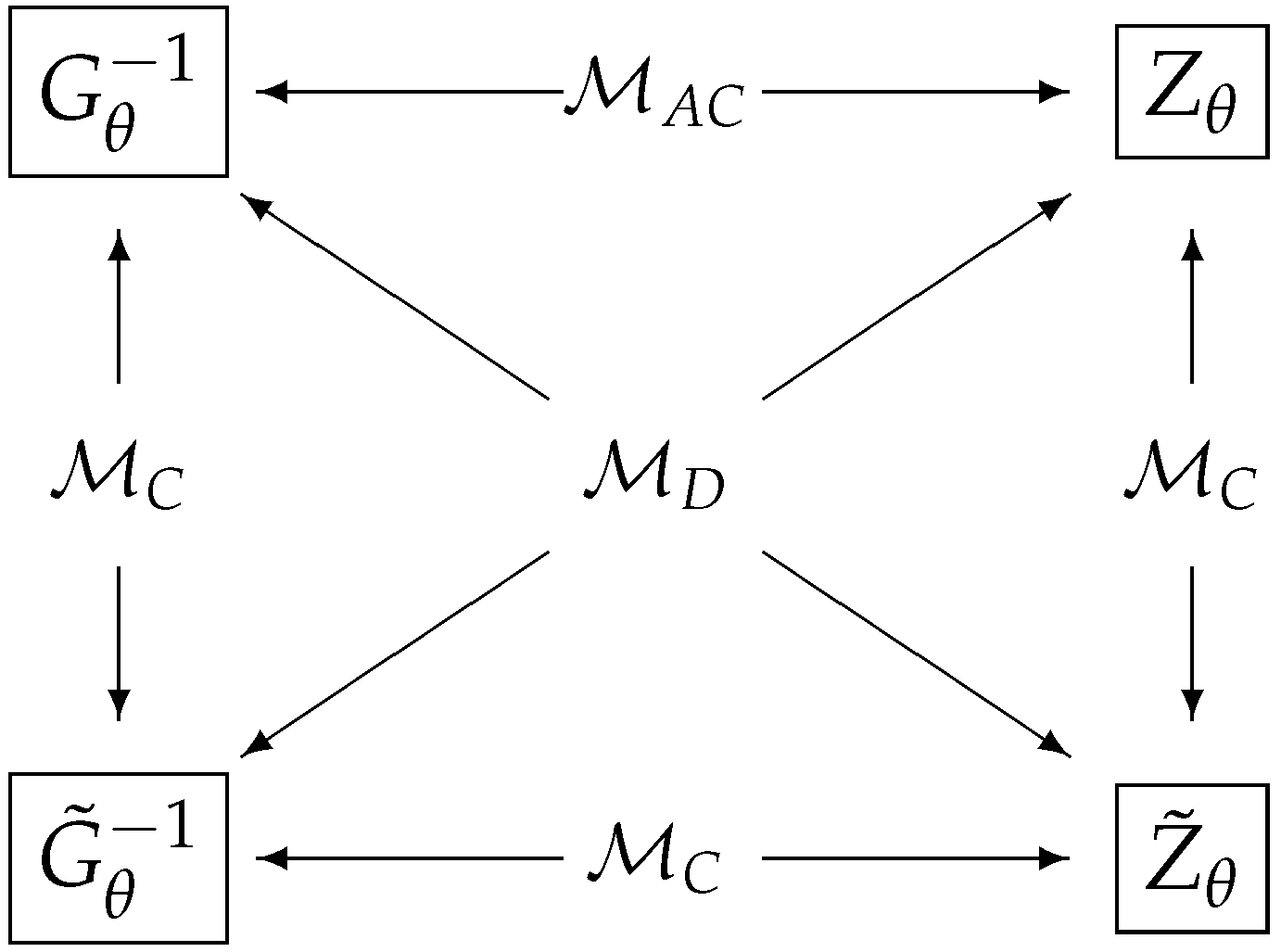
4. Model Classification and Characterization
4.1. Results
4.1.1. Classical Model
- 1.
- The model is classical (Definition 2).
- 2.
- , .
- 3.
- , .
- 4.
- .
- 5.
- , .
- 6.
- .
- 7.
- .
- 8.
- The model is D-invariant and asymptotically classical.
4.1.2. D-Invariant Model
- 1.
- is D-invariant at θ (Definition 3).
- 2.
- , .
- 3.
- , .
- 4.
- 5.
- , .
- 6.
- , with respect to ⇒ with respect to .
- 7.
- is an invariant subspace of the commutation operator .
4.1.3. Asymptotically Classical Model
- 1.
- is asymptotically classical (Definition 4).
- 2.
- , .
- 3.
- .
- 4.
- .
- 5.
- , .
4.1.4. Matrices
- 1.
- is classical. ⇔ ⇔ ⇔
- 2.
- is D-invariant. ⇔ ⇔
- 3.
- is asymptotically classical. ⇔
4.2. Discussion on the Results
4.2.1. Tangent Vector
4.2.2. Quantum Fisher Metric
4.2.3. Tangent Space
4.2.4. Asymptotic Bound
4.3. Proofs
4.3.1. Proof for Proposition 1
4.3.2. Proof for Proposition 2
4.3.3. Proof for Proposition 3
4.3.4. Proof for Theorem 2
5. Examples
5.1. Qubit Models
- is D-invariant. ⇔ is independent of .
- is asymptotically classical. ⇔ () is orthogonal to .
5.2. Non-Classical Quasi-Classical Model
6. Concluding Remarks
Funding
Acknowledgments
Conflicts of Interest
References
- Amari, S.-I. Differential-Geometrical Methods in Statistics; Springer: Berlin/Heidelberg, Germany, 1985; Volume 28. [Google Scholar]
- Amari, S.; Nagaoka, H. Methods of Information Geometry (Translations of Mathematical Monographs); American Mathematical Society: Providence, RI, USA, 2000; Volume 191. [Google Scholar]
- Ay, N.; Jost, J.; Le, H.V.; Schwachhöfer, L. Information Geometry; Springer Nature: Gewerbestrasse, Switzerland, 2017. [Google Scholar]
- Felice, D.; Cafaro, C.; Mancini, S. Information geometric methods for complexity. CHAOS 2018, 28, 032101. [Google Scholar] [CrossRef] [PubMed]
- Helstrom, C.W. Quantum Detection and Estimation Theory; Academic Press: New York, NY, USA, 1976. [Google Scholar]
- Giovannetti, V.; Lloyd, S.; Maccone, L. Advances in quantum metrology. Nat. Photonics 2011, 5, 222–229. [Google Scholar] [CrossRef]
- Tóth, G.; Apellaniz, I. Quantum metrology from a quantum information science perspective. J. Phys. A Math. Theor. 2014, 47, 424006. [Google Scholar] [CrossRef]
- Demkowicz-Dobrzański, R.; Jarzyna, M.; Kołodyński, J. Quantum Limits in Optical Interferometry. Prog. Opt. 2015, 60, 345–435. [Google Scholar]
- Pezzé, L.; Smerzi, A. Quantum theory of phase estimation. In Atom Interferometry; Tino, G.M., Kasevich, M.A., Eds.; IOS Press: Amsterdam, The Netherlands, 2014; pp. 691–741. [Google Scholar]
- Szczykulska, M.; Baumgratz, T.; Datta, A. Multi-parameter quantum metrology. Adv. Phys. X 2016, 1, 621–639. [Google Scholar] [CrossRef]
- Degen, C.L.; Reinhard, F.; Cappellaro, P. Quantum sensing. Rev. Mod. Phys. 2017, 89, 035002. [Google Scholar] [CrossRef] [Green Version]
- Nagaoka, H. On the parameter estimation problem for quantum statistical models. In Proceedings of the 12th International Symposium on Information Theory and Its Applications (ISITA), Inuyama, Japan, 6–9 December 1989; pp. 577–582. [Google Scholar]
- Hayashi, M. (Ed.) Asymptotic Theory of Quantum Statistical Inference: Selected Papers; World Scientific: Singapore, 2005. [Google Scholar]
- Petz, D. Quantum Information Theory and Quantum Statistics; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Holevo, A.S. Probabilistic and Statistical Aspects of Quantum Theory, 2nd ed.; Edizioni della Normale: Pisa, Italy, 2011. [Google Scholar]
- Hayashi, M.; Matsumoto, K. Asymptotic performance of optimal state estimation in qubit system. J. Math. Phys. 2008, 49, 102101. [Google Scholar] [CrossRef]
- Guţă, M.; Kahn, J. Local asymptotic normality for qubit states. Phys. Rev. A 2006, 73, 052108. [Google Scholar] [CrossRef] [Green Version]
- Kahn, J.; Guţă, J. Local asymptotic normality in quantum statistics. Commun. Math. Phys. 2009, 289, 341–379. [Google Scholar] [CrossRef]
- Yamagata, K.; Fujiwara, A.; Gill, R.D. Quantum local asymptotic normality based on a new quantum likelihood ratio. Ann. Stat. 2013, 41, 2197–2217. [Google Scholar] [CrossRef]
- Fujiwara, A.; Yamagata, K. Noncommutative Lebesgue decomposition with application to quantum local asymptotic normality. arXiv 2017, arXiv:1703.07535. [Google Scholar]
- Yang, Y.; Chiribella, G.; Hayashi, M. Attaining the ultimate precision limit in quantum state estimation. Commun. Math. Phys. 2019, 368, 223–293. [Google Scholar] [CrossRef]
- Suzuki, J. Explicit formula for the Holevo bound for two-parameter qubit-state estimation problem. J. Math. Phys. 2016, 57, 042201. [Google Scholar] [CrossRef] [Green Version]
- Nagaoka, H. A New Approach to Cramér-Rao Bounds for Quantum State Estimation; IEICE Technical Report; IEICE: Tokyo, Japan, 1989; pp. 9–14. [Google Scholar]
- Nagaoka, H. On Fisher information of quantum statistical models. In Proceedings of the 10th Symposium on Information Theory and Its Applications (SITA), Yokohama, Japan, 19–21 November 1987; pp. 241–246. [Google Scholar]
- Matsumoto, K. A Geometrical Approach to Quantum Estimation Theory. Ph.D. Thesis, University of Tokyo, Tokyo, Japan, 1997. [Google Scholar]
- Suzuki, J. Explicit formula for the Holevo bound for two-parameter qubit estimation problems. In Proceedings of the 32nd Quantum Information Technology Symposium (QIT32), Suita, Japan, 26 May 2015; pp. 125–130. [Google Scholar]
- Ragy, S.; Jarzyna, M.; Demkowicz-Dobrzański, R. Compatibility in multiparameter quantum metrology. Phys. Rev. A 2016, 94, 052108. [Google Scholar] [CrossRef] [Green Version]


© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suzuki, J. Information Geometrical Characterization of Quantum Statistical Models in Quantum Estimation Theory. Entropy 2019, 21, 703. https://doi.org/10.3390/e21070703
Suzuki J. Information Geometrical Characterization of Quantum Statistical Models in Quantum Estimation Theory. Entropy. 2019; 21(7):703. https://doi.org/10.3390/e21070703
Chicago/Turabian StyleSuzuki, Jun. 2019. "Information Geometrical Characterization of Quantum Statistical Models in Quantum Estimation Theory" Entropy 21, no. 7: 703. https://doi.org/10.3390/e21070703
APA StyleSuzuki, J. (2019). Information Geometrical Characterization of Quantum Statistical Models in Quantum Estimation Theory. Entropy, 21(7), 703. https://doi.org/10.3390/e21070703