Geometric Estimation of Multivariate Dependency


Abstract
:1. Introduction
1.1. Related Work
1.2. Contribution
- (1)
- We propose a novel non-parametric multivariate dependency measure, referred to as geometric mutual information (GMI), which is based on graph-based divergence estimation. The geometric mutual information is constructed using a minimal spanning tree and is a function of the Friedman–Rafsky multivariate test statistic.
- (2)
- We establish properties of the proposed dependency measure analogous to those of Shannon mutual information, such as, convexity, concavity, chain rule, and a type of data-processing inequality.
- (3)
- We derive a bound on the MSE rate for the proposed geometric estimator. An advantage of the estimator is that it achieves the optimal MSE rate without the need for boundary correction, which is required for most plug-in estimators.
1.3. Organization
2. The Geometric Mutual Information (GMI)
2.1. Properties of the Geometric Mutual Information
- (i)
- Concavity in : Let be conditional density of given and let and be densities on . Then for ,The inequality is strict unless either or are zero or .
- (ii)
- Convexity in : Let and be conditional densities of given and let be marginal density. Then for ,The inequality is strict unless either or are zero or .
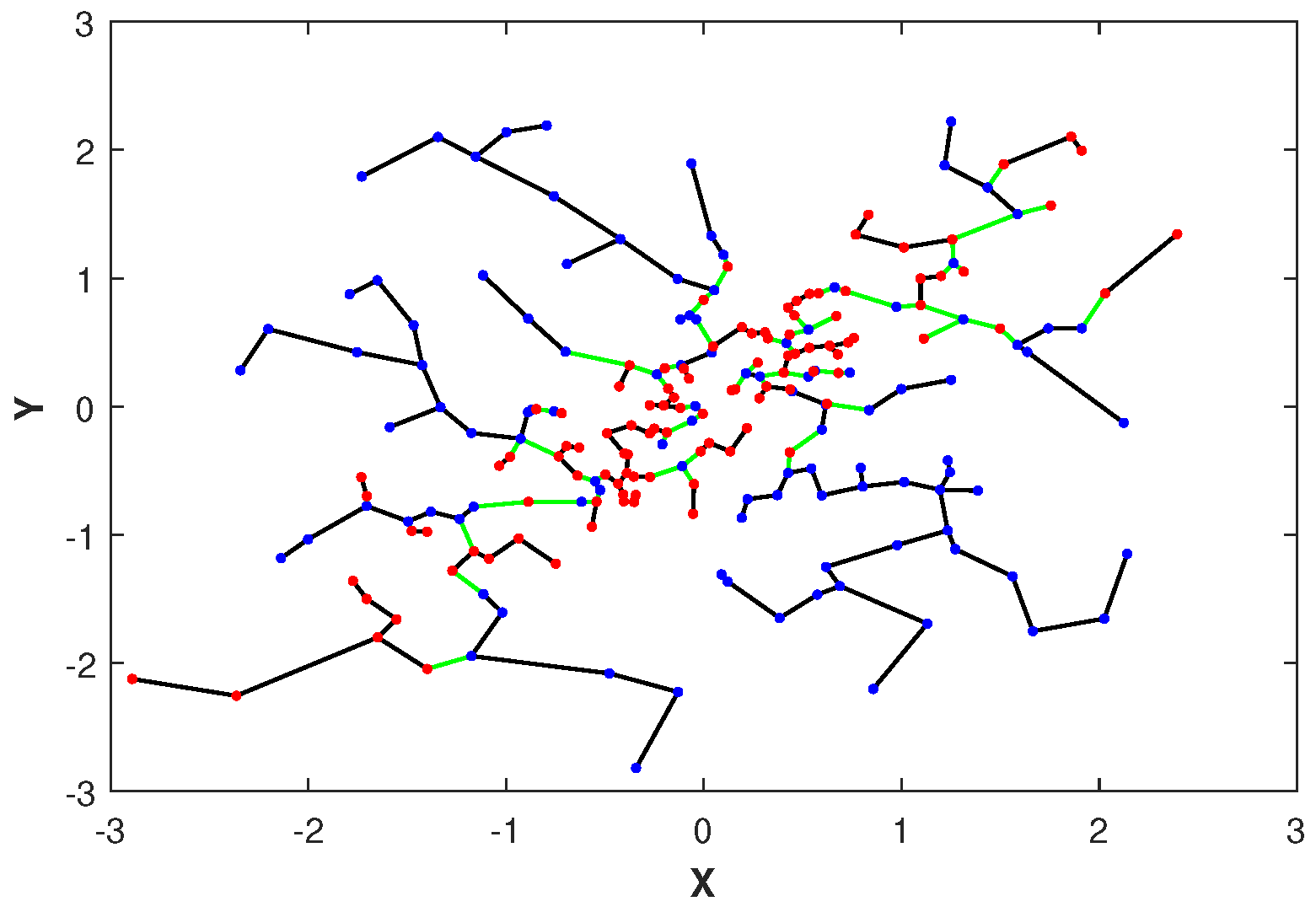
2.2. The Friedman–Rafsky Estimator

| Algorithm 1: MST-based estimator of GMI |
| Input: Data set |
| 1: Find using arguments in Section 2.4 |
| 2: , |
| 3: Divide into two subsets and |
| 4: : shuffle first and second elements of pairs in |
| 5: |
| 6: Construct MST on |
| 7: edges connecting a node in to a node of |
| 8: |
| Output: , where |
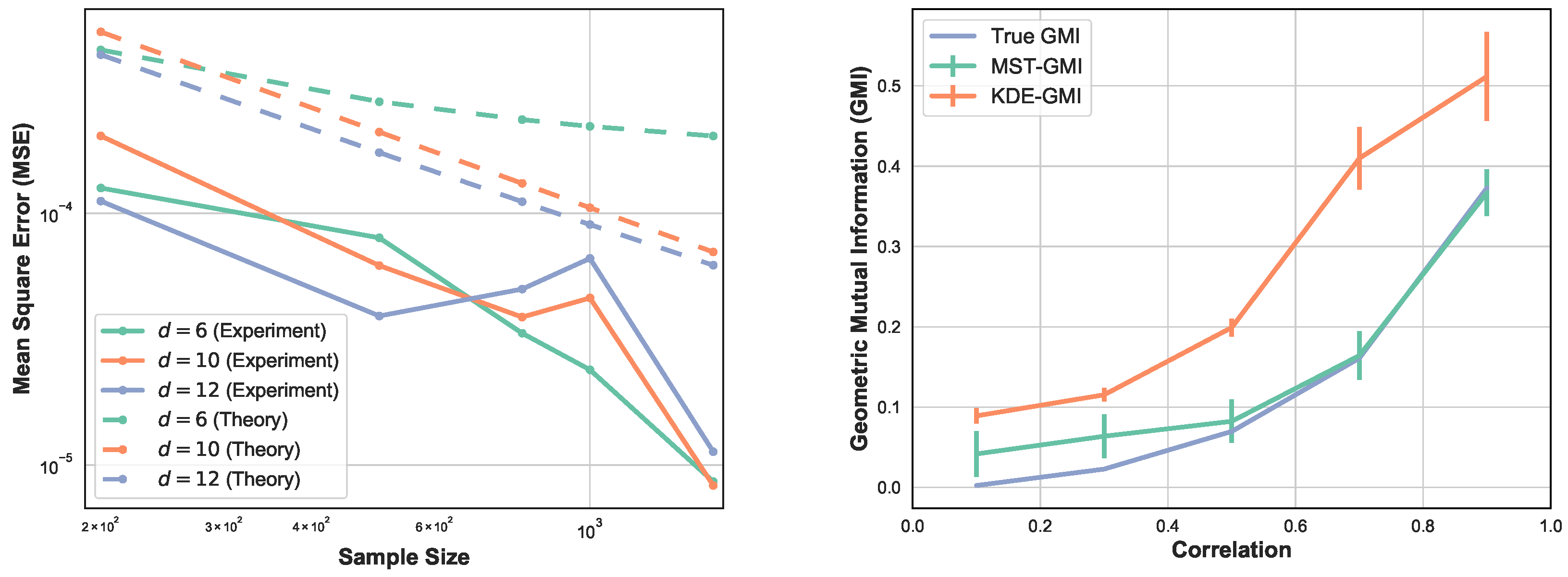
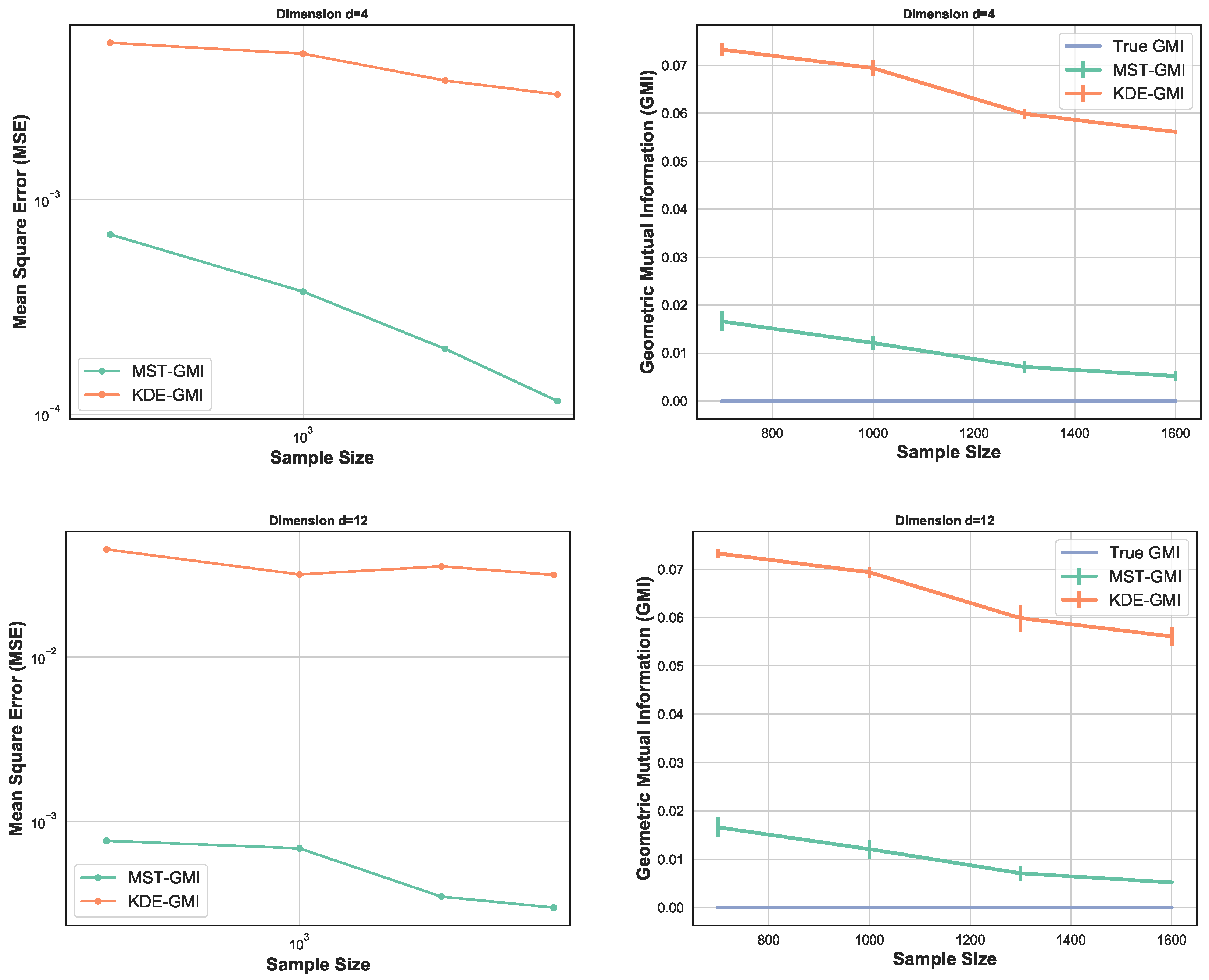
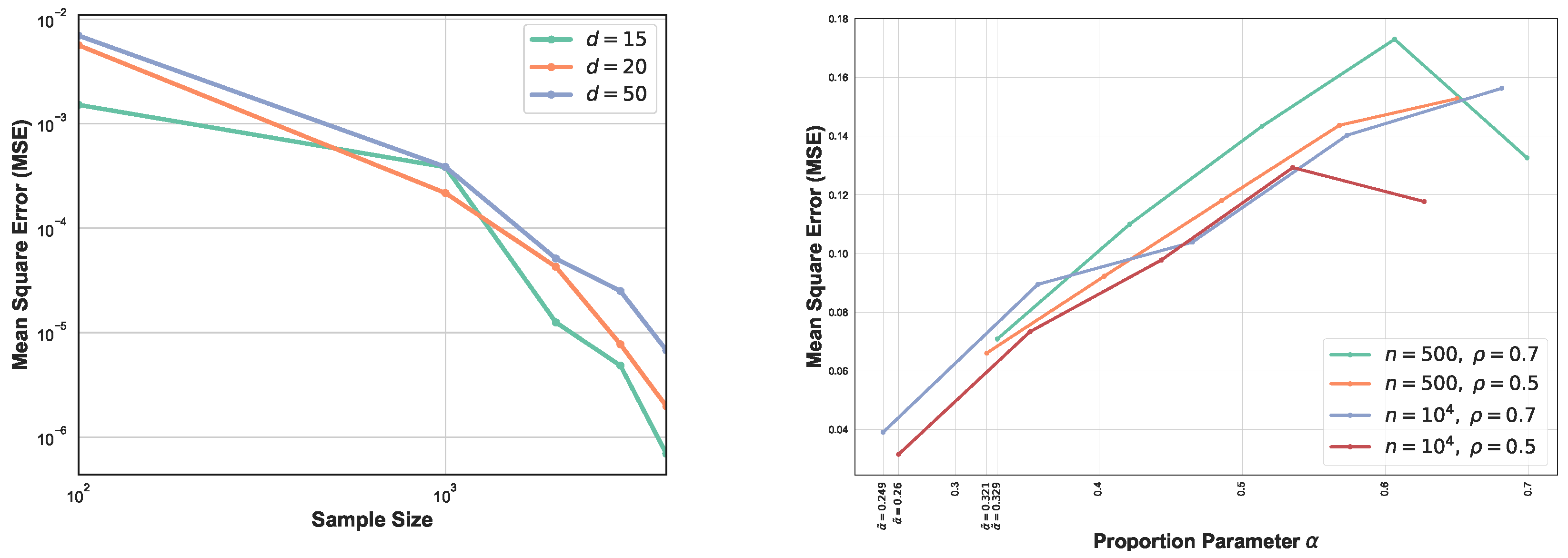
2.3. Convergence Rates
- (A.1)
- Each of the densities belong to with smoothness parameters and Lipschitz constant K.
- (A.2)
- The volumes of the support sets are finite, i.e., .
- (A.3)
- All densities are bounded i.e., there exist two sets of constants and such that , and .
2.4. Minimax Parameter
- ,
- and ,
- ,
- and , where is the smoothness parameter,
- .
- , if .
- , if .
- , if .
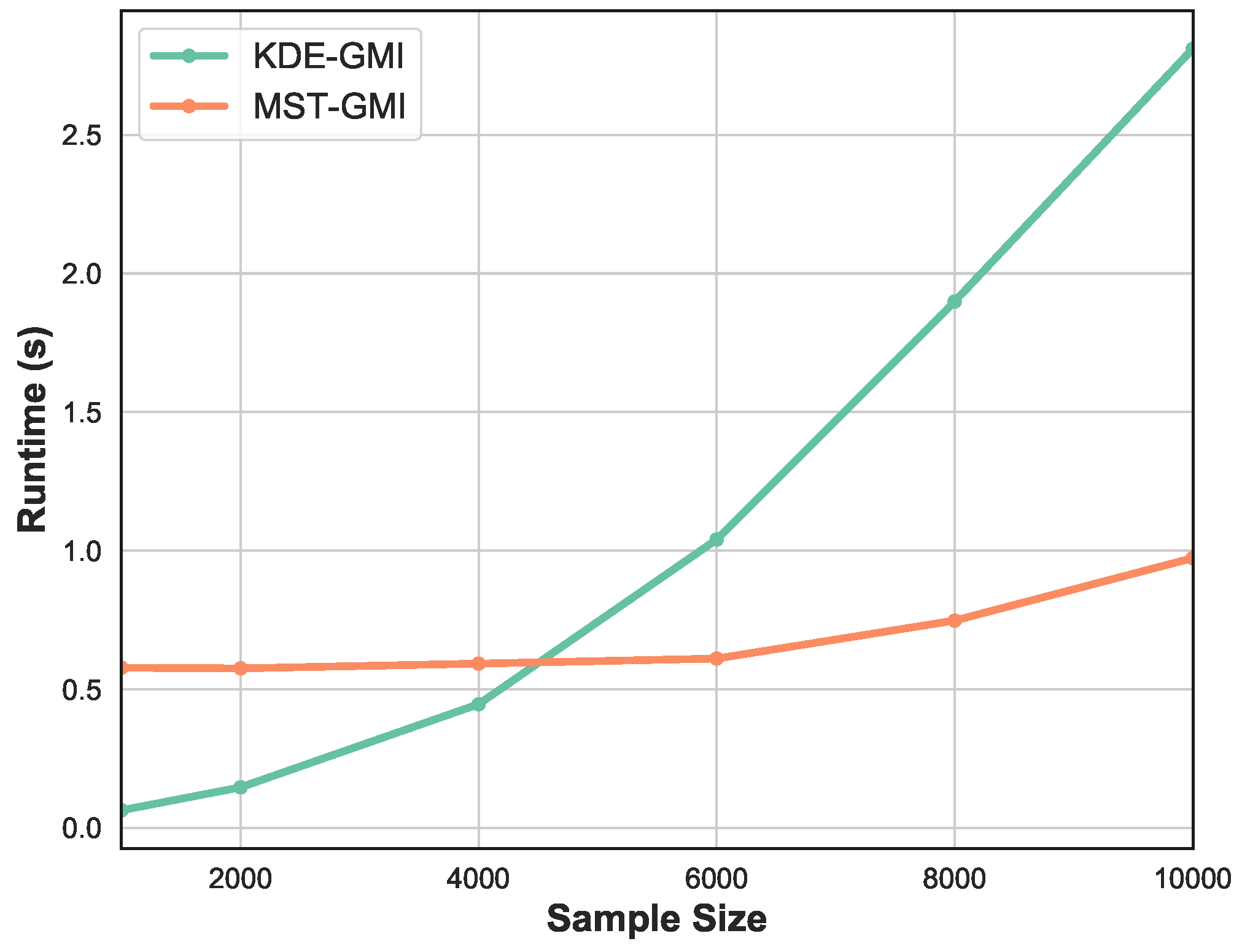
3. Simulation Study
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Theorem 1
Appendix A.2. Theorem 2
Appendix A.3. Proposition 1
Appendix A.4. Theorem 3
Appendix A.5. Theorem 4
Appendix A.6.
- , . Then and implies . Since , so this leads to .
- , . Then and implies . We know that , hence .
- , . Then and so .
References
- Lewi, J.; Butera, R.; Paninski, L. Real-time adaptive information theoretic optimization of neurophysiology experiments. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2006; pp. 857–864. [Google Scholar]
- Peng, H.C.; Herskovits, E.H.; Davatzikos, C. Bayesian Clustering Methods for Morphological Analysis of MR Images. In Proceedings of the IEEE International Symposium on Biomedical Imaging, Washington, DC, USA, 7–10 July 2002; pp. 485–488. [Google Scholar]
- Moon, K.R.; Noshad, M.; Yasaei Sekeh, S.; Hero, A.O. Information theoretic structure learning with confidence. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Brillinger, D.R. Some data analyses using mutual information. Braz. J. Probab. Stat. 2004, 18, 163–183. [Google Scholar]
- Torkkola, K. Feature extraction by non parametric mutual information maximization. J. Mach. Learn. Res. 2003, 3, 1415–1438. [Google Scholar]
- Vergara, J.R.; Estévez, P.A. A review of feature selection methods based on mutual information. Neural Comput. Appl. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Long, F.; Ding, C. Evaluation, Application, and Small Sample Performance. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 153–158. [Google Scholar]
- Sorjamaa, A.; Hao, J.; Lendasse, A. Mutual information and knearest neighbors approximator for time series prediction. Lecture Notes Comput. Sci. 2005, 3697, 553–558. [Google Scholar]
- Mohamed, S.; Rezende, D.J. Variational information maximization for intrinsically motivated reinforcement learning. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2015; pp. 2116–2124. [Google Scholar]
- Neemuchwala, H.; Hero, A.O. Entropic graphs for registration. In Multi-Sensor Image Fusion and its Applications; CRC Press Book: Boca Raton, FL, USA, 2005; pp. 185–235. [Google Scholar]
- Neemuchwala, H.; Hero, A.O.; Zabuawala, S.; Carson, P. Image registration methods in high-dimensional space. Int. J. Imaging Syst. Technol. 2006, 16, 130–145. [Google Scholar] [CrossRef] [Green Version]
- Henze, N.; Penrose, M.D. On the multivarite runs test. Ann. Stat. 1999, 27, 290–298. [Google Scholar]
- Berisha, V.; Hero, A.O. Empirical non-parametric estimation of the Fisher information. IEEE Signal Process. Lett. 2015, 22, 988–992. [Google Scholar] [CrossRef]
- Berisha, V.; Wisler, A.; Hero, A.O.; Spanias, A. Empirically estimable classification bounds based on a nonparametric divergence measure. IEEE Trans. Signal Process. 2016, 64, 580–591. [Google Scholar] [CrossRef]
- Kailath, T. The divergence and Bhattacharyya distance measures in signal selection. IEEE Trans. Commun. Technol. 1967, 15, 52–60. [Google Scholar] [CrossRef]
- Yasaei Sekeh, S.; Oselio, B.; Hero, A.O. Multi-class Bayes error estimation with a global minimal spanning tree. In Proceedings of the 2018 56th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–5 October 2018. [Google Scholar]
- Noshad, M.; Moon, K.R.; Yasaei Sekeh, S.; Hero, A.O. Direct Estimation of Information Divergence Using Nearest Neighbor Ratios. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017. [Google Scholar]
- March, W.; Ram, P.; Gray, A. Fast Euclidean minimum spanning tree: Algorithm, analysis, and applications. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2010; pp. 603–612. [Google Scholar]
- Borůvka, O. O jistém problému minimálním. Práce Moravské Pridovedecké Spolecnosti 1926, 3, 37–58. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066–138. [Google Scholar] [CrossRef] [PubMed]
- Moon, K.R.; Sricharan, K.; Hero, A.O. Ensemble Estimation of Mutual Information. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 3030–3034. [Google Scholar]
- Moon, K.R.; Hero, A.O. Multivariate f-divergence estimation with confidence. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2420–2428. [Google Scholar]
- Moon, K.R.; Sricharan, K.; Greenewald, K.; Hero, A.O. Improving convergence of divergence functional ensemble estimators. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016. [Google Scholar]
- Leonenko, N.; Pronzato, L.; Savani, V. A class of Rényi information estimators for multidimensional densities. Ann. Stat. 2008, 36, 2153–2182. [Google Scholar] [CrossRef]
- Gao, S.; Ver Steeg, G.; Galstyan, A. Efficient estimation of mutual information for strongly dependent variables. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; pp. 277–286. [Google Scholar]
- Pál, D.; Póczos, B.; Szapesvári, C. Estimation of Rényi entropy and mutual information based on generalized nearest-neighbor graphs. In Proceedings of the 24th Annual Conference on Neural Information Processing Systems 2010, Vancouver, BC, Canada, 6–9 December 2010. [Google Scholar]
- Krishnamurthy, A.; Kandasamy, K.; Póczos, B.; Wasserman, L. Nonparametric estimation of Rényi divergence and friends. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 919–927. [Google Scholar]
- Kandasamy, K.; Krishnamurthy, A.; Póczos, B.; Wasserman, L.; Robins, J. Nonparametric von mises estimators for entropies, divergences and mutual informations. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 397–405. [Google Scholar]
- Singh, S.; Póczos, B. Analysis of k nearest neighbor distances with application to entropy estimation. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1217–1225. [Google Scholar]
- Sugiyama, M. Machine learning with squared-loss mutual information. Entropy 2012, 15, 80–112. [Google Scholar] [CrossRef]
- Costa, A.; Hero, A.O. Geodesic entropic graphs for dimension and entropy estimation in manifold learning. IEEE Trans. Signal Process. 2004, 52, 2210–2221. [Google Scholar] [CrossRef]
- Friedman, J.H.; Rafsky, L.C. Multivariate generalizations of the Wald-Wolfowitz and Smirnov two-sample tests. Ann. Stat. 1979, 7, 697–717. [Google Scholar] [CrossRef]
- Smirnov, N.V. On the estimation of the discrepancy between empirical curves of distribution for two independent samples. Bull. Moscow Univ. 1939, 2, 3–6. [Google Scholar]
- Wald, A.; Wolfowitz, J. On a test whether two samples are from the same population. Ann. Math. Stat. 1940, 11, 147–162. [Google Scholar] [CrossRef]
- Noshad, M.; Hero, A.O. Scalable mutual information estimation using dependence graphs. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTAT), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Yasaei Sekeh, S.; Oselio, B.; Hero, A.O. A Dimension-Independent discriminant between distributions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Csiszár, I. Information-type measures of difference of probability distributions and indirect observations. Studia Sci. Math. Hungar. 1967, 2, 299–318. [Google Scholar]
- Ali, S.; Silvey, S.D. A general class of coefficients of divergence of one distribution from another. J. R. Stat. Soc. Ser. B (Methodol.) 1966, 28, 131–142. [Google Scholar] [CrossRef]
- Cover, T.; Thomas, J. Elements of Information Theory, 1st ed.; John Wiley & Sons: Chichester, UK, 1991. [Google Scholar]
- Härdle, W. Applied Nonparametric Regression; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Lorentz, G.G. Approximation of Functions; Holt, Rinehart and Winston: New York, NY, USA; Chicago, IL, USA; Toronto, ON, Canada, 1966. [Google Scholar]
- Andersson, P. Characterization of pointwise Hölder regularity. Appl. Comput. Harmon. Anal. 1997, 4, 429–443. [Google Scholar] [CrossRef]
- Robins, G.; Salowe, J.S. On the maximum degree of minimum spanning trees. In Proceedings of the SCG 94 Tenth Annual Symposium on Computational Geometry, Stony Brook, NY, USA, 6–8 June 1994; pp. 250–258. [Google Scholar]
- Efron, B.; Stein, C. The jackknife estimate of variance. Ann. Stat. 1981, 9, 586–596. [Google Scholar] [CrossRef]
- Yasaei Sekeh, S.; Noshad, M.; Moon, K.R.; Hero, A.O. Convergence Rates for Empirical Estimation of Binary Classification Bounds. arXiv 2018, arXiv:1810.01015. [Google Scholar]
- Kingman, J.F.C. Poisson Processes; Oxford Univ. Press: Oxford, UK, 1993. [Google Scholar]
- Yukich, J.E. Probability Theory of Classical Euclidean Optimization; Vol. 1675 of Lecture Notes in Mathematics; Springer: Berlin, Germany, 1998. [Google Scholar]
- Luenberger, D.G. Optimization by Vector Space Methods; Wiley Professional Paperback Series; Wiley-Interscience: Hoboken, NJ, USA, 1969. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Overview Table for Different d, n, and | |||||
|---|---|---|---|---|---|
| Experiments | Dimension () | Sample Size () | GMI () | MSE () | Parameter () |
| Scenario 1–1 | 6 | 1000 | 0.0229 | 12 | 0.2 |
| Scenario 1–2 | 6 | 1000 | 0.0143 | 4.7944 | 0.5 * |
| Scenario 1–3 | 6 | 1000 | 0.0176 | 6.3867 | 0.8 |
| Scenario 2–1 | 8 | 1500 | 0.0246 | 11 | 0.2 |
| Scenario 2–2 | 8 | 1500 | 0.0074 | 1.6053 | 0.5 * |
| Scenario 2–3 | 8 | 1500 | 0.0137 | 5.3863 | 0.8 |
| Scenario 3–1 | 10 | 2000 | 0.0074 | 2.3604 | 0.2 |
| Scenario 3–2 | 10 | 2000 | 0.0029 | 0.54180 | 0.5 * |
| Scenario 3–3 | 10 | 2000 | 0.0262 | 11 | 0.8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yasaei Sekeh, S.; Hero, A.O. Geometric Estimation of Multivariate Dependency. Entropy 2019, 21, 787. https://doi.org/10.3390/e21080787
Yasaei Sekeh S, Hero AO. Geometric Estimation of Multivariate Dependency. Entropy. 2019; 21(8):787. https://doi.org/10.3390/e21080787
Chicago/Turabian StyleYasaei Sekeh, Salimeh, and Alfred O. Hero. 2019. "Geometric Estimation of Multivariate Dependency" Entropy 21, no. 8: 787. https://doi.org/10.3390/e21080787
APA StyleYasaei Sekeh, S., & Hero, A. O. (2019). Geometric Estimation of Multivariate Dependency. Entropy, 21(8), 787. https://doi.org/10.3390/e21080787