Evolved-Cooperative Correntropy-Based Extreme Learning Machine for Robust Prediction



Abstract
:1. Introduction
- The proposed method develops a novel correntropy criterion with multiple kernels to improve the flexibility for depicting the probability distribution of the current error of the predicting model. Then, a convex cost function has been developed based on the multiple kernel correntropy, which can provide a more robust training strategy for ELMs, resulting in high performance on the predictions against noise and outliers.
- To accurately describe the probability distribution of the current error, the proposed method develops a cooperating evolution strategy to adaptively generate proper bandwidths and coefficients to suit the error distribution which enhances the accuracy on the approximation for the correntropy, leading to more robust training.
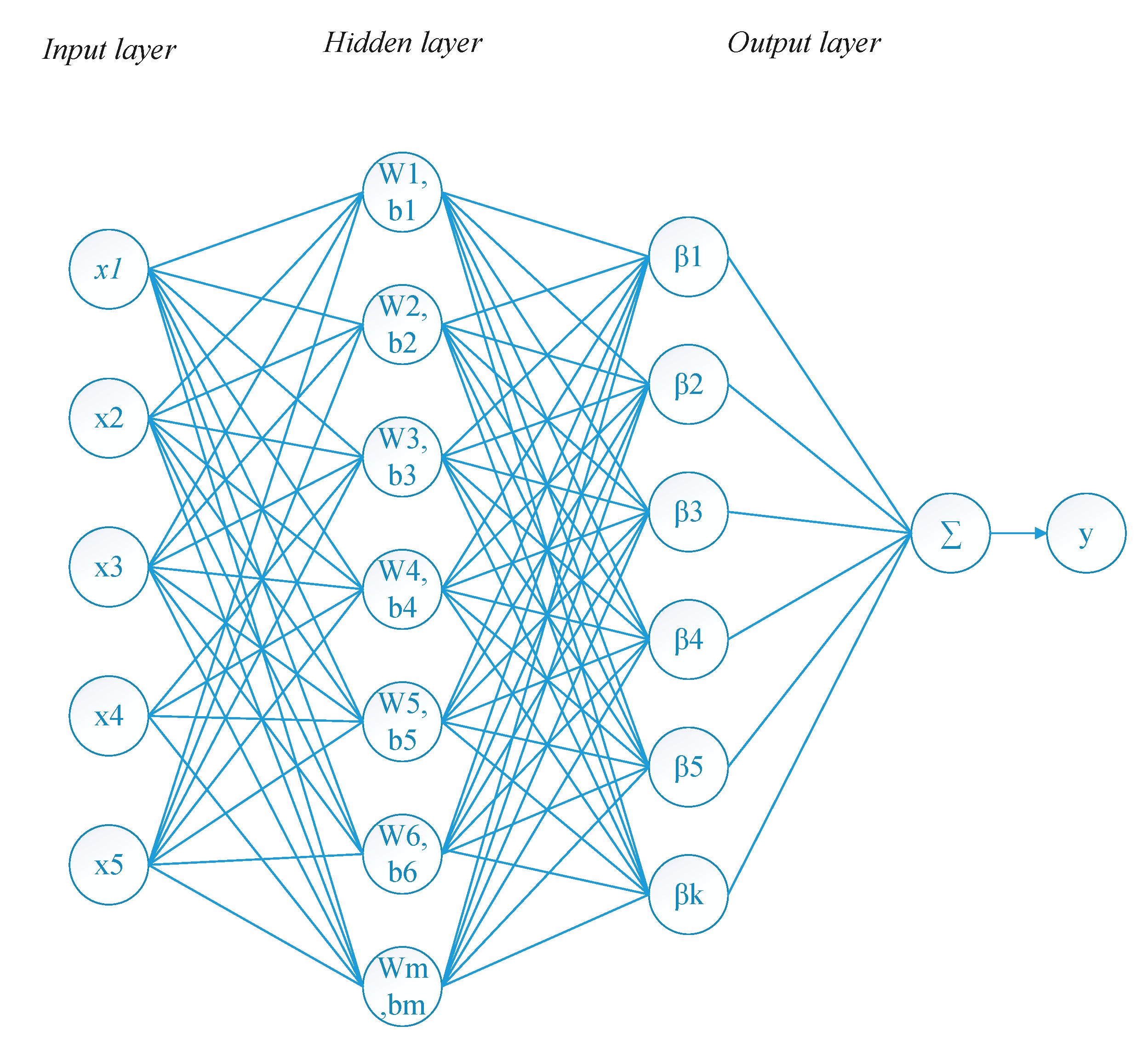
2. The Framework of the Proposed Method
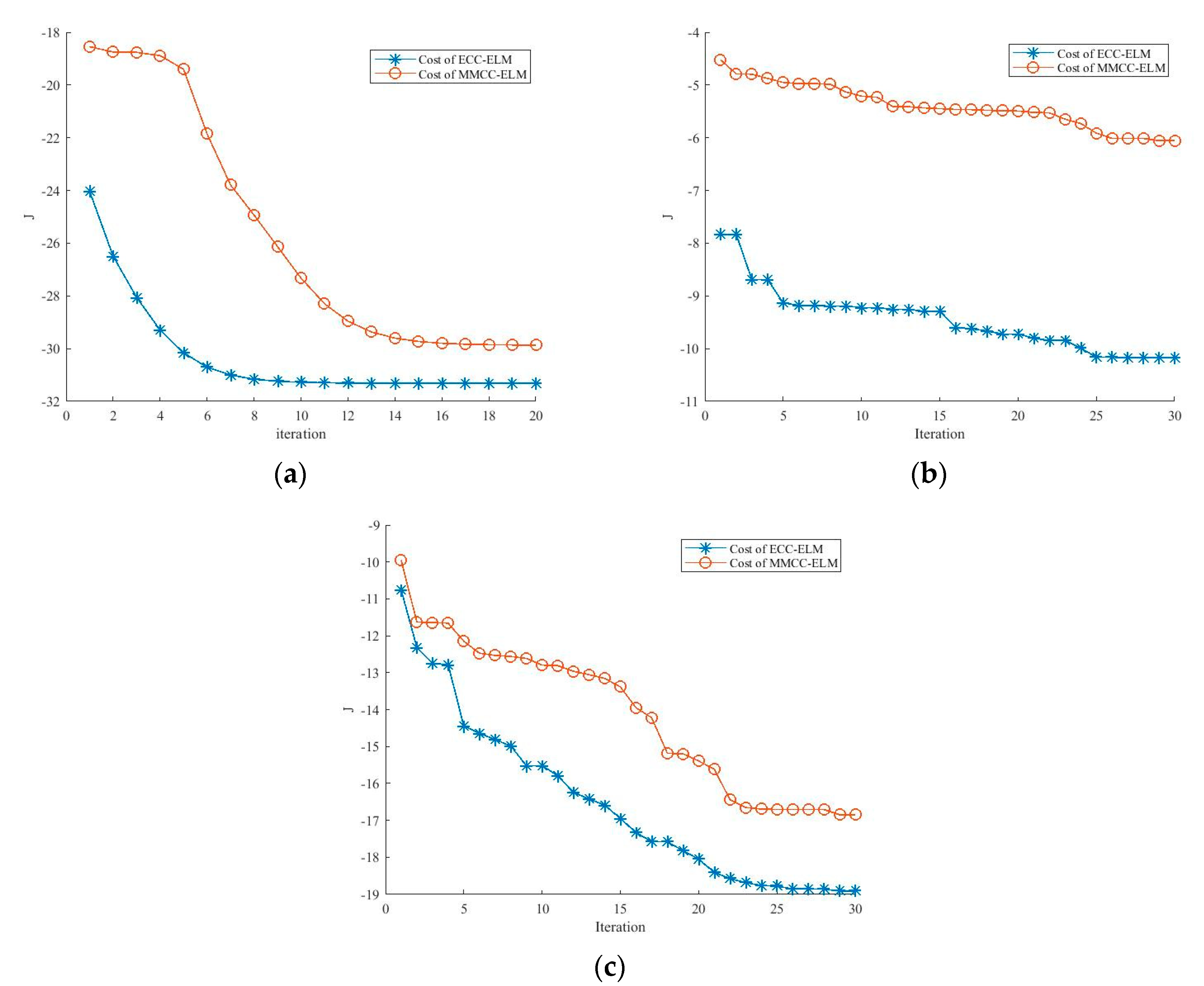
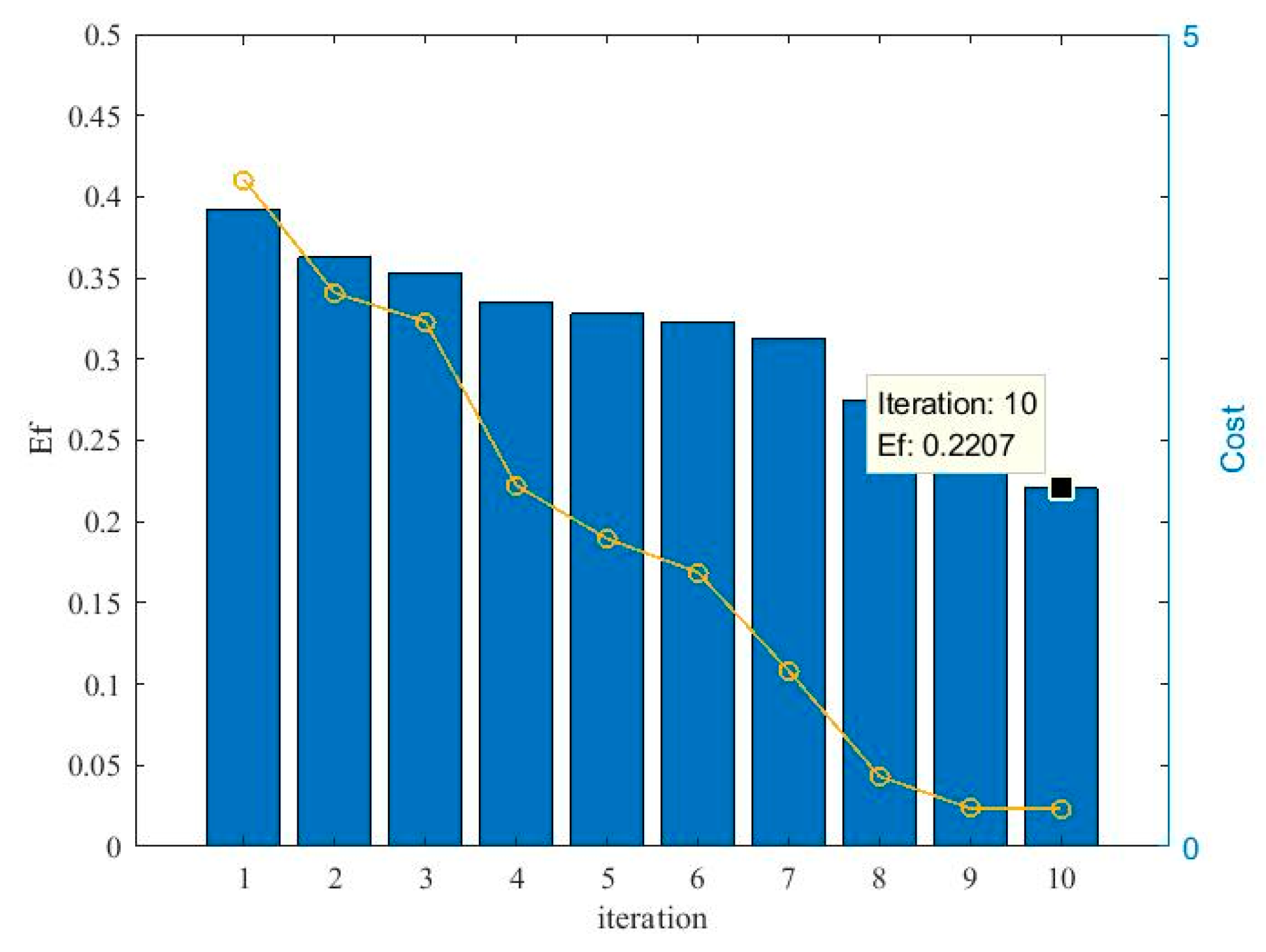
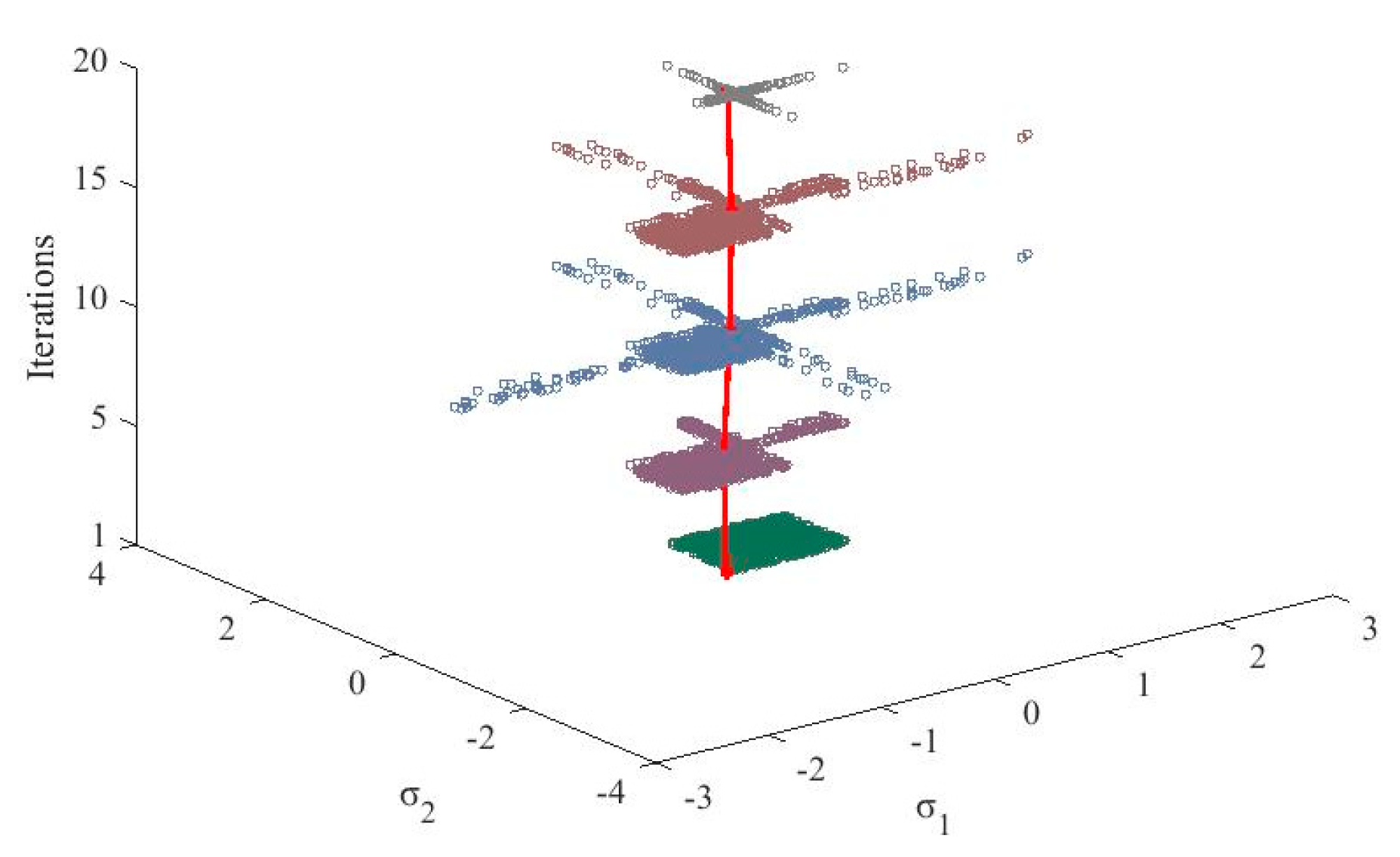
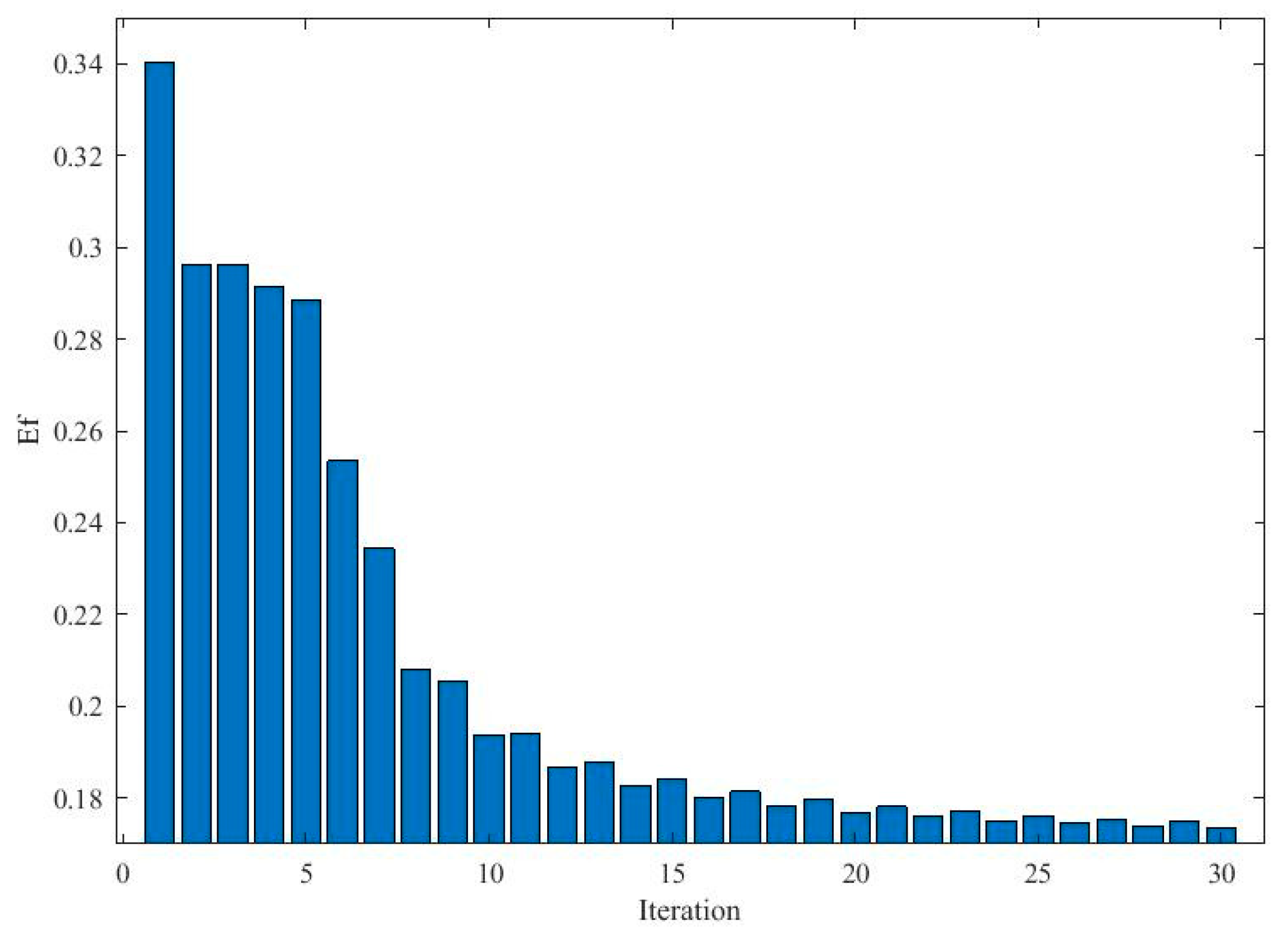
3. The Cooperating Evolution Process for the Bandwidth and Influence Coefficients of the Kernel
| Algorithm 1 Evolved cooperation for the kernel parameters |
| Input: the samples {xi,ti},i = 1, 2, …, N Output: the vector of bandwidth and the vector of influence coefficients A Parameters: the step length and the number of iterations L Initialization: Set the cost function of the best solution MIEbest to and randomly assign the bandwidth of the kernels σc = {σc,1, σc,2, …, σc,N} and the corresponding velocity vσc = {vσc,1, vσc,2, …, vσc,N}. 1: for k = 1, 2, … L do 2: Generate the best influence coefficients Ac using Equation (26) for each particles. 3: Calculate value of cost function for each particle MIEc based on Equation (24) 4: Update the personal best solution and the global best solution based on minimizing the cost function. 5: Calculate the Ef of the iteration with Equation (29) 6: Access the parameters for evolution based on Table 1 7: Update the swarm with Equations (27) and (28) 8: end for 9: Return the global best bandwidth and the corresponding influence coefficients |
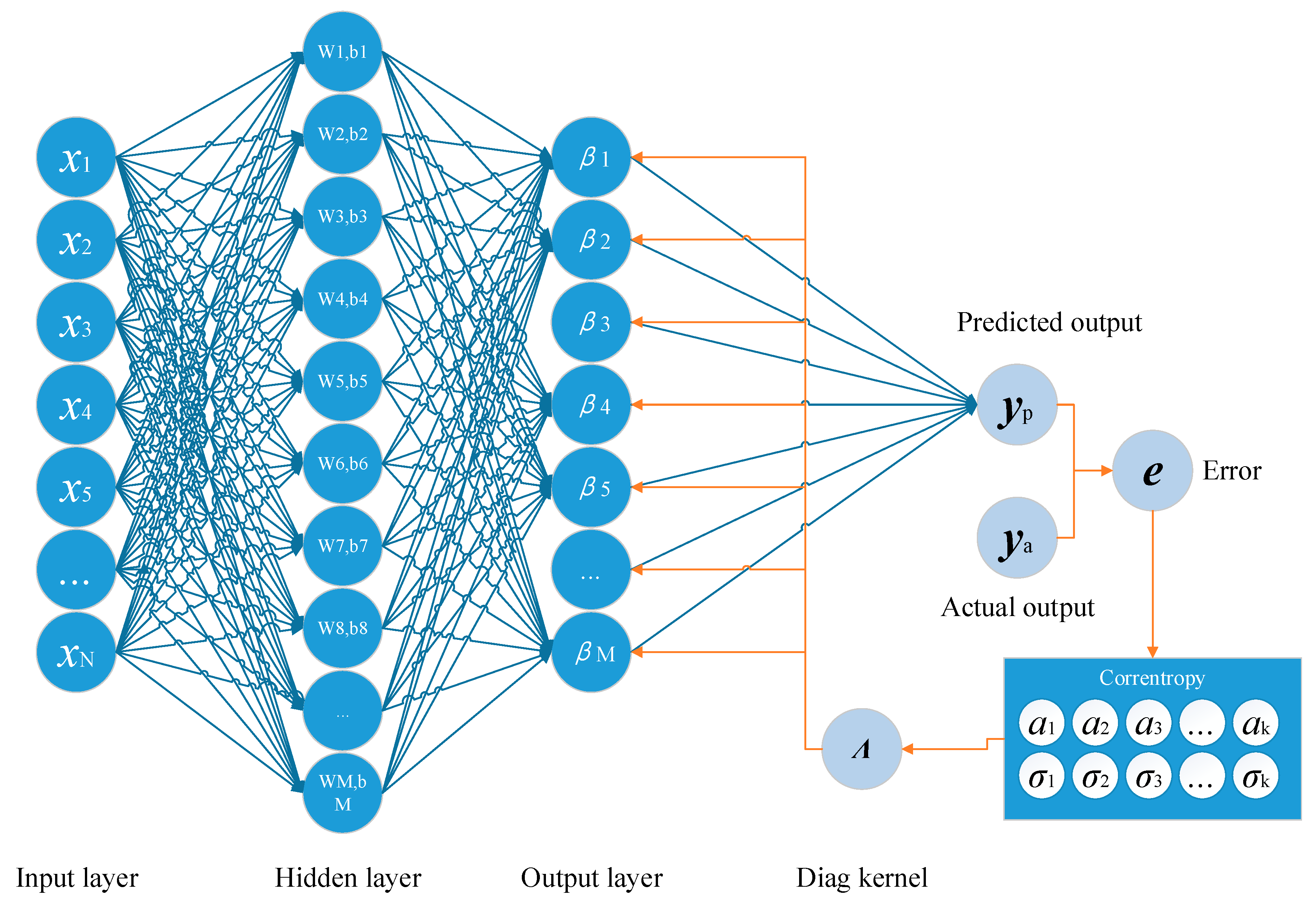
4. Training the Extreme Learning Machine Using the Multi-Dimension Correntropy
| Algorithm 2 ECC-ELM |
| Input: the samples {xi,ti}, i = 1, 2, …, N Output: output weights Parameters: the number of hidden nodes N, the number of iterations L, the iterations T and termination tolerance ε Initialization: Randomly set the weights and bias of the hidden nodes and initialize the output weights using Equation (5) 1: for t = 1, 2, …, T do 2: Calculate the residual error: ei = ti − hi, i = 1, 2, …, N 3: Calculate the kernel parameters {} using Algorithm 1 4: Calculate the diagonal matrix Λ: 5: Update the output weight using Equation (37) 6: Until |Jk() − Jk−1()| < ε 7: end for |
5. Analysis on Time Complexity and Space Complexity of ECC-ELM
6. Experiments
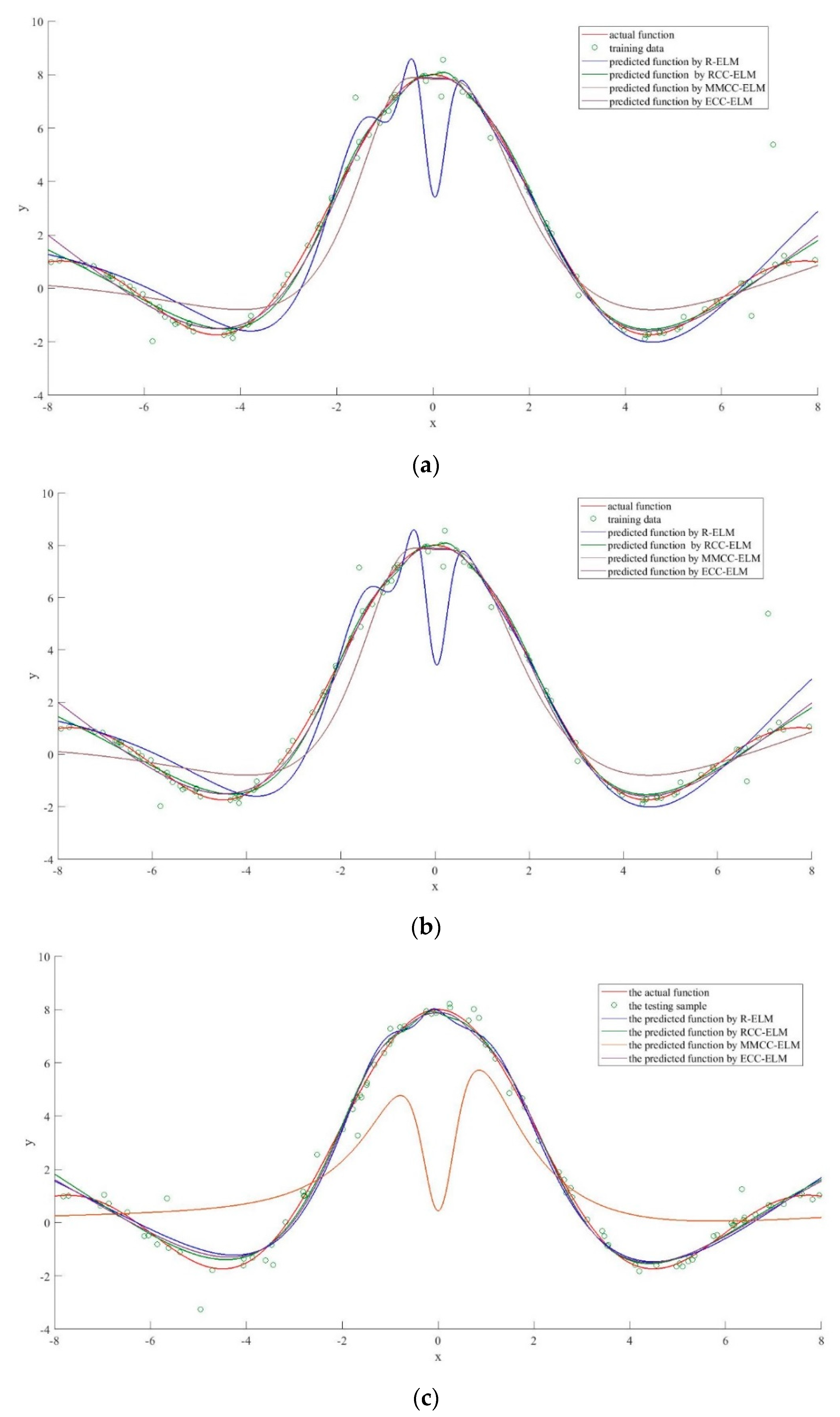
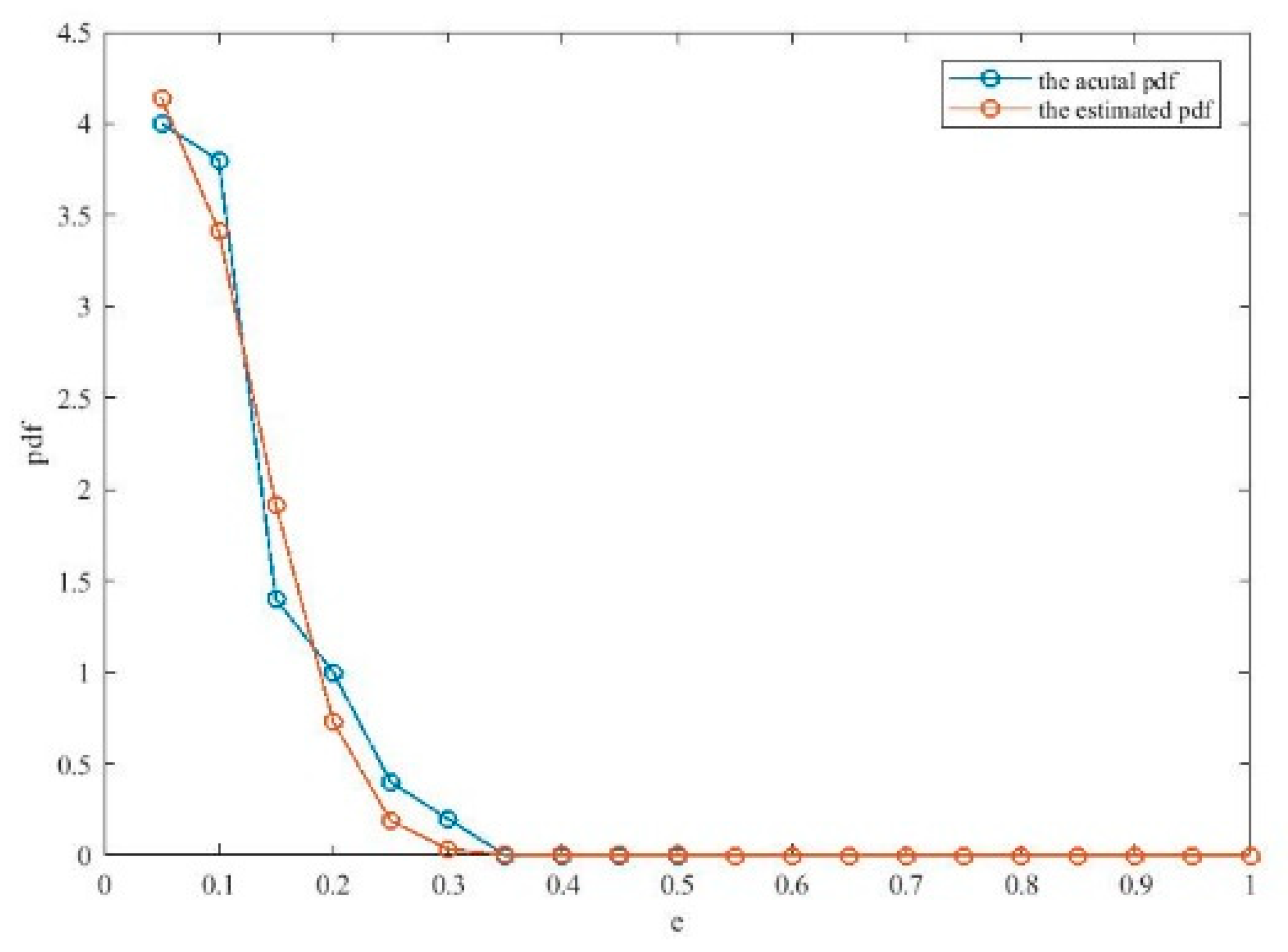
6.1. The Simulation of the Sinc Function with Sas noises
6.2. The Performance Comparison on Benchmark datasets
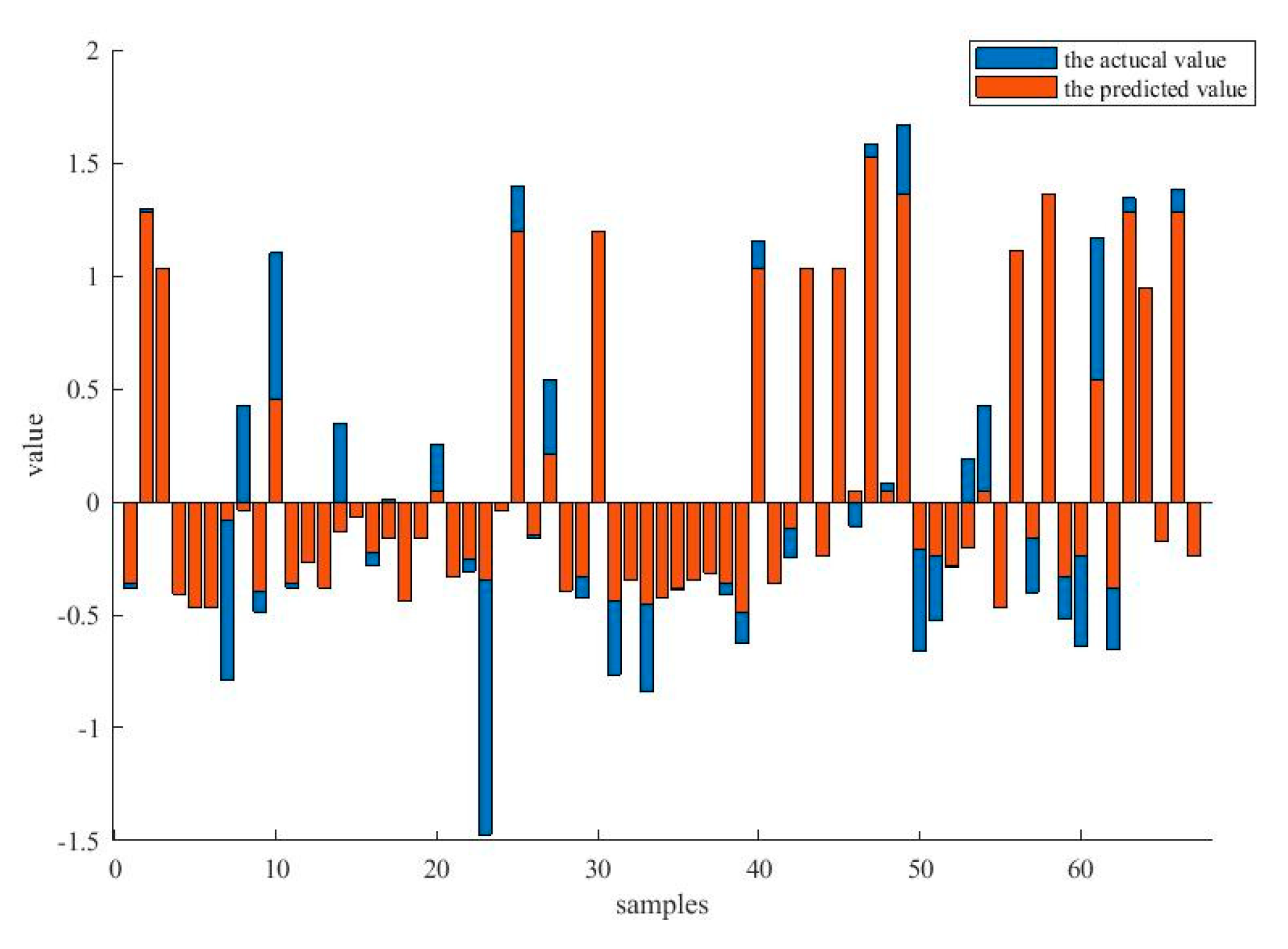
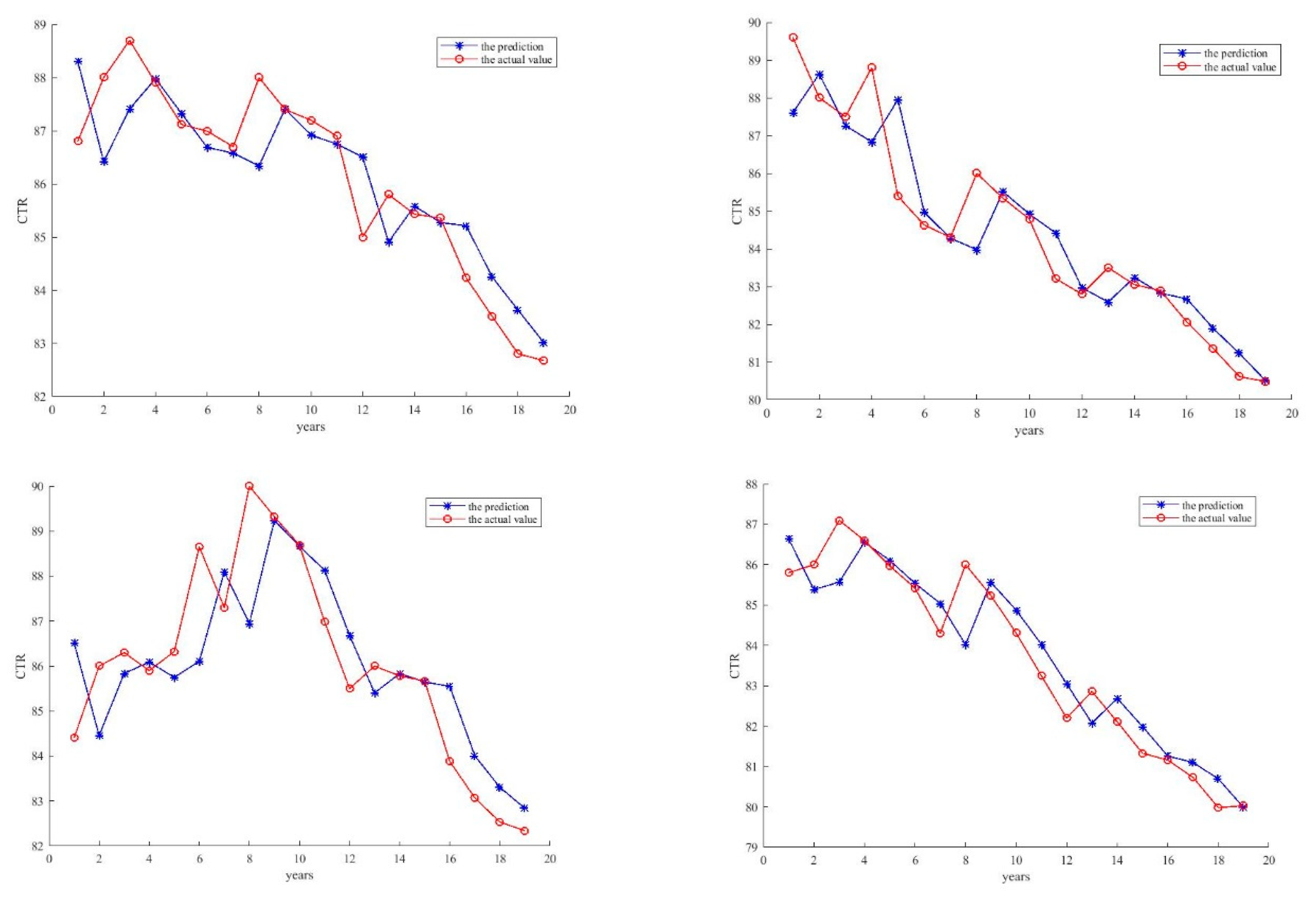
6.3. The Performance Estimations for Forecasting the CTR of Optical Couplers
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Heddam, S.; Keshtegar, B.; Kisi, O. Predicting total dissolved gas concentration on a daily scale using kriging interpolation, response surface method and artificial neural network: Case study of Columbia river Basin Dams, USA. Nat. Resour. Res. 2019, 2, 1–18. [Google Scholar] [CrossRef]
- Ahmadi, N.; Nilashi, M.; Samad, S.; Rashid, T.A.; Admadi, H. An intelligent method for iris recognition using supervised machine learning techniques. Opt. Laser Thechnol. 2019, 120, 105701. [Google Scholar] [CrossRef]
- Aeukumar, R.; Karthigaikumar, P. Multi-retinal disease classification by reduced deep learning features. Neural Comput. Appl. 2017, 28, 329–334. [Google Scholar]
- Pentapati, H.K.; Teneti, M. Robust speaker recognition systems with adaptive filter algorithms in real time under noisy conditions. Adv. Decis. Sci. Image Process. Secur. Comput. Vis. 2020, 4, 1–18. [Google Scholar]
- Eweda, E. Stability bound of the initial mean-square division of high-order stochastic gradient adaptive filtering algorithms. IEEE Trans. Signal Process. 2019, 6, 4168–4176. [Google Scholar] [CrossRef]
- Huang, X.; Wen, G.; Liangm, L.; Zhang, Z.; Tan, Y. Frequency phase space empirical wavelet transform for rolling bearing fault diagnosis. IEEE Access. 2019, 7, 86306–86318. [Google Scholar] [CrossRef]
- Yang, J.; Zhu, H.; Liu, T. Secure and economical multi-cloud storage policy with NSGA-II-C. Appl. Soft Comput. 2019, 83, 105649. [Google Scholar] [CrossRef]
- Albasri, A.; Abdali-Mohammadi, F.; Fathi, A. EEG electrode selection for person identification thru a genetic-algorithm method. J. Med. Syst. 2019, 43, 297. [Google Scholar] [CrossRef]
- Dermanaki Farahani, Z.; Ahmadi, M.; Sharifi, M. History matching and uncertainty quantification for velocity dependent relative permeability parameters in a gas condensate reservoir. Arab. J. Geosci. 2019, 12, 454. [Google Scholar] [CrossRef]
- Shah, P.; Kendall, F.; Khozin, S.; Goosen, R.; Hu, J.; Laramine, J.; Ringel, M.; Schork, N. Artificial intelligence and machine learning in clinical development: A translational perspective. Nature 2019, 2, 1–5. [Google Scholar] [CrossRef]
- Shirwaikar, R.D.; Dinesh, A.U.; Makkithaya, K.; Suruliverlrajan, M.; Srivastava, S.; Leslie, E.S.; Lewis, U. Optimizing neural network for medical data sets: A case study on neonatal apnea prediction. Artif. Intell. Med. 2019, 98, 59–76. [Google Scholar] [CrossRef] [PubMed]
- Lucena, O.; Souza, R.; Rittner, L.; Frayne, R.; Lotufo, R. Convolutional neural network for skull-stripping in brain MR imaging using silver standard masks. Artif. Intell. Med. 2019, 98, 48–58. [Google Scholar] [CrossRef] [PubMed]
- Guan, H.; Dai, Z.; Guan, S.; Zhao, A. A neutrosophic forecasting model for time series based on first-order state and information entropy of high-order fluctuation. Entropy 2019, 21, 455. [Google Scholar] [CrossRef]
- Tymoshchuk, O.; Kirik, O.; Dorundiak, K. Comparative analysis of the methods for assessing the probability of bankruptcy for Ukrainian enterprises. In Lecture Notes in Computational Intelligence and Decision Making; Springer: Basel, Switzerland, 2019; pp. 281–293. [Google Scholar]
- Yang, T.; Jia, S. Research on artificial intelligence technology in computer network technology, International conference on artificial intelligence and security. In Proceedings of the 5th International Conference on Artificial Intelligence and Security (ICAIS 2019), New York, NY, USA, 26–28 July 2019; pp. 488–496. [Google Scholar]
- Senguta, E.; Jain, N.; Garg, D.; Choudhury, T. A review of payment card fraud detection methods using artificial intelligence. In Proceedings of the International Conference on Computational Techniques, Electronics and Mechanical Systems (CTEMS), Belagavi, India, 21–23 December 2018; pp. 494–499. [Google Scholar]
- Ampatzidis, Y.; Partel, V.; Meyering, B.; Albercht, U. Citrus rootstock evaluation utilizing UAV-based remote sensing and artificial intelligence. Comput. Electron. Agric. 2019, 164, 104900. [Google Scholar] [CrossRef]
- Yue, D.; Han, Q. Guest editorial special issue on new trends in energy internet: Artificial intelligence-based control, network security and management. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1551–1553. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.P.; Principe, J.C. The kernel least mean square algorithm. IEEE Trans. Signal Process. 2008, 56, 543–554. [Google Scholar] [CrossRef]
- Vega, L.R.; Rey, H.; Benesty, J.; Tressens, S. A new robust variable step-size NLMS algorithm. IEEE Trans. Signal Process. 2008, 56, 1878–1893. [Google Scholar] [CrossRef]
- Vega, L.R.; Rey, H.; Benesty, J.; Tressens, S. A fast robust recursive least-squares algorithm. IEEE Trans. Signal Process. 2008, 57, 1209–1216. [Google Scholar] [CrossRef]
- Ekpenyong, U.E.; Zhang, J.; Xia, X. An improved robust model for generator maintenance scheduling. Electr. Power Syst. Res. 2012, 92, 29–36. [Google Scholar] [CrossRef]
- Huang, Y.; Lee, M.-C.; Tseng, V.S.; Hsiao, C.; Huang, C. Robust sensor-based human activity recognition with snippet consensus neural networks. In Proceedings of the IEEE 16th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Chicago, IL, USA, 19–22 May 2019. [Google Scholar]
- Ning, C.; You, F. Deciphering latent uncertainty sources with principal component analysis for adaptive robust optimization. Comput. Aided Chem. Eng. 2019, 46, 1189–1194. [Google Scholar]
- He, C.; Zhang, Q.; Tang, Y.; Liu, S.; Liu, H. Network embedding using semi-supervised kernel nonnegative matrix factorization. IEEE Access. 2019, 7, 92732–92744. [Google Scholar] [CrossRef]
- Bravo-Moncayo, L.; Lucio-Naranjo, J.; Chavez, M.; Pavon-Garcia, I.; Garzon, C. A machine learning approach for traffic-noise annoyance assessment. Appl. Acoust. 2019, 156, 262–270. [Google Scholar] [CrossRef]
- Santos, J.D.A.; Barreto, G.A. An outlier-robust kernel RLS algorithm for nonlinear system identification. Nonlinear Dyn. 2017, 90, 1707–1726. [Google Scholar] [CrossRef]
- Guo, W.; Xu, T.; Tang, K. M-estimator-based online sequential extreme learning machine for predicting chaotic time series with outliers. Neural Comput. Appl. 2017, 28, 4093–4110. [Google Scholar] [CrossRef]
- Zhou, P.; Guo, D.; Wang, H.; Chai, T. Data-driven robust M-LS-SVR-based NARX modeling for estimation and control of molten iron quality indices in blast furnace ironmaking. IEEE Trans. Neural Netw. Learn. 2018, 29, 4007–4021. [Google Scholar] [CrossRef]
- Ma, W.; Qiu, J.; Liu, X.; Xiao, G.; Duan, J.; Chen, B. Unscented Kalman filter with generalized correntropy loss for robust power system forecasting-aided state estimation. IEEE Trans. Ind. Inf. 2019. [Google Scholar] [CrossRef]
- Safarian, C.; Ogunfunmi, T. The quaternion minimum error entropy algorithm with fiducial point for nonlinear adaptive systems. Signal Process. 2019, 163, 188–200. [Google Scholar] [CrossRef]
- Dighe, P.; Asaei, A.; Bourlard, H. Low-rank and sparse subspace modeling of speech for DNN based acoustic modeling. Speech Commun. 2019, 109, 34–45. [Google Scholar] [CrossRef]
- Li, L.-Q.; Wang, X.-L.; Xie, W.-X.; Liu, Z.-X. A novel recursive T-S fuzzy semantic modeling approach for discrete state-space systems. Neurocomputing 2019, 340, 222–232. [Google Scholar] [CrossRef]
- Hajiabadi, M.; Hodtani, G.A.; Khoshbin, H. Robust learning over multi task adaptive networks with wireless communication links. IEEE Trans. Comput. Aided Des. 2019, 66, 1083–1087. [Google Scholar]
- Kutz, N.J. Neurosensory network functionality and data-driven control. Curr. Opin. Syst. Biol. 2019, 3, 31–36. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Zheng, N.; Principe, J.C. Quantized minimum error Entropy criterion. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1370–1380. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.P.; Principe, J.C. Correntropy: Properties and applications in non-guassian signal processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Kuliova, M.V. Factor-form Kalman-like implementations under maximum correntropy criterion. Signal Process. 2019, 160, 328–338. [Google Scholar] [CrossRef]
- Ou, W.; Gou, J.; Zhou, Q.; Ge, S.; Long, F. Discriminative Multiview nonnegative matrix factorization for classification. IEEE Access. 2019, 7, 60947–60956. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, L.; Ren, Q. A robust classification framework with mixture correntropy. Inform. Sci. 2019, 491, 306–318. [Google Scholar] [CrossRef]
- Moustafa, N.; Turnbull, B.; Raymond, K. An ensemble intrusion detection technique based on proposed statical flow features for protecting network traffic of internet of things. IEEE Internet Things J. 2019, 6, 4815–4830. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, Y.; Wang, X. Iterated maximum correntropy unscented Kalman filters for non-Gaussian systems. Signal Process. 2019, 163, 87–94. [Google Scholar] [CrossRef]
- Peng, J.; Li, L.; Tang, Y.Y. Maximum likelihood estimation-based joint sparse representation for the classification of hyperspectral remote sensing images. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1790–1802. [Google Scholar] [CrossRef]
- Masuyama, N.; Loo, C.K.; Wermter, S. A kernel Bayesian adaptive resonance theory with a topological structure. Int. J. Neural Syst. 2019, 29, 1850052. [Google Scholar] [CrossRef]
- Shi, W.; Li, Y.; Wang, Y. Noise-free maximum correntropy criterion algorithm in non-Gaussian environment. IEEE Trans. Circuits Syst. II Express Briefs 2019. [Google Scholar] [CrossRef]
- Jiang, Z.; Li, Y.; Hunag, X. A correntropy-based proportionate affine projection algorithm for estimating sparse channels with impulsive noise. Entropy 2019, 21, 555. [Google Scholar] [CrossRef]
- He, R.; Zheng, W.-S.; Hu, B.-G. Maximum correntropy criterion for robust face recognition. IEEE Trans. Patt. Anal. Mach. Intell. 2019, 33, 1561–1576. [Google Scholar]
- Macheshwari, S.; Pachori, R.B.; Rajendra, U. Automated diagnosis of glaucoma using empirical wavelet transform and correntropy features extracted from fundus images. IEEE J. Biol. Health Inf. 2017, 21, 803–813. [Google Scholar] [CrossRef]
- Moharmmadi, M.; Noghabi, H.S.; Hodtani, G.A.; Mashhadi, H.R. Robust and stable gene selection via maximum minimum correntropy criterion. Geomics 2016, 107, 83–87. [Google Scholar]
- Guo, C.; Song, B.; Wang, Y.; Chen, H.; Xiong, H. Robust variable selection and estimation based on modal regression. Entropy 2019, 21, 403. [Google Scholar] [CrossRef]
- Luo, X.; Xu, Y.; Wang, W.; Yuan, M.; Ban, X.; Zhu, Y.; Zhao, W. Towards enhancing stacked extreme learning machine with sparse autoencoder by correntropy. J. Frankl. Inst. 2018, 355, 1945–1966. [Google Scholar] [CrossRef]
- Wang, S.; Dang, L.; Wang, W.; Qian, G.; Chi, K.T.S.E. Kernel adaptive filters with feedback based on maximum correntropy. IEEE Access. 2018, 6, 10540–10552. [Google Scholar] [CrossRef]
- Heravi, A.R.; Hodtani, G.A. A new correntropy-based conjugate gradient backpropagation algorithm for improving training in neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 6252–6263. [Google Scholar] [CrossRef]
- Jaeger, H.; Lukosevicious, M.; Popovivi, D.; Siewert, U. Optimization and applications of echo state networks with leaky integrator neurons. Neural Netw. 2007, 20, 335–352. [Google Scholar] [CrossRef]
- Tanaka, G.; Yamane, T.; Heroux, J.B.; Nakane, R.; Kanazawa, N.; Takeda, S.; Numata, H.; Nakano, D.; Hirose, A. Recent advances in physical reservoir computing: A review. Neural Netw. 2019, 115, 100–123. [Google Scholar] [CrossRef]
- Obst, O.; Trinchi, A.; Hardin, S.G.; Chawick, M.; Cole, I.; Muster, T.H.; Hoschke, N.; Ostry, D.; Price, D.; Pham, K.N. Nano-scale reservoir computing. Nano Commun. Netw. 2013, 4, 189–196. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Wang, F.; Chen, B.; Xin, J. Robust echo state network based on correntropy induced loss function. Neurocomputing 2017, 267, 295–303. [Google Scholar] [CrossRef]
- Huang, G.; Chen, L. Convex incremental extreme learning machine. Neurocomputing 2007, 70, 3056–3062. [Google Scholar] [CrossRef]
- Huang, G.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef]
- Tang, J.; Deng, C.; Huang, G. Extreme learning machine for multilayer perceptron. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 809–821. [Google Scholar] [CrossRef]
- Huang, G.; Bai, Z.; Lekamalage, L.; Vong, C.M. Local receptive fields based extreme learning machine. IEEE Comput. Intell. Mag. 2015, 10, 18–29. [Google Scholar] [CrossRef]
- Arabilli, S.F.; Najafi, B.; Alizamir, M.; Mosavi, A.; Shamshirband, S.; Rabczuk, T. Using SVM-RSM and ELM-RSM Approaches for optimizing the production process of Methyl and Ethyl Esters. Energies 2018, 11, 2889. [Google Scholar]
- Ghazvinei, P.T.; Darvishi, H.H.; Mosavi, A.; Yusof, K.b.W.; Alizamir, M.; Shamshirband, S.; Chau, K.-W. Sugarcane growrh prediction based on meteorological parameter using extreme learning machine and artificial neural network. Eng. Appl. Comp. Fluid. 2018, 12, 738–749. [Google Scholar]
- Shamshirband, S.; Chronopoulos, A.T. A new malware delectation system using a high performance ELM method. In Proceedings of the 23rd international database applications & engineering symposium, Athens, Greece, 10–12 June 2019; p. 33. [Google Scholar]
- Bin, G.; Yan, X.; Yang, X.; Gary, W.; Shuyong, L. An intelligent time-adaptive data-driven method for sensor fault diagnosis in induction motor drive system. IEEE Trans. Ind. Electr. 2019, 66, 9817–9827. [Google Scholar]
- Xing, H.; Wang, X. Training extreme learning machine via regularized correntropy criterion. Neural Comput. Appl. 2013, 23, 1977–1986. [Google Scholar] [CrossRef]
- Chen, B.; Wang, X.; Lu, N.; Wang, S.; Cao, J.; Qin, J. Mixture correntropy for robust learning. Pattern Recognit. 2018, 79, 318–327. [Google Scholar] [CrossRef]
- Zeng, N.; Zhang, H.; Liu, W.; Liang, J.; Alsaadi, F.E. A switching delayed PSO optimized extreme learning machine for short-term load forecasting. Neurocomputing 2017, 240, 175–182. [Google Scholar] [CrossRef]
- Weron, A.; Weron, R. Computer simularion of Levy alpha-stable variables and processes. In Lecture Notes in Pihysics; Springer: Berlin/Heidelberg, Germany, 1995; pp. 379–392. [Google Scholar]
- Frank, A.; Asuncion, A. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2010. [Google Scholar]
- Awesome Data. Available online: http://www.awesomedata.com/ (accessed on 16 September 2015).
- Human Development Reports. Available online: http://hdr.undp.org/en/data# (accessed on 15 September 2019).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Range of Ef | c1 | c2 | ||||
|---|---|---|---|---|---|---|---|
| Convergence | 2 | 2 | 0 | 0 | |||
| Exploitation | 2.1 | 1.9 | 0 | ||||
| Exploration | 2.2 | 1.8 | 0 | ||||
| Jumping out | Ef > 0.75 | 1.8 | 2.2 |
| Sample # | ||||
|---|---|---|---|---|
| Sample 1 | 1 | 0 | 0.001 | 0 |
| Sample 2 | 0.7 | 0 | 0.0001 | 0 |
| Sample 3 | 1.2 | 0 | 0.001 | 0 |
| Algorithm | Parameter | Sample 1 | Sample 2 | Sample 3 |
|---|---|---|---|---|
| R-ELM | N | 100 | 100 | 100 |
| 0.00001 | 0.0001 | 0.0001 | ||
| RCC-ELM | N | 100 | 100 | 100 |
| 0.00001 | 0.00001 | 0.00001 | ||
| Ihq | 30 | 30 | 30 | |
| ε | 0.0001 | 0.0001 | 0.0001 | |
| σ | 1 | 1.2 | 1.2 | |
| MMCC-ELM | N | 100 | 100 | 100 |
| λ | 0.00001 | 0.00001 | 0.00001 | |
| Ihq | 30 | 30 | 30 | |
| ε | 0.0001 | 0.0001 | 0.0001 | |
| Σ1 | 2 | 2.2 | 4.3 | |
| Σ2 | 0.8 | 0.8 | 8.5 | |
| 0.8 | 0.8 | 0.9 | ||
| ECC-ELM | N | 100 | 100 | 100 |
| λ | 0.00001 | 0.00001 | 0.00001 | |
| Ihq | 30 | 30 | 30 | |
| ε | 0.0001 | 0.0001 | 0.0001 |
| Samples | ELM | RCC-ELM | MMCC-ELM | ECCC-ELM | ||||
|---|---|---|---|---|---|---|---|---|
| Training MSE | Testing MSE | Training MSE | Testing MSE | Training MSE | Testing MSE | Training MSE | Testing MSE | |
| Sample 1 | 0.336 | 0.6601 | 0.1339 | 0.3505 | 0.7225 | 1.1085 | 0.1415 | 0.3595 |
| Sample 2 | 0.0828 | 0.11 | 0.0507 | 0.0892 | 1.363 | 2.189 | 0.0257 | 0.0576 |
| Sample 3 | 0.2219 | 0.2572 | 0.2076 | 0.2339 | 0.868 | 0.7583 | 0.2046 | 0.2237 |
| Data Set | Features | Observations | |
|---|---|---|---|
| Training Numbers | Testing Numbers | ||
| Servo | 5 | 83 | 83 |
| Slump | 10 | 52 | 51 |
| Concrete | 9 | 515 | 515 |
| Housing | 14 | 253 | 253 |
| Yacht | 6 | 154 | 154 |
| Airfoil | 5 | 751 | 751 |
| Soil moisture | 124 | 340 | 340 |
| HDI | 12 | 93 | 93 |
| HIV | 10 | 65 | 65 |
| Algorithm | Parameter | Servo | Slump | Concrete | Housing | Yacht | Airfoil | Soil Moisture | HDI | HIV |
|---|---|---|---|---|---|---|---|---|---|---|
| R-ELM | N | 90 | 190 | 185 | 180 | 185 | 200 | 200 | 100 | 100 |
| 0.00010000 | 0.00050000 | 0.00020000 | 0.00020000 | 0.00002000 | 0.00002000 | 0.00002000 | 0.00001000 | 0.00001000 | ||
| RCC-ELM | N | 120 | 100 | 200 | 200 | 200 | 180 | 180 | 150 | 120 |
| 0.00001000 | 0.00010000 | 0.00000100 | 0.00010000 | 0.00000001 | 0.00000001 | 0.00000001 | 0.00000001 | 0.00000001 | ||
| Ihq | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | |
| ε | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | |
| σ | 0.00100000 | 0.00001000 | 0.00005000 | 0.01000000 | 0.00000100 | 0.00000100 | 0.00000100 | 0.00000100 | 0.00000130 | |
| MMCC-ELM | N | 90 | 165 | 200 | 200 | 195 | 150 | 150 | 150 | 150 |
| 0.00100000 | 0.00001000 | 0.00005000 | 0.01000000 | 0.00000100 | 0.00000100 | 0.00000100 | 0.00000100 | 0.00000100 | ||
| Ihq | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | |
| ε | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | |
| Σ1 | 0.2 | 0.5 | 0.5 | 0.5 | 0.5 | 0.2 | 1.0 | 1.2 | 0.7 | |
| Σ2 | 2.8 | 1.6 | 2.6 | 2 | 2 | 2.7 | 0.7 | 0.8 | 0.3 | |
| 0.8 | 0.3 | 0.5 | 0.8 | 0.8 | 0.5 | 0.6 | 0.7 | 0.6 | ||
| ECC-ELM | N | 90 | 180 | 180 | 180 | 180 | 200 | 200 | 200 | 200 |
| 0.00100000 | 0.00001000 | 0.00005000 | 0.01000000 | 0.00000100 | 0.00000100 | 0.00000100 | 0.00000100 | 0.00000100 | ||
| Ihq | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | |
| ε | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 | 0.00010000 |
| Data Set | R-ELM | RCC-ELM | MMCC-ELM | ECCC-ELM | ||||
|---|---|---|---|---|---|---|---|---|
| Training RMSE | Testing RMSE | Training RMSE | Testing RMSE | Training RMSE | Testing RMSE | Training RMSE | Testing RMSE | |
| Servo | 0.0590 ± 0.009 | 0.1039 ± 0.0164 | 0.0740 ± 0.0106 | 0.1031 ± 0.0148 | 0.0839 ± 0.0174 | 0.0989 ± 0.0187 | 0.1047 ± 0.0181 | 0.8742 ± 0.0131 |
| Slump | 0.0081 ± 0.0011 | 0.0461 ± 0.0095 | 0.0000 ± 0.0000 | 0.0422 ± 0.0094 | 0.0001 ± 0.0000 | 0.0408 ± 0.0101 | 0.0001 ± 0.0001 | 0.354 ± 0.1890 |
| Concrete | 0.0738 ± 0.0021 | 0.0917 ± 0.0045 | 0.0561 ± 0.0018 | 0.0872 ± 0.0066 | 0.0560 ± 0.0021 | 0.0867 ± 0.0064 | 0.0561 ± 0.0018 | 0.0852 ± 0.0053 |
| Housing | 0.0439 ± 0.0043 | 0.0896 ± 0.0124 | 0.0495 ± 0.0045 | 0.0830 ± 0.0110 | 0.0554 ± 0.0045 | 0.0821 ± 0.0101 | 0.0352 ± 0.0013 | 0.0791 ± 0.0110 |
| Yacht | 0.0366 ± 0.0093 | 0.0529 ± 0.0090 | 0.0125 ± 0.0008 | 0.0349 ± 0.0113 | 0.0125 ± 0.0008 | 0.0328 ± 0.0074 | 0.0172 ± 0.0027 | 0.0268 ± 0.0031 |
| Airfoil | 0.0974 ± 0.0074 | 0.1031 ± 0.0077 | 0.0736 ± 0.0022 | 0.0906 ± 0.0054 | 0.0736 ± 0.0025 | 0.0898 ± 0.0051 | 0.0736 ± 0.0023 | 0.0889 ± 0.0046 |
| Soil moisture | 0.0032 ± 0.0011 | 0.0095 ± 0.0013 | 0.0007 ± 0.0001 | 0.0015 ± 0.0003 | 0.0006 ± 0.0000 | 0.0012 ± 0.0002 | 0.0006 ± 0.0000 | 0.0009 ± 0.0001 |
| HDI | 0.0004 ± 0.0001 | 0.0006 ± 0.0002 | 0.0001 ± 0.0000 | 0.0003 ± 0.0001 | 0.0001 ± 0.0000 | 0.0003 ± 0.0001 | 0.0001 ± 0.0000 | 0.0003 ± 0.0001 |
| HIV | 0.0376 ± 0.0220 | 0.0599 ± 0.0130 | 0.0050 ± 0.0017 | 0.0079 ± 0.0009 | 0.0047 ± 0.0006 | 0.0065 ± 0.0004 | 0.0059 ± 0.0007 | 0.0059 ± 0.0006 |
| Time (year) | Actual CTR | Predicted CTR | Normalized Error | Predicting Time (ms) |
|---|---|---|---|---|
| 1 | 87.90 | 88.03 | 0.0037 | 2.98 |
| 2 | 87.70 | 88.01 | 0.0068 | 4.02 |
| 3 | 87.40 | 87.94 | 0.0274 | 3.92 |
| 4 | 85.50 | 87.15 | 0.0095 | 4.98 |
| 5 | 86.30 | 87.02 | 0.0122 | 2.26 |
| 6 | 85.93 | 86.61 | 0.0084 | 3.22 |
| 7 | 85.86 | 85.40 | 0.0188 | 5.74 |
| 8 | 84.73 | 85.30 | 0.0145 | 4.48 |
| 9 | 84.01 | 84.33 | 0.0115 | 5.85 |
| 10 | 83.31 | 83.38 | 0.0023 | 4.87 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mei, W.; Liu, Z.; Su, Y.; Du, L.; Huang, J. Evolved-Cooperative Correntropy-Based Extreme Learning Machine for Robust Prediction. Entropy 2019, 21, 912. https://doi.org/10.3390/e21090912
Mei W, Liu Z, Su Y, Du L, Huang J. Evolved-Cooperative Correntropy-Based Extreme Learning Machine for Robust Prediction. Entropy. 2019; 21(9):912. https://doi.org/10.3390/e21090912
Chicago/Turabian StyleMei, Wenjuan, Zhen Liu, Yuanzhang Su, Li Du, and Jianguo Huang. 2019. "Evolved-Cooperative Correntropy-Based Extreme Learning Machine for Robust Prediction" Entropy 21, no. 9: 912. https://doi.org/10.3390/e21090912
APA StyleMei, W., Liu, Z., Su, Y., Du, L., & Huang, J. (2019). Evolved-Cooperative Correntropy-Based Extreme Learning Machine for Robust Prediction. Entropy, 21(9), 912. https://doi.org/10.3390/e21090912