A Standardized Project Gutenberg Corpus for Statistical Analysis of Natural Language and Quantitative Linguistics



Abstract
:1. Introduction
2. Results
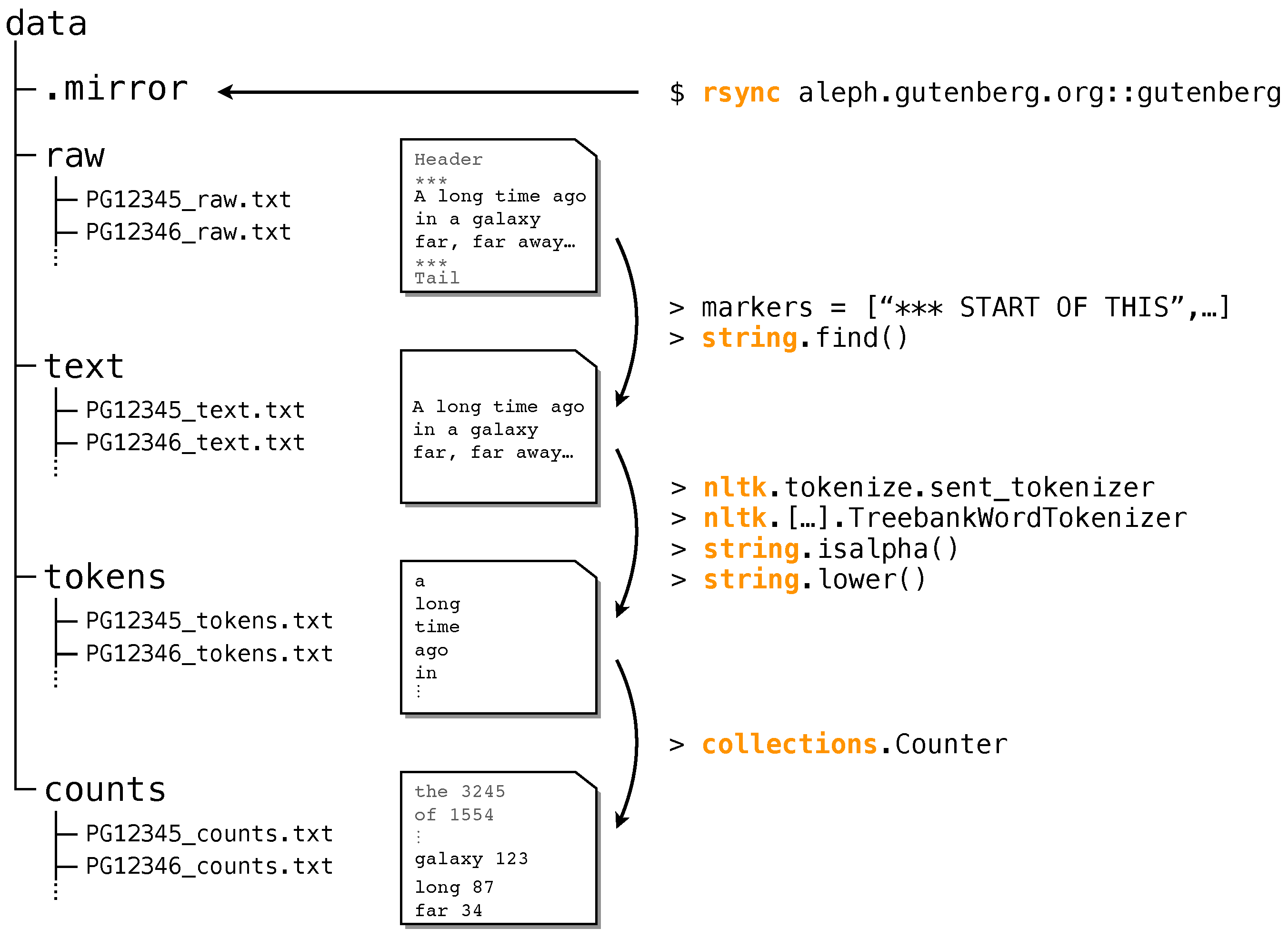
2.1. Data Acquisition
2.2. Data Processing
- Raw data: We download all books and save them according to their PG-ID. We eliminate duplicated entries and entries not in UTF-8 encoding.
- Text data: We remove all headers and boiler plate text, see Methods for details.
- Token data: We tokenize the text data using the tokenizer from NLTK [51]. This yields a time series of tokens without punctuation, etc.
- Count data: We count the number of occurrences of each word-type. This yields a list of tuples (w,), where w is word-type w and is the number of occurrences.
2.3. Data Description
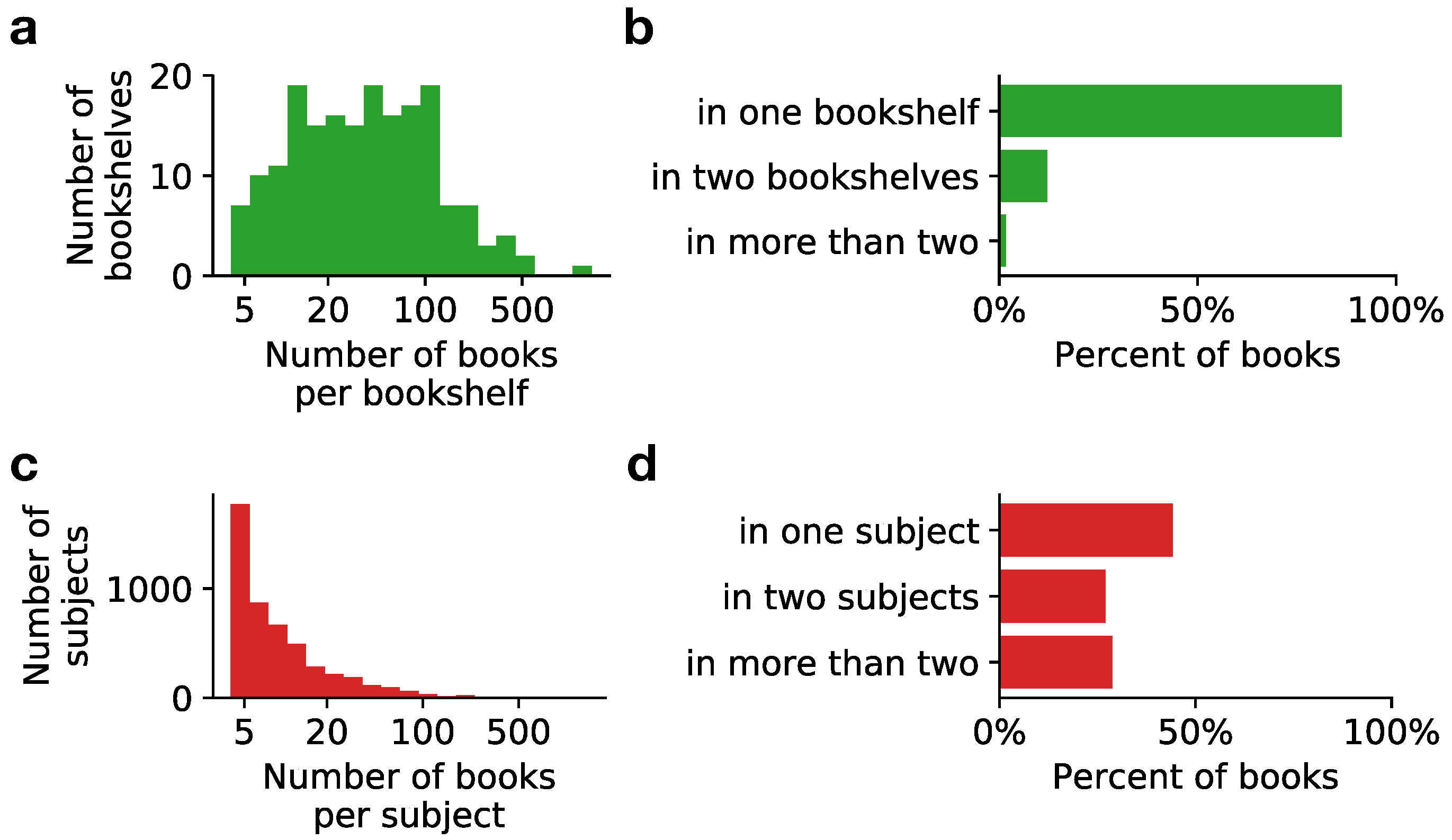
2.4. Quantifying Variability in the Corpus
2.4.1. Labels
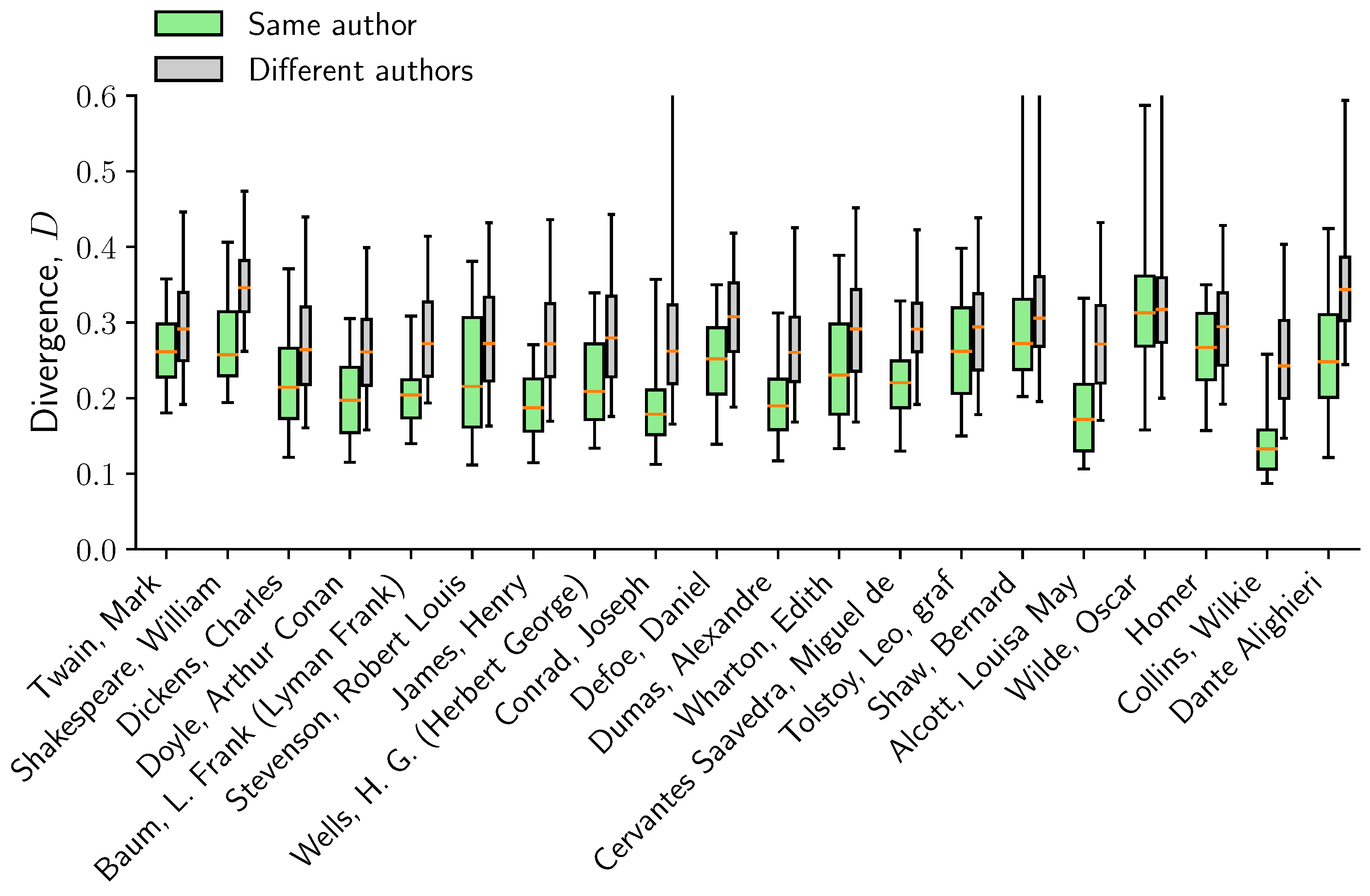
2.4.2. Authors
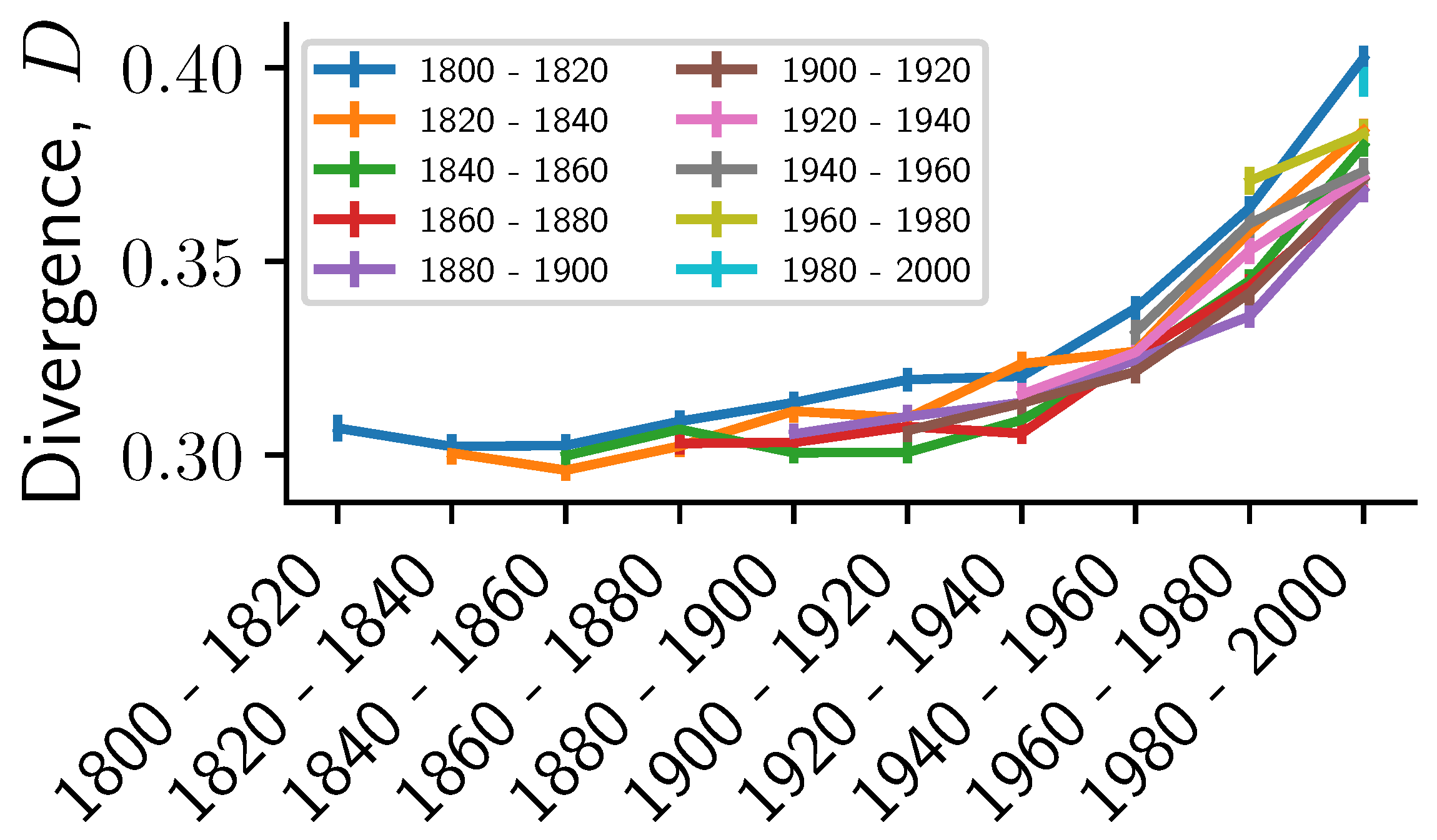
2.4.3. Time
3. Discussion
4. Materials and Methods
4.1. Running the Code
4.2. Preprocessing
4.3. Jensen–Shannon Divergence
4.4. 2-Dimensional Embedding
4.5. Data Availability
4.6. Computational Requirements
4.7. Code Availability
Author Contributions
Funding
Conflicts of Interest
References
- Altmann, E.G.; Gerlach, M. Statistical laws in linguistics. In Creativity and Universality in Language; Degli Esposti, M., Altmann, E.G., Pachet, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 7–26. [Google Scholar]
- Ferrer i Cancho, R.; Solé, R.V. Least effort and the origins of scaling in human language. Proc. Natl. Acad. Sci. USA 2003, 100, 788–791. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Petersen, A.M.; Tenenbaum, J.N.; Havlin, S.; Stanley, H.E.; Perc, M. Languages cool as they expand: Allometric scaling and the decreasing need for new words. Sci. Rep. 2012, 2, 943. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tria, F.; Loreto, V.; Servedio, V.D.P.; Strogatz, S.H. The dynamics of correlated novelties. Sci. Rep. 2014, 4, 5890. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Corominas-Murtra, B.; Hanel, R.; Thurner, S. Understanding scaling through history-dependent processes with collapsing sample space. Proc. Natl. Acad. Sci. USA 2015, 112, 5348–5353. [Google Scholar] [CrossRef] [Green Version]
- Font-Clos, F.; Corral, A. Log-log convexity of type-token growth in Zipf’s systems. Phys. Rev. Lett. 2015, 114, 238701. [Google Scholar] [CrossRef] [Green Version]
- Cocho, G.; Flores, J.; Gershenson, C.; Pineda, C.; Sánchez, S. Rank Diversity of Languages: Generic Behavior in Computational Linguistics. PLoS ONE 2015, 10, e0121898. [Google Scholar] [CrossRef] [Green Version]
- Lippi, M.; Montemurro, M.A.; Degli Esposti, M.; Cristadoro, G. Natural Language Statistical Features of LSTM-Generated Texts. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3326–3337. [Google Scholar] [CrossRef]
- Mazzolini, A.; Gherardi, M.; Caselle, M.; Cosentino Lagomarsino, M.; Osella, M. Statistics of shared components in complex component systems. Phys. Rev. X 2018, 8, 021023. [Google Scholar] [CrossRef] [Green Version]
- Dorogovtsev, S.N.; Mendes, J.F. Language as an evolving word web. Proc. R. Soc. B 2001, 268, 2603–2606. [Google Scholar] [CrossRef] [Green Version]
- Solé, R.V.; Corominas-Murtra, B.; Valverde, S.; Steels, L. Language networks: Their structure, function, and evolution. Complexity 2010, 15, 20–26. [Google Scholar] [CrossRef]
- Amancio, D.R.; Altmann, E.G.; Oliveira, O.N.; Costa, L.D.F. Comparing intermittency and network measurements of words and their dependence on authorship. New J. Phys. 2011, 13, 123024. [Google Scholar] [CrossRef]
- Choudhury, M.; Chatterjee, D.; Mukherjee, A. Global topology of word co-occurrence networks: Beyond the two-regime power-law. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Beijing, China, 23–27 August 2010; pp. 162–170. [Google Scholar]
- Cong, J.; Liu, H. Approaching human language with complex networks. Phys. Life Rev. 2014, 11, 598–618. [Google Scholar] [CrossRef] [PubMed]
- Bochkarev, V.; Solovyev, V.; Wichmann, S. Universals versus historical contingencies in lexical evolution. J. R. Soc. Interface 2014, 11, 20140841. [Google Scholar] [CrossRef] [PubMed]
- Ghanbarnejad, F.; Gerlach, M.; Miotto, J.M.; Altmann, E.G. Extracting information from S-curves of language change. J. R. Soc. Interface 2014, 11, 20141044. [Google Scholar] [CrossRef] [PubMed]
- Feltgen, Q.; Fagard, B.; Nadal, J.P. Frequency patterns of semantic change: Corpus-based evidence of a near-critical dynamics in language change. R. Soc. Open Sci. 2017, 4, 170830. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gonçalves, B.; Loureiro-Porto, L.; Ramasco, J.J.; Sánchez, D. Mapping the Americanization of English in space and time. PLoS ONE 2018, 13, e0197741. [Google Scholar] [CrossRef] [Green Version]
- Amato, R.; Lacasa, L.; Díaz-Guilera, A.; Baronchelli, A. The dynamics of norm change in the cultural evolution of language. Proc. Natl. Acad. Sci. USA 2018, 115, 8260–8265. [Google Scholar] [CrossRef] [Green Version]
- Karjus, A.; Blythe, R.A.; Kirby, S.; Smith, K. Challenges in detecting evolutionary forces in language change using diachronic corpora. arXiv 2018, arXiv:1811.01275. [Google Scholar]
- Montemurro, M.A.; Zanette, D.H. Towards the quantification of the semantic information encoded in written language. Adv. Complex Syst. 2010, 13, 135. [Google Scholar] [CrossRef]
- Takahira, R.; Tanaka-Ishii, K.; Debowski, Ł. Entropy rate estimates for natural language—A new extrapolation of compressed large-scale corpora. Entropy 2016, 18, 364. [Google Scholar] [CrossRef] [Green Version]
- Febres, G.; Jaffé, K. Quantifying structure differences in literature using symbolic diversity and entropy criteria. J. Quant. Linguist. 2017, 24, 16–53. [Google Scholar] [CrossRef] [Green Version]
- Bentz, C.; Alikaniotis, D.; Cysouw, M.; Ferrer-i Cancho, R. The entropy of words—Learnability and expressivity across more than 1000 languages. Entropy 2017, 19, 275. [Google Scholar] [CrossRef] [Green Version]
- Ferrer i Cancho, R.; Solé, R.; Köhler, R. Patterns in syntactic dependency networks. Phys. Rev. E 2004, 69, 51915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kulig, A.; Kwapień, J.; Stanisz, T.; Drożdż, S. In narrative texts punctuation marks obey the same statistics as words. Inf. Sci. 2016, 375, 98–113. [Google Scholar] [CrossRef] [Green Version]
- Michel, J.B.; Shen, Y.K.; Aiden, A.P.; Veres, A.; Gray, M.K.; Team, T.G.B.; Pickett, J.P.; Hoiberg, D.; Clancy, D.; Norvig, P.; et al. Quantitative analysis of culture using millions of digitized books. Science 2011, 331, 176–182. [Google Scholar] [CrossRef] [Green Version]
- Masucci, A.P.; Kalampokis, A.; Eguíluz, V.M.; Hernández-García, E. Wikipedia information flow analysis reveals the scale-free architecture of the semantic space. PLoS ONE 2011, 6, e17333. [Google Scholar] [CrossRef] [Green Version]
- Yasseri, T.; Kornai, A.; Kertész, J. A practical approach to language complexity: A Wikipedia case study. PLoS ONE 2012, 7, e48386. [Google Scholar] [CrossRef] [Green Version]
- Dodds, P.S.; Harris, K.D.; Kloumann, I.M.; Bliss, C.A.; Danforth, C.M. Temporal patterns of happiness and information in a global social network: Hedonometrics and twitter. PLoS ONE 2011, 6, e26752. [Google Scholar] [CrossRef]
- Morse-Gagné, E.E. Culturomics: Statistical traps muddy the data. Science 2011, 332, 35. [Google Scholar] [CrossRef]
- Pechenick, E.A.; Danforth, C.M.; Dodds, P.S. Characterizing the Google Books corpus: Strong limits to inferences of socio-cultural and linguistic evolution. PLoS ONE 2015, 10, e0137041. [Google Scholar] [CrossRef]
- Hart, M. Project Gutenberg. 1971. Available online: https://www.gutenberg.org (accessed on 18 July 2018).
- Ebeling, W.; Pöschel, T. Entropy and long-range correlations in literary English. Europhys. Lett. 1994, 26, 241–246. [Google Scholar] [CrossRef] [Green Version]
- Schurmann, T.; Grassberger, P. Entropy estimation of symbol sequences. Chaos 1996, 6, 414–427. [Google Scholar] [CrossRef]
- Baayen, R.H.H. The effects of lexical specialization on the growth curve of the vocabulary. Comput. Linguist. 1996, 22, 455–480. [Google Scholar]
- Altmann, E.G.; Cristadoro, G.; Esposti, M.D. On the origin of long-range correlations in texts. Proc. Natl. Acad. Sci. USA 2012, 109, 11582–11587. [Google Scholar] [CrossRef] [Green Version]
- Moreno-Sánchez, I.; Font-Clos, F.; Corral, Á. Large-scale analysis of Zipf’s law in English texts. PLoS ONE 2016, 11, e0147073. [Google Scholar] [CrossRef]
- Williams, J.R.; Bagrow, J.P.; Danforth, C.M.; Dodds, P.S. Text mixing shapes the anatomy of rank-frequency distributions. Phys. Rev. E 2015, 91, 052811. [Google Scholar] [CrossRef] [Green Version]
- Tria, F.; Loreto, V.; Servedio, V. Zipf’s, Heaps’ and Taylor’s Laws are determined by the expansion into the adjacent possible. Entropy 2018, 20, 752. [Google Scholar] [CrossRef] [Green Version]
- Hughes, J.M.; Foti, N.J.; Krakauer, D.C.; Rockmore, D.N. Quantitative patterns of stylistic influence in the evolution of literature. Proc. Natl. Acad. Sci. USA 2012, 109, 7682–7686. [Google Scholar] [CrossRef] [Green Version]
- Reagan, A.J.; Mitchell, L.; Kiley, D.; Danforth, C.M.; Dodds, P.S. The emotional arcs of stories are dominated by six basic shapes. EPJ Data Sci. 2016, 5, 31. [Google Scholar] [CrossRef] [Green Version]
- Ferrer i Cancho, R. The variation of Zipf’s law in human language. Eur. Phys. J. B - Condens. Matter Complex Syst. 2005, 44, 249–257. [Google Scholar] [CrossRef]
- Ferrer i Cancho, R.; Solé, R.V. Two Regimes in the Frequency of Words and the Origins of Complex Lexicons: Zipf’s Law Revisited. J. Quant. Linguist. 2001, 8, 165–173. [Google Scholar] [CrossRef] [Green Version]
- Dheeru, D.; Karra Taniskidou, E. UCI Machine Learning Repository. 2017. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 18 July 2018).
- Davies, M. The Corpus of Contemporary American English (COCA): 560 Million Words, 1990-Present. 2008. Available online: https://www.english-corpora.org/coca/ (accessed on 18 July 2018).
- Leech, G. 100 million words of English. Engl. Today 1993, 9, 9–15. [Google Scholar] [CrossRef]
- Biber, D.; Reppen, R. The Cambridge Handbook of English Corpus Linguistics; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Jones, C.; Waller, D. Corpus Linguistics for Grammar: A guide for research; Routledge: Abingdon, UK, 2015. [Google Scholar]
- Cattuto, C.; Loreto, V.; Pietronero, L. Semiotic dynamics and collaborative tagging. Proc. Natl. Acad. Sci. USA 2007, 104, 1461–1464. [Google Scholar] [CrossRef] [Green Version]
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. In Proceedings of the ACL-02 Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; Volume 1, pp. 63–70, ETMTNLP’02. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Gerlach, M.; Font-Clos, F.; Altmann, E.G. Similarity of symbol frequency distributions with heavy tails. Phys. Rev. X 2016, 6, 021009. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J. UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Juola, P. Authorship attribution. Found. Trends® Inf. Retr. 2008, 1, 233–334. [Google Scholar] [CrossRef]
- Stamatatos, E. A survey of modern authorship attribution methods. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 538–556. [Google Scholar] [CrossRef] [Green Version]
- Ioannidis, J.P.A. Why most published research findings are false. PLoS Med. 2005, 2, e124. [Google Scholar] [CrossRef] [Green Version]
- Open Science Collaboration. Estimating the reproducibility of psychological science. Science 2015, 349, aac4716. [Google Scholar] [CrossRef] [Green Version]
- Camerer, C.F.; Dreber, A.; Holzmeister, F.; Ho, T.H.; Huber, J.; Johannesson, M.; Kirchler, M.; Nave, G.; Nosek, B.A.; Pfeiffer, T.; et al. Evaluating the replicability of social science experiments in Nature and Science between 2010 and 2015. Nat. Hum. Behav. 2018, 2, 637–644. [Google Scholar] [CrossRef] [Green Version]
- Yucesoy, B.; Wang, X.; Huang, J.; Barabási, A.L. Success in books: A big data approach to bestsellers. EPJ Data Sci. 2018, 7, 7. [Google Scholar] [CrossRef] [Green Version]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef] [Green Version]
- Grosse, I.; Bernaola-Galván, P.; Carpena, P.; Román-Roldán, R.; Oliver, J.; Stanley, H.E. Analysis of symbolic sequences using the Jensen–Shannon divergence. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 2002, 65, 041905. [Google Scholar] [CrossRef] [PubMed] [Green Version]







{kind=link}
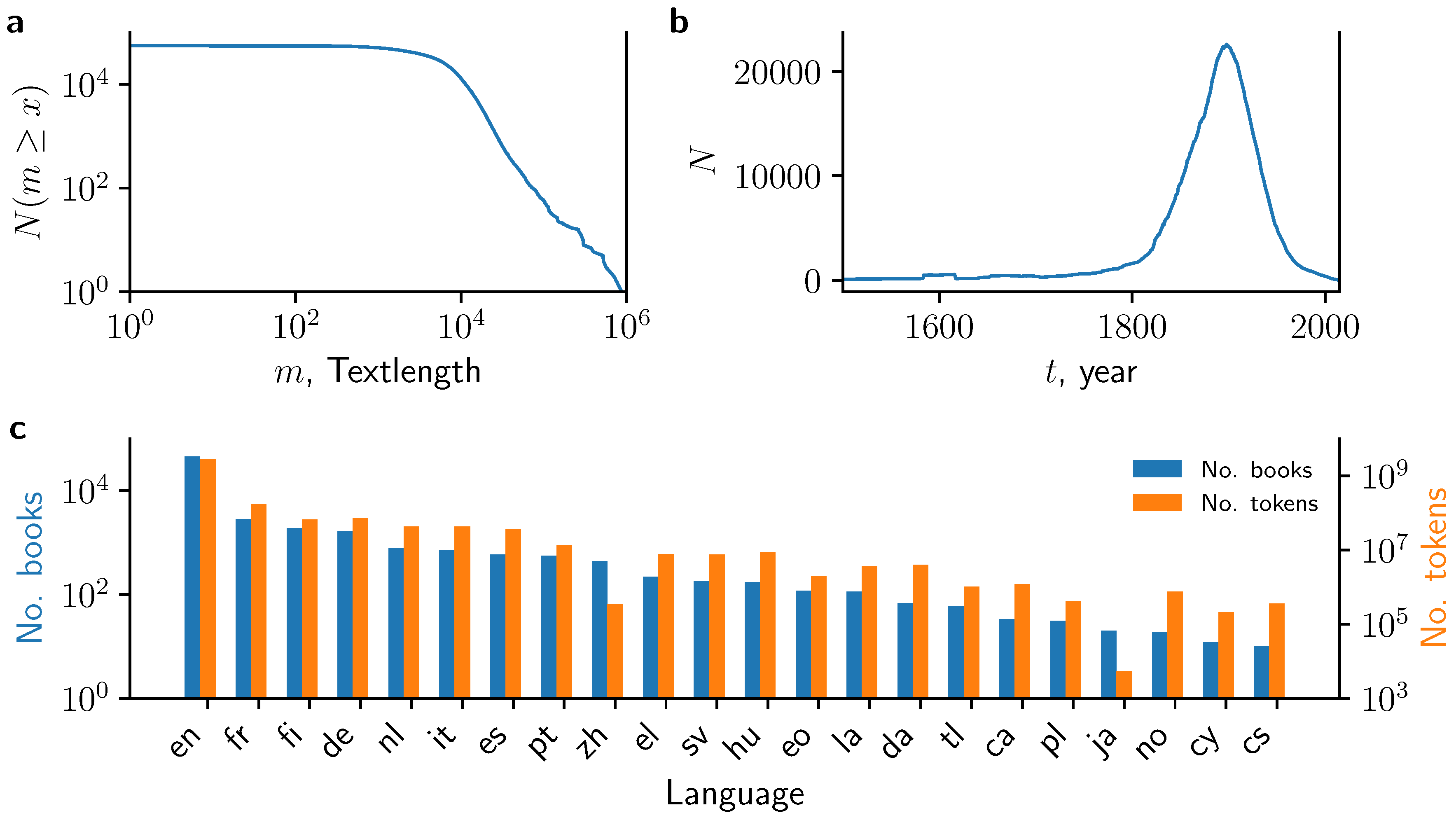{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Books | Bookshelf | Rank | Books | Subject |
|---|---|---|---|---|---|
| 1 | 1341 | Science Fiction | 1 | 2006 | Fiction |
| 2 | 509 | Children’s Book Series | 2 | 1823 | Short stories |
| 3 | 493 | Punch | 3 | 1647 | Science fiction |
| 4 | 426 | Bestsellers, American, 1895-1923 | 3 | 1647 | Science fiction |
| 5 | 383 | Historical Fiction | 5 | 746 | Historical fiction |
| 6 | 374 | World War I | 6 | 708 | Love stories |
| 7 | 339 | Children’s Fiction | 7 | 690 | Poetry |
| … | … | … | … | … | … |
| 47 | 94 | Slavery | 47 | 190 | Short stories, American |
| 48 | 92 | Western | 48 | 188 | Science – Periodicals |
| 49 | 90 | Judaism | 49 | 183 | American poetry |
| 50 | 86 | Scientific American | 50 | 180 | Drama |
| 51 | 84 | Pirates, Buccaneers, Corsairs, etc. | 51 | 165 | Paris (France) – Fiction |
| 52 | 83 | Astounding Stories | 52 | 163 | Fantasy literature |
| 53 | 83 | Harper’s Young People | 53 | 162 | Orphans – Fiction |
| … | … | … | … | … | … |
| 97 | 37 | Animals-Wild-Reptiles and Amphibians | 97 | 100 | Scotland – Periodicals |
| 98 | 37 | Short Stories | 98 | 98 | Horror tales |
| 99 | 36 | Continental Monthly | 99 | 97 | Canada – Fiction |
| 100 | 35 | Architecture | 100 | 97 | France – Court and courtiers |
| 101 | 35 | Bahá’í Faith | 101 | 96 | Social classes – Fiction |
| 102 | 34 | Precursors of Science Fiction | 102 | 95 | Courtship – Fiction |
| 103 | 33 | Physics | 103 | 95 | Seafaring life – Juvenile fiction |
| … | … | … | … | … | … |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gerlach, M.; Font-Clos, F. A Standardized Project Gutenberg Corpus for Statistical Analysis of Natural Language and Quantitative Linguistics. Entropy 2020, 22, 126. https://doi.org/10.3390/e22010126
Gerlach M, Font-Clos F. A Standardized Project Gutenberg Corpus for Statistical Analysis of Natural Language and Quantitative Linguistics. Entropy. 2020; 22(1):126. https://doi.org/10.3390/e22010126
Chicago/Turabian StyleGerlach, Martin, and Francesc Font-Clos. 2020. "A Standardized Project Gutenberg Corpus for Statistical Analysis of Natural Language and Quantitative Linguistics" Entropy 22, no. 1: 126. https://doi.org/10.3390/e22010126
APA StyleGerlach, M., & Font-Clos, F. (2020). A Standardized Project Gutenberg Corpus for Statistical Analysis of Natural Language and Quantitative Linguistics. Entropy, 22(1), 126. https://doi.org/10.3390/e22010126