A Dynamic DNA Color Image Encryption Method Based on SHA-512




Abstract
:1. Introduction
2. Materials and Methods
2.1. Lorenz System
2.2. Four-Wing System
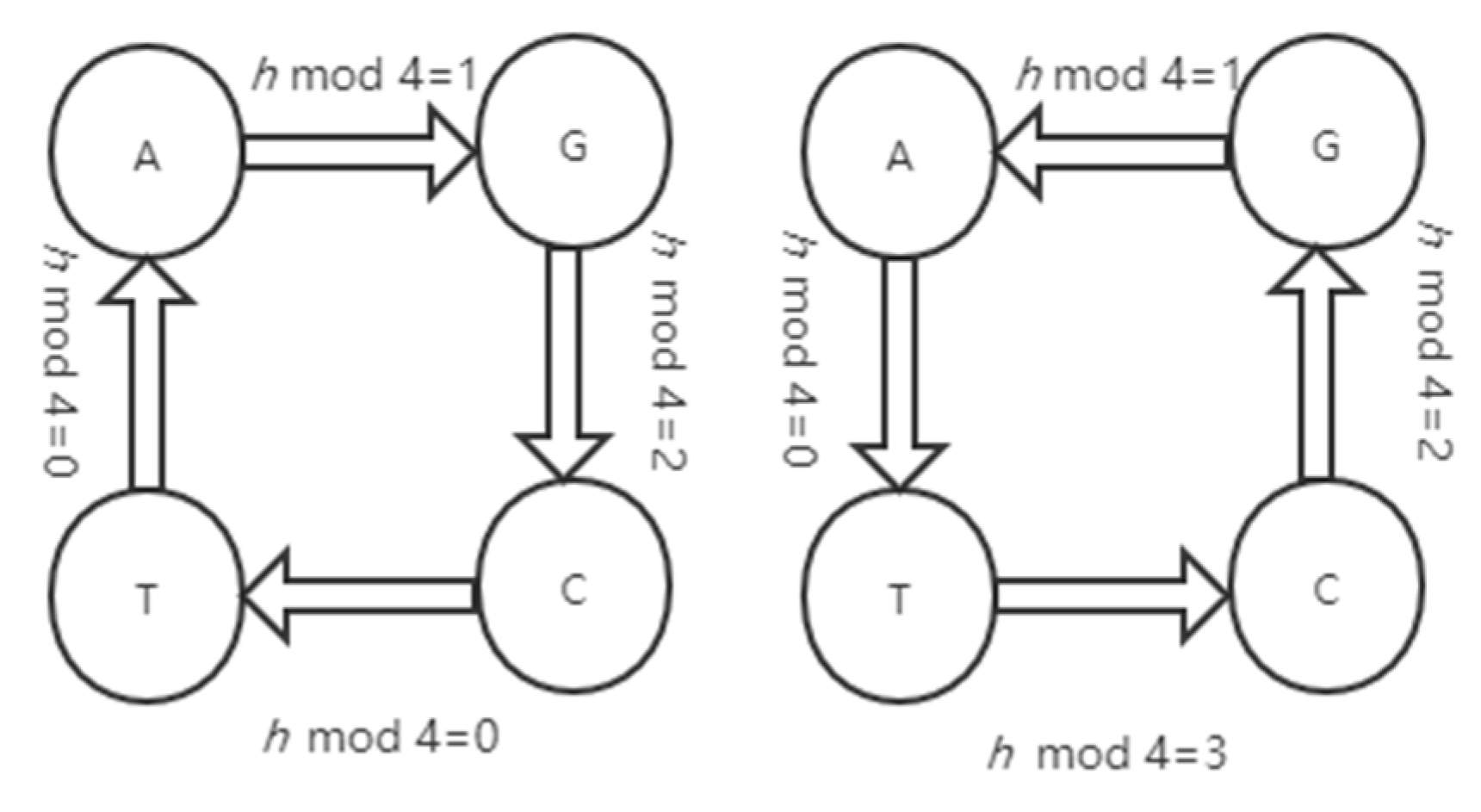
2.3. DNA Coding and Decoding Rule
2.4. DNA Complementary Rules
2.5. DNA Cycle Operation
2.6. Mandelbrot Set
2.7. 2D-RT
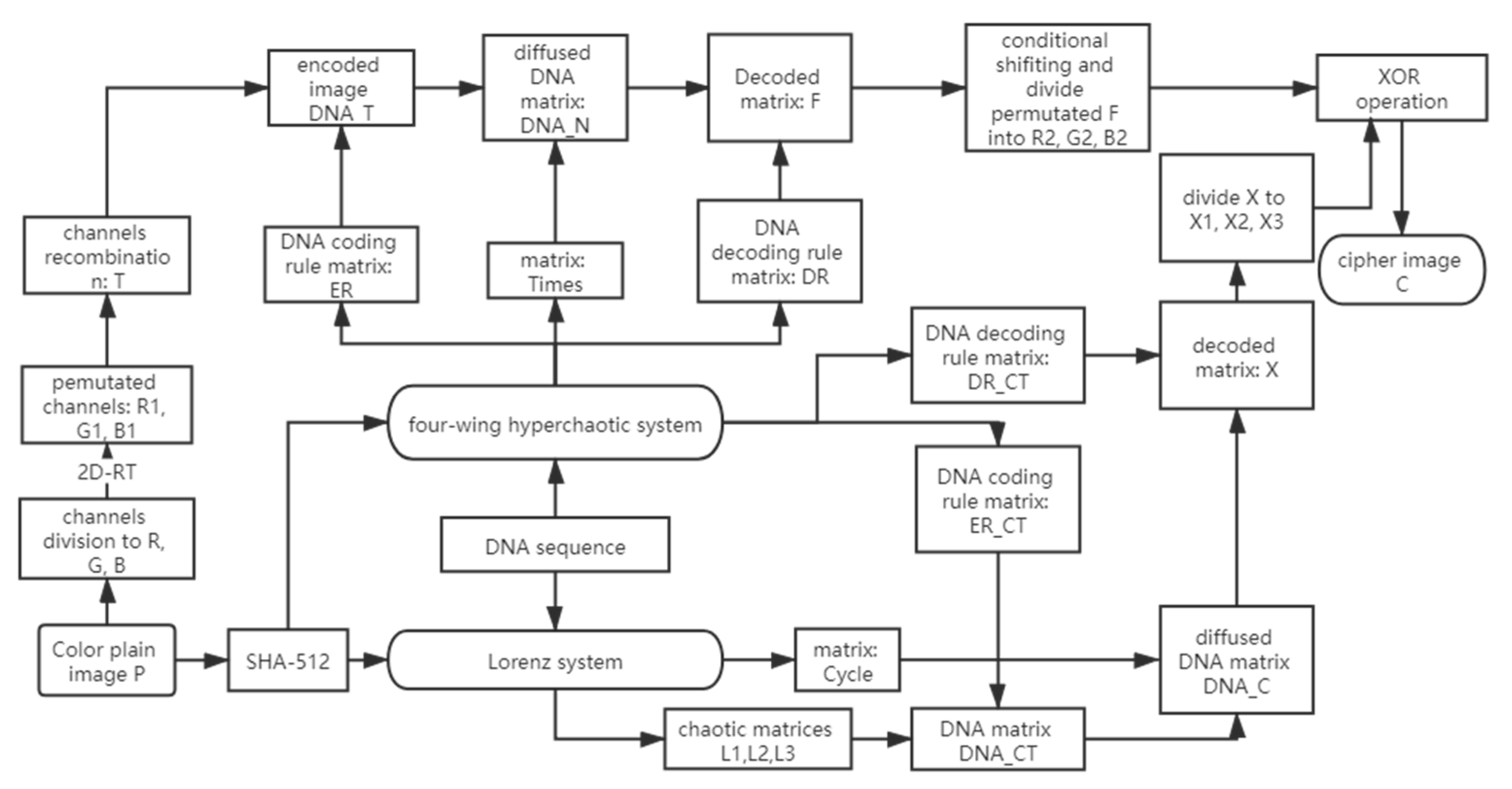
3. Proposed Encryption Scheme
3.1. Initial Values and Intermittent Parameters
3.2. Conditional Shifting Operation
| Algorithm 1: The Conditional Shifting Operation |
| Input: Mandelbrot set M and the channels R2, G2, and B2. |
|
3.3. Whole Image Encryption Process
3.3.1. First Round of Permutation
3.3.2. Process of DNA Encoding
3.4. Diffusion and DNA Decoding
3.5. Second Round of Permutation and Diffusion
4. Stimulation Results and Security Analysis
4.1. Stimulation Results
4.2. Key Space Analysis
4.3. Key Sensitivity Results
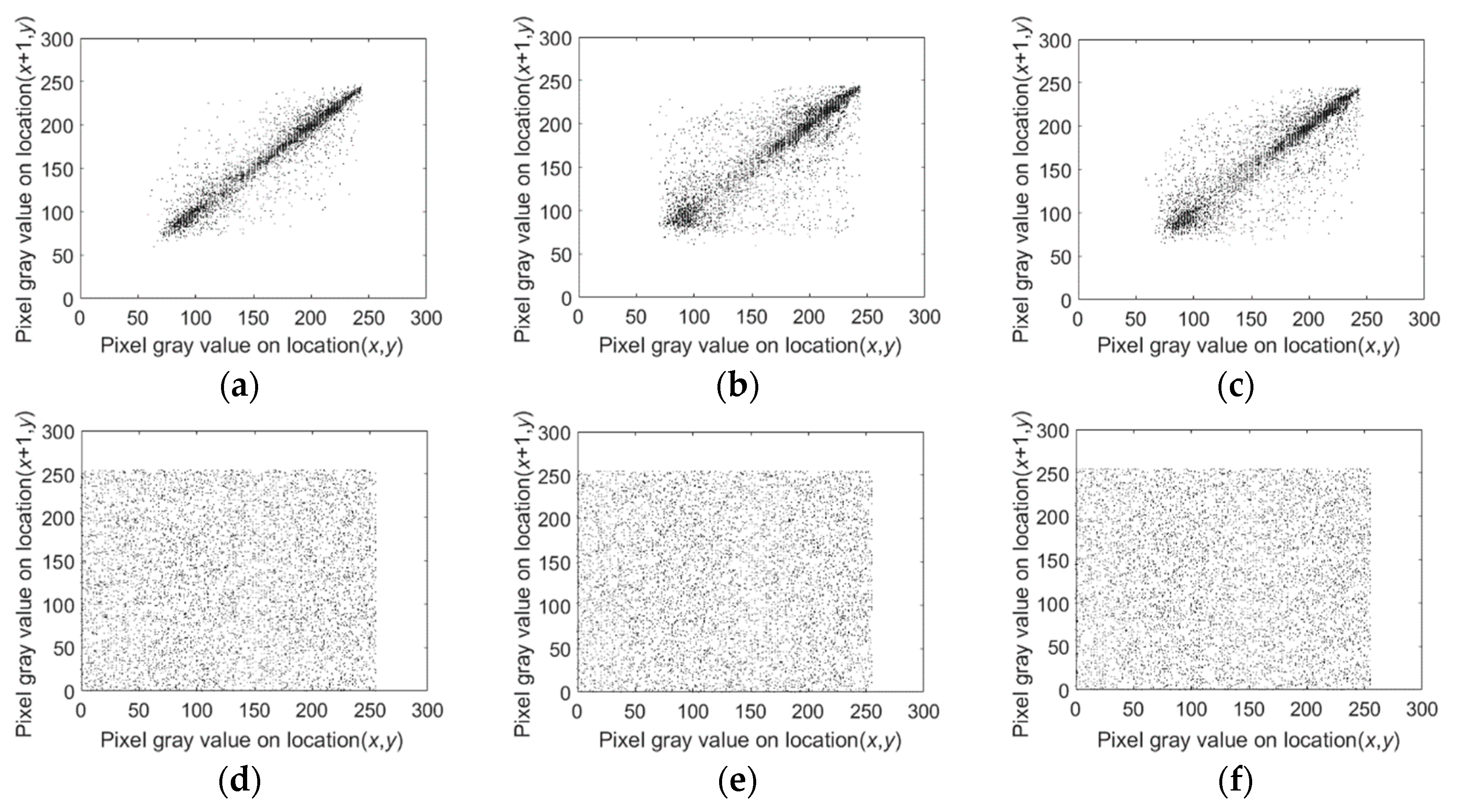
4.4. Correlation Analysis
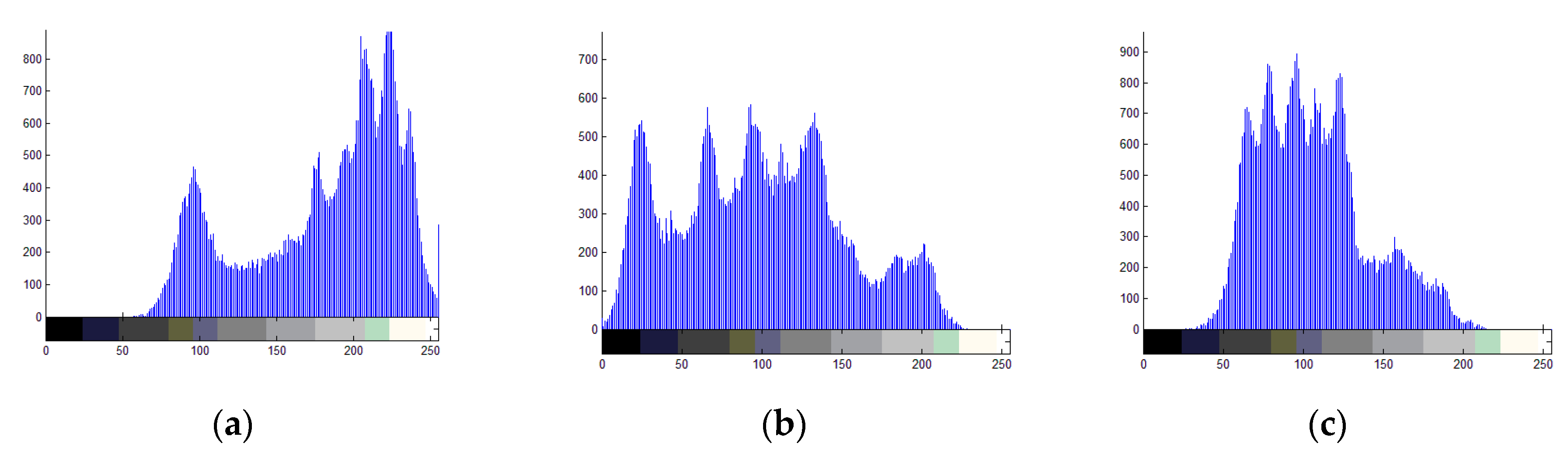
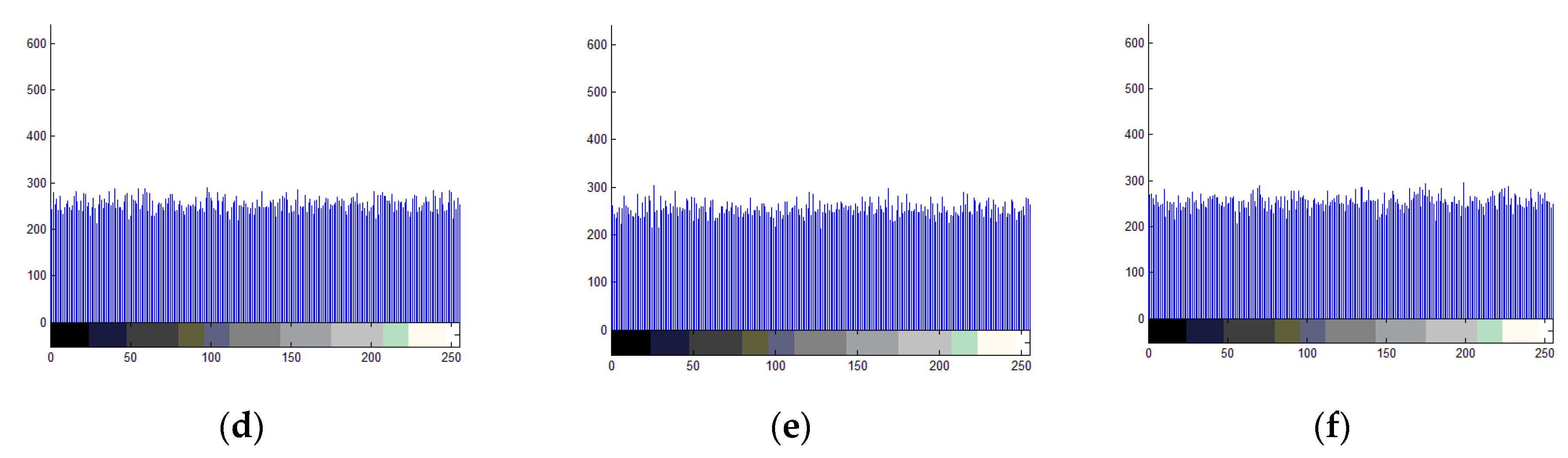
4.5. Histogram Analysis
4.6. Information Entropy Analysis
4.7. Differential Attacks and Chosen Plaintext Attack
4.8. Noise and Occlusion Attack Analysis
4.9. Resistance to Some Typical Attacks
4.10. Contrast Investigation
4.11. Energy
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Huang, H.; He, X.; Xiang, Y.; Wen, W.; Zhang, Y. A compression-diffusion-permutation strategy for securing image. Signal Process. 2018, 150, 183–190. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, Q.; Wei, X. Tabu variable neighborhood search for designing DNA barcodes. IEEE Trans. NanoBiosci. 2020, 19, 127–131. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wang, B.; Lv, H.; Yin, Q.; Zhang, Q.; Wei, X. Constraining DNA Sequences With a Triplet-Bases Unpaired. IEEE Trans. NanoBiosci. 2020, 19, 299–307. [Google Scholar] [CrossRef] [PubMed]
- Hu, T.; Ouyang, C.-J.; Liu, Y.; Gong, L.-H. An image encryption scheme combining chaos with cycle operation for DNA sequences. Nonlinear Dyn. 2016, 87, 51–66. [Google Scholar] [CrossRef]
- Chai, X.; Chen, Y.; Broyde, L. A novel chaos-based image encryption algorithm using DNA sequence operations. Opt. Lasers Eng. 2017, 88, 197–213. [Google Scholar] [CrossRef]
- Liu, H.; Zhao, B.; Huang, L. Aremote-sensing image encryption scheme using dna bases probability and two-dimensional logistic map. IEEE Access 2019, 7, 65450–65459. [Google Scholar] [CrossRef]
- Enayatifar, R.; Guimarães, F.G.; Siarry, P. Index-based permutation-diffusion in multiple-image encryption using DNA sequence. Opt. Lasers Eng. 2019, 115, 131–140. [Google Scholar] [CrossRef]
- Belazi, A.; Talha, M.; Kharbech, S.; Xiang, W. Novel Medical Image Encryption Scheme Based on Chaos and DNA Encoding. IEEE Access 2019, 7, 36667–36681. [Google Scholar] [CrossRef]
- Huo, D.; Zhou, D.-F.; Yuan, S.; Yi, S.; Zhang, L.; Zhou, X. Image encryption using exclusive-OR with DNA complementary rules and double random phase encoding. Phys. Lett. A 2019, 383, 915–922. [Google Scholar] [CrossRef]
- Revathy, K.; Thenmozhi, K.; Amirtharajan, R.; Praveenkumar, P. CR Assisted IE Guarded Authenticated Biomedical Image Transactions. IEEE Photon. J. 2018, 10, 1–13. [Google Scholar] [CrossRef]
- Wang, X.; Hou, Y.; Wang, S.-B.; Li, R. A New Image Encryption Algorithm Based on CML and DNA Sequence. IEEE Access 2018, 6, 62272–62285. [Google Scholar] [CrossRef]
- Chen, J.-X.; Zhu, Z.-L.; Zhang, L.-B.; Zhang, Y.; Yang, B.-Q. Exploiting self-adaptive permutation–diffusion and DNA random encoding for secure and efficient image encryption. Signal Process. 2018, 142, 340–353. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, C.; Wang, J.; Hu, Y. A Color Image Encryption Using Dynamic DNA and 4-D Memristive Hyper-Chaos. IEEE Access 2019, 7, 78367–78378. [Google Scholar] [CrossRef]
- Banu, S.A.; Amirtharajan, R. A robust medical image encryption in dual domain: Chaos-DNA-IWT combined approach. Med Biol. Eng. 2020, 58, 1445–1458. [Google Scholar] [CrossRef] [PubMed]
- Ballesteros, D.M.; Peña, J.; Renza, D. A Novel Image Encryption Scheme Based on Collatz Conjecture. Entropy 2018, 20, 901. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, X.; Luo, Y.; Liu, J.; Cao, L.; Liu, Y. A color image encryption method based on memristive hyperchaotic system and DNA encryption. Int. J. Mod. Phys. B 2020, 34, 2050014. [Google Scholar] [CrossRef]
- Zhu, X.; Liu, H.; Liang, Y.; Wu, J. Image encryption based on Kronecker product over finite fields and DNA operation. Optik 2020, 164725. [Google Scholar] [CrossRef]
- Zhu, S.; Zhu, C. Secure Image Encryption Algorithm Based on Hyperchaos and Dynamic DNA Coding. Entropy 2020, 22, 772. [Google Scholar] [CrossRef]
- Zhan, K.; Jiang, W. Novel four-wing hyper-chaos system and its application in image encryption. Comput. Eng. Appl. 2017, 53, 36–44. [Google Scholar]
- Watson, J.D.; Crick, F.H.C. Molecular Structure of Nucleic Acids: A Structure for Deoxyribose Nucleic Acid. Nature 1953, 171, 737–738. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Zhu, X.; Luo, C. A novel chaotic algorithm for image encryption utilizing one-time pad based on pixel level and DNA level. Opt. Lasers Eng. 2020, 125, 105851. [Google Scholar] [CrossRef]
- Jithin, K.; Sankar, S. Colour image encryption algorithm combining Arnold map, DNA sequence operation, and a Mandelbrot set. J. Inf. Secur. Appl. 2020, 50, 102428. [Google Scholar] [CrossRef]
- Wu, X.; Zhu, B.; Hu, Y.; Ran, Y. A novel color image encryption scheme using rectangular transform-enhanced chaotic tent maps. IEEE Access 2017, 5, 6429–6436. [Google Scholar]
- Álvarez, G.; Li, S. SOME BASIC CRYPTOGRAPHIC REQUIREMENTS FOR CHAOS-BASED CRYPTOSYSTEMS. Int. J. Bifurc. Chaos 2006, 16, 2129–2151. [Google Scholar] [CrossRef] [Green Version]
- Khan, S.; Han, L.; Lu, H.; Butt, K.K.; Bachira, G.; Khan, N. A new hybrid image encryption algorithm based on 2D-CA, FSM-DNA rule generator, and FSBI. IEEE Access 2019, 7, 81333–81350. [Google Scholar] [CrossRef]
- Khan, J.S.; Boulila, W.; Ahmad, J.; Rubaiee, S.; Rehman, A.U.; AlRoobaea, R.; Buchanan, W.J. DNA and Plaintext Dependent Chaotic Visual Selective Image Encryption. IEEE Access 2020, 8, 159732–159744. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiao, D. Self-adaptive permutation and combined global diffusion for chaotic color image encryption. AEU-Int. J. Electron. Commun. 2014, 68, 361–368. [Google Scholar] [CrossRef]
- Rehman, A.U.; Liao, X.; Ashraf, R.; Ullah, S.; Wang, H. A color image encryption technique using exclusive-OR with DNA complementary rules based on chaos theory and SHA-2. Optik 2018, 159, 348–367. [Google Scholar] [CrossRef]
- Chai, X.; Fu, X.; Gan, Z.; Lu, Y.; Chen, Y. A color image cryptosystem based on dynamic DNA encryption and chaos. Signal Process. 2019, 155, 44–62. [Google Scholar] [CrossRef]
- Wang, X.-Y.; Zhang, H.-L.; Bao, X.-M. Color image encryption scheme using CML and DNA sequence operations. Biosystems 2016, 144, 18–26. [Google Scholar] [CrossRef]
- Qayyum, A.; Ahmad, J.; Boulila, W.; Rubaiee, S.; Masood, F.; Khan, F.; Buchanan, W.J. Chaos-based Confusion and Diffusion of Image Pixels using Dynamic Substitution. IEEE Access 2020, 8, 1. [Google Scholar] [CrossRef]
- Masood, F.; Boulila, W.; Ahmad, J.; Arshad, A.; Sankar, S.; Rubaiee, S.; Buchanan, W.J. A Novel Privacy Approach of Digital Aerial Images Based on Mersenne Twister Method with DNA Genetic Encoding and Chaos. Remote Sens. 2020, 12, 1893. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
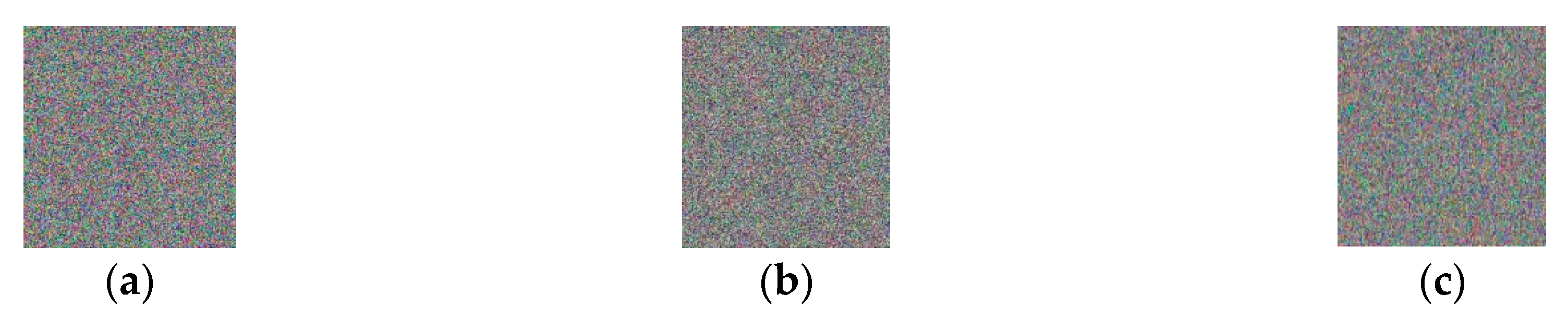{kind=link}
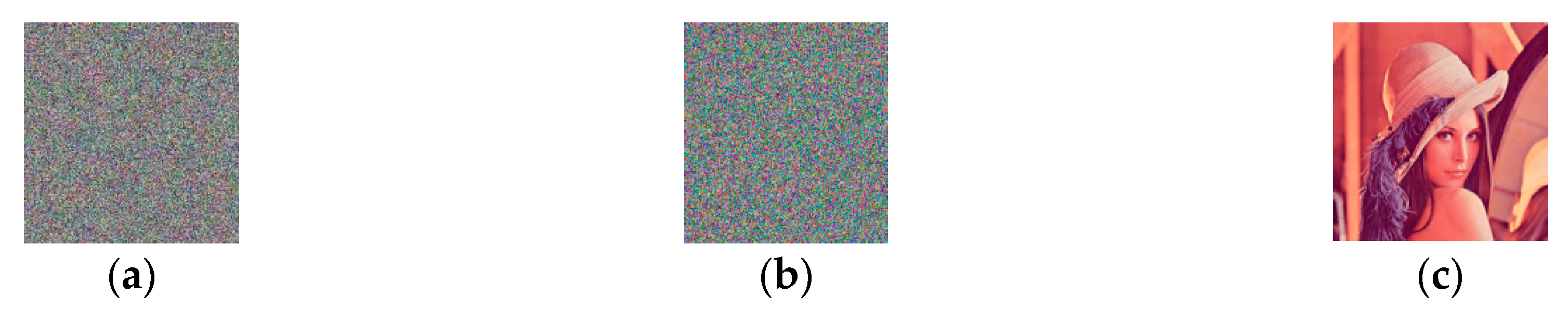{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rule | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 00 | A | A | T | T | G | G | C | C |
| 01 | C | G | G | C | A | T | A | T |
| 10 | G | C | C | G | T | A | T | A |
| 11 | T | T | A | A | C | C | G | G |
| Item | Value |
|---|---|
| System parameters of the four-wing hyperchaotic system | a= 8, b = −1, c = −40, d = 1, e = 2, m = 1, n = −2, n = −14 |
| System parameters of the Lorenz chaotic system | A = 10, β = 8/3, γ = 28 |
| System parameters of the 2D-RT | A = 1, b = 3, c = 5, d = 16, rm = 4, rn = 7, t = 5 |
| Abandoned numbers of the sequence | l0 = 1000, l1 = 1000, l2 = 1000 |
| Image | Changed Key | R | G | B |
|---|---|---|---|---|
| Figure 4a | K1 | 0.9963 | 0.9962 | 0.9960 |
| Figure 4b | K2 | 0.9963 | 0.9957 | 0.9957 |
| Figure 4c | K | 0 | 0 | 0 |
| Image | Changed Key | R | G | B |
|---|---|---|---|---|
| Figure 5a | K1 | 0.9965 | 0.9964 | 0.9956 |
| Figure 5b | K2 | 0.9964 | 0.9962 | 0.9960 |
| Figure 5c | K | 0 | 0 | 0 |
| Image | Direction | Plain Image | Encrypted Image | ||||
|---|---|---|---|---|---|---|---|
| R | G | B | R | G | B | ||
| H | 0.968 | 0.949 | 0.932 | 0.014 | 0.011 | 0.009 | |
| Lena | V | 0.943 | 0.896 | 0.887 | 0.011 | 0.020 | 0.022 |
| D | 0.918 | 0.859 | 0.852 | 0.035 | 0.016 | 0.021 | |
| H | 0.939 | 0.955 | 0.925 | 0.005 | −0.015 | −0.006 | |
| Pepper | V | 0.931 | 0.935 | 0.905 | 0.029 | −0.010 | 0.011 |
| D | 0.887 | 0.894 | 0.842 | 0.012 | −0.014 | 0.025 | |
| H | 0.917 | 0.919 | 0.938 | −0.013 | 0.012 | −0.011 | |
| H | 0.950 | 0.895 | 0.938 | −0.014 | −0.010 | −0.004 | |
| Baboon | V | 0.944 | 0.876 | 0.919 | −0.022 | 0.014 | −0.007 |
| D | 0.921 | 0.827 | 0.889 | −0.010 | −0.018 | 0.021 | |
| All | H | #N/A | #N/A | #N/A | −0.011 | 0.015 | 0.012 |
| black | V | #N/A | #N/A | #N/A | −0.021 | −0.016 | −0.016 |
| D | #N/A | #N/A | #N/A | 0.016 | −0.002 | 0.005 | |
| All | H | #N/A | #N/A | #N/A | 0.001 | 0.002 | 0.003 |
| white | V | #N/A | #N/A | #N/A | 0.005 | 0.010 | 0.003 |
| D | #N/A | #N/A | #N/A | 0.003 | 0.004 | 0.001 | |
| Algorithm | Encrypted Image | |||
|---|---|---|---|---|
| R | G | B | Average | |
| Ours | 0.0011 | 0.0018 | 0.0024 | 0.0018 |
| Ref. [29] | −0.0027 | 0.0033 | −0.0035 | 0.0031 |
| Ref. [28] | 0.0096 | 0.0109 | 0.0122 | 0.0109 |
| Image | Lena | Pepper | Baboon | All Black | All White | |
|---|---|---|---|---|---|---|
| Plain image | R | 76004.8672 | 57105.9766 | 22617.9609 | #N/A | #N/A |
| G | 31563.3516 | 52138.7656 | 36848.7813 | #N/A | #N/A | |
| B | 95871.8906 | 103145.2813 | 35444.8828 | #N/A | #N/A | |
| Encrypted image | R | 229.5391 | 259.8532 | 272.1654 | 263.6427 | 238.7628 |
| G | 231.0976 | 249.9874 | 276.7468 | 263.9653 | 241.7543 | |
| B | 247.1986 | 264.4899 | 286.8965 | 255.3785 | 271.9436 | |
| Algorithm | Variance | ||
|---|---|---|---|
| R | G | B | |
| Ours | 229.5391 | 241.9375 | 248.1328 |
| Ref. [22] | 249.7265 | 257.4453 | 256.1875 |
| Ref. [29] | 247.7800 | 279.6200 | 265.7100 |
| Image | Plain Image | Encrypted Image | ||||
|---|---|---|---|---|---|---|
| R | G | B | R | G | B | |
| Lena | 7.1655 | 7.5578 | 6.8571 | 7.9974 | 7.9976 | 7.9975 |
| Pepper | 7.3009 | 7.5570 | 7.0929 | 7.9974 | 7.9973 | 7.9972 |
| Baboon | 7.6987 | 7.4251 | 7.5809 | 7.9970 | 7.9970 | 7.9971 |
| All black | 0.0000 | 0.0000 | 0.0000 | 7.9971 | 7.9971 | 7.9972 |
| All white | 0.0000 | 0.0000 | 0.0000 | 7.9974 | 7.9973 | 7.9970 |
| Algorithm | Information Entropy | ||
|---|---|---|---|
| R | G | B | |
| Ours | 7.9974 | 7.9976 | 7.9975 |
| Ref. [29] | 7.9973 | 7.9969 | 7.9971 |
| Ref. [27] | 7.9973 | 7.9972 | 7.9969 |
| Ref. [28] | 7.9966 | 7.9972 | 7.9967 |
| Image | NPCR | UACI | ||||
|---|---|---|---|---|---|---|
| R | G | B | R | G | B | |
| Lena | 0.9959 | 0.9960 | 0.9961 | 0.3354 | 0.3344 | 0.3345 |
| Pepper | 0.9962 | 0.9960 | 0.9959 | 0.3341 | 0.3339 | 0.3336 |
| Baboon | 0.9960 | 0.9961 | 0.9959 | 0.3345 | 0.3340 | 0.3334 |
| All black | 0.9961 | 0.9961 | 0.9958 | 0.3344 | 0.3345 | 0.3341 |
| All white | 0.9963 | 0.9959 | 0.9962 | 0.3344 | 0.3334 | 0.3351 |
| Image | NPCR | UACI | ||||
|---|---|---|---|---|---|---|
| R | G | B | R | G | B | |
| Ours | 0.9959 | 0.9960 | 0.9961 | 0.3354 | 0.3344 | 0.3345 |
| Ref. [29] | 0.9960 | 0.9961 | 0.9961 | 0.3356 | 0.3345 | 0.3349 |
| Ref. [28] | 0.9961 | 0.9961 | 0.9961 | 0.3343 | 0.3343 | 0.3342 |
| Ref. [30] | 0.9963 | 0.9960 | 0.9960 | 0.3360 | 0.3330 | 0.3340 |
| Item | R | G | B |
|---|---|---|---|
| GN with intensity = 0.02 | 28.2541 | 28.5421 | 28.3041 |
| GN with intensity = 0.2 | 27.5014 | 27.3657 | 27.4251 |
| SPN with intensity = 0.0002 | 57.4214 | 56.3527 | 56.8765 |
| SPN with intensity = 0.0005 | 66.5047 | 67.4581 | 66.5041 |
| SPN with intensity = 0.001 | 59.1021 | 61.1042 | 61.5384 |
| 1/8 data loss at the lower-left corner | 30.6874 | 34.5478 | 35.6522 |
| 1/8 data loss at the upper-right corner | 33.0001 | 33.0487 | 32.6894 |
| 1/4 data loss at the lower-right corner | 31.5478 | 31.2587 | 31.3586 |
| 1/4 data loss at the upper-left corner | 29.9564 | 32.7532 | 32.2287 |
| Image | Plain Image | Encrypted Image | ||||
|---|---|---|---|---|---|---|
| R | G | B | R | G | B | |
| Lena | 0.3672 | 0.3947 | 0.3405 | 10.5208 | 10.4763 | 10.5223 |
| Pepper | 0.1743 | 0.2341 | 0.1668 | 10.4999 | 10.4879 | 10.5112 |
| Baboon | 0.2248 | 0.2204 | 0.2430 | 10.5261 | 10.5012 | 10.4987 |
| Image | Plain Image | Encrypted Image | ||||
|---|---|---|---|---|---|---|
| R | G | B | R | G | B | |
| Lena | 0.1391 | 0.0989 | 0.1756 | 0.0156 | 0.0156 | 0.0156 |
| Pepper | 0.1499 | 0.1183 | 0.1849 | 0.0156 | 0.0156 | 0.0156 |
| Baboon | 0.1047 | 0.1285 | 0.1233 | 0.0156 | 0.0156 | 0.0156 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.; He, P.; Kasabov, N. A Dynamic DNA Color Image Encryption Method Based on SHA-512. Entropy 2020, 22, 1091. https://doi.org/10.3390/e22101091
Zhou S, He P, Kasabov N. A Dynamic DNA Color Image Encryption Method Based on SHA-512. Entropy. 2020; 22(10):1091. https://doi.org/10.3390/e22101091
Chicago/Turabian StyleZhou, Shihua, Pinyan He, and Nikola Kasabov. 2020. "A Dynamic DNA Color Image Encryption Method Based on SHA-512" Entropy 22, no. 10: 1091. https://doi.org/10.3390/e22101091
APA StyleZhou, S., He, P., & Kasabov, N. (2020). A Dynamic DNA Color Image Encryption Method Based on SHA-512. Entropy, 22(10), 1091. https://doi.org/10.3390/e22101091