1. Introduction
Heart rate variability (HRV) refers to the beat-to-beat variation of the time interval from R peak to R peak (i.e., RR intervals, RRIs or inter-beat intervals, IBIs) in the electrocardiograph (ECG) signals. Healthy heart rate fluctuates in complex patterns, driven by the complex nonlinear interactions of two competing forces (sympathetic stimulation increases and parasympathetic stimulation decreases heart rate), as well as breathing, circulation, etc., which allow the cardiovascular system to rapidly adjust to sudden physical and psychological challenges to homeostasis [
1,
2].
HRV indices are quantitative measures of the emergent property of interdependent regulatory systems which operate on different time scales to help our bodies to adapt to environmental and psychological challenges. The commonly used HRV metrics are quantified using temporal, spectral and nonlinear measures. Time-domain indices quantify the amount of HRV observed during monitoring periods. For example, standard deviation of all NN intervals (SDNN) is used to assess the size of the overall change in heart rate [
3], and its values are different depending on the ECG recording length or segment duration; root mean square of the successive differences (RMSSD), standard deviation of differences between adjacent NN intervals (SDSD), NN50 and pNN50 are sensitive indicators of parasympathetic tone. Frequency-domain values calculate the absolute or relative amount of signal energy within component bands, i.e., ultra-low frequency (ULF), very-low-frequency (VLF), low-frequency (LF), and high-frequency (HF) bands. VLF reflects chemoreceptor regulation, thermoregulation and vasomotor activity [
4]; LF is related to baroreflex regulation [
5], and can reflect the regulation of both the sympathetic and parasympathetic nervous systems; HF mainly reflects the regulatory function of the parasympathetic nerve, and the index is affected by respiration. In young and healthy individuals, the HF band is significantly increased at night and decreased during the day; the LF/HF ratio can reflect the interaction and comparison of the intensity of sympathetic and parasympathetic activities [
6]. The importance of nonlinear dynamic theory for HRV analysis is that it can quantitatively describe the characteristics of complex dynamic systems and extract the evolution information. The most widely used nonlinear analysis methods include detrending fluctuation analysis (DFA) [
7], and entropy or multi-scale entropy based measures [
8,
9,
10,
11,
12]. DFA can quantify the fractal scale index of HRV, which is suitable for detecting long-range power law correlation analysis of non-stationary time series; entropy based measures can study the complexity of HRV from single scale or multiple scale time scales [
13]. Healthy biological systems exhibit spatial and temporal complexity, disease can involve either a loss or increase of variability [
14]. Changes of HRV occur in several systemic diseases, such as diabetes [
15], hypertension [
16], heart failure [
17,
18], and coronary heart disease [
19]. Reduced HRV is a remarkable predictor of cardiac events including sudden death in subjects with coronary artery disease, myocardial infarction and heart failure [
20].
Studies have shown that HRV could be strongly influenced by environmental conditions and subject variables. [
21]. For example, HRV varied with age and gender [
22], ECG recording length or ECG segment duration [
23], physical activity intensity [
24,
25], body posture change [
21], et al. Besides, the intra-day and inter-day reliability of HRV measurements was also introduced in [
26]. Although several studies have found an adequate reproducibility of HRV both in the time and in the frequency domain analyses [
21,
27,
28,
29,
30,
31], others have not made this observation [
31]. Reliability and reproducibility of the various of HRV metrics obtained from short-term records is still under discussion [
21,
31,
32,
33]. Longer recording periods provide data about cardiac reactions to a greater range of environmental stimulation. For example, SDNN over 24 h will always differ to SDNN of ten minutes, and it is more accurate when calculated over 24 h than during the shorter periods; ULF usually requires 24 h Holter monitoring; VLF needs at least a recording time of 10 min or more. Therefore, guarantee of HRV reliability, stability and reproducibility is a key question in longitudinal studies or in clinical conditions, where the same data are recorded from a single individual at different times and scenarios, or in comparative studies where ECG data are recorded from different diseased and healthy control groups. Unfortunately, many HRV studies were conducted without considering such influences or had no standardized or normalized data recording criteria.
HRV analysis has become an established procedure over the past two decades [
34,
35] since the publication of the first guidelines [
36]. There have been advances in recording technology (smaller, wearable, more mobile, more accurate devices) [
37], for example, long-term RR intervals can now be measured by small chest strap and pulse watch systems [
38,
39]. Technology developments have decreased the costs of recording and analysis and have facilitated applications in home monitoring. With the development of wearable devices, continuous HRV metrics monitored and analyzed at patients’ home becomes feasible, which puts forward higher requirements for the standardization of environment conditions during measurement. Moreover, the importance of early detection and early treatment is self-evident, however, diseases or clinical conditions at very early stages have a less pronounced effect on HRV than severe or acute heart disease, and their alteration on HRV may be submerged in the noise of subject variables and environment conditions.
Awareness of the condition of recording and subject variables can aid interpretation of both 24-hour and short-term HRV measurements. Important factors include recording time (i.e., day or night) and recording length (i.e., 5 min, 1 h, or 24 h) [
40], recording method/device [
41], sampling frequency, data quality, removal of artifacts, respiration, and other environmental factors (i.e., home, school/work, hospital or laboratory) [
42]. Important subject variables are age, gender, heart rate, mental stress, emotions, sleep, health status, et al. In addition, influences of body position (i.e., sitting or lying), movement, physical activity, and tasks can all affect measurements subtly or even greatly by changing autonomic nervous system activation, breathing mechanics, and emotions. The level of daily physical and mental activity should also be considered. In particular, 24-hour HRV results significantly depends on activity. Mixing HRV data of subjects with obviously different daily activities is inappropriate and may lead to values that are of little use. Many HRV related algorithms published in the literature were developed and evaluated using different public databases without checking data recording conditions. There is a lack of standardization for those HRV measurements, and thus it is difficult to make direct comparison between groups or studies.
The objectives of the present study were to investigate (1) the variability of HRV in healthy young subject under different recording conditions; and (2) subject variables in the same day of routine daily life. We mainly focus on the variability of healthy young HRV at different home monitoring scenarios in daily life, especially the routine normal daily activities which were diverse at recording time, physical activity intensity, mental activity, and body postures.
2. Data and Methods
2.1. Protocol and Data
A total of 56 volunteered healthy college students aged 21.1 ± 2.1 years (mean ± std) from Southeast University in China took part in this study, including 28 males (21.5 ± 2.4 years) and 28 females (20.8 ± 1.7 years). All participants were informed the experimental protocol and matters needing attention, then signed the written informed consent prior to participating in the study. This study was approved by IEC (Independent Ethics Committee) for clinical research of Zhongda Hospital, affiliated to Southeast University (No. 2019ZDSYLL073-P01).
ECG recordings were collected by a FDA (U.S. Food and Drug Administration) approved ambulatory electrocardiogram monitor (DynaDx Corporation, Mountainview, CA, USA) with a computer-based data-acquisition system and a sleep quality analysis software. The ECG recording equipment was a single-lead Holter device that can record ECG for over 24 h. The study was conducted at the campus of Southeast University. All participants were instructed to wear the ECG device for at least 20 h from Friday night earlier than 23:00 (before going to bed as usual) to Saturday night 19:00, and to follow the experiment protocol during the whole day. Sampling rate of ECG monitoring was set to 512 Hz.
Participants in this study were required to be healthy, free of cardiovascular diseases, diabetes, mental conditions, sleep apnea and other diseases that have a known impact on HRV, and have no adverse life behaviors, such as smoking and drinking alcohol. Female students were not in menstruation period. Subjects were also required to fill in the self-rating depression scale (SDS), profile of mood states (POMS) and Pittsburgh sleep quality index (PSQI) to avoid the influences due to mental and sleep related issues.
Of the 60 initially recruited volunteers, 56 recordings were included and 4 recordings were excluded due to low data quality.
The data collection protocol was shown in
Table 1. The experiment was conducted for 20 h under various recording conditions: sleeping at night, reading quietly in different body postures, brisk walking at a certain exercise intensity, and free-running daily activities (after meals) in the morning, noon and evening.
Night sleeping: Subjects were directed to go to bed at 23:00 and wake up at 7:00 to guarantee 8-h sleep. Sleep quality and staging analysis were performed by the ‘sleephousekeeper’ software. The sleep and wake-up time were calibrated via self-reported forms filled in by the subjects. To keep a comparable ECG recording length with the other activities during daytime, the sleep ECG signals in the period of 01:00–02:00 were selected for subsequent HRV analysis.
Reading: Subjects were required to read paper books of general science in a quiet environment (i.e., in their dormitory) in specified body postures, consisting of sitting posture reading and lying posture reading. Lying posture reading included lying on the left, lying on the right and lying on the back.
Brisk walking: Subject were required to walk at a faster speed than usual on a 400 m plastic track at the campus.
Free-running daily activities (FreeDA): Subjects were asked to follow their normal daily activities except performing physical exercise or taking a shower/bath. They were free to choose whatever they want to do, such as chatting with friends, surfing the Internet, writing homework, cleaning the room, doing laundry and performing other daily activities, but the same activity cannot be run more than 15 min. ECG signals during FreeDA were recorded in three different time periods, i.e., morning, noon and evening, beginning at about 30-min after meals.
2.2. Data Preprocessing
The third-order band-pass Butterworth filter and zero-phase shift filter with a cut-off frequency of 2 Hz to 30 Hz were first used to eliminate the baseline drift, power frequency interference and high frequency noise, which can make the QRS complex (including the Q wave, R wave, and S wave) more prominent, and avoid changing the position of R peaks. At the same time, for those serious noises that may not be resolved using above procedure, a manual removal method was adopted, i.e., the ECG signals drowned in serious noise (probably due to unstable contact between the wearable device and the skin) were set to zero. All ECG recordings were carefully checked with ectopic beats, very few ectopic beats were found and eliminated (i.e., set to zero), and only ECG signals with normal R peaks (i.e., N peaks) were remained.
2.3. High-Quality RR Interval Detection and De-Noising
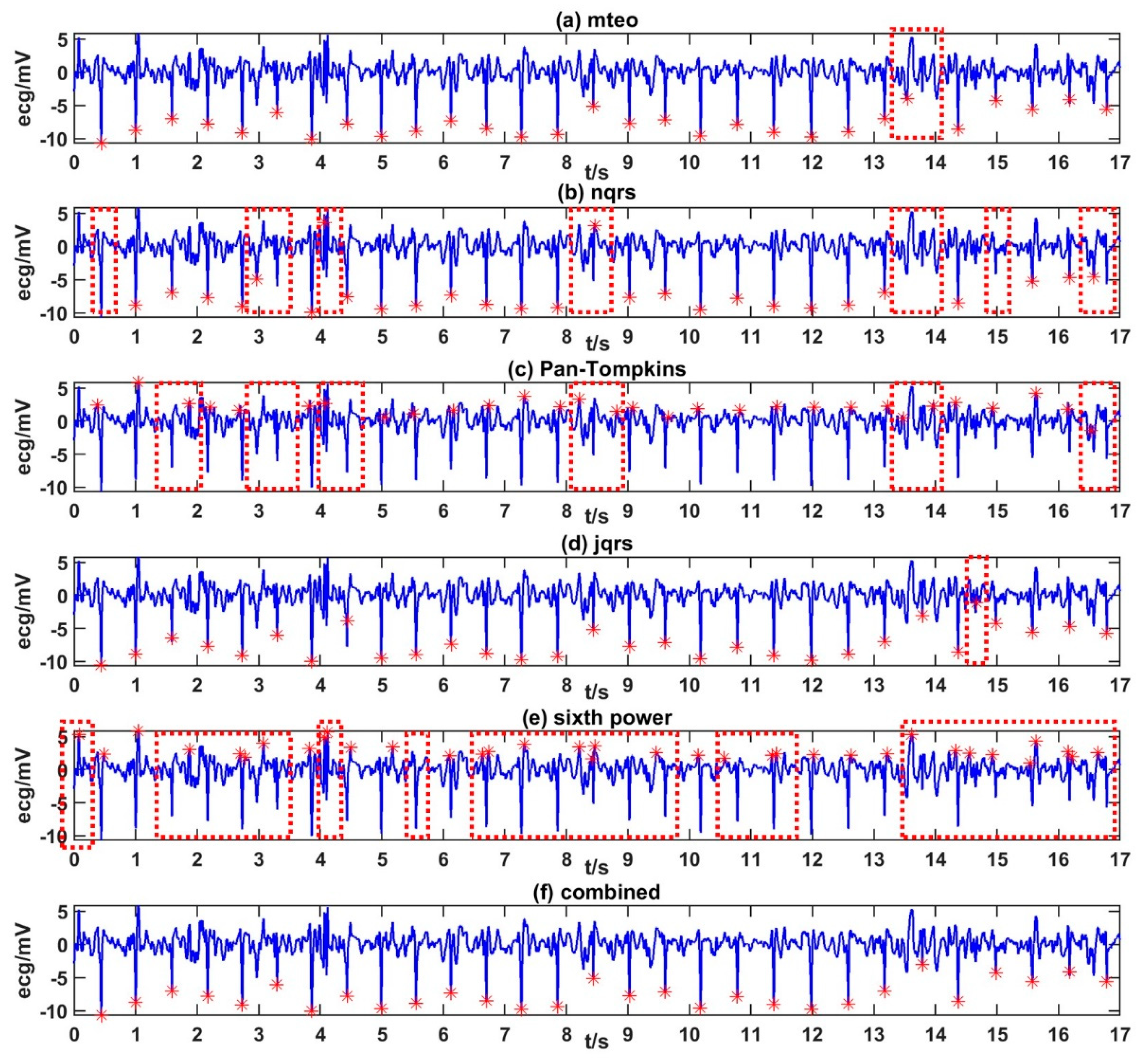
At present, plenty of R-peak detection methods have been proposed on ECG signal analysis. However, when applying these detectors on ECG signals collected in daily life, especially via wearable single-lead ECG devices, the R peak detection accuracies were usually unsatisfying. In this study, the ECG signals during brisk walking and free-running daily activities contains more noise than ECG collected during sleeping and reading. To compare HRV measured in different conditions, we should keep the data quality of detected RRIs at the same or similar level. A single R-peak detection method was not qualified on this database. Hence, we proposed a method combining five commonly used R-peak detection methods to get high-quality RRIs from noisy ECGs.
The five popular R-peak detection methods applied in this study were ‘Pan-Tompkins’ [
43,
44], ‘jqrs’ [
45], ‘mteo’ [
46], ‘nqrs’ [
47], and ‘sixth power’ [
48]. Each R-peak detection method has its own advantages. Details of the proposed method to get high-quality RRIs from noisy ECGs are as follows:
Detect R peaks of the ECG samples with five detection methods. Five sets of initial detection results were obtained.
Categorize the ECG sample by template matching and select weights by the category. There were five categories in total that corresponding to five sets of weights. A set of weights included five weights corresponding to five detection methods. For a specific kind of ECG signal, the method with better performance was assigned more weight.
Calculate the “scores” of each R-peak annotation in five sets of detection results in (1) based on the weights in (2). A high score indicated that the annotation might be correct.
The five sets of R detection results were merged into a vector, and the scores of the initial R-peak annotations obtained in Step (1) were calculated one by one.
First, to calculate the score of R-peak annotation j, the score was calculated based on the weight of the detection method that marked annotation j.
Then, find out whether there were other R-peak annotations marked by other four methods in the left or right range (i.e., within 50 ms around the center of annotation j) of annotation j. There would be some deviation between the results of several detection methods. When other annotations within the range were more concentrated on annotation j, it is more likely that j was a correct R-peak annotation. Therefore, the score of annotation j was inversely related to the distances from it to other annotations within the range. The score of R-peak annotation j was defined in expression (1).
where
is the weight corresponding to the detection method that marked
,
is the annotation within the range,
is the sampling rate of ECG signals.
Finally, a threshold was used to filter out the R-peak annotations with high scores.
where
is the average score of the five R-peak annotations before the annotation being calculated.
The parameters were adjusted according to the accuracy of the data set.
A more accurate R peak position were obtained.
Figure 1 shows examples of the R peak labeling results.
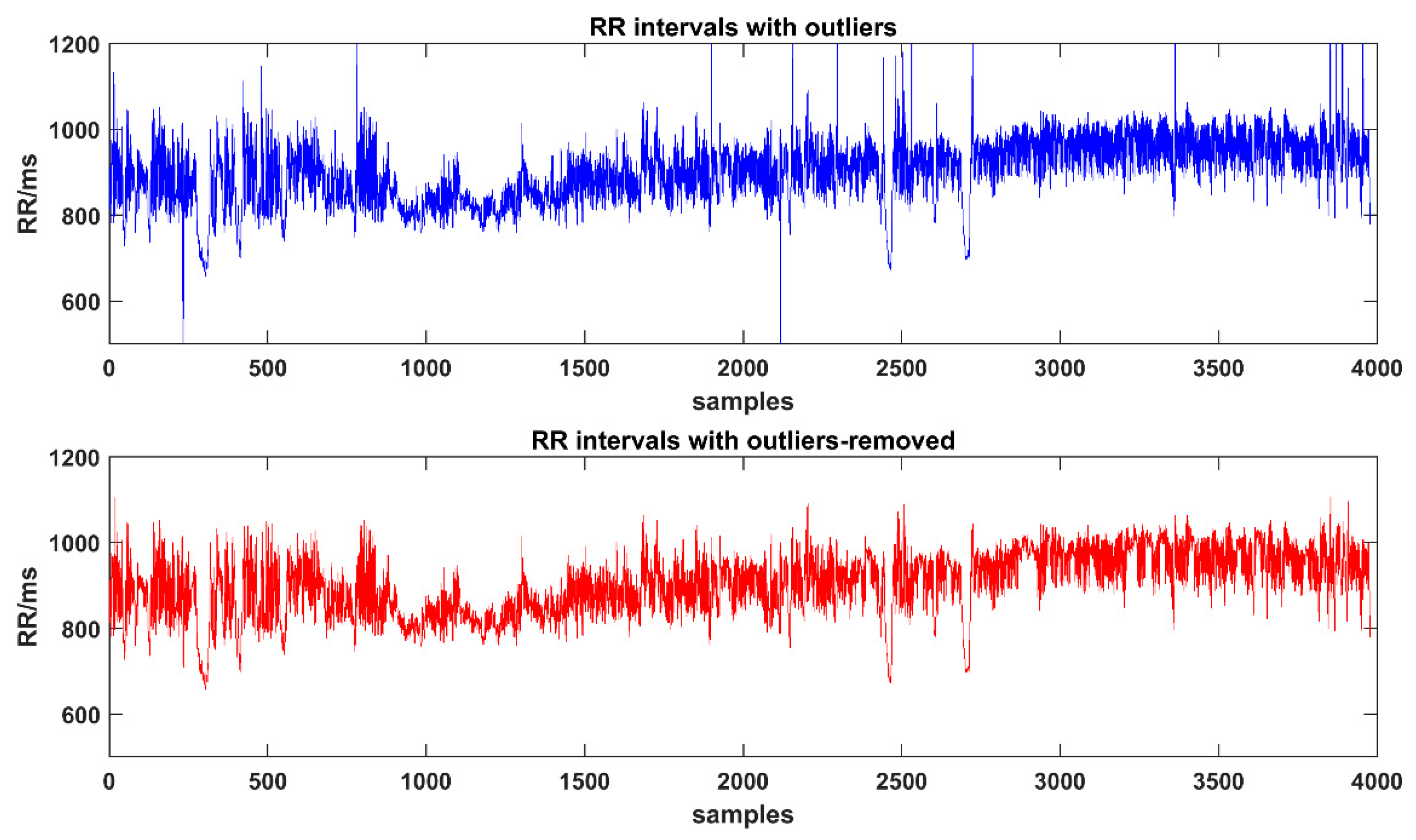
All detected RR time series were carefully checked with artifacts, ectopic beats or outliers. Thus, in this study, the RR intervals are the same meaning of NN intervals. Outliers would have a certain impact on the results of HRV analysis. Here we chose the Thompson algorithm [
49] to find outliers in the RRIs, which divided the original sequence into small windows according to the customized length to find out outliers and then to replace them with the average of adjacent points. In this study, four windows with lengths of 15, 50, 100, and 200 data points were selected to remove outliers.
Figure 2 shows the results of using Thompson algorithm to eliminate outliers.
2.4. HRV Metrics
In this study, we evaluated the variability of healthy HRV mainly based on the widely-used HRV linear metrics (i.e., time-domain and frequency-domain) and nonlinear metrics. All HRV metrics were analyzed under nine different recording scenarios, including sleeping at night, sitting (reading), lying down (reading) separately on the left side, right side and the back, brisk walking and free-running daily activities separately in the early morning, noon and evening. All indices and their definitions analyzed in this study are shown in
Table 2. We used the PhysioNet Cardiovascular Signal Toolbox [
50] to perform indicator calculations, except for fuzzy entropy and multi-scale fuzzy entropy (MATLAB codes from Hamed Azami and Javier Escudero Rodriguez [
51,
52]) and permutation entropy and multi-scale permutation entropy (MATLAB codes provided by Gaoxiang Ouyang [
53,
54]).
2.4.1. Linear HRV Metrics
Linear HRV metrics include time-domain indices and frequency domain indices. Time-domain indices quantify the amount of variability in measurements of the time period between successive heartbeats. For example, SDNN is used to assess the size of the overall change in heart rate, while SDANN relates to the variance below the 0.0033 Hz spectral frequency. RMSSD, SDSD, NN50 and pNN50 reflect the beat-by-beat changes in heart rate, that is, the size of the short-term changes in heart rate.
Frequency-domain measurements estimate the distribution of absolute or relative power at four frequency bands. The Task Force of the European Society of Cardiology and the North American Society of Pacing and Electrophysiology (1996) divided heart rate oscillations into ULF, VLF, LF, and HF bands (see
Table 2). ULF usually requires long-term recordings of Holter monitoring, and thus was not included in this study.
2.4.2. Nonlinear HRV Metrics
Heartbeat is a chaotic dynamic process. The complex interactions between electrophysiology, hemodynamics, autonomic nervous system, fluid regulation and other systems lead to nonlinear phenomena. The oscillations of a healthy heart are complex and nonlinear. The variability of heart rate provides the flexibility to rapidly cope with an uncertain and changing environment. Thus, the traditional linear HRV metrics are not enough to characterize the complex dynamics of generation of the heartbeat. Nonlinear analysis methods differ from the conventional linear HRV methods because they do not assess the magnitude of variability but rather the unpredictability, fractability and complexity of RRIs (or IBIs) time series, which results from the complexity of the mechanisms that regulate HRV. In this case, the nonlinear method is of great value in analyzing the RRIs time series.
This section introduces approximate entropy (ApEn) [
8], fuzzy entropy (FuzzyEn) [
9,
51], sample entropy (SampEn) [
10], permutation entropy (PeEn) [
11,
53], detrending fluctuation analysis (DFA, alpha1 and alpha2) [
7], multi-scale entropy (MSE) [
12], multi-scale fuzzy entropy (MFE) and multi-scale permutation entropy (MPE). Such metrics have potentially important applications with respect to evaluating both dynamical models of biologic control systems and bedside diagnostics. For example, a wide class of disease states, as well as aging, appear to degrade physiologic information content and reduce the adaptive capacity of the individual. Loss of complexity, therefore, has been proposed as a generic feature of pathologic dynamics.
ApEn is a conventional measure to quantify the irregularity or complexity of time series. It reflects the probability of new subsequences, which is a conditional probability method to measure the possibility of new information in time series. Therefore, the more complex time series corresponds to the larger ApEn.
For a given time sequence and given r and m, reconstruct to obtain (N − m + 1) subsequences .
Calculate the distanced between any two reconstructed subsequences. The distance is determined by the maximum difference between the corresponding position elements of the two sequences, including the distance when .
Calculate the ratio
of the number of distances less than
:
Calculate the average similarity rates
and
when the number of subsequences are
and
:
SampEn is an improved complexity measurement based on the concept of ApEn. The initial calculation process is the same as ApEn.
FuzzyEn is improved on the basis of SampEn, which describes the probability of a new pattern in a complex system containing noise. It is the entropy of a fuzzy set, which loosely represents the information of uncertainty.
Permutation Entropy (PeEn)
PeEn is similar to ApEn, SampEn and FuzzyEn, which are all used to measure the complexity of time series. PeEn introduces the idea of permutation when calculating the complexity between reconstructed subsequences.
Consistent with step a) in ApEn, get .
Incremental sorting is performed inside each and mapped to kinds of permutations. The internally sorted order of forms a symbol sequence , and its probability distribution is represented by .
DFA is a scaling method commonly used for detecting long-range correlations in non-stationary time series. It has two important advantages over other scaling analysis: it reduces noise effects and removes local trends, it is relatively unaffected by any non-stationarities.
In the standard DFA, basically, a time series is integrated to obtain a type of random-walk profile. Then, this sequence is divided into non-overlapping boxes of equal size
. In each box, the local trend is estimated by an m-degree polynomial fitting. In a subsequent step, the root-mean-square fluctuation, denoted by
, of the difference between the integrated sequence and the polynomial fits is calculated for each
. Finally, assuming that such fluctuations meet a power-law with respect to the box size, a scaling factor α is computed as the slope of the following fluctuation plot.
Disease and aging will reduce the physiological information and the adaptability of individuals, and the complexity of physiological indicators will be reduced. However, some conditions are associated with highly unstable fluctuations, such as arrhythmias, and the increase in single-scale entropy of such pathological signals contradicts the common perception that the complexity of physiological indicators decreases under pathological conditions. To solve this problem, MSE is proposed.
MSE analyses the complexity of time series from multiple time scales. The algorithm consists of three steps:
Time series coarse graining: for the given time series
, construct a continuous coarse-grained time series
yτ:
where τ is the scale factor, as τ = 1, 2, 3...
Calculate the SampEn of each coarse-grained time series yτ.
Draw the graph line with the scale factor τ as the independent variable and the SampEn of the corresponding scale sequence as the dependent variable.
Similarly, multi-scale fuzzy entropy (MFE) and multi-scale permutation entropy (MPE) were calculated.
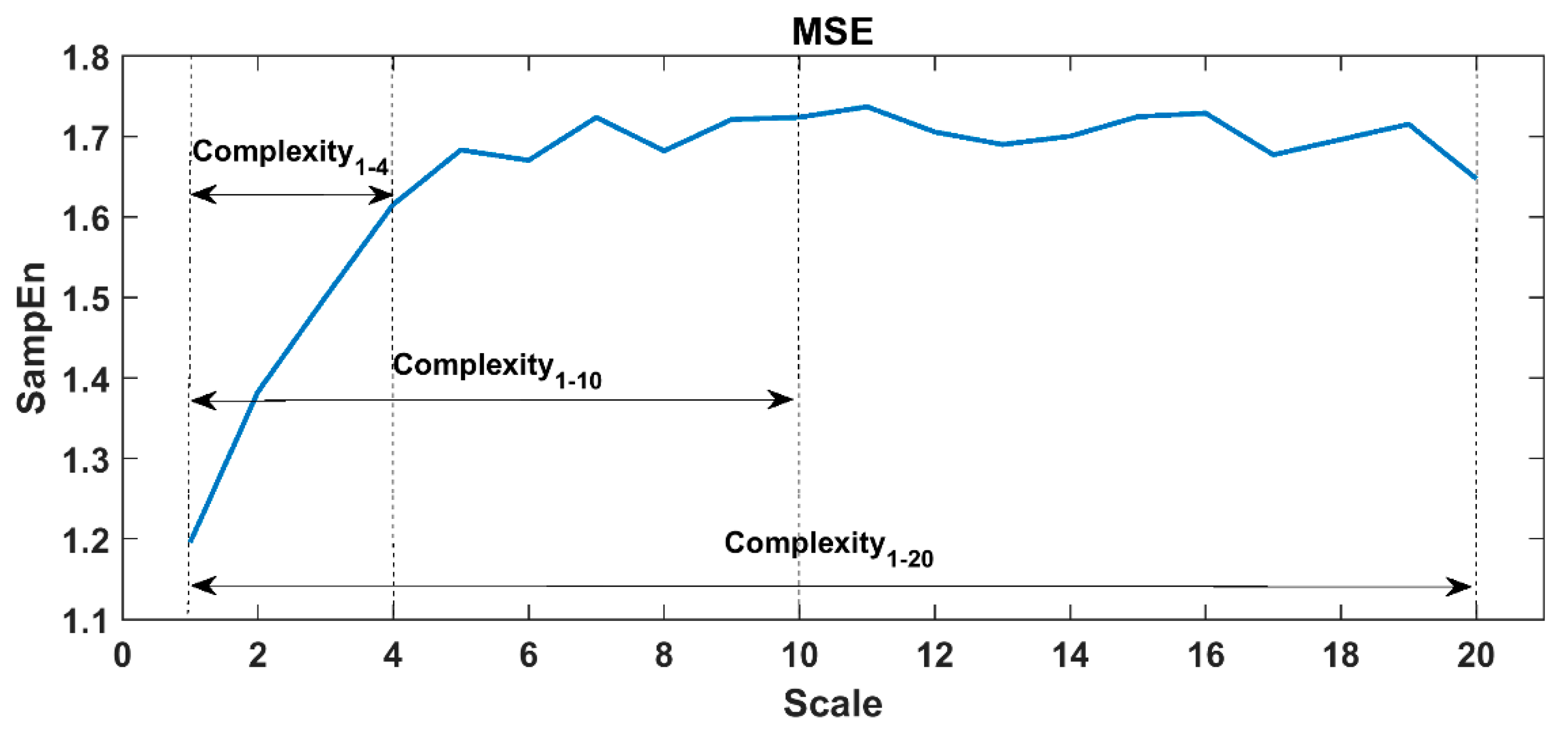
When calculating ApEn, SampEn and FuzzyEn, the embedding dimension m was set to 2, and the similar tolerance r was set to 0.15 times the standard deviation of the sequence. In PeEn, the embedding dimension was set to 3. In the DFA analysis, the fractal interval was set to 4–64, alpha 1 corresponded to 4–15, and alpha 2 corresponded to 16–64. In this study protocol, each task proceeded for 30 to 60 min, thus the scale factor τ in MSE/MFE/MPE was set to 1~20 for 60-min tasks and 1~10 for 30-min tasks (i.e., lying reading tasks) to ensure the reliability of large-scale analysis. A representative MSE curve of the 60-min RRIs time series was shown in
Figure 3, here we constructed 20 coarse-grained time series from the original RRIs. The complexity indices were defined by calculating the area under the MSE curve (see definitions in
Table 2), i.e., Complexity
1-20 (area under the whole MSE curve), Complexity
1-10 (area under the scales 1-10), and Complexity
1-4 (area under the small scales 1–4, which mainly demonstrated the influence of breathing or vagal tone).
2.5. Statistical Analysis
IBM SPSS Statistics 21.0 was used for statistical analysis in this study. The main purpose of statistical analysis is to determine whether there are significant differences between specific groups.
One-sample K-S hypothesis test was used to test whether it follows a normal distribution (significance level α = 0.05). For the population followed a normal distribution, one-way ANOVA test was performed on multiple sets of control samples and independent sample t-test was performed for the analysis between the two sets of samples. For the population did not follow a normal distribution, non-parametric tests were performed. The Mann–Whitney U test was used for the comparison of the two sets of samples, and the Kruskal–Wails H test was used for multiple samples. The significant difference was defined as the p-value < 0.05.
4. Discussion
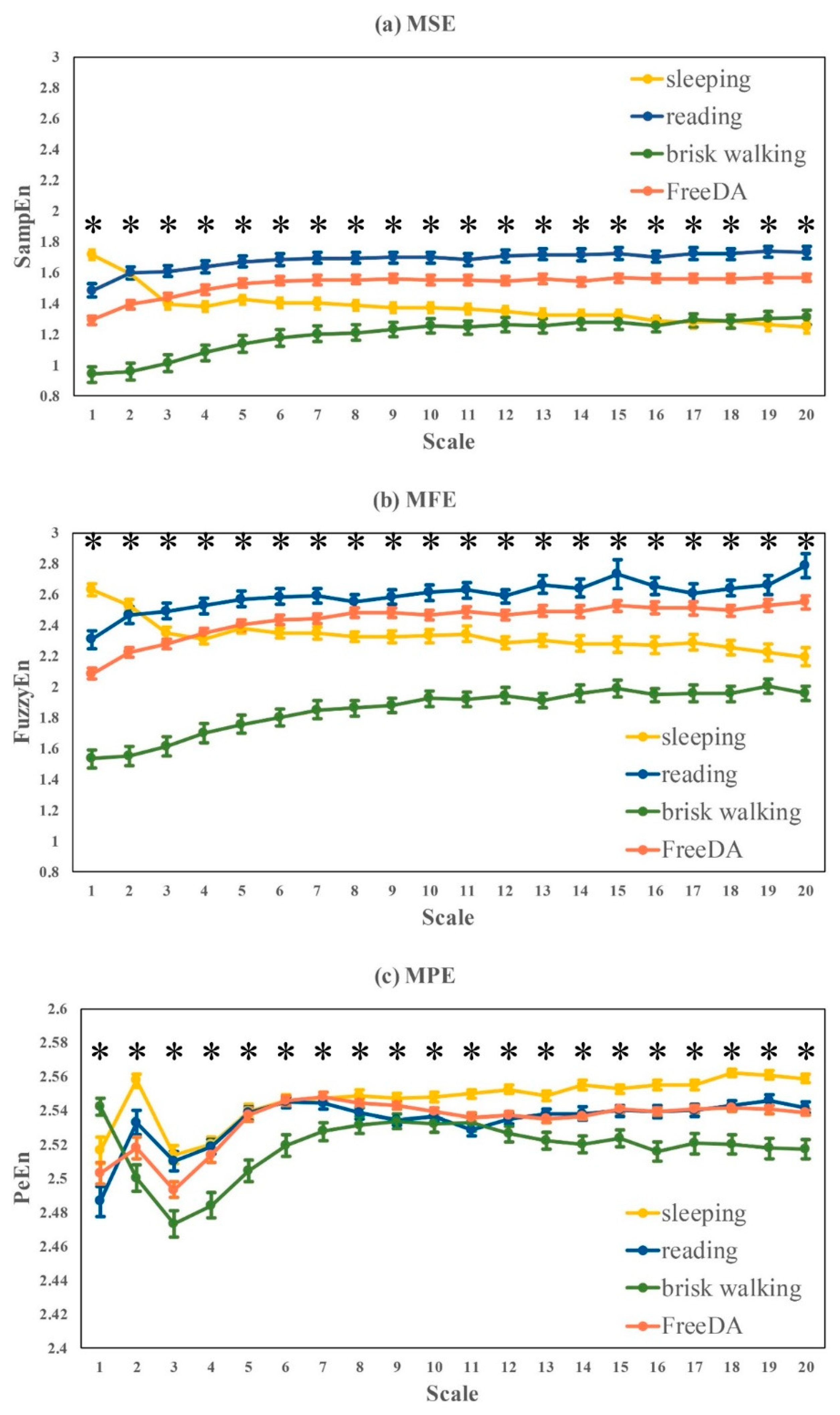
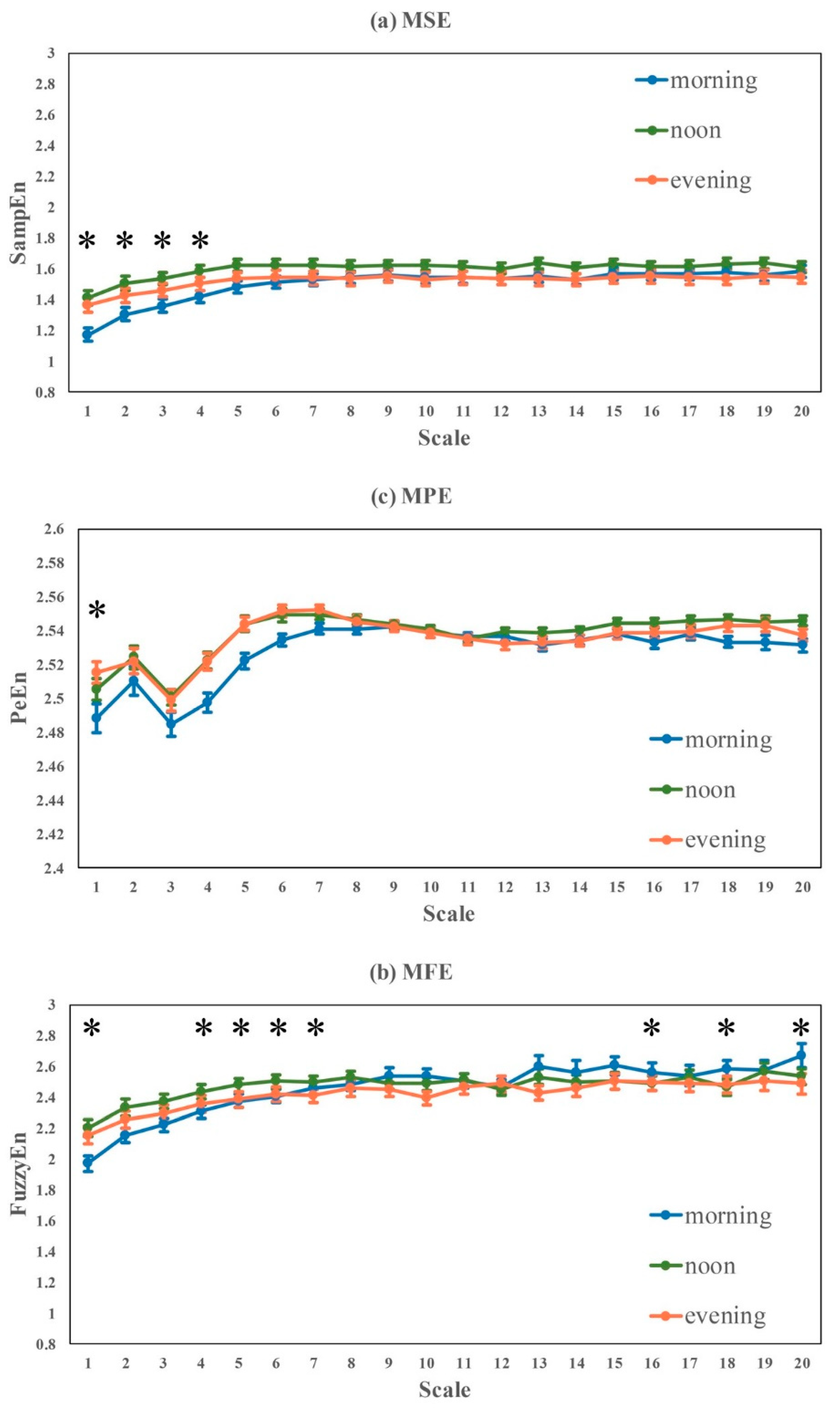
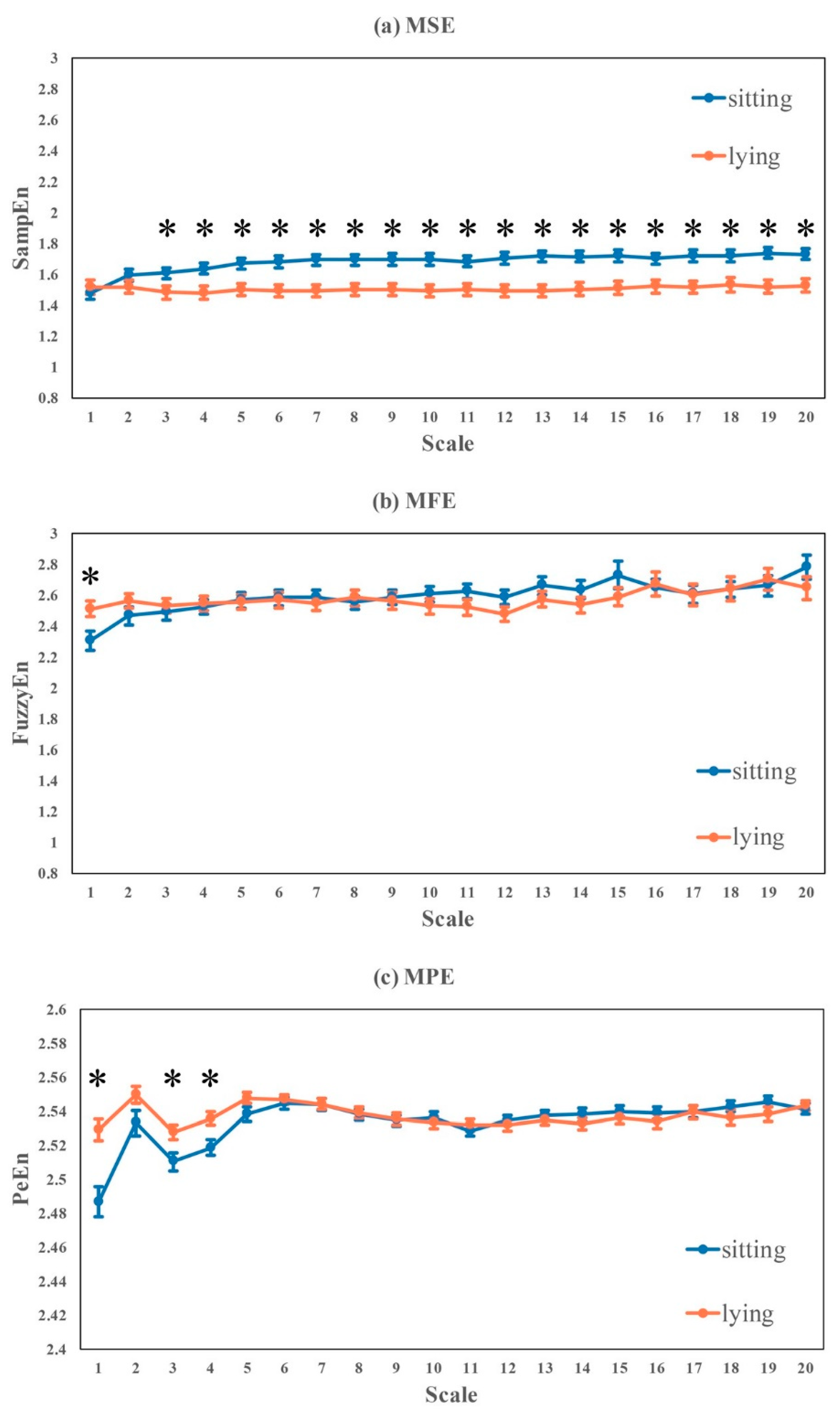
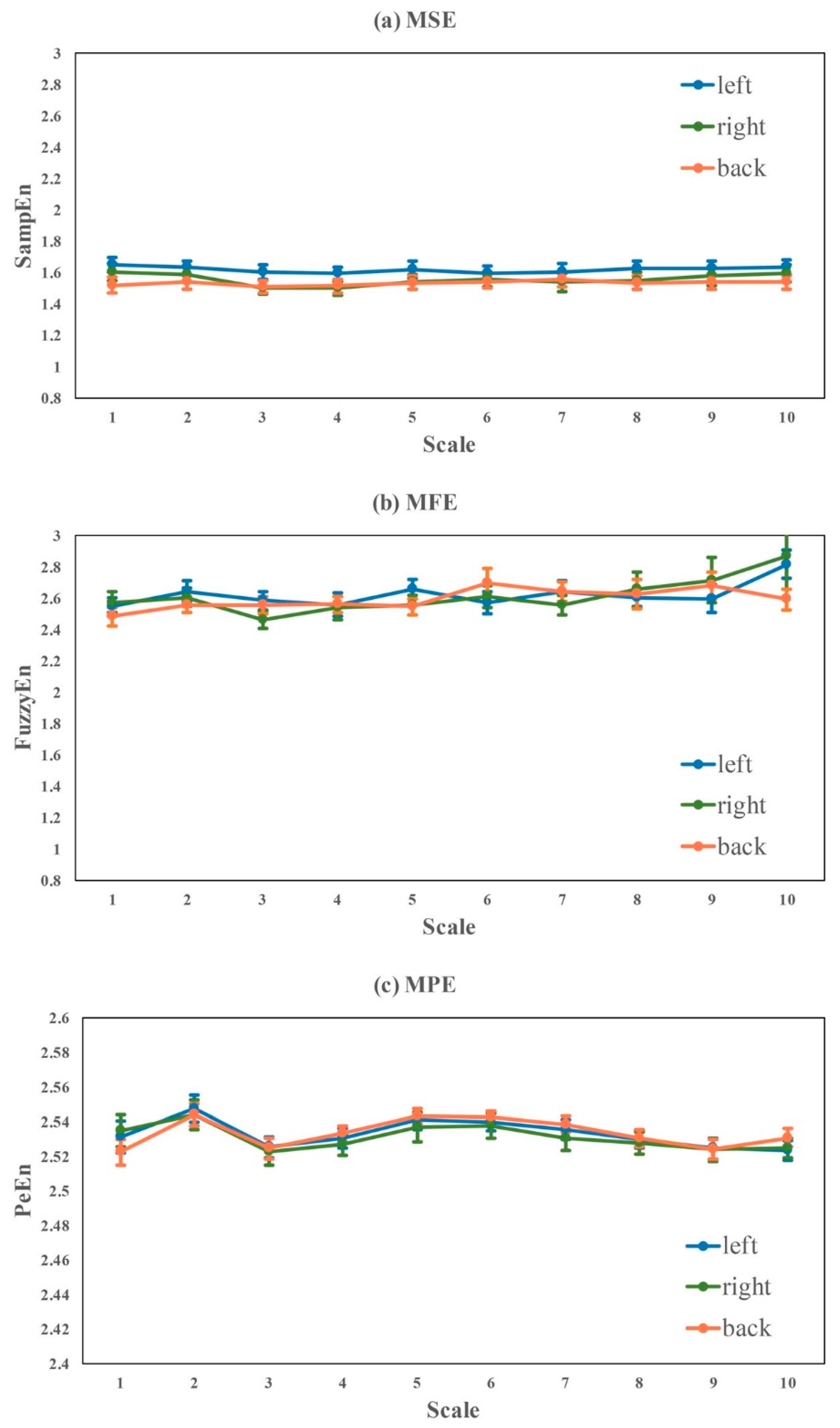
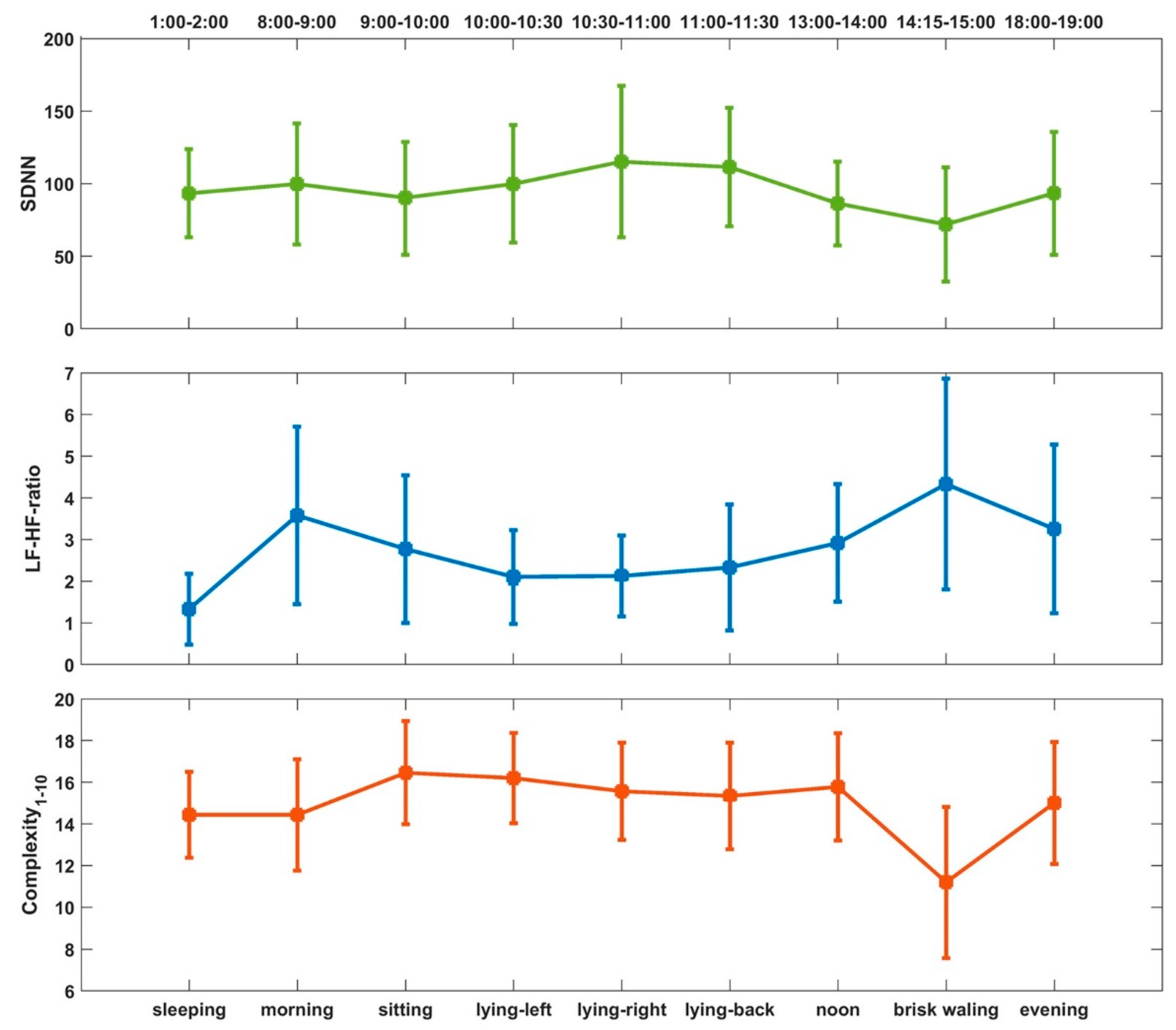
In this study, we focused our investigation on the variability of HRV influenced by data recording conditions for healthy young subjects that have been frequently used as healthy controls in HRV studies, and we did not study the influence of aging and disease. By grouping the HRV metrics into five different categories, we found the following: (1) HRV metrics for healthy subjects, both linear measures and nonlinear measures, were significantly influenced by routine life states and physical activities, ECG recording time (morning, noon, evening), body postures, and gender. (2) Although significant differences between sitting and lying were observed, no significant difference was found among different lying positions. (3) Nonlinear measures were more sensitive to ECG recording time than time- and frequency-measures. Thus, these findings demonstrated that the standardization of ECG data collection and HRV analysis should be emphasized in HRV related studies.
Our findings are consistent with common sense and previously published results. The cardiovascular system shows obvious daily rhythms in most physiologic parameters including HR and blood pressure [
55]. Generally, HRV parameters tend to increase during the night and decrease during the day, but when HR suddenly changes from a low point at night to a higher daily value, the variability around arousal is greater [
56,
57]. The lowest HRV in the morning [
58] corresponds to the period of the highest occurrence of ventricular tachycardia and sudden death [
59,
60,
61]. When doing more intense exercises (like brisk walking), compared with more relaxed daily activities, the sympathetic nerve activity is stronger, the parasympathetic nerve activity is weak, the complexity of HRV is lower, and the body’s ability to adapt to environmental changes will also be weakened. In different time periods, the HRV changes less, but the complexity of the morning was significantly lower than that of noon and evening. It may reflect that the morning is a more stressful state, which is an important time for the body to wake up. The highest complexity is obtained at noon, which may be related to biological rhythm and temperature. We also found that the influence of posture on HRV is greater than that of different periods of the day. Sitting and lying postures showed obvious differences in sympathetic and parasympathetic excitability and complexity. However, we didn’t find significant difference in HRV between lying postures of left, right and supine positions. Similarly, studies have shown that, from supine to standing, HR increased significantly, time-domain HRV metrics decreased correspondingly. Frequency domain variables decreased significantly from supine to sitting position [
62].
We presented the MSE measured complexity, instead of MFE and MPE, in the
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7 and its overall changes during the seven scenarios within 20-h in
Figure 9. The multi-scale based entropy analysis was firstly proposed by Costa et al. [
12] using sample entropy, and named it MSE. MSE is the original and also the most widely used multi-scale complexity measure in physiological signals, such as RR intervals. For the past two decades, hundreds of research studies have applied MSE to investigate problems ranging from heart disease, diabetes, traumatic brain injury, frailty in the elderly, to neurological diseases, which demonstrated that the complexity of healthy physiologic systems is higher than those with advanced aging or pathology [
12]. Hence, it is important to know how to define the baseline of ‘healthy MSE’ based on the observed variability influenced by data recording conditions.
Entropy curves of MFE and MPE are more stable than MSE during different life states or postures. MFE and MPE are more applicable for time series with large noise interference, so they were less influenced by the noises generated from different recording conditions, and thus didn’t show as much variations as MSE in this study. On the other hand, small fluctuations caused by minor health problems could not be quantified by MFE or MPE, either. MSE is more sensitive to RR time series fluctuations than MFE and MPE, and even minor changes in complexity could be monitored by MSE, which is more suitable for the detection of HRV alteration caused by disease in its early-stage. Under these conditions, to apply MSE, we should set up the same measuring protocol for all the involved groups for easy comparison.
In addition, current R peak or P peak detection algorithms generally have strict requirements for ECG or PPG signal quality. It is expected that new algorithms with better noise resistance could be proposed to extract high quality RR or PP intervals from data collected in daily life or during physical activities, which is of great significance to apply HRV for daily health monitoring and management.
In conclusion, the main contribution and new insights of this presented study could be summarized as follows: (1) our findings could provide supportive evidence for future HRV measurement during home monitoring because all the considered variables were controlled properly, e.g., ECG signals of different life states for each subject were recorded within the same day, only healthy young subjects were involved and their ECG recording time periods and environments were almost the same, age and gender were controlled, et al.; (2) instead of recording length, this study focus more on the influence of ECG recording time to HRV, and found the lowest heart rate complexity in the morning and highest complexity at noon, emphasizing the special role of morning in a day; (3) more detailed body postures (i.e., lying-left, lying-right, lying-back) were studied in addition to HRV comparison between sitting and lying; (4) more importantly, various of entropy and multi-scale entropy based measures were analyzed in this study, compared with traditional linear HRV metrics and nonlinear DFA indices, entropy and multi-scale entropy based measures were more sensitive to HRV variations, especially caused by ECG recording time, at recording length of 30–60 min, demonstrating that entropy based measures should be more helpful to detect the sub-healthy status or early-stage diseases that may result in minor variations from healthy HRV, especially during early morning.
5. Study Limitations and Future Directions
The presented study is a pilot study with 56 subjects, and thus the results cannot serve as the HRV norms. All participants were healthy young college students who do not represent the whole spectrum of healthy young people. Although we chose to collect data during weekend to reduce the influences of specific course learning during weekday, there are still diversities between college students and other young people.
To evaluate the influence of body postures, subjects were asked to read books (topic of general science) instead of resting (doing nothing). The protocol for recording ECG signals during different body postures lasted for 2.5 h. It is challenging to have the participants to maintain stable resting state for such a long period, thus reading book was used as an alternative protocol.
Gender-related differences were found for some HRV metrics under specific conditions in this study, and were not found for other metrics. Due to small sample size (with equal number for males and females), we didn’t evaluate group differences by gender in
Table 3,
Table 4,
Table 5 and
Table 6.
The ECG signals recorded in the period of 01:00–02:00 were picked up to represent sleeping state. According to sleep staging report, during this period, most subjects were in deep sleep, some subjects were in light sleep, and nobody was awake. The effects of different sleep stages on HRV should be further investigated in future studies, for example, we are analyzing HRV changes in different sleep stages in another ongoing study on 3–14 years children.
Due to limit of data acquisition time and financial support, other important factors have not been covered in this study, such as age, temperature and season, recording time length, mental stress, emotion, sampling rate, and so on. Further studies are needed to explore those interesting factors.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}