On the Information Bottleneck Problems: Models, Connections, Applications and Information Theoretic Views



.png)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Notation
2. The Information Bottleneck Problem
2.1. The Ib Relevance–Complexity Region
3. Solutions to the Information Bottleneck Problem
3.1. Solution for Particular Distributions: Gaussian and Binary Symmetric Sources
3.1.1. Binary IB
3.1.2. Vector Gaussian IB
3.2. Approximations for Generic Distributions
3.2.1. A Variational Bound
3.2.2. Known Distributions
3.3. Unknown Distributions
3.3.1. Variational IB
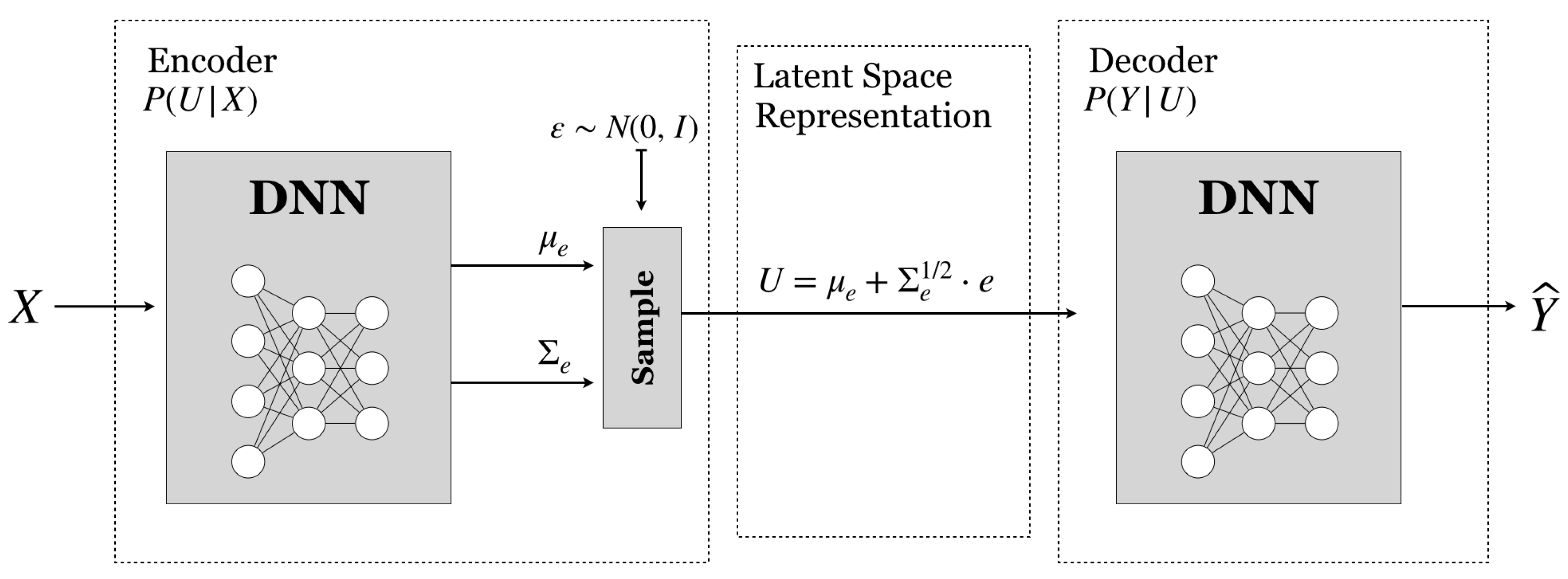
- Sampling from Gaussian Latent Spaces: When the latent space is a continuous vector space of dimension D, e.g., , we can consider multivariate Gaussian parametric encoders of mean , and covariance , i.e., . To sample , where and are determined as the output of a NN, sample a random variable i.i.d. and, given data sample , and generate the jth sample aswhere is a sample of , which is an independent Gaussian noise, and and are the output values of the NN with weights for the given input sample x.An example of the resulting DIB architecture to optimize with an encoder, a latent space, and a decoder parameterized by Gaussian distributions is shown in Figure 3.
- Sampling from a discrete latent space with the Gumbel-Softmax:If U is categorical random variable on the finite set of size D with probabilities ), we can encode it as D-dimensional one-hot vectors lying on the corners of the -dimensional simplex, . In general, costs functions involving sampling from categorical distributions are non-differentiable. Instead, we consider Concrete variables [62] (or Gumbel-Softmax [61]), which are continuous differentiable relaxations of categorical variables on the interior of the simplex, and are easy to sample. To sample from a Concrete random variable at temperature , with probabilities , sample i.i.d. (The distribution can be sampled by drawing and calculating .), and set for each of the components ofWe denote by the Concrete distribution with parameters . When the temperature approaches 0, the samples from the concrete distribution become one-hot and [61]. Note that, for discrete data models, standard application of Caratheodory’s theorem [64] shows that the latent variables U that appear in Equation (3) can be restricted to be with bounded alphabets size.
4. Connections to Coding Problems
4.1. Indirect Source Coding under Logarithmic Loss
4.2. Common Reconstruction
4.3. Information Combining
4.4. Wyner–Ahlswede–Korner Problem
4.5. The Privacy Funnel
4.6. Efficiency of Investment Information
5. Connections to Inference and Representation Learning
5.1. Inference Model
5.2. Minimum Description Length
5.3. Generalization and Performance Bounds
- The logarithmic-loss gives an upper bound on the probability of miss-classification (accuracy):
- The logarithmic-loss is equivalent to maximum likelihood for large n:
- The true distribution P minimizes the expected logarithmic-loss:
5.4. Representation Learning, Elbo and Autoencoders
5.5. Robustness to Adversarial Attacks
6. Extensions: Distributed Information Bottleneck
6.1. The Relevance–Complexity Region
6.2. Solutions to the Distributed Information Bottleneck
6.2.1. Vector Gaussian Model
6.3. Solutions for Generic Distributions
6.4. A Variational Bound
6.5. Known Memoryless Distributions
6.5.1. Distributed Variational IB
6.6. Connections to Coding Problems and Learning
6.6.1. Distributed Source Coding under Logarithmic Loss
6.6.2. Cloud RAN
6.6.3. Distributed Inference, ELBO and Multi-View Learning
7. Outlook
8. Proofs
8.1. Proof of Theorem 1
8.2. Proof of Proposition 1
8.3. Proof of Lemma 1
8.4. Proof of Theorem 2
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tishby, N.; Pereira, F.; Bialek, W. The information bottleneck method. In Proceedings of the Thirty-Seventh Annual Allerton Conference on Communication, Control, and Computing, Allerton House, Monticello, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- Pratt, W.K. Digital Image Processing; John Willey & Sons Inc.: New York, NY, USA, 1991. [Google Scholar]
- Yu, S.; Principe, J.C. Understanding Autoencoders with Information Theoretic Concepts. arXiv 2018, arXiv:1804.00057. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, S.; Jenssen, R.; Principe, J.C. Understanding Convolutional Neural Network Training with Information Theory. arXiv 2018, arXiv:1804.06537. [Google Scholar]
- Kong, Y.; Schoenebeck, G. Water from Two Rocks: Maximizing the Mutual Information. arXiv 2018, arXiv:1802.08887. [Google Scholar]
- Ugur, Y.; Aguerri, I.E.; Zaidi, A. A generalization of Blahut-Arimoto algorithm to computing rate-distortion regions of multiterminal source coding under logarithmic loss. In Proceedings of the IEEE Information Theory Workshop, ITW, Kaohsiung, Taiwan, 6–10 November 2017. [Google Scholar]
- Dobrushin, R.L.; Tsybakov, B.S. Information transmission with additional noise. IRE Trans. Inf. Theory 1962, 85, 293–304. [Google Scholar] [CrossRef]
- Witsenhausen, H.S.; Wyner, A.D. A conditional Entropy Bound for a Pair of Discrete Random Variables. IEEE Trans. Inf. Theory 1975, IT-21, 493–501. [Google Scholar] [CrossRef]
- Witsenhausen, H.S. Indirect Rate Distortion Problems. IEEE Trans. Inf. Theory 1980, IT-26, 518–521. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Tishby, N. Opening the Black Box of Deep Neural Networks via Information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Achille, A.; Soatto, S. Emergence of Invariance and Disentangling in Deep Representations. arXiv 2017, arXiv:1706.01350. [Google Scholar]
- McAllester, D.A. A PAC-Bayesian Tutorial with a Dropout Bound. arXiv 2013, arXiv:1307.2118. [Google Scholar]
- Alemi, A.A. Variational Predictive Information Bottleneck. arXiv 2019, arXiv:1910.10831. [Google Scholar]
- Mukherjee, S. Machine Learning using the Variational Predictive Information Bottleneck with a Validation Set. arXiv 2019, arXiv:1911.02210. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Mukherjee, S. General Information Bottleneck Objectives and their Applications to Machine Learning. arXiv 2019, arXiv:1912.06248. [Google Scholar]
- Strouse, D.; Schwab, D.J. The information bottleneck and geometric clustering. Neural Comput. 2019, 31, 596–612. [Google Scholar] [CrossRef] [PubMed]
- Painsky, A.; Tishby, N. Gaussian Lower Bound for the Information Bottleneck Limit. J. Mach. Learn. Res. (JMLR) 2018, 18, 7908–7936. [Google Scholar]
- Kittichokechai, K.; Caire, G. Privacy-constrained remote source coding. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 1078–1082. [Google Scholar]
- Tian, C.; Chen, J. Successive Refinement for Hypothesis Testing and Lossless One-Helper Problem. IEEE Trans. Inf. Theory 2008, 54, 4666–4681. [Google Scholar] [CrossRef] [Green Version]
- Sreekumar, S.; Gündüz, D.; Cohen, A. Distributed Hypothesis Testing Under Privacy Constraints. arXiv 2018, arXiv:1807.02764. [Google Scholar]
- Aguerri, I.E.; Zaidi, A.; Caire, G.; Shamai (Shitz), S. On the Capacity of Cloud Radio Access Networks with Oblivious Relaying. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2068–2072. [Google Scholar]
- Aguerri, I.E.; Zaidi, A.; Caire, G.; Shamai (Shitz), S. On the capacity of uplink cloud radio access networks with oblivious relaying. IEEE Trans. Inf. Theory 2019, 65, 4575–4596. [Google Scholar] [CrossRef] [Green Version]
- Stark, M.; Bauch, G.; Lewandowsky, J.; Saha, S. Decoding of Non-Binary LDPC Codes Using the Information Bottleneck Method. In Proceedings of the ICC 2019-2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Erdogmus, D. Information Theoretic Learning: Renyi’s Entropy and Its Applications to Adaptive System Training. Ph.D. Thesis, University of Florida Gainesville, Florida, FL, USA, 2002. [Google Scholar]
- Principe, J.C.; Euliano, N.R.; Lefebvre, W.C. Neural and Adaptive Systems: Fundamentals Through Simulations; Wiley: New York, NY, USA, 2000; Volume 672. [Google Scholar]
- Fisher, J.W. Nonlinear Extensions to the Minumum Average Correlation Energy Filter; University of Florida: Gainesville, FL, USA, 1997. [Google Scholar]
- Jiao, J.; Courtade, T.A.; Venkat, K.; Weissman, T. Justification of logarithmic loss via the benefit of side information. IEEE Trans. Inf. Theory 2015, 61, 5357–5365. [Google Scholar] [CrossRef] [Green Version]
- Painsky, A.; Wornell, G.W. On the Universality of the Logistic Loss Function. arXiv 2018, arXiv:1805.03804. [Google Scholar]
- Linsker, R. Self-organization in a perceptual network. Computer 1988, 21, 105–117. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Chow, C.; Liu, C. Approximating discrete probability distributions with dependence trees. IEEE Trans. Inf. Theory 1968, 14, 462–467. [Google Scholar] [CrossRef] [Green Version]
- Olsen, C.; Meyer, P.E.; Bontempi, G. On the impact of entropy estimation on transcriptional regulatory network inference based on mutual information. EURASIP J. Bioinf. Syst. Biol. 2008, 2009, 308959. [Google Scholar] [CrossRef] [Green Version]
- Pluim, J.P.; Maintz, J.A.; Viergever, M.A. Mutual-information-based registration of medical images: A survey. IEEE Trans. Med. Imaging 2003, 22, 986–1004. [Google Scholar] [CrossRef]
- Viola, P.; Wells, W.M., III. Alignment by maximization of mutual information. Int. J. Comput. Vis. 1997, 24, 137–154. [Google Scholar] [CrossRef]
- Cesa-Bianchi, N.; Lugosi, G. Prediction, Learning and Games; Cambridge University Press: New York, NY, USA, 2006. [Google Scholar]
- Lehmann, E.L.; Casella, G. Theory of Point Estimation; Springer Science & Business Media: Berlin, Germany, 2006. [Google Scholar]
- Bousquet, O.; Elisseeff, A. Stability and generalization. J. Mach. Learn. Res. 2002, 2, 499–526. [Google Scholar]
- Shalev-Shwartz, S.; Shamir, O.; Srebro, N.; Sridharan, K. Learnability, stability and uniform convergence. J. Mach. Learn. Res. 2010, 11, 2635–2670. [Google Scholar]
- Xu, A.; Raginsky, M. Information-theoretic analysis of generalization capability of learning algorithms. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2521–2530. [Google Scholar]
- Russo, D.; Zou, J. How much does your data exploration overfit? Controlling bias via information usage. arXiv 2015, arXiv:1511.05219. [Google Scholar] [CrossRef] [Green Version]
- Amjad, R.A.; Geiger, B.C. Learning Representations for Neural Network-Based Classification Using the Information Bottleneck Principle. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [Green Version]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef] [Green Version]
- Jiao, J.; Venkat, K.; Han, Y.; Weissman, T. Minimax estimation of functionals of discrete distributions. IEEE Trans. Inf. Theory 2015, 61, 2835–2885. [Google Scholar] [CrossRef] [PubMed]
- Valiant, P.; Valiant, G. Estimating the unseen: improved estimators for entropy and other properties. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2157–2165. [Google Scholar]
- Chalk, M.; Marre, O.; Tkacik, G. Relevant sparse codes with variational information bottleneck. arXiv 2016, arXiv:1605.07332. [Google Scholar]
- Alemi, A.; Fischer, I.; Dillon, J.; Murphy, K. Deep Variational Information Bottleneck. In Proceedings of the International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Achille, A.; Soatto, S. Information Dropout: Learning Optimal Representations Through Noisy Computation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2897–2905. [Google Scholar] [CrossRef] [Green Version]
- Harremoes, P.; Tishby, N. The information bottleneck revisited or how to choose a good distortion measure. In Proceedings of the 2007 IEEE International Symposium on Information Theory, Nice, France, 24–29 June 2007; pp. 566–570. [Google Scholar]
- Gamal, A.E.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Hotelling, H. The most predictable criterion. J. Educ. Psycol. 1935, 26, 139–142. [Google Scholar] [CrossRef]
- Globerson, A.; Tishby, N. On the Optimality of the Gaussian Information Bottleneck Curve; Technical Report; Hebrew University: Jerusalem, Israel, 2004. [Google Scholar]
- Chechik, G.; Globerson, A.; Tishby, N.; Weiss, Y. Information Bottleneck for Gaussian Variables. J. Mach. Learn. Res. 2005, 6, 165–188. [Google Scholar]
- Wieczorek, A.; Roth, V. On the Difference Between the Information Bottleneck and the Deep Information Bottleneck. arXiv 2019, arXiv:1912.13480. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- Blahut, R. Computation of channel capacity and rate-distortion functions. IEEE Trans. Inf. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef] [Green Version]
- Arimoto, S. An algorithm for computing the capacity of arbitrary discrete memoryless channels. IEEE Trans. Inf. Theory 1972, IT-18, 12–20. [Google Scholar] [CrossRef] [Green Version]
- Winkelbauer, A.; Matz, G. Rate-information-optimal gaussian channel output compression. In Proceedings of the 48th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 19–21 March 2014; pp. 1–5. [Google Scholar]
- Gálvez, B.R.; Thobaben, R.; Skoglund, M. The Convex Information Bottleneck Lagrangian. Entropy 2020, 20, 98. [Google Scholar] [CrossRef] [Green Version]
- Jang, E.; Gu, S.; Poole, B. Categorical Reparameterization with Gumbel-Softmax. arXiv 2017, arXiv:1611.01144. [Google Scholar]
- Maddison, C.J.; Mnih, A.; Teh, Y.W. The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables. arXiv 2016, arXiv:1611.00712. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lim, S.H.; Kim, Y.H.; Gamal, A.E.; Chung, S.Y. Noisy Network Coding. IEEE Trans. Inf. Theory 2011, 57, 3132–3152. [Google Scholar] [CrossRef]
- Courtade, T.A.; Weissman, T. Multiterminal source coding under logarithmic loss. IEEE Trans. Inf. Theory 2014, 60, 740–761. [Google Scholar] [CrossRef] [Green Version]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Academic Press: London, UK, 1981. [Google Scholar]
- Wyner, A.D.; Ziv, J. The rate-distortion function for source coding with side information at the decoder. IEEE Trans. Inf. Theory 1976, 22, 1–10. [Google Scholar] [CrossRef]
- Steinberg, Y. Coding and Common Reconstruction. IEEE Trans. Inf. Theory 2009, IT-11, 4995–5010. [Google Scholar] [CrossRef]
- Benammar, M.; Zaidi, A. Rate-Distortion of a Heegard-Berger Problem with Common Reconstruction Constraint. In Proceedings of the International Zurich Seminar on Information and Communication, Cambridge, MA, USA, 1–6 July 2016. [Google Scholar]
- Benammar, M.; Zaidi, A. Rate-distortion function for a heegard-berger problem with two sources and degraded reconstruction sets. IEEE Trans. Inf. Theory 2016, 62, 5080–5092. [Google Scholar] [CrossRef] [Green Version]
- Sutskover, I.; Shamai, S.; Ziv, J. Extremes of Information Combining. IEEE Trans. Inf. Theory 2005, 51, 1313–1325. [Google Scholar] [CrossRef]
- Land, I.; Huber, J. Information Combining. Found. Trends Commun. Inf. Theory 2006, 3, 227–230. [Google Scholar] [CrossRef] [Green Version]
- Wyner, A.D. On source coding with side information at the decoder. IEEE Trans. Inf. Theory 1975, 21, 294–300. [Google Scholar] [CrossRef]
- Ahlswede, R.; Korner, J. Source coding with side information and a converse for degraded broadcast channels. IEEE Trans. Inf. Theory 1975, 21, 629–637. [Google Scholar] [CrossRef]
- Makhdoumi, A.; Salamatian, S.; Fawaz, N.; Médard, M. From the information bottleneck to the privacy funnel. In Proceedings of the IEEE Information Theory Workshop, ITW, Hobart, Tasamania, Australia, 2–5 November 2014; pp. 501–505. [Google Scholar]
- Asoodeh, S.; Diaz, M.; Alajaji, F.; Linder, T. Information Extraction Under Privacy Constraints. IEEE Trans. Inf. Theory 2019, 65, 1512–1534. [Google Scholar] [CrossRef]
- Erkip, E.; Cover, T.M. The efficiency of investment information. IEEE Trans. Inf. Theory 1998, 44, 1026–1040. [Google Scholar] [CrossRef]
- Hinton, G.E.; van Camp, D. Keeping the Neural Networks Simple by Minimizing the Description Length of the Weights. In Proceedings of the Sixth Annual Conference on Computational Learning Theory; ACM: New York, NY, USA, 1993; pp. 5–13. [Google Scholar]
- Gilad-Bachrach, R.; Navot, A.; Tishby, N. An Information Theoretic Tradeoff between Complexity and Accuracy. In Learning Theory and Kernel Machines; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; pp. 595–609. [Google Scholar]
- Vera, M.; Piantanida, P.; Vega, L.R. The Role of Information Complexity and Randomization in Representation Learning. arXiv 2018, arXiv:1802.05355. [Google Scholar]
- Huang, S.L.; Makur, A.; Wornell, G.W.; Zheng, L. On Universal Features for High-Dimensional Learning and Inference. arXiv 2019, arXiv:1911.09105. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. β-VAE: Learning basic visual concepts with a constrained variational framework. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Machine Learning at Scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Engstrom, L.; Tran, B.; Tsipras, D.; Schmidt, L.; Madry, A. A rotation and a translation suffice: Fooling cnns with simple transformations. arXiv 2017, arXiv:1712.02779. [Google Scholar]
- Pensia, A.; Jog, V.; Loh, P.L. Extracting robust and accurate features via a robust information bottleneck. arXiv 2019, arXiv:1910.06893. [Google Scholar]
- Guo, D.; Shamai, S.; Verdu, S. Mutual Information and Minimum Mean-Square Error in Gaussian Channels. IEEE Trans. Inf. Theory 2005, 51, 1261–1282. [Google Scholar] [CrossRef] [Green Version]
- Dembo, A.; Cover, T.M.; Thomas, J.A. Information theoretic inequalities. IEEE Trans. Inf. Theory 1991, 37, 1501–1518. [Google Scholar] [CrossRef] [Green Version]
- Ekrem, E.; Ulukus, S. An Outer Bound for the Vector Gaussian CEO Problem. IEEE Trans. Inf. Theory 2014, 60, 6870–6887. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Willey & Sons Inc.: New York, NY, USA, 1991. [Google Scholar]
- Aguerri, I.E.; Zaidi, A. Distributed information bottleneck method for discrete and Gaussian sources. In Proceedings of the International Zurich Seminar on Information and Communication, IZS, Zurich, Switzerland, 21–23 February 2018. [Google Scholar]
- Aguerri, I.E.; Zaidi, A. Distributed Variational Representation Learning. arXiv 2018, arXiv:1807.04193. [Google Scholar]
- Winkelbauer, A.; Farthofer, S.; Matz, G. The rate-information trade-off for Gaussian vector channels. In Proceedings of the The 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 2849–2853. [Google Scholar]
- Ugur, Y.; Aguerri, I.E.; Zaidi, A. Rate region of the vector Gaussian CEO problem under logarithmic loss. In Proceedings of the 2018 IEEE Information Theory Workshop (ITW), Guangzhou, China, 25–29 November 2018. [Google Scholar]
- Ugur, Y.; Aguerri, I.E.; Zaidi, A. Vector Gaussian CEO Problem under Logarithmic Loss. arXiv 2018, arXiv:1811.03933. [Google Scholar]
- Simeone, O.; Erkip, E.; Shamai, S. On Codebook Information for Interference Relay Channels With Out-of-Band Relaying. IEEE Trans. Inf. Theory 2011, 57, 2880–2888. [Google Scholar] [CrossRef] [Green Version]
- Sanderovich, A.; Shamai, S.; Steinberg, Y.; Kramer, G. Communication Via Decentralized Processing. IEEE Tran. Inf. Theory 2008, 54, 3008–3023. [Google Scholar] [CrossRef] [Green Version]
- Lapidoth, A.; Narayan, P. Reliable communication under channel uncertainty. IEEE Trans. Inf. Theory 1998, 44, 2148–2177. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; El Gamal, A. Capacity Theorems for the Relay Channel. IEEE Trans. Inf. Theory 1979, 25, 572–584. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Tao, D.; Xu, C. A survey on multi-view learning. arXiv 2013, arXiv:1304.5634. [Google Scholar]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Dhillon, P.; Foster, D.P.; Ungar, L.H. Multi-view learning of word embeddings via CCA. In Proceedings of the 2011 Advances in Neural Information Processing Systems, Granada, Spain, 12–17 December 2011; pp. 199–207. [Google Scholar]
- Kumar, A.; Daumé, H. A co-training approach for multi-view spectral clustering. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 393–400. [Google Scholar]
- Gönen, M.; Alpaydın, E. Multiple kernel learning algorithms. J. Mach. Learn. Res. 2011, 12, 2211–2268. [Google Scholar]
- Jia, Y.; Salzmann, M.; Darrell, T. Factorized latent spaces with structured sparsity. In Proceedings of the Advances in Neural Information Processing Systems, Brno, Czech, 24–25 June 2010; pp. 982–990. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Strouse, D.J.; Schwab, D.J. The deterministic information bottleneck. Mass. Inst. Tech. Neural Comput. 2017, 26, 1611–1630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Homri, A.; Peleg, M.; Shitz, S.S. Oblivious Fronthaul-Constrained Relay for a Gaussian Channel. IEEE Trans. Commun. 2018, 66, 5112–5123. [Google Scholar] [CrossRef] [Green Version]
- du Pin Calmon, F.; Fawaz, N. Privacy against statistical inference. In Proceedings of the 2012 50th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 1–5 October 2012. [Google Scholar]
- Karasik, R.; Simeone, O.; Shamai, S. Robust Uplink Communications over Fading Channels with Variable Backhaul Connectivity. IEEE Trans. Commun. 2013, 12, 5788–5799. [Google Scholar]
- Chen, Y.; Goldsmith, A.J.; Eldar, Y.C. Channel capacity under sub-Nyquist nonuniform sampling. IEEE Trans. Inf. Theory 2014, 60, 4739–4756. [Google Scholar] [CrossRef] [Green Version]
- Kipnis, A.; Eldar, Y.C.; Goldsmith, A.J. Analog-to-Digital Compression: A New Paradigm for Converting Signals to Bits. IEEE Signal Process. Mag. 2018, 35, 16–39. [Google Scholar] [CrossRef] [Green Version]









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaidi, A.; Estella-Aguerri, I.; Shamai, S. On the Information Bottleneck Problems: Models, Connections, Applications and Information Theoretic Views. Entropy 2020, 22, 151. https://doi.org/10.3390/e22020151
Zaidi A, Estella-Aguerri I, Shamai S. On the Information Bottleneck Problems: Models, Connections, Applications and Information Theoretic Views. Entropy. 2020; 22(2):151. https://doi.org/10.3390/e22020151
Chicago/Turabian StyleZaidi, Abdellatif, Iñaki Estella-Aguerri, and Shlomo Shamai (Shitz). 2020. "On the Information Bottleneck Problems: Models, Connections, Applications and Information Theoretic Views" Entropy 22, no. 2: 151. https://doi.org/10.3390/e22020151
APA StyleZaidi, A., Estella-Aguerri, I., & Shamai, S. (2020). On the Information Bottleneck Problems: Models, Connections, Applications and Information Theoretic Views. Entropy, 22(2), 151. https://doi.org/10.3390/e22020151