An Entropy-Based Approach to Portfolio Optimization



Abstract
:1. Introduction
2. Modern Portfolio Theory
2.1. Markowitz Mean-Variance Portfolio Optimization (MVPO)
2.2. Practical Difficulties with MVPO
2.3. Literature Review
3. Entropy as a Risk Measure
3.1. Shannon Entropy (Information Theory)
3.2. Portfolio Optimization Based on Entropy
3.3. Probability Generating Functions
3.4. Portfolio Entropy Objective Function
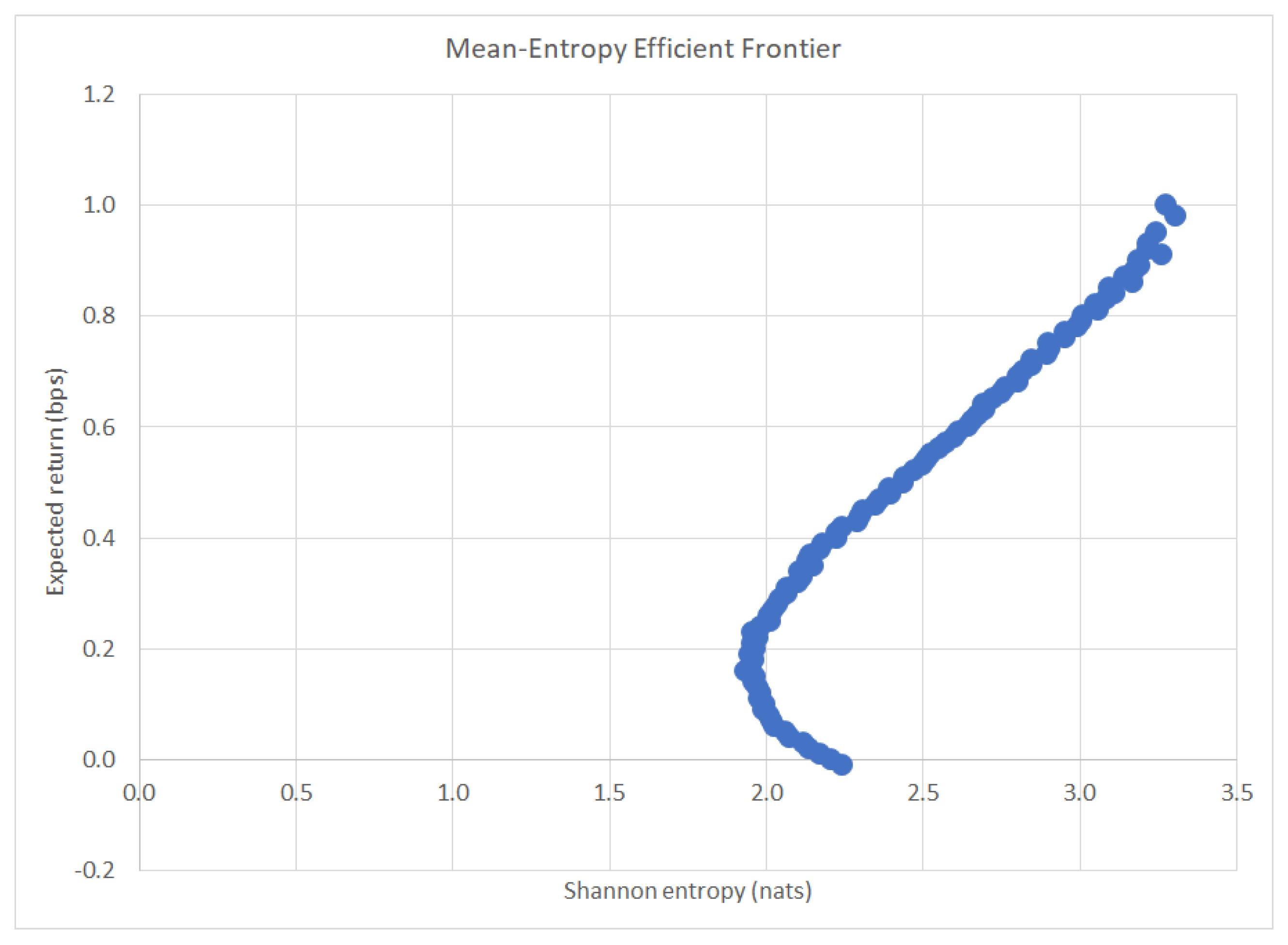
3.5. Return-Entropy Portfolio Optimization (REPO)
4. A Portfolio Selection Example Using REPO
4.1. Data
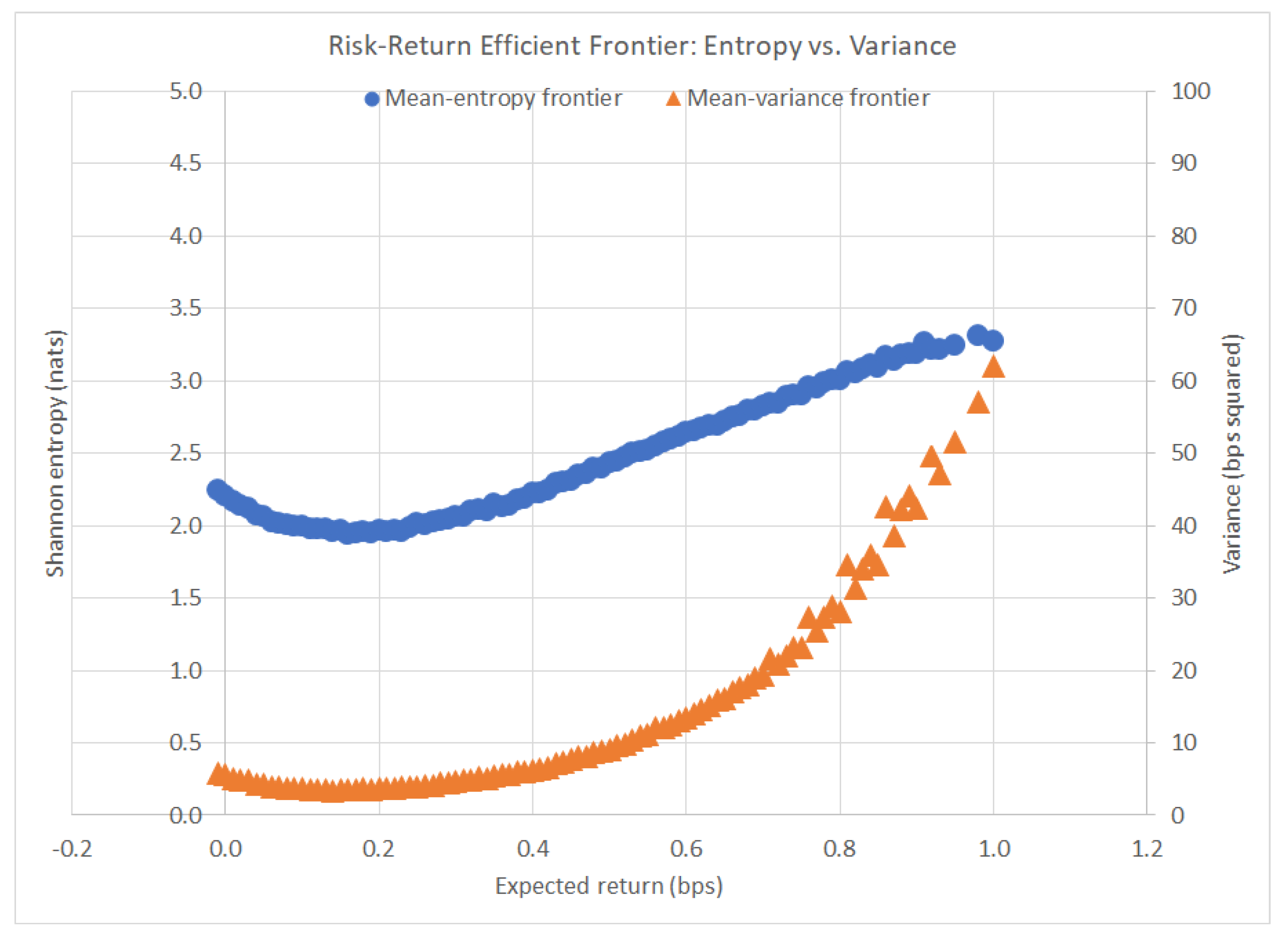
4.2. Efficient Frontier and Portfolio Selection
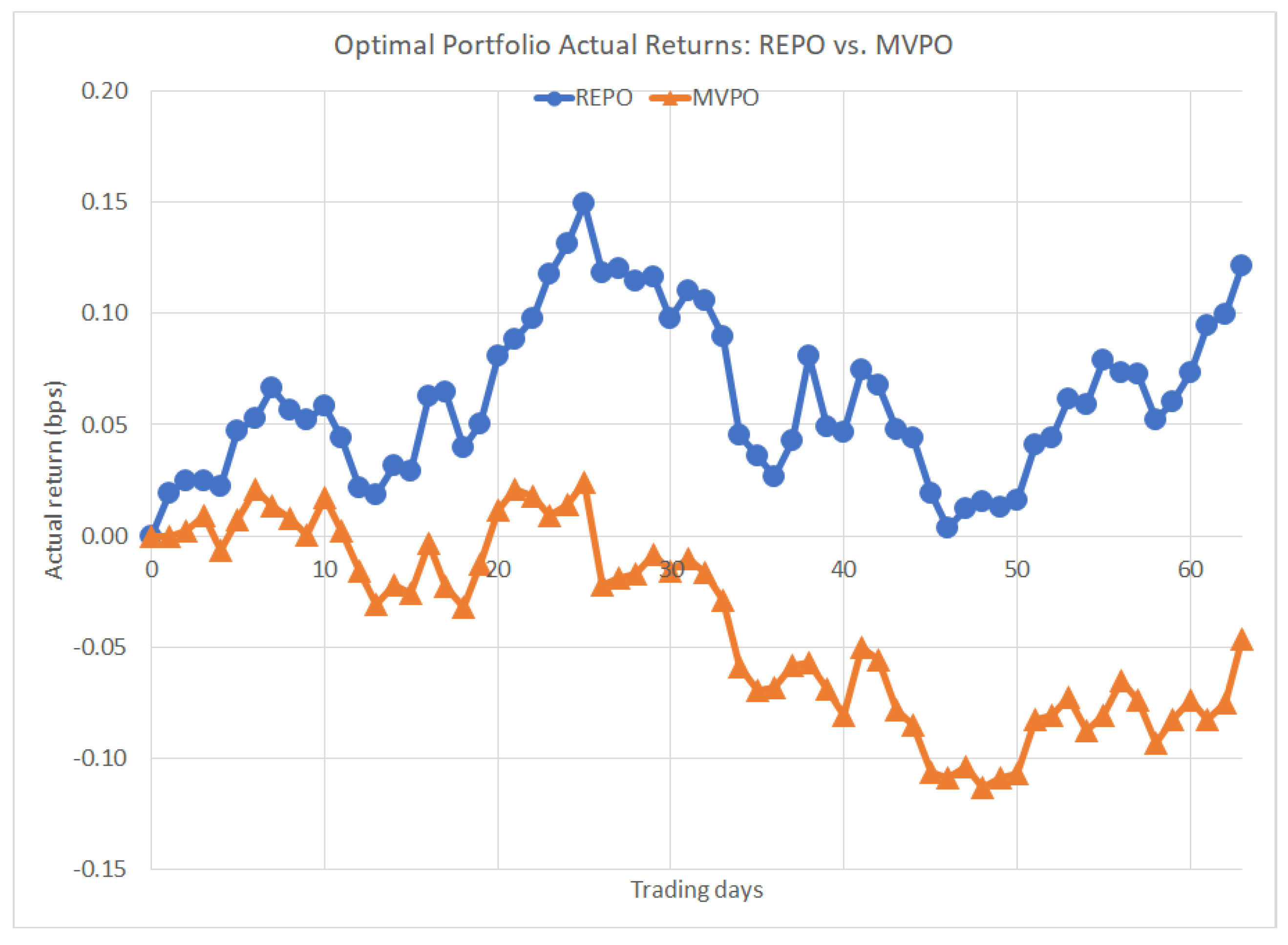
4.3. Comparison to MVPO
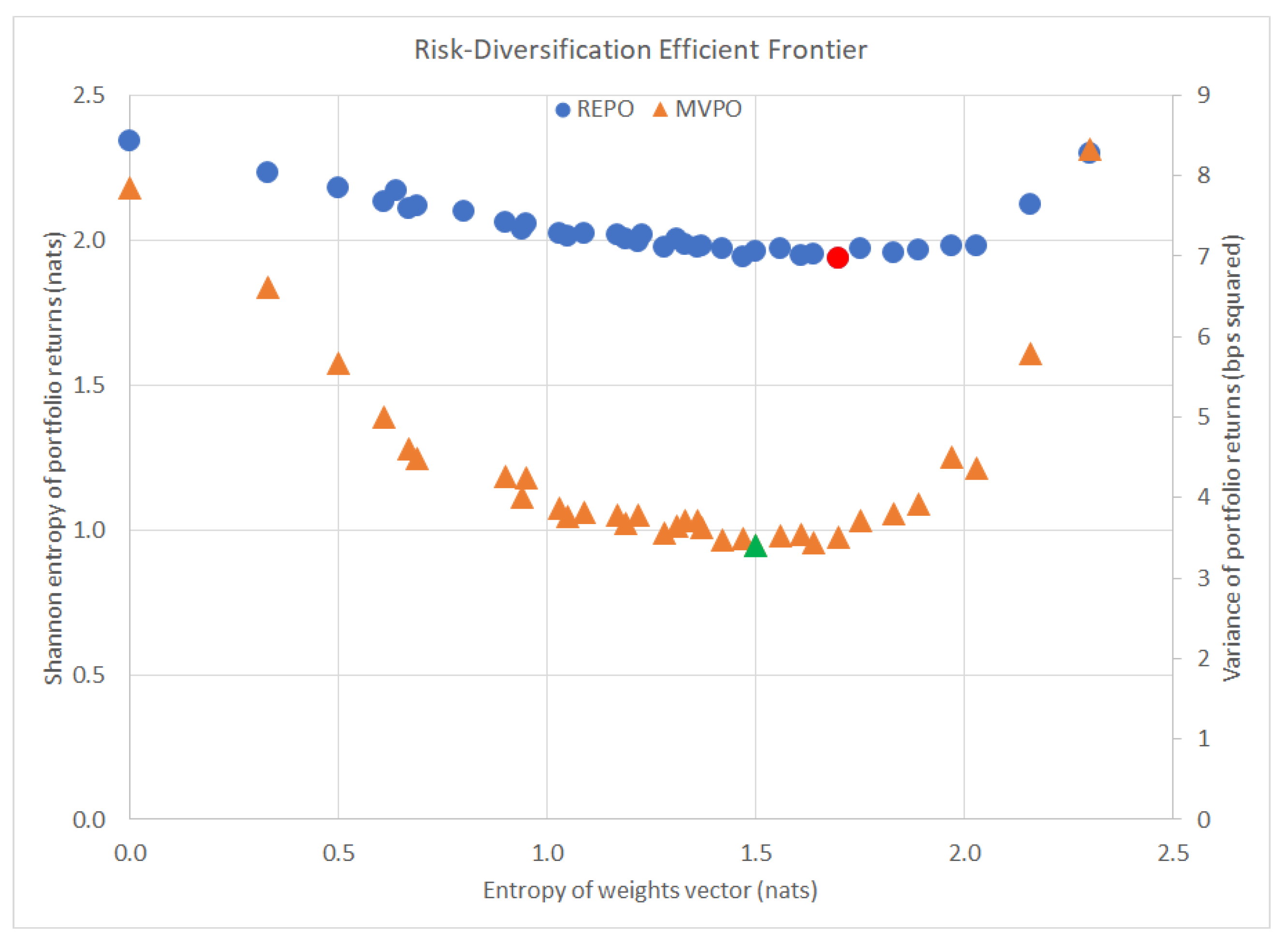
4.4. Addressing the Five Main Issues with MVPO
5. Conclusions
6. Materials and Methods
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| Bps | Basis points |
| CAPM | Capital asset pricing model |
| DEA | Data envelopment analysis |
| MED | Maximum entropy diversification |
| MQE | Mean-quadratic entropy |
| MSSS | Mean-semivariance-skewness-semikurtosis |
| MVPO | Mean-variance portfolio optimization |
| MVSE | Mean-variance-skewness-entropy |
| Nats | Natural units |
| PMPT | Post-modern portfolio theory |
| REPO | Return-entropy portfolio optimization |
Appendix A
References
- Markowitz, H. Portfolio Selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- Tobin, J. Liquidity Preference as Behavior Towards Risk. Rev. Econ. Stud. 1958, 25, 65–86. [Google Scholar] [CrossRef]
- Sharpe, W. Capital Asset Prices: A Theory of Market Equilibrium Under Conditions of Risk. J. Financ. 1964, 19, 425–442. [Google Scholar]
- Lintner, J. The Valuation of Risk Assets and the Selection of Risky Investments in Stock Portfolios and Capital Budgets. Rev. Econ. Stat. 1965, 47, 13–37. [Google Scholar] [CrossRef]
- Lintner, J. Securities Prices, Risk, and Maximal Gains from Diversification. J. Financ. 1965, 20, 587–615. [Google Scholar]
- Mossin, J. Equilibrium in a Capital Asset Market. Econometrica 1966, 34, 768–783. [Google Scholar] [CrossRef]
- Black, F. Global Asset Allocation With Equities, Bonds, and Currencies. In Goldman Sachs Fixed Income Research; Goldman Sachs: New York, NY, USA, 1991; pp. 1–40. [Google Scholar]
- Black, F. Global Portfolio Optimization. Financ. Anal. J. 1992, 48, 28–43. [Google Scholar] [CrossRef]
- McGill, W. Multivariate Information Transmission. Psychometrika 1954, 19, 97–116. [Google Scholar] [CrossRef]
- Garner, W. The Relation Between Information and Variance Analyses. Psychometrika 1956, 21, 219–228. [Google Scholar] [CrossRef]
- Philippatos, G. Entropy, Market Risk, and the Selection of Efficient Portfolios. Appl. Econ. 1972, 4, 209–220. [Google Scholar] [CrossRef]
- Cheng, C. Improving the Markowitz Model Using the Notion of Entropy. Available online: http://diva-portal.org/smash/get/diva2:304730/FULLTEXT01.pdf (accessed on 1 January 2020).
- Usta, I. Portfolio Optimization with Entropy Measure. Available online: https://www.researchgate.net/publication/261859605_Portfolio_optimization_with_entropy_measure (accessed on 1 January 2020).
- Huang, X. Portfolio Selection with Fuzzy Returns. J. Intell. Fuzzy Syst. 2007, 18, 383–390. [Google Scholar]
- Huang, X. Mean-Semivariance Models for Fuzzy Portfolio Selection. J. Comput. Appl. Math. 2008, 217, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Huang, X. An Entropy Method for Diversified Fuzzy Portfolio Selection. Int. J. Fuzzy Syst. 2012, 14, 161–165. [Google Scholar]
- Palo, G. On Entropy and Portfolio Diversification. J. Asset Manag. 2016, 17, 218–228. [Google Scholar]
- Abbas, A. A Kullback–Leibler View of Maximum Entropy and Maximum Log-Probability Methods. Entropy 2017, 19, 232. [Google Scholar] [CrossRef] [Green Version]
- Post, T. Portfolio Analysis Using Stochastic Dominance, Relative Entropy, and Empirical Likelihood. Manag. Sci. 2017, 63, 153–165. [Google Scholar] [CrossRef]
- Green, R. When Will Mean Variance Efficient Portfolios be Well Diversified? J. Financ. 1992, 47, 1785–1809. [Google Scholar] [CrossRef]
- Corvalán, A. Well Diversified Efficient Portfolios. Work. Pap. Cent. Bank Chile 2005, 336, 1–10. [Google Scholar]
- Koumou, G. Coherent Diversification Measures in Portfolio Theory. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3351423 (accessed on 1 January 2020).
- Yu, J. Diversified Portfolios with Different Entropy Measures. Appl. Math. Comput. 2014, 241, 47–63. [Google Scholar] [CrossRef]
- Rao, C.R. Diversity: Its Measurement, Decomposition, Apportionment and Analysis. Sankhya Indian J. Stat. Ser. A 1952, 44, 1–22. [Google Scholar]
- Rao, C.R. Diversity and Dissimilarity Coefficients: A Unified Approach. Theor. Popul. Biol. 1952, 21, 24–43. [Google Scholar] [CrossRef]
- Rao, C.R. Cross Entropy, Dissimilarity Measures, and Characterizations of Quadratic Entropy. IEEE Trans. Inf. Theory 1985, 31, 589–593. [Google Scholar] [CrossRef]
- Rao, C.R. Rao’s Axiomatization of Diversity Measures; John Wiley and Sons: New York, NY, USA, 2004. [Google Scholar]
- Rao, C.R. Quadratic Entropy and Analysis of Diversity. Sankhya Indian J. Stat. Ser. A 2010, 72, 70–80. [Google Scholar] [CrossRef]
- Carmichael, B. Unifying Portfolio Diversification Measures Using Rao’s Quadratic Entropy. CIRANO Tech. Rep. 2015, 16, 1–45. [Google Scholar] [CrossRef] [Green Version]
- Babaei, S. Multi-Objective Portfolio Optimization Considering the Dependence Structure of Asset Returns. Eur. J. Oper. Res. 2015, 244, 525–539. [Google Scholar] [CrossRef]
- Michaud, R. The Markowitz Optimization Enigma: Is Optimized Optimal? Financ. Anal. J. 1989, 45, 31–42. [Google Scholar] [CrossRef]
- Best, M. Sensitivity Analysis for Mean Variance Portfolio Problems. Manag. Sci. 1991, 37, 980–989. [Google Scholar] [CrossRef]
- Jorion, P. Portfolio Optimization in Practice. Financ. Anal. J. 1992, 48, 68–74. [Google Scholar] [CrossRef]
- Chopra, V. The Effect or Errors in Means, Variances, and Covariances on Optimal Portfolio Choice. J. Portf. Manag. 1993, 19, 6–11. [Google Scholar] [CrossRef]
- Jondeau, E. Conditional Asset Allocation under Non-Normality: How Costly Is the Mean-Variance Criterion. In Institute of Banking and Finance, HEC Lausanne; International Center for Financial Asset Management and Engineering: Geneva, Switzerland, 2005; pp. 1–42. [Google Scholar]
- Karandikar, R. Modelling in the Spirit of Markowitz Portfolio Theory in a Non-Gaussian World. Curr. Sci. 2012, 103, 666–672. [Google Scholar]
- Rom, B. Post-Modern Portfolio Theory Comes of Age. J. Investig. 1993, 3, 11–17. [Google Scholar] [CrossRef]
- Sortino, F. Performance Measurement in a Downside Risk Framework. J. Investig. 1994, 3, 59–64. [Google Scholar] [CrossRef]
- Jiang, L. Asymmetry in Stock Comovements: An Entropy Approach. J. Financ. Quant. Anal. 2018, 53, 1479–1507. [Google Scholar] [CrossRef]
- Lassance, N. Minimum Rényi Entropy Portfolios. In Annals of Operations Research; Springer: Berlin, Germany, 2019; pp. 1–37. [Google Scholar]
- Wong, W. An Improved Estimation to Make Markowitz’s Portfolio Optimization Theory Users Friendly and Estimation Accurate with Application on the US Stock Market Investment. Eur. J. Oper. Res. 2012, 222, 85–95. [Google Scholar] [CrossRef]
- Sun, R. Improved Covariance Matrix Estimation for Portfolio Risk Measurement: A Review. J. Risk Financ. Manag. 2019, 12, 48. [Google Scholar] [CrossRef] [Green Version]
- Rényi, A. On Measures of Information and Entropy. Proc. Fourth Berkeley Symp. Math. Stat. Probab. 1960, 4, 547–561. [Google Scholar]
- Bera, A. Optimal Portfolio Diversification Using Maximum Entropy Principle. Econom. Rev. 2008, 27, 484–512. [Google Scholar] [CrossRef]
- Asness, C. Speculative Leverage: A False Cure for Pension Woes. Financ. Anal. J. 2010, 66, 14–15. [Google Scholar] [CrossRef]
- Asness, C. Leverage Aversion and Risk Parity. Financ. Anal. J. 2012, 68, 47–59. [Google Scholar] [CrossRef] [Green Version]
- Usta, I. Mean-Variance-Skewness-Entropy Measures: A Multi-Objective Approach to Portfolio Selection. Entropy 2011, 13, 117–133. [Google Scholar] [CrossRef]
- Fono, L. Kurtosis and Semi-Kurtosis for Portfolio Selection with Fuzzy Returns. In Proceedings of the 58th World Statistics Congress of the International Statistical Institute, Dublin, Ireland, 21–26 August 2011; pp. 6517–6522. [Google Scholar]
- Urbanowicz, K. Entropy and Optimization of Portfolios. Available online: http://arxiv.org/pdf/1409.7002v1.pdf (accessed on 1 January 2020).
- Xu, Y. A Maximum Entropy Method for a Robust Portfolio Problem. Entropy 2014, 16, 3401–3415. [Google Scholar] [CrossRef] [Green Version]
- Geman, D. Tail Risk Constraints and Maximum Entropy. Entropy 2015, 17, 3724–3737. [Google Scholar] [CrossRef] [Green Version]
- Zhou, R. A Mean-Variance Hybrid-Entropy Model for Portfolio Selection with Fuzzy Returns. Entropy 2015, 17, 3319–3331. [Google Scholar] [CrossRef] [Green Version]
- Rotela, P. Entropic Data Envelopment Analysis: A Diversification Approach for Portfolio Optimization. Entropy 2017, 19, 352. [Google Scholar] [CrossRef] [Green Version]
- Zhou, R. Properties of Risk Measures of Generalized Entropy in Portfolio Selection. Entropy 2017, 19, 657. [Google Scholar] [CrossRef] [Green Version]
- Dai, W. Mean-Entropy Models for Uncertainty Portfolio Selection. In Multi-Objective Optimization; Springer: Singapore, 2018. [Google Scholar]
- Shannon, C. A Mathematical Theory of Communication: Part 1. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C. A Mathematical Theory of Communication: Part 2. Bell Syst. Tech. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Jensen, J. Sur les fonctions convexes et les inégalités entre les valeurs moyennes. Acta Math. 1906, 30, 175–193. [Google Scholar] [CrossRef]
- Silverman, B. Density Estimation for Statistics and Data Analysis; Chapman and Hall: London, UK, 1998. [Google Scholar]
- Beirlant, J. Nonparametric Entropy Estimation: An Overview. Int. J. Math. Stat. Sci. 1997, 6, 17–39. [Google Scholar]
- Learned-Miller, E. ICA Using Spacings Estimates of Entropy. J. Mach. Learn. Res. 2003, 4, 1271–1295. [Google Scholar]
- Rosenblatt, M. Remarks on Some Nonparametric Estimates of a Density Function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Parzen, E. On Estimation of a Probability Density Function and Mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Paninski, L. Estimation of Entropy and Mutual Information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef] [Green Version]
- Miller, G. Note on the Bias of Information Estimates. Inf. Theory Psychol. Probl. Methods 1955, 95–100. [Google Scholar]
- Cover, T. Elements of Information Theory; John Wiley and Sons: New York, NY, USA, 1991. [Google Scholar]
- Beaudry, N. An Intuitive Proof of the Data Processing Inequality. Quantum Inf. Comput. 2012, 12, 432–441. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Company Name | Ticker Symbol | Mean (bps) | Variance (bps) | Entropy (nats) |
|---|---|---|---|---|
| Loblaw Companies Ltd. | L | 0.006391 | 8.078711 | 2.381352 |
| First Quantum Minerals Ltd. | FM | 1.003592 | 61.97863 | 3.277249 |
| Thomson Reuters Corp | TRI | −0.019931 | 11.65211 | 2.534170 |
| Alimentation Couche-Tard Inc. | ATD.B | 0.495919 | 17.89425 | 2.798943 |
| Bank of Nova Scotia | BNS | 0.242633 | 11.32819 | 2.466258 |
| Teck Resources Ltd. | TECK.B | 0.729174 | 60.76170 | 3.259236 |
| Canadian Tire Corp Ltd. | CTC.A | 0.284006 | 12.18994 | 2.605140 |
| Inter Pipeline Ltd. | IPL | 0.211462 | 7.847551 | 2.339923 |
| Manulife Financial Corp | MFC | 0.095557 | 24.68777 | 2.746475 |
| Suncor Energy Inc. | SU | 0.424803 | 27.36700 | 2.907254 |
| Method | Minimum Objective | Expected Return | Optimal Solution |
|---|---|---|---|
| MVPO | 3.3993 bps | 0.1394 bps | (0.3,0.0,0.2,0.1,0.0,0.0,0.1,0.3,0.0,0.0) |
| REPO | 1.9355 nats | 0.1630 bps | (0.2,0.0,0.2,0.1,0.1,0.0,0.1,0.3,0.0,0.0) |
| Method | Expected Return | Optimal Solution |
|---|---|---|
| MVPO | 0.37 bps | (0.0,0.1,0.0,0.4,0.0,0.4,0.0,0.0,0.1,0.0) |
| REPO | 0.37 bps | (0.0,0.4,0.3,0.0,0.0,0.0,0.0,0.2,0.1,0.0) |
| REPO | MVPO | Total | % REPO > MVPO | |
|---|---|---|---|---|
| After 2 weeks | 2377 | 1792 | 4169 | 57% |
| After 4 weeks | 3115 | 1054 | 4169 | 75% |
| After 8 weeks | 2537 | 1632 | 4169 | 61% |
| After 13 weeks | 2345 | 1824 | 4169 | 56% |
| After 20 weeks | 1699 | 2470 | 4169 | 41% |
| Risk Tolerance | Portfolio Entropy | Expected Return | Optimal Solution |
|---|---|---|---|
| 1.9551 nats | 0.2311 bps | (0.1,0.0,0.1,0.1,0.2,0.0,0.1,0.3,0.0,0.1) | |
| 2.1317 nats | 0.3588 bps | (0.1,0.1,0.0,0.2,0.1,0.0,0.1,0.3,0.0,0.1) | |
| 2.1419 nats | 0.3660 bps | (0.1,0.1,0.0,0.2,0.1,0.0,0.2,0.2,0.0,0.1) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mercurio, P.J.; Wu, Y.; Xie, H. An Entropy-Based Approach to Portfolio Optimization. Entropy 2020, 22, 332. https://doi.org/10.3390/e22030332
Mercurio PJ, Wu Y, Xie H. An Entropy-Based Approach to Portfolio Optimization. Entropy. 2020; 22(3):332. https://doi.org/10.3390/e22030332
Chicago/Turabian StyleMercurio, Peter Joseph, Yuehua Wu, and Hong Xie. 2020. "An Entropy-Based Approach to Portfolio Optimization" Entropy 22, no. 3: 332. https://doi.org/10.3390/e22030332
APA StyleMercurio, P. J., Wu, Y., & Xie, H. (2020). An Entropy-Based Approach to Portfolio Optimization. Entropy, 22(3), 332. https://doi.org/10.3390/e22030332