Image Representation Method Based on Relative Layer Entropy for Insulator Recognition

 ,
,  , and
, and 
Abstract
:1. Introduction
2. Related Work
3. The Proposed Method
3.1. Deep Convolutional Neural Network Activations
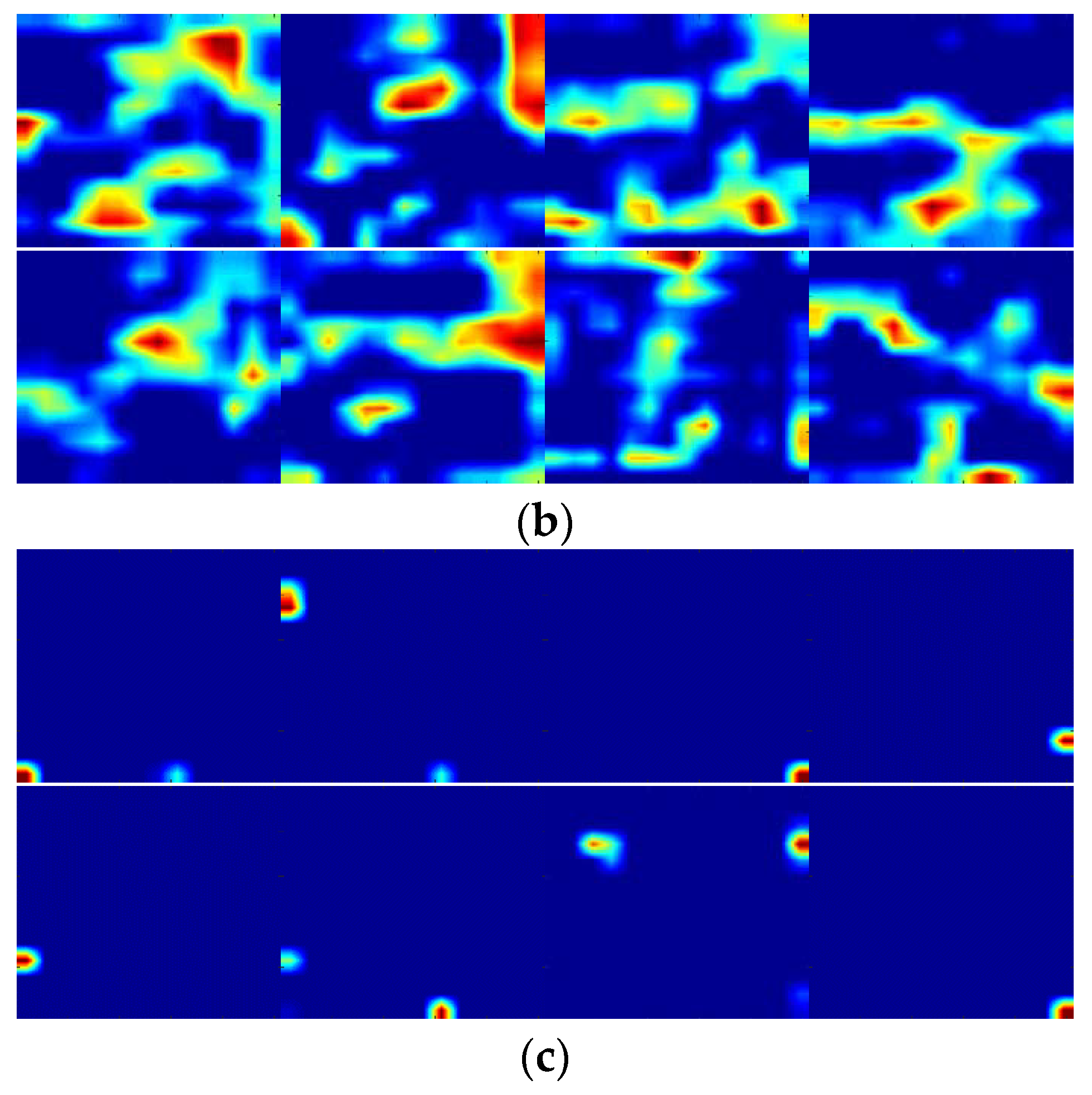
3.2. Deep Convolutional Layer Selection
3.3. In-Layer Feature Map Selection
3.4. Deep Convolutional Descriptor Aggregation
| Algorithm 1: Deep convolutional feature representation generation. |
| Input: Pretrained model, image I Output: IRM_RLE feature vector V(I) Procedure: 1. Extract deep feature maps from layer l, S = [S1,…,Si,…,Sn] 2. Layer entropy and relative layer entropy calculation 3. Deep convolutional layer selection 4. Compute importance degree of each feature maps 5. Select top-ranked Q feature maps 6. Extract deep descriptors from the feature map tensor X = (x1, x2, …, xn) 7. k-means clustering for codebook C = {c1, c2, …, ck} 8. Aggregating deep descriptors for i = 1 to n do t = index argmin d|cj, xi|, j ∈ {1, 2, …, k} v’t = v’t + (xi − ct) end for 9. Return: V(I) |
4. Experiments
4.1. Dataset and Experiment Setup
4.2. Results on the Infrared Insulator Dataset
4.3. Evaluation Experiment on Public Datasets
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jiang, H.; Jin, L.; Yan, S. Recognition and fault diagnosis of insulator string in aerial images. J. Mech. Electr. Eng. 2015, 32, 274–278. [Google Scholar]
- Zhao, Z.; Qi, H.; Qi, Y.; Zhang, K.; Zhai, Y.; Zhao, W. Detection Method Based on Automatic Visual Shape Clustering for Pin-Missing Defect in Transmission Lines. IEEE Trans. Instrum. Meas. 2020, 1. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, V.N.; Jenssen, R.; Roverso, D. Automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Int. J. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Xu, G.; Qi, Y. Representation of binary feature pooling for detection of insulator strings in infrared images. IEEE Trans. Dielectr. Electr. Insul. 2016, 23, 2858–2866. [Google Scholar] [CrossRef]
- Zhaohui, L.; Weiping, F.; Zihui, Y.; Yunpeng, L.; Jiangwei, W.; Shaotong, P. Insulator identification method based on infrared image. In Proceedings of the 2017 IEEE International Conference on Smart Grid and Smart Cities (ICSGSC), Singapore, 23–26 July 2017; pp. 137–141. [Google Scholar]
- Fang, J.; Wang, J.; Yang, L.; Wang, G.; Han, J.; Guo, S. Detection method of porcelain insulator contamination grade based on infrared-thermal-image. Trans. Chin. Soc. Agric. Eng. 2016, 32, 175–181. [Google Scholar]
- Shen-Pei, Z.; Xi, L.; Bing-Chen, Q.; Hui, H. Research on Insulator Fault Diagnosis and Remote Monitoring System Based on Infrared Images. Procedia Comput. Sci. 2017, 109, 1194–1199. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Y. Insulator identification from aerial images using Support Vector Machine with background suppression. In Proceedings of the 2016 International Conference on Unmanned Aircraft Systems (ICUAS), Arlington, VA, USA, 7–10 June 2016; pp. 892–897. [Google Scholar]
- Liu, Y.; Yong, J.; Liu, L.; Zhao, J.; Li, Z. The method of insulator recognition based on deep learning. In Proceedings of the 2016 4th International Conference on Applied Robotics for the Power Industry (CARPI), Jinan, China, 11–13 October 2016; pp. 1–5. [Google Scholar]
- Wu, Y. Research on Insulator Recognition Methods in Aerial Images Based on Machine Learning; North China Electric Power University: Baoding, China, 2016. [Google Scholar]
- Zhao, Z.; Xu, G.; Qi, Y.; Liu, N.; Zhang, T. Multi-patch deep features for power line insulator status classification from aerial images. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3187–3194. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Pdf ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Alrjebi, M.M.; Pathirage, N.; Liu, W.; Li, L. Face recognition against occlusions via colour fusion using 2D-MCF model and SRC. Pattern Recognit. Lett. 2017, 95, 14–21. [Google Scholar] [CrossRef]
- Guo, S.; Huang, W.; Wang, L.; Qiao, Y. Locally Supervised Deep Hybrid Model for Scene Recognition. IEEE Trans. Image Process. 2017, 26, 808–820. [Google Scholar] [CrossRef] [PubMed]
- Hariharan, B.; Arbelaez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Kulkarni, P.; Zepeda, J.; Jurie, F.; Pérez, P.; Chevallier, L.; Praveen, K. Hybrid multi-layer deep CNN/aggregator feature for image classification. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QC, Australia, 19–24 April 2015; pp. 1379–1383. [Google Scholar]
- Yosinski, J.; Clune, J.; Nguyen, A.; Fuchs, T.; Lipson, H. Understanding Neural Networks through Deep Visualization. In Proceedings of the International Conference on Machine Learning (ICML), Lile, France, 6–11 July 2015; pp. 1–12. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding computer vision. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Babenko, A.; Lempitsky, V. Aggregating Deep Convolutional Features for Image Retrieval. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1269–1277. [Google Scholar]
- Zheng, L.; Zhao, Y.; Wang, S.; Wang, J.; Tian, Q. Good Practice in CNN Feature Transfer. arXiv 2016, arXiv:1604.00133. [Google Scholar]
- Zhang, X.-Y.; Li, C.; Shi, H.; Zhu, X.; Li, P.; Dong, J. AdapNet: Adaptability Decomposing Encoder-Decoder Network for Weakly Supervised Action Recognition and Localization. IEEE Trans. Neural Networks Learn. Syst. 2020, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.-Y.; Wang, S.; Zhu, X.; Yun, X.; Wu, G.; Wang, Y. Update vs. upgrade: Modeling with indeterminate multi-class active learning. Neurocomputing 2015, 162, 163–170. [Google Scholar] [CrossRef]
- Zhang, X.-Y.; Shi, H.; Li, C.; Zheng, K.; Zhu, X.; Duan, L. Learning Transferable Self-Attentive Representations for Action Recognition in Untrimmed Videos with Weak Supervision. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–28 January 2019; Volume 33, pp. 9227–9234. [Google Scholar]
- Jégou, H.; Douze, M.; Schmid, C.; Perez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Jégou, H.; Perronnin, F.; Douze, M.; Sanchez, J.; Perez, P.; Schmid, C. Aggregating Local Image Descriptors into Compact Codes. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1704–1716. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, X.-S.; Luo, J.-H.; Wu, J.; Zhou, Z.-H. Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval. IEEE Trans. Image Process. 2017, 26, 2868–2881. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bau, D.; Zhou, B.; Khosla, A.; Oliva, A.; Torralba, A. Network Dissection: Quantifying Interpretability of Deep Visual Representations. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3319–3327. [Google Scholar]
- Zagoruyko, S.; Komodakis, N.; Wilson, R.C.; Hancock, E.R.; Smith, W.A.P.; Pears, N.E.; Bors, A.G. Wide Residual Networks. In Proceedings of the British Machine Vision Conference 2016, York, UK, 19–22 September 2016; pp. 1–12. [Google Scholar]
- Quattoni, A.; Torralba, A. Recognizing indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 413–420. [Google Scholar]
- Yao, B.; Jiang, X.; Khosla, A.; Lin, A.L.; Guibas, L.; Fei-Fei, L. Human action recognition by learning bases of action attributes and parts. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1331–1338. [Google Scholar]
- Fan, R.E.; Chang, K.W.; Hsieh, C.J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Gong, Y.; Wang, L.; Guo, R.; Lazebnik, S. Multi-scale Orderless Pooling of Deep Convolutional Activation Features. In Proceedings of the Lecture Notes in Computer Science; Springer Science and Business Media LLC: Berlin, Germany, 2014; Volume 8695, pp. 392–407. [Google Scholar]
- Azizpour, H.; Razavian, A.S.; Sullivan, J.; Maki, A.; Carlsson, S. From generic to specific deep representations for visual recognition. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 36–45. [Google Scholar]
- Liu, L.; Shen, C.; Hengel, A.V.D. The treasure beneath convolutional layers: Cross-convolutional-layer pooling for image classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4749–4757. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Size | ||
|---|---|---|---|
| Width | Height | Depth | |
| conv1_1 | 224 | 224 | 64 |
| conv1_2 | 224 | 224 | 64 |
| conv2_1 | 112 | 112 | 128 |
| conv2_2 | 112 | 112 | 128 |
| conv3_1 | 56 | 56 | 256 |
| conv3_2 | 56 | 56 | 256 |
| conv3_3 | 56 | 56 | 256 |
| conv4_1 | 28 | 28 | 512 |
| conv4_2 | 28 | 28 | 512 |
| conv4_3 | 28 | 28 | 512 |
| conv5_1 | 14 | 14 | 512 |
| conv5_2 | 14 | 14 | 512 |
| conv5_3 | 14 | 14 | 512 |
| Depth | Size of the Feature Maps | Descriptor Length | Accuracy (%) |
|---|---|---|---|
| conv2_1 | 112 × 112 × 128 | 1,254,400 | 0.9322 |
| conv2_2 | 112 × 112 × 128 | 1,254,400 | 0.9839 |
| conv3_1 | 56 × 56 × 256 | 313,600 | 0.9869 |
| conv3_2 | 56 × 56 × 256 | 313,600 | 0.9921 |
| conv3_3 | 56 × 56 × 256 | 313,600 | 0.9930 |
| conv4_1 | 28 × 28 × 512 | 78,400 | 0.9869 |
| conv4_2 | 28 × 28 × 512 | 78,400 | 0.9904 |
| conv4_3 | 28 × 28 × 512 | 78,400 | 0.9942 |
| conv5_1 | 14 × 14 × 512 | 19,600 | 0.9883 |
| conv5_2 | 14 × 14 × 512 | 19,600 | 0.9897 |
| conv5_3 | 14 × 14 × 512 | 19,600 | 0.9921 |
| Method | Accuracy |
|---|---|
| SPM | 34.40% |
| FV+Bag of parts | 63.18% |
| DPM | 37.60% |
| VLAD Multi-scale [37] | 66.12% |
| VLAD level 2 [37] | 65.52% |
| MOP-CNN [37] | 68.88% |
| Fine-tuning [38] | 66.00% |
| CNN-FC-SVM | 58.40% |
| CL+CNN-Jitter [39] | 71.50% |
| IRM_RLE | 68.88% |
| IRM_RLE | 70.52% |
| IRM_RLE | 66.87% |
| IRM_RLE [5_1, 5_2, 5_3] | 71.87% |
| Method | Accuracy |
|---|---|
| Sparse Bases | 45.7% |
| Color Action Recognition | 51.9% |
| Multiple Instance Learning | 55.6% |
| Very Deep Network | 71.7% |
| Action-Specific Detectors | 75.4% |
| Places365-VGG [40] | 49.20% |
| Places205-VGG [40] | 53.33% |
| ImageNet-VGG [40] | 66.63% |
| Hybrid1365-VGG [40] | 68.11% |
| IRM_RLE 5-1 | 70.05% |
| IRM_RLE 5-2 | 69.50% |
| IRM_RLE 5-3 | 69.38% |
| IRM_RLE [5-1, 5-2, 5-3] | 72.23% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Z.; Qi, H.; Fan, X.; Xu, G.; Qi, Y.; Zhai, Y.; Zhang, K. Image Representation Method Based on Relative Layer Entropy for Insulator Recognition. Entropy 2020, 22, 419. https://doi.org/10.3390/e22040419
Zhao Z, Qi H, Fan X, Xu G, Qi Y, Zhai Y, Zhang K. Image Representation Method Based on Relative Layer Entropy for Insulator Recognition. Entropy. 2020; 22(4):419. https://doi.org/10.3390/e22040419
Chicago/Turabian StyleZhao, Zhenbing, Hongyu Qi, Xiaoqing Fan, Guozhi Xu, Yincheng Qi, Yongjie Zhai, and Ke Zhang. 2020. "Image Representation Method Based on Relative Layer Entropy for Insulator Recognition" Entropy 22, no. 4: 419. https://doi.org/10.3390/e22040419
APA StyleZhao, Z., Qi, H., Fan, X., Xu, G., Qi, Y., Zhai, Y., & Zhang, K. (2020). Image Representation Method Based on Relative Layer Entropy for Insulator Recognition. Entropy, 22(4), 419. https://doi.org/10.3390/e22040419