Long-Range Dependence in Financial Markets: A Moving Average Cluster Entropy Approach



Abstract
:1. Introduction
- Heterogeneity. Volatility series have been analysed by using the cluster entropy approach over a constant temporal horizon (six years of tick-by-tick data sampled every minute). An information measure of heterogeneity, the Market Heterogeneity Index, where T and n are respectively the volatility and moving average windows, has been developed by integrating the cluster entropy curves of the volatility series over the cluster length . It has been also shown that the Market Heterogeneity Index can be used to yield the weights of an efficient portfolio as a complement to Markowitz and Sharpe traditional approaches for markets not consistent with Gaussian conditions [22].
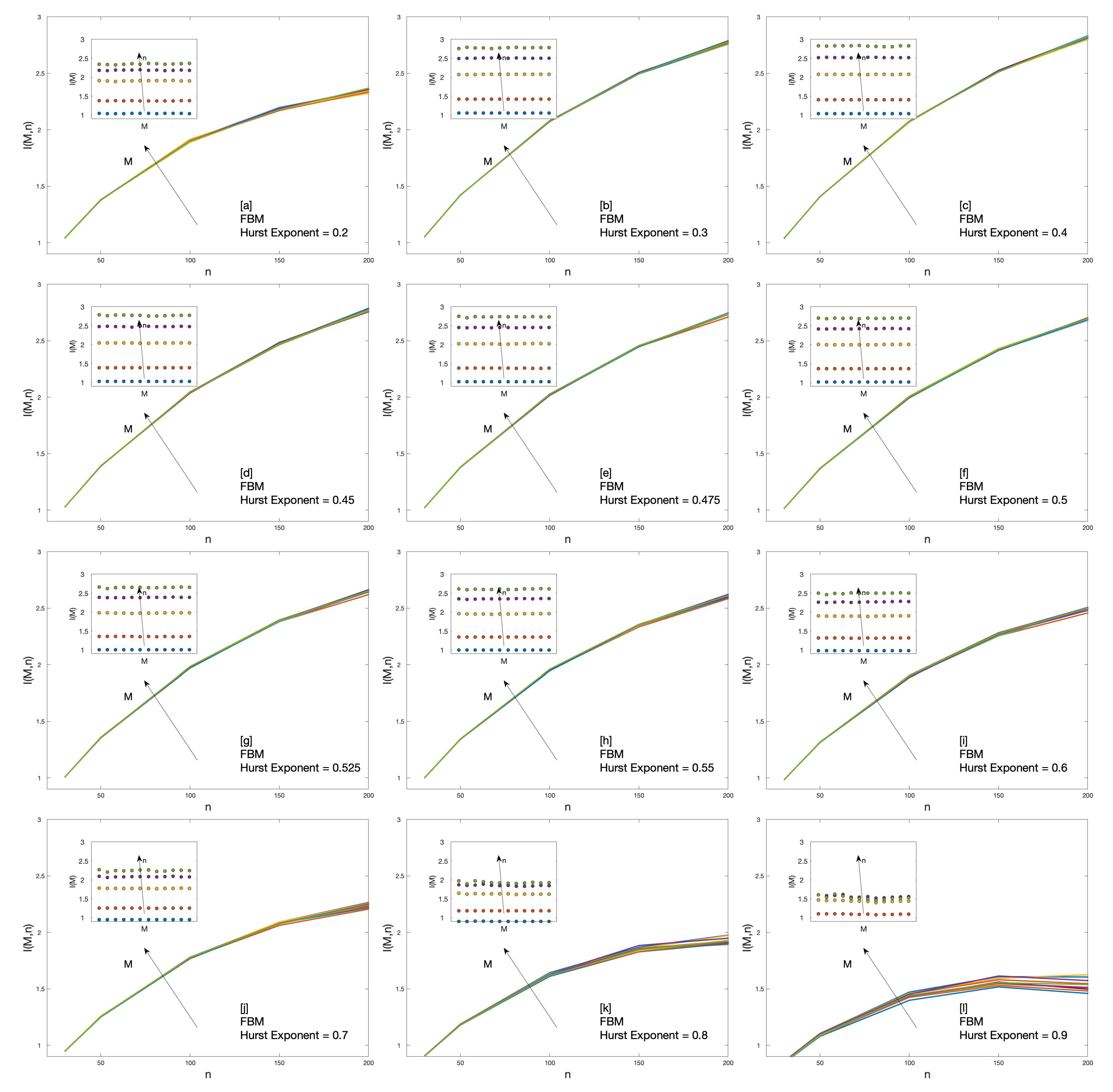
- Dynamics. Prices series have been investigated by using the cluster entropy approach over several temporal horizons (ranging from one to twelve months of tick-by-tick data with sampling interval between 1 up to 20 seconds depending on the specific market). The study has revealed a systematic dependence of the cluster entropy over time horizons in the investigated markets. The Market Dynamic Index, where M is the temporal horizon and n is the moving average window, defined as the integral of the cluster entropy over , demonstrates its ability to quantify the dynamics of assets’ prices over consecutive time periods in a single figure [23].
2. Methods and Data
2.1. Cluster Entropy Method
2.2. Financial Data
2.3. Artificial Data
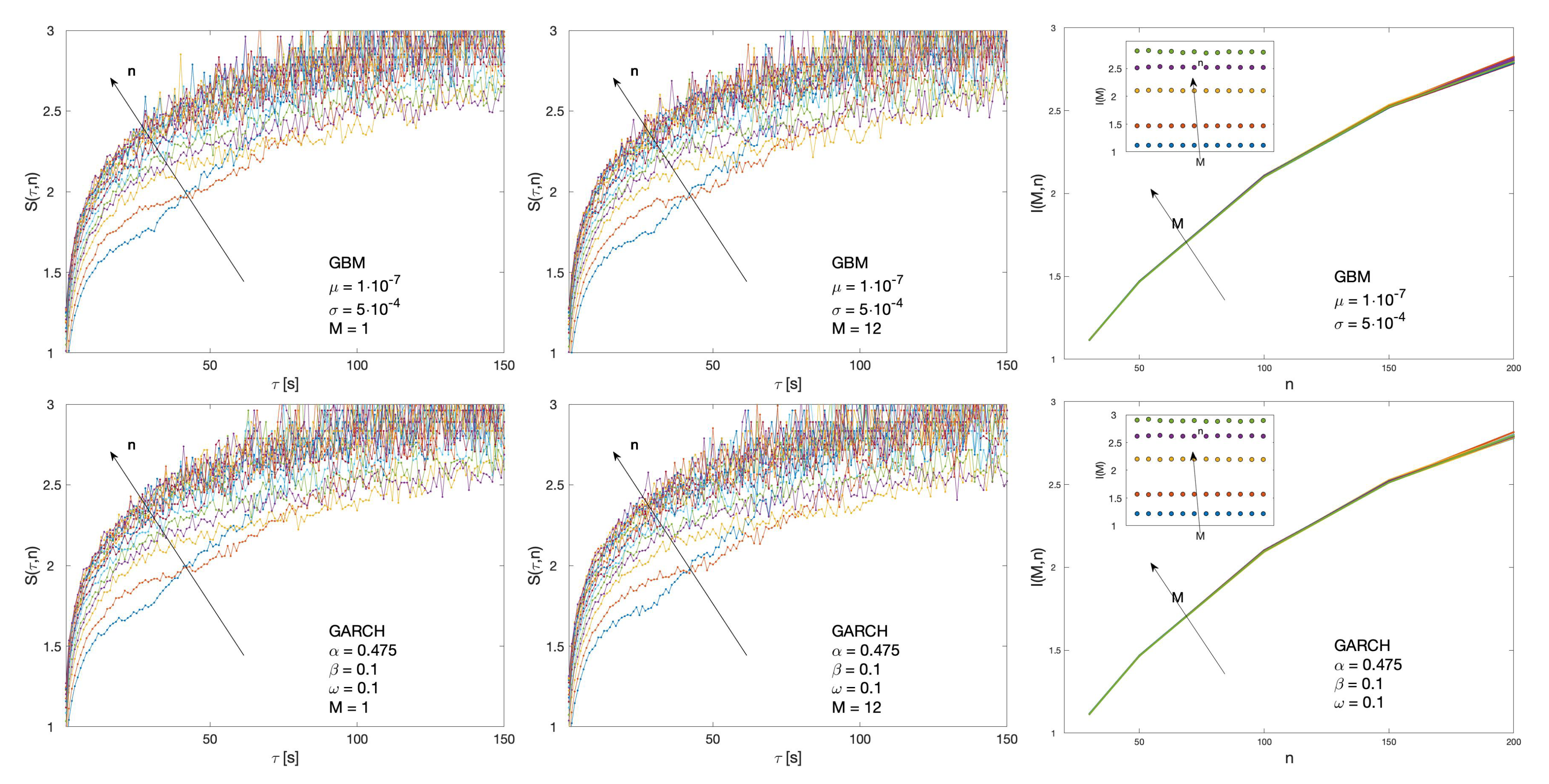
2.3.1. Geometric Brownian Motion
2.3.2. Autoregressive Conditional Heteroskedasticity Models
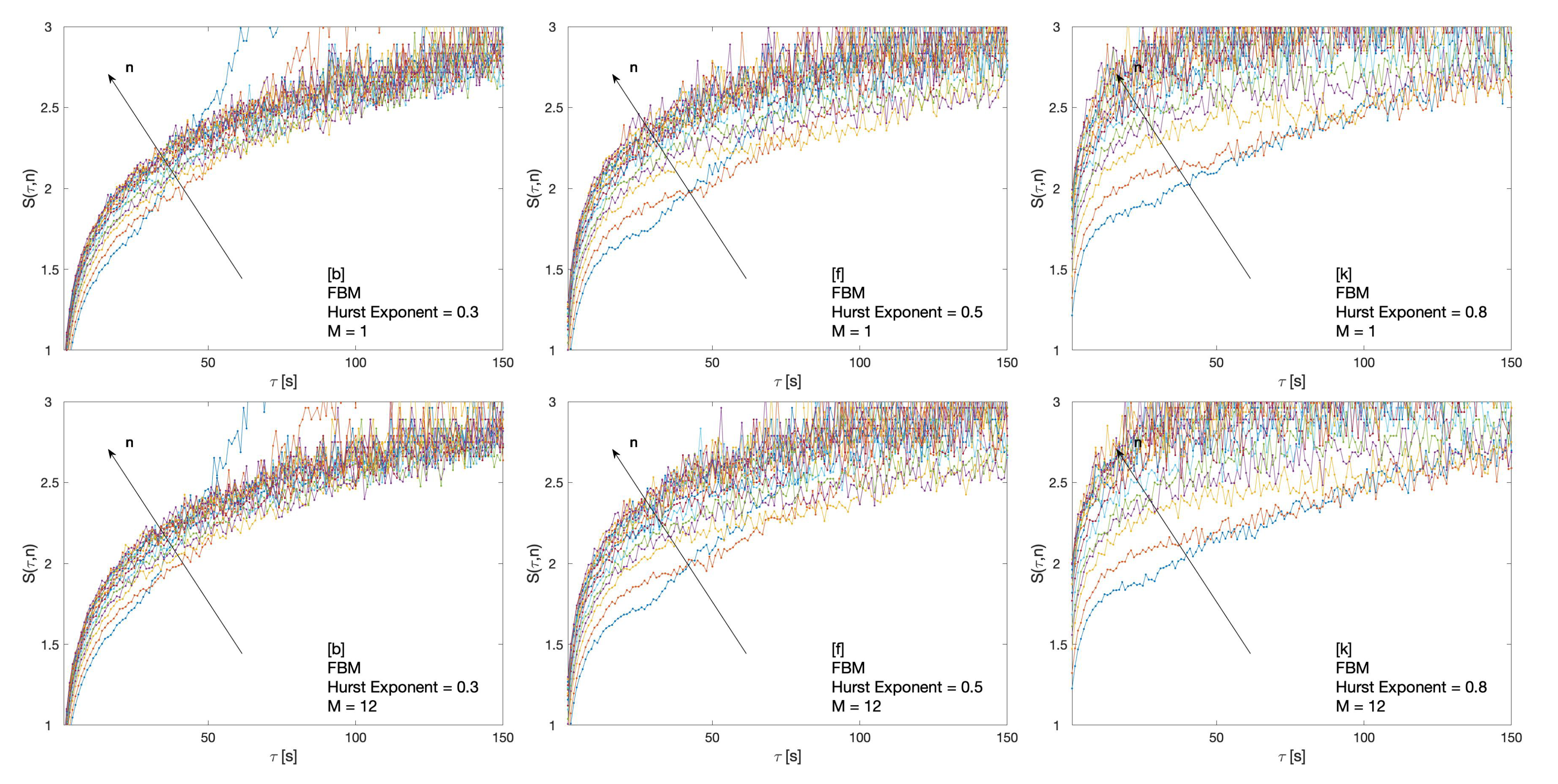
2.3.3. Fractional Brownian Motion
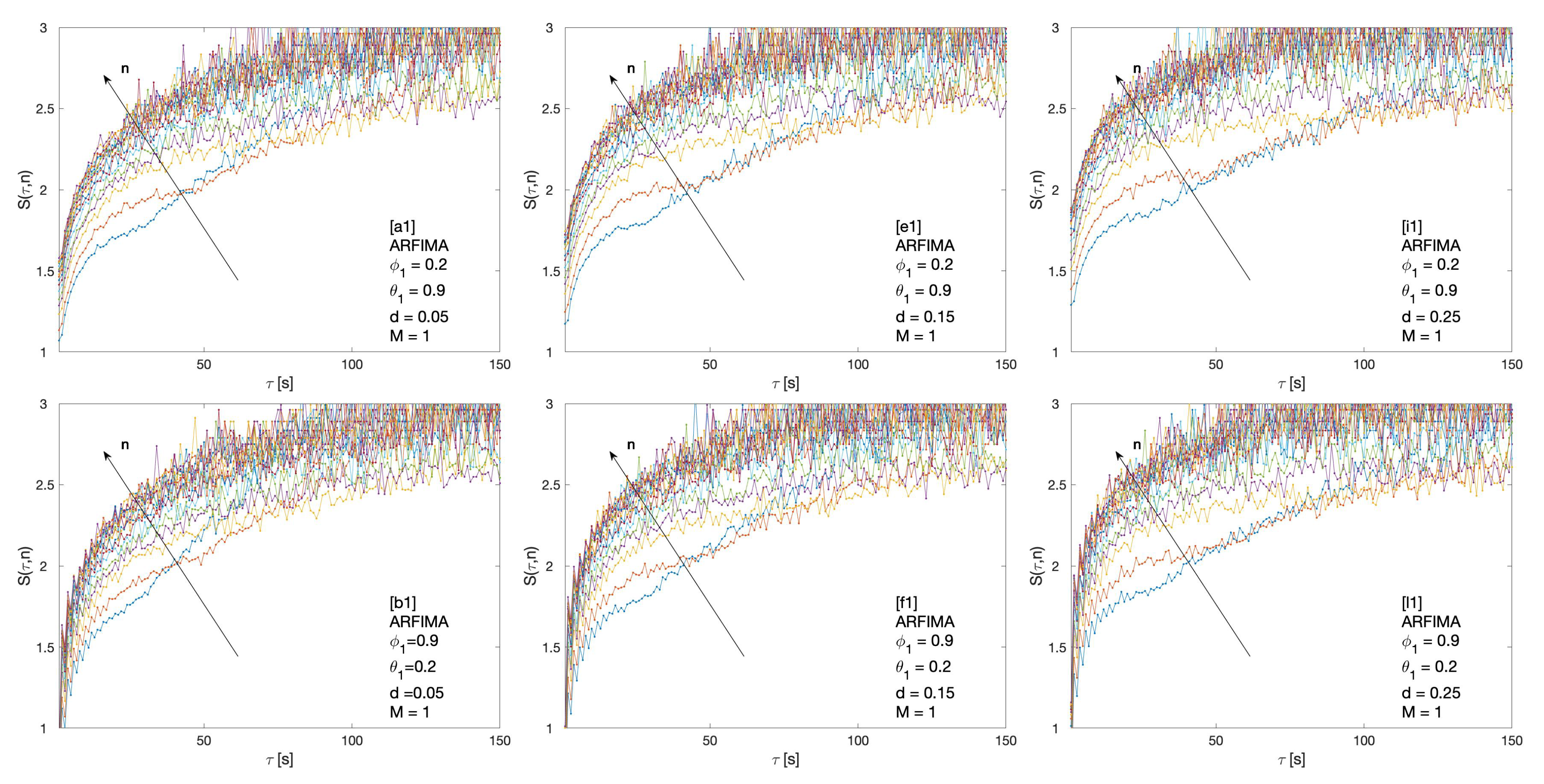
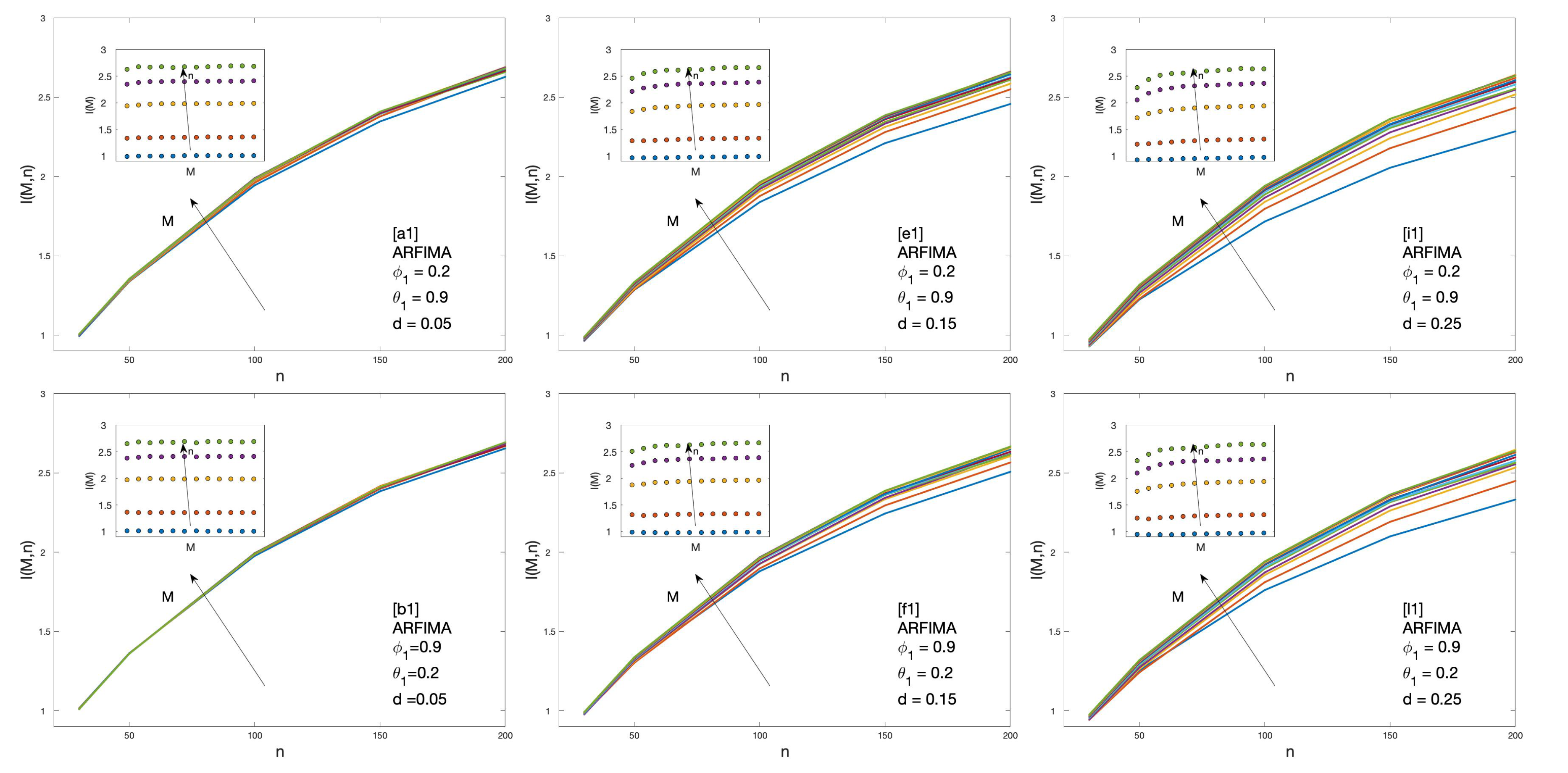
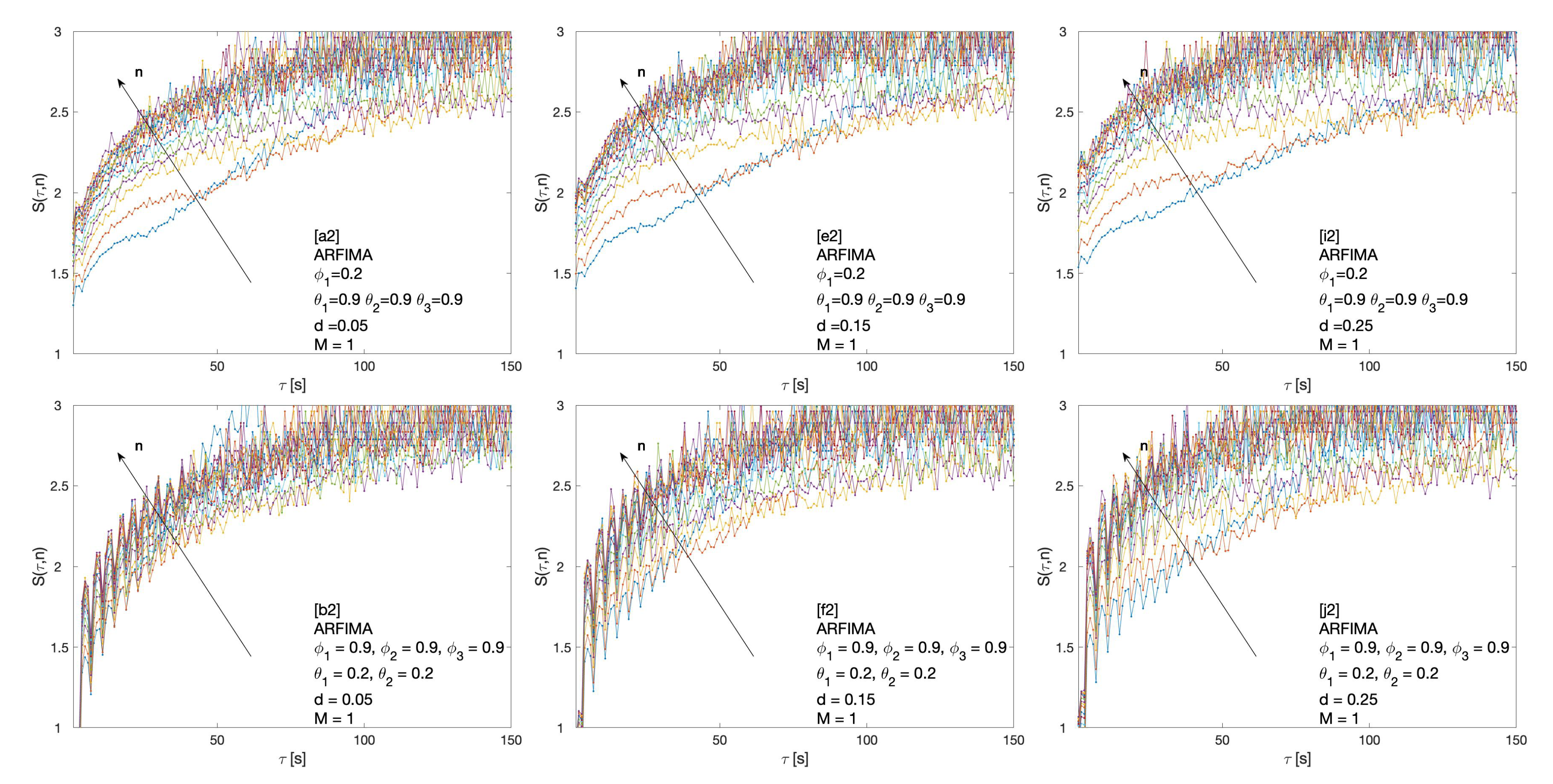
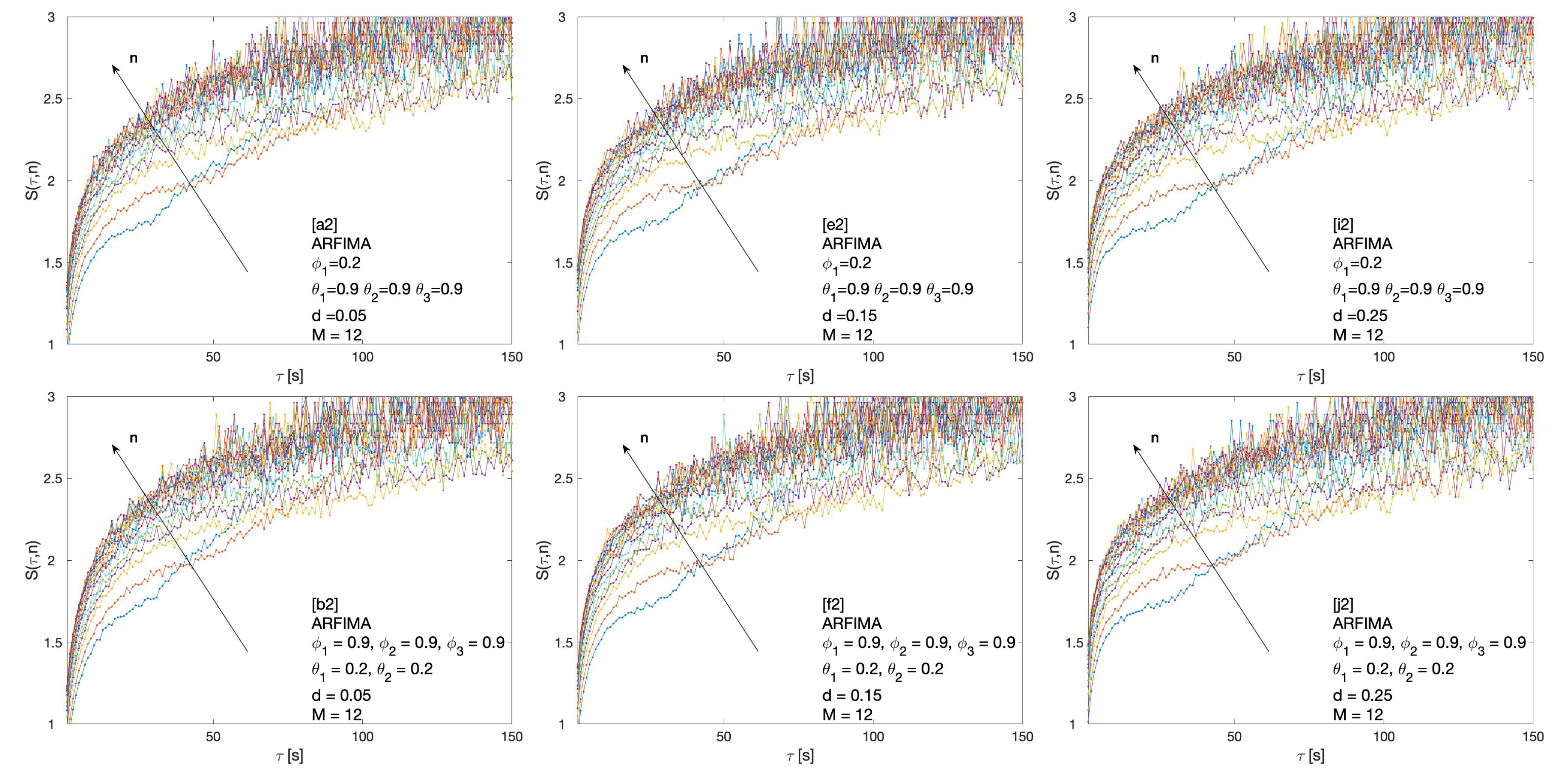
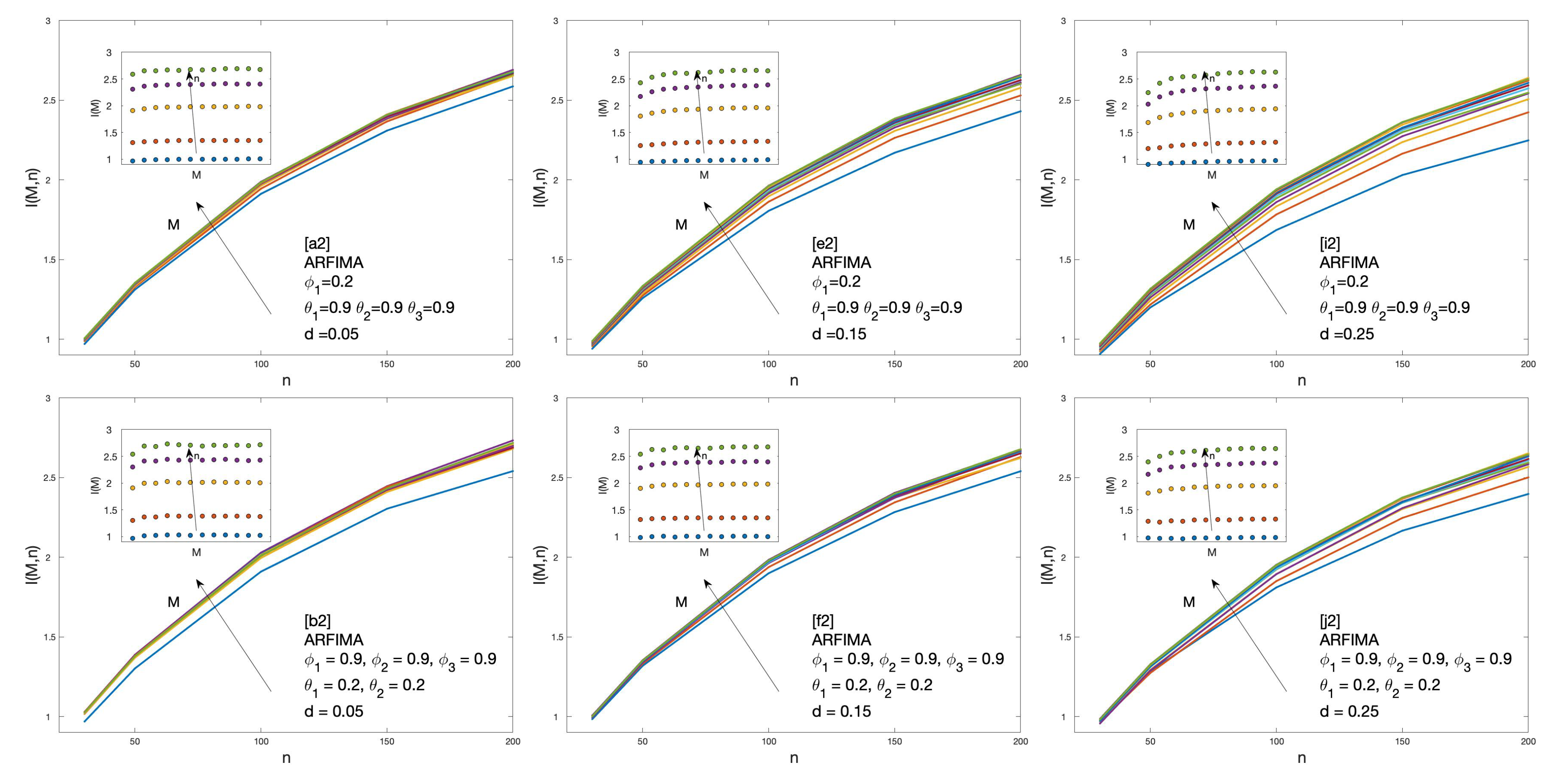
2.3.4. Autoregressive Fractionally Integrated Moving Average
3. Results
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Grassberger, P.; Procaccia, I. Characterization of strange attractors. Phys. Rev. Lett. 1983, 50, 346. [Google Scholar] [CrossRef]
- Crutchfield, J.P. Between order and chaos. Nat. Phys. 2012, 8, 17–24. [Google Scholar] [CrossRef]
- Ormos, M.; Zibriczky, D. Entropy-based financial asset pricing. PLoS ONE 2014, 9, e115742. [Google Scholar] [CrossRef] [PubMed]
- Yang, J. Information Theoretic Approaches in Economics. J. Econ. Surv. 2018, 32, 940–960. [Google Scholar] [CrossRef]
- Ghosh, A.; Julliard, C.; Taylor, A.P. What Is the Consumption-CAPM Missing? An Information-Theoretic Framework for the Analysis of Asset Pricing Models. Rev. Financ. Stud. 2017, 30, 442–504. [Google Scholar] [CrossRef]
- Backus, D.; Chernov, M.; Zin, S. Sources of entropy in representative agent models. J. Financ. 2014, 69, 51–99. [Google Scholar] [CrossRef] [Green Version]
- Zhou, R.; Cai, R.; Tong, G. Applications of entropy in finance: A review. Entropy 2013, 15, 4909–4931. [Google Scholar] [CrossRef]
- Shalizi, C.R.; Shalizi, K.L.; Haslinger, R. Quantifying self-organization with optimal predictors. Phys. Rev. Lett. 2004, 93, 118701. [Google Scholar] [CrossRef] [Green Version]
- Carbone, A.; Castelli, G.; Stanley, H.E. Analysis of clusters formed by the moving average of a long-range correlated time series. Phys. Rev. E 2004, 69, 026105. [Google Scholar] [CrossRef] [Green Version]
- Carbone, A.; Stanley, H.E. Scaling properties and entropy of long-range correlated time series. Phys. A 2007, 384, 21–24. [Google Scholar] [CrossRef]
- Carbone, A. Information Measure for Long-Range Correlated Sequences: The Case of the 24 Human Chromosomes. Sci. Rep. 2013, 3, 2721. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, X.; Sun, Y.; Li, X.; Shang, P. Multiscale transfer entropy: Measuring information transfer on multiple time scales. Commun. Nonlinear Sci. Numer. Simul. 2018, 62, 202–212. [Google Scholar] [CrossRef]
- Humeau-Heurtier, A. The multiscale entropy algorithm and its variants: A review. Entropy 2015, 17, 3110–3123. [Google Scholar] [CrossRef] [Green Version]
- Niu, H.; Wang, J. Quantifying complexity of financial short-term time series by composite multiscale entropy measure. Commun. Nonlinear Sci. Numer. Simul. 2015, 22, 375–382. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication, Part I, Part II. Bell Syst. Tech. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Three approaches to the quantitative definition ofinformation’. Probl. Inf. Transm. 1965, 1, 1–7. [Google Scholar]
- Li, M.; Vitányi, P. An Introduction to Kolmogorov Complexity and Its Applications; Springer: Berlin/Heidelberg, Germany, 2008; Volume 3. [Google Scholar]
- Marcon, E.; Scotti, I.; Hérault, B.; Rossi, V.; Lang, G. Generalization of the partitioning of Shannon diversity. PLoS ONE 2014, 9, e90289. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rubido, N.; Grebogi, C.; Baptista, M.S. Entropy-based generating Markov partitions for complex systems. Chaos 2018, 28, 033611. [Google Scholar] [CrossRef] [Green Version]
- Darbellay, G.A.; Vajda, I. Estimation of the information by an adaptive partitioning of the observation space. IEEE Trans. Inf. Theory 1999, 45, 1315–1321. [Google Scholar] [CrossRef] [Green Version]
- Steuer, R.; Molgedey, L.; Ebeling, W.; Jimenez-Montaño, M.A. Entropy and optimal partition for data analysis. Eur. Phys. J. B 2001, 19, 265–269. [Google Scholar] [CrossRef]
- Ponta, L.; Carbone, A. Information measure for financial time series: Quantifying short-term market heterogeneity. Phys. A 2018, 510, 132–144. [Google Scholar] [CrossRef]
- Ponta, L.; Murialdo, P.; Carbone, A. Quantifying horizon dependence of asset prices: A cluster entropy approach. arXiv 2019, arXiv:1908.00257. Available online: https://arxiv.org/abs/1908.00257 (accessed on 20 May 2020).
- Vera-Valdés, J.E. On Long Memory Origins and Forecast Horizons. J. Forecast. 2020. [Google Scholar] [CrossRef] [Green Version]
- Graves, T.; Franzke, C.L.; Watkins, N.W.; Gramacy, R.B.; Tindale, E. Systematic inference of the long-range dependence and heavy-tail distribution parameters of ARFIMA models. Phys. A 2017, 473, 60–71. [Google Scholar] [CrossRef]
- Bhattacharyya, R.; Datta, R.P. The Dynamics of India’s Major Exchange Rates. Glob. Bus. Rev. 2020. [Google Scholar] [CrossRef]
- Bhardwaj, G.; Swanson, N. An empirical investigation of the usefulness of ARFIMA models for predicting macroeconomic and financial time series. J. Econom. 2006, 131, 539–578. [Google Scholar] [CrossRef] [Green Version]
- Baillie, R.T.; Kongcharoen, C.; Kapetanios, G. Prediction from ARFIMA models: Comparisons between MLE and semiparametric estimation procedures. Int. J. Forecast. 2012, 28, 46–53. [Google Scholar] [CrossRef]
- Engle, R.F.; Rangel, J.G. The spline-GARCH model for low-frequency volatility and its global macroeconomic causes. Rev. Financ. Stud. 2008, 21, 1187–1222. [Google Scholar] [CrossRef]
- Lee, C.L.; Stevenson, S.; Lee, M.L. Low-frequency volatility of real estate securities and macroeconomic risk. Account. Financ. 2018, 58, 311–342. [Google Scholar] [CrossRef]
- Adrian, T.; Rosenberg, J. Stock returns and volatility: Pricing the short-run and long-run components of market risk. J. Financ. 2008, 63, 2997–3030. [Google Scholar] [CrossRef] [Green Version]
- Chernov, M.; Gallant, A.R.; Ghysels, E.; Tauchen, G. Alternative models for stock price dynamics. J. Econom. 2003, 116, 225–257. [Google Scholar] [CrossRef] [Green Version]
- Cotter, J.; Stevenson, S. Modeling long memory in REITs. Real Estate Econ. 2008, 36, 533–554. [Google Scholar] [CrossRef] [Green Version]
- Mandelbrot, B.B.; Van Ness, J.W. Fractional Brownian Motions, Fractional Noises and Applications. SIAM Rev. 1968, 10, 422–437. [Google Scholar] [CrossRef]
- Moving Average Cluster Entropy Code. Available online: https://www.dropbox.com/sh/9pfeltf2ks0ewjl/AACjuScK_gZxmyQ_mDFmGHoya?dl=0 (accessed on 20 May 2020).
- Geometric Brownian Motion Code. Available online: https://it.mathworks.com/help/finance/gbm.html (accessed on 20 May 2020).
- Generalized Autoregressive Conditional Hetereskedastic Code. Available online: https://www.mathworks.com/help/econ/garch.html (accessed on 20 May 2020).
- Fractional Brownian Motion Code. Available online: https://project.inria.fr/fraclab/ (accessed on 20 May 2020).
- Autoregressive Fractional Integrated Moving Average Code. Available online: https://www.mathworks.com/matlabcentral/fileexchange/25611-arfima-simulations (accessed on 20 May 2020).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| M | ||||
|---|---|---|---|---|
| 1 | 586,866 | 586,866 | 1.0000 | 1 |
| 2 | 1,117,840 | 586,866 | 1.9048 | 1 |
| 3 | 1,704,706 | 586,866 | 2.9048 | 2 |
| 4 | 2,291,572 | 586,866 | 3.9048 | 3 |
| 5 | 2,906,384 | 586,866 | 4.9524 | 4 |
| 6 | 3,493,250 | 586,866 | 5.9524 | 5 |
| 7 | 4,069,315 | 586,866 | 6.9340 | 6 |
| 8 | 4,712,062 | 586,866 | 8.0292 | 8 |
| 9 | 5,243,029 | 586,866 | 8.9339 | 8 |
| 10 | 5,885,781 | 586,866 | 10.0292 | 10 |
| 11 | 6,461,845 | 586,866 | 11.0108 | 11 |
| 12 | 6,982,017 | 586,866 | 11.8971 | 11 |
| D | H | d | |||
|---|---|---|---|---|---|
| 1.45 | 0.55 | 0.05 | 0.20 | 0.90 | a1 |
| 0.90 | 0.20 | b1 | |||
| 1.40 | 0.60 | 0.10 | 0.20 | 0.90 | c1 |
| 0.90 | 0.20 | d1 | |||
| 1.35 | 0.65 | 0.15 | 0.20 | 0.90 | e1 |
| 0.90 | 0.20 | f1 | |||
| 1.30 | 0.70 | 0.20 | 0.20 | 0.90 | g1 |
| 0.90 | 0.20 | h1 | |||
| 1.25 | 0.75 | 0.25 | 0.20 | 0.90 | i1 |
| 0.30 | 0.40 | j1 | |||
| 0.85 | k1 | ||||
| 0.90 | 0.20 | l1 | |||
| 0.40 | m1 | ||||
| 0.85 | n1 | ||||
| 1.20 | 0.80 | 0.30 | 0.20 | 0.90 | o1 |
| 0.90 | 0.20 | p1 | |||
| 1.02 | 0.98 | 0.48 | 0.30 | 0.40 | q1 |
| 0.85 | r1 | ||||
| 0.90 | 0.40 | s1 | |||
| 0.85 | t1 |
| D | H | d | Label | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1.45 | 0.55 | 0.05 | 0.20 | - | - | 0.90 | 0.90 | 0.90 | a2 |
| 0.90 | 0.90 | 0.90 | 0.20 | 0.20 | - | b2 | |||
| 1.40 | 0.60 | 0.10 | 0.20 | - | - | 0.90 | 0.90 | 0.90 | c2 |
| 0.90 | 0.90 | 0.90 | 0.20 | 0.20 | - | d2 | |||
| 1.35 | 0.65 | 0.15 | 0.20 | - | - | 0.90 | 0.90 | 0.90 | e2 |
| 0.90 | 0.90 | 0.90 | 0.20 | 0.20 | - | f2 | |||
| 1.30 | 0.70 | 0.20 | 0.20 | - | - | 0.90 | 0.90 | 0.90 | g2 |
| 0.90 | 0.90 | 0.90 | 0.20 | 0.20 | - | h2 | |||
| 1.25 | 0.75 | 0.25 | 0.20 | - | - | 0.90 | 0.90 | 0.90 | i2 |
| 0.90 | 0.90 | 0.90 | 0.20 | 0.20 | - | j2 | |||
| 1.20 | 0.80 | 0.30 | 0.20 | - | - | 0.90 | 0.90 | 0.90 | k2 |
| 0.40 | 0.16 | - | 0.90 | 0.81 | 0.73 | l2 | |||
| 0.90 | 0.90 | 0.90 | 0.20 | 0.20 | - | m2 | |||
| 1.15 | 0.85 | 0.35 | 0.20 | - | - | 0.90 | 0.90 | 0.90 | n2 |
| 1.02 | 0.98 | 0.48 | 0.40 | 0.16 | - | 0.90 | 0.81 | 0.73 | o2 |
| M | [b1] | [f1] | [l1] | [a2] | [e2] | [i2] | [n2] | [o2] |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.9597 | 0.7938 | 0.6013 | 0.8519 | 0.6779 | 0.4956 | 0.3542 | 0.2314 |
| 2 | 0.9863 | 0.8429 | 0.6985 | 0.9293 | 0.7883 | 0.6566 | 0.5414 | 0.4304 |
| 3 | 0.9820 | 0.8789 | 0.7743 | 0.938 | 0.8346 | 0.7362 | 0.6468 | 0.5576 |
| 4 | 0.9848 | 0.8922 | 0.8031 | 0.956 | 0.8689 | 0.7827 | 0.7147 | 0.6380 |
| 5 | 0.9878 | 0.9062 | 0.8325 | 0.9608 | 0.8809 | 0.8102 | 0.7528 | 0.6911 |
| 6 | 0.9940 | 0.9197 | 0.8517 | 0.9724 | 0.9043 | 0.8417 | 0.7840 | 0.7322 |
| 7 | 0.9785 | 0.9186 | 0.8633 | 0.9617 | 0.9038 | 0.8521 | 0.8036 | 0.7614 |
| 8 | 0.9930 | 0.9321 | 0.8775 | 0.9762 | 0.9229 | 0.8710 | 0.8333 | 0.7931 |
| 9 | 0.9867 | 0.9370 | 0.8890 | 0.9737 | 0.9273 | 0.8809 | 0.8438 | 0.8100 |
| 10 | 0.9813 | 0.9333 | 0.8952 | 0.9710 | 0.9261 | 0.8880 | 0.8533 | 0.8195 |
| 11 | 0.9816 | 0.9436 | 0.9011 | 0.9749 | 0.9326 | 0.8965 | 0.8643 | 0.8342 |
| 12 | 0.9853 | 0.9451 | 0.9072 | 0.9741 | 0.9353 | 0.9019 | 0.8764 | 0.8508 |
| M | NASDAQ | S&P500 | DJIA |
|---|---|---|---|
| 1 | 0.5154 | 0.7399 | 0.8892 |
| 2 | 0.6026 | 0.8335 | 0.9257 |
| 3 | 0.6470 | 0.8588 | 0.9332 |
| 4 | 0.6631 | 0.8814 | 0.9283 |
| 5 | 0.6823 | 0.9018 | 0.9417 |
| 6 | 0.7124 | 0.9246 | 0.9534 |
| 7 | 0.7162 | 0.9224 | 0.9461 |
| 8 | 0.7288 | 0.9309 | 0.9618 |
| 9 | 0.7370 | 0.9479 | 0.9645 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Murialdo, P.; Ponta, L.; Carbone, A. Long-Range Dependence in Financial Markets: A Moving Average Cluster Entropy Approach. Entropy 2020, 22, 634. https://doi.org/10.3390/e22060634
Murialdo P, Ponta L, Carbone A. Long-Range Dependence in Financial Markets: A Moving Average Cluster Entropy Approach. Entropy. 2020; 22(6):634. https://doi.org/10.3390/e22060634
Chicago/Turabian StyleMurialdo, Pietro, Linda Ponta, and Anna Carbone. 2020. "Long-Range Dependence in Financial Markets: A Moving Average Cluster Entropy Approach" Entropy 22, no. 6: 634. https://doi.org/10.3390/e22060634
APA StyleMurialdo, P., Ponta, L., & Carbone, A. (2020). Long-Range Dependence in Financial Markets: A Moving Average Cluster Entropy Approach. Entropy, 22(6), 634. https://doi.org/10.3390/e22060634