1. Introduction
Liquidity is unobservable and elusive concept, which encompasses many transaction properties observed on the markets [
1]. Various definitions of liquidity are proposed in the literature related to the bid-ask spreads [
2], focused on the price impact of trading volumes [
3], or referring to the market depth and dynamics of the order book [
4,
5]. Liquidity studies are performed on the basis of different information sets with different data frequency and on different markets. In order to maintain a uniform approach we focus on the bid-ask spread as a measure of transaction costs and follow the definition of liquidity as the ability to trade in a reasonable time and at a low cost [
6].
Two types of liquidity measures are widely recognized: benchmarks and proxies [
7]. In a calculation of benchmarks high-frequency data are required. These data are gathered in big datasets. Dealing with them is highly challenging and time-consuming. In the past decade a number of researchers have sought to determine which liquidity proxy based on low-frequency (daily) data is the best one to represent unobserved liquidity. The competition for the best liquidity proxy relies on the examination of the strength of dependency between proxies and benchmarks [
2,
7,
8,
9]. There is no single answer, which measure is the best approximation for the unobserved liquidity and thus its proper measurement is a very demanding process [
9,
10,
11].
Proxies for bid-ask spreads, the so-called percent-cost proxies, are based either on bid and ask quotes (the closing quoted spread of Chung and Zhang [
12]) or on high-low-open-close
prices (the effective spread of Corwin and Schultz [
8], Abdi and Ranaldo measure [
13], or high-low range [
14]). The application of the high and low prices is justified by the fact that high prices are usually buyer-initiated prices, while low prices are usually the seller-initiated [
8]. However, these prices are also commonly used for non-parametric volatility estimators as e.g., Garman and Klass estimators [
15]. Moreover, there is the evidence in the literature that liquidity is related to volatility [
16].
To our best knowledge it has not been verified yet, whether daily proxies based on the range of prices and quotes measure unobserved liquidity or volatility. In order to address this gap we examine to what extent liquidity proxies measure liquidity and/or volatility. We employ four benchmarks based on high-frequency data as well as four percent-cost proxies based on daily data [
7,
17]. Volatility is approximated by two realized variance measures [
18] as well as downside and upside realized semivariance [
19].
Three approaches are applied: firstly, we investigate the correlation coefficients for proxies and either benchmarks or volatility estimates. Secondly, through the partial determination analysis we examine which of these two, liquidity benchmark or volatility estimate, explains variability of liquidity proxies [
20]. Thirdly, we apply mutual information to measure inherent dependencies between any proxy and either liquidity benchmark or volatility estimate [
21]. All approaches are conducted within the cross-section and the portfolio time-series settings.
This paper makes a unique contribution to the literature. We find that proxies proposed in the literature based on high-low-open-close prices measure volatility rather than liquidity. The closing quoted spread proposed by Chung and Zhang [
12] is the only daily proxy which shows higher dependence with liquidity benchmark than with any volatility estimate. This measure uses the bid and ask quotes observed at the end of the day. Other percent-cost liquidity proxies based on four prices (applied in [
8,
13,
14]) approximate volatility, not liquidity. These conclusions are robust to the changes of an approach undertaken, the cross-section or the portfolio time-series, a method of the dependency measurement and the aggregation of liquidity measures, daily or monthly. They also remain unchanged when high liquidity or low liquidity periods are considered.
Liquidity and volatility are the key factors in price formation process, which are as important in the case of emerging markets as in the case of developed ones. Our study is conducted on the biggest emerging market in the Central and East European countries, on the Warsaw Stock Exchange (WSE). Thus this study extends the understanding of the nature of those relations also on relatively less liquid markets. Our findings are important for both practitioners who seeks for the best liquidity proxies as for academics who deliberate on such measures.
The rest of the paper is organized as follows:
Section 2 presents the literature review on volatility and liquidity relation,
Section 3 shows the research methodology,
Section 4 presents empirical results,
Section 5 investigates the robustness of the results in sub-periods and
Section 6 concludes.
2. Volatility and Liquidity—The Literature Review
Discussion on the relationship between volatility and liquidity has a long history [
22,
23]. Obviously, these two are of the highest importance to regulators and practitioners. As both volatility and liquidity are latent and both are closely related to the process governing prices, the task of complete distinction of these two is challenging. Karpoff [
24] shows the evidence that the large volume and price changes have common sources in the information flow process. Thus the dissemination of information among market participants seems to play crucial role in shaping these two. However, Karpoff did not use a notion of “liquidity”. His seminal paper is on volume, but volume itself might be perceived as a liquidity measure.
The relation between liquidity and volatility in the microstructure theory is not unambiguously defined. In the inventory models this relation is negative [
25,
26]: higher liquidity implies lower volatility and vice versa. In the information-based models this relation could be also positive [
27]: higher liquidity might be accompanied by higher volatility.
The empirical studies show different results in this area. On the one hand Chung and Zhang find that a market uncertainty represented by the Volatility Index, VIX, is a crucial determinant for stock liquidity in the US [
12]. Also Ma et al. [
28] show that liquidity on the stock markets is lower when investor risk perception reflected by VIX is higher. On the emerging markets Girard et al. [
29] find that the relationship between expected volume and volatility is negative and relate it to market inefficiencies. There is the evidence that the transaction costs are higher on the emerging markets [
9,
30,
31]. Also, liquidity tends to decrease when volatility on a domestic market or the market uncertainty measured by VIX increase [
32]. On the other hand, Chordia et al. [
33] indicate that market volatility induces lower spreads, which means that there is a positive relationship between liquidity and volatility. The evidence from the Chinese stock market is that although market volatility reduces trading activity, it has mixed effects on market liquidity [
34].
The difference between the best buy and sell prices, the bid-ask spread, has been historically the most popular measure of liquidity [
35]. Domowitz et al. [
30] differentiate between liquidity (approximated by trading volume), transaction costs (spreads) and volatility, and consider the relationship between these three variables. They show that higher volatility tends to reduce turnover. In their approach liquidity is separated from transaction costs, while in majority of studies the transaction costs (namely bid-ask spreads) are used to measure liquidity (e.g., [
2,
25,
36,
37]).
Summing up, there is a clear distinction between liquidity and volatility in the literature, even if the exact definitions of both concepts vary from one study to another [
38,
39]. It seems that the liquidity estimates from different dimensions should be interrelated, and they should express stronger dependency with each other than with any volatility estimate.
3. Data and Methodology
A vast number of papers is driven by the need of obtaining the best proxy of liquidity at the possible lowest cost. The liquidity measures usually require the access to databases with intraday quotations. The existence of the simple, easy-to-calculate and widely available measure would be appreciated by the market participants. Thus many attempts of creating such a measure on the basis of daily data are made (e.g., [
2,
7,
8,
13,
36]). We focus on measures based on daily prices or quotations, and examine how strongly are these liquidity proxies related to liquidity benchmarks as well as to well-known volatility estimates.
We consider one market, the Warsaw Stock Exchange (WSE), which is an order-driven market without market makers. This market has been considered as the emerging one [
40,
41,
42,
43]. We use long sample of 11 years (2737 days or 133 months); the sample period starts from January 2006 and ends up in December 2016. This 11-year period is long enough to capture different market regimes. Although within this time the WSE was considered as an emerging market, previous studies show that the coherence of liquidity measures is similar to one observed on the developed markets [
14]. We take into account quotations of 73 stocks that have been constantly listed within this period and are considered as either big or medium in terms of capitalization. In the case of the WSE it means that they have market value over 50 mln euro. Stocks which experienced splits within sample period were removed from the study. The list of stocks is available upon request. Our primary data come from tick-by-tick database and are cleared from the errors such as multiple records, entries with negative spread, entries for which the spread is more than 50 times the median spread on that day etc. [
44]. Finally they are aggregated into equally sampled intraday data.
The empirical framework is conducted on the basis of methodology presented in [
7]. Both the cross-section approach for the levels, as well as the portfolio time-series for differences of liquidity measures are applied. The novelty of our approach lies in the examination of interdependence of proxies with benchmarks and with volatility estimates at the same time. Additionally to the calculation of correlation coefficients, we also conduct regression analysis and calculate partial determination coefficients—it allows us to decompose the impact of both benchmarks and volatility measures on variation of proxies. Finally, we examine the dependence between variables using the mutual information measure.
Since the aim of the paper is to examine the relationship between proxies and both benchmarks and volatility estimates, we employ different measures for each of these categories. Starting with proxies we use only percent-cost proxies that are based on the daily values, either HLOC prices, or bid and ask quotes. The following proxies are considered:
effective spread estimator of Corwin and Schultz [
8], which rely on the empirical observation, that the highest price within the day
t,
, is the buyer-initiated price, whereas the lowest price,
, is the seller-initiated price:
where
, and
. We adjusted the high-low ratio spread estimator for overnight returns [
8];
the closing percent quoted spread proposed by Chung and Zhang [
12]:
where
and
are ask and bid quotes, respectively, observed at the end of the day
t. It is the only one among our proxies that is based on quotes instead of prices;
the high-low range which is a reformulation of the closing percent quoted spread of Chung and Zhang where the bid and ask quotes are replaced with the high and low prices:
the measure of Abdi and Ranaldo [
13] defined as follows:
where
is the closing price on day
t.
All daily proxies are interpreted in the same way—the higher the value, the less liquidity is provided.
We also consider different benchmarks, which control for several aspects of the transaction costs. Assume the following notation: there are K equally sampled observations within a day, . The benchmarks are defined as follows:
proportional effective spread
and
is an effective spread, obtained as
where
is price of the last transaction in an equally spaced time interval (e.g., 5-min), while
is the mid price of the best ask quote,
, and the best bid quote,
, within specified interval;
.
is a variable indicating the direction of the
k-th trade with 1 and
for buy and sell orders, respectively. In order to indicate the direction of a trade, Lee and Ready algorithm is applied [
45].
proportional quoted spread
This spread is based on the quotes only and does not take into account the direction of orders measure [
46]. Next two measures are based on the transaction (trade) prices or quotes:
squared log return on trade prices
When aggregating over period (day or month) a stock’s liquidity benchmark is calculated as volume-weighted average of its values computed over all k observations in the period.
Volatility is approximated by estimates which are based on the logarithmic high-frequency returns:
where k represents an interval and t is for a given day. It is assumed that at a sufficiently high frequency and in the absence of jumps, the realized variance can be a good approximation of the unobservable volatility. Thus we also consider minimum RV as a measure that is known to be robust to jumps:
Additionally, we also consider two realized semivariances that allow to focus on the particular risk of long or short position [
19]:
downside realized semivariance
where
I is an indicator variable conditioning calculation of the variance only on the basis of negative returns.
upside realized semivariance
where
I is an indicator of positive returns.
All benchmarks and volatility estimates are calculated with the highfrequency R package [
48].
4. Empirical Research
The empirical research is divided into three parts. Firstly, we apply cross-section analysis for the levels of liquidity and volatility measures as well as portfolio time-series analysis for the first difference of time-series. Secondly, we provide results for the partial determination coefficient analysis, which enables us to differentiate between the relation of a proxy with a liquidity benchmark and volatility estimate. In the last step we calculate mutual information which quantifies the amount of information about a proxy obtained through observing the benchmarks or volatility estimates.
Before examining the dependency between considered variables, we present averages of our proxies, benchmarks and volatility estimates aggregated into a monthly frequency.
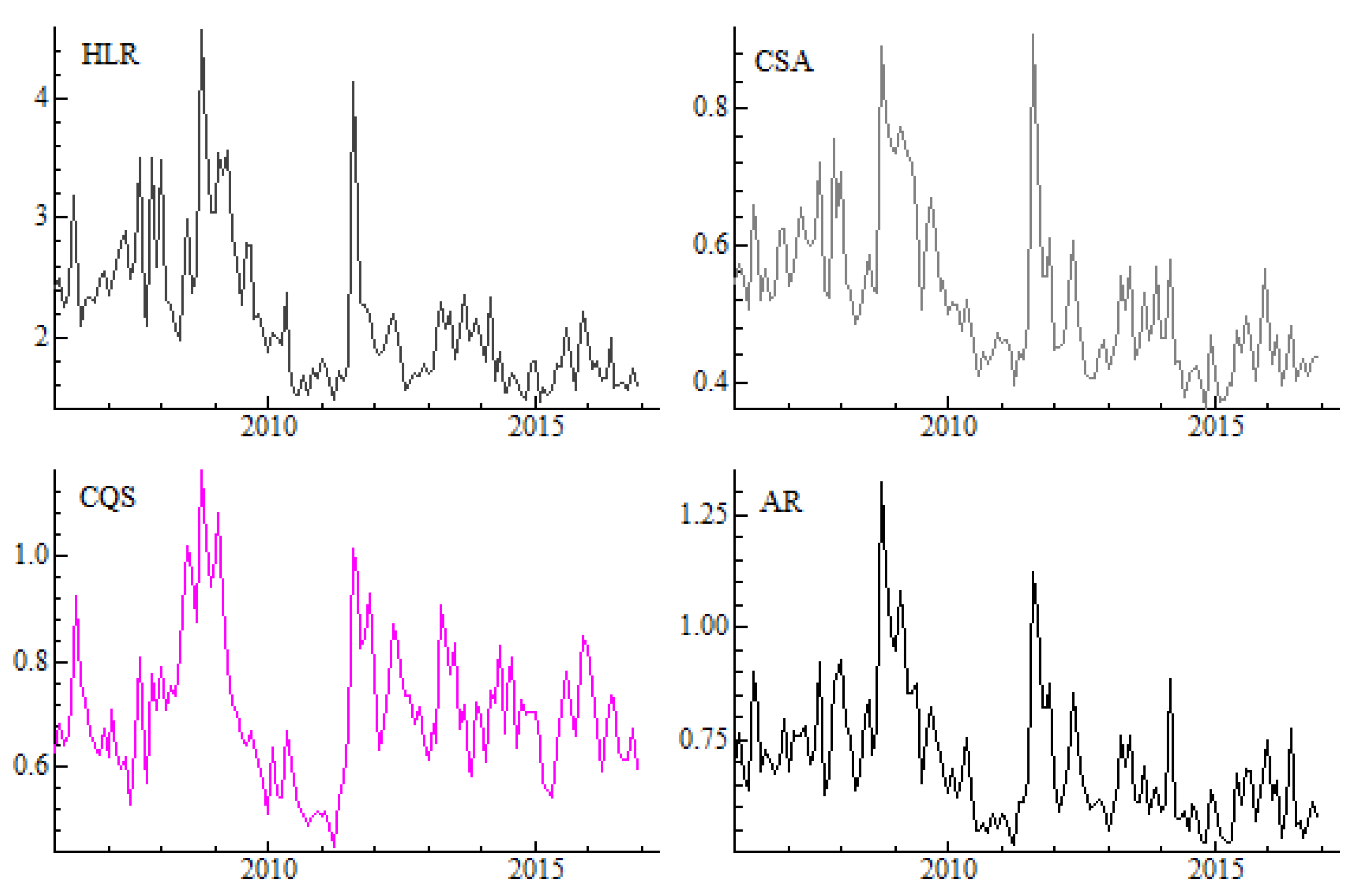
Figure 1 shows that the dynamics of the four proxies based on daily prices and quotes are similar. The average values of proxies are increasing (and liquidity is decreasing) in the time of global financial crisis in 2008 as well as in mid 2011 as a result of the sovereign debt crisis in Europe. This pattern is common across all daily proxies.
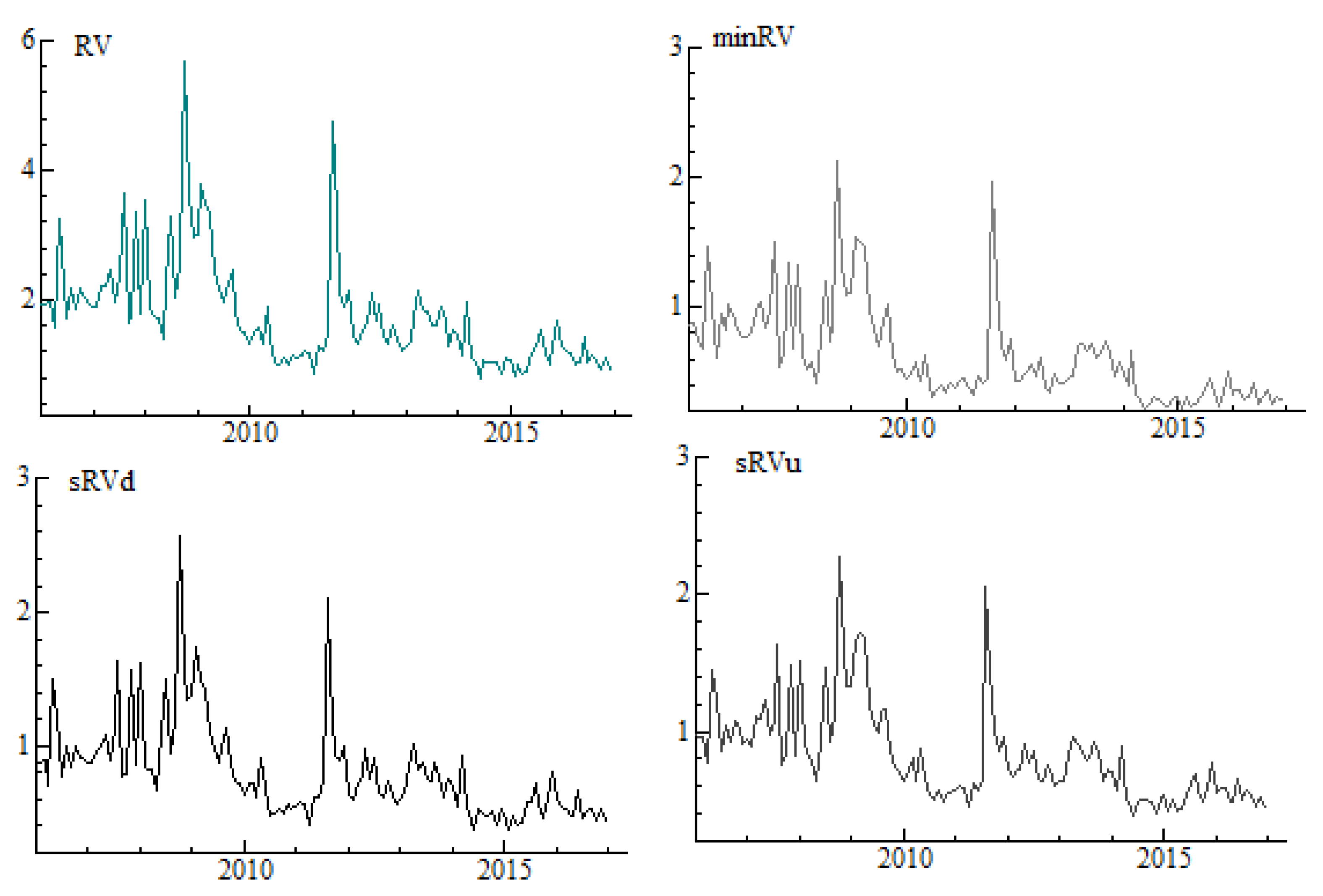
Figure 2 presents liquidity benchmarks considered in the study. We find that the overall trends and comovements of measures are quite similar. The higher the benchmarks’ values, the less liquidity is provided. Finally, the dynamics of four volatility estimates in the cross-section approach is presented in
Figure 3. There are no substantial visual differences in behaviour of the series, besides the fact that realized variance,
, displays the highest values. Both realized semivariances measure risk of either positive returns (upside realized semivariance
) or negative returns (downside realized semivariance
d), while
is robust to jumps measure of volatility.
4.1. Cross-Section Analysis
The average cross-sectional correlations between liquidity proxies and liquidity benchmarks or volatility estimates are computed according to the research methodology presented in [
7]: for each day (and each month) we calculate the cross-sectional correlations across all firms in the sample, and then the average correlation is calculated over all days (or months). Spearman rank correlations are applied. This analysis is provided in four different frequencies and with the respect to all considered measures of either liquidity or volatility, for daily and monthly measures separately. We check if the correlations are different between each proxy-benchmark and proxy-volatility pairs using t-test on the time-series of correlations in the spirit of Fama-MacBeth. Following Fong et al. [
7], we calculate the cross-sectional correlations and then regress the correlations of one pair on the correlations of another pair. We assume that the time series of correlations of each proxy is IID over time, and examine if the regression intercept is zero and the slope is one. The Newey-West standard errors are applied in order to adjust for autocorrelation [
51].
Table 1 presents the Spearman rank
coefficients for proxies and liquidity benchmarks calculated on the basis of four frequencies: 5-, 10-, 30-, and 60-minute data, and volatility estimates calculated in the same frequencies. Benchmarks and volatility estimates are presented in pairs for each sampling frequency. Columns 2–5 present the correlations obtained for the series aggregated into daily data, while columns 6–9 display the correlations for series aggregated into monthly data.
For estimates calculated on the basis of 5-min data, we find the evidence that for , and correlations with benchmarks are rather low (in absolute values) and definitely weaker than these observed with volatility estimates. It means that proxies based on daily prices (HLOC), are closer to volatility estimates than to any benchmark. The mostly striking example is , which is characterized by strong correlations (higher than 55%) with any estimate of volatility, and simultaneously is weakly correlated with benchmarks as or . The only opposite case is observed for , for which the correlations with liquidity benchmarks are stronger than with volatility estimates. This finding holds true also when other frequencies are examined.
When focusing on the monthly aggregates, the main result holds: correlations with volatility estimates are stronger than with benchmarks for all proxies, and the only exception is
. Our findings show that correlations of
with
and
are around 79% and thus are very close to correlation coefficients reported in [
7]—79.9% and 91.5%, respectively. For the remaining sampling frequencies similar results are observed. For
the lower the frequency of calculating benchmarks or volatility estimates is, the higher the correlation with volatility, but still the correlations with benchmarks remain high.
4.2. Portfolio Time-Series Approach
The portfolio time-series approach is based on equally-weighted portfolios across all stocks for a day or a month. We compute a benchmark or volatility estimate in a specified interval by taking the average of detrended benchmarks and volatility estimates over all stocks in a day or a month. The detrending is done by calculating first differences of the time-series. As detrended series are stationary Pearson correlations are calculated.
Table 2 shows that independently of the sampling frequency for
,
and
the correlations with any estimate of volatility are higher than with any liquidity benchmark. The same situation applies to monthly portfolios.
The remarkable exception among proxies is
again, for which in daily portfolios the correlations with both spreads
and
are 47% and 50%, respectively, while the correlations with volatility estimates ranges from 12% to 29% (these numbers apply to the case in which both benchmarks and volatility estimates are based on 5-min data). In monthly portfolios there is no clear answer, which of these two, liquidity benchmarks or volatility estimates, are highly correlated with
. As we examine two overlapping correlations with a common variable (proxy), first with a benchmark and second with a volatility estimate, we apply Zou’s test [
52]. This test calculates the confidence interval of differences between two correlations. If the confidence interval includes zero the null hypothesis that these correlations are equal cannot be rejected.
We find that considered proxies based on HLOC prices are much more related to volatility estimates than to liquidity benchmarks. The only measure which in daily frequency pronounces higher correlation coefficient with two liquidity benchmarks, and , is the closing quoted spread, . These results are consistent for all frequencies in which calculation of benchmarks or volatility estimates has been done.
4.3. Partial Determination Coefficients
The previous sub-sections are devoted to the correlations between proxies and benchmarks or volatility estimates separately. Here we propose to apply the regression analysis and investigate partial determination coefficients. The idea is the following: we consider linear regression for liquidity and volatility measures, that have been used in the cross-section (in
Section 4.1) and the portfolio time-series analysis (in
Section 4.2). For the former the equation has a following form:
where
denotes liquidity proxy for stock
i,
denotes liquidity benchmark,
stays for volatility estimate.
For the latter, the portfolio time-series analysis, the equation is following:
where
is the first difference, and
t is a time index. The regressions are estimated for both daily and monthly portfolios.
The coefficient of partial determination is the proportion of variation, that can be described by the predictors used in the full model, but cannot be explained in a reduced model [
53]. The formula to compute the coefficient of partial determination,
, is as follows:
where
is the sum of squares of residuals from the model with only one independent variable, and
is the sum of squares of residuals from the full model. In our case the reduced model is a model with either a liquidity benchmark or a volatility estimate, while the full model takes into account both variables simultaneously. Since
RV among all volatility estimates displays the highest correlation coefficient with proxies, we further show the results for this estimate. As the changes in frequency have no impact on the correlation coefficients and 5-min frequency of observation is usually used as a rule of thumb [
54,
55,
56], henceforth we present results for benchmarks and volatility estimates based on 5-min frequency only (the calculations for remaining proxies and frequencies are available upon request). In calculations rsq R package [
57] is applied.
Firstly, we provide results for the cross-section approach.
Table 3 presents the determination coefficients,
, as well as partial determination coefficients for both variables, the liquidity benchmark
and the volatility estimate
. We find that both for daily and monthly proxies the value of determination coefficient
varies from 5% to 62%. The comparison of partial determination coefficients,
and
, shows that for
,
and
both in daily and monthly data partial determination coefficients are much higher for the volatility estimate than for the liquidity benchmark. The only proxy for which we obtain higher partial determination coefficient for liquidity benchmarks than for volatility proxy is
. Here in the case of proportional effective spread,
, in daily data the partial determination coefficient for liquidity is 40% versus 2% for volatility. For
the impact of benchmark is 42%, while for volatility it is less than 2% (1.6%). In the case of monthly data, the conclusions are nearly the same.
Secondly, we repeat the procedure for the portfolio time-series approach.
Table 4 shows the determination and partial determination coefficients. As in the previous case in daily data
is the only proxy for which the partial determination coefficients for liquidity benchmarks, namely
,
and
, are higher than for volatility estimates. For monthly data the partial determination coefficients are more balanced: for
we obtain 30% for liquidity benchmark versus 40% for volatility estimate, while for
we get 39% versus 36%. Still
seems to represent liquidity, while the other proxies measure volatility.
4.4. Mutual Information
So far we have used dependency measures which assume linearity of the relation. As a robustness check we also apply a mutual information which could be considered as a nonparametric dependency measure. Mutual information is an estimate of inherent dependence between two random variables. It specifies the “amount of information” that is shared by two variables and is expressed in terms of the joint probability distribution. The
concept comes from the Information Theory and is closely related to that of entropy [
58,
59,
60]. The entropy of random variable
X,
, is expressed in the following way:
where
is a probability mass function, while
L is the length of the time series.
The joint entropy for two random variables,
X and
Y, is defined as:
where
is the joint probability that
and
. The mutual information between
X and
Y is then defined:
can be then normalized:
The normalized values of are within interval, with 0 denoting that both random variables are independent, and 1 denoting they share the same information.
In the study the mutual information measures are calculated both for the cross-section approach and the portfolio time-series approach (we applied the infotheo R package [
61]).
Table 5 shows the results for the cross-section on daily and monthly data. For proxies versus benchmarks relation in daily data the highest values are obtained for
and either
or
. In monthly data all benchmarks have the highest mutual information with
. For proxy versus volatility relation,
is characterized by the highest mutual information with all volatility estimates both for daily and for monthly data.
Table 6 presents the average mutual information for the portfolio time-series approach. For proxies versus benchmarks the highest mutual information is observed between
and
or
. These dependencies are even more pronounced in the case of monthly data.
For volatility versus proxies relation, is featured by the highest amount of mutual information with any volatility estimate, while shows the lowest mutual information with volatility measures. These results hold for both daily and monthly data. Summing up, the results obtained in this Section do not differ significantly from the previous findings.
5. Sub-Period Analysis
A potential drawback in our approach is that empirical results may be sensitive to the number of observations taken into considerations. Moreover, some statistical properties may depend on the specifics of the time-series and may be sensitive to the choice of the sample period. This section is devoted to validate the results and assess their consistency. Instead of the whole 11-year period we have chosen two specific two-year sub-periods (484 days) that are closely related to the market liquidity level. The sub-periods are 2007.07.02–2009.06.08. and 2013.01.02–2014.12.30 and relate to the low liquidity and high liquidity regimes, respectively (see
Figure 1 and
Figure 2). Following previous results we conduct an analysis using all three approaches, the calculation of correlation coefficients, partial determination coefficients and the mutual information for both cross-section and portfolio time-series analyses. Since in the chosen sub-periods there are only 24 months we carry out these computations for the daily aggregation and 5-minute frequency only. The results are shown in the
Appendix A in
Table A1,
Table A2,
Table A3,
Table A4,
Table A5,
Table A6.
Generally in sub-periods we find the same relations as in the whole sample. In both periods volatility estimates show higher correlations with proxies than with liquidity benchmarks. The only exception is which demonstrates much higher correlation with benchmarks than with volatility estimates in the cross-section analysis. In the portfolio time-series approach we find high dependence only between and or benchmarks. The regression analysis highlights very weak impact of any intraday measures on and (low determination coefficient). However, seems to be entirely explained by volatility measures. The mutual information results confirm those obtained in two previous approaches. The highest mutual information is observed for and both and . Also we find high mutual information for in association with volatility estimates. These results hold for both sub-periods.
When the comparison between two sub-periods is performed,
CQS as the best proxy for liquidity indicates higher correlation with
PES and
PQS in high liquidity subperiod than in low liquidity time. Hovewer, according to Zou’s test [
52] this difference in correlations between high and low liquidity periods are significant only for
CQS-PQS pair. The regression analysis confirms this finding, i.e., the determination coefficient as a goodness of fit measure is higher in the high liquidity period when the impact of benchmarks in the bivariate relationship is stronger. The mutual information allows to formulate the same conclusions but only in the cross-section approach. In the portfolio time-series the results are ambiguous.
6. Conclusions
This paper investigates whether liquidity proxies based on daily data commonly used in the literature indeed approximate latent liquidity. The relations between stock market volatility and liquidity have been the subject of much recent investigation both from the academics’ and practitioners’ point of view. Our research question is driven by the fact that some liquidity proxies, similarly to some volatility measures, apply four prices, that is high-low-open-close prices [
15]. In such circumstances, there arises a question, what exactly is measured by a given liquidity proxy. This is an important issue, as there is a need for easy-to-obtain and calculate liquidity measure and many horse races for finding the best proxy are run. The proxies based on range of prices are often examined in such races.
Our results show that measures based on high and low prices capture rather unobserved volatility than liquidity. Both the effective spread estimator of Corwin and Schultz [
8] and the spread of Abdi and Ranaldo [
13] that have been proposed recently are closer related to different volatility estimates than to any liquidity benchmarks used in the study. Also the high-low range used as a reformulation of the closing quoted spread of Chung and Zhang is less correlated with benchmarks than with volatility estimates. These findings are confirmed by partial determination coefficients from the regression analysis as well as the non-parametric approach based on the mutual information calculation. They hold for the cross-section approach as well as the portfolio time-series.
The only measure based on closing bid and ask quotes, the closing quoted spread of Chung and Zhang [
12], has higher dependency with liquidity benchmarks than with volatility estimates. This is confirmed within the correlation analysis, the partial determination coefficients’ analysis and through application of mutual information as a measure of non-linear dependency. All these approaches unanimously indicate that among daily proxies
is mostly related to liquidity benchmarks. This proxy is also indicated as the best one in Fong et al. [
7].
The answer to the question in the title, “do liquidity proxies based on daily prices and quotes really measure liquidity?” is ‘yes’ for proxies based on daily quotes and ‘no’ for proxies based on daily prices as the latter approximate volatility rather than liquidity. According to our results the proper measurement of liquidity based on daily data requires knowledge of bid and ask prices at the end of the day. Unfortunately this information is not offered in the widely available databases.



{kind=link}
{kind=link}
{kind=link}


