1. Introduction
Domain generation algorithms (DGA) provide methods for generating large numbers of pseudo-random domain names using specific parameters such as the date, the time, or text as seeds for random initialization. DGAs are often associated with malicious network behaviors. Recent botnets (e.g., Conficker, Kraken, and Torpig) use DGAs to quickly generate candidate remote command-and-control server domain lists [
1,
2]. They subsequently redirect normal domain name service (DNS) requests to the botnet [
3] for conducting malicious activities, such as distributed denial-of-service attacks, spamming, phishing, and click fraud [
4,
5,
6,
7] by establishing communication with the infected host through seemingly valid domain names. Therefore, the effective detection of algorithmically generated domain names is crucial for preventing malicious cyber activities.
In recent years, researchers have proposed several types of models to detect algorithmically generated domain names. Traditional models require manual reverse engineering of the DGA-based malwares, which is time consuming and laborious. The malwares can easily escape detection by changing their DGAs during examination. Therefore, reverse engineering models cannot meet the accuracy and timeliness requirements. Models based on blacklist filtering have a limited coverage of algorithmically generated domain names and cannot adapt to the growth of the malicious domain name set. Models based on traditional statistical machine learning methods have become mainstream in detecting algorithmically generated domain names. These models are based on the analysis of domain names or DNS requests. Models based on the analysis of DNS requests detect algorithmically generated domain names by analyzing the differences in the statistical characteristics of the requested domains, request interval, number of request failures, etc., when sending DNS requests to legitimate domain names and algorithmically generated domain names. Models based on the analysis of domain names detect algorithmically generated domain names by analyzing the differences in the distribution characteristics of characters, words, word lengths, numbers of words, etc., between legitimate and algorithmically generated domain names. The main drawback of these models is that they inevitably require intensive manual feature engineering for building the feature set. When the DGA produces variants, these models require the feature set to be reconstructed. This makes it difficult for the models to adapt to large and frequent changes in the DGAs. Furthermore, models based on the analysis of DNS requests usually rely on third-party credit systems and have very high detection costs.
Neural models have recently achieved remarkable progress in various research fields including computer vision, natural language processing, and network security. Neural models can automatically extract the discriminative category features from domain names and effectively detect algorithmically generated domain names by constructing neural networks with multiple hidden layers. However, neural models rely on large-scale domain name datasets for training and are more susceptible to an imbalanced sample distribution than other models.
To address the aforementioned issues, we propose a model to detect algorithmically generated domain names. Our main contributions are as follows:
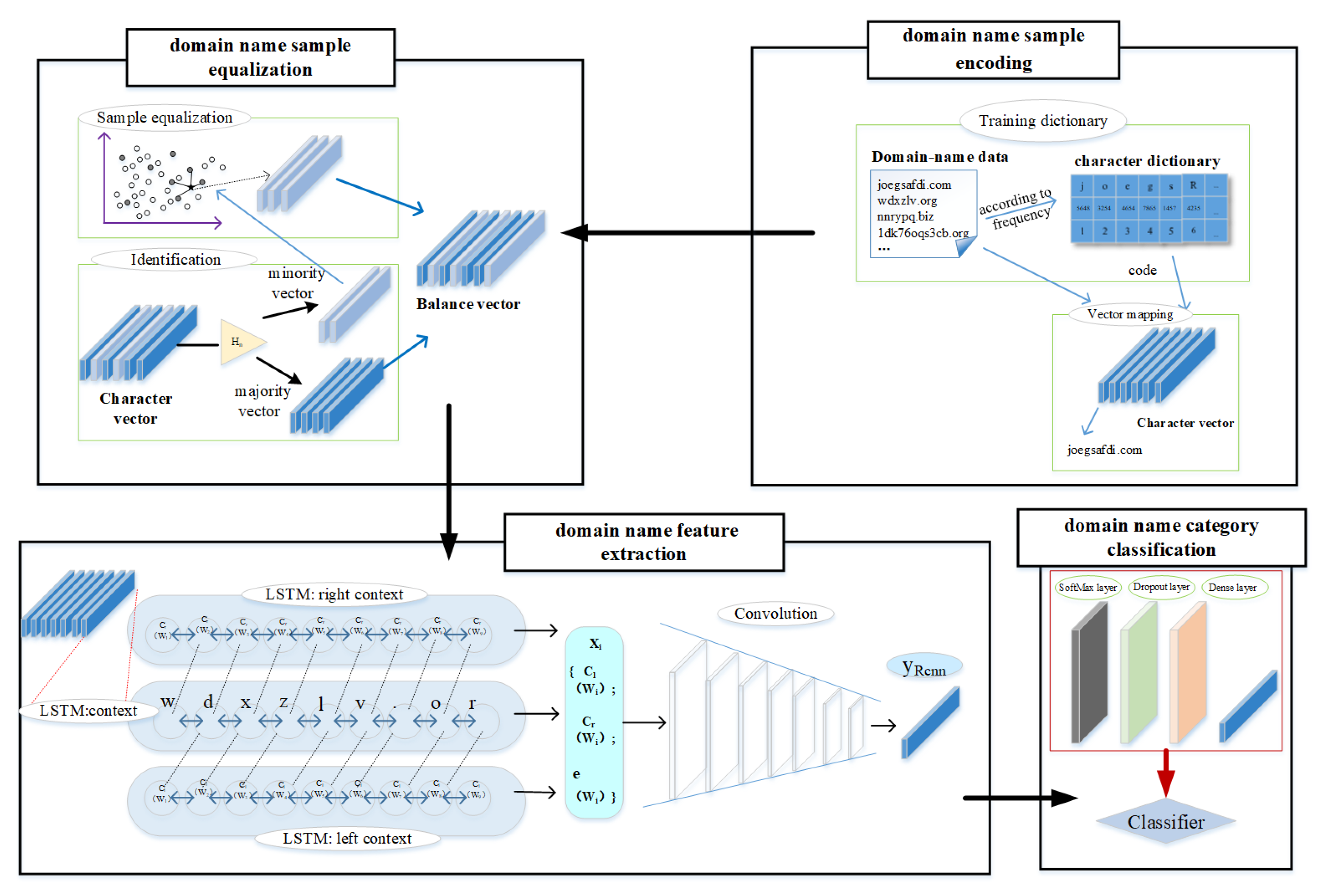
To address the problem of an imbalanced sample distribution, we employ an improved borderline synthetic minority over-sampling algorithm (Borderline-SMOTE) to optimize sample balance in the domain name datasets.
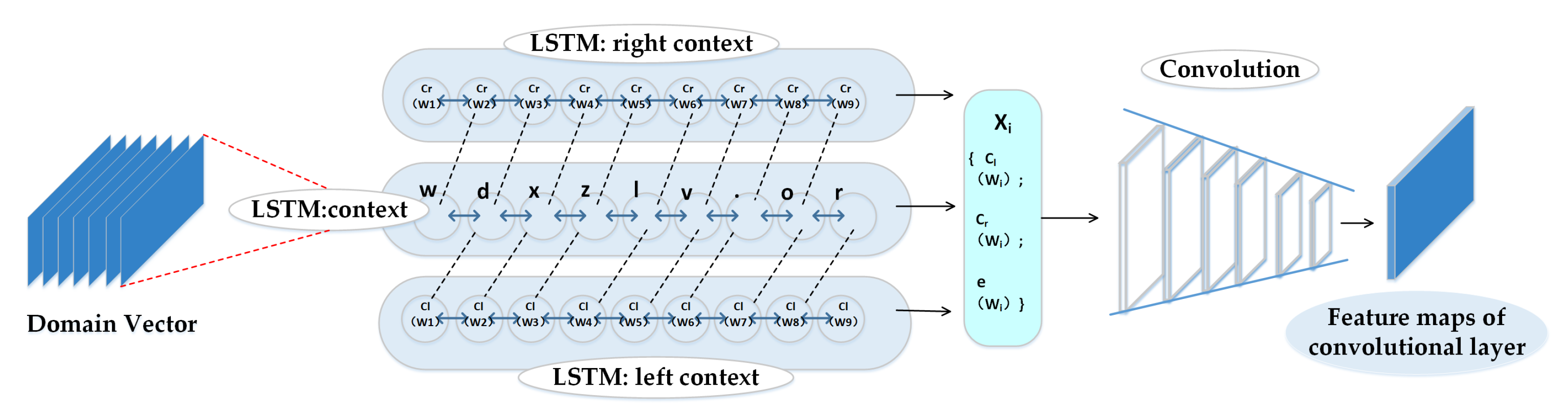
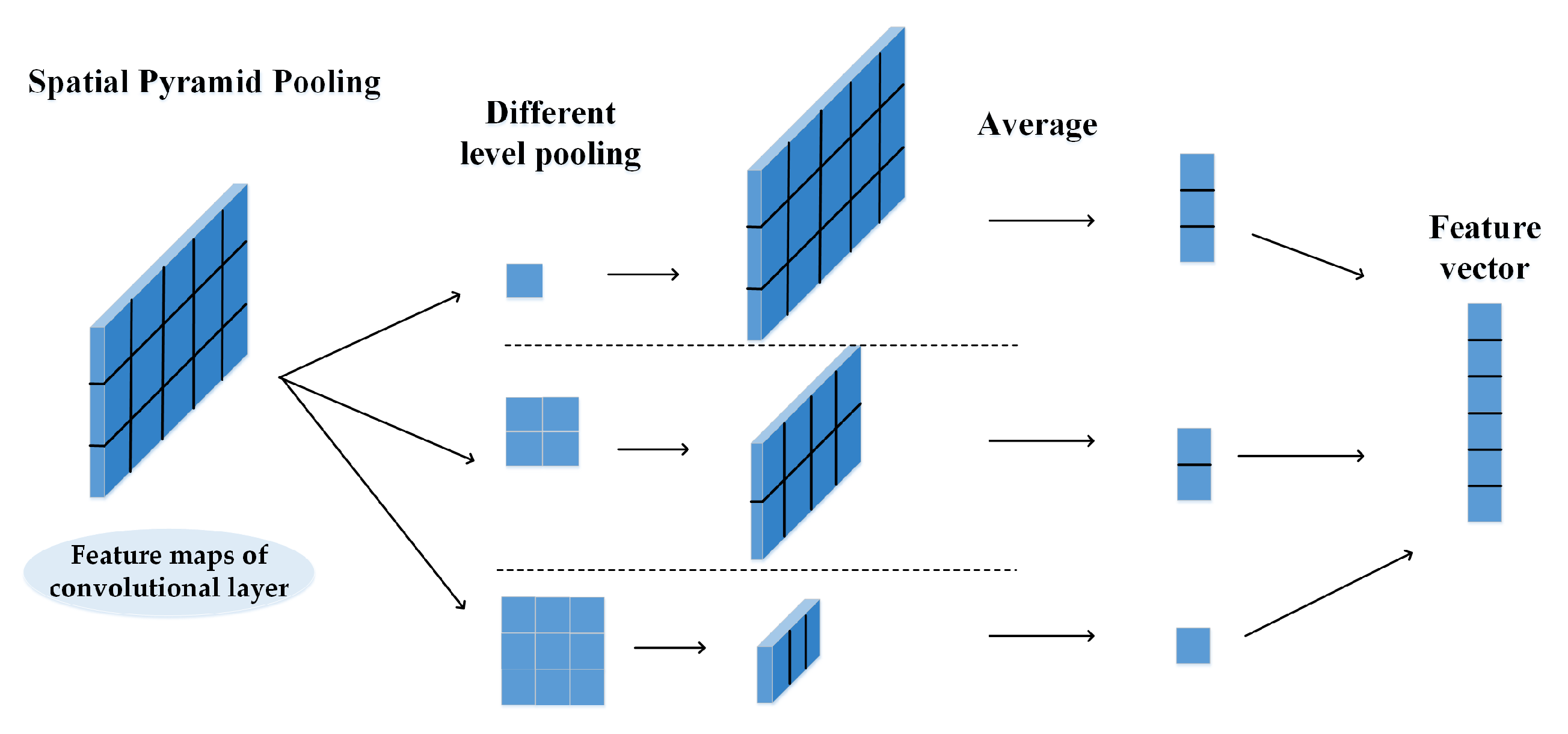
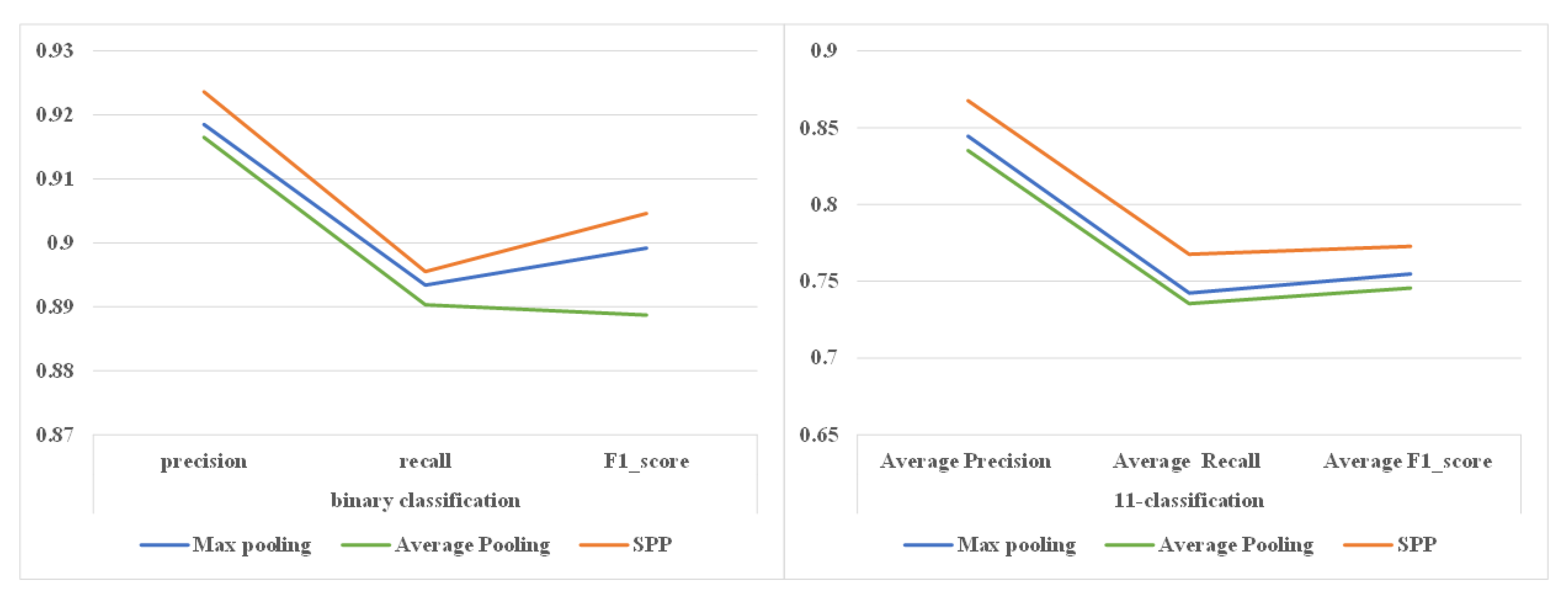
To address the problem of feature extraction, we propose a hybrid neural network that combines a convolutional neural network, a bi-directional long short-term memory (Bi-LSTM) network, and a spatial pyramid pooling strategy. We first employ a convolutional neural network and Bi-LSTM to extract semantic and contextual features from domain names simultaneously and then refine the contextual representation by utilizing the spatial pyramid pooling strategy to capture multi-scale contextual information from the domain names. Therefore, the features captured by the proposed hybrid neural network have more discriminative power and are less sensitive to noise.
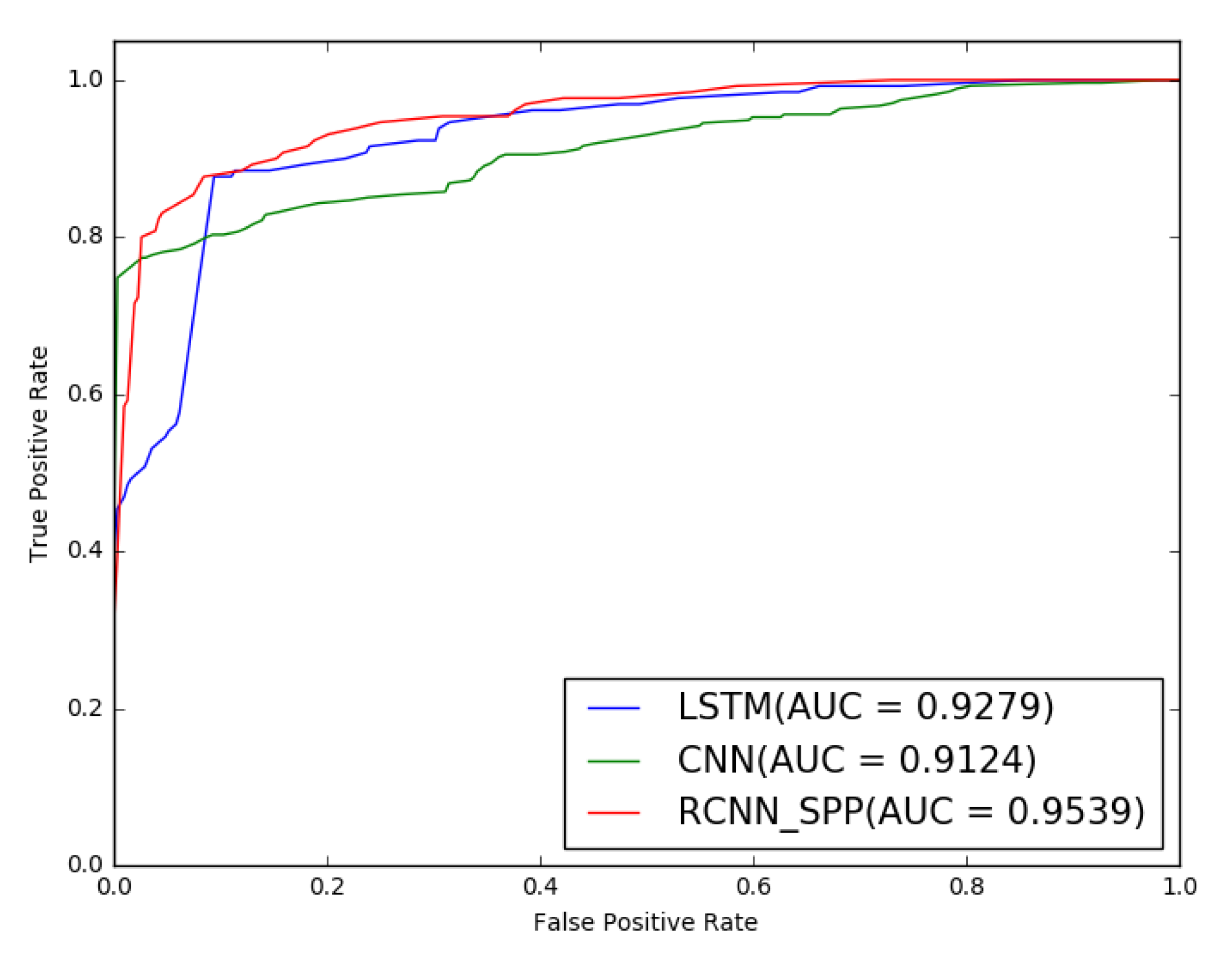
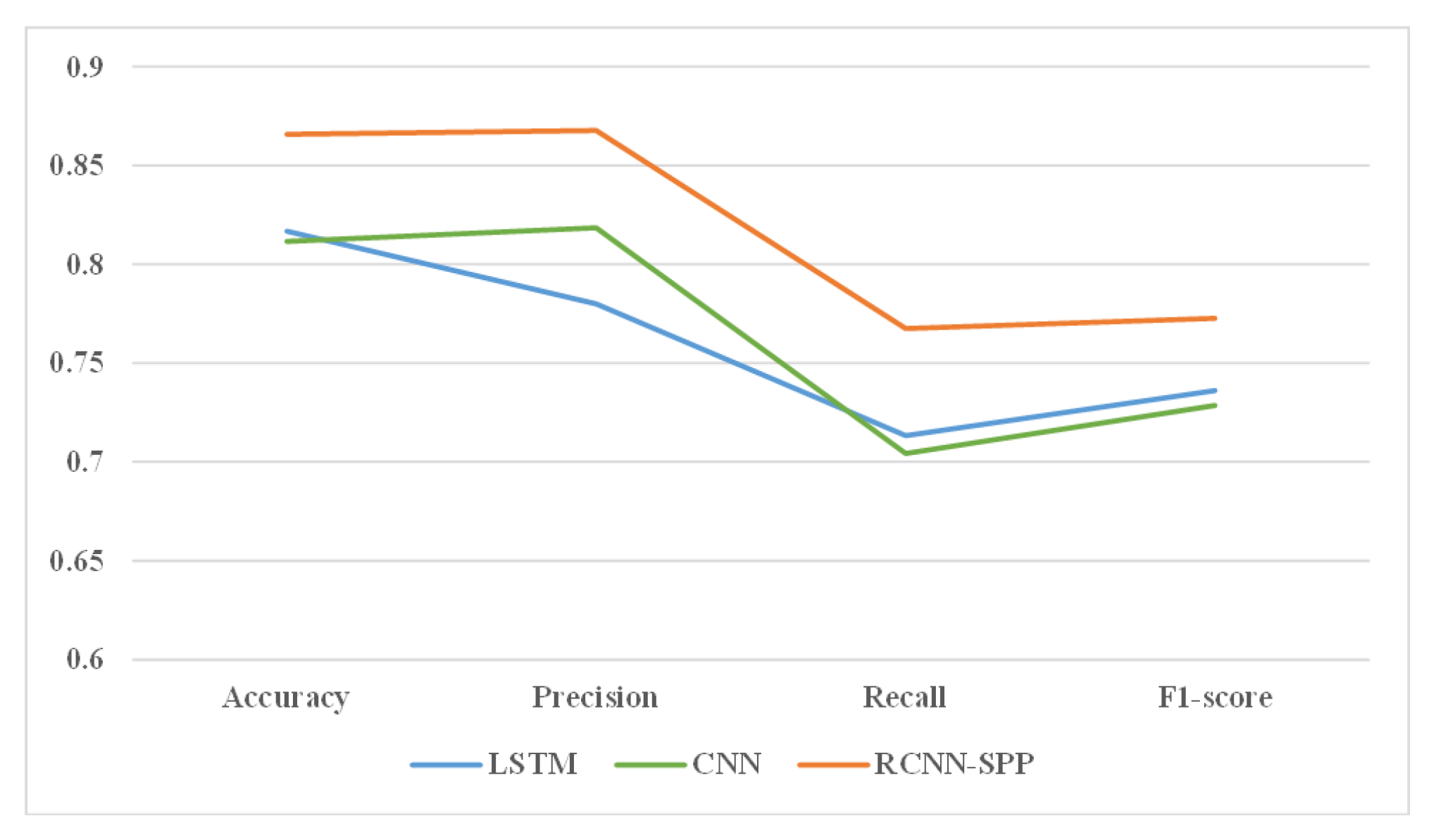
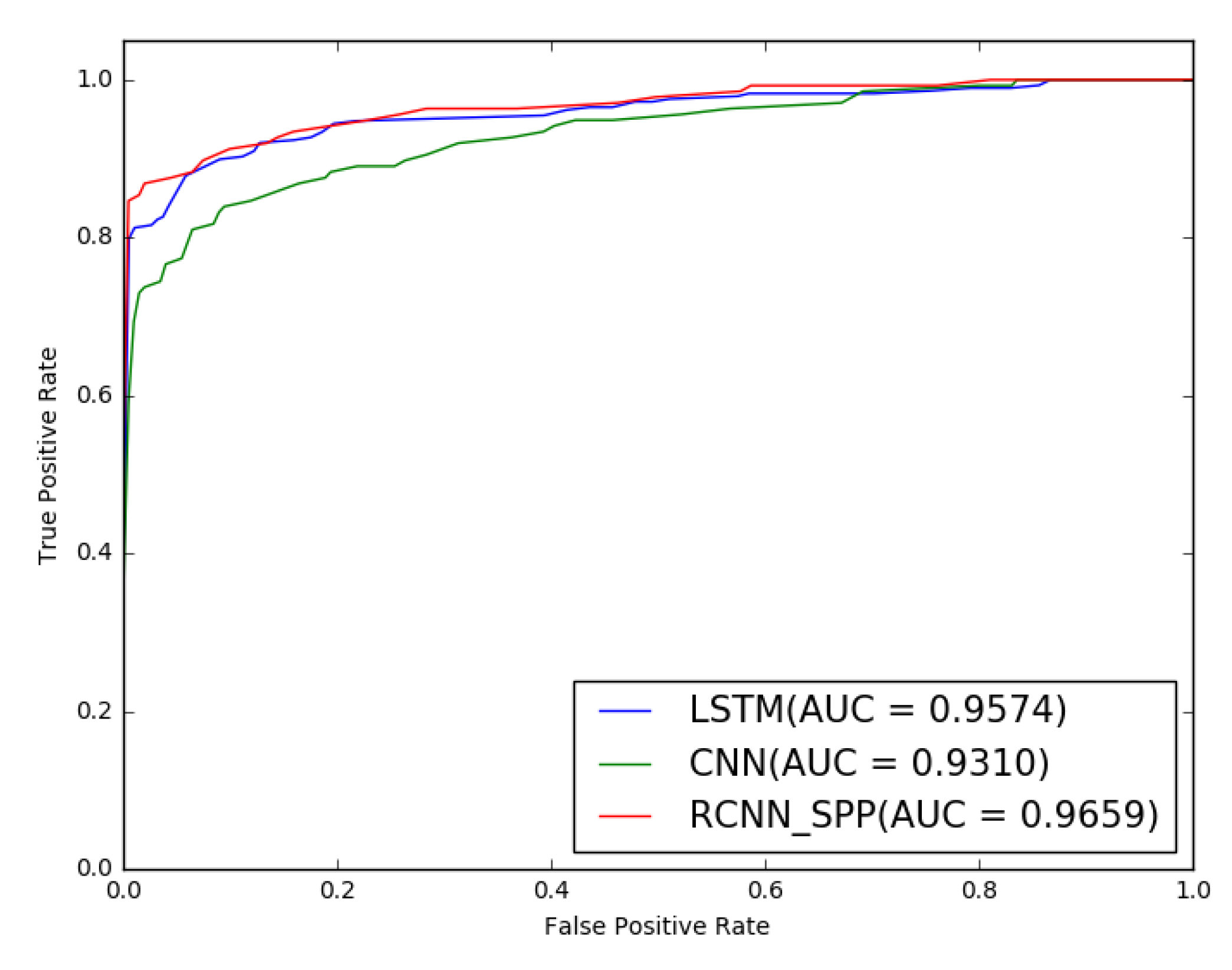
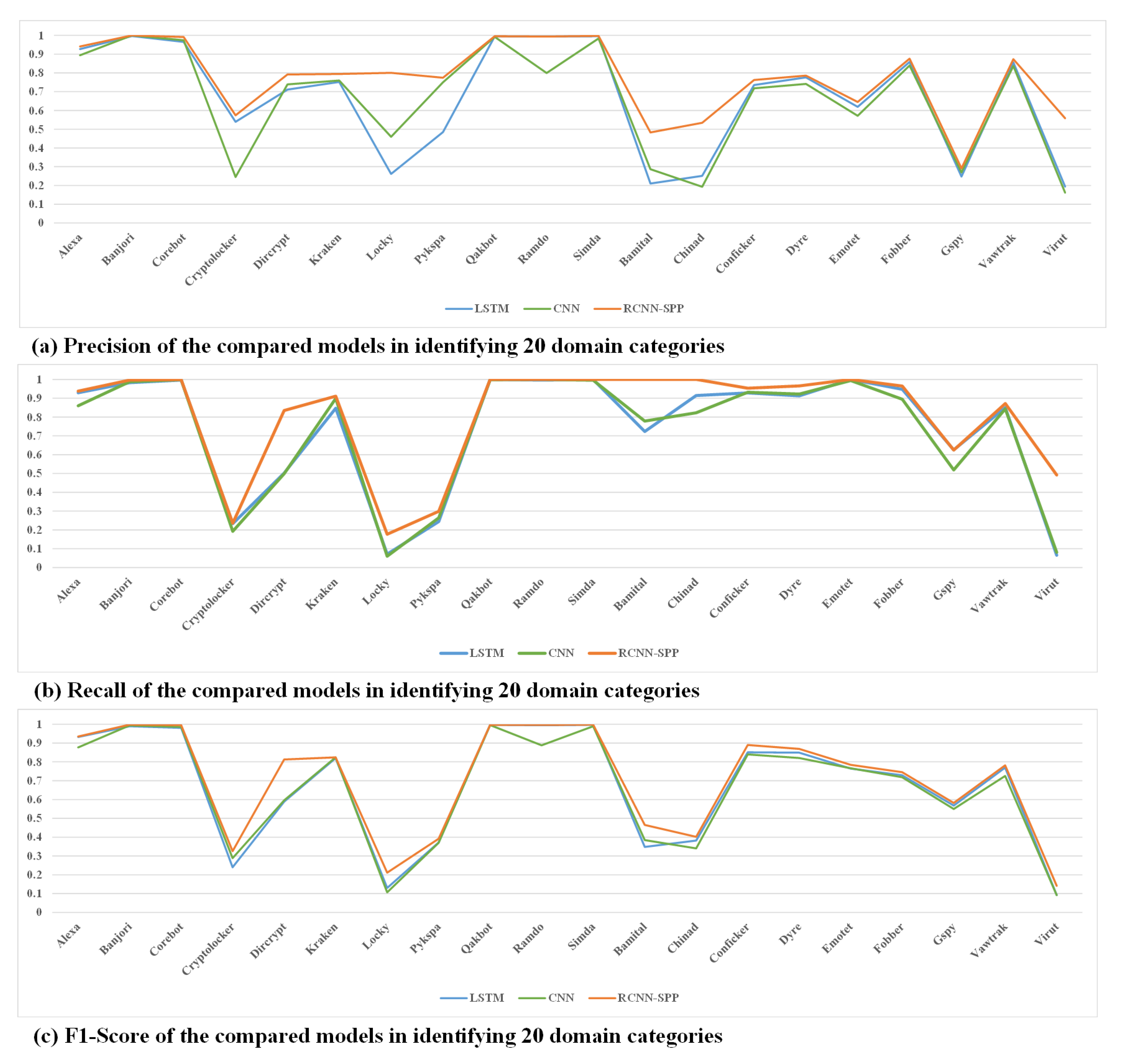
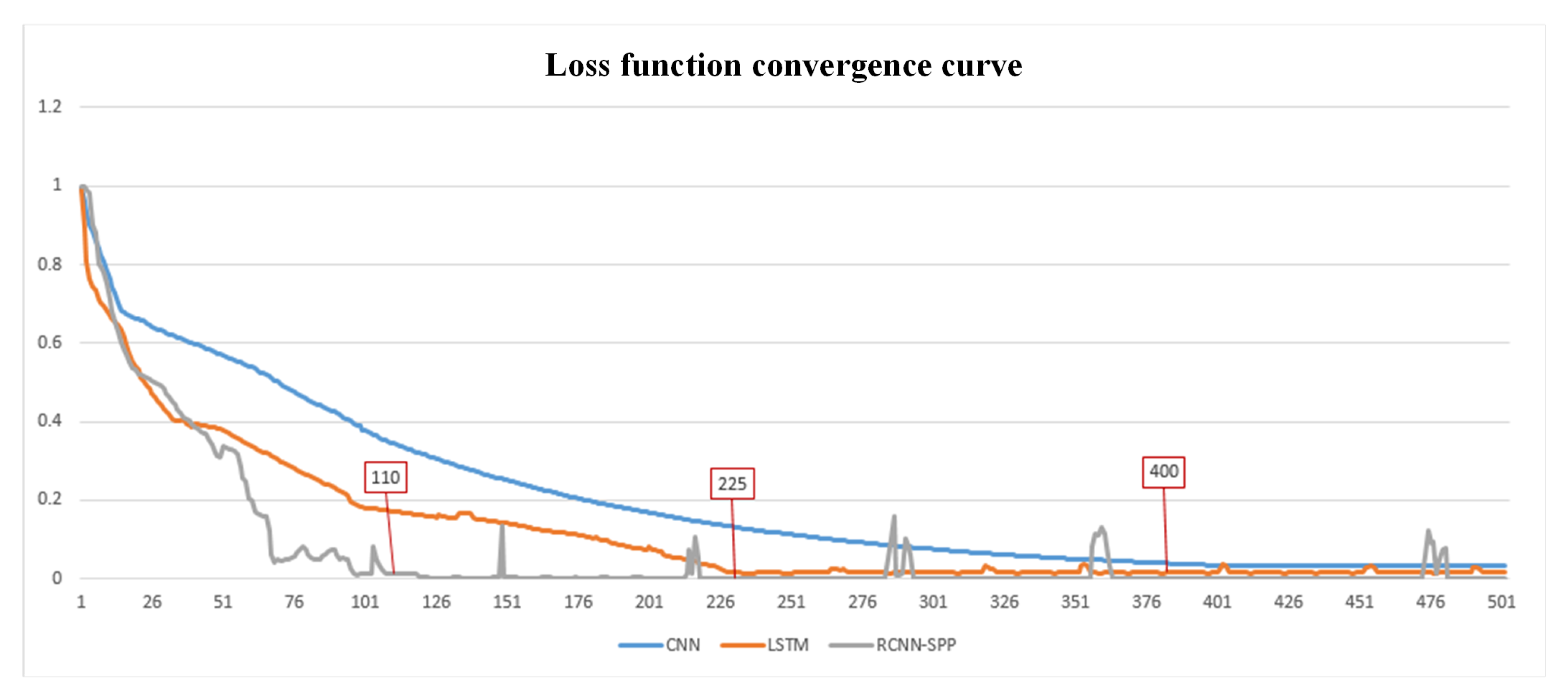
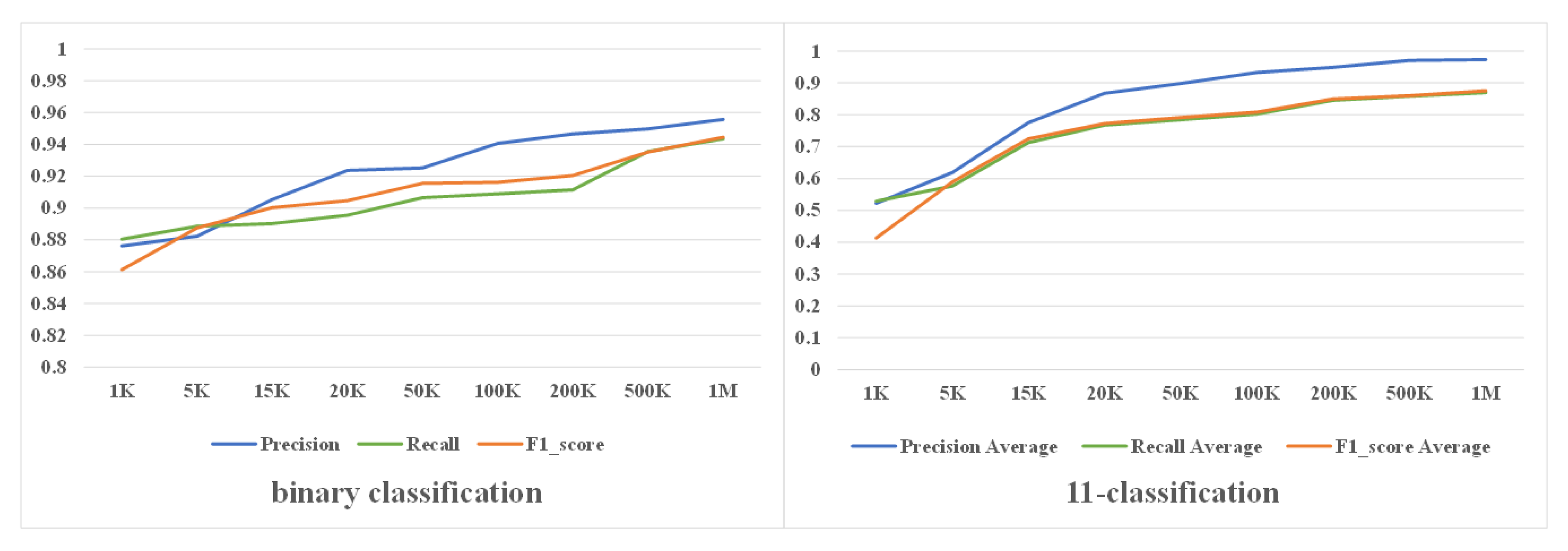
We conduct extensive experiments and analysis to validate the effectiveness of the sample equalization strategy and the performance of the proposed model RCNN-spatial pyramid pooling (SPP). The experiment results demonstrate that the sample equalization method can provide a benefit to performance, and RCNN-SPP can significantly outperform competing models in terms of accuracy, robustness, and convergence speed.
The remainder of this paper is organized as follows.
Section 2 briefly reviews the related works on detecting algorithmically generated domain names.
Section 3 provides an overview of the the model and introduces its details.
Section 4 presents and discusses the impact of the sample equalization method and the performance of RCNN-SPP and other competing models using several domain name datasets. Finally,
Section 5 presents some brief concluding remarks.
2. Related Works
Existing models for detecting algorithmically generated domain names are primarily based on reverse engineering, blacklist filtering, statistical machine learning methods, and neural networks.
As an example of a reverse engineering-based model, Plohmann et al. [
8] performed a comprehensive measurement study of 43 DGA-based malware families and variants. They also pre-computed all possible domains the DGAs can generate and covered the majority of the known and active DGAs by re-implementing these DGAs. However, reverse engineering of DGA-based malware is resource intensive and time consuming and is incapable of dealing with rapidly evolving DGAs and variants.
Building a blacklist that includes domains and IP addresses involved in malicious operations is a common and simple way of detecting algorithmically generated domain names. Kührer et al. [
9] conducted a comprehensive analysis of fifteen public malware blacklists and four blacklists operated by antivirus vendors and found that most blacklists have insufficient coverage of malicious domains and fail to protect against malwares that utilize DGAs. This is because the blacklists can only be updated periodically while the attackers can evade blacklist detection easily by continuously generating different domain names using DGAs.
Other models formulate the detection of algorithmically generated domain names as a classification problem and apply statistical machine learning methods to solve the classification problem. Some models distinguish the algorithmically generated domain names by obtaining discriminative information from DNS requests. Wang et al. [
10] proposed a DGA-based botnet detection model called Dbod. Dbod clusters hosts according to the relationship intensity between them and identifies the bot-infected hosts based on the differences in query behavior, such as the query time and count distributions, between compromised and normal hosts. Truong et al. [
11] proposed a model to detect domain-flux botnets and DGA-bot infected hosts. The model first locates botnets by analyzing the periodicity characteristics of the DNS requests and then extracts relevant features, such as the length and Shannon entropy of the domain names and the occurrence frequency of n-grams across the domain names, from the stream of DNS requests to distinguish algorithmically generated domain names. Schüppen et al. [
12] proposed a novel system to detect DGA-related domain names among arbitrary non-existent domain (NXD) DNS traffic. The system builds a feature set that includes structural, linguistical, and statistical features extracted from the domain names and feeds it into a classifier to identify algorithmically generated domain names. Zang et al. [
13] adopted spectral and K-means clustering to cluster the domain names generated by a DGA or its variant and subsequently build a feature set that includes TTL, the distribution of the resolved IP addresses, whois, and historical information from each cluster. Finally, they applied an SVM classifier to identify algorithmically generated domain names. Antonakakis et al. [
14] proposed a prototype DGA-bot detection system called Pleiades. Pleiades groups the non-existent domains into clusters according to the groups of hosts that query these domains and then employs an alternating decision tree (ADT) and a hidden Markov model (HMM) to identify algorithmically generated domain names and C&Cservers. These models usually require background information like DNS requests and protocol parsing and rely on a third-party credit system to obtain this information. This is expensive and time consuming in practice.
Considering the remarkable differences between algorithmically generated domain names and human generated domain names in terms of the distribution of alphanumeric characters, domain name length, number of characters, and other features, some models rely on the analysis of domain names to detect algorithmically generated domain names. Yadav et al. [
15] analyzed the performance of several statistical metrics including the Kullback–Leibler divergence [
16], Jaccard index [
17], and Levenshtein edit distance [
18] and employed a L1-regularized linear regression model designated as LASSO to identify algorithmically generated domain names. Yang et al. [
19] analyzed several types of features including word frequency, parts-of-speech, inter-word correlation, and inter-domain correlations by bi-directional maximum matching and then built an ensemble classifier to identify algorithmically generated domain names. Li et al. [
20] proposed a hierarchical model to identify DGA domains. The hierarchical model first classifies the DGA domains from legitimate domains using the decision tree and then groups similar DGAs together to determine the DGA algorithm using the DBSCAN clustering algorithm. Raghuram et al. [
21] proposed a generative model by analyzing the probability distribution of characters, words, word lengths, and number of words in human generated domain names. These models require the manual construction of feature sets by users with rich feature-engineering experience. Therefore, they cannot achieve satisfactory results when dealing with new DGAs based on the original feature sets.
Deep neural networks have achieved significant success in various fields including network security. Woodbridge et al. [
22] employed a long short-term memory (LSTM) network to learn distinct discriminative features from the character sequences of algorithmically generated and human generated domain names and then applied a binary or multinomial logistic regression classifier to detect DGAs and distinguish one DGA from another. Considering that many DGAs use English wordlists to generate plausibly meaningful domain names, Curtin et al. [
23] introduced a novel measure called the smashword score to estimate how closely an algorithmically generated domain name resembles English words and proposed a character-level recurrent neural network to deal with algorithmically generated domain names similar to human generated domain names. Yu et al. [
24] proposed a novel criterion for creating a noise-free DGA/non-DGA dataset from real traffic and a CNN-based DGA detection model. However, this model still cannot effectively distinguish between word-based algorithmically generated domain names and legitimate ones. They also studied the problem of how to supply sufficient labeled training data for deep learning-based DGA classifiers [
25]. Zeng et al. [
26] employed several deep learning models popular in computer vision including Alex, VGG, Squeeze Net, Inception, and ResNet to classify DGA domains and non-DGA domains. These neural models can extract the class features from domain names in an automatic and efficient way. However, they usually rely on large-scale domain name datasets for model training and are sensitive to an imbalanced sample distribution in the training datasets. In addition, considering the diversity and complexity of various DGAs, it is difficult to extract abundant and discriminative class features from domain names using a single type of neural network.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}