1. Introduction
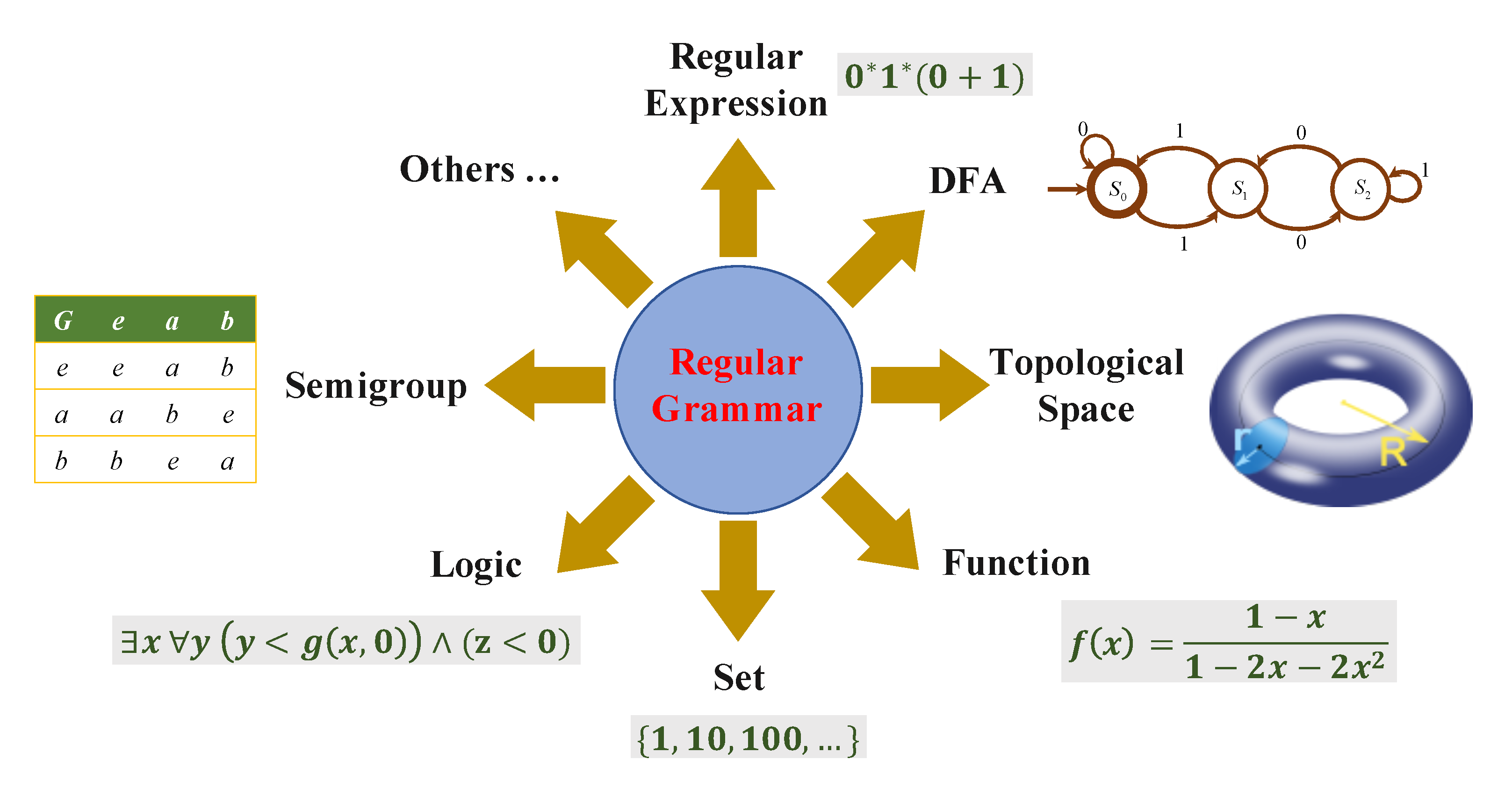
Regular grammars (RGs) have been widely studied in the theory of computation and intensively applied in natural language processing, compiler construction, software design, parsing and formal verification [
1,
2,
3,
4]. Despite their importance and pervasiveness, there is limited research [
5,
6,
7] investigating the internal structure of regular grammars. As such, our understanding of regular grammars is relatively coarse-grained.
One approach to understand a more fine-grained understanding of regular grammars is to investigate them through machine learning. Recent research has demonstrated that recurrent neural networks (RNNs) can achieve superior performance in a wide array of areas that involve sequential data [
8], e.g., financial forecasting, language processing, program analysis and particularly grammatical inference. Specially, recent work has shown that certain types of regular grammars can be more easily learned by recurrent networks [
9,
10]. This is important in that it provides crucial insights in understanding regular grammar complexity. Furthermore, understanding the learning process of regular grammar also help differentiating different recurrent models [
11,
12,
13].
Our intent is to establish a closer connection between the complexity of regular grammars and machine learning tasks from both theoretical and empirical perspectives. From a theoretical perspective, we regard classification and representation as two fundamental problems (Izrail Gelfand once remarked, “all of mathematics is some kind of representation theory” [
14]). We follow previous work [
15] by studying a grammar from its concentric ring graph representation, which contains sets of strings (with a certain length) accepted and rejected by this grammar. Note that this representation can be used for any grammar. An entropy value is then introduced based on the properties of the concentric ring graph that categorizes all regular grammars into three classes with different levels of complexity, and further establishes several classification theorems based on different representations of regular grammars. In addition, through an empirical study, different regular grammars are categorized by applying them to a set of learning tasks. That is, given enough positive (accepted) and negative (rejected) string samples of a specific regular grammar, it is expected that machine learning models will gradually identify a latent pattern of a grammar through the training process. This shows that this indeed reflects the difficulty of learning regular grammars and highly depends on the complexity of a grammar. All RNNs were evaluated and compared on string sets generated by different RGs with different levels of complexity so as to explore the characteristics of each regular grammar. As such, the empirical results become well aligned with the theoretical analysis. It is hoped that these results can provide a deeper understanding of a regular grammar under a learning scenario as well as practical insights into its complexity.
In summary, the contributions of this paper are as follows:
We propose a new entropy metric for measuring the complexity of regular grammar in terms of machine learning which reflects the internal structure and hence provides a fine-grained understanding of a regular grammar.
We categorize regular grammars into three disjoint subclasses based on the entropy value with several classification theorems for different representations proved.
We empirically demonstrate the validity of the proposed metric and corresponding classification by a series of experiments on the Tomita grammars.
The rest of the paper is organized as follows.
Section 2 provides preliminary and background material on recurrent neural networks and regular grammars.
Section 3 surveys relevant work on complexity and classification of regular grammars.
Section 4 presents our complexity metric and categorization results with several theorems based on different representations proved. Case study and experimental results are shown in
Section 5 and
Section 6, respectively.
Section 7 is the conclusion and future work.
4. Categorization of Regular Grammars
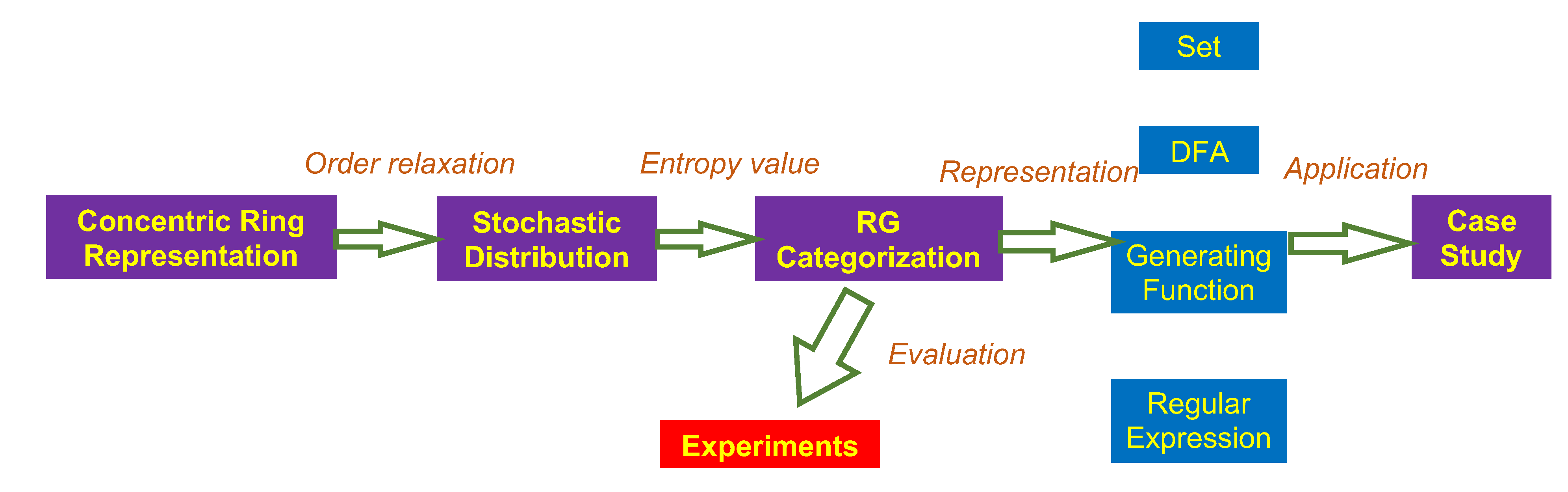
This section reviews the concentric ring representation of regular grammar, and, using this representation, we introduce an entropy metric to evaluate their complexity. All RGs are then categorized into three classes according to their entropy values. Last, we provide several classification theorems of RGs in terms of their different representations. A flowchart of our analysis is shown
Figure 2.
4.1. Entropy of a Regular Language from an Concentric Ring Representation
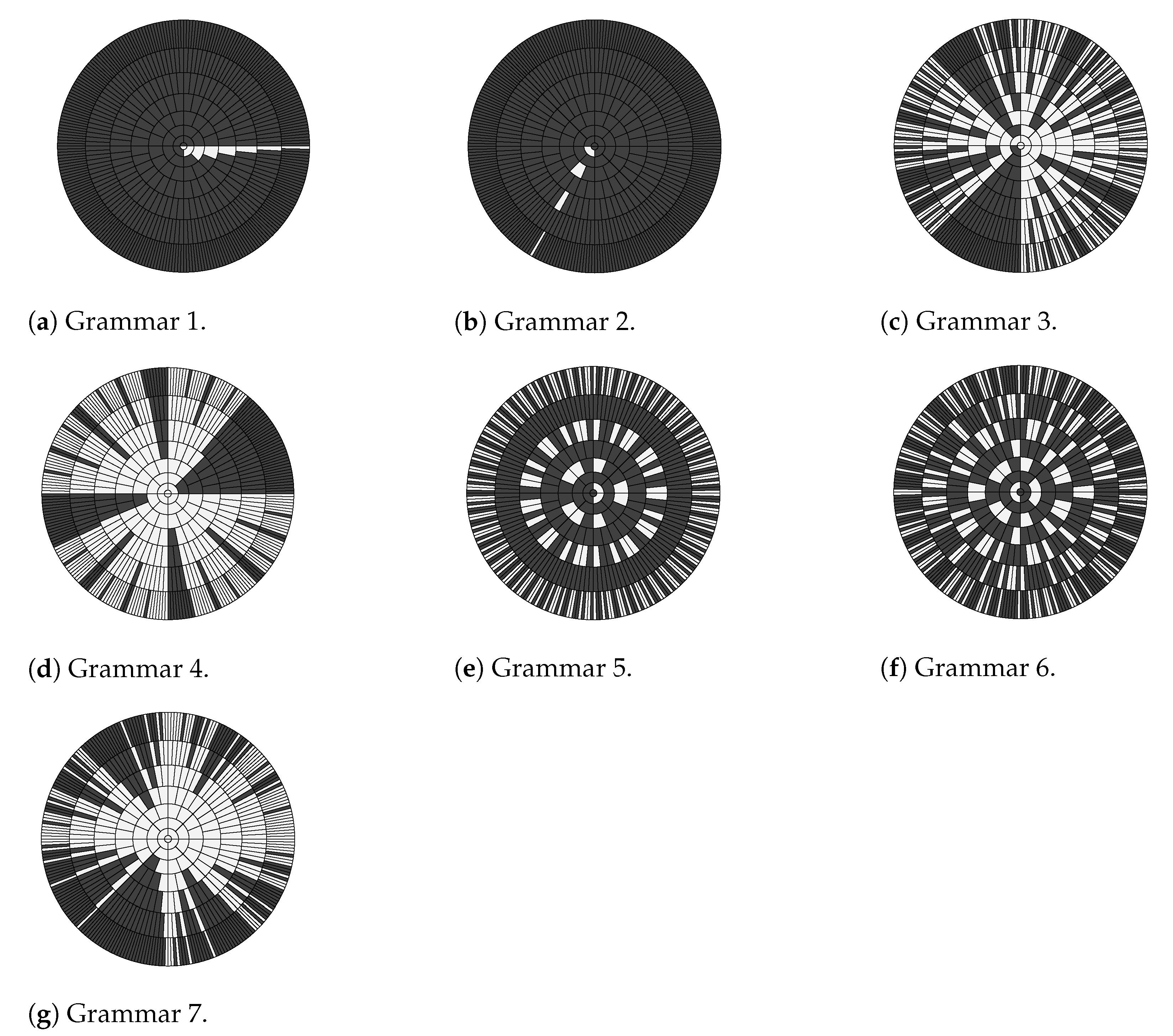
The concentric ring representation [
15] of a regular grammar reflects the distribution of its associated positive and negative strings within a certain length. Specifically, in each concentric ring, all strings with the same length are arranged in lexicographic order where white and black areas represent accepted and rejected strings respectively. Three ring graphs for Tomita Grammars 1, 3 and 6 are shown in
Figure 3 to illustrate their differences. In each graph, every concentric ring contains the sets of strings and its following strings at a specific length that are accepted and rejected by its RG. Note that the percentages of accepted (or rejected) strings for different grammars are very different. For example, Grammars 3 and 6 have the numbers of accepted strings much larger than that of Grammar 1. This difference in prior empirical work [
31,
41] showed that Grammar 6 is much harder to learn than Grammars 1 and 3. An intuitive explanation is that, for Grammar 6, flipping any 0 to 1 or vice versa means any accepted or rejected string can be converted into a string with the opposite label. A RNN needs to learn such subtle changes in order to correctly recognize all strings accepted by Grammar 6. Since this change can happen to any digit, a RNN must account for all digits without neglecting any.
We now formally show that a RG that generates a more balanced set of accepted and rejected strings has a higher level of complexity and appears more difficult to learn. Given an alphabet , the collection of all strings of symbols from with length N is denoted as . For a grammar G, let () and () be the numbers (ratios) of positive and negative strings, respectively. The constraint that all strings are arranged in a lexicographic order is relaxed, which indicates that all strings in are randomly distributed. We then denote the expected times of occurrence for an event —two consecutive strings having different labels—by . This gives the following definition of entropy for RGs with a binary alphabet.
Definition 1 (Entropy).
Given a grammar G with alphabet , its entropy is:where is the entropy calculated for strings with the length of N. (Here, we use lim sup for certain particular cases, i.e., when N is set to an odd value for Grammar 5.). Furthermore, the following proposition to efficiently calculate the entropy by expressing explicitly becomes:
Proof of Proposition 1. Given any concentric ring (corresponding to the set of strings with a length of
N) shown in
Figure 3, let
R denote the number of consecutive runs of strings and
and
denote the number of consecutive runs of positive strings and negative strings in this concentric ring respectively. Then, we have
. Without loss of generality, we can choose the first position as
in the concentric ring. Then, we introduce an indicator function
I by
representing that a run of positive strings starts at the
ith position and
otherwise. Since
, we have
By substituting
into the entropy definition, we have
□
Thus, the metric entropy is well-defined and lies between 0 and 1. Proposition 1 implies that the entropy of an RG is equal to the entropy of its complement, which confirms our intuition in terms of learning task. Without loss of generality, we assume from now on that for all RGs the set of accepted strings has a smaller cardinality. In addition, we conclude that an RG generating more a balanced string sets has a higher entropy value. As such, we can categorize all RGs with a binary alphabet based on their entropy values.
Definition 2 (Subclass of Regular Grammar). Given any regular grammar G with , we have:
- (a)
G belongs to Polynomial class if ;
- (b)
G belongs to Exponential class if ; and
- (c)
G belongs to Proportional class if .
Formally speaking, the metric entropy defines an equivalence relation, denoted as . A subclass of regular grammar can be considered as the equivalence class by the quotient , where denotes the sets of all RGs. In this way, we have , where denote polynomial, exponential, and proportional classes, respectively.
When compared to the entropy in shift space, which only considers accepted strings, our Definition 1 considers both the accepted and rejected strings. This is more informative and has other benefits. For example, given a dataset with samples uniformly sampled from an unknown dataset, we can then estimate the complexity of this unknown dataset by calculating the entropy of the available dataset. For a
k-class classification task with strings of length
N, let
denote the number of strings in the
ith class. Then, we have
. We can then generalize Definition 1 to a
k-class classification case by substituting this into Definition 1. However, this can be challenging for the entropy defined for shift space since it can only be constructed in a one-versus-all manner. In addition, the shift space cannot express all RGs, especially for grammars that lack shift-invariant and closure properties [
44].
4.2. Set Representation
Here, we conduct a combinatorial analysis. Given a regular grammar G, we consider it as a set and explore the property of its cardinality. Namely, we have the following theorem:
Theorem 1. Given any regular grammar G with , we have:
- (a)
G belongs to if and only if , where denotes the polynomial function of N;
- (b)
G belongs to if and only if where and and ; and
- (c)
G belongs to if and only if , where .
Here, ∼ indicates that some negligible terms are omitted when N approaches infinity.
Proof of Theorem 1. In both Definition 2 and Proposition 1, lim sup is used to cover certain particular cases, for instance when N is set to odd value for Grammar 5. In the following proof, without loss of generality, lim is used instead of lim sup for simplicity. According to Proposition 1, for any regular grammar G, its entropy . It can be checked that the maximum value of is 1 when . In addition, the minimum value of is 0 and can be reached when or 1. However, or 1 are only allowed for grammars that either accept or reject any string, hence are not considered in this theorem. As such, in this case, the value of entropy is taken as the minimum when or . In the following, we only discuss the former case and the latter can be similarly derived.
For each class of grammars, given that their takes the corresponding form shown in Theorem 1, the proof for the sufficient condition is trivial and can be checked by applying L’Hospital’s Rule. As such, in the following, we only provide a proof for the necessary condition.
From (4), we have:
where
denotes the derivative of
with respect to
N. It is easy to check that
exists for regular grammars. Then, we separate the above equation as follows:
It should be noted that the second term in the above equation equals 0. Specifically, assuming that
has the form of
where
(
b cannot be larger than 2 for binary alphabet), then the denominator of the second term is infinity. If
has the form of
, then the numerator tends to zero while the denominator is finite. As such, we have
If , then we have , indicating that the dominant part of has a polynomial form of N hence , where denotes the polynomial function of N.
If , then we have , which gives that , where . If , then we have where . Furthermore, if , we have where . □
Theorem 1 shows the reason for naming these subclasses. In addition, when a specific order is posed on the set of given RG, we have a similar result from number theory. Specifically, given a string with length N, we associate the string with a decimal number, i.e., . Note that this formula is different from the traditional approach to transforming a binary number to a decimal number, since 0 has physical meaning in regular grammar. For example, 000 is different from 00 in regular grammar. That is the reason that we need an additional term term to differentiate these situations. In this way, has induced an order on the regular grammar. Let denote the nth smallest number in this set; then, we have the following result:
Corollary 1. Given any regular grammar G with , we have:
- (a)
G belongs to if and only if ;
- (b)
G belongs to if and only if ; and
- (c)
G belongs to if and only if .
Here, .
Here, we provide a brief explanation of Corollary 1. The denominator approximates the length of the string and the numerator represents the cardinality of the set. Hence, comparing with the original Definition 2, this corollary provide an alternative perceptive of entropy. Take Tomita Grammar 1 for example. The set is with the number , and the formula for is given by ; hence, by simple calculation, we find that the limit of the ratio is 0 when n approaches to infinity, which implies that Grammar 1 belongs to the polynomial class. Note that in general it is difficult to calculate the explicit formula for and therefore Corollary 1 has certain limitation in practical applications.
4.3. DFA Representation
Here, we provide an alternative way to obtain the classifications for RGs using the transition matrices of its associated minimal DFA [
27] in terms of states. This approach provides immediate results if the minimal DFA is available. As such, this reduces the computation cost of a data-driven approach. Here, we again use the case when the alphabet size is two. However, it is easy to extend this for grammars with larger alphabets. Given a regular grammar
G with the alphabet
and its associated minimal complete DFA
M with
n states, let
,
denote the transition matrices of
M associated with input 0 and 1, and the transition matrix of the DFA is defined as
. Alternatively, the transition matrix of a given DFA can be considered as the transition matrix of underlying directed graph by neglecting the labels associated with the edges. With the above settings, we have the following theorem:
Theorem 2. Given any regular grammar G with , we have:
- (a)
G belongs to if and only if and ;
- (b)
G belongs to if and only if and , and where denotes the second largest modulus of the eigenvalues of T; and
- (c)
G belongs to if and only if or .
Here, represents the number of diagonal elements equal to 2 and denotes the set of modulus of all eigenvalues of T.
Proof of Theorem 2. We first introduce a lemma which is used in the proof.
Lemma 1. Let and denote two one-hot encoded column vectors corresponding to a starting state and an ending state of a DFA respectively. One can construct an adjacent matrix P for this DFA by regarding it as an undirected graph with each node represents a state and every edge represents the existence of a transition between a pair of states. Then, the number of L-length strings that reach the ending state from is .
Based on the lemma above, it is easy to see that the number of positive strings is
where
q is a one-hot encoded column vector representing an accepting state. By applying Jordan decomposition to
P, i.e.,
, we can see that
and
is the only term depending on
N. Specifically, take one Jordan block
with the eigenvalue of
and let
denote the nilpotent matrix associated with
, that is, the superdiagonal of
contains ones and all other entries are zero. Then, we have:
It is easy to see that when the absolute of the eigenvalue, i.e., , has a polynomial form of N. This result can be generalized to all Jordan blocks of J. As shown in the proof of Theorem 1, this corresponds to the case when G belongs to the polynomial class (we omit the proof since the number of diagonal elements of T equal to 2 is 1, as discussed in the paper). Denote the second largest eigenvalue of T as b, then dominates , where is some constant. As such, one can easily derive the proof by following the proof for the exponential class in Theorem 1. □
Theorem 2 indicates that the entropy of a RG lies in the spectrum of its associated DFA. Specifically, in the polynomial and exponential classes, a DFA with its summed transition matrix T having only one diagonal element that is equal to 2 indicates that this DFA has only one “absorbing” state (either the accepting state or the rejecting state). Assume that a DFA has one absorbing state and is running over a string. Once reaching the absorbing state, this DFA makes a permanent decision—either acceptance or rejection—on this string, regardless of the ending symbol has been read or not. In comparison, in the proportional class, a DFA can have either zero or two absorbing states (one accepting state and one rejecting state). In the case of Tomita grammars, every grammar has exactly one absorbing state except for Grammars 5 and 6, which have no absorbing states. The DFAs for Grammars 5 and 6 can only determine the label of a string after processing the entire string.
Recall that we require that for all RGs the set of accepted strings has a smaller cardinality. As such, the incomplete DFA for a given RG can be obtained by deleting the rejecting absorbing state and all the edges associated with the state from a minimal complete DFA. (This is important since for a proportional class there might exist two absorbing states and the accepting absorbing state in that case cannot be deleted. A more significant result is that, in the monoid representation of regular grammar, only the monoid associated with polynomial and exponential grammar is a nulloid. The discussion of monoid representation is out scope here.) Similarly, the transition matrix of the incomplete DFA becomes:
Corollary 2. Given any regular grammar G with , we have:
- (a)
G belongs to if and only if ;
- (b)
G belongs to if and only if and ; and
- (c)
G belongs to if and only if .
Here, denotes the largest eigenvalue of .
Corollary 2 together with Theorem 2 provides a complete analysis of classification results for a DFA representation. It is easy to see that neither strictly local or strictly piecewise belongs to the proportional class since they all have one absorbing-rejecting state. They can be categorized into either the polynomial or exponential class according to their specific forbidden factors or subsequences. Please refer to classification theorems of regular grammars with arbitrary alphabet size in
Appendix B.
4.4. Generating Function Representation
Now, we derive the classification results based on the generating function representation of a regular grammar. A generating function encodes an infinite sequence of numbers by treating them as the coefficients of a power series, which is widely applied in combinatorial enumeration. Specifically, the generating function of regular grammar is defined as follows:
An important result is that generating function of regular grammar is a rational function. We have the following theorem for classification:
Theorem 3. Given any regular grammar G with , we have:
- (a)
G belongs to if and only if is finite or the radius of convergence r of is equal to 1;
- (b)
G belongs to if and only if the radius of convergence r of is between 1/2 and 1, and ; and
- (c)
G belongs to if and only if the radius of convergence r of is equal to 1/2.
The theorem can be understood from two perspectives. First, from Theorem 1, we can readily derive the radius of convergence by a ratio test. Another is related to calculating the generating function from a DFA. Specially, we have the following lemma [
50]:
Lemma 2. The generating function from state i to state j is given bywhere denotes the matrix obtained by removing the jth row and ith column of B. Note that the radius of convergence r only depends on the denominator of the function , and r is the smallest pole of the function. By Lemma 2, the denominator has the form . As such, the radius is the inverse of the largest eigenvalue of the transition matrix. The classification theorem is a generating function of a regular grammar and can be easily generalized to a regular grammar with multiple alphabets.
4.5. Regular Expression Representation
Here, we provide an analysis from a regular expression perspective. First, we consider the following interesting question: Given a regular grammar, how many parameters does one need to uniquely determine a positive string? The question is closely related to automatically generate positive samples by computer. We start with a simple example. For Tomita Grammar 7, we have , and we only need four numbers to generate a string . However, for a more complicated example Tomita Grammar 4, we have , and, in this case, we have to record both the number and location of the suffix string 1, 10, 100 separately. Hence, we need numbers to generate a sample. Moreover, we have the following fact:
Fact 1. Given any regular grammar G with , we have:
- (a)
G belongs to if and only if ;
- (b)
G belongs to if and only if ; and
- (c)
G belongs to if and only if .
Here, k is a constant and denotes the required number of parameters.
Another perspective to explore this problem is to apply group theory. Specifically, given a regular grammar, we can consider it as a topological space. Furthermore, it can be decomposed into several disjoint orbits of different base points, and the whole topological space is generated by the actions on these base points. In this way, these actions form a monoid and the cardinality of the monoid reflects the complexity of the grammar. Again, we use Tomita Grammars 4 and 7 as an example to illustrate this idea. For , the base point of the topological space is and we define the following different actions: , adding 0 in the first slot; , adding 1 in the second slot; , adding 0 in the third slot; and , adding 1 in the fourth slot. Note that first adding 1 in the second slot and then adding 0 in the first slot is exactly the same as first adding 0 in the first slot and then adding 1 in the second slot, which means that these actions commute to each other. Hence, this monoid is an abelian monoid (more formally, this monoid can be considered as the quotient of a free monoid by a normal submonoid, i.e., ) and the cardinality of the monoid is . For , the base points are , 0 and 00, and we define the following actions: , attaching 1 in the back; , attaching 10 in the back; and , attaching 100 in the back. Note that this monoid H is no longer commutative, since acting on base point 0 gives the string 0101 while acting on base point 0 gives the string 0011. Hence, in this case, the monoid is a free monoid generated by and the cardinality of this monoid is . More generally, we have the following fact:
Fact 2. Given any regular grammar G with , we have:
- (a)
G belongs to if and only if or ;
- (b)
G belongs to if and only if ; and
- (c)
G belongs to if and only if .
Here, k is a constant and denotes the cardinality of the monoid of actions on the topological space.
Facts 1 and 2 give the following theorem:
Theorem 4. Given any regular grammar G with , we have:
- (a)
G belongs to if and only if there is no + inside the Kleene star * in the regular expression;
- (b)
G belongs to if and only if there exists a polynomial grammar inside the Kleene star * in the regular expression; and
- (c)
G belongs to if and only if there exists an exponential grammar inside the Kleene star * or in the regular expression, where k is a constant.
Theorem 4 provides an analysis based on the regular expression. Note that, except for the special case in proportional class, this result does not depend on the size of alphabet. More examples are presented in the next section.
5. Case Study for Tomita Grammars
As our goal is to study the characteristics of subclasses of regular grammar in terms of machine learning, we use the often cited Tomita grammars [
51] as examples for our analysis, which is consistent with the evaluation. For each classification result in
Section 4, we choose an example to illustrate its application. The full results for the Tomita grammars are listed in
Table 3.
5.1. Set Representation
Here, we use Tomita Grammar 3 to illustrate the application of Theorem 1. Note that, in
Table 3, we can see that it is difficult to derive an explicit formula for
from a pure combinatorial approach. Instead, we provide a brief proof that Grammar 3 belongs to exponential class. Let
denote the set of positive samples with length N, and it is easy to notice that it can be decomposed into the following four disjoint sets: samples ending with consecutive even numbers of 1 s, samples ending with consecutive odd numbers of 1 s, samples ending with 0 s and the number of 0 s at the end limited by the constraint, and samples ending with 0 s and the number of 0 s at the end not limited by the constraint. We use
,
,
,and
to denote these sets, respectively. Hence, we have that
. Furthermore, we have the following recursion formulas:
where
denotes the floor function and the initial condition is
,
,
, and
. By adding these formulas, we have
, which implies that this sequence increases faster than Fibonacci sequence. Hence, it cannot belong to the polynomial class.
In contrast, let denote the event that an even number of 0 s followed by odd number of 1 s and denotes the event that even number of 0 s always followed by odd number of 1 s in the whole string. Hence, when the length of the string N approaches infinity, the expectation of the probability of is an infinite product of probability of , which approaches zero. The indicates that the ratio of positive samples approaches zero when N approaches infinity. Thus, does not contain the term . Finally, we conclude that this grammar belongs to exponential class.
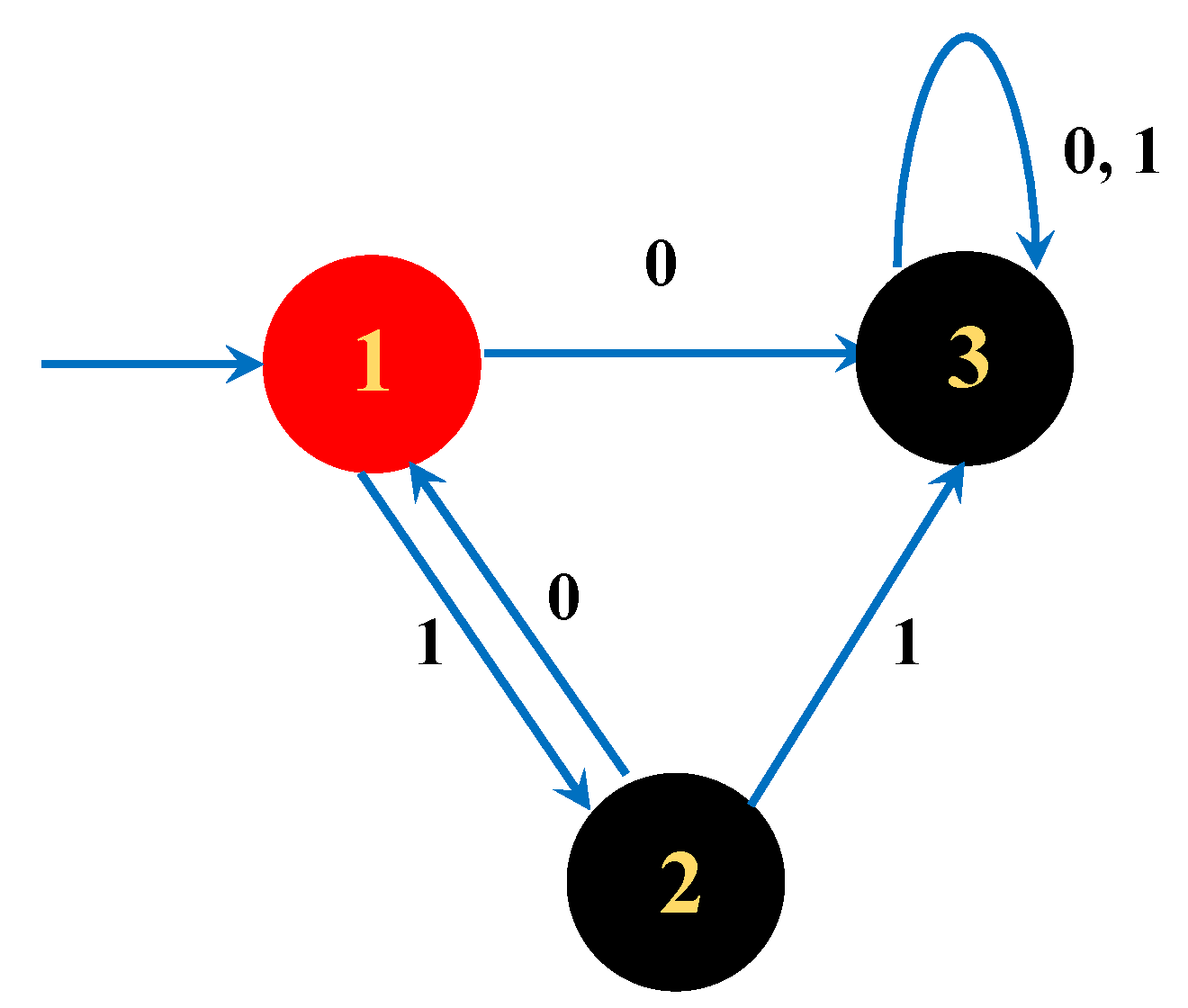
5.2. DFA Representation
Here, we use Tomita Grammar 2 to illustrate the application of Theorem 2. The transition matrix of the complete DFA is
obtained from
Figure 4.
By simple calculation, we have and . In addition, the transition matrix of the incomplete DFA is , and the largest eigenvalue is 1, which means it belongs to the polynomial class.
5.3. Generating Function Representation
Here, we use Tomita Grammar 4 to illustrate the application of Theorem 3. The generating function is , and the radius of convergence is the smallest positive pole of the function. Namely, we need to solve the equation and we have , which lies between the values of 0 and 1. Hence, it belongs to the exponential class.
5.4. Regular Expression Representation
Here, we use Tomita Grammar 5 to illustrate the application of Theorem 4. For , there exists an expression inside the Kleene star. For grammar , there exists a polynomial grammar inside the Kleene star, indicating that is an exponential grammar. Hence, G belongs to the proportional class.
6. Evaluation
Here, our empirical results show that the categorization of RGs is related to the difficulty of RNNs to learn these grammars, and the implementation is publicly available (
https://github.com/lazywatch/rnn_theano_tomita.git). We evaluated the three Tomita Grammars 1, 3 and 5. For each grammar, its subclass is shown in
Table 3. Following prior work [
31], we generated three training sets of binary strings with their lengths ranging from 1 to 14 for these grammars. We also collected three validation sets of strings with different lengths of [1, 4, 7, ⋯, 25], to make sure that the models can be trained to generalize to longer strings. The training process was terminated either when the model achieved a
-score that is equal or higher than 0.95 or when a maximum of 5000 epochs were reached. We selected several different recurrent networks to demonstrate how the difficulty of learning generalizes to different models. Specifically, we trained SRN, 2-RNN, GRU and LSTM with data generated on each grammar to a perform a binary classification task. We configured all RNNs to have the same size of hidden layer across all grammars and trained them on each grammar for 10 random trials using a mean squared error loss. In each trial, we randomly initialized the hidden layer of the model.
We followed previous research [
20] and used either activation functions—
sigmoid and
tanh—to build these RNNs. In addition, for each RNN, we used one-hot encoding to process the input alphabets of 0 s and 1 s. With this configuration, the input layer is designed to contain a single input neuron for each symbol in the alphabet of the target language. Thus, only one input neuron is activated at each time step. Moreover, we followed the approach introduced in previous research and applied the following loss function to all RNNs:
This loss function can be viewed as selecting a special “response” neuron
and comparing it to the label
y, i.e., 1 for acceptance and 0 for rejection. Thus,
indicates the value of the neuron
at time
T after a RNN receives the final input symbol. By using this simple loss function, we attempt to eliminate the potential effect of adding an extra output layer and introducing more weight and bias parameters. In addition, by this design, we ensure that the knowledge learned by a RNN resides in the hidden layer and its transitions. When applying different activation functions, we make sure that
is always normalized between the range of 0 and 1, while other neurons have their values between 0 and 1 for
sigmoid activation and −1 to 1 for
tanh activation. During training, we optimized parameters through stochastic gradient descent and employed RMSprop optimization [
52].
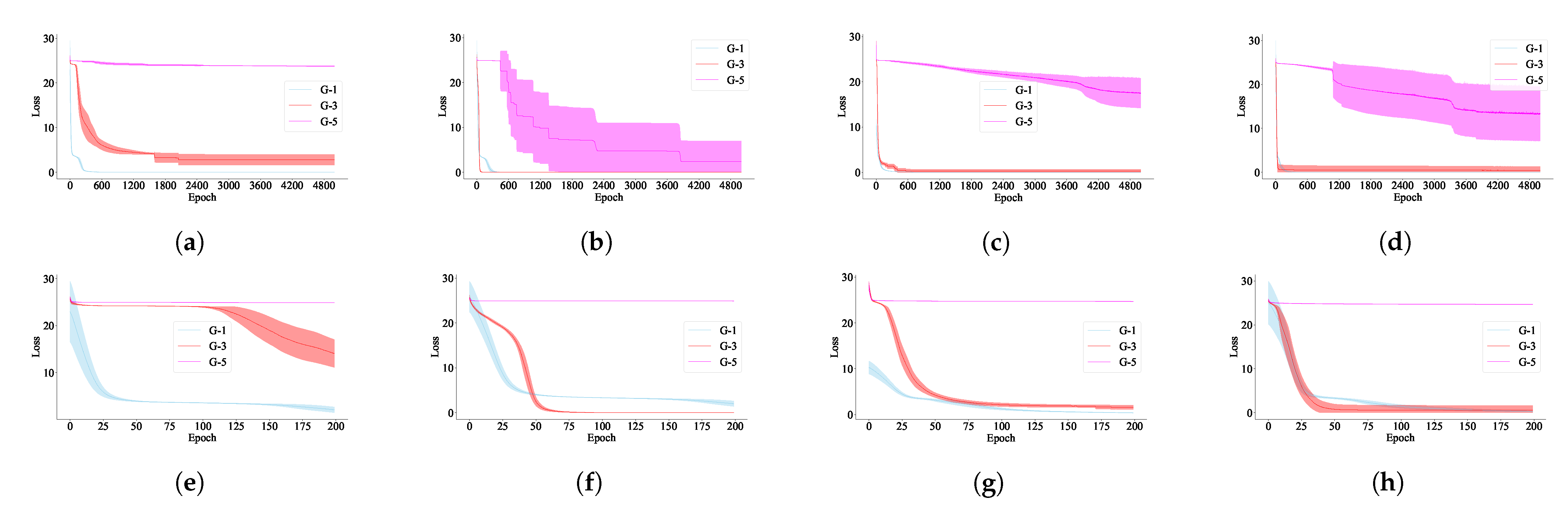
The results are shown in
Figure 5, where the results from all trials fit the shaded area associated with each plot. The
x-axis represents the number of epochs during training and the
y-axis represents the loss. In
Figure 5a–d, we see that Grammars 1 and 3, which have lower entropy values, have learning that converges much more quickly and consistently than that of Grammar 5, which has the highest entropy value. This effect holds for all RNNs evaluated. Note that Grammar 5 defines two sets of strings with equal cardinality when the string length is even. In this case, by flipping any binary digit of a string to its opposite (e.g., flipping a 0 to 1 or vice versa), a valid or invalid string can be converted into a string with the opposite label. This implies that a model must pay equal attention to any string in order to learn the underlying grammar, which makes the learning process more challenging.
To better illustrate the difference of the difficulty of learning Grammars 1 and 3, a zoomed view is provided in
Figure 5e–h, for each plot at the top row of
Figure 5. While the learning process of all models converges within 100 epochs for both grammars, it is clear that the learning process is slower for Grammar 3. These results agree with both our analysis of the entropy of these grammars and our intuition.
It would be interesting to further investigate the relationship between recurrent models and grammar learning, which is out of the scope for this paper. A promising approach would be to investigate their connection is to more closely represent DFA representations, since both are stateful models. In general, while it is possible to validate the connection between nonlinear RNNs and DFAs empirically, it has been challenging to establish a theoretical connection between nonlinear RNNs and finite state machines. Specifically, second-order RNNs naturally fit into the task of learning any DFA, while some first-order RNNs only represent a portion of DFAs, indicating that the gap (not computationally) between first-/second-order RNNs is not as significant as expected. However, for these gated models (LSTM/GRU), we only observe the differences by experiments.
From the evaluation results, a more general question is to establish an analysis between different types of RNNs and DFAs. To better study this, we discuss the following two questions: Given a RG, does there exist some common substrings misclassified by different RNNs? Given a RNN, are there consistent persistent flaws when learning different RGs? Our results observed on the Tomita grammars can be considered as an initial attempt to answer the above questions. We first find that all RNNs perform perfectly on polynomial RGs (e.g., Grammars 1, 2 and 7), and first-order RNNs perform poorly on proportional RGs (e.g., Grammars 5 and 6). In addition, for first-order RNNs, both their overall classification performance and misclassified strings indicate that these RNNs randomly choose some RGs to learn when learning proportional RGs. For exponential RGs (e.g., Grammar 3), we find that there exist some patterns in strings misclassified by certain first-order and gated RNNs. For example, LSTM tends to ignore “101” appearing at the end of a string and subsequently a has high false-positive errors (and learns some less deterministic transitions). In contrast, the SRN tends to lose count of consecutive 0 s or 1 s. These results indicate that these RNNs learn a smoothed boundary of the manifold that holds these strings. Since these common substrings are more likely to lie in the periphery of the manifold, it suggests the use of up-sampling to compensate for this problem.
7. Conclusions and Future Work
A theoretical analysis and empirical validation for subclasses of regular grammars is presented. Specifically, to measure the complexity of regular grammar, we introduced an entropy metric based on the concentric ring representation, which essentially reflects the difficulty in training RNNs to learn the grammar. Using entropy, we categorized regular grammar into three disjoint subclasses: polynomial class, exponential class and proportional class. In addition, we provided classification theorems for different representations of regular grammar. Given a regular grammar, these theorems use its corresponding properties in the given representation to efficiently determine which subclass a grammar belongs to without calculating the entropy value. Several common representations including deterministic finite automata, regular expression and sets have a corresponding case study which illustrates their applications. This categorization could also be applied to other relevant representations. Finally, we conducted an experiment to demonstrate the influence of grammar learning based on its complexity, which validates the effectiveness of the proposed entropy metric and the theoretical analysis. All RNNs have problems learning certain classes of grammars. It would seem the grammar chosen matters more than the RNN architecture. We believe this work provides a deeper understanding of the internal structure of regular grammar in the context of learning.
Future work could include an extension to other types of grammars, e.g., context-free grammars. The concentric ring representation is independent of grammar type and can be similarly applied to context-free grammars giving similar results to their entropy. However, classification differs dramatically. For instance, when we consider the parentheses grammar, the entropy can be obtained by the central binomial coefficient, which fails to fall in any of the classes proposed in this work. Another perspective is to study grammar learning in terms of recurrent models. Such a connection between DFA and RNNs can provide insights into explainable artificial intelligence and adversarial machine learning.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




