Bayesian Estimation of Geometric Morphometric Landmarks for Simultaneous Localization of Multiple Anatomies in Cardiac CT Images


Abstract
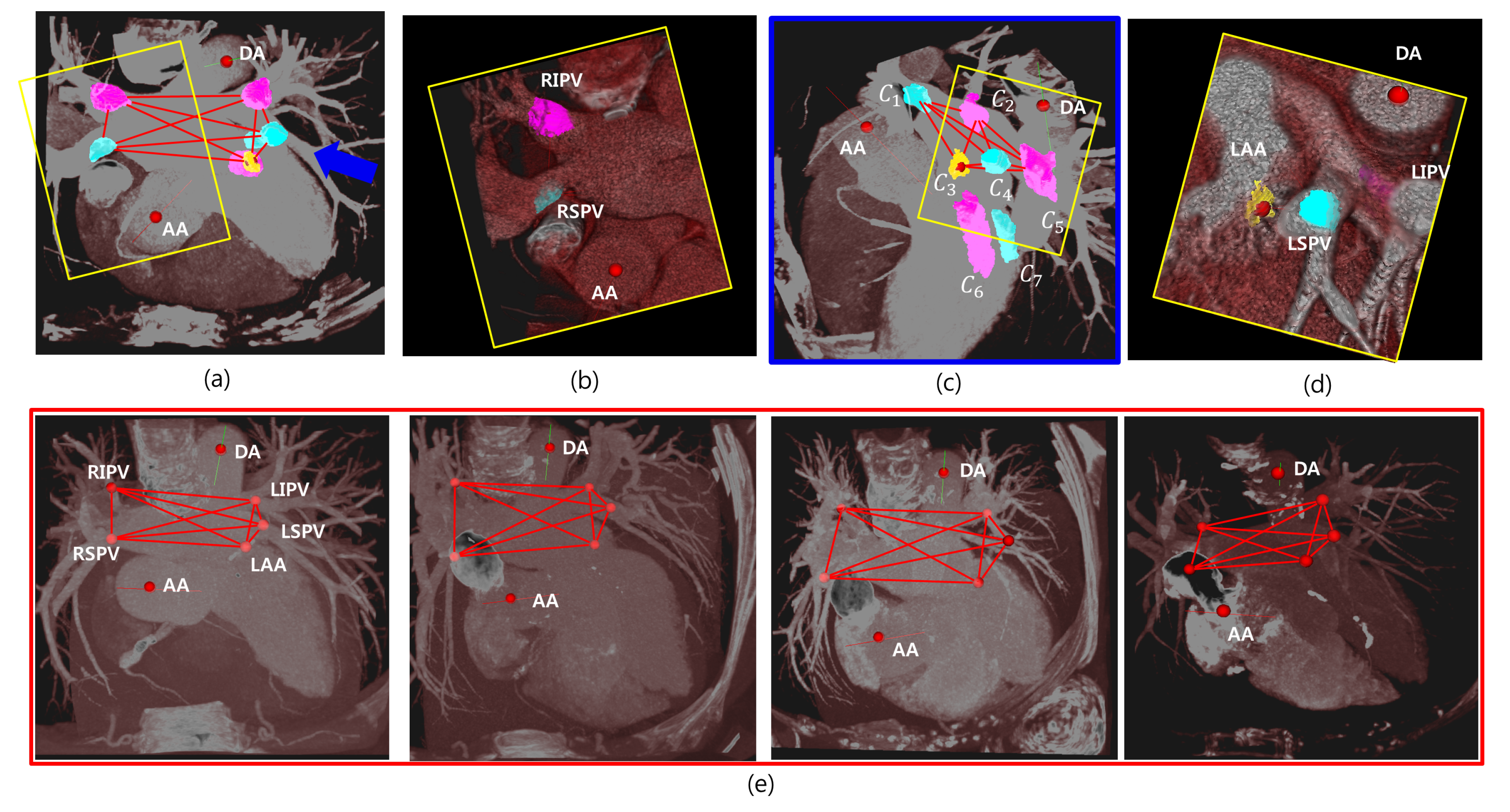
:1. Introduction
- We proposed an adaptive model for estimating patient-specific image parameters.
- We designed a Bayesian formulation utilizing the relative geometric prior distribution to solve the LA landmark detection problem.
- We estimated and provided the relative prior distributions between five anatomies (LSPV, RSPV, LIPV, LSPV, LAA) and AA and DA based on distance measures.
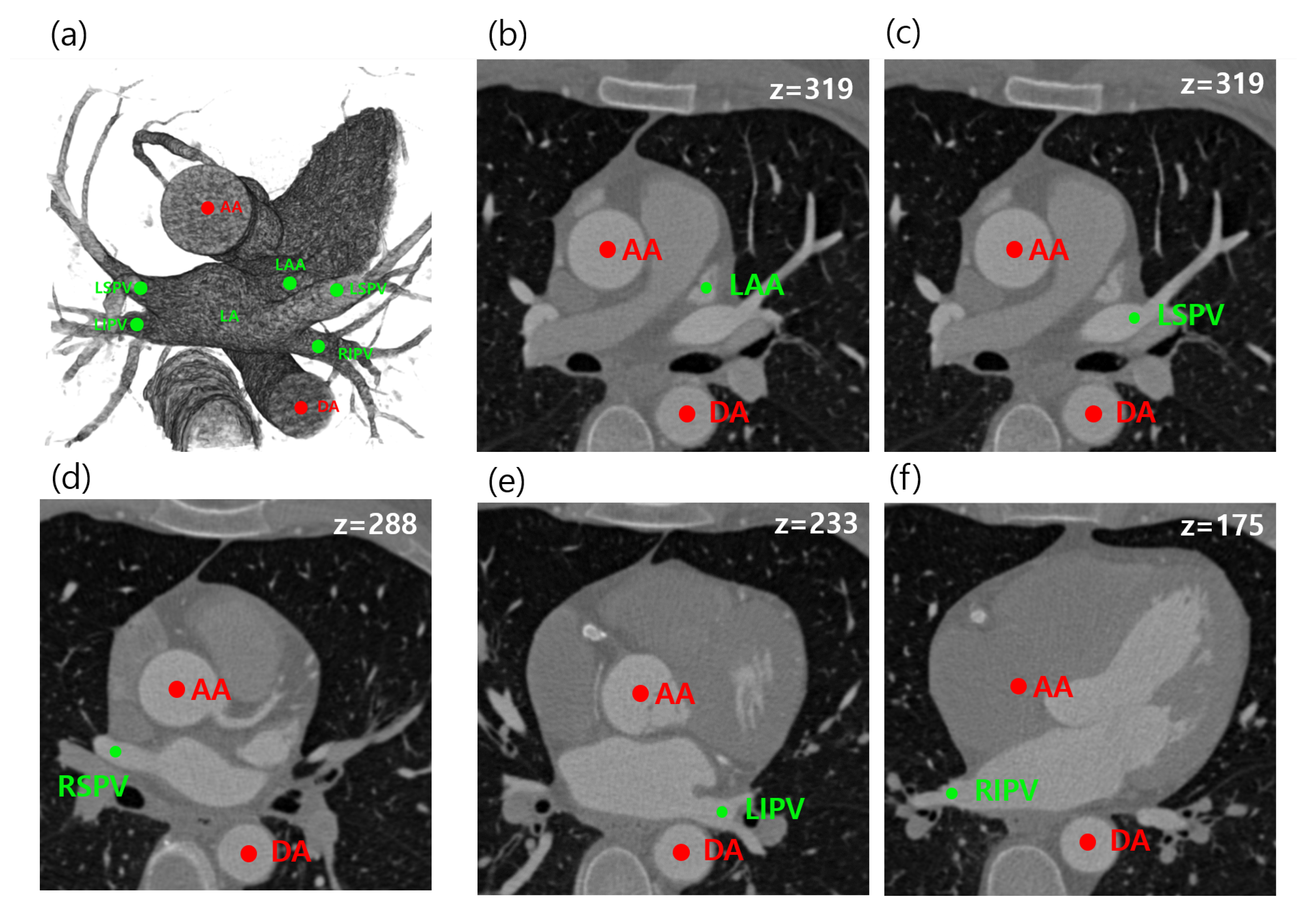
2. Materials and Methods
2.1. Estimation of Image-Specific Parameters
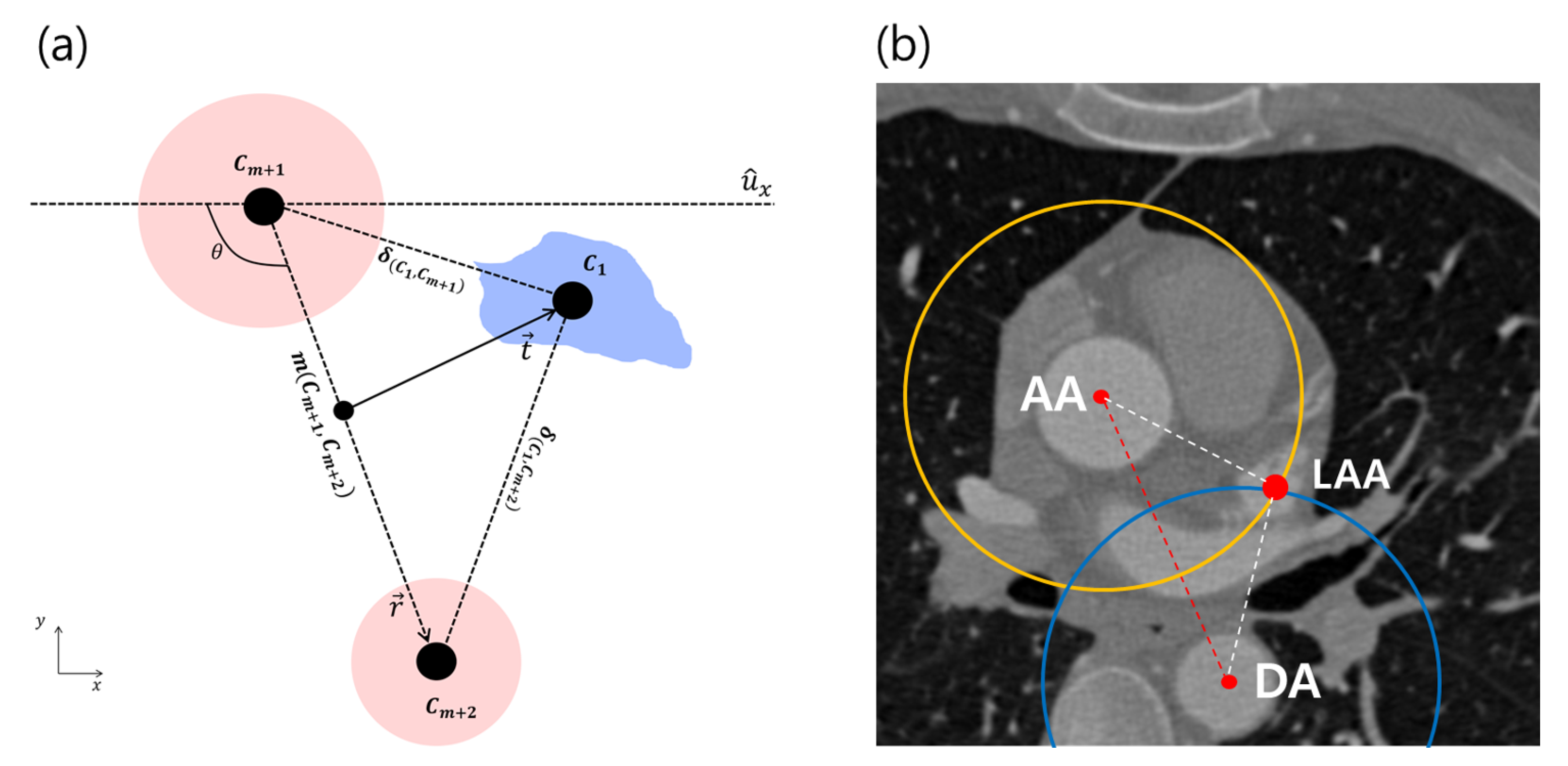
2.2. Localization of Reference Objects
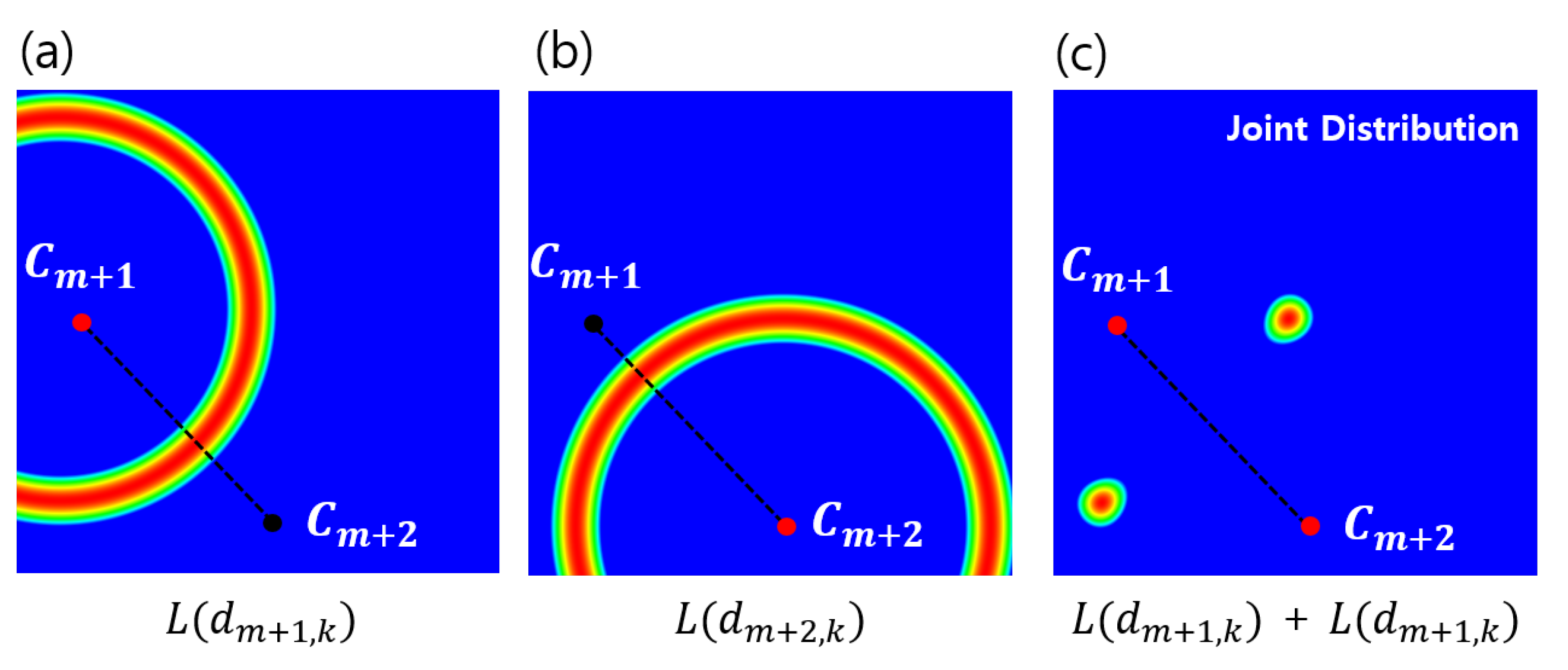
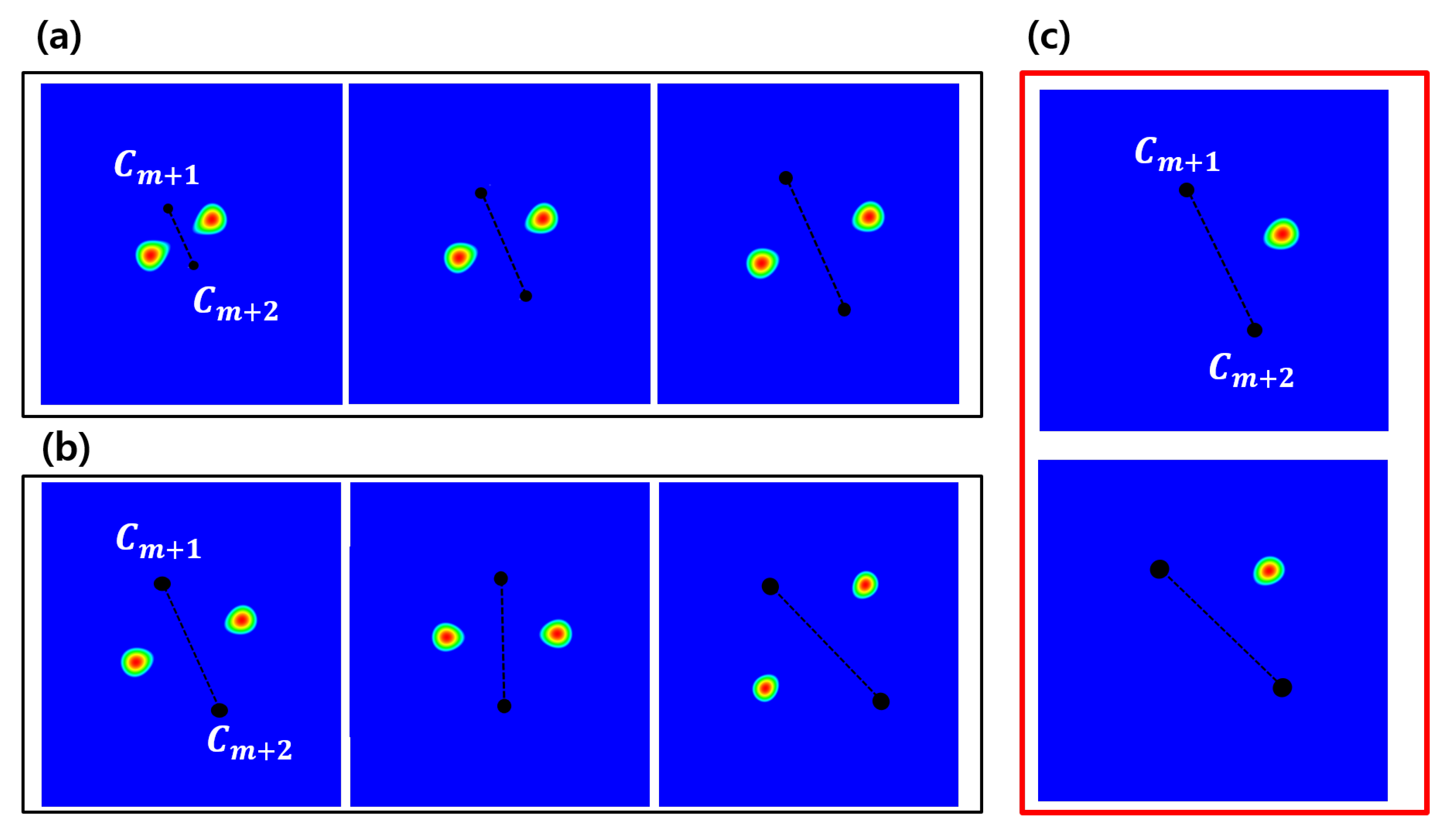
2.3. Localization of Multiple Target Objects
3. Experimental Results
3.1. Data Set
3.2. Parameters
3.3. Analysis of Geometric Prior Distribution
3.4. Quantitative Comparison with Other Methods
- TPR, true positive rate ();
- TP, true positive; TP:=;
- FN, false negative; FN:=;
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Oral, H.; Scharf, C.; Chugh, A.; Hall, B.; Cheung, P.; Good, E.; Veerareddy, S.; Pelosi, F.; Morady, F. Catheter ablation for paroxysmal atrial fibrillation. Circulation 2003, 108, 2355–2360. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weerasooriya, R.; Khairy, P.; Litalien, J.; Macle, L.; Hocini, M.; Sacher, F.; Lellouche, N.; Knecht, S.; Wright, M.; Nault, I.; et al. Catheter ablation for atrial fibrillation. J. Am. Coll. Cardiol. 2011, 57, 160–166. [Google Scholar] [CrossRef] [PubMed]
- Verma, A.; Jiang, C.Y.; Betts, T.R.; Chen, J.; Deisenhofer, I.; Mantovan, R.; Macle, L.; Morillo, C.A.; Haverkamp, W.; Weerasooriya, R.; et al. Approaches to catheter ablation for persistent atrial fibrillation. N. Engl. J. Med. 2015, 372, 1812–1822. [Google Scholar] [CrossRef] [PubMed]
- Kistler, P.M.; Earley, M.J.; Harris, S.; Abrams, D.; Ellis, S.; Sporton, S.C.; Schilling, R.J. Validation of Three-Dimensional Cardiac Image Integration: Use of Integrated CT Image into Electroanatomic Mapping System to Perform Catheter Ablation of Atrial Fibrillation. J. Cardiovasc. Electrophysiol. 2006, 17, 341–348. [Google Scholar] [CrossRef] [PubMed]
- Ostermayer, S.H.; Reisman, M.; Kramer, P.H.; Matthews, R.V.; Gray, W.A.; Block, P.C.; Omran, H.; Bartorelli, A.L.; Della Bella, P.; Di Mario, C.; et al. Percutaneous left atrial appendage transcatheter occlusion (PLAATO system) to prevent stroke in high-risk patients with non-rheumatic atrial fibrillation: Results from the international multi-center feasibility trials. J. Am. Coll. Cardiol. 2005, 46, 9–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jia, D.; Jeon, B.; Park, H.B.; Chang, H.J.; Zhang, L.T. Image-Based Flow Simulations of Pre-and Post-left Atrial Appendage Closure in the Left Atrium. Cardiovasc. Eng. Technol. 2019, 10, 225–241. [Google Scholar] [CrossRef] [PubMed]
- Tobon-Gomez, C.; Geers, A.J.; Peters, J.; Weese, J.; Pinto, K.; Karim, R.; Ammar, M.; Daoudi, A.; Margeta, J.; Sandoval, Z.; et al. Benchmark for algorithms segmenting the left atrium from 3D CT and MRI datasets. IEEE Trans. Med. Imaging 2015, 34, 1460–1473. [Google Scholar] [CrossRef]
- Xiong, Z.; Xia, Q.; Hu, Z.; Huang, N.; Bian, C.; Zheng, Y.; Vesal, S.; Ravikumar, N.; Maier, A.; Yang, X.; et al. A global benchmark of algorithms for segmenting the left atrium from late gadolinium-enhanced cardiac magnetic resonance imaging. Med. Image Anal. 2020, 67, 101832. [Google Scholar] [CrossRef]
- Karim, R.; Mohiaddin, R.; Rueckert, D. Left atrium segmentation for atrial fibrillation ablation. In Medical Imaging; International Society for Optics and Photonics: Washington, DC, USA, 2008. [Google Scholar]
- Lombaert, H.; Sun, Y.; Grady, L.; Xu, C. A multilevel banded graph cuts method for fast image segmentation. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 259–265. [Google Scholar]
- Depa, M.; Sabuncu, M.R.; Holmvang, G.; Nezafat, R.; Schmidt, E.J.; Golland, P. Robust atlas-based segmentation of highly variable anatomy: Left atrium segmentation. In International Workshop on Statistical Atlases and Computational Models of the Heart; Springer: Berlin/Heidelberg, Germany, 2010; pp. 85–94. [Google Scholar]
- Zhuang, X.; Rhode, K.S.; Razavi, R.S.; Hawkes, D.J.; Ourselin, S. A registration-based propagation framework for automatic whole heart segmentation of cardiac MRI. IEEE Trans. Med. Imaging 2010, 29, 1612–1625. [Google Scholar] [CrossRef] [Green Version]
- Tao, Q.; Shahzad, R.; Ipek, E.G.; Berendsen, F.F.; Nazarian, S.; van der Geest, R.J. Fully automated segmentation of left atrium and pulmonary veins in late gadolinium enhanced MRI. J. Cardiovasc. Magn. Reson. 2016, 18, O84. [Google Scholar] [CrossRef] [Green Version]
- Zuluaga, M.A.; Cardoso, M.J.; Modat, M.; Ourselin, S. Multi-atlas propagation whole heart segmentation from MRI and CTA using a local normalised correlation coefficient criterion. In Proceedings of the International Conference on Functional Imaging and Modeling of the Heart, Bordeaux, France, 6–8 June 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 174–181. [Google Scholar]
- Qiao, M.; Wang, Y.; van der Geest, R.J.; Tao, Q. Fully automated left atrium cavity segmentation from 3D GE-MRI by multi-atlas selection and registration. In Proceedings of the International Workshop on Statistical Atlases and Computational Models of the Heart, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 230–236. [Google Scholar]
- Nuñez-Garcia, M.; Zhuang, X.; Sanroma, G.; Li, L.; Xu, L.; Butakoff, C.; Camara, O. Left atrial segmentation combining multi-atlas whole heart labeling and shape-based atlas selection. In International Workshop on Statistical Atlases and Computational Models of the Heart; Springer: Berlin/Heidelberg, Germany, 2018; pp. 302–310. [Google Scholar]
- Mortazi, A.; Karim, R.; Rhode, K.; Burt, J.; Bagci, U. CardiacNET: Segmentation of left atrium and proximal pulmonary veins from MRI using multi-view CNN. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 377–385. [Google Scholar]
- Liao, H.; Tang, Y.; Funka-Lea, G.; Luo, J.; Zhou, S.K. More knowledge is better: Cross-modality volume completion and 3D+ 2D segmentation for intracardiac echocardiography contouring. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 535–543. [Google Scholar]
- Zhang, X.; Noga, M.; Martin, D.G.; Punithakumar, K. Fully automated left atrium segmentation from anatomical cine long-axis MRI sequences using deep convolutional neural network with unscented Kalman filter. Med. Image Anal. 2020, 68, 101916. [Google Scholar] [CrossRef] [PubMed]
- Borra, D.; Andalò, A.; Paci, M.; Fabbri, C.; Corsi, C. A fully automated left atrium segmentation approach from late gadolinium enhanced magnetic resonance imaging based on a convolutional neural network. Quant. Imaging Med. Surg. 2020, 10, 1894. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Alansary, A.; Cerrolaza, J.J.; Khanal, B.; Sinclair, M.; Matthew, J.; Gupta, C.; Knight, C.; Kainz, B.; Rueckert, D. Fast multiple landmark localisation using a patch-based iterative network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 563–571. [Google Scholar]
- Oktay, O.; Bai, W.; Guerrero, R.; Rajchl, M.; de Marvao, A.; O’Regan, D.P.; Cook, S.A.; Heinrich, M.P.; Glocker, B.; Rueckert, D.; et al. Stratified Decision Forests for Accurate Anatomical Landmark Localization in Cardiac Images. IEEE Trans. Med. Imaging 2017, 36, 332–342. [Google Scholar] [CrossRef] [PubMed]
- Ghesu, F.C.; Georgescu, B.; Zheng, Y.; Grbic, S.; Maier, A.; Hornegger, J.; Comaniciu, D. Multi-scale deep reinforcement learning for real-time 3D-landmark detection in CT scans. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 176–189. [Google Scholar] [CrossRef] [PubMed]
- Seidlitz, J.; Váša, F.; Shinn, M.; Romero-Garcia, R.; Whitaker, K.J.; Vértes, P.E.; Wagstyl, K.; Reardon, P.K.; Clasen, L.; Liu, S.; et al. Morphometric similarity networks detect microscale cortical organization and predict inter-individual cognitive variation. Neuron 2018, 97, 231–247. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Daboul, A.; Ivanovska, T.; Bülow, R.; Biffar, R.; Cardini, A. Procrustes-based geometric morphometrics on MRI images: An example of inter-operator bias in 3D landmarks and its impact on big datasets. PLoS ONE 2018, 13, e0197675. [Google Scholar] [CrossRef] [Green Version]
- Moriconi, S.; Zuluaga, M.A.; Jäger, H.R.; Nachev, P.; Ourselin, S.; Cardoso, M.J. Elastic registration of geodesic vascular graphs. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 810–818. [Google Scholar]
- Devine, J.; Aponte, J.D.; Katz, D.C.; Liu, W.; Vercio, L.D.L.; Forkert, N.D.; Marcucio, R.; Percival, C.J.; Hallgrímsson, B. A Registration and Deep Learning Approach to Automated Landmark Detection for Geometric Morphometrics. Evol. Biol. 2020, 47, 246–259. [Google Scholar] [CrossRef]
- Jeon, B.; Hong, Y.; Han, D.; Jang, Y.; Jung, S.; Hong, Y.; Ha, S.; Shim, H.; Chang, H.J. Maximum a posteriori estimation method for aorta localization and coronary seed identification. Pattern Recognit. 2017, 68, 222–232. [Google Scholar] [CrossRef]
- Jeon, B.; Jang, Y.; Shim, H.; Chang, H.J. Identification of coronary arteries in CT images by Bayesian analysis of geometric relations among anatomical landmarks. Pattern Recognit. 2019, 96, 106958. [Google Scholar] [CrossRef]
- Rotterdam Dataset. Available online: http://coronary.bigr.nl/centerlines/ (accessed on 30 December 2020).
- Schaap, M.; Metz, C.; van Walsum, T.; van der Giessen, A.; Weustink, A.; Mollet, N.; Bauer, C.; Bogunovi, H.; Castro, C.; Deng, X.; et al. Standardized Evaluation Methodology and Reference Database for Evaluating Coronary Artery Centerline Extraction Algorithms. Med. Image Anal. 2009, 13, 701–714. [Google Scholar] [CrossRef] [Green Version]
- Alhafez, B.A.; Ocazionez, D.; Sohrabi, S.; Sandhu, H.; Estrera, A.; Safi, H.J.; Evangelista, A.; Hurtado, L.D.S.; Guala, A.; Prakash, S.K.; et al. Aortic arch tortuosity, a novel biomarker for thoracic aortic disease, is increased in adults with bicuspid aortic valve. Int. J. Cardiol. 2019, 284, 84–89. [Google Scholar] [CrossRef] [PubMed]
- Vital. Available online: https://www.vitalimages.com/ (accessed on 30 December 2020).
- Alansary, A.; Oktay, O.; Li, Y.; Le Folgoc, L.; Hou, B.; Vaillant, G.; Kamnitsas, K.; Vlontzos, A.; Glocker, B.; Kainz, B.; et al. Evaluating reinforcement learning agents for anatomical landmark detection. Med. Image Anal. 2019, 53, 156–164. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al, W.A.; Yun, I.D. Partial policy-based reinforcement learning for anatomical landmark localization in 3d medical images. IEEE Trans. Med. Imaging 2019, 39, 1245–1255. [Google Scholar] [CrossRef] [PubMed] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | LSPV (mm) | LIPV (mm) | RSPV (mm) | RIPV (mm) | LAA (mm) |
|---|---|---|---|---|---|
| AA | 65.71 2.95 | 80.09 6.04 | 44.16 3.55 | 63.74 8.71 | 49.23 3.02 |
| DA | 46.54 7.31 | 26.22 4.38 | 82.15 9.62 | 63.31 8.66 | 65.37 10.77 |
| Method | LSPV | LIPV | LAA | RIPV | RSPV | Average |
|---|---|---|---|---|---|---|
| Proposed (Public [31]) | 1.0 | 1.0 | 0.93 | 1.0 | 0.96 | 0.98 |
| Proposed (Selected) | 1.0 | 0.94 | 0.88 | 1.0 | 0.92 | 0.95 |
| Vitrea (Public [31]) | 0.94 | 0.97 | - | 0.97 | 0.81 | 0.92 |
| Vitrea (Selected) | 0.93 | 0.89 | - | 0.96 | 0.82 | 0.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeon, B.; Jung, S.; Shim, H.; Chang, H.-J. Bayesian Estimation of Geometric Morphometric Landmarks for Simultaneous Localization of Multiple Anatomies in Cardiac CT Images. Entropy 2021, 23, 64. https://doi.org/10.3390/e23010064
Jeon B, Jung S, Shim H, Chang H-J. Bayesian Estimation of Geometric Morphometric Landmarks for Simultaneous Localization of Multiple Anatomies in Cardiac CT Images. Entropy. 2021; 23(1):64. https://doi.org/10.3390/e23010064
Chicago/Turabian StyleJeon, Byunghwan, Sunghee Jung, Hackjoon Shim, and Hyuk-Jae Chang. 2021. "Bayesian Estimation of Geometric Morphometric Landmarks for Simultaneous Localization of Multiple Anatomies in Cardiac CT Images" Entropy 23, no. 1: 64. https://doi.org/10.3390/e23010064
APA StyleJeon, B., Jung, S., Shim, H., & Chang, H. -J. (2021). Bayesian Estimation of Geometric Morphometric Landmarks for Simultaneous Localization of Multiple Anatomies in Cardiac CT Images. Entropy, 23(1), 64. https://doi.org/10.3390/e23010064