To facilitate reproducibility, the code and scripts for running experiments can be found in the supplementary. Additionally, we have included information about model architectures and metrics in
Appendix F. Our experiments aim to test whether the NID architecture and the objective of Equation (
6) can be used to effectively model higher-order interactions. In comparison to standard approaches, NID provides a more detailed description of where the information exists in a distribution, which may be desirable when attempting to understand certain systems. We show that NID performs as well or better on synthetic data with higher-order interactions, while simultaneously producing an accurate and expressive decomposition.
5.1. Distinguishing Error-Correcting Codes From Noise
In our first set of experiments, we introduce two synthetic datasets that only contain higher-order dependencies (i.e., all lower order information is indistinguishable from noise). The first of these is based on the high-dimensional parity distribution. We generate data by drawing uniform samples from the
hypercube, then add an additional random variable corresponding to the parity of the previous
. In each dataset, we generated roughly
samples, and used a
train/validation split. Even this simple example is deceptively challenging from a learning perspective, with theoretical results for related problems, such as learning parity with noise [
29], the classical XOR problem in supervised learning [
30], overparameterization in XOR detection [
31], and the depth of computation required for learning higher-order functions [
32]. Recent work has also illustrated the practical failure of standard deep networks to efficiently learn/represent the parity function [
33].
In
Table 1, we report values for the negative log-likelihood on four different sizes of parity data, with mean and deviation across 5 random initializations. Each of the approaches in the top half of the table attempt to model the joint density of the data, with the first three being sequence models (RNN, LSTM, and GRU) and the remaining being autoregressive density estimators (MADE, MADE-U, and MADE-S). As
of the variables are indistinguishable from noise, we only report the negative log-likelihood for the last variable in the sequence/autoregressive prediction. This value represents how well a given architecture can reproduce the parity mapping for a fixed ordering of the variables. If the model learns the correct functional relationship, it should report 0 nats (appearing as bolded values in the table), and if cannot distinguish the relationship from noise, it should report
nats. For the sequence models, we attempt to predict the next variable in the sequence from the current variable and some cumulative latent representation. The autoregressive models are all MADE networks [
25] which parameterize the logits of Bernoulli random variables. We explored two ways of incorporating multiple autoregressive orderings into MADE, by either (a) ensembling the outputs of unique MADE networks for each ordering (MADE-U), or (b) using a single MADE network shared across all orderings (MADE-S). In both cases, we selected a linear number of orderings at random, since parity is symmetric in the ordering of variables. Note that doing this implies MADE-U and MADE-S test the naive baseline introduced in
Section 4 when
. For values of
there is no structure to learn, and each model correctly returns the log-likelihood of random noise. We found that the performance of most models degraded in the large parity regime. For 15 and 20 parity, none of the sequence models were able to identify the ground truth relationship. Note that we avoid injecting additional supervision in these models, such as providing variable length sequences, introducing symmetry priors, or predicting the cumulative parity. The autoregressive models did much better in these cases, with most of the variants converging to the ground truth. Adding multiple orderings (MADE-U and MADE-S) helped the autoregressive models in the higher-dimensional cases. While both extensions performed similarly on all experiments, MADE-U used a separate model for each of the
n orderings, making it extremely inefficient in the number of parameters.
In the bottom half of
Table 1, we compare models that lower bound the joint density. The first two models are generative models (Autoencoders and Gaussian Variational Autoencoders), and the remaining are variants of the NID algorithm. While both of these approaches optimize a lower bound, they differ in how they measure the quality of a learned representation. To discourage memorization, autoencoders create a bottleneck in the architecture and often add noise to the compressed intermediate representation. However, this is not a hard constraint on the flow of information through the network, and autoencoders are still prone to memorization. In contrast, NID attempts to predict
using only information from other variables
, which prevents the network from passing information about
directly to the output. Unlike the sequence and density models, which could only meaningfully predict a single variable, both of these approaches can potentially predict every variable. For this reason, we report the sum of negative log-likelihoods for all variables. By Equation (
6), we see that NID contains a different term for reconstruction at each order
k. We chose
for these experiments (i.e., the NID network has 5 layers of incremental likelihood estimation), and show the reconstruction at the final value of
k for the sake of comparison. In the case of parity, we found a larger number of layers to be detrimental to performance for two reasons: (1) early layers have nothing to predict (by design of the experiment), leading to an inefficient utilization of model parameters and computation; (2) early representations heavily influence future computations, and networks with a large number of layers were prone to unstable learning dynamics. This was especially noticeable in parity, as early layers do not have a salient gradient signal to follow during training. The left half of
Table 2 below shows how the differences between intermediate layers compare to the ground truth decomposition for 5-parity. Recall that the local differences of
Section 4 measure the incremental change in likelihood when increasing the subset size, and Equation (
6) measures the change in likelihood when utilizing contextual representations of increasing size. Using mean as our representation function allowed the network to detect structure at earlier contextual size (between layers 3 and 4) than the ground truth subset size of 4 and 5.
We found that NID consistently outperforms the autoencoders in terms of reconstruction. To further verify that the network is learning to identify the correct relationships instead of memorizing the input, we freeze the weights/gradients of a trained NID model and feed its outputs into a small feed-forward MLP (NID + MLP). By the nature of parity, if the ground truth function is known for at least one variable, then a simple linear function can extend this prediction to all other variables. We see that this is indeed the case for NID, as NID + MLP is able to achieve near perfect reconstruction. If we attempt to do the same thing with the output of the autoencoders, we do not observe any change in the overall reconstruction. This implies that the autoencoders are memorizing noise information to improve reconstruction, rather than learning useful or meaningful features from the data.
The second dataset is based on error-correcting codes (MDS codes [
34]), which can be thought of as a generalization of the parity function. In MDS codes, the dependence exists among any subset of greater than
k variables, while all subsets of size
k are independent. Each conditional marginal in an MDS code is parameterized by a Categorical distribution with discrete support
, compared to
for parity. As with the previous synthetic dataset, we compare the aforementioned approaches on this data, with results appearing in
Table 3. As a slight change of notation, the bolded values in this Table represent the best approach (in terms of NLL) for each column/dataset. These data are strictly harder than the parity problem, and many of the approaches did poorly in comparison. In particular, both of the autoencoders were unable to distinguish structure from noise in any of the datasets. Although NID was able to perform well in some cases, we observed a large amount of variability and sensitivity to initial conditions on this data in comparison to parity (as seen in the deviation for NID across almost every MDS experiment). However, when freezing and combining with an MLP (as with the parity experiments), the variability reduces substantially. This can be explained as follows. The reported values correspond to a sum of independent predictors for each
based on contexts of increasing order. If even a single one of these predictors learns the true function, then the MLP can use it to predict all other variables. High variability in the standard setting implies that the true function is not always learned for each
, whereas low variability in NID + MLP implies the true function is learned consistently at least once.
5.2. Higher-Order Interactions in the Neural Code
In their work on using maximum entropy methods to test for collective behavior in the neural code, the authors of [
35] used data collected from simultaneous recordings of a salamander retina. These data were recently made open source [
36], and they contain a description of the setting under which experiments were conducted, along with the pipeline for data collection. To summarize some of the key points, the data consists of neural spike trains recorded from salamander retinal ganglion cells, with potentials binned at 20 ms (meaning any activation of a single neuron within the time window is recorded as 1). In total, there are 160 neurons and approximately 300,000 samples gathered over a period of 2 h. This data is one of very few public datasets that contain simultaneous measurements of neurons from a multi-electrode array (MLA). Simultaneous recording is critical for studying the neural code, as neuron co-activation (population coding) and temporal locality (rate coding) are the main contenders for how information is encoded in the brain.
To further explore the collective hypothesis, we applied models from the previous section to this data in a number of different ways. The left side of
Table 4 shows the negative log-likelihood obtained by autoencoders and Gaussian variational autoencoders. In addition to the standard MLP architecture used in previous sections, we test how well these models do when using a Convolutional architecture. On the right side of
Table 4, we use MADE-S and parameterize a linear number of subsets using a sliding window of size
k (the baseline mentioned at the beginning of
Section 4). Note that, unlike the parity experiment, it makes sense in this context to use
. The numbers reported in
Table 4 were from the
k which produced the best likelihood, which happened to be 50 in our experiments (shown in
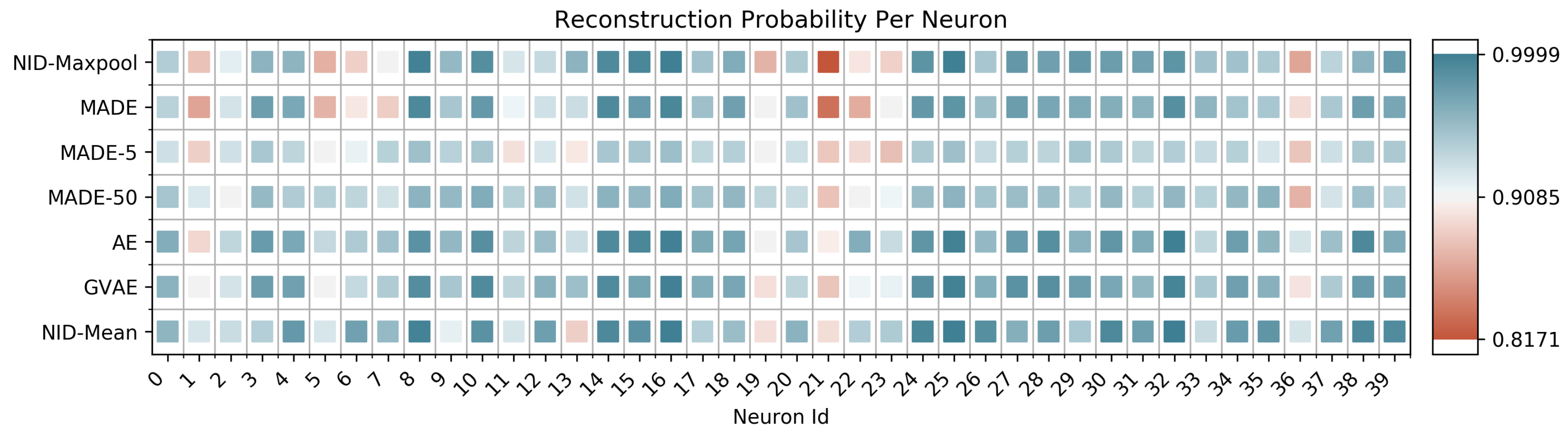
Figure 2 as MADE-50). We compare the above approaches against NID using mean pooling (NID-Mean) and max pooling (NID-Maxpool) as the representation function. Additionally, in
Table 5 we report the intermediate reconstruction of NID-Mean at each layer (as in
Table 2). If we plot the negative log-likelihood for each neuron across different methods—or when blocks of size
k are used in MADE-S, an average over the
k appearances of this neuron in the loss—we observe that many neurons are almost perfectly predictable, with a select few responsible for the gap in reconstruction.
Figure 2 shows a random selection of 40 neurons, with plots for the remaining 120 appearing in
Appendix E.
Even for a relatively small value of
(shown in
Figure 2 as MADE-5), NID performs comparably or better than both autoregressive models and autoencoders, and often does better at modeling critical neurons. This result lends itself to the following interpretation. While lower-order dependency might be global among the collection of neurons (for example, through redundant activations), higher-order dependency is likely not a global property. This observation is supported by the capability of all approaches to almost perfectly model most neurons. At the local level, some neurons are difficult to completely predict with standard approaches, but can be predicted with NID-Mean. This might imply that the activity of certain neurons depends on higher-order functions among neighboring neurons (or, more generally, functions for which our approach is more capable of modeling). Given what is known about the Neurophysiology of the retina, these results may not be so surprising. Most of the neuronal processing in early visual areas is thought to be feedforward, with a sparse collection of inhibitory cell types (such as amacrine and horizontal cells) that play a role in defining spatial receptive fields [
37]. The neurons that are more difficult to predict may correspond to these laterally interconnected neurons, although there is no way for us to test this hypothesis on the current data. One interesting path forward for future work would be analyze data in which cell types are known, to see if they could be differentiated purely by their activation patterns (as opposed to their connectivity structure [
38], or the use of imaging). Additionally, evaluation of different brain regions (other than early sensory processing) may yield more interesting (higher-order) information profiles.







{kind=link}
{kind=link}