1. Introduction
In this paper we study features of the spectral problem for the family of elliptic operators of the reaction-diffusion type posed in the finite domain
,
. These operators are also known as Schrödinger operators or Schrödinger Hamiltonians and they are defined by the differential expression of the form:
Here
is the distributional realisation of the Laplace operator and
is the multiplication operator with the real function
. The parameter
describes a random perturbation of a given potential. The associated spectral problem is to find an eigenvalue
and an eigenmode
such that
u verifies:
and a set of boundary conditions. We will consider boundary conditions that lead to the realization of the expression
H as a self-adjoint operator in a Hilbert space. In particular, we will consider functions
with Dirichlet boundary conditions and
, where
is the first-order Sobolev space of functions (square integrable functions whose gradient is also square integrable) that satisfy the periodic boundary conditions [
1,
2]. In what follows we will use
to denote the
norm of a square integrable function.
We will consider—as an academic prototype—short-range confining electrostatic potentials such as those considered in [
3] (see also [
1,
2]) and a more challenging class of confining potentials related to the effect of Anderson localization [
4]. By the effect of localization we mean that we search for eigenvalues
such that
u,
, is essentially zero in the large part of the domain
. The Anderson model describes quantum states of an electron in a disordered alloy that can transition from metallic to insulating behavior. Loosely stated, we aim to model the connection
, where
,
is the eigenmode of the lowermost
in (
1). Such eigenmodes are called the ground states, and
is called the ground state energy. Note that for the elliptic reaction-diffusion operators
defined in
and with the potential
, which is bounded, nonnegative and positive on a set of positive measures, there exists—by an application of the Krein–Rutman Theorem—the unique ground state
, which verifies (
1) and so the mapping
is well defined; see [
5,
6].
We emphasize that we use the following regularization approach from [
6] to deal with rough potentials. Namely for
, which is bounded, nonnegative and positive on a set of positive measures there exists
,
such that
. It can be shown by direct calculation that the operator
defined in
by the differential expression:
has the same eigenvalues as the operator
. Furthermore,
is an eigenmode of
if and only if
is an eigenmode of
. Based on this equivalence, we call the function
the effective confining potential defined by
. For more details see [
5,
7].
One possibility of obtaining data-sparse representations of the solutions of elliptic problems is through the use of tensor networks also known as tensor train decompositions or matrix product states [
8,
9]. We choose a more direct approach known as Variational Physical Informed Neural Network (VPINN) [
10,
11,
12]. Realizations of these dense network architectures are trained to solve the variational formulation of the problem. This approach to training neural networks is a part of the unsupervised learning paradigm. It is a mesh-less approach that is capable of solving variational (physical) problems, by minimizing the loss functional, which combines the variational energy of the system together with penalty terms implementing further physical or normalization constraints.
The main physical constraint for the ground state is the positivity constraint. To deal with excited states we need to implement further symmetry constraints in the variational space. We opt for a different approach, also based on positivity constraints and a-posteriori error estimation. We use the neural network to approximate the solution of the source problem:
with associated boundary conditions. The solution
u is called the landscape function, and in this case we are interested in the mapping
. The landscape function is a positive function in
and its reciprocal
is called the effective potential. The effective potential provides a mechanism that incurs localization on bounded states. To localize the excited states we use the approach of [
5,
7]. Let
be the
i-th lowermost minimum of the effective potential
W. It was observed in [
5] that the following heuristic formula:
yields good approximations to the energies of excited states. Note that this relationship, given its simplicity, is also something we might reasonably hope to learn algorithmically from a sample of landscape functions. This was stated as a motivation to utilize neural networks in the study of the eigenvalue problem for Schrödinger operators [
3].
For an eigenmode
of
H with the eigenvalue
we have the estimate:
,
. This estimate can be obtained (see [
13]) using the Feynman–Kac formula for the representation of the bounded state as an expectation of an integral of the Brownian motion. It was further argued in [
13] that an eigenmode
with energy
can only localize in the region:
Subsequently, as a combination of (
2) and (
3) we get both information on the excited state energy and information on the location of the excited state’s support.
The Motivation and the Contribution of this Paper
The use of neural networks as data-sparse representations of complex, high dimensional nonlinear mappings is an emerging trend in many disciplines. In particular, it has been used to tackle many body Schrödinger equations [
14,
15], the Black–Scholes equation, the Hamilton–Jacobi–Bellman equation, and the Allen–Cahn equation [
10,
11,
16,
17,
18,
19,
20].
In general, all of the above problems can be reduced to computing an approximation of the function . This approximation is constructed by optimizing (training) the parameters of the family of test functions (we chose the family of all realizations of a given neural network architecture) so that the value of the appropriate energy functional (for the chosen model) is minimal. The main challenge in such an approach is to assess the approximation accuracy and to ensure that the computed realization of the neural network satisfies further physical constraints, such as symmetry constraint or the boundary conditions.
Further physical, but also numerical, constraints can be built into the optimization model in several ways. The most scalable and flexible way is to use penalization [
10,
11,
20,
21]. A alternative more subtle, and more accurate way is to introduce the constraints directly into the family of test functions as it is done in the architecture of the PauliNet from [
14] (see also [
22,
23]), or to construct a family of test functions using an ansatz that combines several components of the solution, which are themselves realizations of neural networks [
12,
24].
In this study we focus on the potentials for which the Hamiltonian satisfies the Krein–Rutman theorem (the scaled ground state is the unique positive and smooth function). Examples of such potentials are the effective potentials associated with the Anderson localization. Since this is a more restrictive class of potentials than those considered in [
14], we opt for a direct approach. Our contribution is the introduction of the residual error estimator into the Deep Ritz Algorithm from [
20]. This in turn allows us to use Temple–Kato [
25,
26] or similar inequalities [
27,
28] to ascertain if the ground state generated by the neural network is a certified small perturbation of a physical eigenstate. For activation functions that are smooth enough we can calculate the strong form of the eigenvalue residual and then compute its norm using a quadrature or quasi-Monte Carlo integration. Using the residual estimator we stop the optimization (training process) when the eigenvalue residual is small enough (satisfies the preset tolerance) and/or the convergence criterion for the optimization algorithm is met (Adam optimizer). The use of ansatz functions based on neural networks, such as [
24], will undoubtedly be a method of choice for 2D or 3D problems. However, this method depends on an accurate representation of the boundary of the domain
and thus faces challenges in scaling to higher dimensions.
The treatment of physical symmetries becomes critical when approximating excited states. For dealing with this task, we reformulate the problem as an inverse problem based on the solution of the source problem . The main constraint that the solution must satisfy is again positivity, and we construct an error estimator to certify the quality of the solution.
The network architectures used so far are dense network architectures. Inspired by [
3], we study a parameter-dependent family of potentials and present a fully convolutional encoder–decoder neural network as a reduced order (surrogate) model for this family of partial differential equations and the mapping
. We formulate a new certified surrogate modeling approach based on neural networks that is inspired by the work on certified surrogate modeling from [
29] and the U-net architecture from [
30]. We use the residual error estimator from the first part of the paper as a criterion for the surrogate (encoder–decoder) model update. For further details see
Section 3.5.
Let us summarize the three classes of exemplar problems studied in this paper. First, we study the eigenvalue problem for approximating the unique positive normalized ground state . We aim to construct certified, robust and scalable—with respect to the increase in the dimension of the problem—approximation methods. Second, to approximate the eigenvalues higher in the spectrum we study the landscape function. The landscape function is obtained as a solution to the source problem . It is again a positive smooth function and positivity is the only physical constraint needed to study the localization phenomena for the associated eigenstates. Further, we use simple residual control to ensure that the computed solution is a small perturbation of the true landscape function. As the third class of problems, we present the data-based surrogate model of the map connecting a class of potentials to the associated landscape functions. Here we are concerned with the use of convolutional networks as a data-sparse reduced order model in the context of certified surrogate modeling of this mapping. In particular, we are interested in the possibility of updating the surrogate model based on the residual error estimator.
2. Theoretical Background
In order to be precise and explicit, we will present the theoretical foundations on a somewhat restricted set of neural network architectures. The network architectures that will be used in practical computations are presented in
Appendix B. The change of the family of the realizations of neural networks over which the optimization is carried out does not change the presentation of the algorithms in any practical way. Our main contribution is in the introduction of the error control in the Deep Ritz algorithm from [
20]. We will now summarize the basic definitions from [
31], which are necessary to interpret the numerical experiments.
Definition 1. Given , a neural network θ of depth D with the input dimension and the output dimension is the D-tuple where:By the convention and . In the case in which we call the network shallow, and otherwise the network is called deep. The vector is called the network architecture of the neural network θ. We will use
to denote the depth of the given neural network
. In the case in which the structure of matrices
,
is not further restricted, we say that the network is dense. In the case in which a sparsity pattern is assumed we have several subclasses of neural networks. For exemple, if the matrices
,
have a structure of a Toeplitz matrix
—here
,
are parameter vectors defining a Toeplitz matrix [
32]—we talk about convolutional neural networks.
Let be a function that is not a polynomial. By we denote the function . We will now define a realization of the neural network with respect to the function .
Definition 2. A function is defined by the formula:where , is called the realization of the neural network θ with respect to the activation function ρ. Among various activation functions we single out the rectified linear unit (ReLU) function
and the sigmoid function
. The set of all ReLU realizations of a neural network
has a special structure. We call a function
piece-wise linear if there is a finite set of pairwise disjoint, closed polyhedra whose union is
such that a restriction of
f onto a chosen polyhedron is an affine function. It has been shown in [
33] that any piece-wise linear function can be represented by a ReLU neural network and that any ReLU realization of a neural network is piece-wise linear. This observation is key to linking the approximation theory for neural networks with the standard Sobolev space regularity theory for partial differential equations.
Let us now fix some further notation. Let m be the number of the degrees of freedom of the space of piece-wise linear functions associated to the fixed polyhedral tessellation of . We use to denote the set of all piece-wise linear functions on this tessellation. We also use the notations , and to denote the space of piece-wise linear, quadratic and cubic functions, respectively. The corresponding interpolation operators (for continuous arguments) are denoted respectively by , and .
We will now briefly review a-posteriori error estimates that are used in this work. Let us note the following convention. We use
and
to denote the ground state energy and the normalized positive ground state. We use
to denote the energy of a first excited state and we note that the notation is generalized for higher excited states in an obvious way. We denote the Rayleigh quotient of the operator
H for the state
by
. The standard Kato–Temple estimate from [
26] can be written in a dimension-free form, also known as the relative form:
The quantity
is a measure of the so-called relative spectral gap [
34,
35] and it measures the distance to the unwanted part of the spectrum. It can be estimated by symmetry considerations or other a-priori information. In fact, a more careful analysis from [
35] shows that the scaled residual is an asymptotically exact estimate of the relative error and so we will heuristically drop the measure of the gap even in the preasymptotic regime. A consequence of the Davis–Kahan theorem [
36] is that the residual also estimates the eigenvector error:
Subsequently, the error estimator is a good stopping criterion for a certified approximation of an eigenmode.
For the source problem
,
we note the following relationship:
between the residual and the relative
error. Subsequently we use
/
as an error estimator for the source problem.
Algorithms
We will now present the modifications of algorithms that we used to study the localization phenomena. We modified the Deep Ritz algorithm from [
20] with the introduction of the a-posteriori (residual) error estimator. We call our variant the Certified Deep Ritz Algorithm. It is motivated by the work on certified reduced-order modeling in [
29]. In order to be able to formulate strong residuals, we chose smooth activation functions
, so that
can be used to form the strong residual.
The performance of the stochastic gradient descent, when applied to the loss function, can be highly sensitive to the choice of the learning rate. Furthermore, it can also suffer from oscillation effects introduced by the choice of the sampling method in the numerical integration routines. For this reason we have opted to use the Adam optimizer from [
37], which determines the learning rate by adaptively using information from higher-order moments.
To enforce the positivity constraint, we composed a realization of the neural network with the function , . We call the function a positivity mask and it must be chosen appropriately for the governing boundary conditions. As the positivity mask for Schrödinger Hamiltonians we either chose a smooth nonnegative function , which decays to zero as , or set the positivity mask as the identity.
In Algorithm 1 the parameter
is the penalty parameter used to enforce the boundary conditions and the parameter
is used to normalize the eigenmode approximation. We solve the integral using a Gauss quadrature rule in 1D and for higher dimensional problems we use quasi-Monte Carlo integration from [
38,
39] or a sparse grid quadrature [
40] to approximate the integrals in the loss function as well as for the final (more accurate) evaluation of the energy functional. Alternatively in 2D, we sometimes choose to compute the integrals by projecting the realization of a neural network into a finite element space and then use the finite element quadrature to compute the integral. According to the authors of [
11,
41], this is an appropriate approach for problems of moderate dimensions (
,
). For higher-dimensional problems, Monte Carlo integration is the only scalable approach recommended.
| Algorithm 1: Certified Deep Ritz Algorithm. |
![Entropy 23 00095 i001]() |
To apply Algorithm 1 to an eigenvalue problem we choose:
and set the normalization parameter
and
for the loss function:
In the case of the source problem for the computation of the landscape function we set the normalization parameter
and
and define the loss function as:
As the error indicator we take
, where
. Here we have chosen as an example the homogeneous Dirichlet boundary condition
. Other self-adjoint boundary conditions can equally be implemented by penalizing the boundary conditions residual at the boundary
. Note that computing derivatives of realizations of neural networks is efficiently implemented in many programming environments such as TensorFlow [
42].
3. Results
In this section we present direct approximation methods for estimating the ground state , the ground state energy and the landscape function u. We use the Certified Deep Ritz Algorithm presented as Algorithm 1.
3.1. Direct Approximations of the Ground State in 1D
We now present the results of the application of Algorithm 1 on the 1D Schrödinger operator
For the domain
, we choose the loss function (
6) and set
as the positivity mask in Algorithm 1.
To benchmark the accuracy of the VPINN approximations we have solved the problem to high relative accuracy using the Chebyshev spectral method as implemented in the package chebfun [
43,
44]. We emphasize that chebfun was not used during the training of the network in any way. To compute the residuals and the energy of the ground state we used a Gaussian quadrature where the deep network is evaluated at the sufficient number—for the given interval
—of Gaussian points.
We constructed the potential
V as a linear combination of the finite well and two inverted Gaussian bell functions:
We used
to denote the indicator function and chose
,
,
,
,
,
,
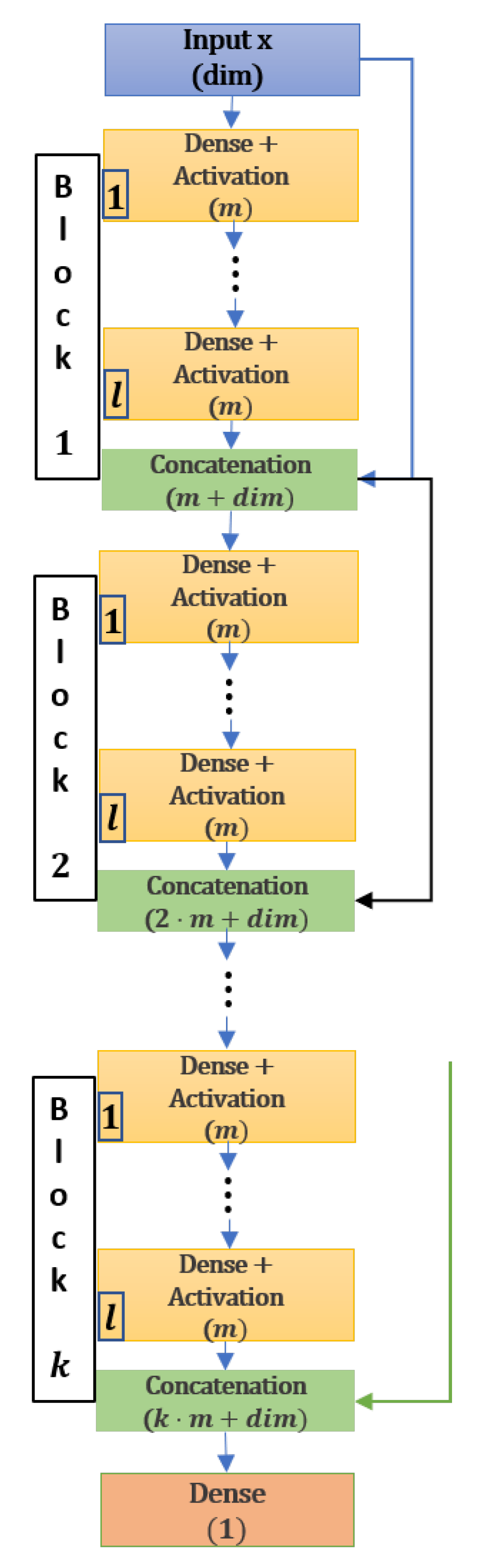
. The neural network has 1162 trainable parameters and we used the DenseNet VPINN architecture
with the activation function
; see
Figure A1.
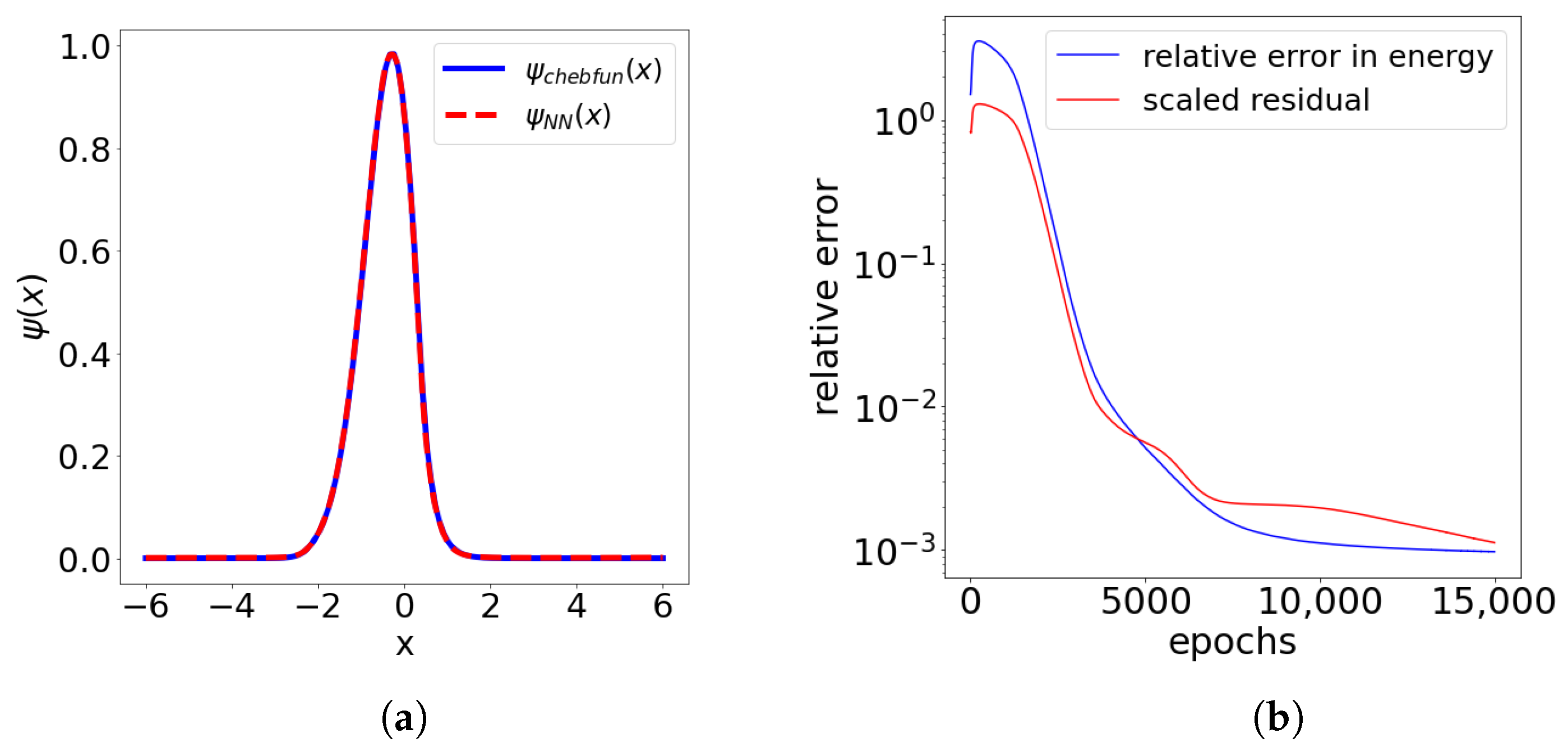
Figure 1 shows the solution and the error estimate during 15,000 epochs of a run of the Adam optimizer with the learning rate
and a batch size of 1024. In this example we used 1024 quadrature points on an interval
and the penalty parameters
and
.
One can observe robust, almost asymptotically exact, performance of the estimator:
Let us also emphasize that
measures the distance of the Rayleigh quotient (energy functional) to the nearest eigenvalue. For evaluation of the integrals in higher dimensions we refer the reader to
Appendix B. Note that the final error for the approximation of the ground state energy was
, whereas the final relative
error in the ground state was
. This is in line with the eigenmode error estimate (
5).
3.2. Direct Approximations of the Ground State in Higher-Dimensional Spaces
We present VPINN approximation results for the ground state and the ground state energy of the Schrödinger equation with harmonic oscillator potential
using the dense network with the architecture depicted in
Figure A1. We study the problem on the truncated domain
, where
n is the dimension of the space. Neural network architecture should be constructed with caution. There are multiple sources of instability when dealing with neural networks, e.g., exploding and vanishing gradients. We experimented with a variety of different activation functions:
,
,
,
etc. After training of the neural network using the quasi-Monte Carlo realization of the energy integrals to define the loss function we computed the approximate ground state energy using the approximation of the energy functional (Rayleigh quotient) using the Sobol sequences with 100,000 points. We also report on the results obtained using Smolyak grids of order 6 with the Gauss–Patterson rule. The results are presented in
Table 1.
The accuracy of the ground state energy approximations that were obtained using quasi-Monte Carlo integration are comparable with the accuracy reported in [
20]. On the other hand, the results obtained by using Smolyak’s points were unsatisfactory in dimensions higher than 3. This observation will be the subject of future research. It appears that the oscillation of the realizations of the neural network on the boundary of the computational domain together with the appearance of negative weights in sparse grid integral formulas contributed to the instability of the approach. We used the
architectures for
and
in 9D and the swish function
as the activation function. The positivity mask was chosen as the identity.
3.3. Approximations of the Landscape Function in 1D
We now present the result of the approximation method using the landscape function as a solution of the partial differential equation
,
. The potential
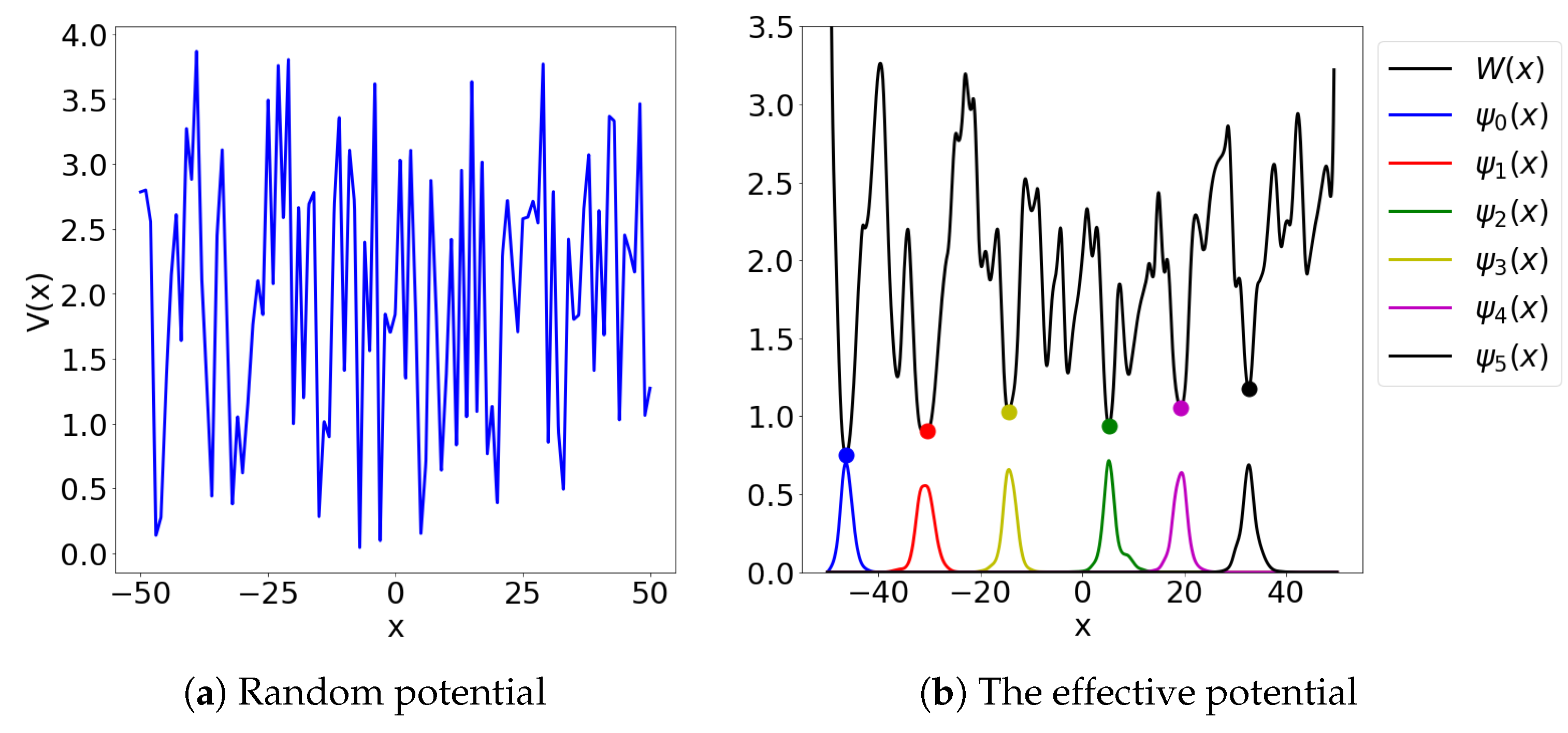
is constructed as a random piece-wise linear function (see
Figure 2). More to the point, let
,
be independently drawn numbers from the uniform distribution on the interval
. We construct the potential
V as the piece-wise linear interpolant of
,
. We again used chebfun for benchmarking. We set
and defined the loss function as:
Here we have used the architecture of the dense VPINN network; see
Appendix C. We used
for the experiments. In
Figure 2 we can see the six local minima of the effective potential
obtained from the neural network and the first six eigenstates computed by the chebfun. Note that the potential
is defined only in the interior of the domain
. In
Table 2 we present the results of the benchmarking of the approximation formula (
2) against highly accurate chebfun eigenvalue approximations.
The neural network has 6402 trainable parameters and we used the VPINN architecture with the activation function . The positvitiy mask was chosen as the identity. The network was trained using 50,000 epochs of the Adam optimizer with the learning rate and a batch size of 2048. In this example we also used 2048 quadrature points on an interval .
3.4. Direct VPINN Approximation of the Landscape Function in 2D
We now apply Algorithm 1 to the problem of approximating the landscape function in 2D. When presenting the examples we will report on the used network architecture as well as indicate the number of trainable parameters for each of the architectures. The activation function used for all neural networks in this subsection is the sigmoid function . We now set and in the next table present a convergence study for the family of architectures .
The convergence histories of relative
and
errors, measured with respect to the benchmark FEniCS solution, are shown in
Table 3. We can observe that the errors drop at a favorable rate with an increase in
k. On the other hand, an increase in
m causes a much more pronounced increase in the number of trainable parameters (complexity of the network) but incurs, in comparison, only a moderate improvement of the accuracy level.
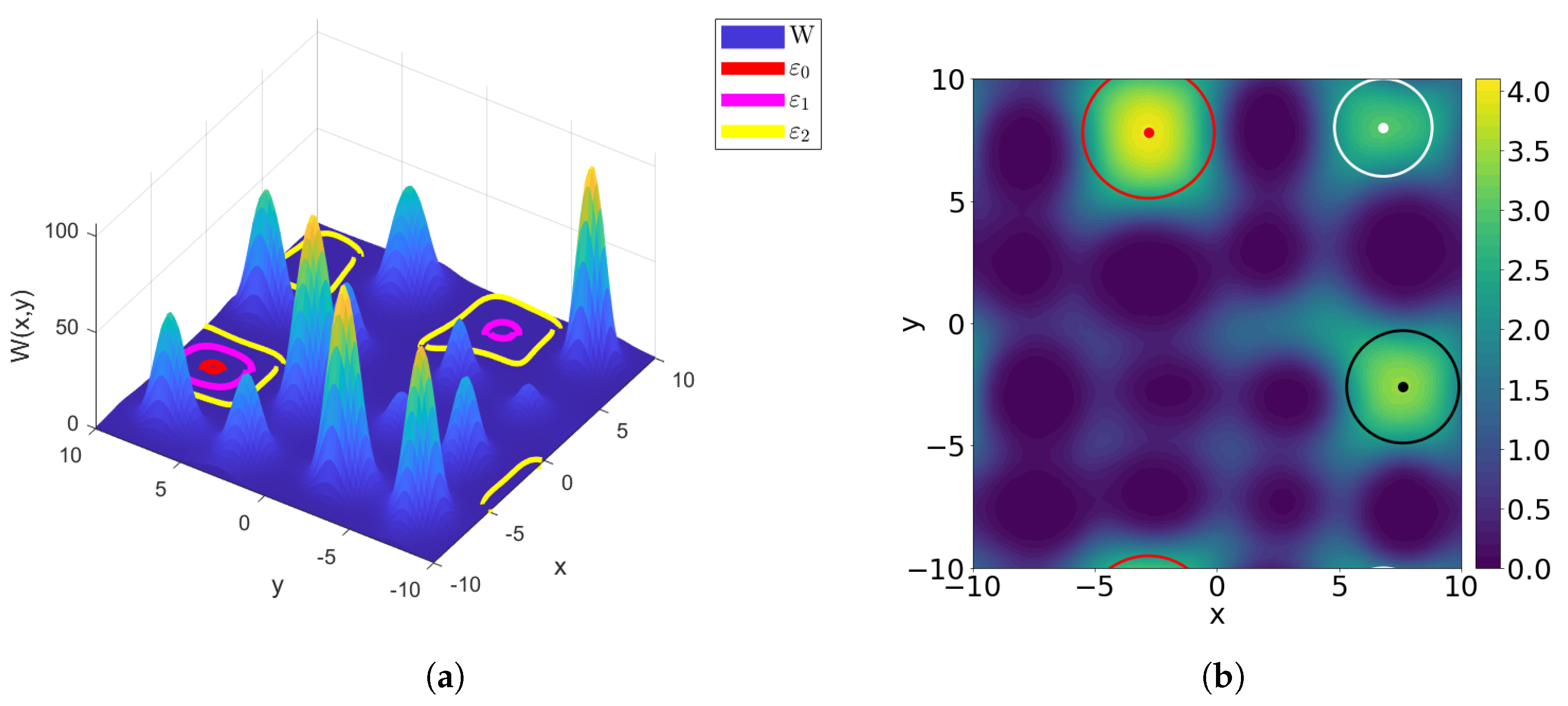
In
Figure 3 we plot the effective potential
W and the landscape function
u.
3.5. Encoder–Decoder Network as a Reduced-Order Model for a Family of Landscape Functions
We now study the use of the sparse, U-Net-inspired [
30], network architecture as a surrogate model for the function
. In
Figure 3 we show the landscape function
u with periodic boundary conditions for the potential
constructed as a lattice superposition of sixteen Gaussian bell functions
. The centers
were chosen randomly inside each block of the
uniform quadrilateral tessellation of
. The constants
were chosen randomly and independently from intervals
and
, respectively. To introduce local defects in the lattice, we have further randomly chosen three Gaussian bells and removed them from the potential. The choice of Gaussian bells to be removed was restricted, so that the boundary conditions were respected and that none of the erased bells were pairwise adjacent.
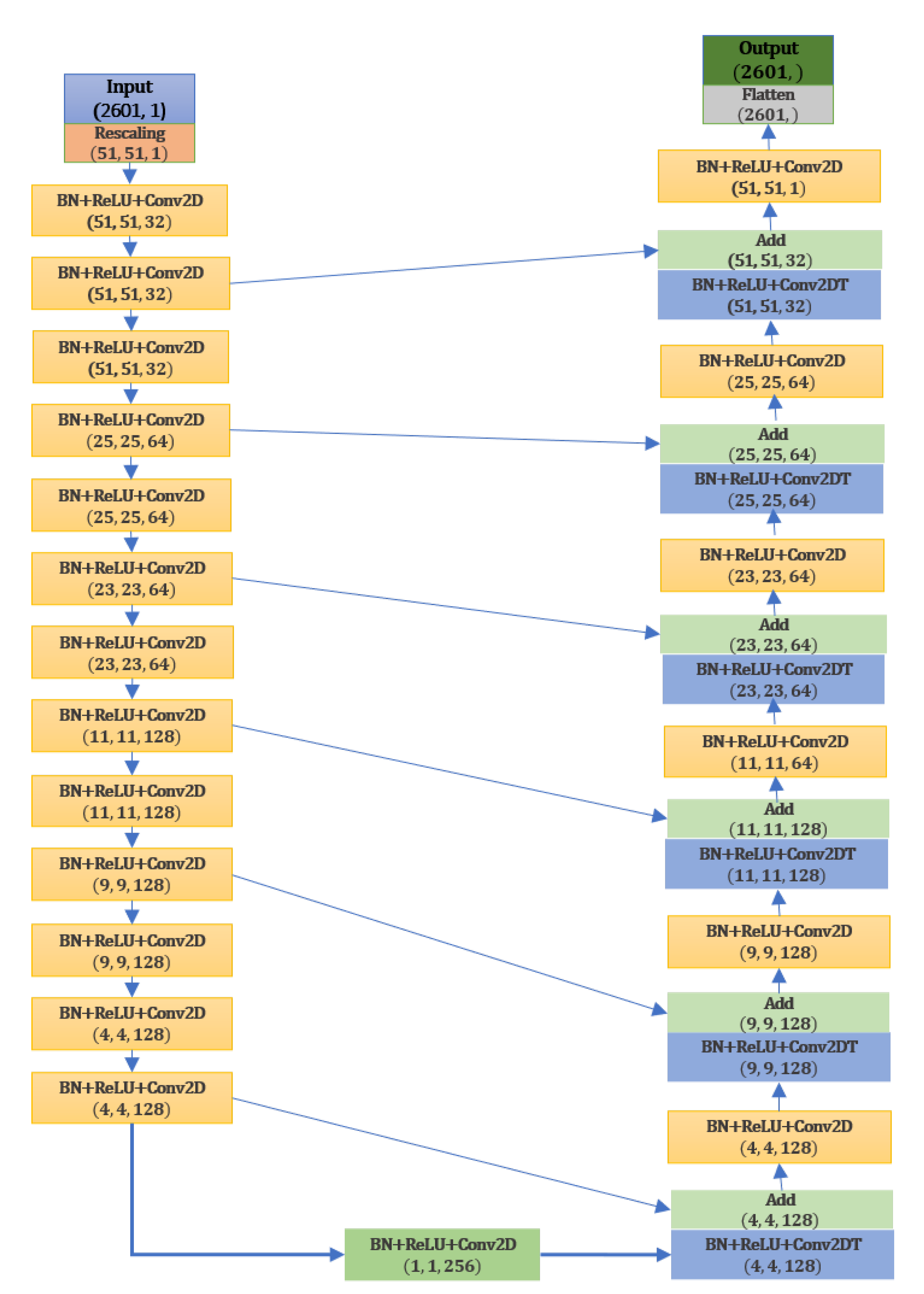
As the reduced order model for this family of problems, we have used the encoder–decoder fully convolutional neural network (FCNN) from
Appendix C with 2,614,531 trainable parameters. This is a relatively small number of parameters in comparison with the typical convolutional neural network architectures with fully connected layers. The architecture of the neural network is shown in
Figure A2.
To train the model we generated 98,400 potentials and then used FEniCS to compute the associated landscape functions , . The domain of the Hamiltonaian was , with the periodic boundary conditions. We used the uniform quadrilateral discretization with the step size and elements to compute the training examples. To construct the reduced-order model, we projected (by interpolation) these functions onto the space of elements for the same mesh. After implementing the periodic boundary conditions we obtained exactly 2500 free nodes for this space of functions.
We denote the values of the potential
V in those nodes as the vector
and we tacitly identify the vector
with the function
. Let
be the extension operator from
to the space of continuous piece-wise linear functions. Then
defines the mapping
. We used the learning rate
for the first 100 epochs of the Adam optimizer and the learning rate
for a further 50 epochs. The activation function
was used to promote sparsity and the MSE loss function was used for the training. The batch size for the Adam algorithm was 1024. We implemented the certified surrogate modeling approach by combining the evaluation of the neural network with the error estimator
. In the case in which the residual measure
for the function
is larger than the preset tolerance, we updated the surrogate model (neural network). To this end we solved in FEniCS the problem
and used the standard update algorithm for the convolutional neural network and the new training example.
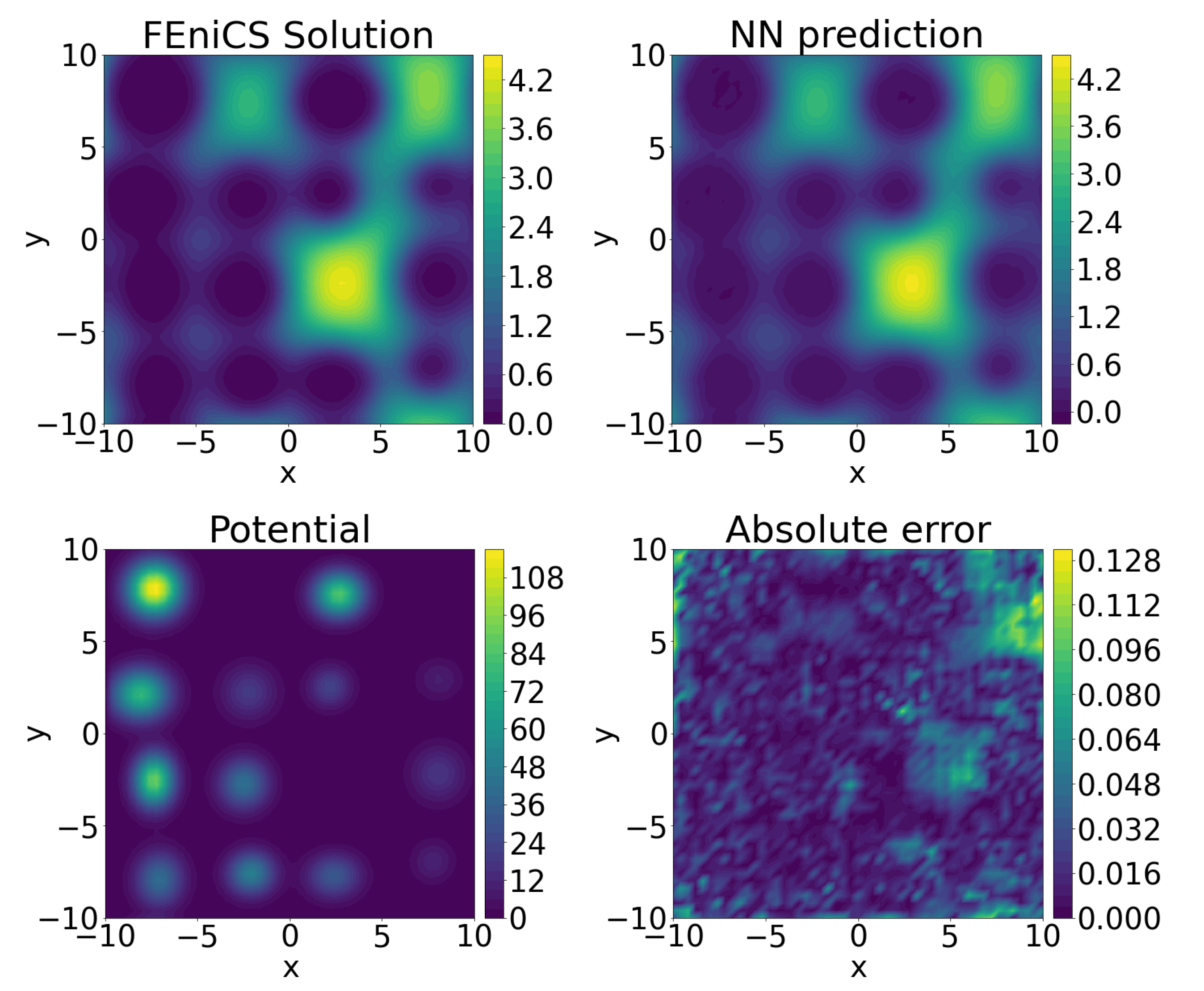
We evaluated the performance of the neural network reduced-order model on a set of 200 testing potentials that were not used in the training of the network, see
Table 4. The benchmarking comparison against the FEniCS solution is presented in
Figure 4.
4. Discussion
According to the authors of [
45], deep learning approaches to dealing with partial differential equations fall into the following three categories: (a) Rayleigh–Ritz approximations, (b) Galerkin approximations and (c) least squares approximations. We have considered a hybrid approach that combines robust stochastic optimization of overparametrized networks based on the Rayleigh–Ritz approach with standard residual based error estimates, which together yield a hybrid approximation method. We were particularly influenced by the review in [
45] and the Deep Ritz algorithm as described in [
20].
In the example from
Table 3 we further computed a piece-wise cubic and piece-wise quadratic approximation of the landscape function using the standard finite element method and an approximation of the landscape function using a variant of the Deep Ritz method. We measured the error of the
and the VPINN approximation against the
benchmark solution. The relative
error of the piece-wise quadratic approximation was computed to be
, whereas the relative error of the VPINN approximation with 1203 free parameters was computed to be
. Note, however, that the piece-wise quadratic approximation required the training of 10,000 parameters. This indicates that the neural network achieves a considerable data compression when compared with a piece-wise polynomial approximation. The situation is even more interesting in 1D. There we compared the ground state approximation by the Chebyshev series, as implemented in chebfun. We needed 149 terms in the Chebyshev expansion to reach the order of machine precision. On the other hand, the Adam optimizer was able to find a realization of the dense neural network with VPINN architecture
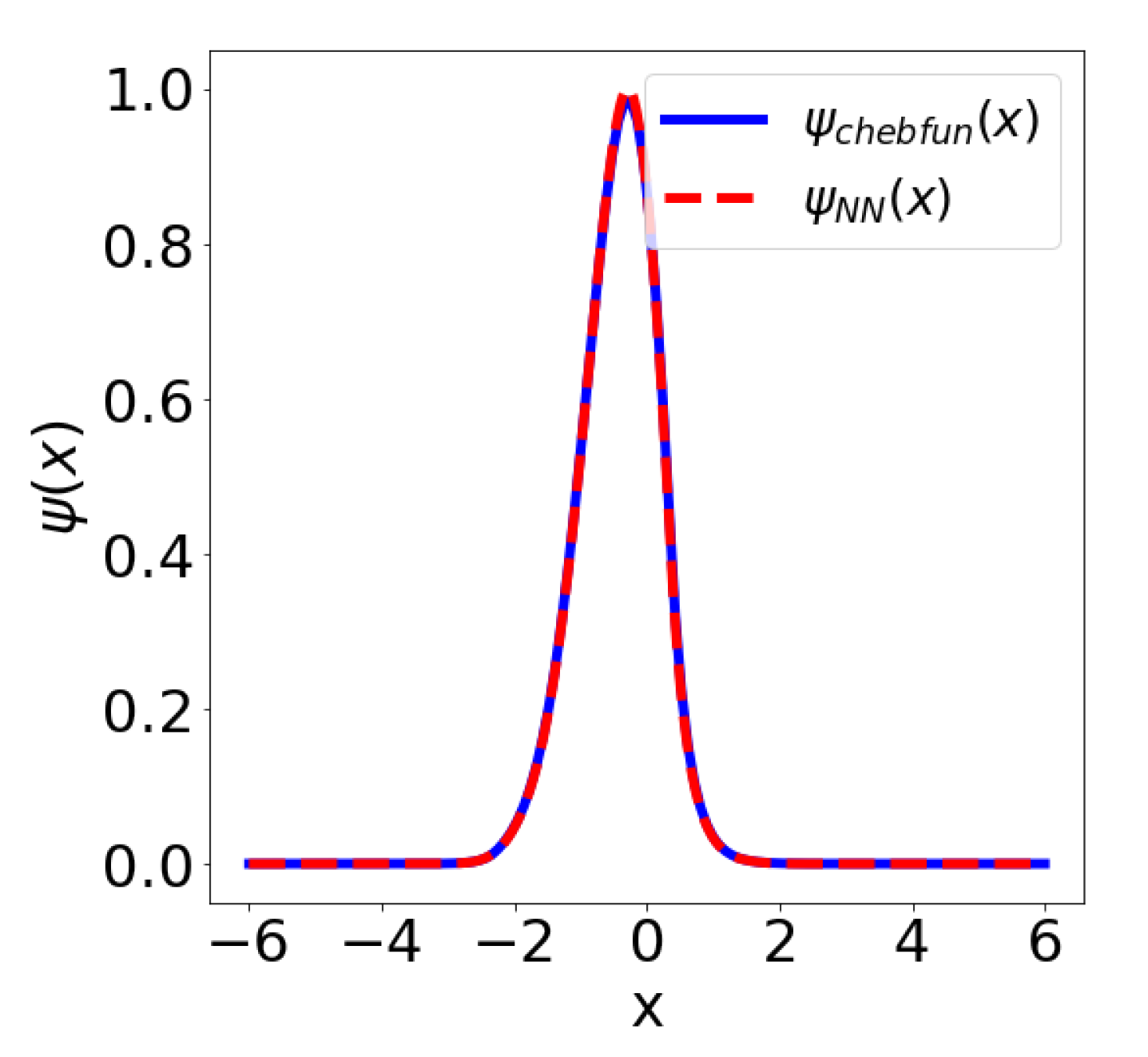
from
Appendix A. This architecture only has 30 trainable parameters and it achieves a relative distance (in the
sense) of
to the benchmark chebfun solution. The relative error in the ground state energy is only
, see
Figure 5.
The integrals needed to approximate the energy functional were computed using Gaussian quadrature rules. Unfortunately, this approach does not yield stable methods in higher-dimensional problems. The reason is in the fact that sparse grid quadratures (e.g., [
40]) also have nodes with negative weights and this was observed to cause severe numerical instability. An approach based on the quasi-Monte Carlo integration, which utilizes low-discrepancy sequences of integration nodes and has only positive weights (see [
39]) yielded an efficient and stable method in higher-dimensional situations. Furthermore, since realizations of neural networks are frequently functions with many local extrema, computing their integrals needs to be handled with care. This is particularly relevant when enforcing discretizations of physical or normalization constraints by penalization. We point out that the scalability of sparse-grid integration schemes in this respect was not satisfactory.
Another promising technique for obtaining data-sparse compressed approximation of the solutions of partial differential equations is based on the concept of tensor networks, also known as matrix product states or tensor train decompositions [
9]. This approach has been successfully converted into numerical approximation algorithms such as the quantized tensor train decompositions [
8,
46]. The scaling robust performance of this approach has been demonstrated on a class of multi-scale model problems in [
46]. However, the numerical methods still have to be tailor-made for the chosen problems. On the other hand, there are many freely available robust and highly developed libraries for working with deep neural networks. This is the reason for our choice of the discretization method.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}