
Information Entropy in Chemistry: An Overview



Abstract
:1. Introduction
- (a)
- the peculiarities of the calculations of information entropies of isolated molecules, molecular ensembles, and solids;
- (b)
- the relation of information entropies to chemical and physicochemical processes;
- (c)
- the relation of information entropy to the digital recognition of chemical structures.
2. Basic Definitions
3. Information Entropy for Describing Chemical Structures
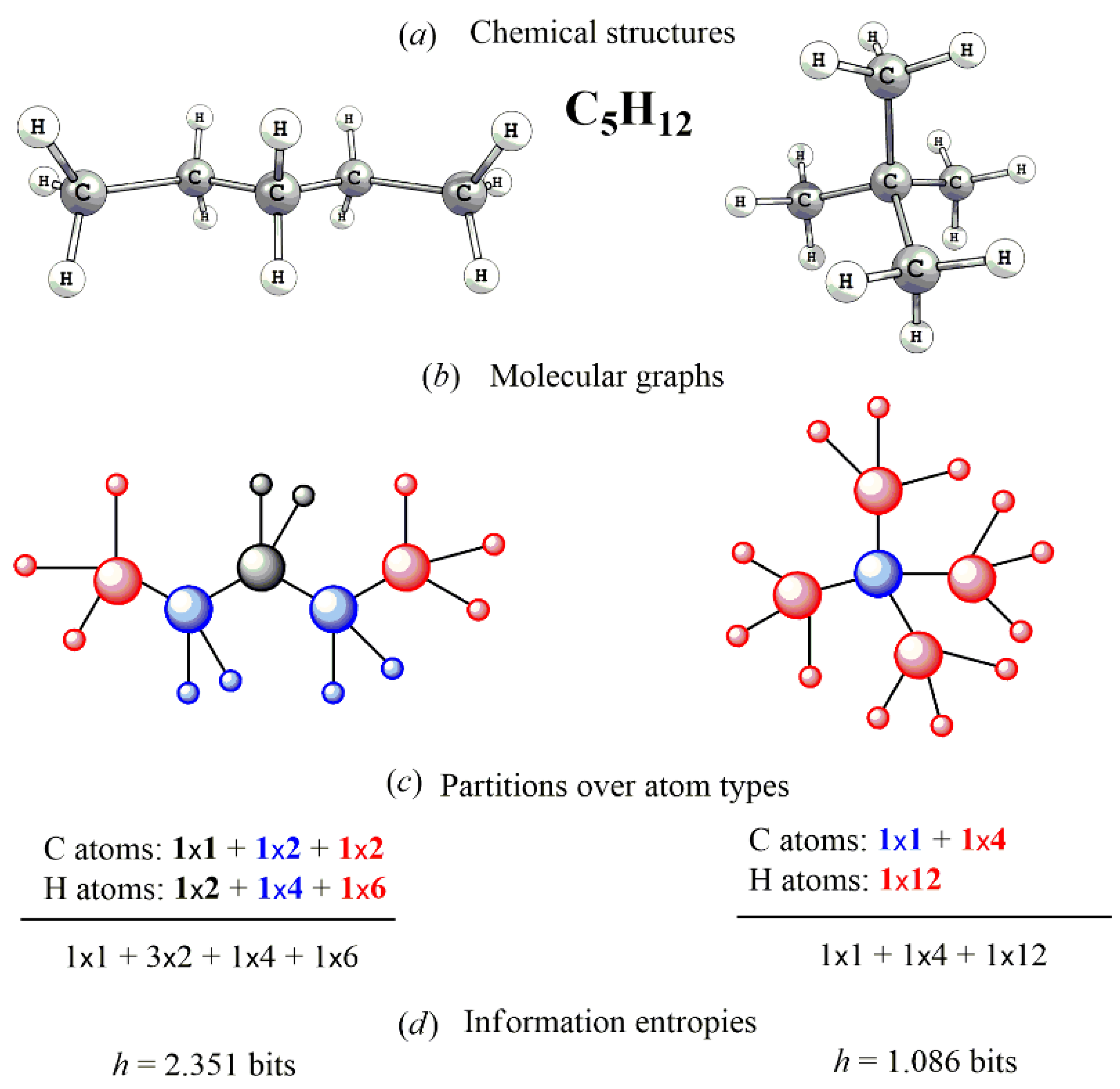
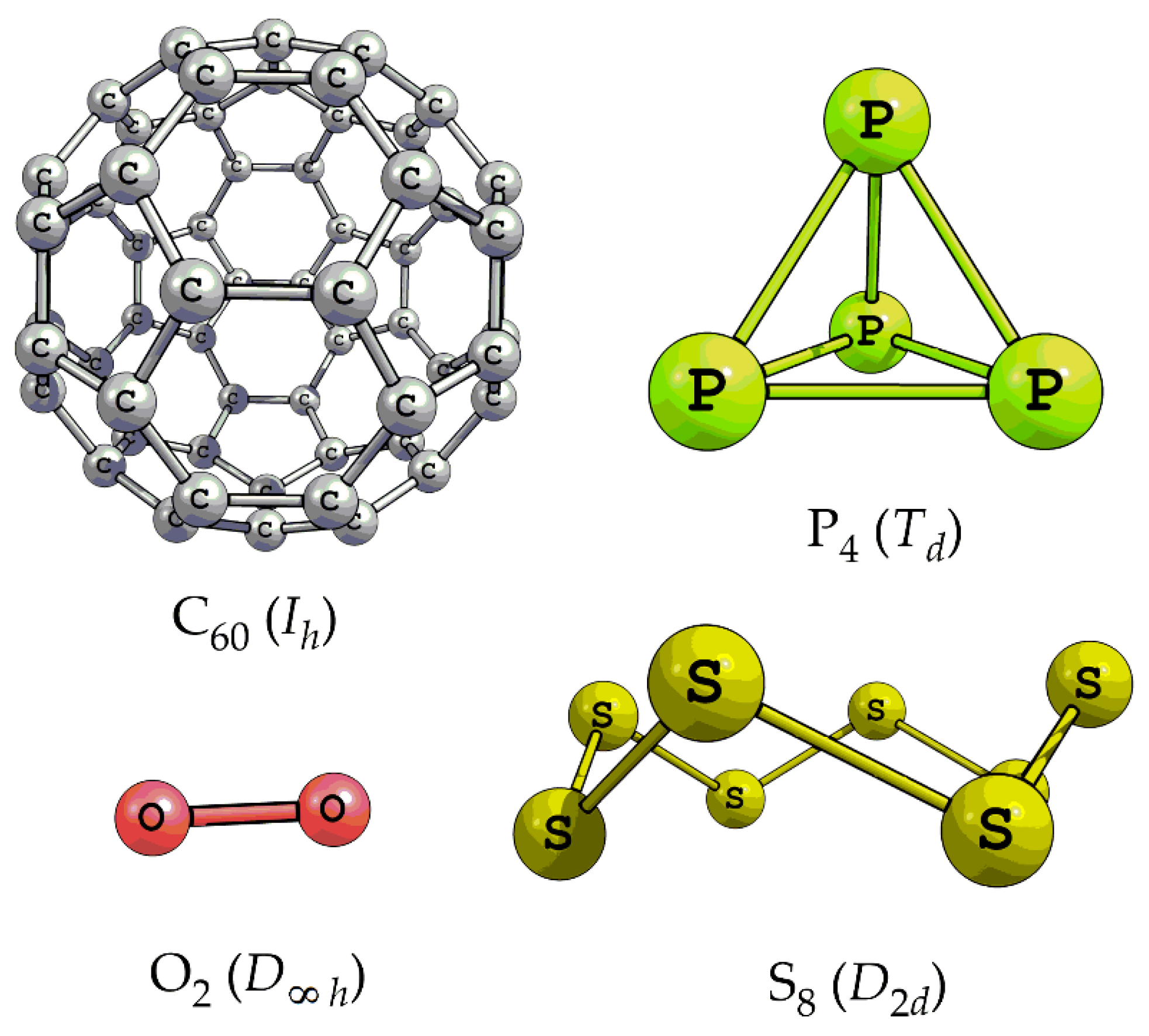
3.1. Discrete Information Entropy Approach: Quantifying Molecules as a Set
3.2. Continual Information Entropy Approach: Quantifying Electronic Density of Atoms and Molecules
3.3. Chemical Applications of Information Entropy Relating to Signal Processing
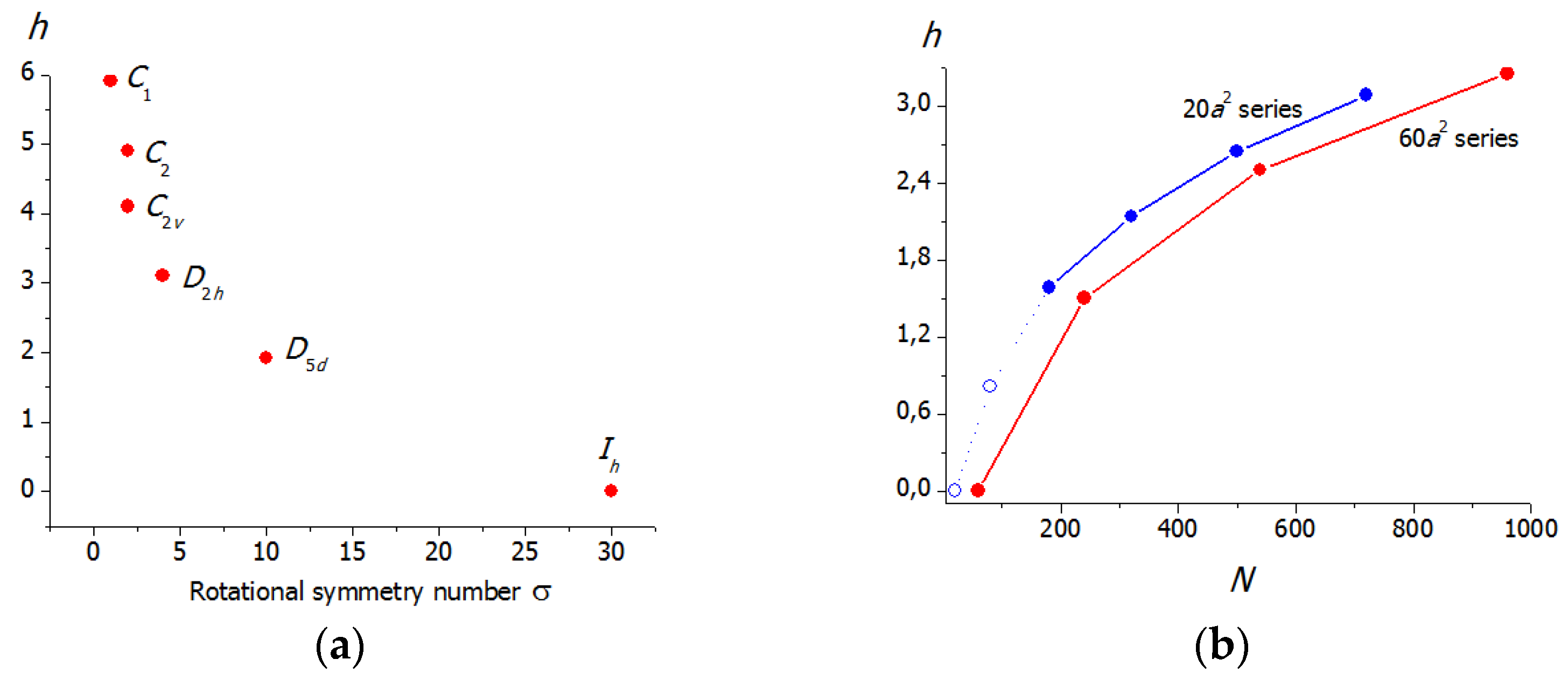
4. Information Entropy of Complex Chemical Objects
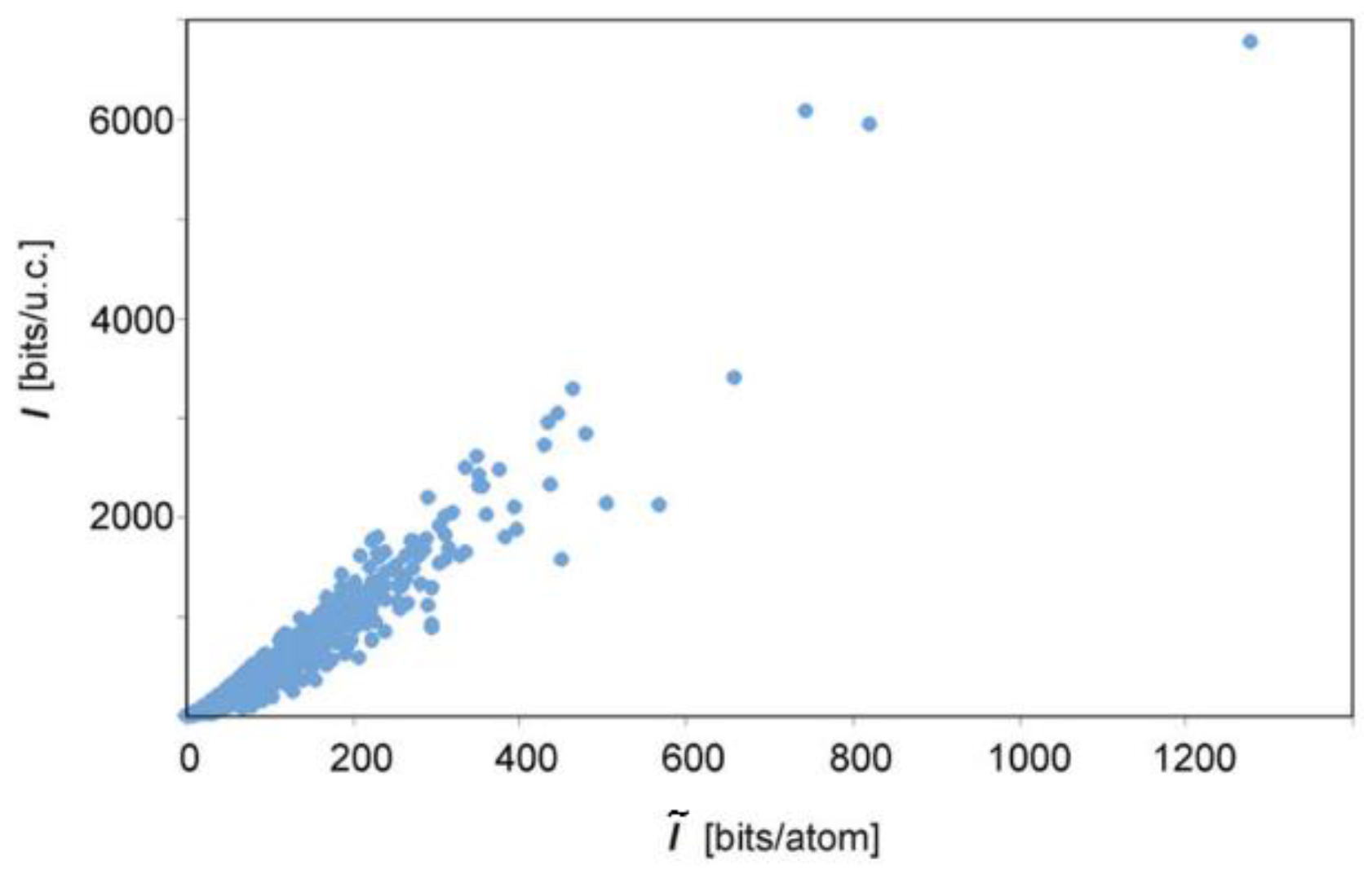
4.1. Information Entropy of Solids
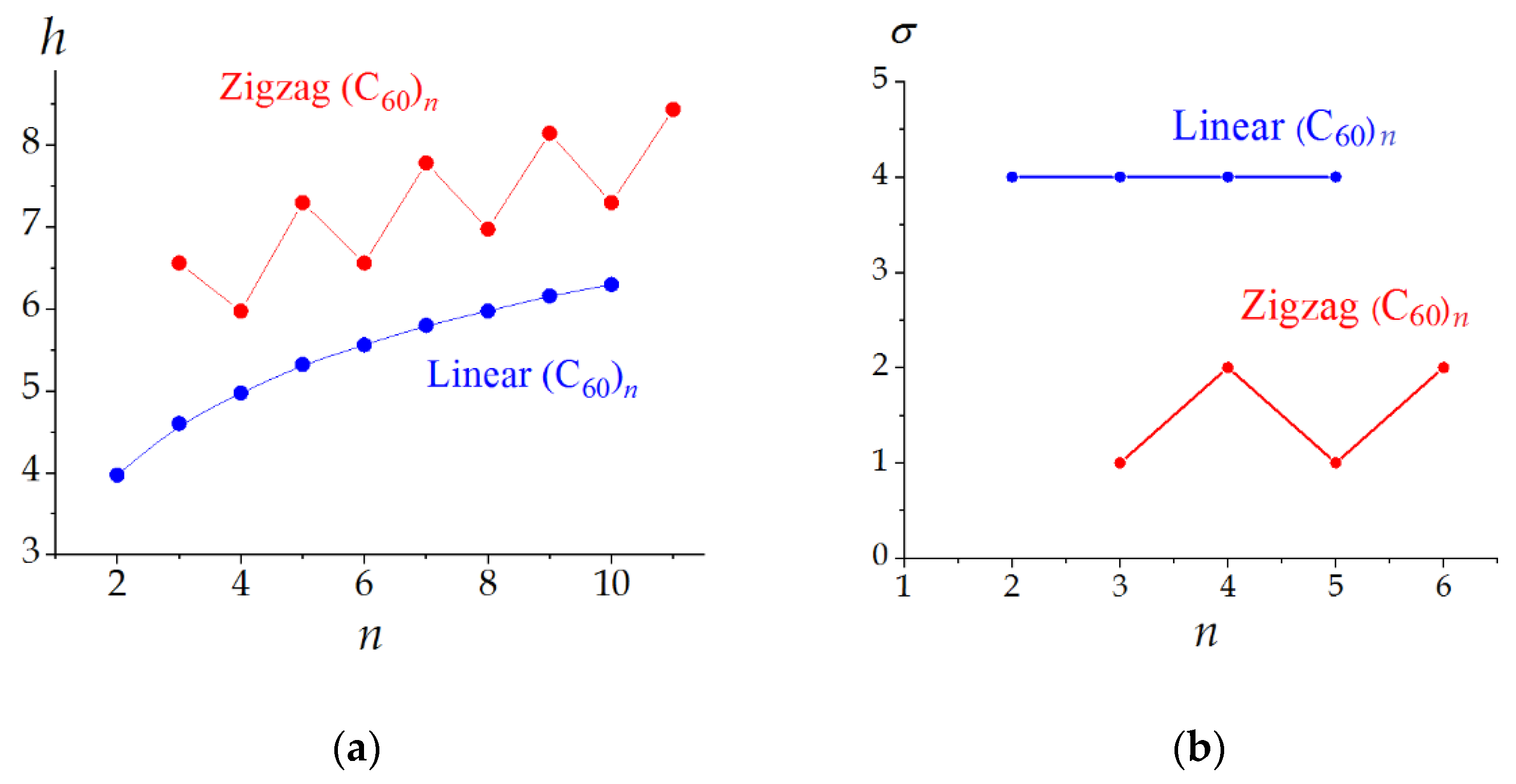
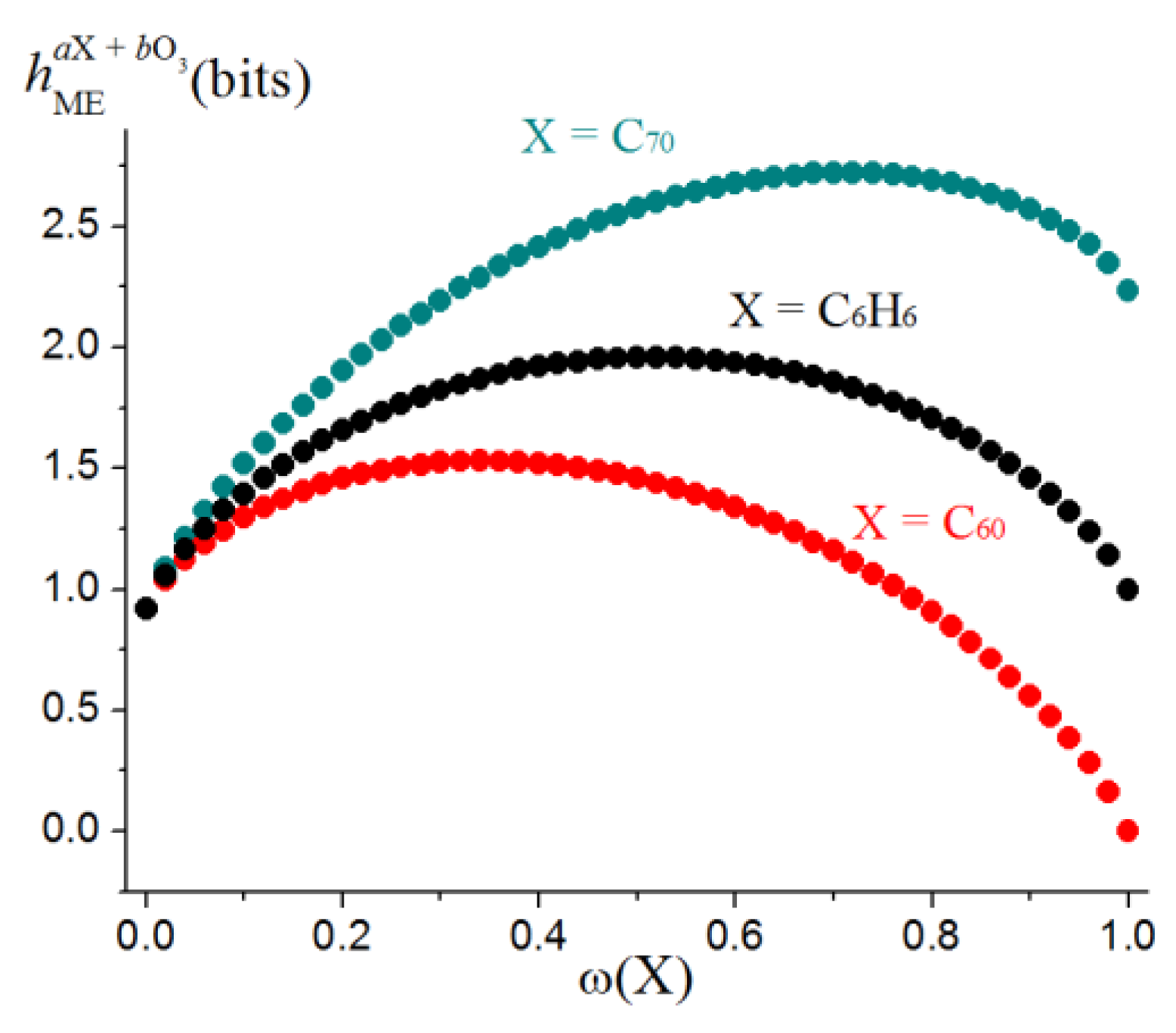
4.2. Information Entropy of Molecular Ensembles
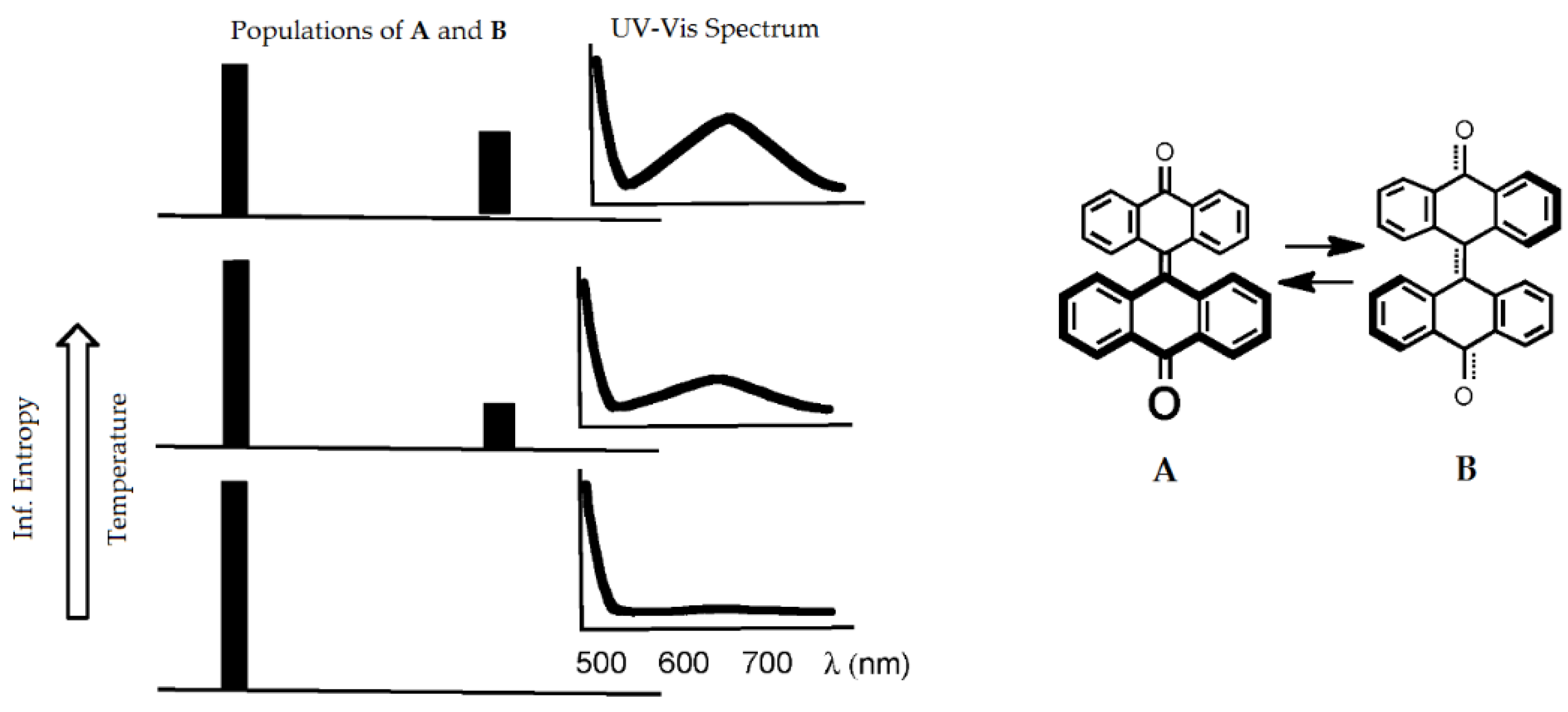
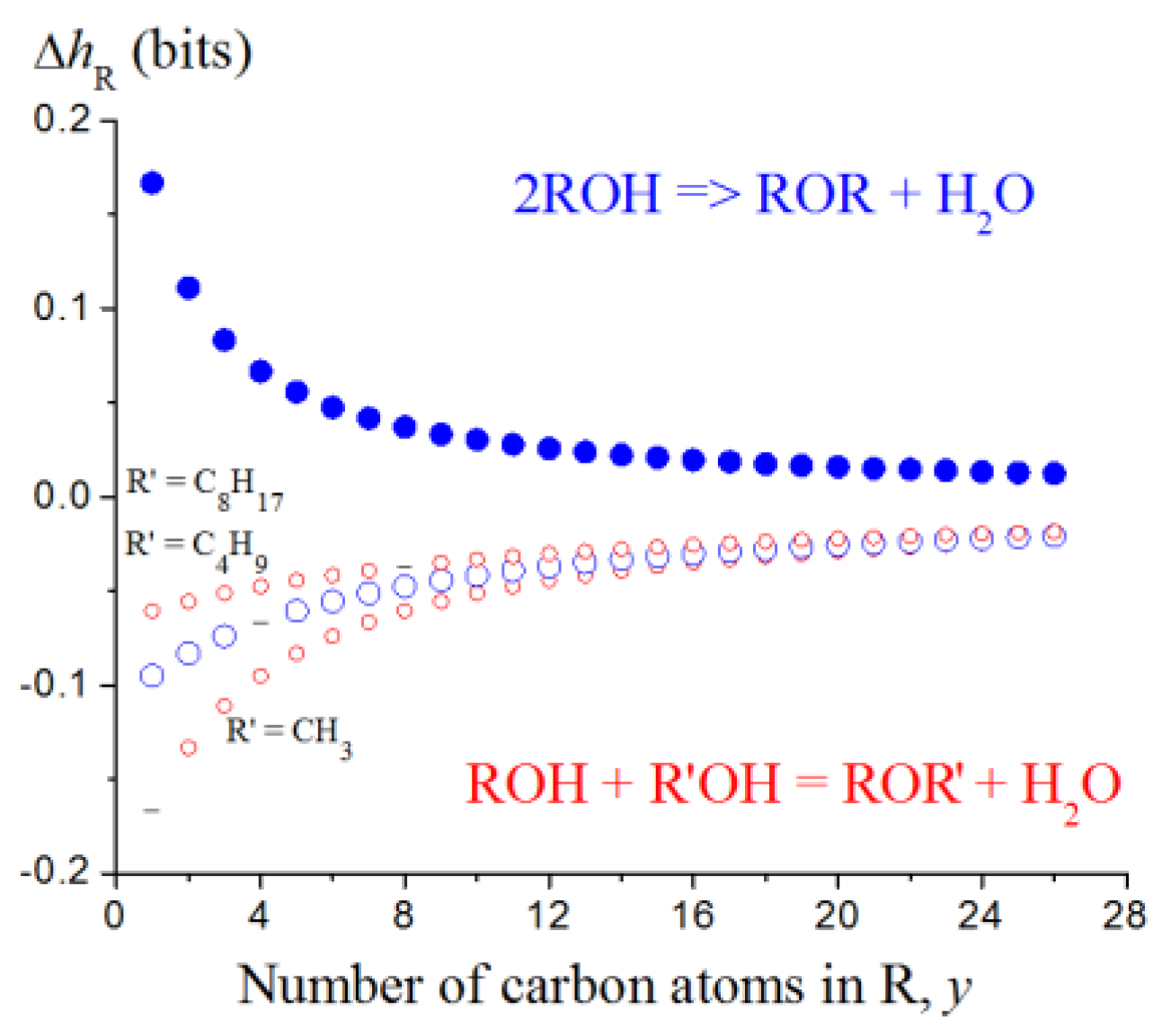
5. Information Entropy of Chemical Reactions
6. Discrete Information Entropy Approach and Some Aspects of Physical and Digital Chemistry
6.1. Everlasting Comparison of Information and Thermodynamic Entropies
6.2. Information Entropy and Physicochemical Processes
6.3. Information Entropy and Digital Chemistry
7. Applying Information Entropy to Nucleic Acids
8. Conclusions
- in terms of novel theories of semantic information;
- using information entropy in combination with other structural properties (molecular size, oxidation state, etc.);
- limiting the considered semantic field (for example, applying information entropy only to the limited isomeric or homologue series, reactions of one type, etc.).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Hartley, R.V.L. Transmission of Information. Bell Syst. Tech. J. 1928, 7, 535–563. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Haken, H. Information and Self-Organization: A Macroscopic Approach to Complex Systems; Springer: New York, NY, USA, 1989. [Google Scholar]
- Jimenez-Angeles, F.; Odriozola, G.; Lozada-Cassou, M. Entropy effects in self-assembling mechanisms: Also a view from the information theory. J. Mol. Liq. 2011, 164, 87–100. [Google Scholar] [CrossRef]
- Stankevich, I.M.; Stankevich, I.V.; Zefirov, N.S. Topological indices in organic chemistry. Russ. Chem. Rev. 1988, 57, 191–208. [Google Scholar] [CrossRef]
- Bonchev, D. Kolmogorov’s information, Shannon’s entropy, and topological complexity of molecules. Bulgar. Chem. Commun. 1995, 28, 567–582. [Google Scholar]
- Dehmer, M.; Mowshowitz, A. A history of graph entropy measures. Inf. Sci. 2011, 181, 57–78. [Google Scholar] [CrossRef]
- Barigye, S.J.; Marrero-Ponce, Y.; Pérez-Giménez, F.; Bonchev, D. Trends in information theory-based chemical structure codification. Mol. Divers. 2014, 18, 673–686. [Google Scholar] [CrossRef]
- Ghorbani, M.; Dehmer, M.; Emmert-Streib, F. Properties of entropy-based topological measures of fullerenes. Mathematics 2020, 8, 740. [Google Scholar] [CrossRef]
- Nalewajski, R.F.; Parr, R.G. Information theory, atoms in molecules, and molecular similarity. Proc. Natl. Acad. Sci. USA 2000, 97, 8879–8882. [Google Scholar] [CrossRef] [Green Version]
- Nalewajski, R.F. Understanding electronic structure and chemical reactivity: Quantum-information perspective. Appl. Sci. 2019, 9, 1262. [Google Scholar] [CrossRef] [Green Version]
- Mohajeri, A.; Alipour, M. Shannon information entropy of fractional occupation probability as an electron correlation measure in atoms and molecules. Chem. Phys. 2009, 360, 132–136. [Google Scholar] [CrossRef]
- Matroudi, A.; Noorizadeh, S. N-Derivatives of Shannon entropy density as response functions. Phys. Chem. Chem. Phys. 2020, 22, 21535–21542. [Google Scholar] [CrossRef] [PubMed]
- García-Garibay, M.A. The entropic enlightenment of organic photochemistry: Strategic modifications of intrinsic decay pathways using an information-based approach. Photochem. Photobiol. Sci. 2010, 9, 1574–1588. [Google Scholar] [CrossRef]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar] [CrossRef] [Green Version]
- Jumarie, P.G. A critical review of shannon information theory. In Springer Series in Synergetics; Springer: New York, NY, USA, 1990; pp. 44–65. [Google Scholar] [CrossRef]
- Kolchinsky, A.; Wolpert, D.H. Semantic information, autonomous agency and non-equilibrium statistical physics. Interface Focus 2018, 8, 20180041. [Google Scholar] [CrossRef]
- Bennett, C.H. Notes on Landauer’s principle, reversible computation, and Maxwell’s Demon. Stud. Hist. Philos. Sci. Part B 2003, 34, 501–510. [Google Scholar] [CrossRef] [Green Version]
- Bérut, A.; Arakelyan, A.; Petrosyan, A.; Ciliberto, S.; Dillenschneider, R.; Lutz, E. Experimental verification of Landauer’s principle linking information and thermodynamics. Nature 2012, 483, 187–189. [Google Scholar] [CrossRef] [PubMed]
- Toyabe, S.; Sagawa, T.; Ueda, M.; Muneyuki, E.; Sano, M. Experimental demonstration of information-to-energy conversion and validation of the generalized Jarzynski equality. Nat. Phys. 2010, 6, 988–992. [Google Scholar] [CrossRef] [Green Version]
- Aydin, A.; Sisman, A.; Kosloff, R. Landauer’s principle in a quantum szilard engine without Maxwell’s Demon. Entropy 2020, 22, 294. [Google Scholar] [CrossRef] [Green Version]
- Koski, J.V.; Maisi, V.; Pekola, J.P.; Averin, D.V. Experimental realization of a Szilard engine with a single electron. Proc. Natl. Acad. Sci. USA 2014, 111, 13786–13789. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amigó, J.M.; Balogh, S.G.; Hernández, S. A brief review of generalized entropies. Entropy 2018, 20, 813. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dehmer, M.; Mowshowitz, A. Generalized graph entropies. Complexity 2011, 17, 45–50. [Google Scholar] [CrossRef]
- Bachelard, G. The New Scientific Spirit; Beacon Press: Boston, MA, USA, 1985. [Google Scholar]
- Kerber, A.; Laue, R.; Meringer, M.; Rücker, C. Molecules in Silico: The generation of structural formulae and its applications. J. Comput. Chem. Jpn. 2004, 3, 85–96. [Google Scholar] [CrossRef]
- Thakkar, A. A hierarchy for additive models of polarizability. AIP 2012, 1504, 586–589. [Google Scholar] [CrossRef]
- Clark, T.; Hicks, M.G. Models of necessity. Beilstein J. Org. Chem. 2020, 16, 1649. [Google Scholar] [CrossRef]
- Hoffmann, R.; Laszlo, P. Representation in chemistry. Angew. Chem. 1991, 30, 1–16. [Google Scholar] [CrossRef]
- Titov, I.Y.; Stroylov, V.S.; Rusina, P.; Svitanko, I.V. Preliminary modelling as the first stage of targeted organic synthesis. Russ. Chem. Rev. 2021, 90, 831–867. [Google Scholar] [CrossRef]
- Sokolov, I.V. Topological ideas in stereochemistry. Russ. Chem. Rev. 1973, 42, 452–463. [Google Scholar] [CrossRef]
- Mowshowitz, A.; Dehmer, M. Entropy and the complexity of graphs revisited. Entropy 2012, 14, 559–570. [Google Scholar] [CrossRef]
- Minkin, V.I. Current trends in the development of A. M. Butlerov’s theory of chemical structure. Russ. Chem. Bull. 2012, 61, 1265–1290. [Google Scholar] [CrossRef]
- Zubarev, D.Y.; Boldyrev, A.I. Developing paradigms of chemical bonding: Adaptive natural density partitioning. Phys. Chem. Chem. Phys. 2008, 10, 5207–5217. [Google Scholar] [CrossRef] [PubMed]
- Minkin, I.V.; Minyaev, R.M.; Hoffmann, R. Non-classical structures of organic compounds: Unusual stereochemistry and hypercoordination. Russ. Chem. Rev. 2002, 71, 869–892. [Google Scholar] [CrossRef] [Green Version]
- Boldyrev, A.I.; Wang, L.-S. Beyond classical stoichiometry: Experiment and theory. J. Phys. Chem. A 2001, 105, 10759–10775. [Google Scholar] [CrossRef]
- Bader, R.W.F. Atoms in Molecules. A Quantum Theory; Oxford University Press: Oxford, UK, 1994; pp. 1–458. [Google Scholar]
- Vashchenko, A.V.; Borodina, T.N. H-H interaction in phenanthrene: Attraction or repulsion? J. Struct. Chem. 2013, 54, 479–483. [Google Scholar] [CrossRef]
- Sabirov, D. A correlation between the mean polarizability of the “kinked” polycyclic aromatic hydrocarbons and the number of H-H bond critical points predicted by Atoms-in-Molecules theory. Comput. Theor. Chem. 2014, 1030, 81–86. [Google Scholar] [CrossRef]
- Bonchev, D.; Kamenski, D.; Kamenska, V. Symmetry and information content of chemical structures. Bull. Math. Biol. 1976, 38, 119–133. [Google Scholar] [CrossRef]
- Bonchev, D.; Trinajstić, N. Chemical information theory: Structural aspects. Int. J. Quantum Chem. 1982, 22, 463–480. [Google Scholar] [CrossRef]
- Basak, S.; Harriss, D.; Magnuson, V. Comparative study of lipophilicity versus topological molecular descriptors in biological correlations. J. Pharm. Sci. 1984, 73, 429–437. [Google Scholar] [CrossRef]
- Basak, S.C.; Gute, B.D.; Grunwald, G.D. Use of topostructural, topochemical, and geometric parameters in the prediction of vapor pressure: A hierarchical QSAR approach. J. Chem. Inf. Comput. Sci. 1997, 37, 651–655. [Google Scholar] [CrossRef]
- Sabirov, D.S.; Osawa, E. Information entropy of fullerenes. J. Chem. Inf. Model. 2015, 55, 1576–1584. [Google Scholar] [CrossRef]
- Sabirov, D.; Shepelevich, I. Information entropy of oxygen allotropes. A still open discussion about the closed form of ozone. Comput. Theor. Chem. 2015, 1073, 61–66. [Google Scholar] [CrossRef]
- Sabirov, D. Information entropy changes in chemical reactions. Comput. Theor. Chem. 2018, 1123, 169–179. [Google Scholar] [CrossRef]
- Sabirov, D.S. Information entropy of mixing molecules and its application to molecular ensembles and chemical reactions. Comput. Theor. Chem. 2020, 1187, 112933. [Google Scholar] [CrossRef]
- Sabirov, D.S. Information entropy change in [2 + 2]-oligomerization of the C60 fullerene. Int. J. Chem. Model. 2017, 9, 203–213. [Google Scholar]
- Sabirov, D.S.; Ori, O.; Tukhbatllina, A.A.; Shepelevich, I.S. Covalently bonded fullerene nano-aggregates (C60)n: Digitalizing their energy–topology–symmetry. Symmetry 2021. submitted. [Google Scholar]
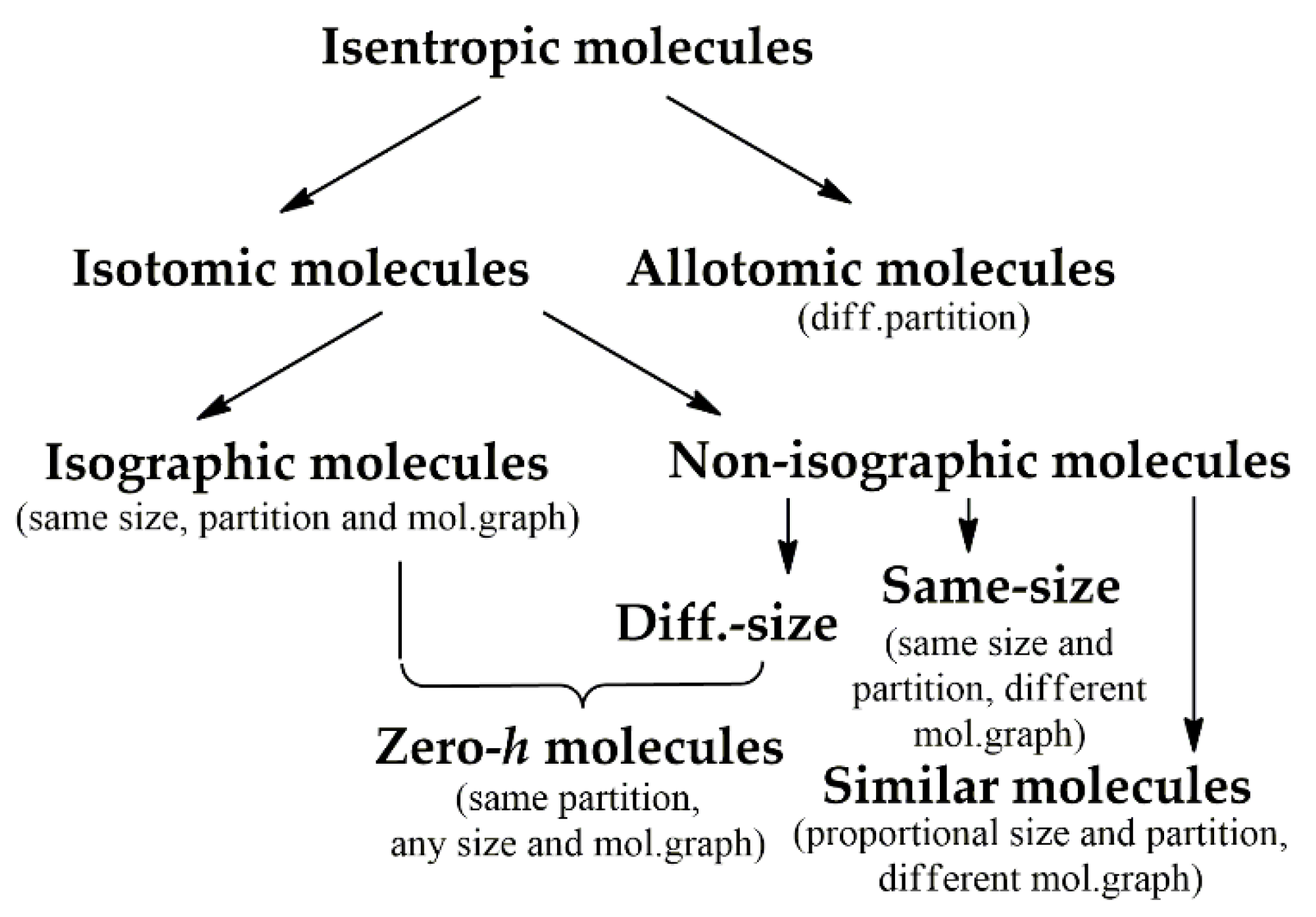
- Sabirov, D.; Koledina, K. Classification of isentropic molecules in terms of Shannon entropy. EPJ Web 2020, 244, 01016. [Google Scholar] [CrossRef]
- Sabirov, D.S.; Sokolov, V.I.; Terentyev, O.A. Activation energies and information entropies of helium penetration through the fullerene walls. Insights into the formation of endofullerenes nX@C60/70 (n = 1 and 2) from the information entropy approach. RSC Adv. 2016, 6, 72230–72237. [Google Scholar] [CrossRef] [Green Version]
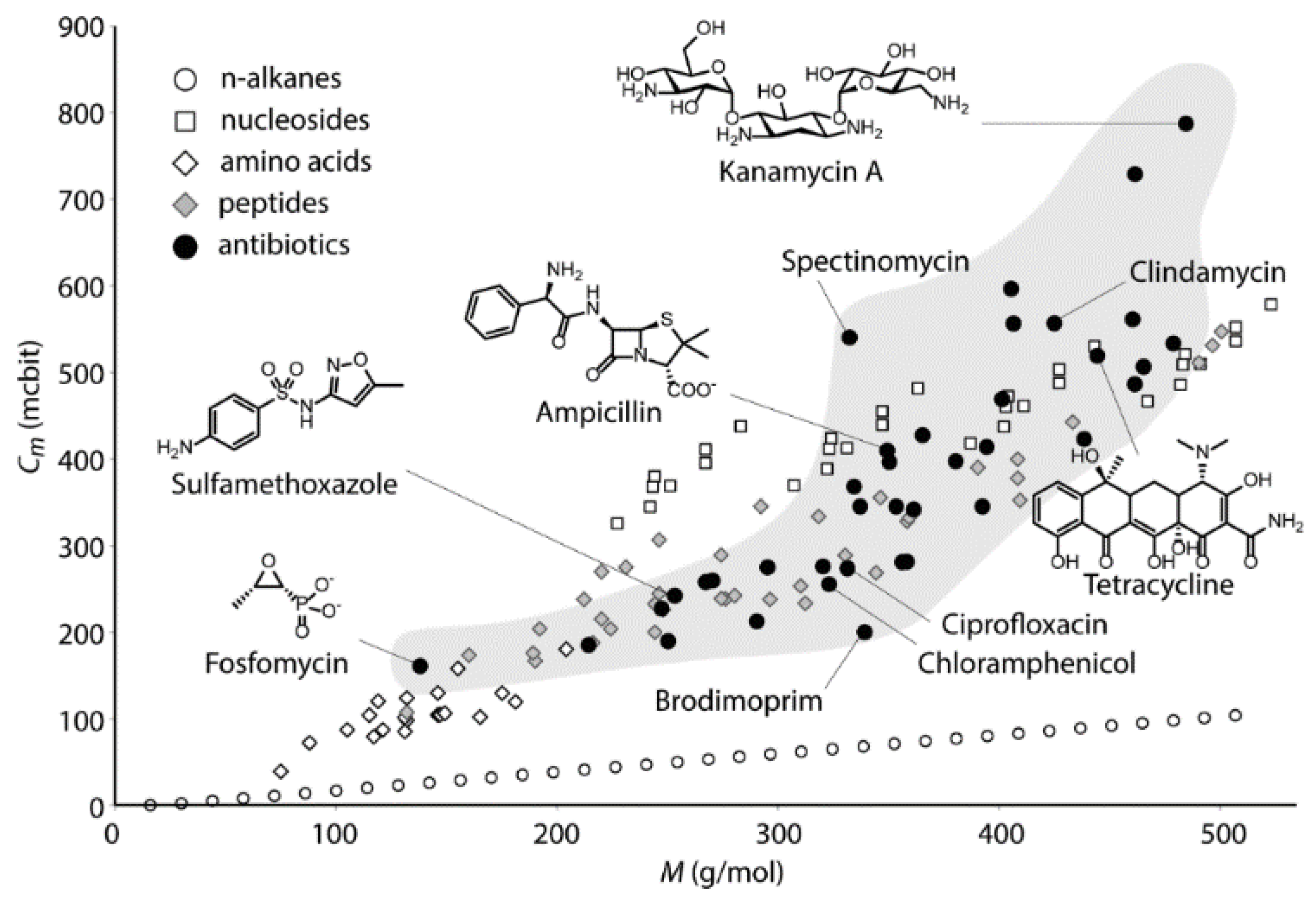
- Sabirov, D.S. Information entropy of interstellar and circumstellar carbon-containing molecules: Molecular size against structural complexity. Comput. Theor. Chem. 2016, 1097, 83–91. [Google Scholar] [CrossRef]
- Osawa, E. Formation mechanism of C60 under nonequilibrium and irreversible conditions—An Annotation. Fuller. Nanotub. Carbon Nanostruct. 2012, 20, 299–309. [Google Scholar] [CrossRef]
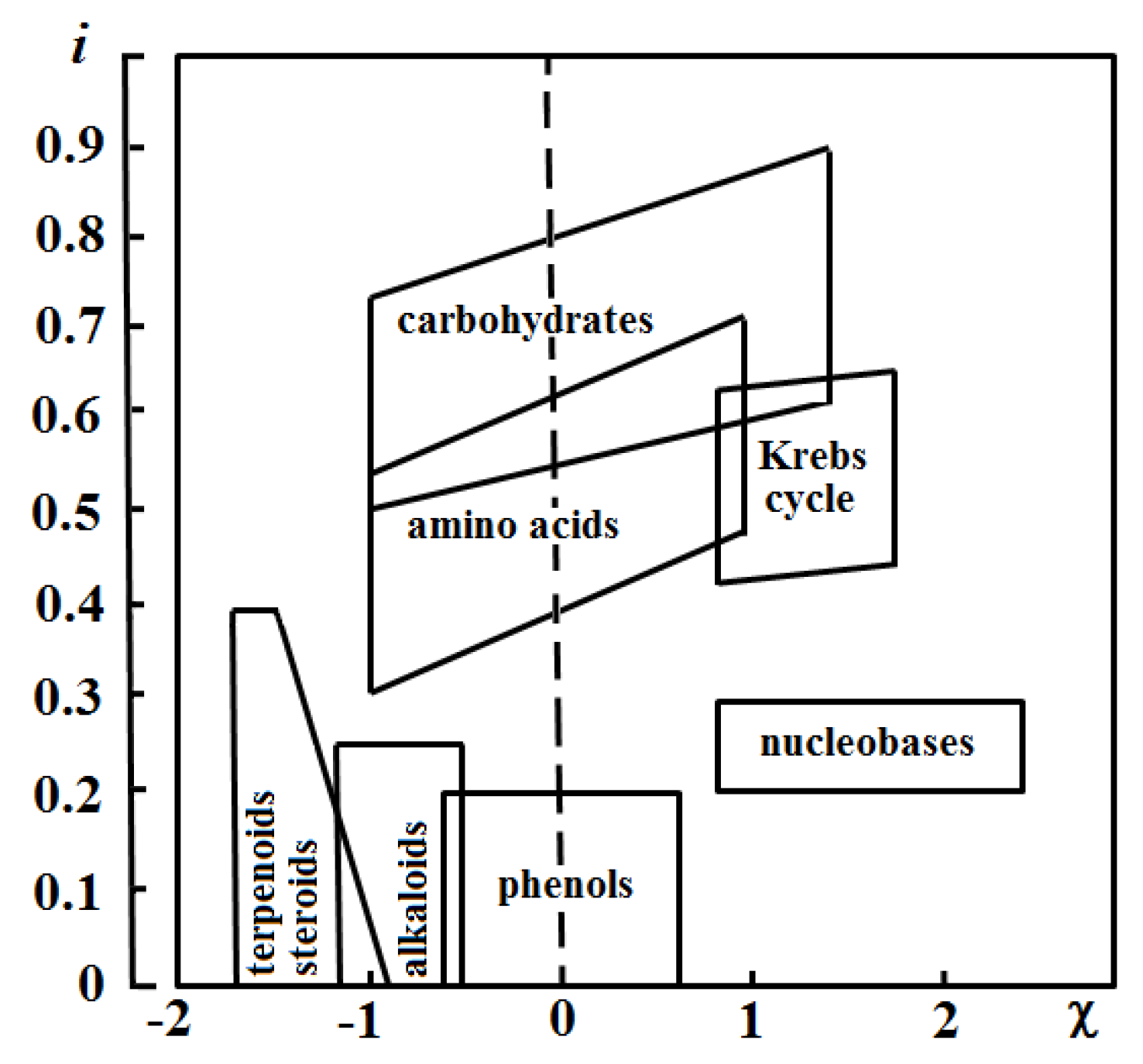
- Castellano, G.; González-Santander, J.L.; Lara, A.; Torrens, F. Classification of flavonoid compounds by using entropy of information theory. Phytochemistry 2013, 93, 182–191. [Google Scholar] [CrossRef]
- Castellano, G.; Lara, A.; Torrens, F. Classification of stilbenoid compounds by entropy of artificial intelligence. Phytochemistry 2014, 97, 62–69. [Google Scholar] [CrossRef]
- Castellano, G.; Torrens, F. Information entropy-based classification of triterpenoids and steroids from Ganoderma. Phytochemistry 2015, 116, 305–313. [Google Scholar] [CrossRef]
- Zhdanov, Y.A. Information Entropy in Organic Chemistry; Rostov University: Rostov, Russia, 1979; pp. 1–56. [Google Scholar]
- Sabirov, D.S.; Garipova, R.R.; Kinzyabaeva, Z.S. Fullerene–1,4-dioxane adducts: A DFT study of the structural features and molecular properties. Fuller. Nanotub. Carbon Nanostruct. 2019, 28, 154–159. [Google Scholar] [CrossRef]
- Sabirov, D.S.; Ori, O.; László, I. Isomers of the C84 fullerene: A theoretical consideration within energetic, structural, and topological approaches. Fuller. Nanotub. Carbon Nanostruct. 2018, 26, 100–110. [Google Scholar] [CrossRef]
- Ghorbani, M.; Dehmer, M.; Zangi, S. Graph operations based on using distance-based graph entropies. Appl. Math. Comput. 2018, 333, 547–555. [Google Scholar] [CrossRef]
- Ghorbani, M.; Rajabi-Parsa, M.; Majidi, R.; Mirzaie, R.A. Novel results on entropy-based measures of fullerenes. Fuller. Nanotub. Carbon Nanostruct. 2020, 29, 114–125. [Google Scholar] [CrossRef]
- Ghorbani, M.; Dehmer, M.; Rajabi-Parsa, M.; Mowshowitz, A.; Emmert-Streib, F. On properties of distance-based entropies on fullerene graphs. Entropy 2019, 21, 482. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghorbani, M.; Dehmer, M.; Mowshowitz, A.; Tao, J.; Emmert-Streib, F. The Hosoya Entropy of graphs revisited. Symmetry 2019, 11, 1013. [Google Scholar] [CrossRef] [Green Version]
- Ghorbani, M.; Dehmer, M.; Rajabi-Parsa, M.; Emmert-Streib, F.; Mowshowitz, A. Hosoya entropy of fullerene graphs. Appl. Math. Comput. 2019, 352, 88–98. [Google Scholar] [CrossRef]
- Chen, Z.; Dehmer, M.; Emmert-Streib, F.; Shi, Y. Entropy bounds for dendrimers. Appl. Math. Comput. 2014, 242, 462–472. [Google Scholar] [CrossRef]
- Bertz, S.H. The first general index of molecular complexity. J. Am. Chem. Soc. 1981, 103, 3599–3601. [Google Scholar] [CrossRef]
- Bertz, S.H. Complexity of synthetic reactions. The use of complexity indices to evaluate reactions, transforms and. New J. Chem. 2003, 27, 860–869. [Google Scholar] [CrossRef]
- Böttcher, T. An additive definition of molecular complexity. J. Chem. Inf. Model. 2016, 56, 462–470. [Google Scholar] [CrossRef]
- Böttcher, T. From molecules to life: Quantifying the complexity of chemical and biological systems in the universe. J. Mol. Evol. 2017, 86, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nagaraj, N.; Balasubramanian, K. Three perspectives on complexity: Entropy, compression, subsymmetry. Eur. Phys. J. Spec. Top. 2017, 226, 3251–3272. [Google Scholar] [CrossRef] [Green Version]
- Helgaker, T.; Coriani, S.; Jørgensen, P.; Kristensen, K.; Olsen, J.; Ruud, K. Recent advances in wave function-based methods of molecular-property calculations. Chem. Rev. 2012, 112, 543–631. [Google Scholar] [CrossRef] [PubMed]
- Sen, K.; De Proft, F.; Borgoo, A.; Geerlings, P. N-derivative of Shannon entropy of shape function for atoms. Chem. Phys. Lett. 2005, 410, 70–76. [Google Scholar] [CrossRef]
- Geerlings, P.; Borgoo, A. Information carriers and (reading them through) information theory in quantum chemistry. Phys. Chem. Chem. Phys. 2010, 13, 911–922. [Google Scholar] [CrossRef]
- Flores-Gallegos, N. On the calculations of Shannon’s entropy in atoms and molecules I: The continuous case in position and momentum spaces. Chem. Phys. Lett. 2019, 720, 1–6. [Google Scholar] [CrossRef]
- Noorizadeh, S.; Shakerzadeh, E. Shannon entropy as a new measure of aromaticity, Shannon aromaticity. Phys. Chem. Chem. Phys. 2010, 12, 4742–4749. [Google Scholar] [CrossRef]
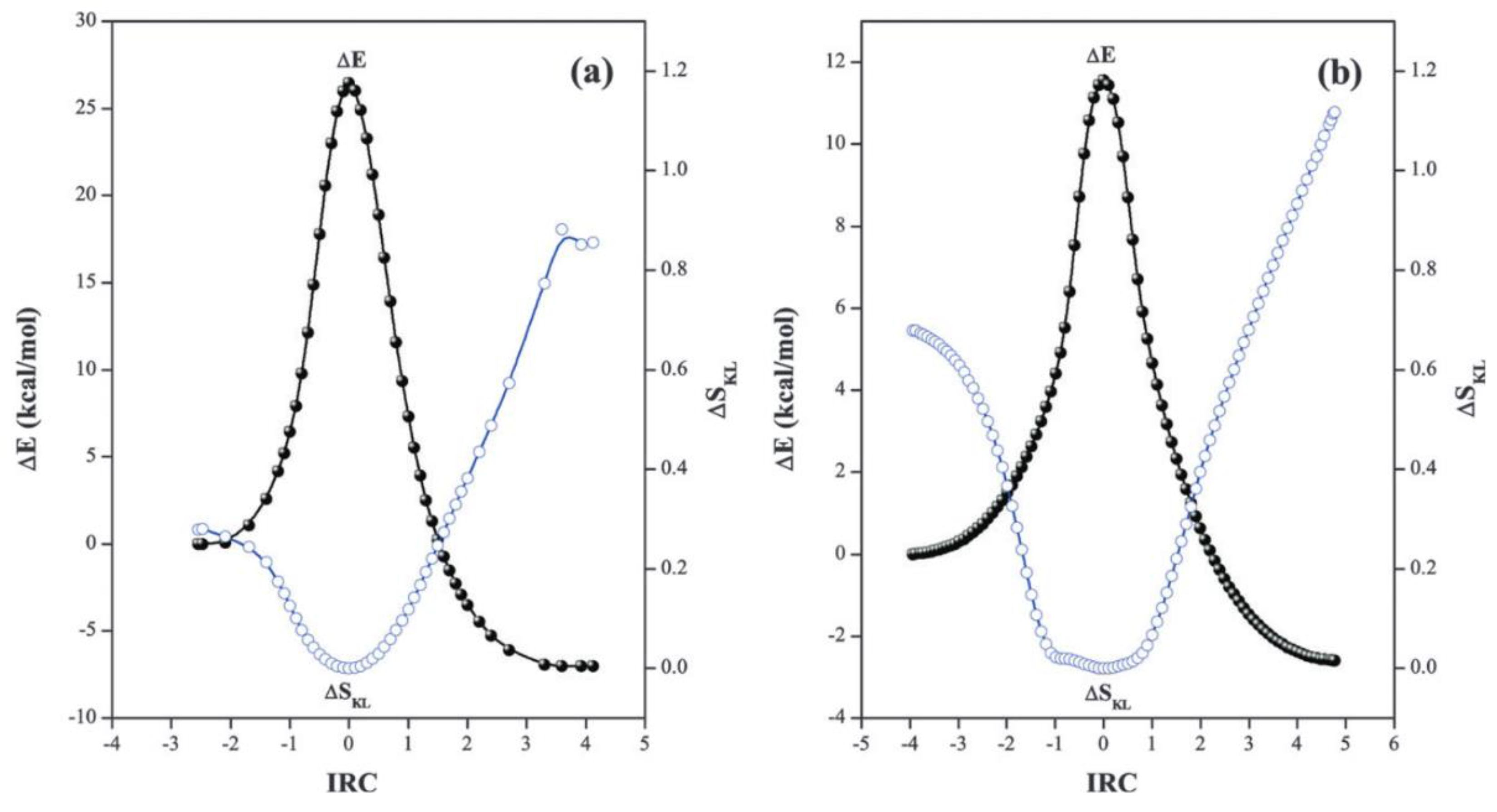
- Ho, M.; Schmider, H.L.; Weaver, D.F.; Smith, V.H., Jr.; Sagar, R.P.; Esquivel, R.O. Shannon entropy of chemical changes: SN2 displacement reactions. Int. J. Quantum Chem. 2000, 77, 376. [Google Scholar] [CrossRef]
- Borgoo, A.; Jaque, P.; Toro-Labbé, A.; Van Alsenoy, C.; Geerlings, P. Analyzing Kullback–Leibler information profiles: An indication of their chemical relevance. Phys. Chem. Chem. Phys. 2009, 11, 476–482. [Google Scholar] [CrossRef] [PubMed]
- Nalewajski, R.F. Information-theoretic descriptors of molecular states and electronic communications between reactants. Entropy 2020, 22, 749. [Google Scholar] [CrossRef] [PubMed]
- Nalewajski, R. Resultant Information descriptors, equilibrium states and ensemble entropy. Entropy 2021, 23, 483. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, P.H. Estimating configurational entropy of complex molecules: A novel variable transformation approach. Chem. Phys. Lett. 2009, 468, 90–93. [Google Scholar] [CrossRef]
- Schneider, T.D. A brief review of molecular information theory. Nano Commun. Netw. 2010, 1, 173–180. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gribov, L.A. Molecules as information receiver-converter systems. Vestnik Rossiyskoy Akademii Nauk. 2002, 72, 611–617. [Google Scholar]
- Galimov, D.I.; Tuktarov, A.R.; Sabirov, D.; Khuzin, A.A.; Dzhemilev, U. Reversible luminescence switching of a photochromic fullerene [60]-containing spiropyran. J. Photochem. Photobiol. A Chem. 2019, 375, 64–70. [Google Scholar] [CrossRef]
- Sabirov, D.S. Anisotropy of Polarizability of fullerene higher adducts for assessing the efficiency of their use in organic solar cells. J. Phys. Chem. C 2013, 117, 9148–9153. [Google Scholar] [CrossRef]
- Hayakawa, D.; Gouda, H.; Hirono, S.; Ueda, K. DFT study of the influence of acetyl groups of cellulose acetate on its intrinsic birefringence and wavelength dependence. Carbohydr. Polym. 2018, 207, 122–130. [Google Scholar] [CrossRef]
- Garcia-Garibay, A.M. Chemical reactivity in organized media: Statistical entropy and information in crystals and enzymes. Curr. Opin. Solid State Mater. Sci. 1998, 3, 399–406. [Google Scholar] [CrossRef]
- Nemcsics, A.; Nagy, S.; Mojzes, I.; Schwedhelm, R.; Woedtke, S.; Adelung, R.; Kipp, L. Investigation of the surface morphology on epitaxially grown fullerene structures. Vacuum 2009, 84, 152–154. [Google Scholar] [CrossRef]
- Nosonovsky, M. Self-organization at the frictional interface for green tribology. Philos. Trans. R. Soc. 2010, 368, 4755–4774. [Google Scholar] [CrossRef] [PubMed]
- Fischer, J.M.; Parker, A.J.; Barnard, A.S. Interfacial informatics. J. Phys. Mater. 2021, 4, 041001. [Google Scholar] [CrossRef]
- Tatevsky, V.M. The Structure of the Molecules; Khimiya: Moscow, Russia, 1977; pp. 1–512. [Google Scholar]
- Krivovichev, S. Structural complexity of minerals: Information storage and processing in the mineral world. Mineral. Mag. 2013, 77, 275–326. [Google Scholar] [CrossRef]
- Aksenov, S.M.; Yamnova, N.A.; Borovikova, E.Y.; Stefanovich, S.Y.; Volkov, A.S.; Deineko, D.V.; Dimitrova, O.V.; Gurbanova, O.A.; Hixon, A.E.; Krivovichev, S.V. Topological features of borophosphates with mixed frameworks: Synthesis, crystal structure of first aluminum and lithium borophosphate Li3{Al2[BP4O16]}·2H2O and comparative crystal chemistry. J. Struct. Chem. 2020, 61, 1760–1785. [Google Scholar] [CrossRef]
- Bindi, L.; Nespolo, M.; Krivovichev, S.V.; Chapuis, G.; Biagioni, C. Producing highly complicated materials. Nature does it better. Rep. Prog. Phys. 2020, 83, 106501. [Google Scholar] [CrossRef] [PubMed]
- Krivovichev, S.V.; Krivovichev, V.G.; Hazen, R.M. Structural and chemical complexity of minerals: Correlations and time evolution. Eur. J. Miner. 2018, 30, 231–236. [Google Scholar] [CrossRef] [Green Version]
- Krivovichev, S.V. Structural complexity and configurational entropy of crystals. Acta. Crystallogr. B Struct. Sci. Cryst. Eng. Mater. 2016, 72, 274–276. [Google Scholar] [CrossRef]
- Krivovichev, S.V. Structure description, interpretation and classification in mineralogical crystallography. Crystallogr. Rev. 2016, 23, 2–71. [Google Scholar] [CrossRef]
- Krivovichev, S.V. Polyoxometalate clusters in minerals: Review and complexity analysis. Acta Crystallogr. Sect. B Struct. Sci. Cryst. Eng. Mater. 2020, 76, 618–629. [Google Scholar] [CrossRef]
- Zolotarev, A.A.; Krivovichev, S.V.; Cámara, F.; Bindi, L.; Zhitova, E.S.; Hawthorne, F.; Sokolova, E. Extraordinary structural complexity of ilmajokite: A multilevel hierarchical framework structure of natural origin. Int. Union Crystallogr. J. 2020, 7, 121–128. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Plášil, J. Uranyl-oxide hydroxy-hydrate minerals: Their structural complexity and evolution trends. Eur. J. Minerol. 2018, 30, 237–251. [Google Scholar] [CrossRef]
- Banaru, A.; Aksenov, S.; Krivovichev, S. Complexity parameters for molecular solids. Symmetry 2021, 13, 1399. [Google Scholar] [CrossRef]
- Krivovichev, S.V.; Hawthorne, F.; Williams, P.A. Structural complexity and crystallization: The Ostwald sequence of phases in the Cu2(OH)3Cl system (botallackite–atacamite–clinoatacamite). Struct. Chem. 2016, 28, 153–159. [Google Scholar] [CrossRef]
- Sabirov, D.; Tukhbatullina, A.; Shepelevich, I. Information entropy of regular dendrimer aggregates and irregular intermediate structures. Liquids 2021, 1, 2. [Google Scholar] [CrossRef]
- Bal’makov, M.D. Information capacity of condensed systems. Phys. Uspekhi 1999, 42, 1167–1173. [Google Scholar] [CrossRef]
- Bal’makov, M.D. Virtual models of the synthesis of nanosystems. Glas. Phys. Chem. 2003, 29, 589–595. [Google Scholar] [CrossRef]
- Bal’makov, M.D. Statistical aspect of the formation of nanosystems. Glass Phys. Chem. 2002, 28, 437–440. [Google Scholar] [CrossRef]
- Bal’makov, M.D. Entropy and disorder. Glass Phys. Chem. 2001, 27, 287. [Google Scholar] [CrossRef]
- Bal’makov, M.D. Information basis of nanochemistry. Russ. J. Gen. Chem. 2002, 72, 1023–1030. [Google Scholar] [CrossRef]
- Aleskovskii, V.B. Chemical and information synthesis. In The Beginnings of the Theory, Methods, Tutorial, SPb; Publishing House of St. Petersburg University: St. Petersburg, FL, USA, 1997; pp. 1–72. [Google Scholar]
- Talanov, V.M.; Ivanov, V.V. Structure as the source of information on the chemical organization of substance. Russ. J. Gen. Chem. 2013, 83, 2225–2236. [Google Scholar] [CrossRef]
- Aleskovskii, V.B. Quantum synthesis. Russ. J. Appl. Chem. 2007, 80, 1785–1792. [Google Scholar] [CrossRef]
- Aleskovskii, V.B. Information as a factor of self-organization and organization of matter. Russ. J. Gen. Chem. 2002, 72, 569–574. [Google Scholar] [CrossRef]
- Ugi, I.; Gillespie, P. Representation of chemical systems and interconversions bybe matrices and their transformation properties. Angew. Chem. 1971, 10, 914–915. [Google Scholar] [CrossRef]
- Karreman, G. Topological information content and chemical reactions. Bull. Math. Biol. 1955, 17, 279–285. [Google Scholar] [CrossRef]
- Chambadal, P. Evolution et Applications du Concept d’Entropie; Dunod: Paris, France, 1963; pp. 1–278. [Google Scholar]
- Kadomtsev, B.B. Dynamics and information. Phys. Uspekhi 1994, 37, 425–499. [Google Scholar] [CrossRef]
- Kobozev, N.I. Physicochemical simulation of information and thinking. Thermodynamics of the information process. Russ. J. Phys. Chem. A 1966, 40, 281–294. [Google Scholar]
- Kobozev, N.I. A Study on Thermodynamics of the Information and Thinking Processes; Moscow University Press: Moscow, Russia, 1971; pp. 1–196. [Google Scholar]
- Corey, E.J.; Cheng, X.-M. The Logic of Chemical Synthesis; Wiley: Hoboken, NJ, USA, 1995; pp. 1–464. [Google Scholar]
- Schmitt, A.; Herzel, H. Estimating the entropy of DNA sequences. J. Theor. Biol. 1997, 188, 369–377. [Google Scholar] [CrossRef]
- Akhter, S.; Bailey, B.A.; Salamon, P.; Aziz, R.; Edwards, R.A. Applying Shannon‘s information theory to bacterial and phage genomes and metagenomes. Sci. Rep. 2013, 3, 1033. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koonin, E.V. The meaning of biological information. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150065. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vopson, M.M.; Robson, S.C. A new method to study genome mutations using the information entropy. Physics A 2021, 584, 126383. [Google Scholar] [CrossRef]
- Koslicki, D. Topological entropy of DNA sequences. Bioinformatics 2011, 27, 1061–1067. [Google Scholar] [CrossRef] [Green Version]
- Thomas, D.; Finan, C.; Newport, M.; Jones, S. DNA entropy reveals a significant difference in complexity between housekeeping and tissue specific gene promoters. Comput. Biol. Chem. 2015, 58, 19–24. [Google Scholar] [CrossRef] [PubMed]
- Kuruoglu, E.E.; Arndt, P.F. The information capacity of the genetic code: Is the natural code optimal? J. Theor. Biol. 2017, 419, 227–237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nigatu, D.; Henkel, W.; Sobetzko, P.; Muskhelishvili, G. Relationship between digital information and thermodynamic stability in bacterial genomes. EURASIP J. Bioinform. Syst. Biol. 2016, 2016, 4555. [Google Scholar] [CrossRef] [PubMed] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
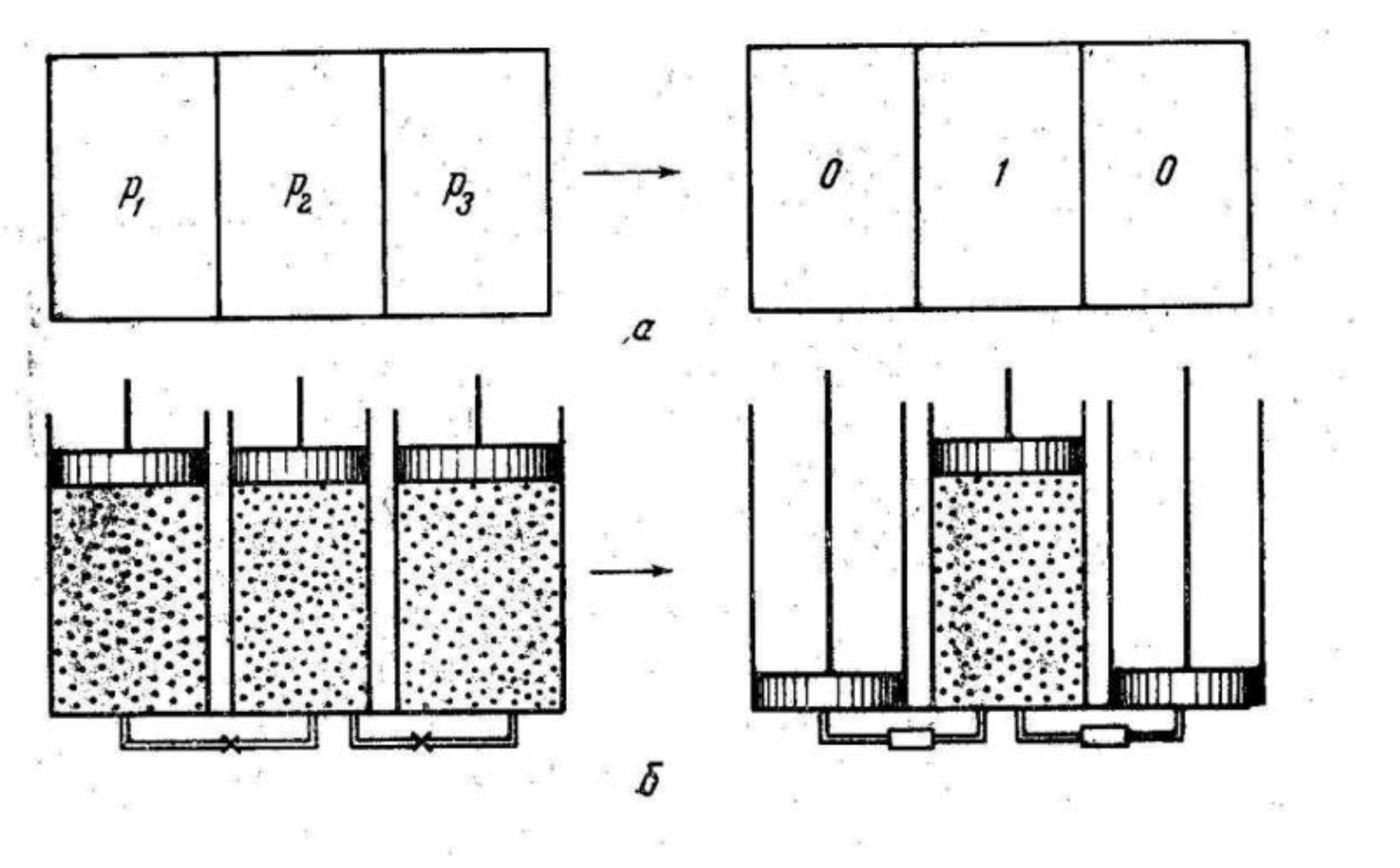{kind=link}
| Partition | h (Bits) | Examples |
|---|---|---|
| Diatomic species | ||
| 1 × 2 | 0 | All homonuclear diatomic species A2 (e.g., H2, H2+, and O2) |
| 2×1 | 1 | All heteronuclear diatomic species AB (e.g., HF, HD, and HO•) |
| Triatomic species | ||
| 1 × 3 | 0 | Cyclic species A3 (e.g., hypothetical cyclic ozone O3) |
| 1 × 2 + 1 × 1 | 0.918 | Linear/angular species AAA (e.g., open ozone O3, N3–, and I3–) and angular ABA (e.g., H2O, H2S, and: CH2) |
| 3 × 1 | 1.585 | ABC (e.g., HCN, HNC, and HOD) and AAB (e.g., HOO•) |
| Tetraatomic species | ||
| 1 × 4 | 0 | Tetrahedral A4 species (e.g., P4) |
| 1 × 3 + 1 × 1 | 0.811 | AB3 (e.g., •CH3, NH3, PCl3, NO3–, and CO32–) |
| 2 × 2 | 1 | ABBA (e.g., HC≡CH) |
| 1 × 2 + 2 × 1 | 1.5 | A2BC (e.g., H2C=O and H2C=S) |
| 4 × 1 | 2 | ABBC, ABCD, and ABBB (e.g., HC≡CCl, HCNO, and: C=C=C=O, respectively) |
| Molecule | Partition | h (Bits) |
|---|---|---|
| CH4 | 1 × 4 + 1 × 1 | 0.722 |
| CH3Cl | 1 × 3 + 2 × 1 | 1.371 |
| C2H6 | 1 × 6 + 1 × 2 | 0.811 |
| C2H4 | 1 × 4 + 1 × 2 | 0.918 |
| C2H2 | 2 × 2 | 1.000 |
| CH3OH | 1 × 3 + 3 × 1 | 1.792 |
| CH3CH2OH | 1 × 3 + 1 × 2 + 4 × 1 | 2.419 |
| CH3OCH3 | 1 × 6 + 1 × 2 + 1 × 1 | 1.224 |
| CH3COOH | 1 × 3 + 5 × 1 | 2.406 |
| C6H6 | 2 × 6 | 1.000 |
| C60 (Ih) | 1 × 60 | 0 |
| C70 (D5h) | 3 × 10 + 2 × 20 | 2.236 |
| Molecule | Structural Formula | Shannon Aromaticity, SA × 10–6 |
|---|---|---|
| Benzene |  | 1.7 × 10–6 |
| Naphthalene |  | 0.0737 |
| Anthracene |  | 0.1378 (a) 0.0612 (b) |
| Phenanthrene |  | 0.0042 (a) 0.1489 (b) |
| Crystal Class (Schoenflies Symbols) | Order | Partition of Group Elements | h, (Bits/Element) | htot, (Bits/Group) |
|---|---|---|---|---|
| C1 | 1 | {1} | 0 | 0 |
| C2, Ci, Cs | 2 | {1, 1} | 1.000 | 2.000 |
| C3 | 3 | {1, 2} | 0.918 | 2.755 |
| C4, S4 | 4 | {1, 1, 2} | 1.500 | 6.000 |
| C6, S6, C3h | 6 | {1, 1, 2, 2} | 1.918 | 11.510 |
| C2h, C2ʋ, D2 | 4 | {1, 3} | 0.811 | 3.245 |
| D2h | 8 | {1, 7} | 0.544 | 4.349 |
| C3ʋ, D2 | 6 | {1,2, 3} | 1.459 | 8.755 |
| C4h | 8 | {1, 1, 2, 4} | 1.750 | 14.000 |
| C4ʋ, D4, D2d | 8 | {1, 1, 2, 4} | 1.750 | 14.000 |
| C6h | 12 | {1, 2, 3, 6} | 1.730 | 20.755 |
| C6ʋ, D6, D3d, D3h | 12 | {1, 1, 2, 2, 6} | 1.959 | 23.510 |
| D4h | 16 | {1, 1, 2, 4, 8} | 1.875 | 30.000 |
| D6h | 24 | {1, 2, 3, 6, 12} | 1.865 | 44.755 |
| T | 12 | {1, 3, 8} | 1.189 | 14.265 |
| Th | 24 | {1, 1, 6, 8, 8} | 1.939 | 46.529 |
| Td, O | 24 | {1, 3, 6, 6, 8} | 2.094 | 50.265 |
| Oh | 48 | {1, 1, 3, 8, 8, 12, 15} | 2.369 | 113.700 |
| Category | Total Information Content (Bits/Unit Cell) | Approximate Number of Mineral Species | Examples |
|---|---|---|---|
| Very simple | 0–20 | 600 | diamond, copper, halite, galena, uraninite, fluorite, quartz, corundum, ringwoodite, calcite, dolomite, zircon, goethite |
| Simple | 20–100 | 1100 | alunite, jarosite, nepheline, kieserite, szomolnokite, kaolinite, olivine-group minerals, diopside, orthoclase, albite, biotite 1M |
| Intermediate | 100–500 | 1800 | enstatite, epidote, biotite 2M1, leucite, apatite, natrolite, tale 2M, pyrope, grossular, beryl, muscovite 2M1, staurolite, actinolite, holmquistite, coesite, tourmaline, analcime, boracite |
| Complex | 500–1000 | 300 | eudialyte, steenstrupine, coquimbite, sapphirine, alum, cymrite, aluminite |
| Very complex | >1000 | 100 | vesuvianite, paulingite, bouazzerite, asheroftine-(Y), bementite, antigorite |
| Compound | Ideal Symmetry of a Molecule | Real Symmetry of a Molecule | ||
|---|---|---|---|---|
| I2 | 0 | 0 | 0 | 0 |
| S6 | 0 | 0 | 0 | 0 |
| α-S8 | 0 | 0 | 2.000 | 16.000 |
| α-N2 | 0 | 0 | 0 | 0 |
| β-P4 | 0 | 0 | 3.585 | 14.340 |
| C60 | 0 | 0 | 1.522 | 91.320 |
| Ice Ih | 0.918 | 2.754 | 2.252 | 6.756 |
| Benzene | 1.000 | 12.000 | 2.585 | 31.020 |
| Naphthalene | 2.281 | 41.058 | 3.170 | 57.060 |
| Ensemble aA + bB | Partition | hA (Bits) | hB (Bits) | ωmax(A) | |
|---|---|---|---|---|---|
| aNH3 + bN2 | 1 × a + 1 × 3a + 1 × 2b | 0.811 | 0 | 0.637 | 1.462 |
| aC60 + bO2 | 1 × 60a + 1 × 2b | 0 | 0 | 0.5 | 1 |
| aC60 + bO3 | 1 × 60a + 1 × b + 1 × 2b | 0 | 0.918 | 0.346 | 1.531 |
| aC70 + bO3 | 2 × 20a + 3 × 10a + 1 × b + 1 × 2b | 2.236 | 0.918 | 0.714 | 2.723 |
| aC6H6 + bO3 | 2 × 6a + 1 × b + 1 × 2b | 1 | 0.918 | 0.514 | 1.960 |
| aC60 + bC2H2 | 1 × 60a + 1 × 2b | 0 | 1 | 0.333 | 1.585 |
| aC70 + bC2H2 | 2 × 20a + 3 × 10a + + 1 × 2b | 2.236 | 1 | 0.702 | 2.747 |
| aC6H6 + bC2H2 | 2 × 6a + 2 × 2b | 1 | 1 | 0.5 | 2 |
| Reaction | Formal Equation | Hreorg | Hredistr | ||
|---|---|---|---|---|---|
| Dissociation | D → A + B + … + C | hD | |||
| Addition | A + B + … + C → D | hD | |||
| Atomization | AaBb…cC → aA + bB + … + cC | h(AaBb…cC) | –h(AaBb…cC) | ||
| Isomerization | A → B | hB | hA | hB − hA | 0 |
| Number of Molecules in Molecular Ensemble (n) | h = HΩ (Bits) | hME (Bits) | Δhmix (bits) | Examples |
|---|---|---|---|---|
| 2 | 0.918 | 1.836 | 0 | O3 + C2H4; :CH2 + C2H4; H2O + C2H4 |
| 2 | 0.811 | 1.622 | 0 | intermetallic phases AB3 + A3B9 |
| 2 | 1 | 2 | 0 |  |
| 2 | 1 | 2 | 0 |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sabirov, D.S.; Shepelevich, I.S. Information Entropy in Chemistry: An Overview. Entropy 2021, 23, 1240. https://doi.org/10.3390/e23101240
Sabirov DS, Shepelevich IS. Information Entropy in Chemistry: An Overview. Entropy. 2021; 23(10):1240. https://doi.org/10.3390/e23101240
Chicago/Turabian StyleSabirov, Denis Sh., and Igor S. Shepelevich. 2021. "Information Entropy in Chemistry: An Overview" Entropy 23, no. 10: 1240. https://doi.org/10.3390/e23101240
APA StyleSabirov, D. S., & Shepelevich, I. S. (2021). Information Entropy in Chemistry: An Overview. Entropy, 23(10), 1240. https://doi.org/10.3390/e23101240