
A Network Theory Approach to Curriculum Design



Abstract
:1. Introduction
2. Complexity and Curriculum
3. Mathematical Model
3.1. Assumptions
3.2. Network Construction
“One clear distinction that arises between the functions we have studied thus far is that while a linear function exhibits a constant rate of change, an exponential function exhibits a constant percent change”.
| Introduced Topic | Directly Connected Topic |
| Linear Functions | Rate of Change |
| Linear Functions | Exponential Functions |
| Exponential Functions | Percent Change |
| Rate of Change | Percent Change |
- To start with, we make a list of all the topics in the chosen text under each chapter, section, and subsection. These topics are listed in a Table A1 in Appendix A. Each topic is given a numeric code. In the language of sets, pertains to the set of topics covered in the textbook, where refers to the i-th assigned code for each topics
- Based on the topics listed in first two columns of the Table A1, we then create a third column as shown in Appendix A, where the elements constitute the set : That is, topic may contain up to M direct connections outlined in the corresponding text being mapped, . The elements of set Y therefore represent distinct topics in X which are related to .
3.3. Metrics Computed
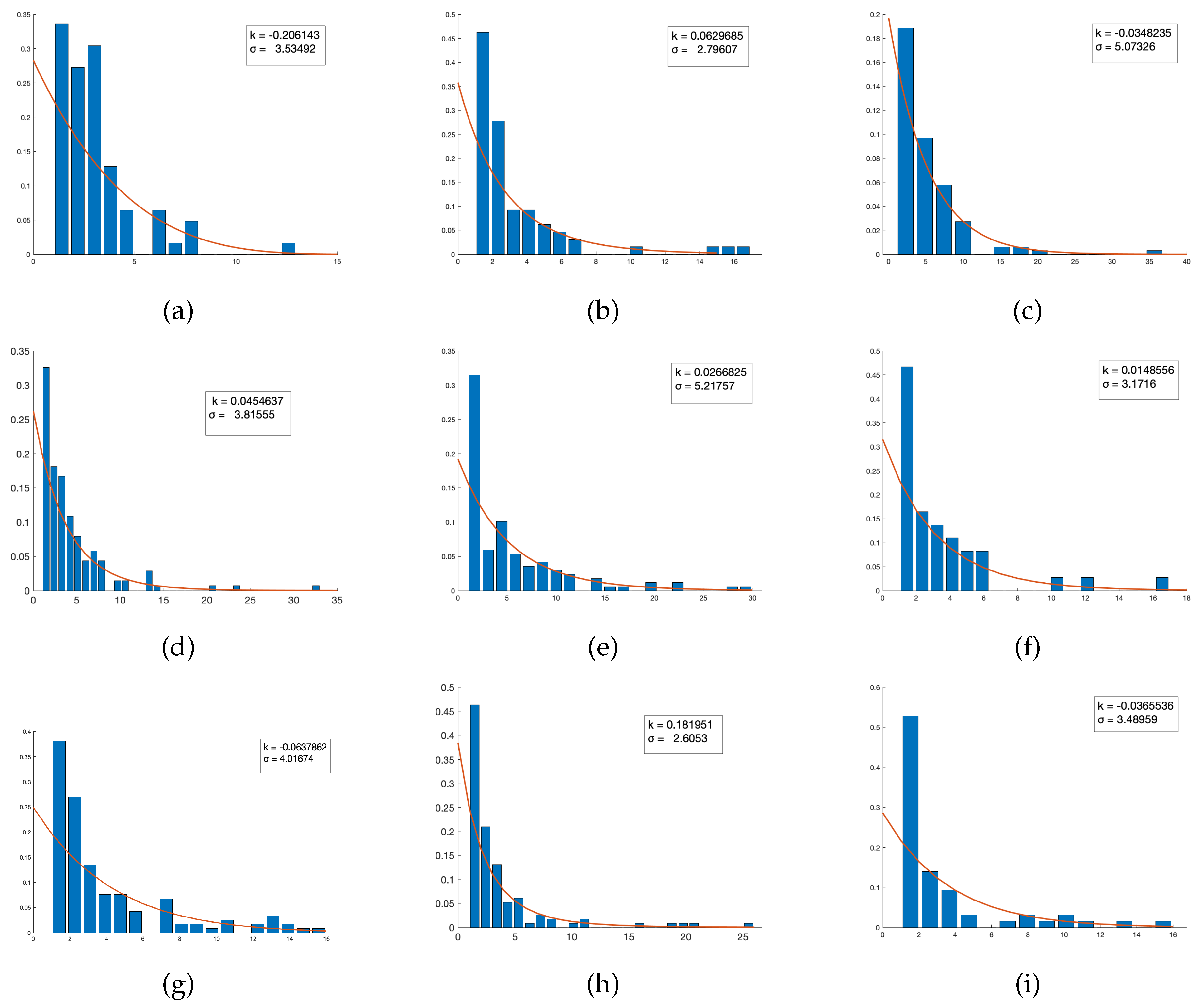
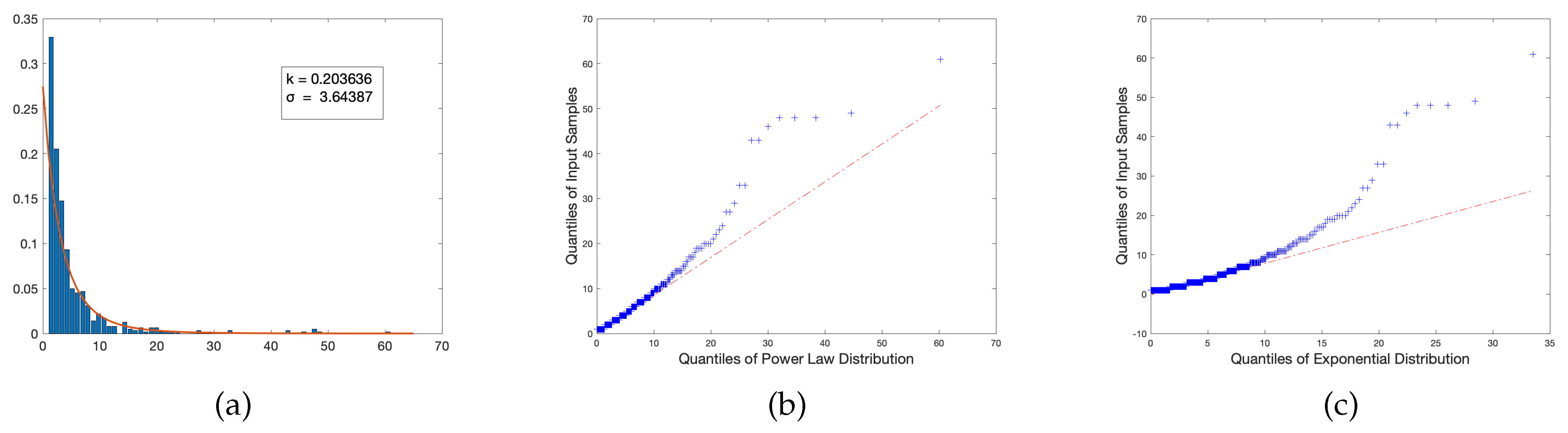
- The Degree Distribution (DD) helps us ascertain that the ‘textbook network’ does indeed display a power law profile and hence the metrics typically associated with the analyses of such networks are meaningful in this context. The power law nature of such a network reveals that there is a specific structure to curriculum which is not random. The degree distribution of the network is given by the probability functionwhere c is a constant, x denotes the degree of the node and is the exponent which is determined through our computations.
- Clustering Coefficient (CC) tells us about the average number of connections for each node, giving us a glimpse into the variety of ways a particular topic in precalculus can be understood. A fundamental assumption of the constructivist model of mathematics is the potential to make meaning. Therefore the greater the clustering coefficient, the more diverse the ways in which a concept can be comprehended depending on the particular background and proclivity of the student. The local clustering coefficient, denoted , is commonly given by the expression:resulting in the average clustering coefficient for the network,
- Average Path Length (APL) tells us the average number of steps that must be taken to traverse between any two nodes. In the context of this study, the APL tells us about how efficiently one can move from one idea to another. It is particularly useful to strategize about how to resolve mathematical problems. A network possessing a low APL is preferable, since it makes explicit the links between concepts and provides a road-map to travel efficiently from one point to another. This, coupled with a high CC, makes for easy navigation between ideas and also increases the likelihood of exploring many possible ways to navigate between these ideas. The APL is given by the equationwhere represents the path length from node i to node j.
- Hubs (H) are nodes which have a large number of edges. The threshold number of edges to qualify to be a hub, in general, is determined by the nature of the problem itself. We use the minimum number of chapters from all the texts examined to decide a threshold to qualify for a hub. This number turns out to be 6 based on the book by Faires [30].
4. Results
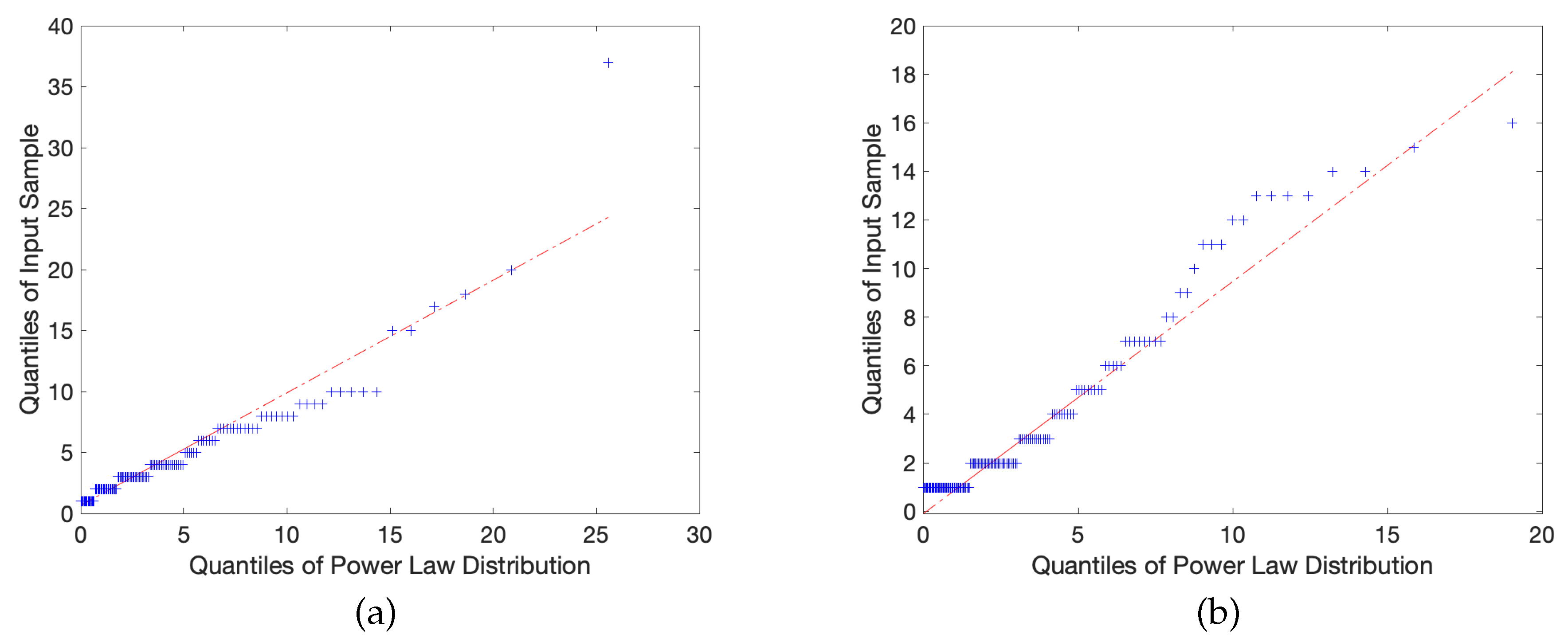
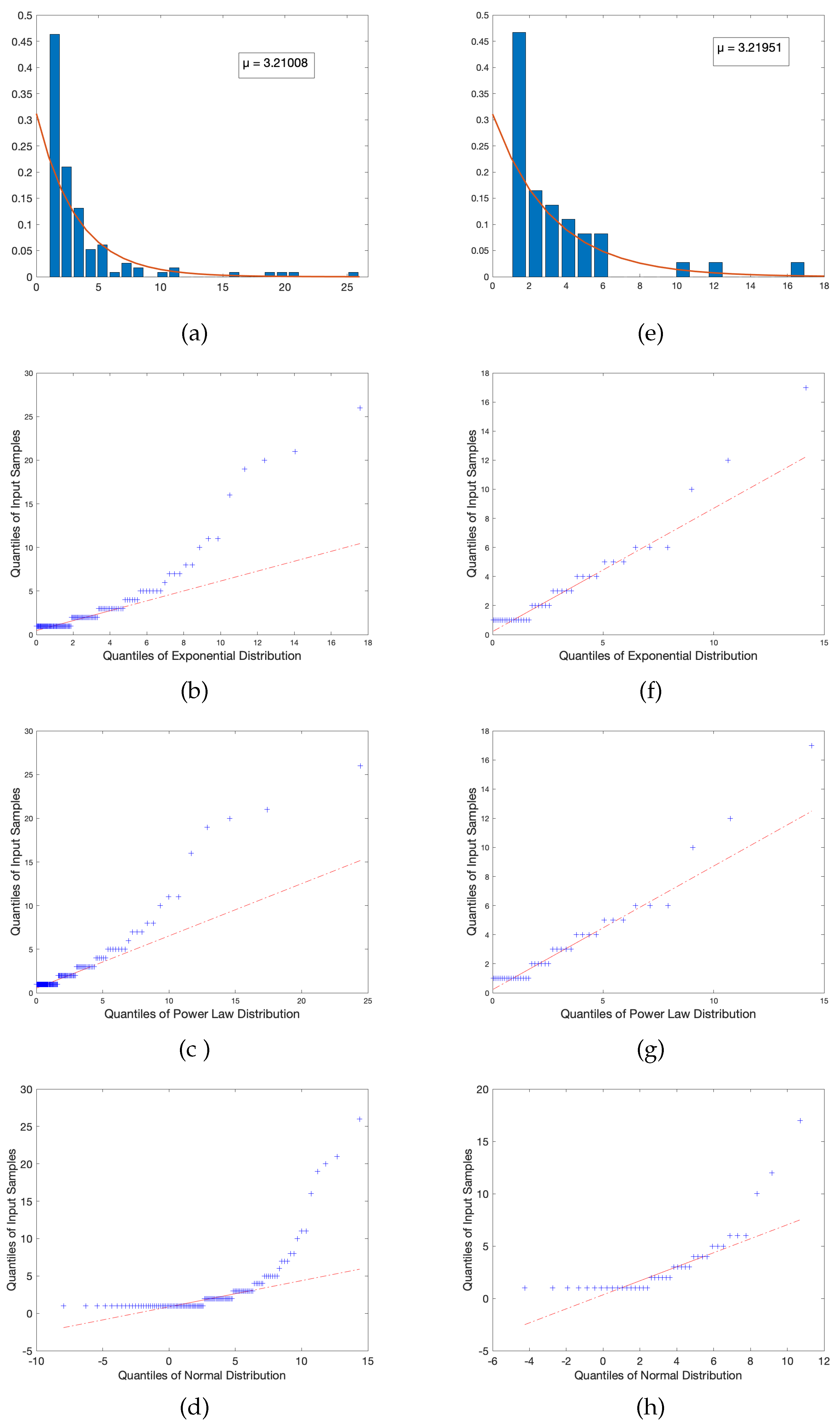
4.1. Power Law Distribution
4.2. Comparing the Network Profiles
5. Network Resilience Analysis
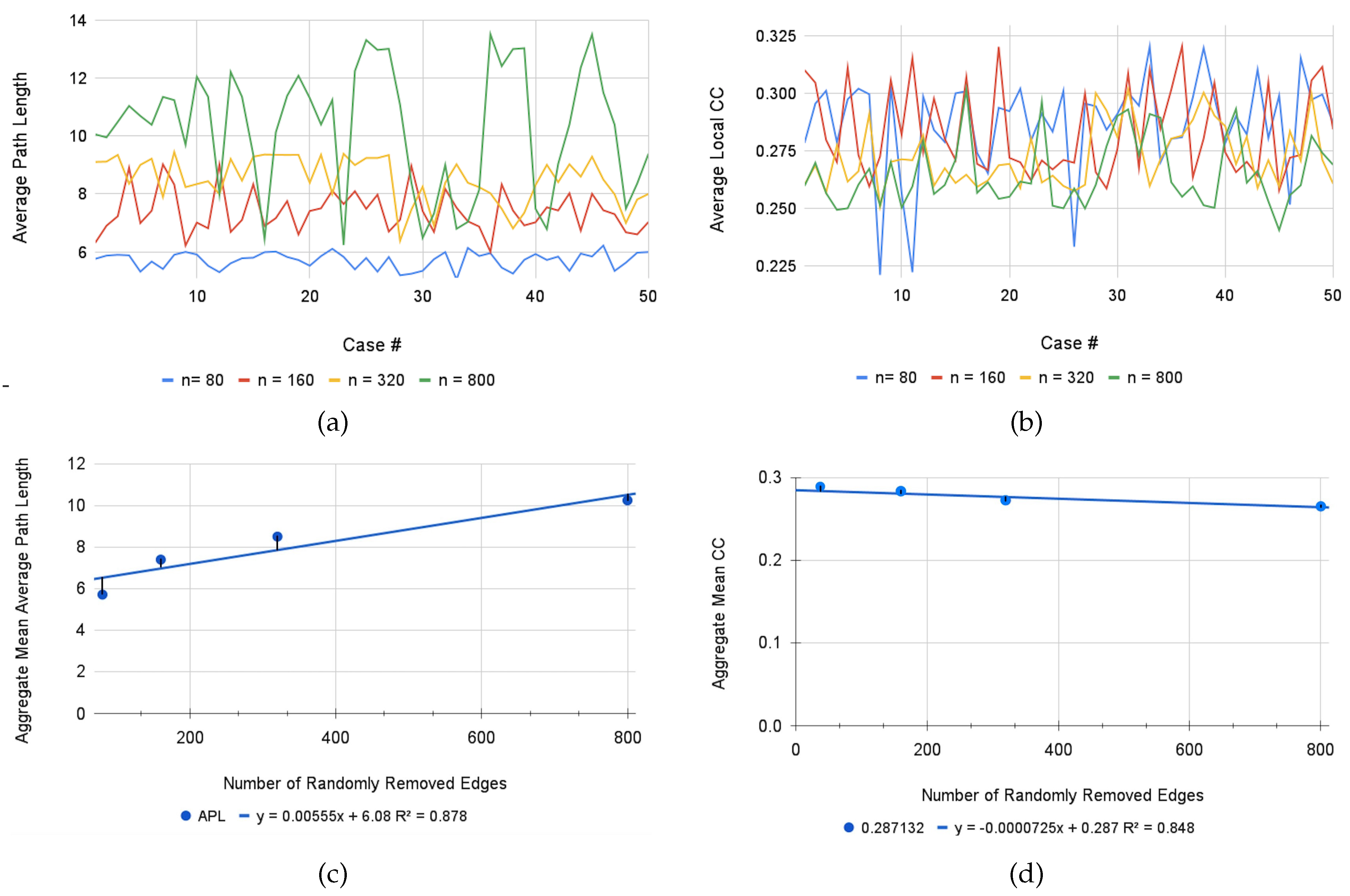
5.1. Stochastic Network Simulations
5.2. Simulation Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Network Construction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic Name | Code | Directly Connected Topics |
|---|---|---|
| Polynomial Functions | PF | RATZEROTHM, RF, REMAINALG, DIVALG, FACTTHM, GRAPHTECH, UPLOWBOUND, QUAD, LINEARFUNC, NONLIN, INEQ, F/R, DESCARTES, |
| Rational Zero Theorem | RATZEROTHM | PF |
| Rational Functions | RF | PF, GRAPH, MOD, PARTFRAC, LINEARFUNC, NONLIN, INEQ, F/R |
| Transformations | TRANS | GRAPH |
| Graphs | GRAPH | RF, TRANS, ASYM, MOD, EXP, LOG, EQN, PERIODICFUNC, LINEARFUNC, SYSLIN, LINPROG |
| Asymptotes | ASYM | GRAPH |
| Modeling | MOD | RF, GRAPH, EXP, LOG, EQN, PERIODICFUNC, LAWS, TRIGRAT, MATRIX, SYSLIN, HYPERBOLA, ELLIPSE, PARABOLA, SEQUENCES, BIN, RECURS |
| Partial Fractions | PARTFRAC | RF |
| Remainder Algorithm | REMAINALG | PF, SYNTH |
| Synthetic Division | SYNTH | REMAINALG, DIVALG |
| Division Algorithm | DIVALG | PF, SYNTH, LONGDIV |
| Long Division | LONGDIV | DIVALG |
| Factor Theorem | FACTTHM | PF |
| Intermediate Value Theorem | IVT | GRAPHTECH |
| Graphing with Technology | GRAPHTECH | PF, IVT |
| Descartes’ Rule | DESCARTES | PF |
| Upper and Lower Bounds | UPLOWBOUND | PF |
| Quadratic Functions | QUAD | PF, QUADGRAPHING, OPTIM |
| Graphing Quadratics | QUADGRAPHING | QUAD |
| Optimization | OPTIM | QUAD |
| Exponential Functions | EXP | GRAPH, MOD, LOG, EQN, NAT, F/R |
| Logarithms | LOG | GRAPH, MOD, EXP, EQN, NAT, COM, LIQU, F/R |
| Equation Representations | EQN | GRAPH, MOD, EXP, LOG, TRIG, IDENT, HYPERBOLA, ELLIPSE, PARABOLA, POLAR |
| Natural Log | NAT | LOG, EXP |
| Common Log | COM | LOG |
| Application: Liquids | LIQU | LOG |
| Trigonometry | TRIG | EXP, LOG |
| Right Triangle Trig | RTTRI | LOG |
| Unit Circle | UNITCIRCLE | LOG |
| Trig Identities | IDENT | EQN, UNITCIRCLE |
| Periodic Functions | PERIODICFUNC | MOD, RTTRI |
| Inverses | INVERSE | RTTRI |
| Trig Laws | LAWS | MOD, RTTRI |
| Trig Ratios | TRIGRAT | MOD, RTTRI |
| Matrices | MATRIX | MOD, METHODS, SYSOFEQNS |
| Methods of Evaluating Systems | METHODS | MATRICES, DET, CRAMER, GAUSSJORD |
| Systems of Equations | SYSOFEQNS | MATRIX, LINEARFUNC |
| Determinants | DET | METHODS |
| Cramer’s Rule | CRAMER | METHODS |
| Gauss-Jordan | GAUSSJORD | METHODS |
| Linear Functions | LINEARFUNC | PF, RF, GRAPH, SYSOFEQNS, F/R |
| Non-Linear Functions | NONLIN | PF, RF, SYSLIN, F/R |
| Systems of Non-Linear Eqns | SYSNLIN | GRAPH, MOD, NONLIN, INEQ |
| Inequalities | INEQ | PF, RF, SYSLIN, F/R |
| Linear Programming | LINPROG | GRAPH |
| Conic | CONIC | HYPERBOLA, ELLIPSE, PARABOLA, POLAR, F/R |
| Hyperbolas | HYPERBOLA | MOD, EQN, CONIC |
| Ellipses | ELLIPSE | MOD, EQN, CONIC |
| Parabolas | PARABOLA | MOD, EQN, CONIC |
| Polar | POLAR | EQN, CONIC |
| Sequences | SEQUENCES | MOD, INDUCTION, BIN, RECURS, GEO, ARITH, SERIES, F/R |
| Proof by Induction | INDUCTION | PROOF, SEQUENCES |
| Binomial Theorem | BIN | MOD, SEQUENCES |
| Recursion | RECURS | MOD, SEQUENCES |
| Geometric Sequences | GEO | SEQUENCES, PARTIALSUMS |
| Arithmetic Sequences | ARITH | SEQUENCES, PARTIALSUMS |
| Series | SERIES | SEQUENCES, PARTIALSUMS |
| Partial Sums | PARTIALSUMS | GEO, ARITH, SERIES |
| Proofs | PROOF | INDUCTION |
| Functions and Relations | F/R | PF, RF, EXP, LOG, TRIG, LINEARFUNC, NONLIN, INEQ, CONIC, SEQUENCES |
Appendix B. Codes for Hubs in All Books
| Hub Name | Code |
|---|---|
| Functions and Relations | F/R |
| Linear Functions | LF |
| Polynomial Functions | PF |
| Rational Functions | RF |
| Trig | TRIG |
| Conics | CONICS |
| Sequences | SEQUENCES |
| Limits | LIMITS |
| Series | SERIES |
| Graphing | GRAPH |
| Modeling | MOD |
| Inequalities | INEQ |
| Equations | EQN |
| Rate of Change | ROC |
| Average Speed | AS |
| Constant Rate of Change | CROC |
| Quadratic | QUAD |
| Composition | COMPOSITION |
| Function Notation | FUNCTNOT |
| Inverses | INV |
| Domain and Range | D/R |
| Exponential Function | EF |
| Growth and Decay | GROW/DEC |
| Transformations | TRANSF |
| Roots and End Behavior | ROOTS/EB |
| Circular Motion | CIRCMOT |
| Angle Measure | ANGMES |
| Cosine | COS |
| Sine | SIN |
| Right Triangle | RTTRI |
| Non-Right Triangles | NRTTRI |
| Average Rate of Change | AROC |
| Tangent | TAN |
| Change in Quantity | DELQ |
| Covariation | COV |
| Proportions | PROP |
| Box Activity | BOX |
| Percent Change | %DEL |
| Logarithm | LOG |
| Technology | TECH |
| Real Number Line | REALLN |
| X-Y Plane | XYPLANE |
| Applications | APPS |
| Distance Formula | DISTF |
| Pythagorean Theorem | PYTHTHM |
| Parabola | PARABOLA |
| Symmetry | SYMM |
| Calculus | CALC |
| Complex Numbers | COMPLEX |
| Periodic | PERIODIC |
| Cotangent | COT |
| Secant | SEC |
| Cosecant | COSEC |
| Trigonometric Identities | IDENTITIES |
| Sum and Difference Formulas | SUMDIFF |
| Hyperbola | HYPERBOLA |
| Ellipse | ELLIPSE |
| Circle | CIRC |
| Reflection | REFLECT |
| Quadratic Formula | QUADF |
| Polar Form | POLAR |
| Radians | RAD |
| Reciprocal | RECIP |
| Roots of Unity | ROOTUNITY |
| DeMoivre’s Theorem | DEMOIVRE |
| Secant Line | SECLINE |
| Slope | SLOPE |
| Euler’s Constant | E |
| Factorial | FACTORIAL |
| Tangent Line | TANLN |
| Combinatorics | COMBINATORICS |
| Mathematical Modeling | MATHMODEL |
| Dependent Variable | DV |
| Independent Variable | IV |
| Applications: Free Falling Objects | FALLINGOBJECTS |
| Oblique Triangles | OBLIQUE |
| Vectors | VECTORS |
| Differential and Difference Equations | DIFFEQ |
| Set Representations | SETS |
| Function Representations | REP |
| Role of Numbers and Quantity | NUMBERS |
| Permutations and Combinations | PERMUTCOMB |
| Counting Principles | COUNTPRINC |
| Probability | PROB |
| Binomial Expansion | BINEXP |
| Recursion | RECURS |
| Difference Tables | DIFFTAB |
| Tables | TAB |
| Proof | PROOF |
| Geometry | GEOM |
| Analytic Geometry | ANALGEOM |
| Coordinate Plane | COORDPL |
| Exponent Value | EXPVAL |
| Events | EVENTS |
| Area Under Curve | AREAUNDCURVE |
| Division Algorithm | DIVALG |
| Operations | OPER |
Appendix C. Hubs
| Book | Hub Names |
|---|---|
| Abramson | RF, LF, PF, RF, TRIG, CONICS, SEQUENCES, LIMITS, SERIES |
| Blitzer | GRAPH, MOD, INEQ, RF, PF, EQN, CONICS, SERIES, F/R |
| Pathways | ROC, AS, CROC, QUAD, F/R, COMPOSITION, FUNCTNOT, INV, D/R, EF, GROW/DEC, PF, TRANSF, ROOTS/EB, RF, CIRCMOT, ANGMES, COS, SIN, RTTRI, NRTTRI |
| Stewart | PF, RF, GRAPH, MOD, LOG, EF, SEQUENCES, EQN R/F |
| Faires | R/F, LF, REALLN, XYPL, RF, APPLICATION, QUAD, D/R, GRAPH, TECH, PYTHTHM, TRANSF, PARABOLA, SYMM, CALC, INV, ROOTS, PF, COMPLEX, TRIG, SIN, COS, PERANG, ANG, TAN, COTAN, SEC, COSEC, IDENTITIES, SUMDIFF, RTTRI, EF, LOG, GROW/DEC, CONICS, ELLIPSE, HYPERBOLA, CIRC, REFLECT, QUADF, POLAR, DISTF, COMPOSITION |
| CME | TAN, SIN, COS, PYTHTHM, GRAPH, ANG, RADIANS, TRIG, CIRC, EQN, RECIPROCAL, COMPLEX, DEMOIVRE, PF, IDENTITIES, SUM, RF, SECLINE, SLOPE, EF, E, FACTORIAL, TANLN, COMBINATORICS, PERMUTCOMB, R/F, PROB, BINEXP, RECURS, DIFFTAB, TAB, PROOF, GEOM, ANALGEOM, COORDPL, EXPVAL, EVENTS, CALC, AREAUNDCURVE, COUNTPRINC, ROOTUNITY |
| Larson | DIVALG, PF, GRAPHS, MOD, EQNS, OPER |
| COMAP | TRANSF, LINEAR, GEOMETRY, PF, F/R, GRAPHS, MATHMODEL, TABLES, EQN, DV, IV, EXP, LOG, INVERSE, MODELING, FALLINGOBJECTS, TECHNOLOGY, COMPLEX, PERIODIC, COS, SIN, RADIAN, TAN, RTTRI, OBLIQUE, VECTORS, POLAR, MATRIX, ANALGEO, PARABOLA, COUNTINGPRINC, DIFFEQ |
| Rockswold | F/R, SETS, REP, GRAPHS, LINEAR, INEQ, NUMBERS, MODELS, ZERO, EQN, QUADRATIC, PF, DIVISION, RF |
References
- Jörg, T. Thinking in complexity about learning and education: A programmatic view. Complicity Int. J. Complex. Educ. 2009, 6, 1–22. [Google Scholar] [CrossRef]
- Monahan, C.; Munakata, M.; Vaidya, A. Creativity as an Emergent Property of Complex Educational System. Northeast J. Complex Syst. (NEJCS) 2019, 1, 4. [Google Scholar] [CrossRef] [Green Version]
- Stephen, D.G.; Dixon, J.A. The self-organization of insight: Entropy and power laws in problem solving. J. Probl. Solving 2009, 2, 72–102. [Google Scholar] [CrossRef] [Green Version]
- Uzzi, B.; Spiro, J. Collaboration and creativity: The small world problem. Am. J. Sociol. 2005, 111, 447–504. [Google Scholar] [CrossRef] [Green Version]
- Jacobson, M.J.; Levin, J.A.; Kapur, M. Education as a complex system: Conceptual and methodological implications. Educ. Res. 2019, 48, 112–119. [Google Scholar] [CrossRef] [Green Version]
- Koopmans, M. Education is a complex dynamical system: Challenges for research. J. Exp. Educ. 2020, 88, 358–374. [Google Scholar] [CrossRef]
- Siew, C.S. Applications of network science to education research: Quantifying knowledge and the development of expertise through network analysis. Educ. Sci. 2020, 10, 101. [Google Scholar] [CrossRef] [Green Version]
- Sun, H.; Yen, P.; Cheong, S.A.; Koh, E.; Kwek, D.; Tan, J.P.L. Network Science Approaches to Education Research. Int. J. Complex. Educ. 2020, 1, 122–149. [Google Scholar]
- Doll, W.E., Jr. A Post-Modern Perspective on Curriculum; Teachers College Press: New York, NY, USA, 1993. [Google Scholar]
- Doll, W.E. Complexity and the culture of curriculum. Educ. Philos. Theory 2008, 40, 190–212. [Google Scholar] [CrossRef]
- Hiebert, J.; Carpenter, T.P. Learning and teaching with understanding. In Handbook of Research on Mathematics Teaching and Learning: A Project of the National Council of Teachers of Mathematics; Macmillan: Basingstoke, UK, 1992; pp. 65–97. [Google Scholar]
- Monahan, C.H. Fostering Mathematical Creativity among Middle School Mathematics Teachers. Ph.D. Thesis, Montclair State University, Upper Montclair, NJ, USA, 2020. [Google Scholar]
- Munakata, M.; Vaidya, A. Fostering creativity through personalized education. Primus 2013, 23, 764–775. [Google Scholar] [CrossRef]
- Available online: https://www.ucl.ac.uk/teaching-learning/connected-curriculum-framework-research-based-education (accessed on 4 June 2021).
- Fung, D. A Connected Curriculum for Higher Education; UCL Press: London, UK, 2017; p. 182. [Google Scholar]
- Wraga, W.G. Toward a connected core curriculum. Educ. Horiz. 2009, 87, 88–96. [Google Scholar]
- Davies, J.P.; Fung, D. The context of the Connected Curriculum. In Teaching and Learning in Higher Education: Perspectives from UCL; UCL IOE Press: London, UK, 2017; pp. 3–20. [Google Scholar]
- Barnett, R. Supercomplexity and the curriculum. Stud. High. Educ. 2000, 25, 255–265. [Google Scholar] [CrossRef]
- Davis, B. Complexity as a discourse on school mathematics reform. In Transdisciplinarity in Mathematics Education; Springer: Cham, Switzerland, 2018; pp. 75–88. [Google Scholar]
- Mason, M. Complexity theory and the philosophy of education. Educ. Philos. Theory 2008, 40, 4–18. [Google Scholar] [CrossRef]
- Ovens, A.; Butler, J. Complexity, curriculum, and the design of learning systems. In Routledge Handbook of Physical Education Pedagogies; Routledge: London, UK, 2016; pp. 115–129. [Google Scholar]
- Wood, P.; Butt, G. Exploring the use of complexity theory and action research as frameworks for curriculum change. J. Curric. Stud. 2014, 46, 676–696. [Google Scholar] [CrossRef] [Green Version]
- Kondepudi, D.K. Introduction to Modern Thermodynamics; Wiley: Chichester, UK, 2008; Volume 666. [Google Scholar]
- Korzybski, A. Science and Sanity; Institute of General Semantics: New York, USA, 1958; p. xxviii. [Google Scholar]
- Abramson, J.P. Precalculus: OpenStax; OpenStax: Huston, TX, USA, 2018. [Google Scholar]
- Blitzer, R. Precalculus, 5th ed.; Pearson: Harlow, UK, 2013; ISBN 10: 0321837347. [Google Scholar]
- Carlson, M. Precalculus: Pathway to Calculus, 8th ed.; MacMillan: New York, NY, USA, 2020. [Google Scholar]
- CME. Precalculus Common Core; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2013; ISBN 10: 1256741833. [Google Scholar]
- COMAP (Consortium for Mathematics and Its Applications). Precalculus: Modeling Our World, 1st ed.; W. H. Freeman: New York, NY, USA, 2001; ISBN 10: 0716743590. [Google Scholar]
- Faires, J.D.; DeFranza, J. Precalculus; Cengage Learning: Boston, MA, USA, 2011; ISBN 10: 084006862X. [Google Scholar]
- Larson, R.; Hostetler, R.; Edwards, B.H. Precalculus Functions and Graphs: A Graphing Approach, 3rd ed.; Houghton Mifflin: Boston, MA, USA, 2000; ISBN 10: 0618074104. [Google Scholar]
- Rockwold, G.; Atwood, D.; Krieger, T.; Krieger, T. Precalculus with Modeling & Visualization: A Right Triangle Approach; Pearson: Harlow, UK, 2009; ISBN 10: 0321659554. [Google Scholar]
- Stewart, J.; Redlin, L.; Watson, S. Precalculus: Mathematics for Calculus; Cengage Learning: Belmont, CA, USA, 2011; ISBN 10: 0840068077. [Google Scholar]
- Sullivan, M.; Sullivan, M., III. Precalculus; Pearson: Harlow, UK, 2019; ISBN 10: 0135189403. [Google Scholar]
- Cornog, M. A history of indexing technology. Indexer 1983, 13, 152–157. [Google Scholar]
- Understanding Book Indices. Available online: https://greenleafbookgroup.com/learning-center/book-creation/understanding-book-indexes (accessed on 17 August 2021).
- Albert, R.; Barabási, A.L. Statistical mechanics of complex networks. Rev. Mod. Phys. 2002, 74, 47. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E. The structure and function of complex networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E. Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 2005, 46, 323–351. [Google Scholar] [CrossRef] [Green Version]
- Clauset, A.; Shalizi, C.R.; Newman, M.E. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef] [Green Version]
- Novak, J.D. Concept mapping: A useful tool for science education. J. Res. Sci. Teach. 1990, 27, 937–949. [Google Scholar] [CrossRef]
- Morcom, V.E. Scaffolding peer collaboration through values education: Social and reflective practices from a primary classroom. Aust. J. Teach. Educ. (Online) 2016, 41, 81–99. [Google Scholar] [CrossRef] [Green Version]
- Tettey, B.A.; Acquah, M.; Jecty, R. Using Interactive Charts in a Demonstration Lesson to Help Learners of Colleges of Education Teach Measurement of Angle Properties of Parallel Lines in Basic Schools. Int. J. Comput. (IJC) 2020, 37, 46–66. [Google Scholar]
- Novak, J.D. Importance of conceptual schemes for science teaching. Sci. Teach. 1964, 10, 10. [Google Scholar]
- Trochim, W.M. Concept mapping: Soft science or hard art? Eval. Program Plan. 1989, 12, 87–110. [Google Scholar] [CrossRef]







| Text (Reference) | First Author | Edition | Year | Publisher |
|---|---|---|---|---|
| [25] | Abramson | 1st | 2017 | OpenStax |
| [26] | Blitzer | 5th | 2013 | Pearson |
| [27] | Carlson | 8th | 2020 | MacMillan |
| [28] | CME | - | 2013 | - |
| [29] | COMAP | - | 2002 | W. H. Freeman |
| [30] | Faires | 5th | 2011 | Cengage |
| [31] | Larson | 3rd | 2000 | Houghton Mifflin |
| [32] | Rockwold | 4th | 2010 | Pearson |
| [33] | Stewart | 6th | 2012 | Cengage |
| [34] | Sullivan | 11th | 2020 | Pearson |
| Book | APL | CC | % H | # H | Edges/Nodes | Mean Edges per Node | Power-Law Exponent | p-Value |
|---|---|---|---|---|---|---|---|---|
| Abramson | 19.0047 | 0.2662 | 11.54 | 9 | 116/78 | 1.487 | −5.851 | 0.14 |
| Blitzer | 3.7652 | 0.0481 | 12.33 | 9 | 109/73 | 1.493 | −16.881 | 0.16 |
| Carlson | 3.9001 | 0.2725 | 21.83 | 31 | 268/142 | 1.887 | −16.6774 | 0.07 |
| Stewart | 3.361 | 0.0417 | 15.00 | 9 | 101/60 | 1.683 | −28.357 | 0.06 |
| Faires | 3.2133 | 0.3414 | 35.25 | 43 | 327/122 | 2.680 | −38.478 | 0.84 |
| CME | 3.4179 | 0.4152 | 32.03 | 41 | 314/128 | 2.453 | −29.716 | 0.06 |
| Larson | 3.6915 | 0.156 | 14.63 | 6 | 66/41 | 1.610 | −68.315 | 0.051 |
| COMAP | 3.6908 | 0.3397 | 21.19 | 32 | 302/151 | 2 | −22.996 | 0.22 |
| Rockswold | 3.4128 | 0.2815 | 11.76 | 14 | 192/119 | 1.613 | −55.960 | 0.07 |
| No. of Removed Nodes, n | n = 5 | n = 80 | n = 160 | n = 320 | n = 800 |
|---|---|---|---|---|---|
| Percent Equivalent of Total Edges | 0.3097 | 4.9566 | 9.9132 | 19.8265 | 49.5662 |
| Absolute Percent Error in APL | 0.0666 | 11.7704 | 44.7580 | 66.4542 | 100.6488 |
| Absolute Percent Error in CC | 0.8559 | 9.3076 | 10.4080 | 13.9279 | 16.2400 |
| Mean APL | 5.1142 | 5.7123 | 7.3982 | 9.9291 | 12.9921 |
| Standard Deviation of APL | 0.0029 | 0.2820 | 0.7283 | 0.7835 | 2.1169 |
| Mean CC | 0.3138 | 0.2871 | 0.2836 | 0.2725 | 0.2651 |
| Standard Deviation of CC | 0.0028 | 0.0210 | 0.0190 | 0.0132 | 0.0146 |
| Rank | Network | Composite RMSD | Rank of Graph Size Based on # of Nodes |
|---|---|---|---|
| 1 | Pathways | 1.2989 | 2 |
| 2 | COMAP | 1.7228 | 1 |
| 3 | CME | 4.8429 | 3 |
| 4 | Stewart | 5.1918 | 8 |
| 5 | Larson | 5.3651 | 9 |
| 6 | Blitzer | 6.6795 | 7 |
| 7 | Faires | 6.6892 | 4 |
| 8 | Rockswold | 7.0268 | 5 |
| 9 | Abramson | 10.7050 | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
O’Meara, J.; Vaidya, A. A Network Theory Approach to Curriculum Design. Entropy 2021, 23, 1346. https://doi.org/10.3390/e23101346
O’Meara J, Vaidya A. A Network Theory Approach to Curriculum Design. Entropy. 2021; 23(10):1346. https://doi.org/10.3390/e23101346
Chicago/Turabian StyleO’Meara, John, and Ashwin Vaidya. 2021. "A Network Theory Approach to Curriculum Design" Entropy 23, no. 10: 1346. https://doi.org/10.3390/e23101346
APA StyleO’Meara, J., & Vaidya, A. (2021). A Network Theory Approach to Curriculum Design. Entropy, 23(10), 1346. https://doi.org/10.3390/e23101346