1. Introduction
The multi-modal fusion technique turns up to be an interesting topic in AI technology fields. It integrates the information in multiple modalities and therefore is expected to perform better prediction than the case using any unimodal information [
1]. Nowadays it has been applied in a broad range of applications, such as multimedia event detection [
2,
3], sentiment analysis [
1,
4], cross-modal translation [
5,
6,
7], Visual Question Answering (VQA) [
8,
9], etc.
The multi-modal fusion techniques can be typically divided into three approaches, which are the early fusion [
10], the late fusion [
11] and the hybrid fusion [
12]. The early fusion approach extracts the representation of features from each model and then fuses them at the feature level [
10]. This approach is more suitable for sentiment analysis. In contrast, the late fusion approach trains the different models at first and then merges them at the decision level [
13]. This approach, however, is good at emotion recognition. To take advantage of these two solutions, the hybrid fusion approach was subsequently proposed [
14]. Most of the abovementioned methods use simple and straightforward ways to integrate the information parameters, e.g., by merely concatenating or averaging the multi-modal vectors, which cannot make use of the dedicated interrelationships among the multiple models at all [
15].
Recently, by leveraging the tensor product representations, many researchers have geared towards achieving rich dynamic interactions in both intra-modality and inter-modality directly to boost the performance [
1,
15,
16,
17,
18]. Zadeh [
16] proposed a tensor fusion network (TFN) which calculates the interaction between different modalities by the cross-product of tensor. Unfortunately, such representations suffer from an exponential growth in feature dimensions and resulting in high cost training process. To tackle this problem, an efficient decomposition method (LMF) is proposed [
17] which leads to low-rank tensor factors and much less computational complexity, meanwhile, preserves the capacity of expressing the interactions of modalities. However, the method is still prone to parametric explosions once the features get too long. Meanwhile, it also ignores the local dynamics of interactions that are crucial to the final prediction [
15].
Motivated by this problem, in this paper, we make use of higher-order orthogonal iteration decomposition and projection to our tasks. It also ensures that the local dynamics of interactions are preserved with reasonable computational and memory costs [
19,
20].
The main contributions of our paper are given below:
- (1)
A tensor fusion method for multi-modalities prediction is proposed based on the higher-order orthogonal iteration decomposition and projection. It can remove the redundant information of duplicated inter-modal while producing fewer parameters with minimal information loss.
- (2)
The proposed method can tradeoff the dimensionality reduction ratio and the error rate well. Meanwhile, it guarantees that the new tensor is closest to the original tensor in the case of maximal dimension reduction.
- (3)
The performance of the proposed method has been verified through the evaluation processes on three common available multi-modal task datasets.
2. Relevant Mathematical Notations
To make the following algorithm description neat and clearer, some tensor related notations and operations are given at first:
: a tensor, denoting a higher-order extension of vectors and matrices in this paper.
: a n-mode unfolded matrix
: the Frobenius norm of a tensor
: the n-mode product of a tensor
⊗: the Kronecker product
Matricization: also known as unfolding or flattening, is the process of reordering the elements of an N-way array into a matrix. The n-mode matricization of a tensor
is denoted by
. It arranges the n-mode fibers to be the columns of the resulting matrix [
21] as shown in
Figure 1:
Tensor Multiplication: The n-mode product of a tensor
with a matrix
is denoted by
and is of size
, elementwise, we have
Singular Value Decomposition (SVD): A real matrix
can be expressed as the product
where
and
are orthogonal matrices and
is a diagonal matrix.
Tucker’s Tensor Decomposition (Tucker decomposition): Tucker decomposition is higher order SVD. Which approximates tensor
with the core tensor
and
N factor matrices
.
where
denotes an arbitrarily small positive real number.
3. Methodology
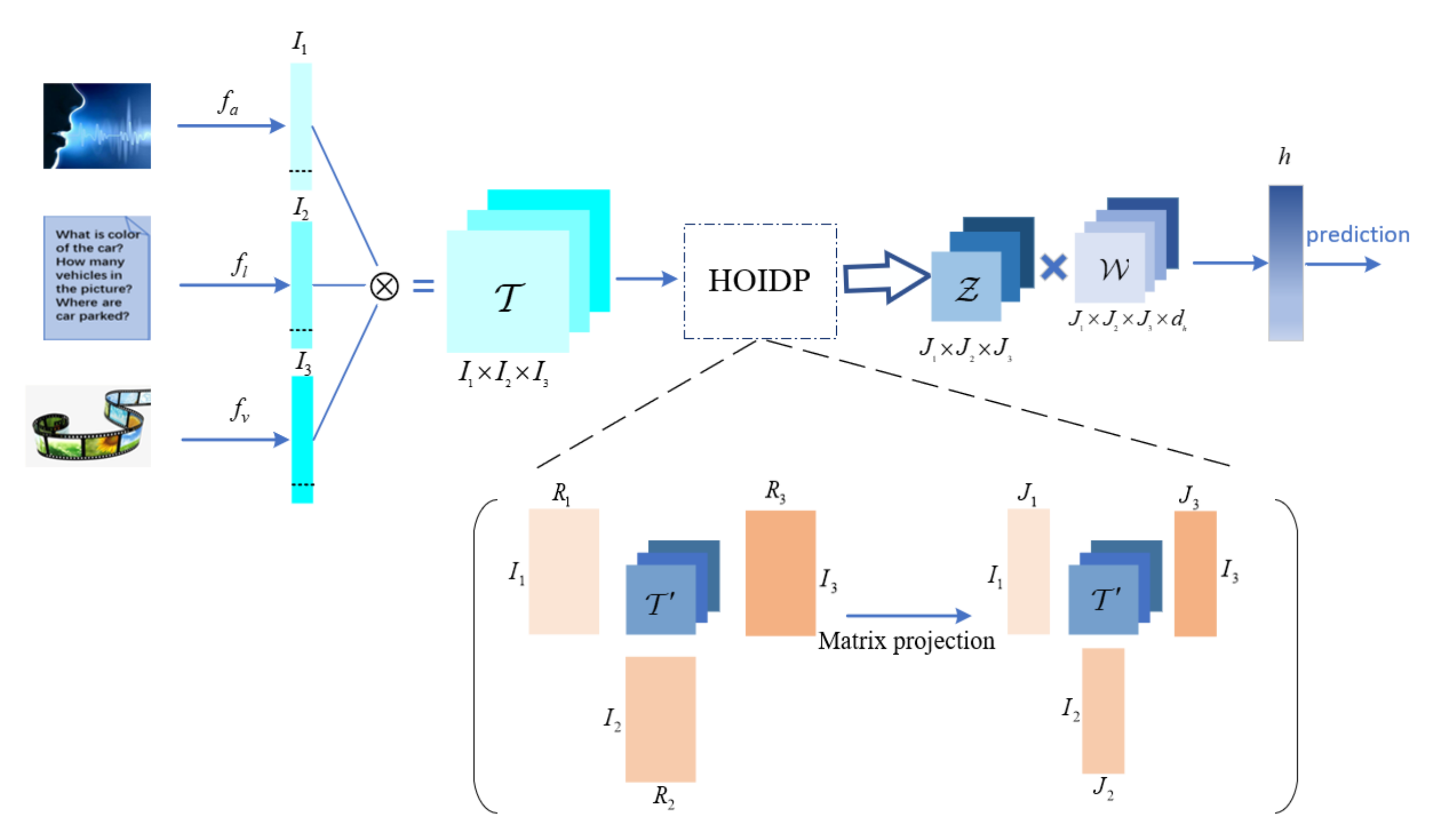
In this section, a multi-modal fusion method based on Higher-order Orthogonal Iteration Decomposition and Projection (HOIDP) is proposed. Similar to many other multi-modal prediction methods, the new method is composed of feature extraction and multi-modal fusion, network model training, and generating prediction task stages. The main contribution of this paper is mainly in the first stage. In another word, it belongs to an early fusion method.
As shown in
Figure 2, three modalities, i.e., the audio, the text, and the video inputs, are used in our algorithm presentation as well as our following experiments. At first, we obtain the three unimodal representations
,
and
, which are the outputs of the three sub-embedding networks
,
, and
of the audio, the text, and the video input, respectively, with the unimodal feature as their inputs. Secondly, we put these unimodal representations into a tensor
using the Kronecker product and then perform higher-order orthogonal iteration decomposition and projection to get tensor
. In the end, we put the feature tensor
into a deep neural network to generate the prediction tasks. The detailed algorithm is introduced in the following subsection.
3.1. Multi-Modal Fusion Based on Tensor Representation
Tensor representation is an effective approach for multi-modal fusion. We define
N modalities as
, and
which are column vectors of sizes
, and
. We represent a
N-modal tensor fusion approach by the Kronecker product in mathematical form.
Equation (
4) can capture multi-modal interactions effectively.
The input tensor
then goes through a linear layer
to produce a vector representation
h as shown in Equation (5).
where
is a fully connected deep neural network, and
is the weight and
b is the bias. The weight
is conditioned on the feature tensor
. Since the tensor
is higher dimensional and results increasing computational complexity, a higher-order orthogonal iteration decomposition is proposed in order to improve performance and reduce the data redundancy and parameter complexity in follow subsection.
3.2. Higher-Order Orthogonal Iteration Decomposition
We use the Tucker decomposition method to decompose the
N-order tensor
using (3). The solution of the core tensor and factor matrix can be obtained by solving the following optimization problem:
We adopt a higher-order orthogonal iteration decomposition algorithm to solve the above optimization problem to get the core tensor and the factor matrix . The core process is described in detail as the following steps:
Step 1: The n-mode unfolded matrix of tensor is calculated, and the singular value decomposition of the n-mode unfolded matrix is carried out respectively to obtain , let the left singular value matrix be the initial factor matrix .
Step 2: Set and perform the operations: , then perform the singular value decomposition of the n-mode unfolded matrix to obtain , and finally let .
Step 3: Calculate the core tensor of the k-th iteration by using the factor matrix. The core tensor of each iteration is calculated until the convergence condition is satisfied.
Algorithm 1 shows the process.
| Algorithm 1 The higher-order orthogonal iterative decomposition algorithm. |
- Input:
the N-order tensor ; - Output:
the core tensor and the factor matrix ; - 1:
Initialize the factor matrix : Calculated by Equation (2); ; . - 2:
Update factor matrix: ; ; ; . - 3:
Compute the core tensor of the k-th iteration: ; - 4:
ifthen - 5:
Go to Step 2; - 6:
else - 7:
Return , ; - 8:
end if
|
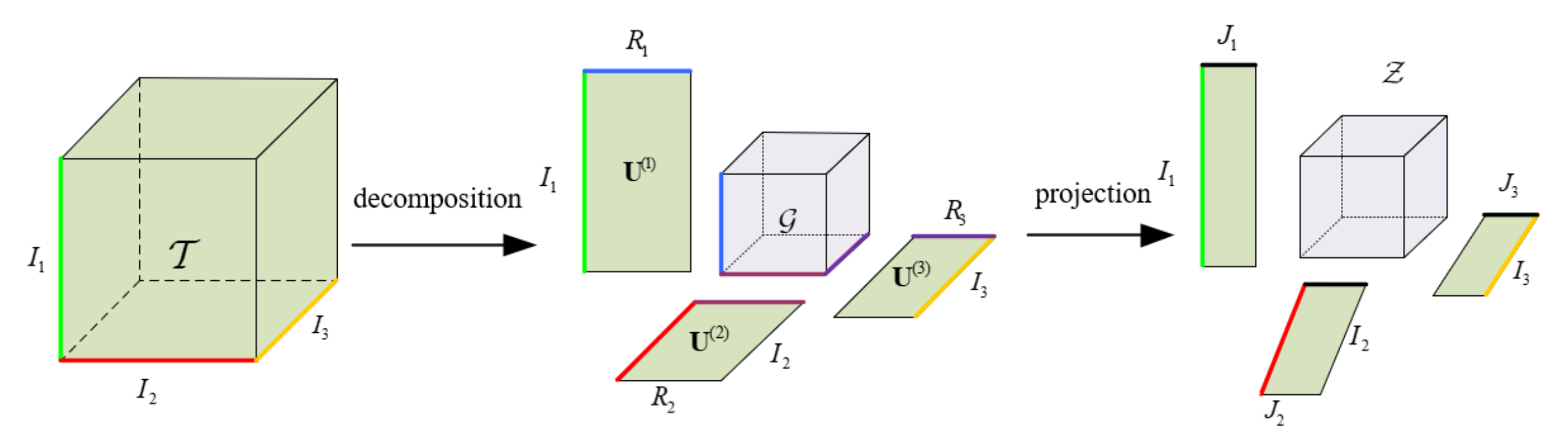
3.3. Factor Matrix Projection
Through the above algorithm, we obtain the core tensor and matrix factors of the tensor
. Since the factor matrix
represents the principal components of the tensor in each mode, the column vector of the factor matrix represents the principal components in this mode, and the columns are arranged in descending order according to the energy magnitude - the importance degree of features. Therefore, similar to the singular value decomposition, the factor matrices
are selected such that they perform projection to the original tensor
with the front columns
of each factor matrix, as shown in (7).
We can get an new tensor , which is the order of low dimensions in the new eigenspace compared to the original tensor .
Let us replace
with
in Equation (
5) and since weight
conditioned on feature tensor
, so we also replace
with
.
In practice, we flatten tensors and for reducing the last operation to matrix multiplication.
In this paper, we consider the number of modalities to be 3. In
Figure 3, tensor
is decomposed into a core tensor
and three factor matrices
,
, and
, the three factor matrices are then projected on the front columns
,
, and
. This process can be used for both compression and feature extraction of higher-order data.
4. Experimental Methodology
To verify the improvement of the method, we compare our method with DF [
22], MARN [
23], MFN [
24], TEN [
16], and LMF [
17] in sentiment analysis, personality trait recognition, and emotion recognition at three different multi-modal datasets.
4.1. Datasets
Experiments were performed on three multi-modal data sets CMU-MOSI [
25], POM [
26], and IEMOCAP [
27]. Each data set is composed of three modalities: language, video, and audio. The CMU-MOSI includes a collection of 93 comment videos from different film reviews. Multiple opinion clips and emotion annotations consist in each video and are annotated in the range [−3,3], the two thresholds represent highly negative and highly positive respectively. The POM consists of 903 review videos from different movies. Each video has the characteristics of the speaker: self-confidence, enthusiasm, pleasant voice, dominant, credible, vivid, professional, entertaining, introverted, trusting, relaxed, extroverted, thorough, nervous, persuasive, and humorous. IEMOCAP contains 151 videos that are designed to identify emotions displayed in human interactions, such as voice and gesture. The audio-visual data is recorded for approximately 12 h by 10 actors in a two-person conversation. Ten actors were asked to complete three selected scripts with clear emotional content. The dataset contains 9 emotional labels which include anger, happiness, sadness, frustration, and neutral states.
The three datasets include multiple information which has been divided into training, validation, and test sets to evaluate the generalization of the model in this paper. And it is ensured that there are no identical speakers between training sets and test sets. The data split for the three datasets is shown in
Table 1.
4.2. Multimodal Data Features
Each data set is composed of three modalities, i.e., language, video, and audio. We perform word alignment using P2FA [
28] to reach alignment across modalities. The audio and video features can be obtained by calculating the average of feature values in the word time interval [
29].
The experiment process of the information is as follows.
Language: pre-trained Glove word embeddings [
30] are used to embed a single word sequence transcribed from video clips into the word vector sequence of spoken text.
Visual: Facet library is applied for extracting visual features of each frame (sampling at 30 Hz), including head pose, 20 facial action units, 68 facial landmarks, gaze tracking, and HOG features [
31].
Audio: the COVAREP acoustic analysis framework [
32] is applied for extracting a set of low-level audio features.
4.3. Model Architecture
Three unimodal sub-embedding networks are used to extract representations for each modality [
17]. For visual and audio modalities, a simple 2-layer feed-forward neural network is used as a sub-embedding network. And for language, we use a long short-term memory network [
33] to extract representations. The model architecture is illustrated in
Figure 1.
In this paper, the models are tested using five-fold cross-validation which was proposed by CMU-MOSI. All experiments are performed without the information of speaker identity, while no speaker is repeated in the train and test sets, to make the model universal and independent of speaker information. The hyper-parameters are chosen by using grid search which is based on the performance of the model on the validation set. We trained our model using the Adam optimizer with a learning rate of 0.0003. The subnetworks , and are regularized by using dropout on all hidden layers with p = 0.15 and L2 norm coefficient as 0.01. The train, validation, and test folds are the same for each of the models. The models are implemented using Pytorch.
4.4. Evaluation Metrics
Based on the provided tags, multiple evaluation tasks are performed during our evaluation consisting of multi-category classification and regression. The multi-category classification task is applied to three multi-modal datasets, and the regression task is applied to the POM and CMU-MOSI. For the binary and multi-category classification, the F1 score and the average accuracy (ACC) are used to represent model performance. F1 score can be regarded as a weighted average of precision and recall and can be expressed as
It has a maximum value of 1 and a minimum value of 0. Similarly, for regression tasks, mean absolute error (MAE) and the correlation (Corr) between prediction and true scores are used to express performance. All these indicators show better performance with the higher values but except for MAE.
5. Experimental Results and Discussion
Based on the research questions introduced in
Section 3, we present and discuss the results from the experiments in this section.
5.1. Comparison with the State-of-the-Art
In the experiment, we compared our model with 5 methods. The Deep Fusion (DF) [
22] proposed a concatenation of the deep neural model for each modality followed by a joint neural network. The Multi-attention Recurrent Network (MARN) [
23] used a neural component called the Multi-attention block (MAB) which models the interaction between modalities through time and storing them in the Long-short Term Hybrid Memory (LSTM). The Memory Fusion Network (MFN) [
24] was proposed for multi-view sequential learning. The Tensor Fusion Network [
16] combined each modality into a tensor by computing the outer product. The Low-rank Multi-modal Fusion (LMF) [
17] performed the tensor factorization with the same low-rank for multi-modal fusion.
In
Table 2, the MAE, Corr, Acc-2, Acc-7, and F1 are presented. The accuracy of the proposed method is marked improvements in CMU-MOSI and POM. It is also marginally better than the LMF method in Happy and Angry recognition.
5.2. Computation Accuracy Analysis
The main function of the HOIDP method can achieve the purpose of dimensionality reduction. In this process, the core tensor and factor matrix are obtained by decomposing the original tensor firstly, and then the core tensor with the factor matrix are combined which have been updated by the HOIDP, finally, it forms a projection of the original tensor.
We verified whether the new tensor can replace the original tensor by calculating its error rate. The error rate is measured in norms is shown below:
where
and
are Frobenius Norms. Since the new tensor is composed of the core tensor and the projection of the updated factor matrix, the dimensionality reduction ratio is defined to measure the similarity between the new and the original tensor as
where
is a function that expresses the number of non-zero matrix elements. The dimensionality reduction ratio is generated by calculating the ratio of the non-zero elements in the core tensor and the updated matrix to non-zero elements in the original tensor. This dimension reduction ratio can effectively represent the degree of dimensions reduced.
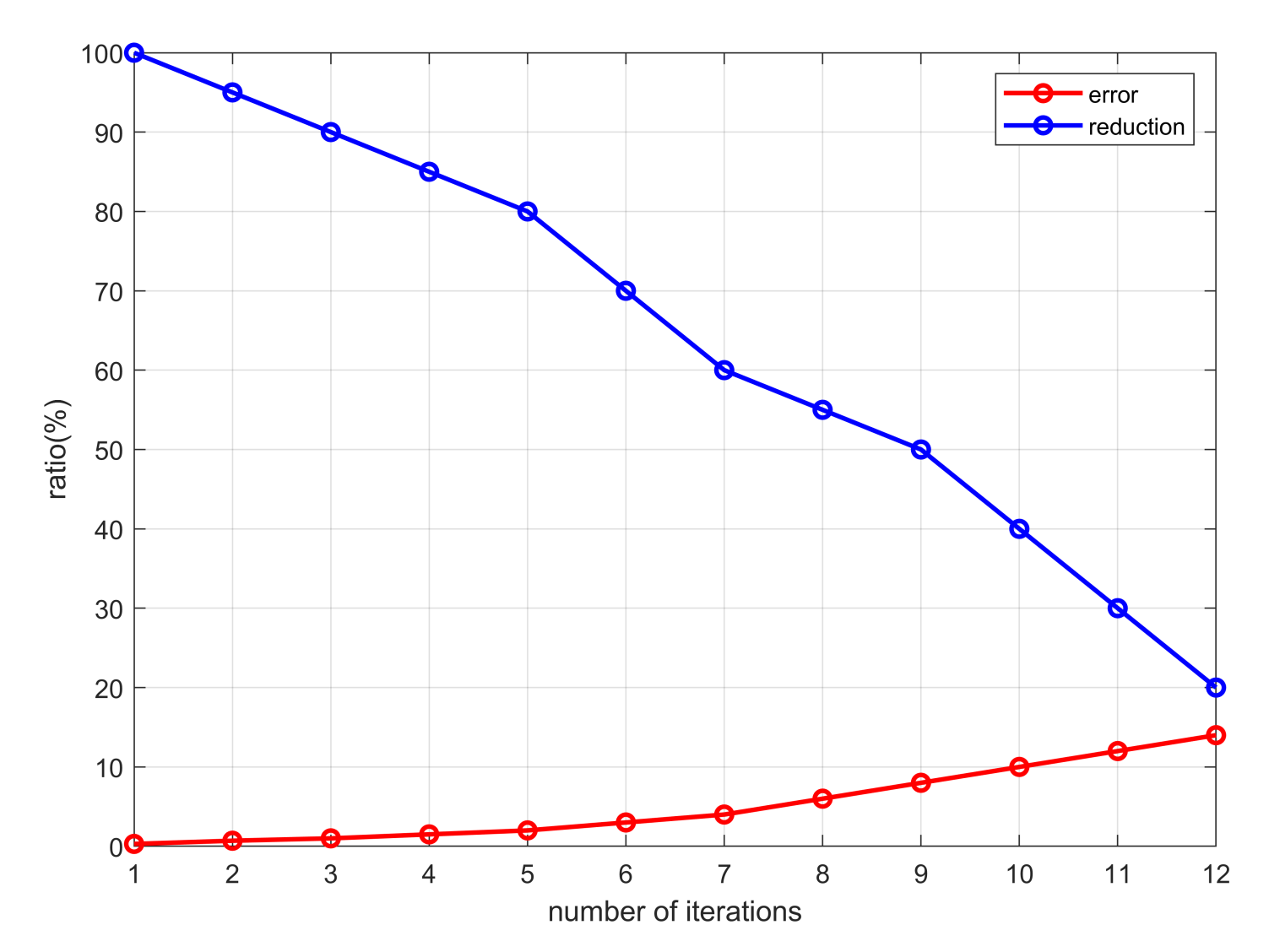
We use
to reflect the relationship between the error rate and the dimensionality reduction which is shown in
Figure 4. The abscissa is the number of iterations and the ordinate is the ratio value. We set the error rate to 0.3%, 0.7%, 1%, 1.5%, 2%, 3%, 4.1%, 6%, 8.2%, 10%, 11.9% and 14.2% successively. The larger the error rate, the greater difference between the new and the original tensor, and the lower similarity between them.
It can be seen from
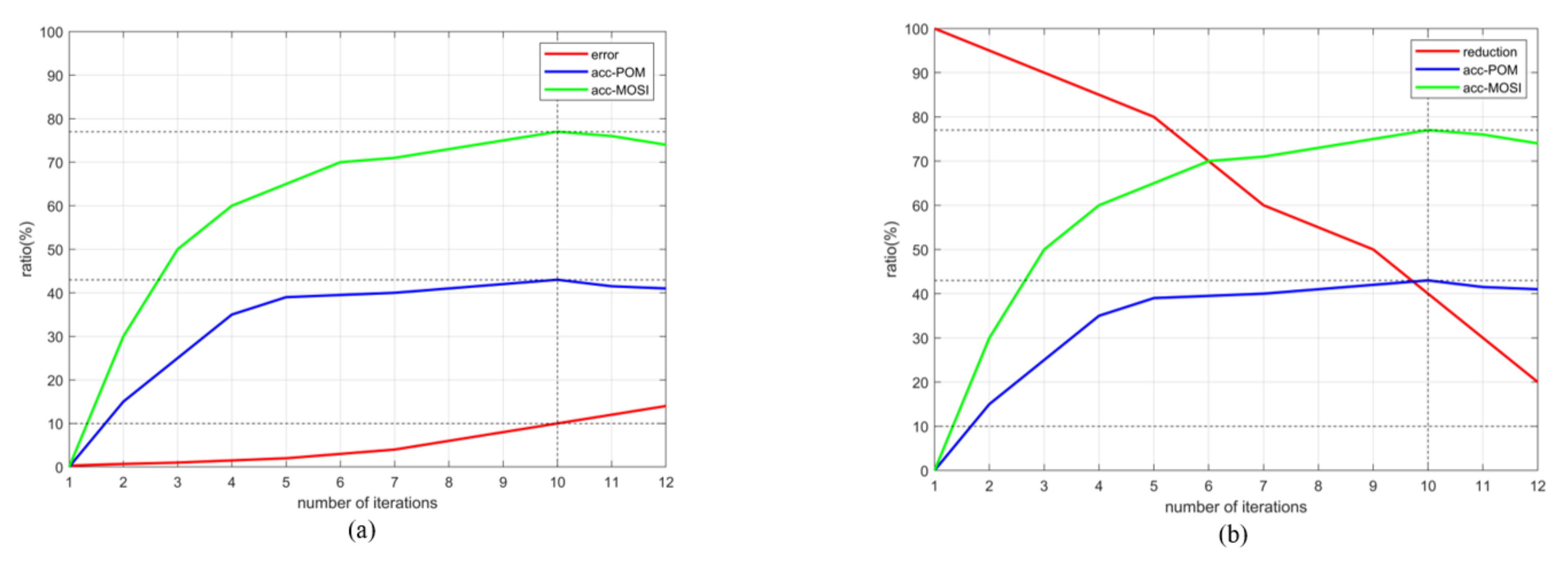
Figure 4 that the lower the dimensionality reduction ratio, the higher is the error rate. It means that we cannot blindly pursue a low dimension in the process of dimensionality reduction. It can achieve a balance between the dimensionality reduction ratio and error rate. In the experimental process, we found that when the number of iterations of tensor decomposition is 10, the error rate is 11.9%, and the dimension reduction ratio is 39.5%. The ACC achieved higher performance on CMU-MOSI and POM data sets as shown in
Figure 5, and the prediction results are better when performing the task.
The values of the dimensionality reduction ratio and error rate directly affect the accuracy of feature extraction of multi-modal data, and the evaluation metrics. Therefore, we should ensure that the new tensor is closest to the original tensor in case of maximum dimensionality reduction, and maintain the balance between dimensionality reduction and error according to the different requirements.
Furthermore, to evaluate the computational complexity of HOIDP, we measured the training and test speeds of HOIDP and compared them with TFN and LMF [
17] as shown in
Table 3. Here we set the dimension reduction error rate to 11.9% and the dimension reduction rate to 39.5% as it can achieve quite a significant increase in performance.
The models are executed in the same environment. The data represents the average frequency value of data point inferences per second (IPS) respectively.
6. Conclusions
In this paper, a multi-modal fusion method based on higher-order orthogonal iterative decomposition is proposed, the method can remove the redundant information and leads to fewer parameters with minimal information loss. In addition, we can trade off the dimensionality reduction ratio and the error rate well according to the requirements.
Experiments result show that the method improves the accuracy, the Happy and Angry recognition. It is compared to the other methods and provides the same benefits as the tensor fusion method. It is also immune to a large number of parameters. Furthermore, it can be seen that the HOIDP approach is more efficient and achieves a higher dimensionality reduction effect while maintaining a lower error rate.
Author Contributions
Conceptualization, F.L. and J.C.; methodology, F.L.; validation, F.L.; writing—original draft preparation, F.L.; writing—review and editing, J.C., C.C. and W.T.; supervision, J.C.; funding acquisition, J.C. and F.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Natural Science Foundation of Shaanxi Province: 2020JM-554; Yan’an University Scientific Research Project: YDY2019-18 and Key Research and Development Projects of Shaanxi Province: 2021NY-036.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors acknowledge Xinzhuang Chen and Zhiwei Guo for their comments and suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| TFN | Tensor Fusion Network |
| HOIDP | Higher-order Orthogonal Iteration Decomposition and Projection Fusion |
| DF | Deep Fusion |
| MARN | Multi-attention Recurrent Network |
| MFN | Memory Fusion Network |
| LMF | Low-rank Multi-modal Fusion |
| ACC | Accuracy |
| MAE | Mean Absolute Error |
| LSTM | Long-sort Term Hybrid Memory |
| SVD | Singular Value Decomposition |
References
- Fung, P.N. Modality-based Factorization for Multimodal Fusion. In Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019), Florence, Italy, 2 August 2019. [Google Scholar]
- Shuang, W.; Bondugula, S.; Luisier, F.; Zhuang, X.; Natarajan, P. Zero-Shot Event Detection Using Multi-modal Fusion of Weakly Supervised Concepts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23 June 2014; IEEE: Washington, DC, USA, 2014; pp. 2665–2672. [Google Scholar]
- Habibian, A.; Mensink, T.; Snoek, C. VideoStory Embeddings Recognize Events when Examples are Scarce. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2013–2089. [Google Scholar] [CrossRef] [PubMed]
- Xie, Z.; Guan, L. Multimodal Information Fusion of Audio Emotion Recognition Based on Kernel Entropy Component Analysis. Int. J. Semant. Comput. 2013, 7, 25–42. [Google Scholar] [CrossRef]
- Qi, J.; Peng, Y. Cross-modal Bidirectional Translation via Reinforcement Learning. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 2630–2636. [Google Scholar]
- Bhagat, S.; Uppal, S.; Yin, Z.; Lim, N. Disentangling multiple features in video sequences using gaussian processes in variational autoencoders. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 102–117. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Yang, Z.; Garcia, N.; Chu, C.; Otani, M.; Nakashima, Y.; Takemura, H. Bert representations for video question answering. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1556–1565. [Google Scholar]
- Garcia, N.; Otani, M.; Chu, C.; Nakashima, Y. KnowIT VQA: Answering knowledge-based questions about videos. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–8 February 2020; pp. 10826–10834. [Google Scholar]
- D’mello, S.K.; Kory, J. A Review and Meta-Analysis of Multimodal Affect Detection Systems. ACM Comput. Surv. 2015, 47, 43:1–43:36. [Google Scholar] [CrossRef]
- Kanluan, I.; Grimm, M.; Kroschel, K. Audio-visual emotion recognition using an emotion space concept. In Proceedings of the 16th European Signal Processing Conference, Lausanne, Switzerland, 25–29 August 2008; IEEE: Karlsruhe, Germany, 2008; pp. 1–5. [Google Scholar]
- Chetty, G.; Wagner, M.; Goecke, R. A Multilevel Fusion Approach for Audiovisual Emotion Recognition; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Jong-Seok, L.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis; Using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Lan, Z.z.; Bao, L.; Yu, S.I.; Liu, W.; Hauptmann, A.G. Multimedia classification and event detection using double fusion. Multimed. Tools Appl. Int. J. 2014, 71, 333–347. [Google Scholar] [CrossRef]
- Hou, M.; Tang, J.; Zhang, J.; Kong, W.; Zhao, Q. Deep multimodal multilinear fusion with high-order polynomial pooling. Adv. Neural Inf. Process. Syst. 2019, 32, 12136–12145. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor Fusion Network for Multimodal Sentiment Analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.; Morency, L.P. Efficient Low-rank Multimodal Fusion with Modality-Specific Factors. arXiv 2018, arXiv:1806.00064. [Google Scholar]
- Mai, S.; Hu, H.; Xing, S. Modality to Modality Translation: An Adversarial Representation Learning and Graph Fusion Network for Multimodal Fusion. Proc. AAAI Conf. Artif. Intell. 2020, 34, 164–172. [Google Scholar] [CrossRef]
- Baltrusaitis, T.; Ahuja, C.; Morency, L.P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, W.; Wang, J.; Wanga, S. Deep Multimodal Representation Learning: A Survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Nojavanasghari, B.; Gopinath, D.; Koushik, J.; BAltruaitis, T.; Morency, L.P. Deep Multimodal Fusion for Persuasiveness Prediction. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 284–288. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Poria, S.; Vij, P.; Morency, L.P. Multi-attention Recurrent Network for Human Communication Comprehension. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Morency, L.P. Memory Fusion Network for Multi-view Sequential Learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5634–5641. [Google Scholar]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos. arXiv 2016, arXiv:1606.06259. [Google Scholar]
- Park, S.; Han, S.S.; Chatterjee, M.; Sagae, K.; Morency, L.P. Computational Analysis of Persuasiveness in Social Multimedia: A Novel Dataset and Multimodal Prediction Approach. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; ACM: New York, NY, USA, 2014; pp. 50–57. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive Emotional Dyadic Motion Capture Database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Yuan, J.; Liberman, M. Speaker identification on the SCOTUS corpus. J. Acoust. Soc. Am. 2008, 123, 3878. [Google Scholar] [CrossRef]
- Chen, M.; Wang, S.; Liang, P.P.; Baltruaitis, T.; Zadeh, A.; Morency, L.P. Multimodal Sentiment Analysis with Word-Level Fusion and Reinforcement Learning. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 163–171. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceeding of the 2014 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Zhu, Q.; Yeh, M.C.; Cheng, K.T.; Avidan, S. Fast Human Detection Using a Cascade of Histograms of Oriented Gradients. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, USA, 17–22 June 2006; pp. 1491–1498. [Google Scholar]
- DeGottex, G.; Kane, J.; Drugman, T.; Raitio, T.; Scherer, S. COVAREP: A Collaborative Voice Analysis Repository for Speech Technologies. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing, Florence, Italy, 4–9 May 2014; pp. 960–964. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}