
Sharp Guarantees and Optimal Performance for Inference in Binary and Gaussian-Mixture Models †

Abstract
:1. Introduction
1.1. Motivation
1.2. Data Models
- (Noisy) Signed:
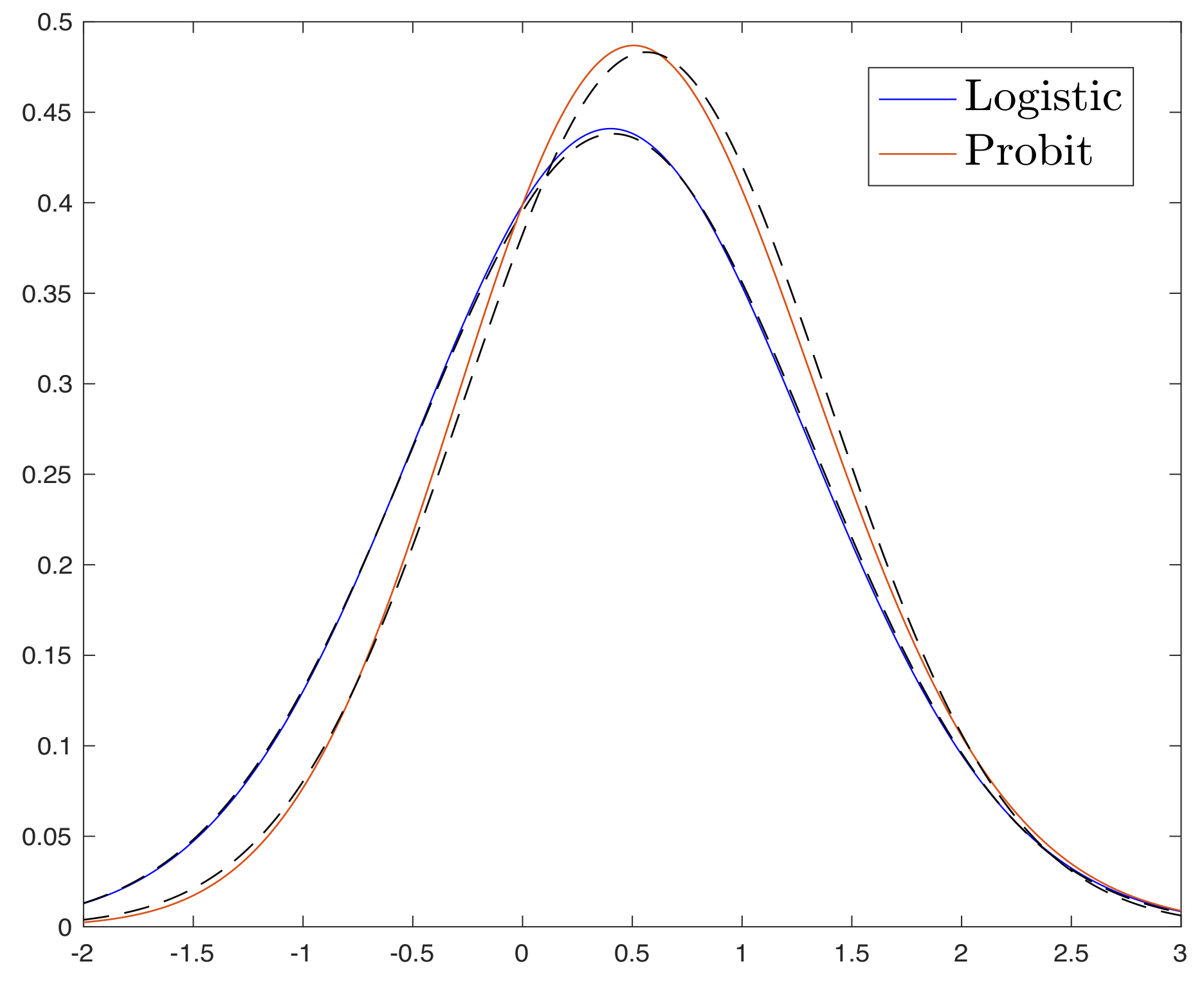
- Logistic:
- Probit:
1.3. Empirical Risk Minimization
- Least Squares (LS):,
- Least-Absolute Deviations (LAD):,
- Logistic Loss:,
- Exponential Loss:,
- Hinge Loss:.
1.4. Contributions and Organization
- Precise Asymptotics: We show that the absolute value of correlation of to the true vector is sharply predicted by where the “effective noise” parameter can be explicitly computed by solving a system of three non-linear equations in three unknowns. We find that the system of equations (and, thus, the value of ) depends on the loss function ℓ through its Moreau envelope function. Our prediction holds in the linear asymptotic regime in which and (see Section 2).
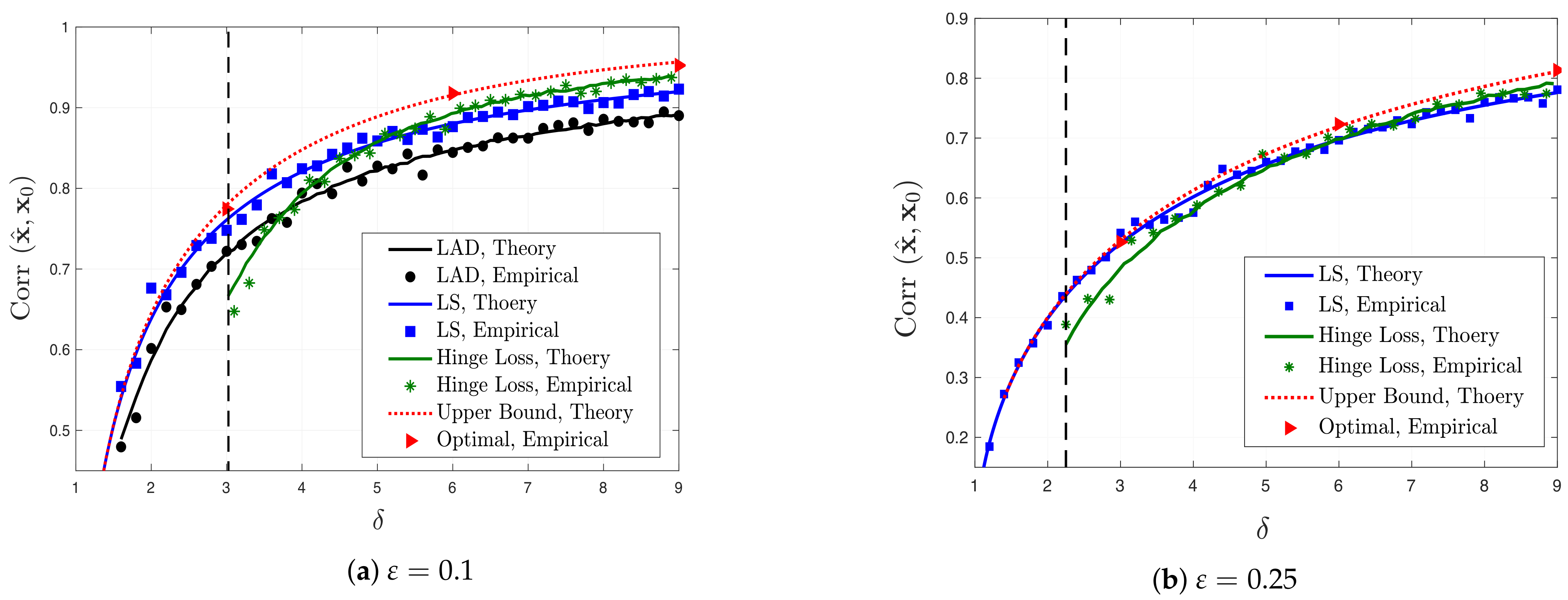
- Fundamental Limits: We establish fundamental limits on the performance of convex optimization-based estimators by computing an upper bound on the best possible correlation performance among all convex loss functions. We compute the upper bound by solving a certain nonlinear equation and we show that such a solution exists for all (see Section 3.1).
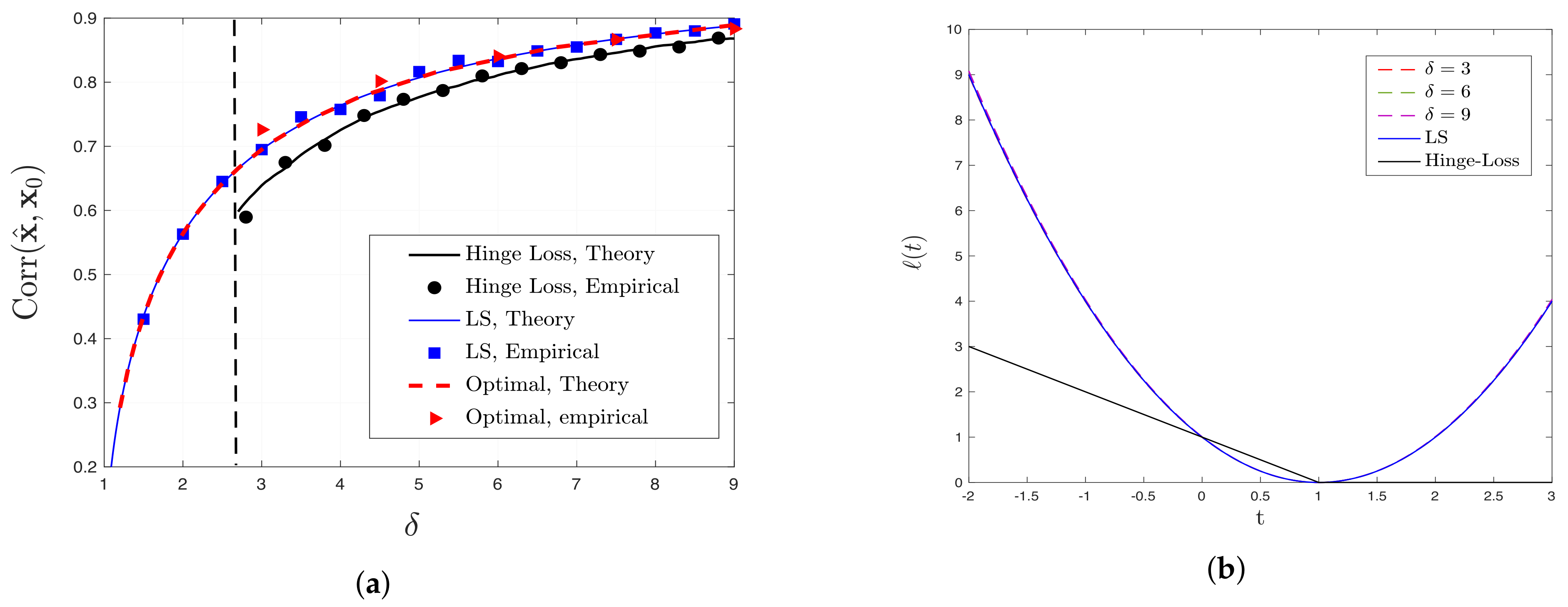
- Optimal Performance and (sub)-optimality of LS for binary models: For certain binary models including signed and logistic, we find the loss functions that achieve the optimal performance, i.e., they attain the previously derived upper bound (see Section 3.2). Interestingly, for logistic and Probit models with , we prove that the correlation performance of least-squares (LS) is at least as good 0.9972 and 0.9804 times the optimal performance. However, as grows large, logistic and Probit models approach the signed model, in which case LS becomes sub-optimal (see Section 4.1).
- Extension to the Gaussian-Mixture Model: In Section 5, we extend the fundamental limits and the system of equations to the Gaussian-mixture model. Interestingly, our results indicate that, for this model, LS is optimal among all convex loss functions for all .
- Numerical Simulations: We do numerous experiments to specialize our results to popular models and loss functions, for which we provide simulation results that demonstrate the accuracy of the theoretical predictions (see Section 6 and Appendix E).
1.5. Related Works
- (a)
- Sharp asymptotics for linear measurements.
- (b)
- One-bit compressed sensing.
- (c)
- Classification in high-dimensions.
2. Sharp Performance Guarantees
2.1. Definitions
2.2. A System of Equations
2.3. Asymptotic Prediction
3. On Optimal Performance
3.1. Fundamental Limits
3.2. On the Optimal Loss Function
4. Special Cases
4.1. Least-Squares
4.2. Logistic and Hinge Loss
5. Extensions to Gaussian-Mixture Models
5.1. System of Equations for GMM
5.2. Theoretical Prediction of Error for Convex Loss Functions
5.3. Special Case: Least-Squares
5.4. Optimal Risk for GMM
6. Numerical Experiments
Numerical Experiments for GMM
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Properties of Moreau Envelopes
Appendix A.1. Derivatives
- (a)
- The proximal operator is unique and continuous. In fact, whenever with .
- (b)
- The value is finite and depends continuously on , with for all x as .
- (c)
- The Moreau envelope function is differentiable with respect to both arguments. Specifically, for all , the following properties are true:If in addition ℓ is differentiable and denotes its derivative, then
Appendix A.2. Alternative Representations of (8)
Appendix A.3. Examples of Proximal Operators
Appendix A.4. Fenchel–Legendre Conjugate Representation
Appendix A.5. Convexity of the Moreau Envelope
Appendix A.6. The Expected Moreau-Envelope (EME) Function and its Properties
Appendix A.6.1. Derivatives
Appendix A.6.2. Strict Convexity
“ If ℓ is strictly convex and does not attain its minimum at 0, then is also strictly convex. ”
- , for all .
- .
Appendix A.6.3. Strict Concavity
“ If ℓ is convex, continuously differentiable and , then is strictly concave. ”
Appendix A.6.4. Summary of Properties of (uid135)
- (a)
- The function Ω is differentiable and its derivatives are given as follows:
- (b)
- The function Ω is jointly convex and concave on γ.
- (c)
- The function Ω is increasing in α.For the statements below, further assume that ℓ is strictly convex and continuously differentiable with .
- (d)
- The function Ω is strictly convex in and strictly concave in λ.
- (e)
- The function Ω is strictly increasing in α.
Appendix B. Proof of Theorem 1
Appendix B.1. Technical Tool: CGMT
Appendix B.1.1. Gordon’s Min-Max Theorem (GMT)
Appendix B.1.2. Convex Gaussian Min-Max Theorem (CGMT)
Appendix B.2. Applying the CGMT to ERM for Binary Classification
Appendix B.3. Analysis of the Auxiliary Optimization
Appendix B.4. Convex-Concavity and First-Order Optimality Conditions
Appendix B.5. On the Uniqueness of Solutions to (A57): Proof of Proposition 1
Appendix C. Discussions on the Fundamental Limits for Binary Models
- On the Uniqueness of Solutions to Equation
Appendix C.1. Distribution of SY in Special Cases
- Signed:
- Logistic:
- Probit:


Appendix D. Proofs and Discussions on the Optimal Loss Function
Appendix D.1. Proof of Theorem 3
Appendix D.2. On the Convexity of Optimal Loss Function
Appendix D.2.1. Provable Convexity of the Optimal Loss Function for Signed Model
Appendix E. Noisy-Signed Measurement Model


Appendix F. On LS Performance for Binary Models
Appendix F.1. Proof of Corollary 2
Appendix F.2. Discussion
Linear vs. Binary
Appendix G. Fundamental Limits for Gaussian-Mixture Models: Proofs for Section 5
Appendix G.1. Proof of Corollary 3
Appendix G.2. Proof of Theorem 5
References
- Donoho, D.L. High-dimensional data analysis: The curses and blessings of dimensionality. AMS Math. Chall. Lect. 2000, 1, 32. [Google Scholar]
- Donoho, D.L. Compressed sensing. Inf. Theory IEEE Trans. 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Stojnic, M. Various thresholds for ℓ1-optimization in compressed sensing. arXiv 2009, arXiv:0907.3666. [Google Scholar]
- Chandrasekaran, V.; Recht, B.; Parrilo, P.A.; Willsky, A.S. The convex geometry of linear inverse problems. Found. Comput. Math. 2012, 12, 805–849. [Google Scholar] [CrossRef]
- Donoho, D.L.; Maleki, A.; Montanari, A. The noise-sensitivity phase transition in compressed sensing. Inf. Theory IEEE Trans. 2011, 57, 6920–6941. [Google Scholar] [CrossRef] [Green Version]
- Tropp, J.A. Convex recovery of a structured signal from independent random linear measurements. arXiv 2014, arXiv:1405.1102. [Google Scholar]
- Oymak, S.; Tropp, J.A. Universality laws for randomized dimension reduction, with applications. Inf. Inference J. IMA 2017, 7, 337–446. [Google Scholar] [CrossRef]
- Bayati, M.; Montanari, A. The LASSO risk for gaussian matrices. Inf. Theory IEEE Trans. 2012, 58, 1997–2017. [Google Scholar] [CrossRef] [Green Version]
- Stojnic, M. A framework to characterize performance of LASSO algorithms. arXiv 2013, arXiv:1303.7291. [Google Scholar]
- Oymak, S.; Thrampoulidis, C.; Hassibi, B. The Squared-Error of Generalized LASSO: A Precise Analysis. arXiv 2013, arXiv:1311.0830. [Google Scholar]
- Karoui, N.E. Asymptotic behavior of unregularized and ridge-regularized high-dimensional robust regression estimators: Rigorous results. arXiv 2013, arXiv:1311.2445. [Google Scholar]
- Bean, D.; Bickel, P.J.; El Karoui, N.; Yu, B. Optimal M-estimation in high-dimensional regression. Proc. Natl. Acad. Sci. USA 2013, 110, 14563–14568. [Google Scholar] [CrossRef] [Green Version]
- Thrampoulidis, C.; Oymak, S.; Hassibi, B. Regularized Linear Regression: A Precise Analysis of the Estimation Error. In Proceedings of the 28th Conference on Learning Theory, Paris, France, 3–6 July 2015; pp. 1683–1709. [Google Scholar]
- Donoho, D.; Montanari, A. High dimensional robust m-estimation: Asymptotic variance via approximate message passing. Probab. Theory Relat. Fields 2016, 166, 935–969. [Google Scholar] [CrossRef] [Green Version]
- Thrampoulidis, C.; Abbasi, E.; Hassibi, B. Precise Error Analysis of Regularized M-Estimators in High Dimensions. IEEE Trans. Inf. Theory 2018, 64, 5592–5628. [Google Scholar] [CrossRef] [Green Version]
- Advani, M.; Ganguli, S. Statistical mechanics of optimal convex inference in high dimensions. Phys. Rev. X 2016, 6, 031034. [Google Scholar] [CrossRef] [Green Version]
- Weng, H.; Maleki, A.; Zheng, L. Overcoming the limitations of phase transition by higher order analysis of regularization techniques. Ann. Stat. 2018, 46, 3099–3129. [Google Scholar] [CrossRef] [Green Version]
- Thrampoulidis, C.; Xu, W.; Hassibi, B. Symbol Error Rate Performance of Box-relaxation Decoders in Massive MIMO. IEEE Trans. Signal Process. 2018, 66, 3377–3392. [Google Scholar] [CrossRef] [Green Version]
- Miolane, L.; Montanari, A. The distribution of the Lasso: Uniform control over sparse balls and adaptive parameter tuning. arXiv 2018, arXiv:1811.01212. [Google Scholar]
- Bu, Z.; Klusowski, J.; Rush, C.; Su, W. Algorithmic analysis and statistical estimation of slope via approximate message passing. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BD, Canada, 8–14 December 2019; pp. 9361–9371. [Google Scholar]
- Xu, J.; Maleki, A.; Rad, K.R.; Hsu, D. Consistent risk estimation in high-dimensional linear regression. arXiv 2019, arXiv:1902.01753. [Google Scholar]
- Celentano, M.; Montanari, A. Fundamental Barriers to High-Dimensional Regression with Convex Penalties. arXiv 2019, arXiv:1903.10603. [Google Scholar]
- Kammoun, A.; Alouini, M.S. On the precise error analysis of support vector machines. arXiv 2020, arXiv:2003.12972. [Google Scholar]
- Amelunxen, D.; Lotz, M.; McCoy, M.B.; Tropp, J.A. Living on the edge: A geometric theory of phase transitions in convex optimization. arXiv 2013, arXiv:1303.6672. [Google Scholar]
- Donoho, D.L.; Johnstone, L.; Montanari, A. Accurate Prediction of Phase Transitions in Compressed Sensing via a Connection to Minimax Denoising. IEEE Trans. Inf. Theory 2013, 59, 3396–3433. [Google Scholar] [CrossRef] [Green Version]
- Mondelli, M.; Montanari, A. Fundamental limits of weak recovery with applications to phase retrieval. arXiv 2017, arXiv:1708.05932. [Google Scholar] [CrossRef] [Green Version]
- Taheri, H.; Pedarsani, R.; Thrampoulidis, C. Fundamental limits of ridge-regularized empirical risk minimization in high dimensions. arXiv 2020, arXiv:2006.08917. [Google Scholar]
- Bayati, M.; Lelarge, M.; Montanari, A. Universality in polytope phase transitions and message passing algorithms. Ann. Appl. Probab. 2015, 25, 753–822. [Google Scholar] [CrossRef]
- Panahi, A.; Hassibi, B. A universal analysis of large-scale regularized least squares solutions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3381–3390. [Google Scholar]
- Abbasi, E.; Salehi, F.; Hassibi, B. Universality in learning from linear measurements. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BD, Canada, 8–14 December 2019; pp. 12372–12382. [Google Scholar]
- Goldt, S.; Reeves, G.; Mézard, M.; Krzakala, F.; Zdeborová, L. The Gaussian equivalence of generative models for learning with two-layer neural networks. arXiv 2020, arXiv:2006.14709. [Google Scholar]
- Donoho, D.L.; Maleki, A.; Montanari, A. Message-passing algorithms for compressed sensing. Proc. Natl. Acad. Sci. USA 2009, 106, 18914–18919. [Google Scholar] [CrossRef] [Green Version]
- Bayati, M.; Montanari, A. The dynamics of message passing on dense graphs, with applications to compressed sensing. Inf. Theory IEEE Trans. 2011, 57, 764–785. [Google Scholar] [CrossRef] [Green Version]
- Mousavi, A.; Maleki, A.; Baraniuk, R.G. Consistent parameter estimation for LASSO and approximate message passing. Ann. Stat. 2018, 46, 119–148. [Google Scholar] [CrossRef] [Green Version]
- El Karoui, N. On the impact of predictor geometry on the performance on high-dimensional ridge-regularized generalized robust regression estimators. Probab. Theory Relat. Fields 2018, 170, 95–175. [Google Scholar] [CrossRef] [Green Version]
- Boufounos, P.T.; Baraniuk, R.G. 1-bit compressive sensing. In Proceedings of the 2008 IEEE 42nd Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 19–21 March 2008; pp. 16–21. [Google Scholar]
- Jacques, L.; Laska, J.N.; Boufounos, P.T.; Baraniuk, R.G. Robust 1-bit compressive sensing via binary stable embeddings of sparse vectors. IEEE Trans. Inf. Theory 2013, 59, 2082–2102. [Google Scholar] [CrossRef] [Green Version]
- Plan, Y.; Vershynin, R. One-Bit Compressed Sensing by Linear Programming. Commun. Pure Appl. Math. 2013, 66, 1275–1297. [Google Scholar] [CrossRef] [Green Version]
- Plan, Y.; Vershynin, R. Robust 1-bit compressed sensing and sparse logistic regression: A convex programming approach. IEEE Trans. Inf. Theory 2012, 59, 482–494. [Google Scholar] [CrossRef] [Green Version]
- Plan, Y.; Vershynin, R. The generalized lasso with non-linear observations. IEEE Trans. Inf. Theory 2016, 62, 1528–1537. [Google Scholar] [CrossRef]
- Genzel, M. High-dimensional estimation of structured signals from non-linear observations with general convex loss functions. IEEE Trans. Inf. Theory 2017, 63, 1601–1619. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Jacques, L. Quantized compressive sensing with rip matrices: The benefit of dithering. arXiv 2018, arXiv:1801.05870. [Google Scholar] [CrossRef]
- Thrampoulidis, C.; Abbasi, E.; Hassibi, B. Lasso with non-linear measurements is equivalent to one with linear measurements. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 3420–3428. [Google Scholar]
- Candès, E.J.; Sur, P. The phase transition for the existence of the maximum likelihood estimate in high-dimensional logistic regression. arXiv 2018, arXiv:1804.09753. [Google Scholar] [CrossRef] [Green Version]
- Sur, P.; Candès, E.J. A modern maximum-likelihood theory for high-dimensional logistic regression. Proc. Natl. Acad. Sci. USA 2019, 201810420. [Google Scholar] [CrossRef] [Green Version]
- Mai, X.; Liao, Z.; Couillet, R. A Large Scale Analysis of Logistic Regression: Asymptotic Performance and New Insights. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3357–3361. [Google Scholar]
- Salehi, F.; Abbasi, E.; Hassibi, B. The Impact of Regularization on High-dimensional Logistic Regression. arXiv 2019, arXiv:1906.03761. [Google Scholar]
- Montanari, A.; Ruan, F.; Sohn, Y.; Yan, J. The generalization error of max-margin linear classifiers: High-dimensional asymptotics in the overparametrized regime. arXiv 2019, arXiv:1911.01544. [Google Scholar]
- Deng, Z.; Kammoun, A.; Thrampoulidis, C. A Model of Double Descent for High-dimensional Binary Linear Classification. arXiv 2019, arXiv:1911.05822. [Google Scholar]
- Mignacco, F.; Krzakala, F.; Lu, Y.M.; Zdeborová, L. The role of regularization in classification of high-dimensional noisy Gaussian mixture. arXiv 2020, arXiv:2002.11544. [Google Scholar]
- Aubin, B.; Krzakala, F.; Lu, Y.M.; Zdeborová, L. Generalization error in high-dimensional perceptrons: Approaching Bayes error with convex optimization. arXiv 2020, arXiv:2006.06560. [Google Scholar]
- Rockafellar, R.T.; Wets, R.J.B. Variational Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009; Volume 317. [Google Scholar]
- Barron, A.R. Monotonic Central Limit Theorem for Densities; Technical Report; Stanford University: Stanford, CA, USA, 1984. [Google Scholar]
- Costa, M.H.M. A new entropy power inequality. IEEE Trans. Inf. Theory 1985, 31, 751–760. [Google Scholar] [CrossRef]
- Blachman, N. The convolution inequality for entropy powers. IEEE Trans. Inf. Theory 1965, 11, 267–271. [Google Scholar] [CrossRef]
- Brillinger, D.R. A Generalized Linear Model with “Gaussian” Regressor Variables. In A Festschrift For Erich L. Lehmann; Springer: New York, NY, USA, 1982; p. 97. [Google Scholar]
- Dhifallah, O.; Lu, Y.M. A precise performance analysis of learning with random features. arXiv 2020, arXiv:2008.11904. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Gordon, Y. On Milman’s Inequality and Random Subspaces which Escape through a Mesh in Rn; Springer: Berlin/Heidelberg, Germany, 1988. [Google Scholar]
- Dhifallah, O.; Thrampoulidis, C.; Lu, Y.M. Phase retrieval via polytope optimization: Geometry, phase transitions, and new algorithms. arXiv 2018, arXiv:1805.09555. [Google Scholar]
- Rockafellar, R.T. Convex Analysis; Princeton University Press: Princeton, NJ, USA, 1970. [Google Scholar]
- Genzel, M.; Jung, P. Recovering structured data from superimposed non-linear measurements. arXiv 2017, arXiv:1708.07451. [Google Scholar] [CrossRef]
- Goldstein, L.; Minsker, S.; Wei, X. Structured signal recovery from non-linear and heavy-tailed measurements. IEEE Trans. Inf. Theory 2018, 64, 5513–5530. [Google Scholar] [CrossRef]
- Thrampoulidis, C.; Rawat, A.S. The generalized lasso for sub-gaussian measurements with dithered quantization. arXiv 2018, arXiv:1807.06976. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|
| Predicted Performance | ||||||||
| Empirical (Gaussian) | ||||||||
| Empirical (Rademacher) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taheri, H.; Pedarsani, R.; Thrampoulidis, C. Sharp Guarantees and Optimal Performance for Inference in Binary and Gaussian-Mixture Models. Entropy 2021, 23, 178. https://doi.org/10.3390/e23020178
Taheri H, Pedarsani R, Thrampoulidis C. Sharp Guarantees and Optimal Performance for Inference in Binary and Gaussian-Mixture Models. Entropy. 2021; 23(2):178. https://doi.org/10.3390/e23020178
Chicago/Turabian StyleTaheri, Hossein, Ramtin Pedarsani, and Christos Thrampoulidis. 2021. "Sharp Guarantees and Optimal Performance for Inference in Binary and Gaussian-Mixture Models" Entropy 23, no. 2: 178. https://doi.org/10.3390/e23020178
APA StyleTaheri, H., Pedarsani, R., & Thrampoulidis, C. (2021). Sharp Guarantees and Optimal Performance for Inference in Binary and Gaussian-Mixture Models. Entropy, 23(2), 178. https://doi.org/10.3390/e23020178